前言
YOLO系列目标检测算法是卷积神经网络中的一阶段检测算法,是基于深度学习的端到端的回归方法。
YOLO官网:https://github.com/pjreddie/darknet
检测模型
YOLOv1
论文地址:https://arxiv.org/abs/1506.02640
官方代码:https://github.com/pjreddie/darknet
发表时间: 2016年5月9日
引用格式:Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
YOLOv1的网络结构
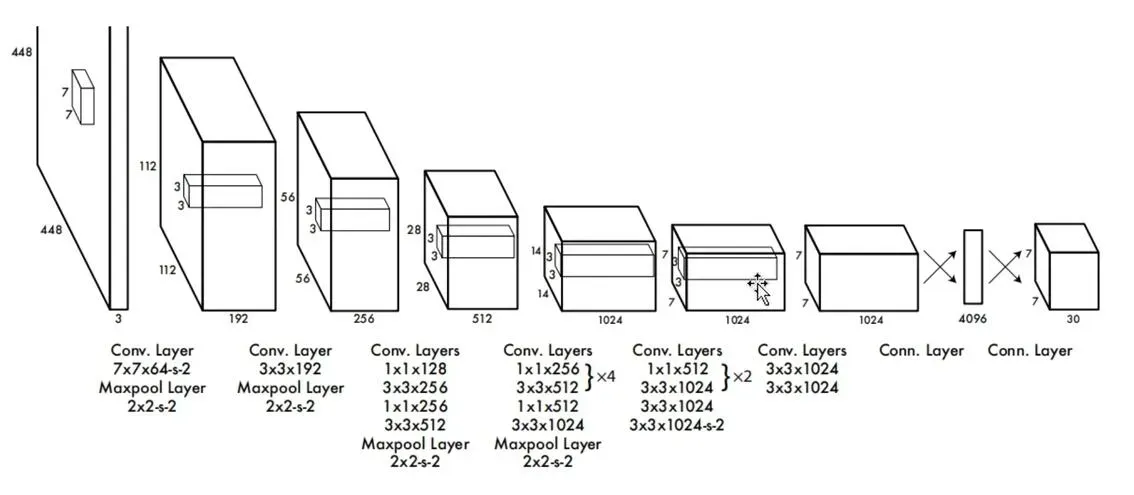
YOLOv1的backbone使用的是GoogleLeNet,速度比VGG-16快,YOLOv1完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69billion,但是YOLOv1精度稍低于VGG-16。
由于输出层为全连接层,因此在检测时,YOLOv1模型的输入只支持与训练图像相同的输入分辨率。
YOLOv1的核心思想
把物体检测(object detection)问题处理成回归问题。就是利用整张图作为一个卷积神经网络结构的输入,直接在输出层回归边界框(bounding box)的位置和bounding box所属的类别。
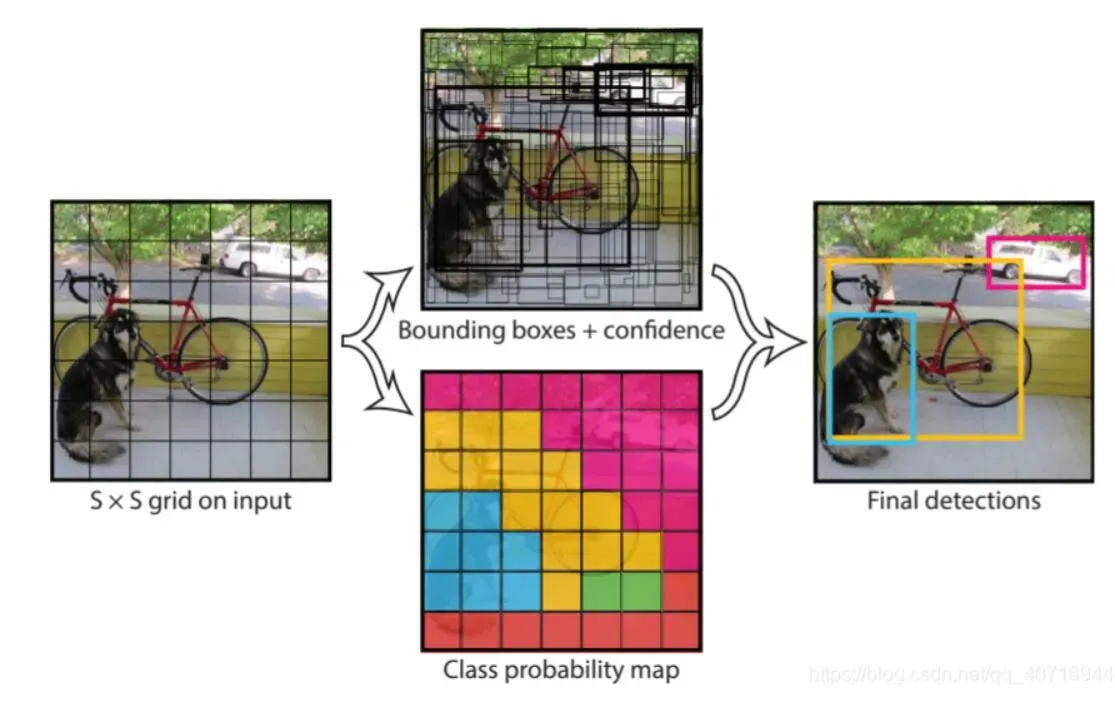
注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
注意:
- 虽然每个格子可以预测B个bounding box,但是最终只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。所以对小目标检测不是很友好。
YOLO算法的缺点
- YOLO对相互靠的很近的物体和很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类;
- YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。
- 同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱;
- 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
思考
- YOLOv1方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLOv1的检测效果并不理想。
- YOLOv1采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
