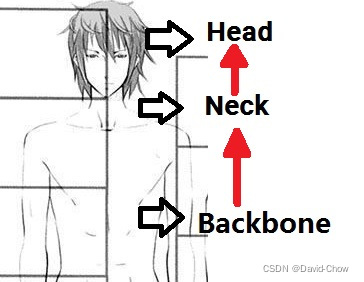
Backbone—— Neck —— Head
1.Backbone:翻译为骨干网络的意思,既然说是主干网络,就代表其是网络的一部分,那么是哪部分呢?这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,共后面的网络使用。这些网络经常使用的是resnet VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。
2.Neck:是放在backbone和head之间的,是为了更好的利用backbone提取的特征。
4.Bottleneck:瓶颈的意思,通常指的是网网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。
2.Head:head是获取网络输出内容的网络,利用之前提取的特征,head利用这些特征,做出预测。
Backbone结构分类
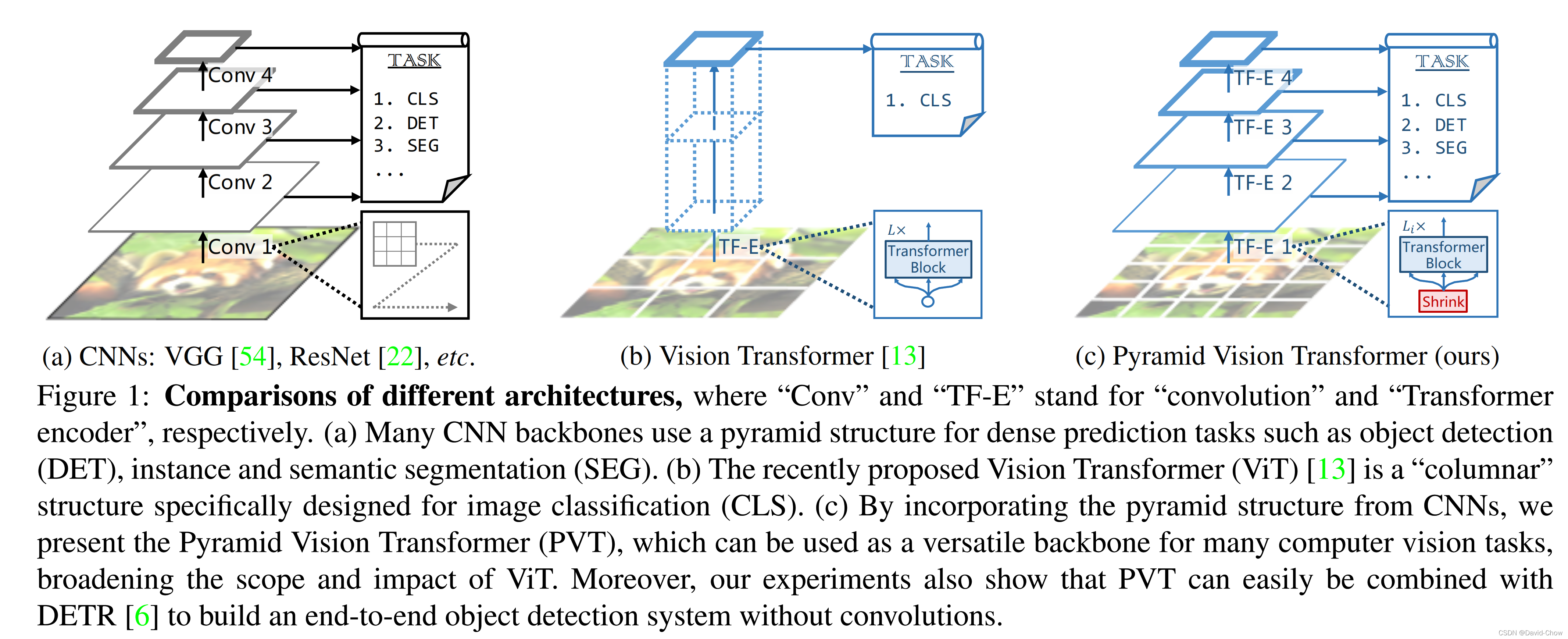
主要分成三类:CNNs结构, Transformer结构(如ViT及衍生算法,比如PVT),CNNs+Transformer结构。
前两者比较如下图所示:
零、 Image Classification on ImageNet 排行榜
见网址ImageNet Benchmark (Image Classification) | Papers With Code
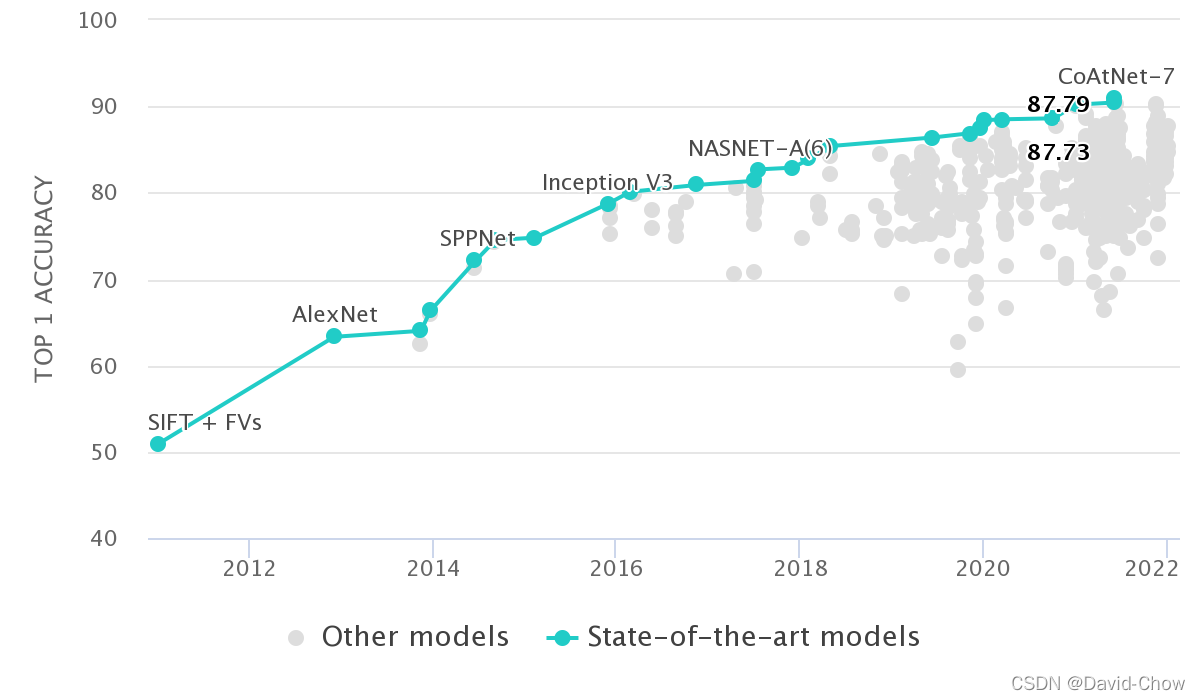
可以从该排行榜中挖掘主流的Backbone及其应用效果。
一、普通(非轻量化)CNNs结构Backbone
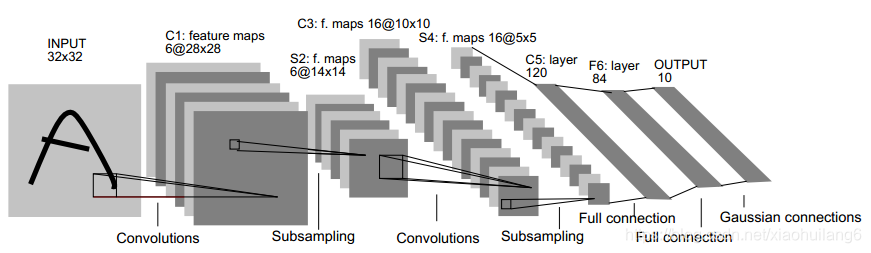
1. LeNet5:(1998)
https://ieeexplore.ieee.org/document/726791
1998年,Yann LeCun等提出的LeNet5,用于手写数字识别的卷积神经网络。LeNet5一共有5层:2个卷积层(conv1,conv2)+3个全连接层(fc3,fc4,fc5),基本架构为:conv1->pool1->conv2->pool2->fc3->fc4->fc5->softmax,总共有60k参数。
| Name | Output | Kernel-Size | Padding | Stride | Channel |
| Input | 32*32 | / | / | / | 1 |
| Conv | 28*28 | 5*5 | 0 | 1*1 | 6 |
| Pool-ave | 14*14 | 2*2 | 0 | 2*2 | 6 |
| Conv | 10*10 | 5*5 | 0 | 1*1 | 16 |
| Pool-ave | 5*5 | 2*2 | 0 | 2*2 | 16 |
