在目标检测领域中,对于边界框的回归问题上,都会遇到一个专业名词—–非极大值抑制(NMS)。对于网络的输出,我们会通过设置confidence(置信度)阈值来过滤一部分目标,但此时一个物体上还会存在多个预测框,此刻就需要对这些预测框进一步处理,采用的方法就是非极大值抑制,而常常采用的手段是IOU(交并比)。通过设置IOU阈值来获得我们最终的预测框。
目录
我们拿yolo来说,如果网络输入是416*416大小,那么会产生52*52、26*26、13*13三个不同的特征层来预测不同尺度的目标,同时每个特征层又会产生3种不同尺度的锚框(先验框),那么我们就可以获得52*52*3+26*26*3+13*13*3=10647个锚框。
如果你对网络进行输出,会发现在锚框的tensor后又跟着一个维度,比如这样的(1,10647,x),其中1指的是batch_size的维度,10647指的锚框数量,后面的x是包含了bbox(x,y,w,h)4个信息,confidence和预测类别信息,如果你是coco类,那么后面这个维度就是85。你可以理解为每一个锚框预测都会产生这几个值。
下面我将用代码来举个例子,并且为了方便起见,我这里只有1个类。
假设通过网络输出我有这样一个tensor,大小是[1,3,6],3是有3个锚框。在6这个维度上,表示[center_x,center_y,width,height,conf,classes]
pred = torch.tensor([[
[1.2312e+01, 1.5709e+01, 3.8783e+01, 6.6860e+01, 1.2674e-01, 1.0000e+00],
[5.4555e+01, 1.7518e+01, 4.0713e+01, 3.3931e+01, 2.2637e-01, 1.0000e+00],
[7.8304e+01, 1.6306e+01, 4.9968e+01, 3.6646e+01, 2.3244e-01, 1.0000e+00]
]])坐标系可以这样建立:
'''
w
——————————————————> x
| |
| |
| * | h
| (x,y) |
| |
|-----------------
y
'''然后我们将这几个预测框画出来,代码如下。其中pred.squeeze(0)是将第0个维度去掉,即去除batch_size这个维度,获得[3,6]的shape.由于在matplotlib中,坐标系默认是左下角为原点,y轴向上,x向右,但我们图像中的坐标系是左上角为坐标原点,x轴向右,y轴向下,因此可以用plt.gca().invert_yaxis()进行转换,同时,我们获得预测框信息中前两列为中心点坐标,我们需要对其重新计算,获得左上角坐标。
pred = pred.squeeze(0)
pred = pred.cpu().detach().numpy()
fig = plt.figure()
ax = fig.add_subplot(111)
plt.plot(pred[:, 0], pred[:, 1], 'o')
# plt.Rectangle(xy,w,h) 默认为xy为矩形左下角坐标 左下角x=center_x - w/2;y=center_y + h/2
# 换成左上角为原点,那么默认从左上角画矩形,x=center_x - w/2;y=center_y - h/2
rect1 = plt.Rectangle((pred[0, 0] - pred[0, 2]/2, (pred[0, 1] - pred[0, 3]/2)), pred[0, 2], pred[0, 3], fill=False)
rect2 = plt.Rectangle((pred[1, 0] - pred[1, 2]/2, pred[1, 1] - pred[1, 3]/2), pred[1, 2], pred[1, 3], fill=False)
rect3 = plt.Rectangle((pred[2, 0] - pred[2, 2]/2, pred[2, 1] - pred[2, 3]/2), pred[2, 2], pred[2, 3], fill=False)
ax.add_patch(rect1)
ax.add_patch(rect2)
ax.add_patch(rect3)
plt.xlim(-10, 150)
plt.ylim(-20, 110)
plt.gca().invert_yaxis() # 将坐标原点设置为左上角
plt.show()我们将获得如下的图,三个预测框,蓝色的点是中心点坐标。
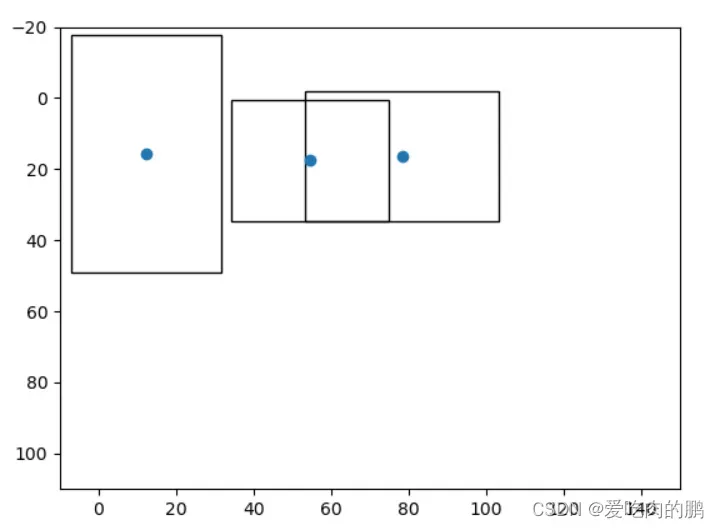
然后我们可以进一步的输出,其中 class_conf, class_pred = pred[:, 5:].max(1) 从第5个维度开始,选择每一行最大class_conf的index,
