简单介绍一下自己最近发表在TIP上的一个工作: Learning Discriminative Cross-modality Features for RGB-D Saliency Detection (2021)
在这个工作里,我们提出了一种新的跨模态融合策略,关联度融合(correlation fusion),用于解决基于RGB-D(Depth)数据的显著性目标检测任务。

任务介绍
显著性物体检测(salient object detection, SOD)是为了定位并分割一个视觉场景中最显著(具有视觉吸引力)的物体。本工作基于RGB-D图像,深度图像的输入可以弥补RGB图像丢失的空间信息,从而更好的检测复杂场景下的显著性物体。
难点与动机:
- 难点:模态鸿沟(modality gap)。由于RGB-D图像分别表示不同模态的信息(RGB:颜色信息,D:空间结构信息),简单的特征拼接会引入模态不匹配问题。现有的方法关注于如何设计有效的“交互 / 融合”模块,用于桥接两种模态之间的鸿沟。
- 动机:寻找两种模态之间的共性:任意像素对,来自于同一类别(前景/背景),其关联度会大于来自不同类别的像素对。这一特性同时适用于RGB和D两种模态,并且关联度的值域分布一致(即[0,1]),因此我们提出一种简单的关联度融合作为一种新的跨模态融合策略。
- 优势:融合RGB,D两种模态之间的关联度,可以很好地互补两种模态的不足。比如,图中(上)背景与前景深度图差异较小,可以借用颜色信息很好地区分开来;图中(下)背景与前景颜色相似,可以用深度差区分开来。
