1.摘要
以往的情感分类大多是基于粗粒度进行的,针对七分类情感语料进行的研究不多,且最终的情感分类结果只包含一种情感,很少对多情感共存现象进行研究,因此不能完全体现用户情感的丰富性。
针对这些不足,本文提出一种基于Attention与BiLSTM模型的多情感分类方法,通过BiLSTM模型构建五个情感分类器来获取文本上下文关系,分别是1.愤怒;2.无聊;3.焦虑;4.幸福;5.悲伤;6.厌恶;7. 中立(如Happiness、Anger、Sadness、Fear、Surprise等)情感分类器,引入Attention机制来表示不同特征的重要性,增强上下文语义信息,并获取更深层次特征,最后通过Softmax进行回归,完成所属情感的预测。通过对基于Attention与BiLSTM模型的实验结果进行分析得出结论:基于Attention与BiLSTM模型的多情感分类方法研究可以更为准确的判别文本的多种情感,取得了更好地分类效果,验证了模型的有效性。
基于研究结果建立语音检测平台。设计由服务器计算支持,编程完成语音检测平台网页搭建。用Flask搭建网页框架,用html编写网页前端,采用HTTPS协议实现服务器和浏览器间的内容传输。在该检测平台完成情绪检测。经实验验证论文完成的算法是有效的。
2. Attention-BiLSTM模型的设计与实验
2.1 Attention-BiLSTM模型结构及核心代码
本文提出一种基于Attention与BiLSTM的多情感分类模型,并将其应用在语音情感分类研究中。Attention与BiLSTM模型如图所示,首先Attention机制增强上下文语义信息,并获取更深层次特征,最后通过Softmax进行回归,完成所属语音情感的预测。
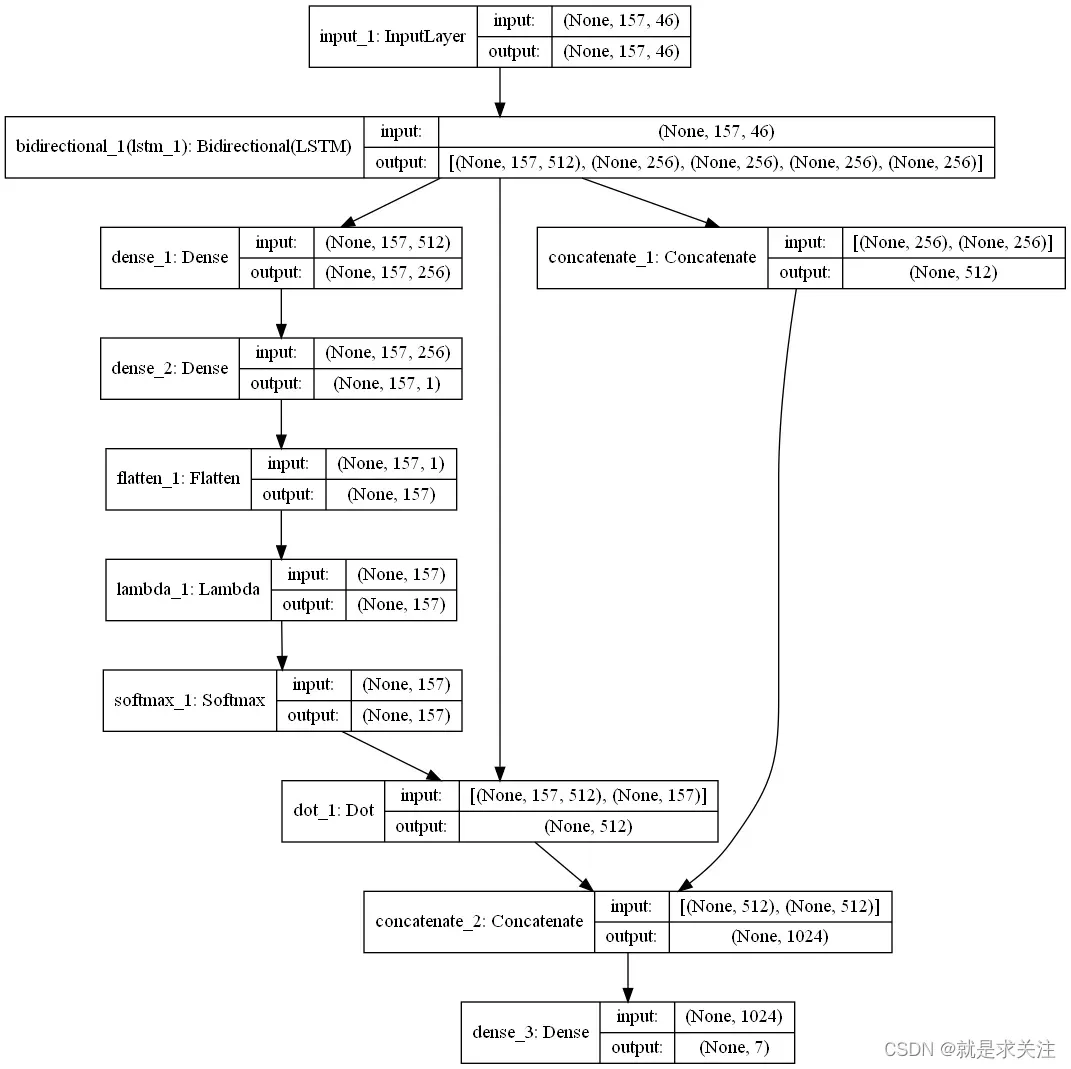
模型核心代码如下:
input = keras.Input(shape=(pre_proc.N_FRAMES, pre_proc.N_FEATURES))
states, forward_h, _, backward_h, _ = layers.Bidirectional(layers.LSTM(units, return_sequences=True, return_state=True))(input)
last_state = layers.Concatenate()([forward_h, backward_h])