- YOLOv1的loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
整体过程
- 输入图像,将图像划分为7*7(S=7)的网格
- 对每个网格,预测两个边框(B=2)(包括网格内是否具备对象,四个位置坐标,在每个分类类别C中的置信度),输出就是S x S x ((1+4)*B+C)的一个tensor。
- 得到7x7x2个目标窗口,根据阈值去除可能性比较低的目标窗口,通过非极大值抑制(NMS)去除冗余窗口。
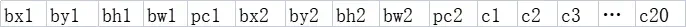
上图是在7*7个目标窗口中取出的y,由于每个网格预测两个边框,所以这里前五个是一个边框,后五个是一个边框,再往后的C1到C20是由数据集决定的检测类别数量。其取值就是置信度,如果c1的数值相较其他19个都高,那这个网格预测出目标的类别就是C1。这里pc1或者pc2如果都为0,则这里面其他数值是多少都不重要了,因为这代表着网格中没有目标。
损失函数
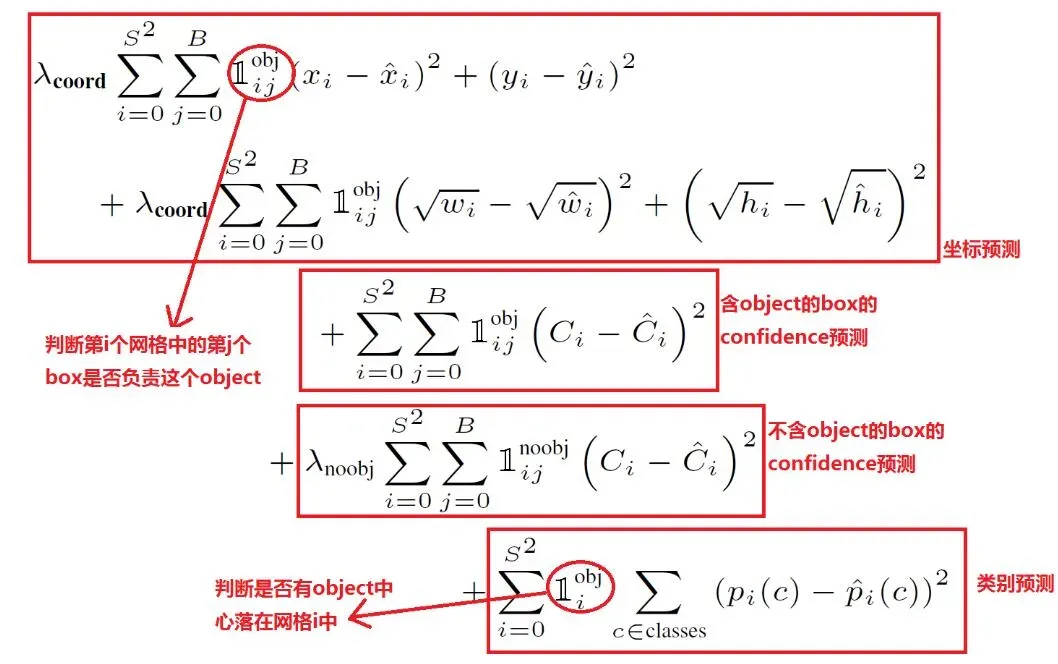
注意:圈起来的那个是指示函数(indicator function)
它的含义是:当输入为True的时候,输出为1,输入为False的时候,输出为0。
有目标的时候,obj是1,其他为0,不参与计算。
无目标的时候,noobj是1,其他为0,不参与计算。
公式解释:
- 第一个方框:目标边框包含目标情况下的损失计算方法。
是为了解决正负样本不均衡的问题。
- xywh的预测损失计算均采用平均绝对值误差(Mean Absolute Error,MAE)
- 计算损失选择IoU值较高的参与运算
- 第二个方框:表示目标边框内有目标时候,前景概率损失的计算方法。
- 上文提到,当有目标时,实际的前景概率为1。所以
- 一个网格会预测两个框,包含目标的情况下,计算损失的时候只会选择其中一个和真实边框IoU较高的做计算。同样,拿IoU较高的前景概率做损失计算。
- 上文提到,当有目标时,实际的前景概率为1。所以
- 第三个方框:表示目标边框内没有目标时候,前景概率损失的计算方法。
- 上文提到,当没有目标时,实际的前景概率为0。所以
- 不包含目标的情况下,两个前景概率都参与运算。
- 第四个方框: 表示目标边框内有目标时候,类别预测损失的计算方法。
部分代码解读
encoder
我们知道神经网络的目的就是拟合一个超复杂函数,让机器自己计算出相应的参数,并且使这个函数能尽量地逼近我们需要预测的事件上去,只要两者的误差尽可能的小,就证明这个模型是好的,也就是 这里令
为真实值,则
为预测值。这个部分就是通过已知数据设置相应的
真实值。
已知预测值的形状为(S,S,(B*(4+1)+C)),则
真实值也要处理成相应形状,并且对应填好下图表示的每个数值。(下图为1130,对应会有7730个,这是其中的1/49)。
