基本信息
论文:VirTex: Learning Visual Representations from Textual Annotations
作者:Karan Desai、Justin Johnson;均来自University of Michigan
发布会议:CVPR 2021
面向任务:CV+NLP迁移学习,表示学习
摘要:
本文的目标是从更少的图像中学习高质量的视觉表示。此前很多方法从预训练中学习视觉表示开始,后来逐渐探索无监督预训练以充分利用大量未标记的图像,但是耗费巨大。所以本文重新审视有监督的预训练,并寻求有效的替代基于分类的预训练数据的方法,最终提出 VirTex——一种使用语义密集caption来学习视觉表示的预训练方法。结果表明,在多种下游任务中,尽管图像数量减少10倍,VirTex 产生的特征也足以匹敌或超过在ImageNet上进行分类预训练学习的特征。
Introduction
学习视觉表示的方法
经典范式:先在ImageNet上进行图片分类任务预训练CNN网络,然后将学到的视觉表示应用于下游任务。虽然取得了很大成功,但是预训练阶段需要大量人工标注,耗费太大。
无监督预训练:使用未标记图像学习视觉表示然后转移到下游任务。虽然继续将无监督预训练扩展到越来越大的未标记图像集是很重要的,但是本文作者重新关注监督预训练,寻求一种替代传统分类预训练的方法,以更有效地使用每张图像。
本文方法(VirTex):从文本注释中学习视觉表示的方法。如图 1所示:首先,从头开始联合训练 ConvNet 和 Transformer ,为图像生成自然语言caption。然后,将学习到的特征转移到下游的视觉识别任务中。
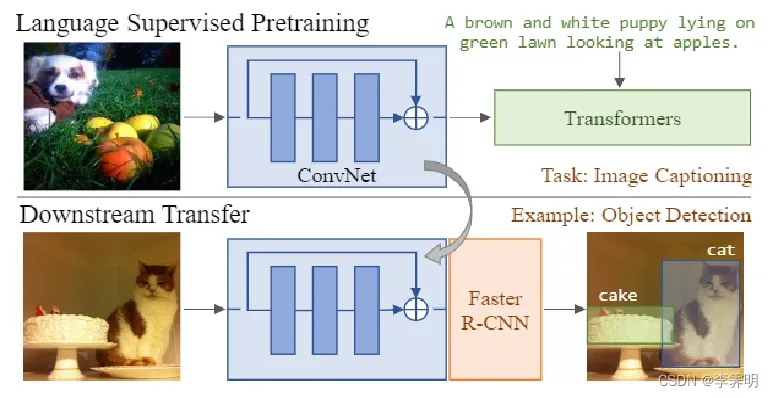
VirTex的优点
1)图 2中 比较了用于学习视觉表示的不同预训练任务。与无监督的对比方法和监督分类相比,caption提供了语义更密集的学习信号。因此,我们的目标是利用caption的这种语义密度以数据有效的方式学习视觉表示。
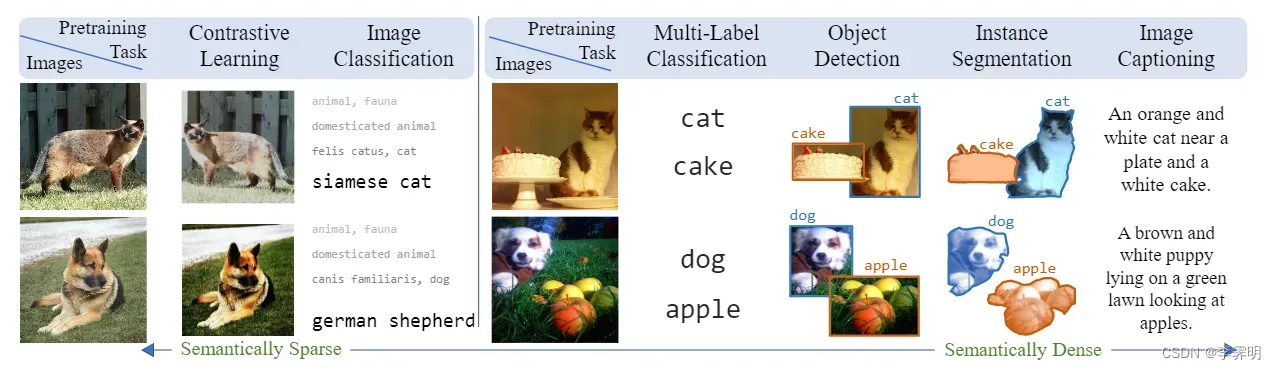
VirTex的主要贡献是表明在学习视觉表示的监督方法中,自然语言可以获得比其它方法更好的数据效率。