for image_i, pred in enumerate(prediction):
class_conf, class_pred = pred[:, 5:].max(1)输出如下:
class_conf = tensor([1., 1., 1.]) class_pred = tensor([0, 0, 0])这表明第5个维度输出的类别最大概率值,对应的索引都为0这个类,比如在voc数据集中第0这个类指person类。
接下来是获得置信度confidence或者有些代码里也写sorce,该值是类别的概率值和分类的值相乘
pred[:, 4] *= class_conf # conf = obj_conf * class_conf我们打印一下此刻新的pred
tensor([[12.3120, 15.7090, 38.7830, 66.8600, 0.1267, 1.0000],
[54.5550, 17.5180, 40.7130, 33.9310, 0.2264, 1.0000],
[78.3040, 16.3060, 49.9680, 36.6460, 0.2324, 1.0000]])
通过置信度阈值滤除进行筛选
设置一个置信度阈值,比如是0.2,然后设置一个min_wh=2,表示w和h最小值阈值,在我们预测边界框中进一步筛选(返回的是布尔值)
i = (pred[:, 4] > 0.2) & (pred[:, 2] > min_wh) & (pred[:, 3] > min_wh) # 返回三个bool值 是看行的内容,不是看列的内容,把满足条件的两个锚框筛选出来那么通过上述的我们知道,将会把pred中第一行输出为False,因为该行中第置信度那个维度是0.1267,低于我们的阈值(也就是我们滤除的一个边界框),即输出为:
tensor([[54.5550, 17.5180, 40.7130, 33.9310, 0.2264, 1.0000],
[78.3040, 16.3060, 49.9680, 36.6460, 0.2324, 1.0000]])
然后我们对class_conf通过i返回的bool值进行筛选,(筛选之前的输出为:tensor([1., 1.,1.]))
筛选之后就变为了:tensor([1., 1.]) 把原来中间那个去掉了。
同理,对class_pred也进行筛选
class_pred = class_pred[i].unsqueeze(1).float()接下来是对边界框信息进行处理,我们刚开始得到的信息是center_x,center_y,w,h,现在我们要得到x1,y1,x2,y2,即边界框的左上角和右下角
def xywh2xyxy(x):
# Convert bounding box format from [x, y, w, h] to [x1, y1, x2, y2]
y = torch.zeros_like(x) if isinstance(x, torch.Tensor) else np.zeros_like(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y然后我们将刚刚通过置信度筛选的各个信息进行拼接,pred2[:,:5]是前4个维度(box信息),class_conf.unsqueeze(1)是筛选后class_conf再通过unsqueeze在1这个维度上再加一个维度(为了方便拼接),cat中的维度1其实就是进行列的拼接
pred2 = torch.cat((pred2[:, :5], class_conf.unsqueeze(1), class_pred), 1)得到的结果如下,我们可以看到现在多了一个维度,最后一个就是预测得到类的索引:
tensor([[ 34.1985, 0.5525, 74.9115, 34.4835, 0.2264, 1.0000, 0.0000],
[ 53.3200, -2.0170, 103.2880, 34.6290, 0.2324, 1.0000, 0.0000]])
然后我们再进行一次可视化
fig = plt.figure()
ax = fig.add_subplot(111)
rect1 = plt.Rectangle((pred2[0,0].cpu().detach().numpy(), pred2[0,1].cpu().detach().numpy()),
pred2[0, 2].cpu().detach().numpy()-pred2[0, 0].cpu().detach().numpy(),
pred2[0, 3].cpu().detach().numpy() - pred2[0,1].cpu().detach().numpy(),
fill=False)
rect2 = plt.Rectangle((pred2[1, 0].cpu().detach().numpy(), pred2[1, 1].cpu().detach().numpy()),