hidden = layers.Dense(units, activation="tanh", use_bias=False,kernel_initializer=keras.initializers.RandomNormal(mean=0., stddev=1.))(states)
out = layers.Dense(1, activation='linear', use_bias=False,kernel_initializer=keras.initializers.RandomNormal(mean=0., stddev=1.))(hidden)
flat = layers.Flatten()(out)
energy = layers.Lambda(lambda x:x/np.sqrt(units))(flat)
normalize = layers.Softmax(name="alpha")
alpha = normalize(energy)
context_vector = layers.Dot(axes=1)([states, alpha])
context_vector = layers.Concatenate()([context_vector, last_state])
pred = layers.Dense(pre_proc.N_EMOTIONS, activation="softmax")(context_vector)
model = keras.Model(inputs=[input], outputs=[pred])2.2 数据集介绍
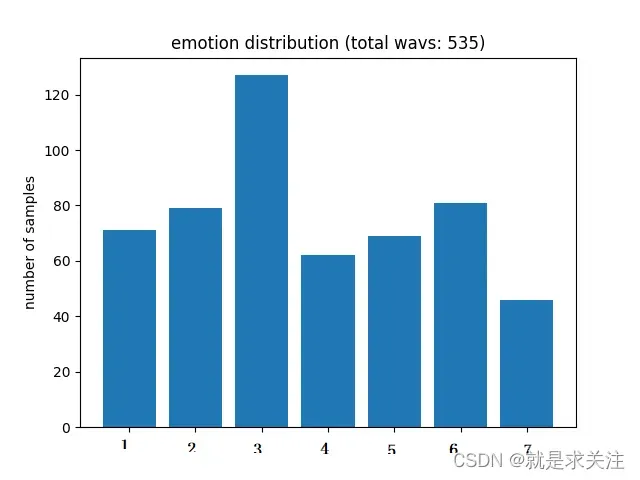
EMODB 数据库是免费提供的德国情感数据库。该数据库由德国柏林工业大学通信科学研究所创建。十名专业演讲者(五男五女)参与了数据记录。该数据库总共包含 535 个话语。EMODB 数据库包含七种情绪:1)愤怒;2)无聊;3)焦虑;4)幸福;5)悲伤;6)厌恶;7) 中立。数据以 48 kHz 的采样率记录,然后下采样至 16 kHz。。该数据库由德国柏林工业大学通信科学研究所创建。十名专业演讲者(五男五女)参与了数据记录。该数据库总共包含 535 个话语。EMODB 数据库包含七种情绪:1)愤怒;2)无聊;3)焦虑;4)幸福;5)悲伤;6)厌恶;7) 中立。( 1) anger; 2) boredom; 3) anxiety; 4) happiness; 5) sadness; 6) disgust; and 7) neutral.)