| Conv | 1*1 | 5*5 | 0 | 1*1 | 120 |
| FC | / | / | / | / | 84 |
| Output | / | / | / | / | N |
2. AlexNet:(2012)
https://dl.acm.org/doi/10.1145/3065386
2012年,Alex Krizhevsky等提出AlexNet。AlexNet是LSVRC-2012的冠军网络,在ImageNet LSVRC-2012的比赛中,取得了top-5错误率为15.3%的成绩。AlexNet一共有8层:5个卷积层(conv1,conv2,conv3,conv4,conv5)+3个全连接层(fc6,fc7,fc8),基本架构为:conv1->pool1->conv2->pool2->conv3–>conv4->conv5->pool5->fc6->fc7->fc8->softmax,总共有60M参数。
AlexNet 的突破点主要有:
- 网络更大更深,LeNet5(具体可以参考动图详细讲解 LeNet-5 网络结构) 有 2 层卷积 + 3 层全连接层,有大概6万个参数,而AlexNet 有 5 层卷积 + 3 层全连接,有6000万个参数和65000个神经元。
- 使用 ReLU 作为激活函数, LeNet5 用的是 Sigmoid,虽然 ReLU 并不是 Alex 提出来的,但是正是这次机会让 ReLU C位出道,一炮而红。关于激活函数请参考我的另一篇博客 深度神经网络中常用的激活函数的优缺点分析。AlexNet 可以采用更深的网络和使用 ReLU 是息息相关的。
- 使用 数据增强 和 dropout 来解决过拟合问题。在数据增强部分使用了现在已经家喻户晓的技术,比如 crop,PCA,加高斯噪声等。而 dropout 也被证明是非常有效的防止过拟合的手段。
- 用最大池化取代平均池化,避免平均池化的模糊化效果, 并且在池化的时候让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
| Name | Output | Kernel-Size | Padding | Stride | Channel |
| Input | 224*224 | / | / | / | 3 |
| Conv | 55*55 | 11*11 | 0 | 4*4 | 96 |
| LRN | 55*55 | 5 | / | / | 96 |
| Pool-max | 27*27 | 3*3 | 0 | 2*2 | 96 |
| Conv | 27*27 | 5*5 | 2*2(SAME) | 1*1 | 256 |
| LRN | 27*27 | 5 | / | / | 256 |