pred2[1, 2].cpu().detach().numpy() - pred2[1, 0].cpu().detach().numpy(),
pred2[1, 3].cpu().detach().numpy() - pred2[1, 1].cpu().detach().numpy(),
fill=False)
ax.add_patch(rect1)
ax.add_patch(rect2)
plt.xlim(-10, 150)
plt.ylim(-20, 110)
plt.gca().invert_yaxis() # 将坐标原点设置为左上角
plt.show()可以于之前那三个预测框进行对比,可以很清楚的看到,我们已经对其中的一个边界框进行了滤除,现在只剩下两个预测框。
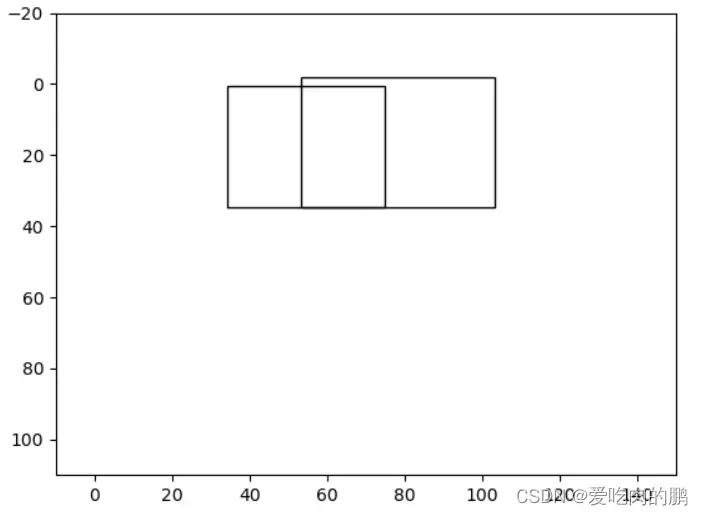
通过IOU进一步筛选预测框
然后剩余的预测框按置信度从大到小进行排列
pred2 = pred2[(-pred2[:, 4]).argsort()]tensor([[ 53.3200, -2.0170, 103.2880, 34.6290, 0.2324, 1.0000, 0.0000],
[ 34.1985, 0.5525, 74.9115, 34.4835, 0.2264, 1.0000, 0.0000]])
for c in pred2[:, -1].unique():
dc = pred2[pred2[:, -1] == c] # 再最后一列找和c一致的类
dc = dc[:min(len(dc), 100)] # limit to first 100 boxes 选出不超过100个框
while len(dc) > 1:
det_max.append(dc[:1]) # save highest conf detection
iou = bbox_iou(dc[0], dc[1:]) # iou with other boxes
dc = dc[1:][iou < 0.2] # remove ious > threshold先附上IOU的完整代码如下:
def bbox_iou(box1, box2, x1y1x2y2=True):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
# box1是通过置信度阈值得到最大的预测框
box2 = box2.t()
# Get the coordinates of bounding boxes
if x1y1x2y2:
# x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else:
# x, y, w, h = box1
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
# 左上角用max 右下角min; w = 右下角x-左上角x,h=右下角y - 左上角y
inter_area = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
union_area = ((b1_x2 - b1_x1) * (b1_y2 - b1_y1) + 1e-16) + \
(b2_x2 - b2_x1) * (b2_y2 - b2_y1) - inter_area
return inter_area / union_area # iou然后我们把上述代码再详细理解一下。
获得最大置信度bbox的坐标和其他bbox的坐标(代码中的box2.t()是进行转置,主要就是为了方便获得坐标,box2.t()得到的为:)
tensor([[34.1985],
[ 0.5525],
[74.9115],
[34.4835],
[ 0.2264],
[ 1.0000],
[ 0.0000]])
# x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]算出最大置信度框和其他框相交的部分面积,如图像中红色区域面积
# Intersection area
# 左上角用max 右下角min; w = 右下角x-左上角x,h=右下角y - 左上角y
inter_area = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)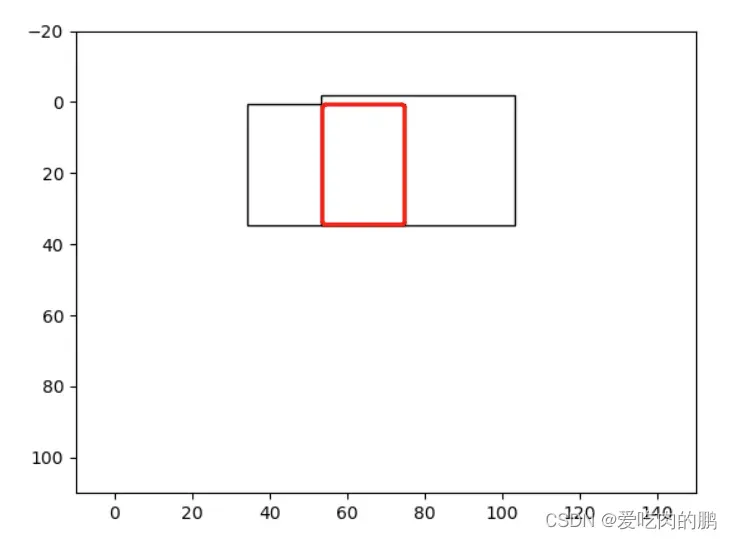
可以得到相交的面积为:
tensor([732.6212])
然后算并集面积的值,算并集的面积就是两个框的面积之和再减去相交的面积
因此公式为:
(box1_x2-box1_x1)*(box1_y2-box_y1)+(box2_x2′-box2_x1′)*(box2_y2′-box2_y1′)-inter_area
代码中的1e-16是为了防止再求IOU时分母出现0.