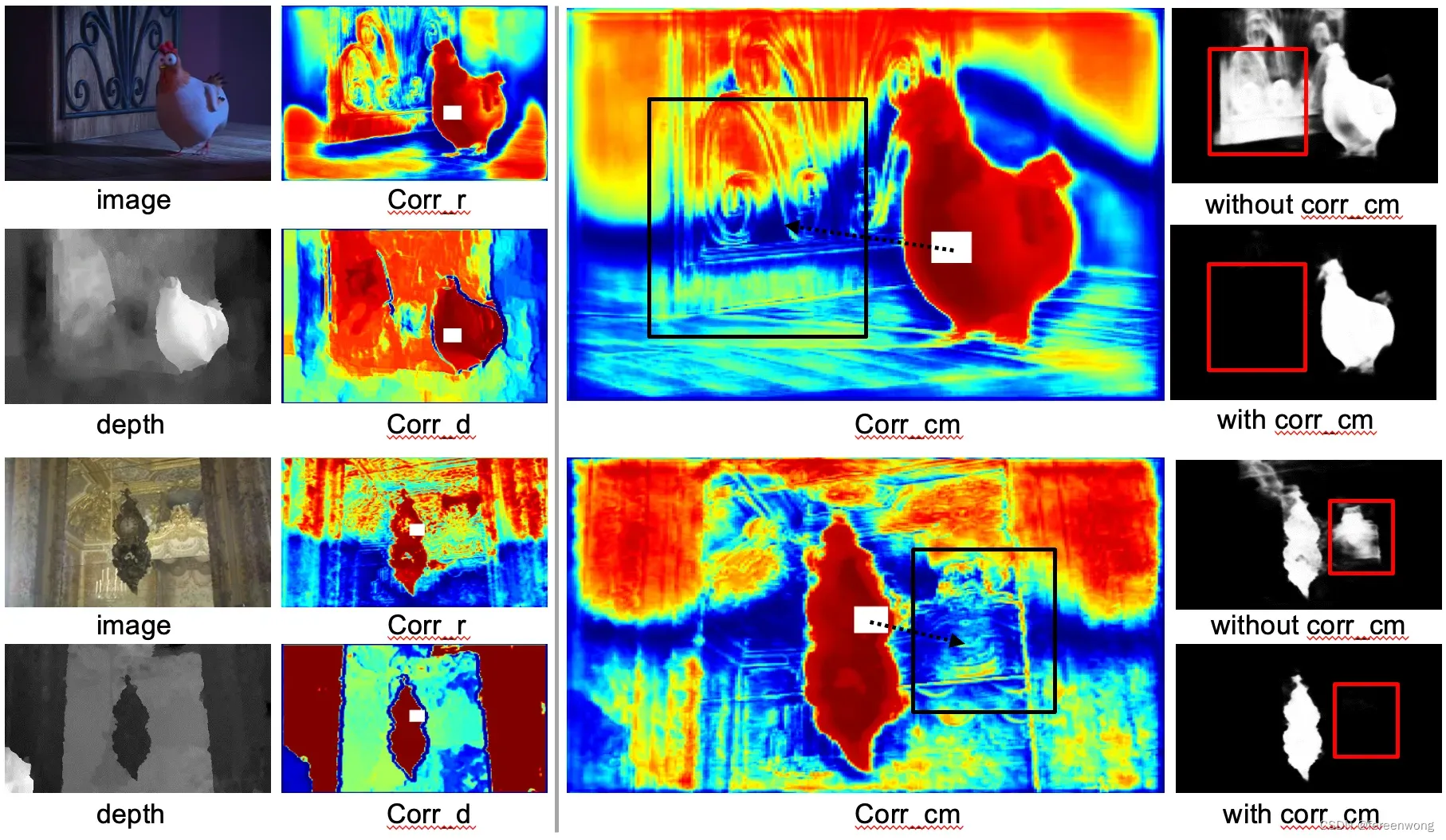 (图中corr_r是基于RGB特征计算的所有像素点与白色方块的关联度,corr_d对应深度特征,corr_cm是融合corr_r与corr_d得到的关联度,最后一列我们对比了加入/移除关联度融合模块的实验结果)
(图中corr_r是基于RGB特征计算的所有像素点与白色方块的关联度,corr_d对应深度特征,corr_cm是融合corr_r与corr_d得到的关联度,最后一列我们对比了加入/移除关联度融合模块的实验结果)
方法概要
长距离关联度融合模块
这一模块是基于RGB与D特征,计算两个模态中像素对之间的关联度。在设计过程中我们考虑两个因素:
1)跨模态一致性,保证在不同模态之间计算的关联度值域范围一致。
我们选用cosine similarity,即对于任一像素点对
, 其特征分别为
,对应的关联度计算如下:
2)计算高效性。
对于一个特征
,如果对于所有像素点对计算关联度,其计算复杂度为
其中
. 而后关联度的计算从原本的
(“点-点”对)转换为在
(“点-块”对)。计算复杂度也由最初的
降为
, 其中
. (注意这里我们没有对特征区分RGB或D,因为在两个模态中,关联度的计算是完全相同的)
最后融合两个模态的关联度。
由于关联度本身不存在跨模态鸿沟,且在不同模态保持了值域一致。基于RGB特征
和Depth特征
分别计算得到
,我们简单地融合两者:
其中
表示跨模态关联度(cm, cross modality).
特征优化模块
得到跨模态的关联度后,我们将其用于特征优化。这部分包含两次特征优化:
第一次:长距离关联度优化,增加上下文环境信息:(模块命名为:CM-LCG, Cross-Modal Long-range Context information Gathering)
1)降维
的卷积层将
;
2)融合
,拼接后经过一个
(ca, context aware)
第二次:短距离关联度优化,优化局部细节:(模块命名为:RFR, relation feature refinement)
1)对于每一个像素点
,计算与卷积核窗口范围内的像素点之间(即
点,以
卷积为例,其中
)的关联度,记为
,
2)在每个滑动窗口内,将常规卷积的weight加权,卷积计算由常规的卷积操作变为动态的卷积:

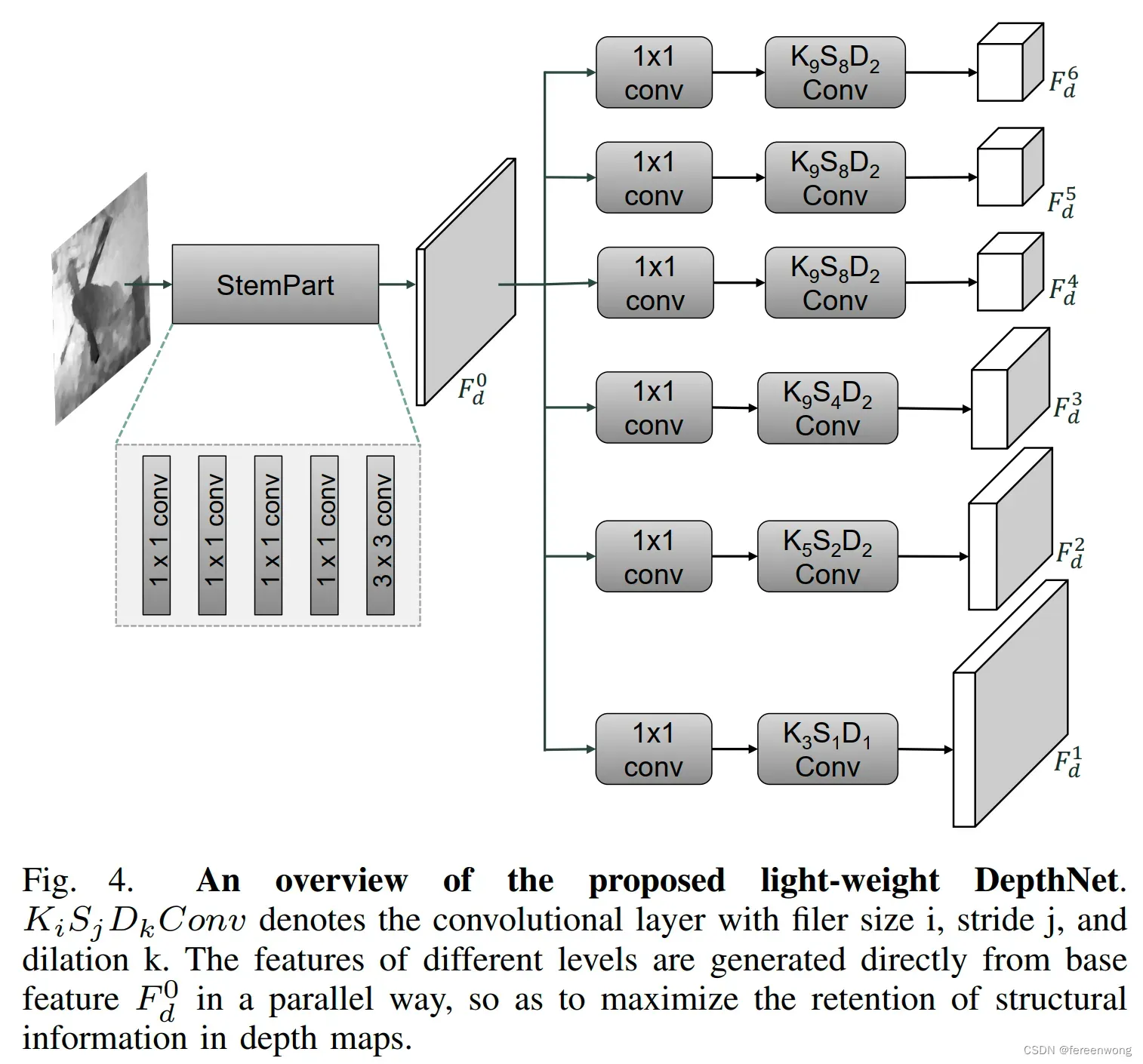
轻量级的深度特征提取模块(DepthNet)
原因:为什么我们需要一个轻量级的深度特征提取模块?
在基于RGB-D图像的显著性检测工作中,在提取深度图像信息时,常见的方法一般有两种:
1)与RGB图像共享特征提取网络,模型会缺乏提取不同模态特有信息的能力;
2)不共享参数且保持与RGB相同的特征提取结构,大大的增加网络参数量。
基于以上不足,我们希望为深度图像设计一个轻量级的、不共享权重的特征提取模块。
思考:为什么可以用轻量级的深度特征提取模块?