2.3 实验结果分析
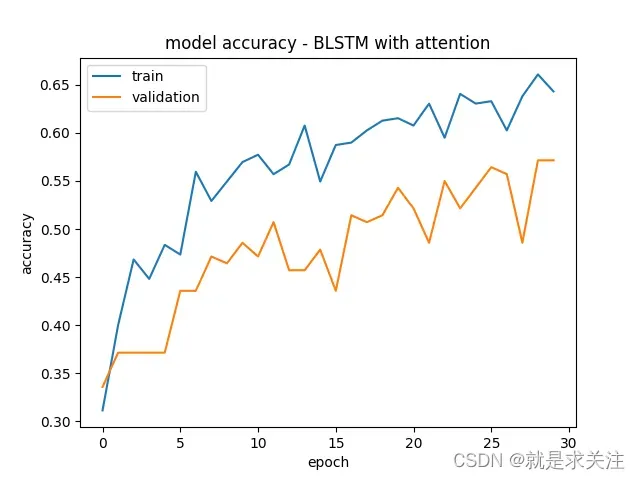
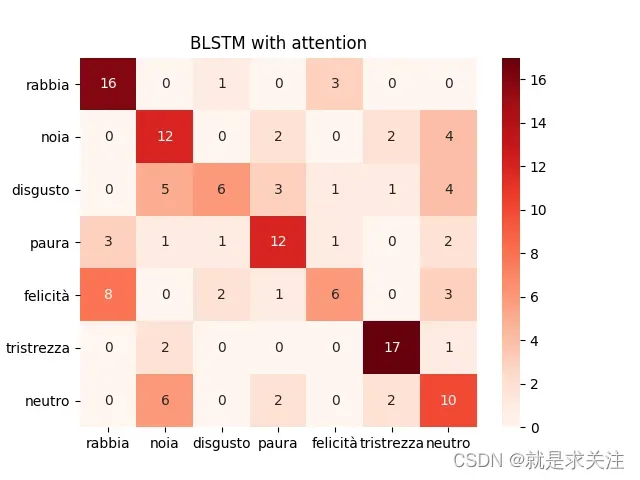
本文提出的Attention与BiLSTM模型的F1值为0.57,证明本文提出的Attention与BiLSTM模型很好的考虑文本情感之间的关联,解决情感语义信息丢失问题,通过多情感分类器预测帖子可能存在的所有情感,更加符合人类的情感丰富性。同时根据多情感共存的情况在情感分类任务中占有较大的比重这一现象及实验结果来看,Attention与BiLSTM模型的多分类器是提高了模型Marco-F1值的关键因素之一。
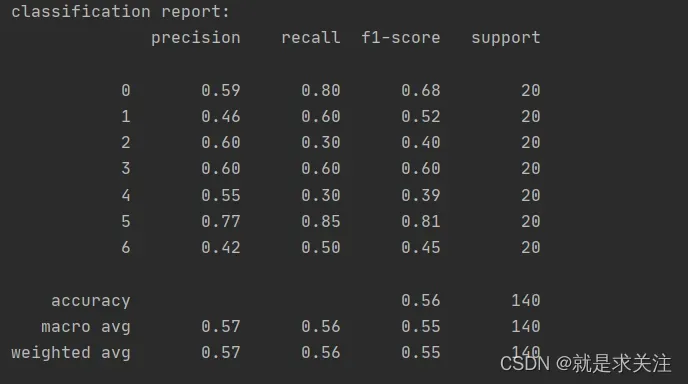
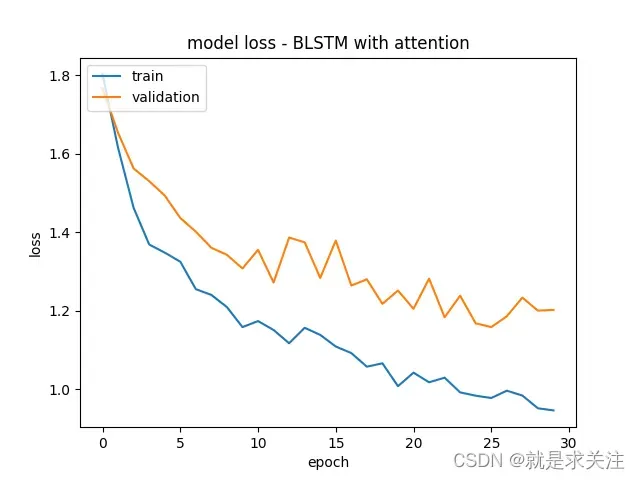
其实验结果图如下:
3. 语音识别系统实现
3.1 环境搭建
对于提到的语音情感识别方法平台为基于Windows操作系统的个人主机,深度学习框架采用的是tensorflow和Keras,其中TensorFlow作为Keras的后端。具体配置如下:
python3.6.5、tensorflow=1.12、Keras=2.2.4、flask==1.0.2 、librosa等
3.2 系统实现与展示
Flask是使用Python编写的Web微框架。Flask主要依赖两种工具,一个是Web服务器网关接口(Web ServerGateway Interface WSGI)工具集—Werkzeug,另一个是Jinja2模板引擎,不需要关心底层的请求响应处理,能更方便、高效地编写Web程序。

4.总结
本内容为基于深度学习的语音情感识别,作为情感识别的一个重要领域,语音情感识别将受到工业界和学术界的越发重视,完善成熟的语音情感识别系统,将会为日后便捷的人机交互系统提供有力支撑。
代码连接:
models文件下的结构如下:包含三个模型和各种图。
算法、应用全部代码下载连接:
基于Attention机制的BiLSTM语音情感识别研究与web系统实现-深度学习文档类资源-CSDN下载
文章出处登录后可见!