论文地址:https://arxiv.org/pdf/2102.10772.pdf
相关博客:
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
一、简介
在各个领域都获得的巨大的成功,包括但不限于自然语言、图像、视频和音频。先前的工作表明,在大规模语料上预训练的
能够学习到有益于下游广泛语言任务的向量表示。在视觉领域,基于
的模型也在图像分类、目标检测和全景分割上实现了很好的效果。除了建模单一模态外,
模型也在
等联合视觉-语言推理任务上实现了很好的表现。
然而,尽管在特定领域的应用中达成了不错的成就,但是基于
的跨领域链接不同任务的工作并不多。在目睹了
的成功后,各种问题自然会出现:用于自然语言推理训练的
模型是否也能在图像上执行目标检测,或者说基于
的图像编码器是否能用来进行检测文本蕴含?总的来说,是否能够建立单个模型来同时处理不同领域的各种任务,向通用人工智能前进一步?先前的工作尝试解决这些问题,但是存在一定的限制:
- 仅应用在单个领域或者特定模态的任务上;
和
仅专注在视觉任务上,
以及延伸的工作仅能处理语言任务,而
和
等仅在特定的视觉-语言多模态领域。
- 对于每个任务涉及任务相关的微调,没有在任务间利用共享参数,通常
个任务具有
- 仅在单个领域中的相关或者相似任务上执行多任务,有时会使用硬编码的训练策略;例如,
仅在语言领域任务上工作,而
则仅在相关的视觉-语言任务上。
在本文中,作者构建了一个称为的统一
模型,其将图像和(或)文本作为输入,然而在视觉感知、自然语言理解和联合视觉-语言推理的各种任务上进行联合训练。
由
编码器构成,其能够将每个输入模态编码为
hidden states,在编码后的输入模态上应用一个解码器,然后在解码器的输出上应用一个任务相关的输出头来对每个任务进行预测。相较于先前基于
的多任务学习工作,
在更广阔的任务上实现了与先前工作相当的效果,不仅仅
这样的视觉语言任务,也有纯视觉和纯语言任务。本文的贡献如下:
- 提出了
,一个统一的
编码器解码器架构,能够使用较少的参数来同时处理多任务和多领域;
- 学习视觉领域、文本领域和交叉领域的最突出的任务,包括目标检测、
、视觉蕴含以及
基准上的自然语言理解任务,包括
、
、
和
。证明了这些多样的任务能够同时学习,并且在本文的训练方案下能够适当收敛;
- 通过对各种任务的分析,展示了像
二、:跨领域统一
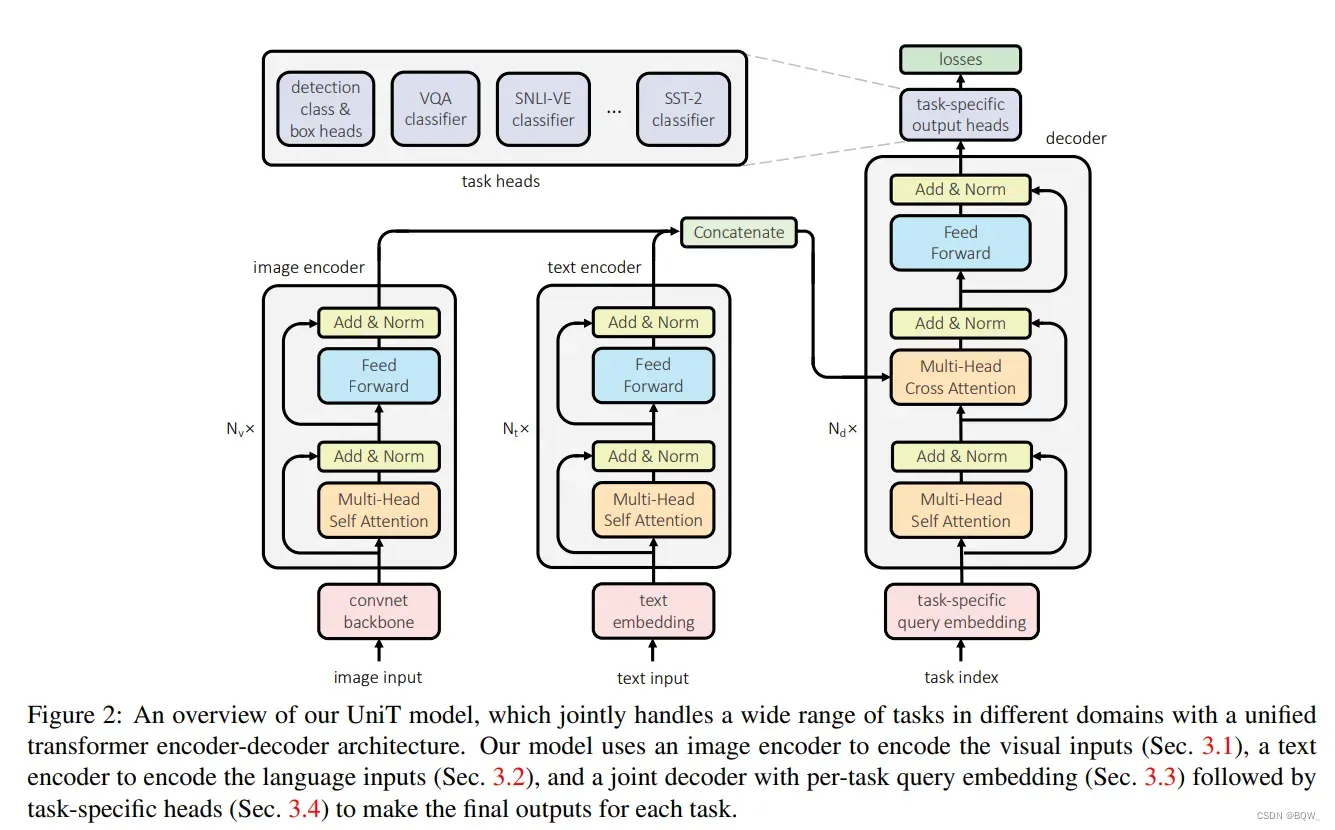
本工作中,使用统一的单个模型联合学习跨不同模态的多任务。模型是建立在基于
编码器-解码器架构上的,由每个模态一个编码器和统一的解码器组成。上图是整个