1)深度图像作为一个辅助信息,在显著性物体检测任务中,深度图像提供的是物体之间的相对深度差。不同于RGB图像,需要大的网络提取复杂的特征,深度图像在这个工作中只用于计算像素间的关联度。(可以仔细观察一下上面的公式,即,用大网络没多大必要)
2)深度图像难以从大的网络中得到更多的优势,因为这些网络都是以ImageNet(仅RGB图像)预训练的参数初始化的。(即,用大网络没多大好处)
设计轻量级深度特征提取网络的时候,为了更好的保留深度图像的几何结构特征,重点考虑两个设计思路:
1)平行分支用于多层次特征提取。如果采用顺序结构,多层卷积后,容易平滑深度图像的深度差,因此我们在简单的主干网络后面,采用平行分支提取多尺度特征;
2)移除池化层。此外,多尺度的实现我们用不同stride(
)的卷积层来实现对特征的下采样
本文中的深度图特征提取网络结构:
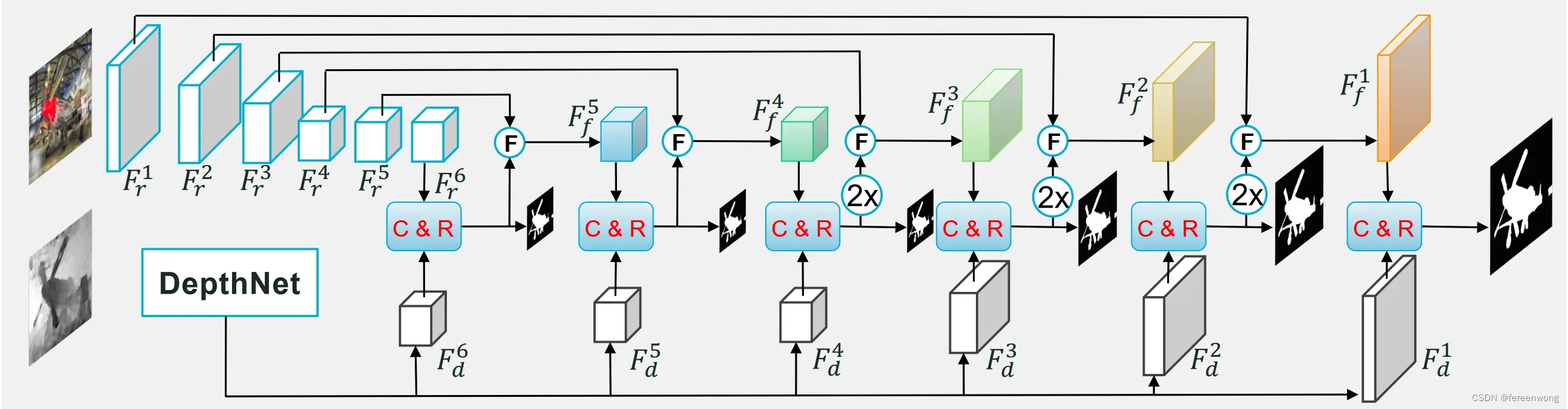
总体流程图
我们提出的模型总体流程图如下,我们的贡献点主要体现在两个模块:
1)DepthNet, 我们提出的轻量级深度图特征提取模块;
2)C&R,我们提出的关联度特征优化模块,其中C是指CM-LCG, R指的是RFR。
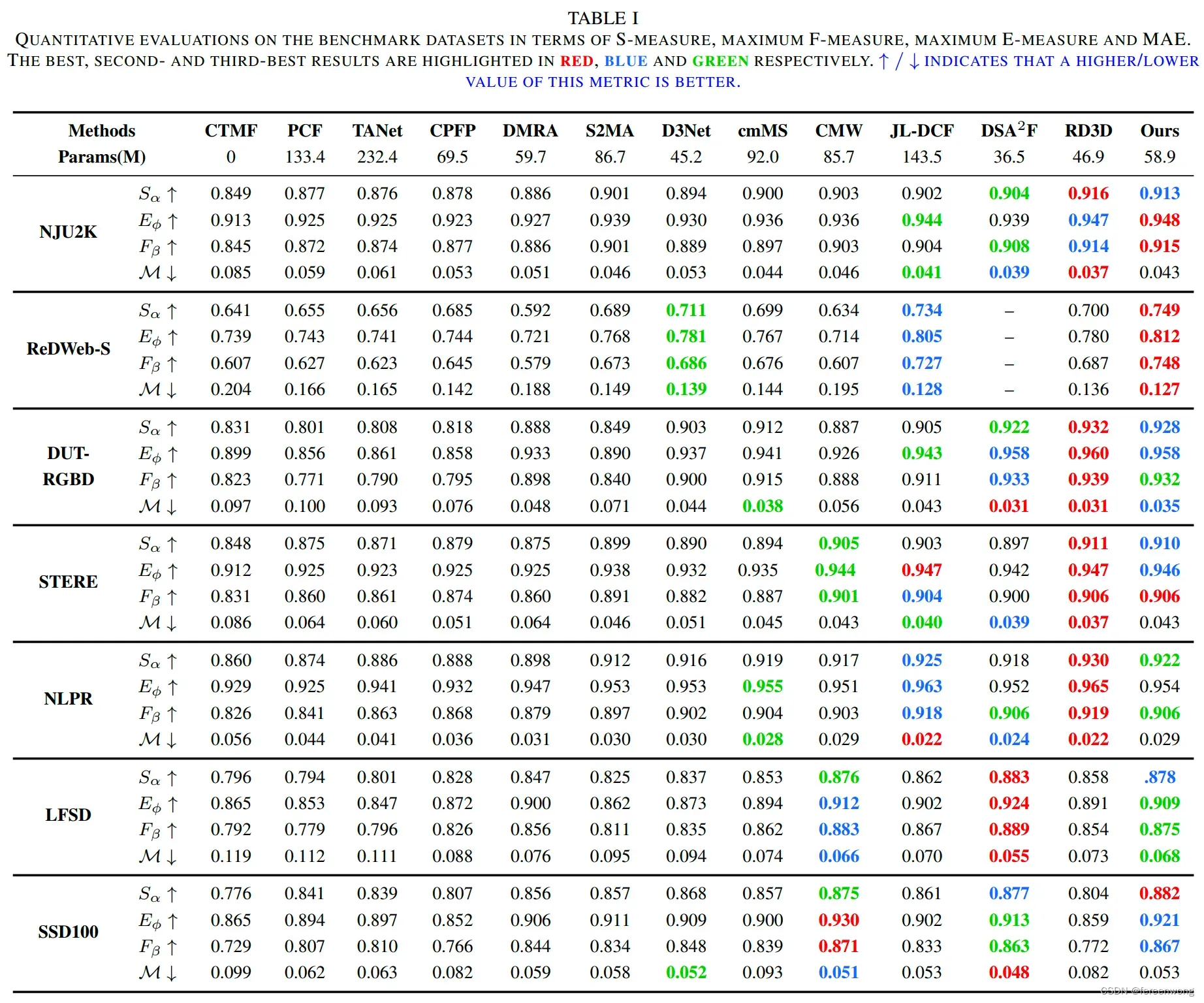
实验结果
- 我们在七个常用的RGB-D显著性物体检测数据集上进行实验,包括NJU2K, ReDWeb-S, DUT-RGBD, NLPR, LFSD, STERE 和SSD.