union_area = ((b1_x2 - b1_x1) * (b1_y2 - b1_y1) + 1e-16) + \
(b2_x2 - b2_x1) * (b2_y2 - b2_y1) - inter_area因此我们可以得到并集的面积为:
tensor([2479.9390])
燃尽计算IOU,IOU就是交并比,意思就是两个框的交集面积与并集面积之比。
inter_area / union_area我们可以计算得到我们两个预测框的iou值为:
tensor([0.2954])
然后我们将小于我们人为设置的IOU阈值的预测框保留,大于的则滤除(通常IOU设置为0.5,但因为我这里为了演示,所以取0.2)【为什么说去除大于阈值的,因为两个预测框如果IOU越大,说明重叠越严重,我们希望的只保留一个】,下图就是我们最终保留下来的预测框
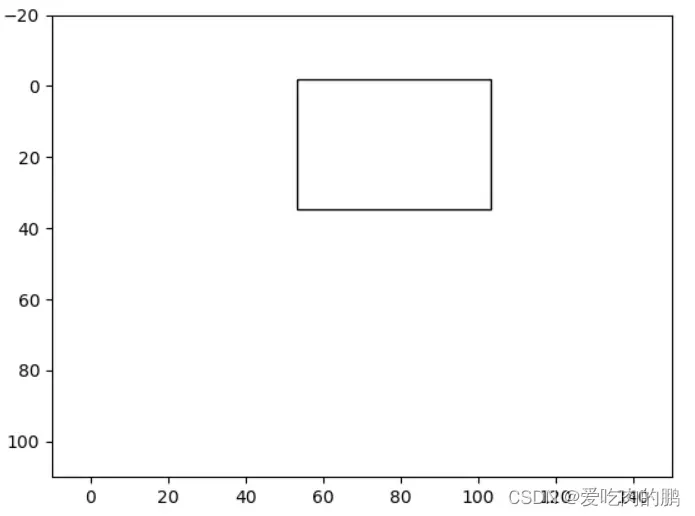
完整的NMS代码:
def non_max_suppression(prediction, conf_thres=0.5, nms_thres=0.4):
# prediction shape (1,10647,6) 10647是锚框数,每个锚框有6个值,(x,y,w,h,conf,class)
"""
Removes detections with lower object confidence score than 'conf_thres'
Non-Maximum Suppression to further filter detections.
Returns detections with shape:
(x1, y1, x2, y2, object_conf, class_conf, class)
"""
min_wh = 2 # (pixels) minimum box width and height
output = [None] * len(prediction)
for image_i, pred in enumerate(prediction):
# Experiment: Prior class size rejection
# x, y, w, h = pred[:, 0], pred[:, 1], pred[:, 2], pred[:, 3]
# a = w * h # area
# ar = w / (h + 1e-16) # aspect ratio
# Filter out confidence scores below threshold
class_conf, class_pred = pred[:, 5:].max(1) # max class_conf, index
pred[:, 4] *= class_conf # finall conf = obj_conf * class_conf
i = (pred[:, 4] > conf_thres) & (pred[:, 2] > min_wh) & (pred[:, 3] > min_wh)
# s2=time.time()
pred2 = pred[i]
# print("++++++pred2 = pred[i]",time.time()-s2, pred2)
# If none are remaining => process next image
if len(pred2) == 0:
continue
# Select predicted classes
class_conf = class_conf[i]
class_pred = class_pred[i].unsqueeze(1).float()
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
pred2[:, :4] = xywh2xyxy(pred2[:, :4])
# pred[:, 4] *= class_conf # improves mAP from 0.549 to 0.551
# Detections ordered as (x1y1x2y2, obj_conf, class_conf, class_pred)
pred2 = torch.cat((pred2[:, :5], class_conf.unsqueeze(1), class_pred), 1)
# Get detections sorted by decreasing confidence scores
pred2 = pred2[(-pred2[:, 4]).argsort()]
det_max = []
for c in pred2[:, -1].unique():
dc = pred2[pred2[:, -1] == c] # select class c
dc = dc[:min(len(dc), 100)] # limit to first 100 boxes
# Non-maximum suppression
while len(dc) > 1:
det_max.append(dc[:1]) # save highest conf detection
iou = bbox_iou(dc[0], dc[1:]) # iou with other boxes
dc = dc[1:][iou < nms_thres] # remove ious > threshold
if len(det_max): # 保留下来的置信度最高的那个预测框
det_max = torch.cat(det_max) # concatenate
output[image_i] = det_max[(-det_max[:, 4]).argsort()] # sort
return output
文章出处登录后可见!