的架构。
本文考虑图像和文本两种输入模态。对于图像上的基于编码器,首先会应用卷积神经网络来抽取一个视觉
,然后其被
编码器进一步编码为合并了全局上下文信息的
序列。对于语言输入,这里使用12层的uncased版本的
,其将输入的单词序列也编码为
序列。在将输入编码为
序列后,将
解码器应用在单个模态上向量序列上,或者多个模态拼接的向量序列上(这取决于任务是单模态还是多模态)。作者在所有任务上测试了分离解码器和共享解码器。最终,从
解码器获得的表示被传递至任务相关的头,并输出最终的预测值。由于
的简单性,其可以轻易扩展到更多模态和输入上。
作者实验表明,可以在8个数据集上联合学习7个任务。
2.1 图像编码器
单独的视觉任务和”视觉-语言”任务需要感知和理解图像。
中使用卷积神经网络后跟一个
编码器来编码图像
,将其转换为视觉编码
列表:
。图像编码的过程是受
启发。首先,使用将卷积神经网络
应用在输入图像上,抽取出一个尺寸为
的
:
在实现中,卷积网络使用并在目标检测任务上进行预训练。
为了进一步编码出尺寸为的视觉
,在
上应用一个具有
层且
为
的
编码器
,其中
是视觉
的长度。此外,给定不同的任务可能需要抽取不同类型的信息,因此在
编码器中添加一个任务相关嵌入向量
,这允许抽取任务相关的信息
是一个将视觉特征维度
投影至编码器
维度
的线性投影层。视觉
编码器
的构建遵循
,其中位置编码会被添加至
。任务相关的token
是一个维度为
的可学习参数,其被合并至视觉特征序列
的开始。
2.2 文本编码器
像QNLI,MNLI,QQP,SST-2等GLUE基准,以及VQA和visual entailment等视觉语言推理任务都会提供文本输入。这里使用BERT来编码文本输入。
给定输入文本,以与BERT相同的方法将其转换为长度为S的token序列,其中
。这个token序列会被输入至预训练
BERT中来抽取尺寸为的
,其中
是
BERT的hidden size。类似于图像编码器,文本编码器也会token序列前添加一个可学习任务嵌入向量。
然而,在实践中发现仅保留中
[CLS]对应的向量来作为解码器的输入就能达到同样的效果。
在本文的实现中,使用BERT-base-uncased,其且
。
2.3 领域不可知解码器
在将输入模态编码后,应用一个hidden size为且具有
层的
解码器
,该解码器会输出一个
hidden state序列,然后用于每个任务的预测。不同于文本和图像编码器,每个模态都有一个具体的架构,解码器在所有任务上都使用相同的领域不可知
解码器。
对于纯视觉任务,解码器应用在编码后的图像;对于纯语言任务,解码器应用在编码后 的文本
;对于视觉语言联合任务,将两种模态合并至单个输入