Related Work
该篇工作与最近使用替代数据源或预训练任务在 ImageNet 上超越监督预训练的努力有关,但是又有一些差别。
Weakly Supervised Learning方法使用大量带有低质量标签的图像来学习视觉表示;相比之下,VirTex专注于使用更少的带有高质量注释的图像。
Self-Supervised Learning侧重于通过解决定义在未标记图像上的pretext任务(比如聚类、对比学习)来学习视觉表示。这些方法依赖于低级视觉线索(颜色、纹理),缺乏语义理解,而VirTex利用文本注释进行语义理解。
Vision-and-Language Pretraining 尝试学习图像文本配对数据的联合表示,这些数据可以转移到多模式下游任务。相比之下,VirTex通过图像字幕进行预训练,并将视觉任务置于视觉和语言预训练的下游。
类似工作:
[75] Mert Bulent Sariyildiz, Julien Perez, and Diane Larlus, “Learning visual representations with caption annotations,” in ECCV, 2020. 3, 6
[76] Jonathan C Stroud, David A Ross, Chen Sun, Jia Deng, Rahul Sukthankar, and Cordelia Schmid, “Learning video representations from textual web supervision,” in ECCV, 2020. 3
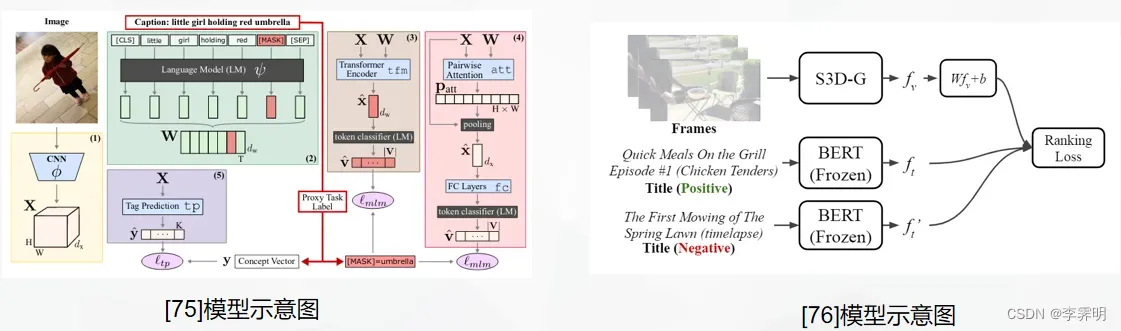
[75]通过图像条件掩码语言建模从caption中学习视觉表示,他们依靠预训练的 BERT 来获取文本特征。 [76]使用成对的文本元数据学习视频表示,但是他们只在视频任务上操作和评估他们的方法。
[75] Mert Bulent Sariyildiz, Julien Perez, and Diane Larlus,“Learning visual representations with caption annotations,” in ECCV, 2020. 3, 6