- 综合考虑七个数据集上的总体性能:
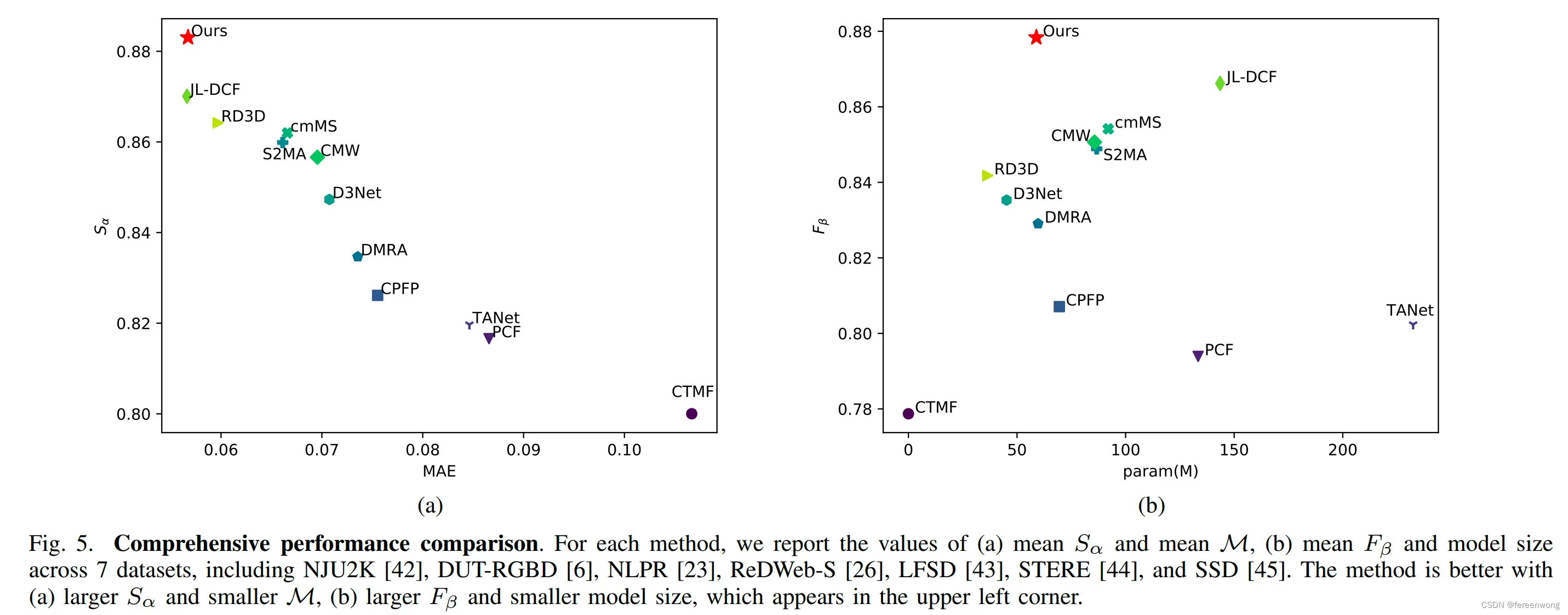
左边对比指标和
,更高
和更低的
表示模型性能更优(越靠近左上角)
右边对比指标和模型参数量,更高
和更小的模型参数表示模型性能更优(越靠近在左上角)
- 可视化对比:

文章出处登录后可见!