。
解码器
将编码后的输入序列
和一个长度为
的任务相关的
query嵌入序列。
解码器第
层会输出一个解码序列
,其长度与
相同为
解码器的架构同DETR中实现的解码器。在解码器的第层,自注意力机制被应用在解码的
,交叉注意力被用于编码输入模态
。
在实现时,要么对所有任务使用单个共享的解码器,或者为每个具体的任务
使用分离解码器
。
2.4 任务相关的输出头
每个任务的预测头被应用在解码
hidden state 。对于目标检测任务,使用分类头来产生分类概率输出,以及一个
box头来为中的每个位置产生
bounding box。分类头和box头的实现如同DETR。对于每个box上具有属性标签的数据集,实现类似BUTD中的属性分类头 。
类别头和box头的输出会被后处理为object bounding box。对解码器所有层的
hidden state 上都会应用这些头
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \textbf{c}^l&=…
其中,是类别、
box和属性的输出序列,所有的长度均为,与
query嵌入相同。
在测试时,仅使用从解码器顶层得到的预测值。因此不同的检测数据集通常有不同数量的类别,每个数据集都有自己的类别头、
box头和属性头。在和
上应用的损失函数同
DETR,在上的属性损失函数同
BUTD。
本文中所有的任务,包括:视觉问答、visual entailment和自然语言理解等,都能被转换为任务
上的
类别分类任务。在解码器顶层的第1个
hidden state 上应用任务相关的分类器,并为任务
输出一个尺寸为
的分类预测值
。
为了预测输出类别,使用具有GeLU激活函数的两层,且输出维度等于解码器
hidden size。使用预测值和真实标签
计算交叉熵损失函数来训练模型
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \textbf{p}&=W_…
2.5 训练
在多个任务上联合训练。在训练中的每次迭代,随机的选择一个任务和数据集来填充
batch。根据数据集的大小和经验来人工指定每个任务的抽样概率。在本文的实现中,模型在64块Nvidia Volta V100-SXM2-32GB的GPU上进行训练,batch size为64。使用具有学习率为5e-5的加权Adam优化器。
三、实验
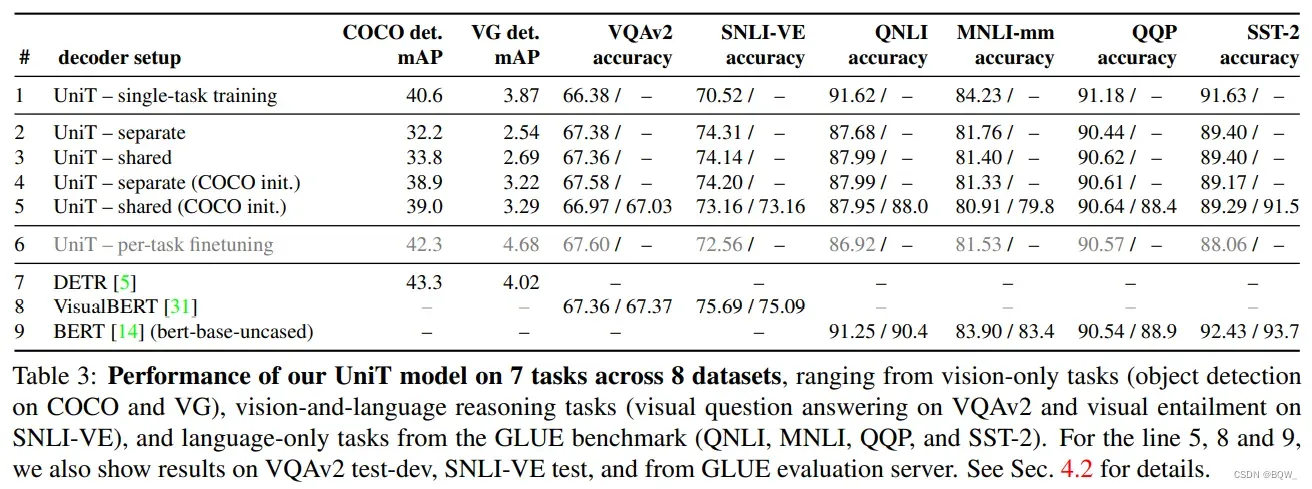
四、总结
- 单纯将两个模态的模型进行联合训练,理论上没有太多可以借鉴的;
- 实验结果以及训练过程具有借鉴意义。
文章出处登录后可见!