本文通过图像条件掩码语言模型(ICMLM)从caption中学习视觉表示,如图所示,利用图像信息来重构其相应image caption的掩码字符 ,他们依靠预训练的 BERT 来获取文本特征。
注意在目标任务评估期间仅使用 CNN 。
[76] Jonathan C Stroud, David A Ross, Chen Sun, Jia Deng, Rahul Sukthankar, and Cordelia Schmid, “Learning video representations from textual web supervision,” in ECCV, 2020. 3
本文使用成对的文本元数据学习视频表示,但是他们只在视频任务上操作和评估他们的方法。
VirTex(Desai & Johnson,2020)、ICMLM(Bulent Sariyildiz等人,2020)和Con-VIRT(Zhang等人,2020)采用了更多最新的架构和预训练方法,最近证明了基于transformer的语言建模、屏蔽语言建模和对比学习目标的潜力,可以从文本中学习图像表示。VirTex、ICMLM和ConVIRT在加速器上训练了20万张图像。
《Learning Transferable Visual Models From Natural Language Supervision》创建了一个从互联网上收集4亿对图像-文本对的数据集,并提出了CLIP(Contrastive Language-Image Pre-training),它是一种有效的从自然语言监督中学习视觉表示的方法。并通过在30多个不同现有的计算机视觉数据集中研究了这种方法的性能。
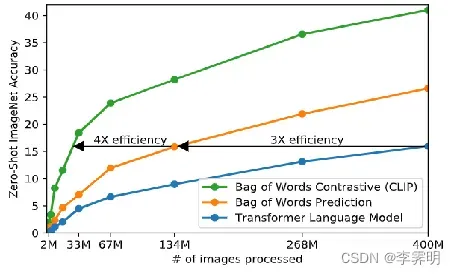
CLIP最初的方法类似于 VirTex,从头开始联合训练图像 CNN 和文本转换器来预测图像的标题。然而在扩展这种方法时遇到了困难(如图所示,我们展示了transformer语言模型,它已经使用了其 ResNet-50 图像编码器两倍的计算量,学习识别 ImageNet 类的速度比预测相同文本的简单的词袋编码基线慢三倍)