| Pool-max | 13*13 | 3*3 | 0 | 2*2 | 256 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 384 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 384 |
| Conv | 13*13 | 3*3 | 1*1(SAME) | 1*1 | 256 |
| Pool-max | 6*6 | 3*3 | 0 | 2*2 | 256 |
| FC+Dropout | / | / | / | / | 4096 |
| FC+Dropout | / | / | / | / | 4096 |
| Output | / | / | / | / | N |

3. VGG:(2014)
https://arxiv.org/abs/1409.1556v1
牛津大学视觉组/Google DeepMind提出来的。现在来看这个网络结构还是非常简单明了的:
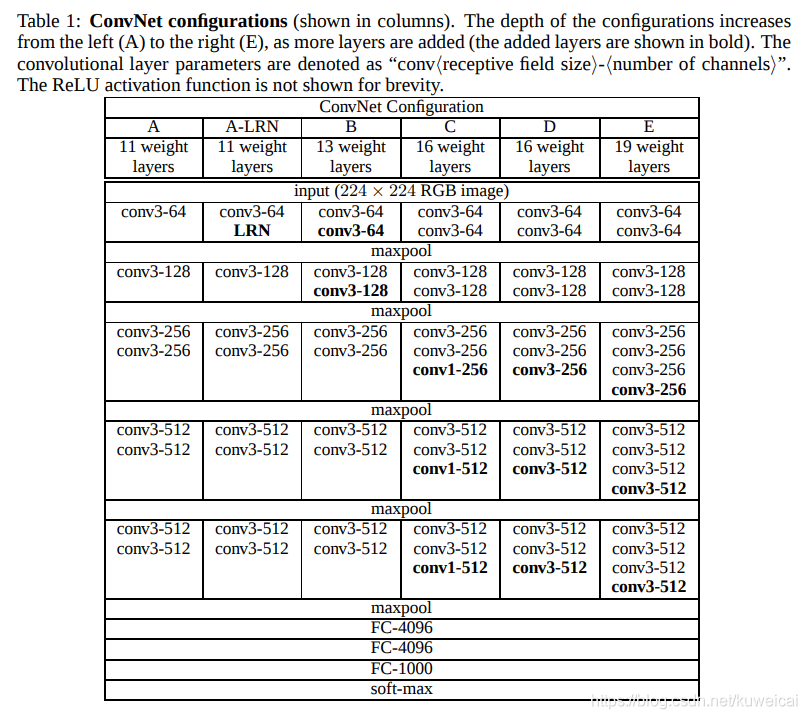
在但是 VGGNet 主要的突破在于:
-
选用比较小的卷积核(3×3),而之前无论 AlexNet 还是 LeNet5 都是采用较大的卷积核,比如 11×11, 7×7。而采用小卷积核的意义主要有两点,一是在取得相同的感受野的情况下,比如两个3×3的感受野和一个5×5的感受野的大小相同,但是计算量却小了很多,关于这点原文中有很详细的解释,建议直接看原文;第二点是两层3×3相比一层5×5可以引入更多的非线性,从而使模型的拟合能力更强,这点作者也通过实验进行了证明。其实这里还有一个优点就是采用小的卷积核更方便优化卷积计算,比如Winograd算法对小核的卷积操作有比较好的优化效果。
-
引入1*1的卷积核,在不影响输入输出维度的情况下,引入非线性变换,增加网络的表达能力,降低计算量。
-
训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度。
-
采用了Multi-Scale的方法来训练和预测。可以增加训练的数据量,防止模型过拟合,提升预测准确率。
-
在预测时:采用Multi-Scale策略,图像放缩至S,在最后一个卷积层,通过滑动窗口方法,分别获得各个窗口内特征的分类,再将所有分类求平均;
-
在训练时:采用数据增强方法:缩放至不同尺度(Multi-Scale),随机裁剪(Multi-Crop)为224*224,增加数据量,防止过拟合;
4. GoogLeNet(InceptionNet)系列
GoogLeNet 有多个版本(V1到V4),可以参考 :图像分类丨Inception家族进化史「GoogleNet、Inception、Xception」。