![]()
def encoder(self,boxes,labels):
'''
boxes (tensor) [[x1,y1,x2,y2],[]]
labels (tensor) [...]
return 7x7x30
'''
grid_num = 7 # 设置的S,即一张图片上网格的数量
target = torch.zeros((grid_num,grid_num,30)) # 设置空的目标
cell_size = 1./grid_num # 每个网格的大小
wh = boxes[:,2:]-boxes[:,:2] #(x2,y2)-(x1,y1) = (w,h)
cxcy = (boxes[:,2:]+boxes[:,:2])/2 # ((x2,y2)+(x1,y1))/2 得到中心坐标
for i in range(cxcy.size()[0]): # 对应图片中的物体数
cxcy_sample = cxcy[i] # 选取物体[i]的中心坐标(归一化之后的)
ij = (cxcy_sample/cell_size).ceil()-1 # 对应到相应的格子里
target[int(ij[1]),int(ij[0]),4] = 1 # 在上图pc1处填写数字1,表示具有物体存在
target[int(ij[1]),int(ij[0]),9] = 1# 在上图pc2处填写数字1,表示具有物体存在
target[int(ij[1]),int(ij[0]),int(labels[i])+9] = 1 # labels是物体类别,此处是从1-20,也就是在9+从1到20,对应c1-c20的位置
xy = ij*cell_size #匹配到的网格的左上角相对坐标
delta_xy = (cxcy_sample -xy)/cell_size # 相对每个网格内的坐标值
# 填写bx,by,bh,bw
target[int(ij[1]),int(ij[0]),2:4] = wh[i]
target[int(ij[1]),int(ij[0]),:2] = delta_xy
target[int(ij[1]),int(ij[0]),7:9] = wh[i]
target[int(ij[1]),int(ij[0]),5:7] = delta_xy
return target # 返回塑造好的真实值
画个图理解一下:

本文为自用总结,部分内容出自以下文章,强烈推荐阅读:
YOLO系列详解:YOLOv1、YOLOv2、YOLOv3、YOLOv4、YOLOv5
深度学习目标检测系列:一文弄懂YOLO算法|附Python源码
yolov1,yolov2,yolov3 训练,解读,复现
目标检测|YOLOv2原理与实现(附YOLOv3)
文章出处登录后可见!