后来CLIP采用对比学习联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。
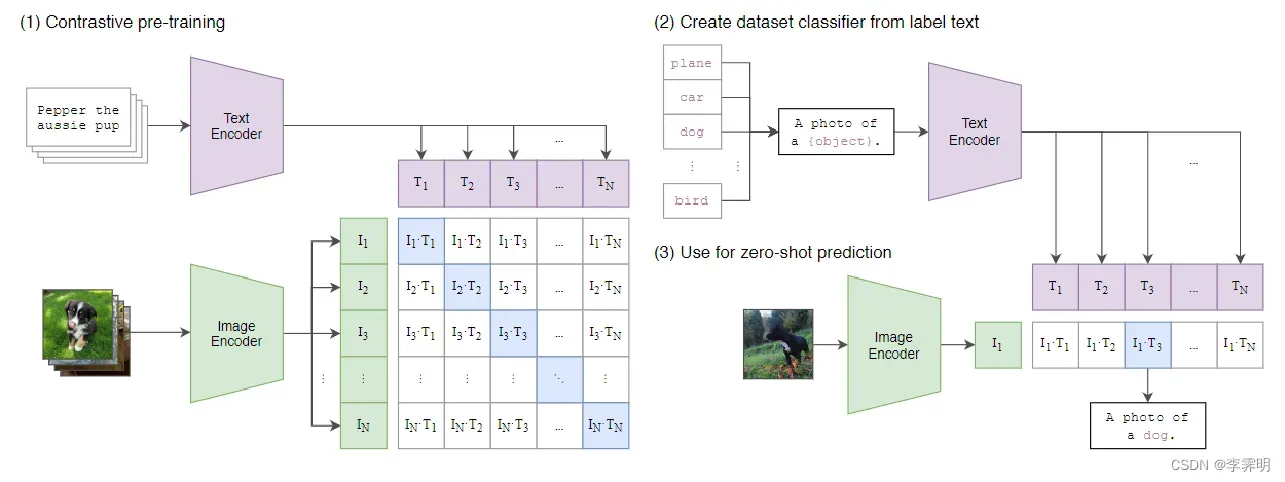
一些图像模型模型联合训练图像特征提取器和线性分类器来预测某些标签,而 CLIP 联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。在测试时,学习文本编码器通过嵌入目标数据集类别的名称或描述来合成零样本线性分类器。
给定一批 N个(图像,文本)对,CLIP 被训练来预测 N×N 对(图像,文本)配对中哪一个是正确匹配的。为此,CLIP 学习了一个多模态嵌入空间通过联合训练图像编码器和文本编码器来最大化批次中 N对正确配对的图像和文本嵌入的余弦相似度,同时最小化 N^2−N不正确配对的嵌入的余弦相似度。最后再优化这些相似性分数的对称交叉熵损失。
Method
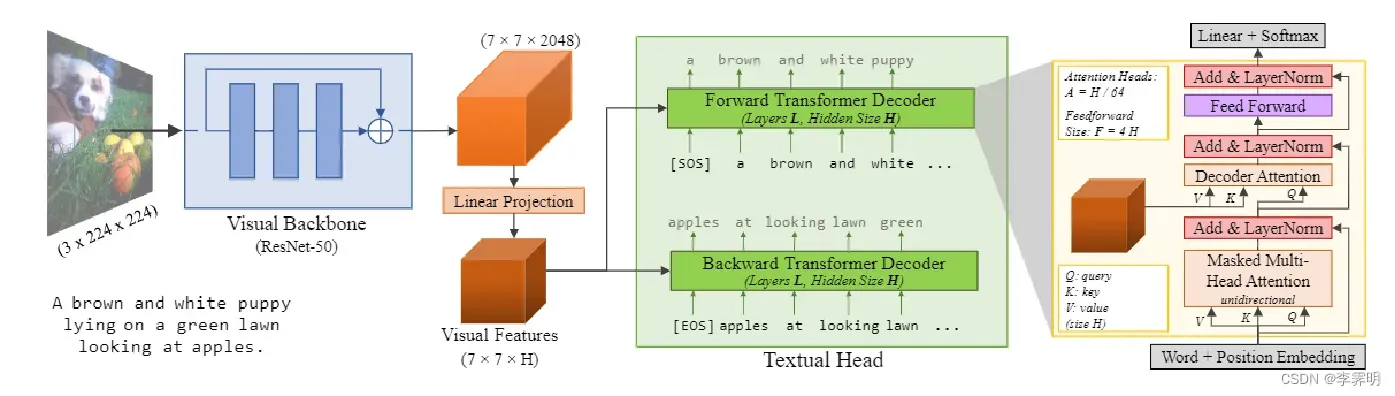
如图 3 所示,VirTex 模型有两个组件:visual backbone和textual head。visual backbone从输入图像中提取视觉特征;textual head接受这些特征并执行双向caption预测对应的caption。
Language Modeling:masked language models(MLMs);
Visual Backbone:ResNet-50;
Textual Head: Transformers。
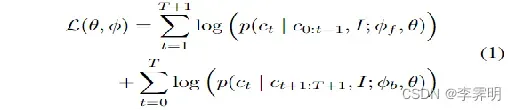
目标函数就是前向和后向caption的加和
在训练期间,textual head接收图像特征和图像caption后,首先通过学习token和位置嵌入将文本token转换成向量C,然后是元素求和、层归一化和 dropout。接下来通过一系列 Transformer层处理这些向量。如图所示,每一层对向量C进行掩码多头自注意力操作,token向量和图像向量之间的multi headed attention,并对每个向量应用两层全连接网络。在最后一个 Transformer layer 之后,我们对每个向量应用一个线性层来预测标记词汇表上的非归一化对数概率。
Experiments
performance
Image Classification with Linear Models
第一组评估实验涉及在冻结的visual backbone上训练线性模型——并将 VirTex 与各种预训练方法进行比较。
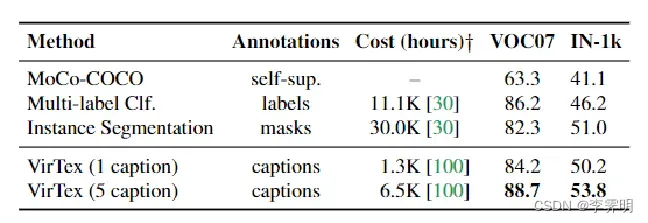
Annotation Cost Efficiency: 如左表所示,注释成本效率:本文在 COCO 上比较了各种预训练方法的下游性能。可以看到 Vir-Tex 优于(指标是mAP和accurary)所有方法,并且具有最好的性能。这表明使用caption学习视觉特征比标签或掩码更具成本效益
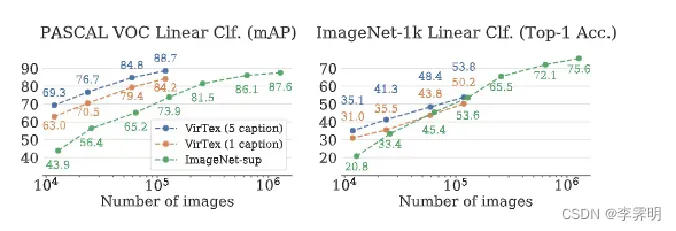
Data Efficiency: 如左图,我们比较了使用不同数量的图像训练的 VirTex 和 IN-sup 模型。尽管使用了 10 倍更少的图像,但 Vir-Tex 与 IN-sup 在下游任务紧密匹配或显著优于 IN-1k(mAP88.7vs87.6)。表明 VirTex 具有卓越的数据效率。
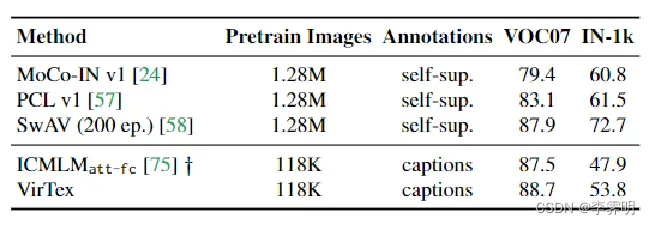
Comparison with other methods:我们将 VirTex 的下游性能与最近的 SSL 方法( MoCo, PCL,和SwAV)和并发工作(ICMLM)进行比较。†:使用预训练的 BERT-base。尽管接受的训练图像要少得多,VirTex 在 VOC07 上的表现还是优于所有方法。
Ablations
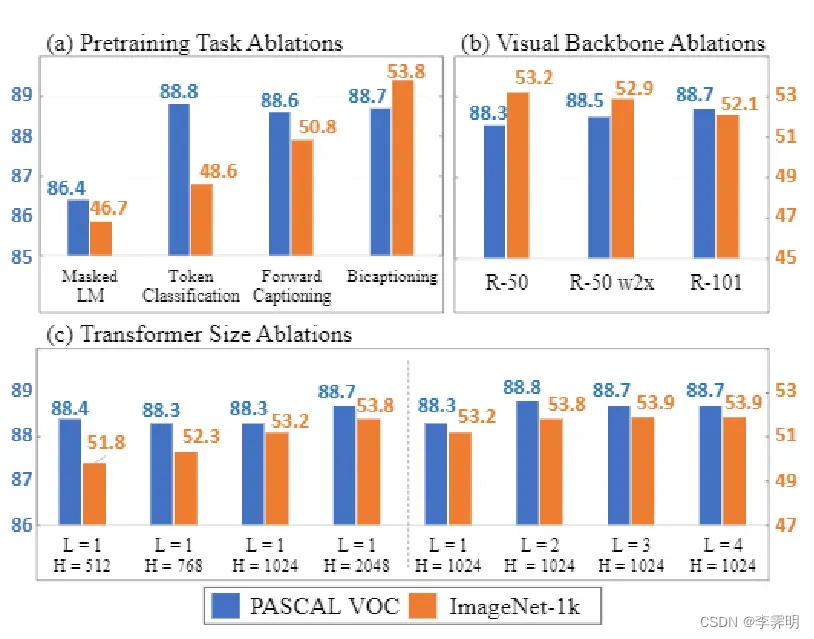
Pretraining Task Ablations:结果如图 5(a) 所示。 Bicaptioning 优于前向captioning,表明更密集的来自双向建模的监督信号是有益的。Bicaptioning和前向captioning都优于标记分类,这表明学习语言的序列结构进行建模可以改善视觉特征。
Visual Backbone Ablations: 图(b) :VOC07上更大的视觉主干提高了下游性能——更宽 (R-50 w2×) 和更深 (R-101)。
Transformer Size Ablations: © transformer尺寸:更大的transformer(更宽更深)提高下游性能。
本文将 VirTex 与四个下游任务的不同预训练方法进行比较。在所有任务上,VirTex 明显优于使用相似数量预训练图像的所有方法。尽管使用了 10 倍的预训练图像,但 VirTex 非常接近或超过了 ImageNet 监督和自监督方法。
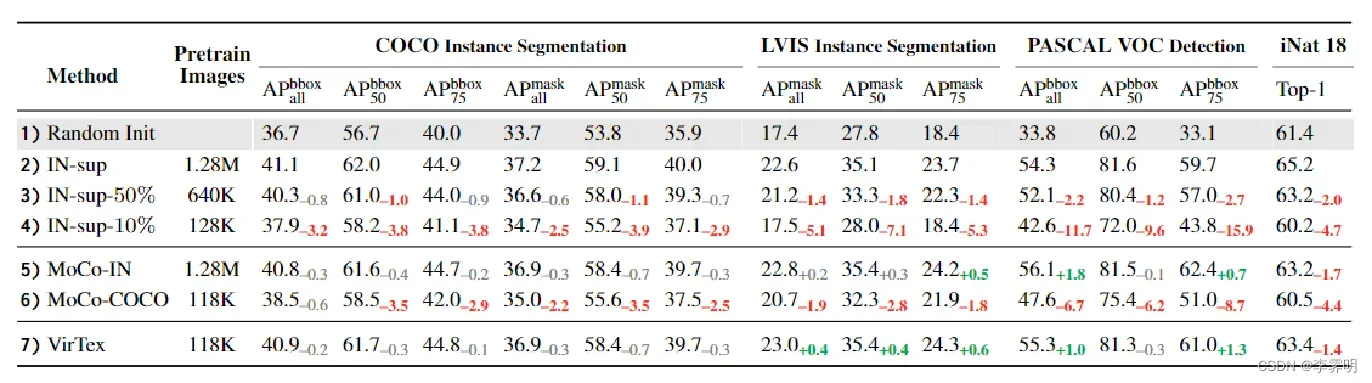
如表 3 所示,尽管使用了 少10 倍的预训练图像,但 VirTex 在所有任务(第 2、5 行和第 7 行)上匹配或超过了 ImageNet 监督预训练和 MoCo-IN。此外,VirTex 显着优于使用相似或更多预训练图像(row3,4,6vs.7)的方法,表明其卓越的数据效率。在所有任务中,VirTex 在 LVIS 上有显着改进,这表明自然语言注释在捕捉现实世界中视觉概念长尾方面的有效性。

如图6所示,我们展示了在 COCO 上从头开始训练的 VirTex 模型的定量和定性结果。所有模型都表现出适度的性能。然而,众所周知,caption指标与人类判断的相关性很弱——我们在 COCO 上超越了人类的表现。
在图 6 中展示了一些tokens的可视化。可以观察到VirTex 模型关注相关图像区域并进行预测,这表明 VirTex 学习了具有良好语义理解的有意义的视觉特征。
Conclusion
本文提出的VirTex是一种一种使用语义密集的caption来学习视觉表示的预训练方法。在COCO Captions 数据集上从头开始训练卷积网络,并将其迁移到图像分类、目标检测和实例分割等下游任务上。
实验证明自然语言可以为学习可迁移的视觉表示提供监督,使用文本注释学习视觉表示可以与基于监督分类和自监督学习的方法在 ImageNet 上竞争,其数据利用效率高于其他方法。
文章出处登录后可见!