GoogLeNet 也叫 Inception net,因为 GoogLeNet 中的核心组成部分就是 inception module。另外值得一提的是 GoogLeNet 的名字有向 LeNet 致敬的意思。GoogLeNet 参加了2014年的 ImageNet 挑战赛,并取得分类任务第一名的成绩。GoogLeNet 相比 VGG 来说网络深度更进一步,达到了 22 层,另外在宽度上也做了拓展,但是参数量却小得多,而且效果也很不错.
YOLO V1 的主干网络就是基于 GoogLeNet 的。
先上Paper列表:
大体思路:
- [v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
- [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
- [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
- [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
- Inception v1的网络,将1×1,3×3,5×5的conv和3×3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
- v2的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3×3的conv替代inception模块中的5×5,既降低了参数数量,也加速计算;
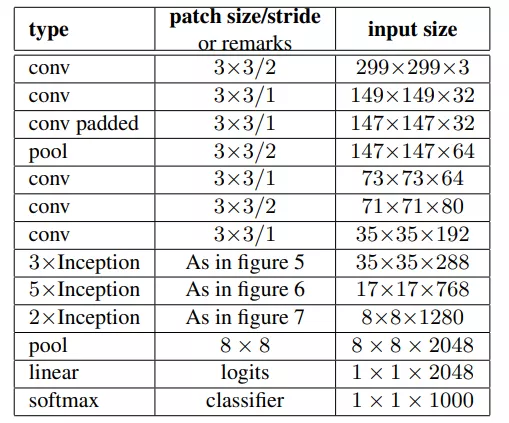
- v3一个最重要的改进是分解(Factorization),将7×7分解成两个一维的卷积(1×7,7×1),3×3也是一样(1×3,3×1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224×224变为了299×299,更加精细设计了35×35/17×17/8×8的模块;
- v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。
4. 1 Inception-v1(GoogleNet): (2015)
《Going Deeper with Convolutions》https://arxiv.org/abs/1409.4842
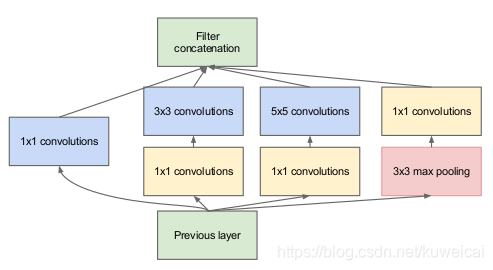
核心创意思想:如下图所示,由于图像的突出部分可能有极大的尺寸变化,这为卷积操作选择正确的内核大小创造了困难,比如更全局的信息应该使用大的内核,而更局部的信息应该使用小内核。不妨在同一级运行多种尺寸的滤波核,让网络本质变得更"宽"而不是”更深“。

于是,就提出Inception模块(左),具有三种不同的滤波器(1×1,3×3,5×5)和max pooling。为降低计算量,GooLeNet借鉴Network-in-Network的思想,用1×1卷积降维减小参数量(右)。可在保持计算成本的同时增加网络的深度和宽度。
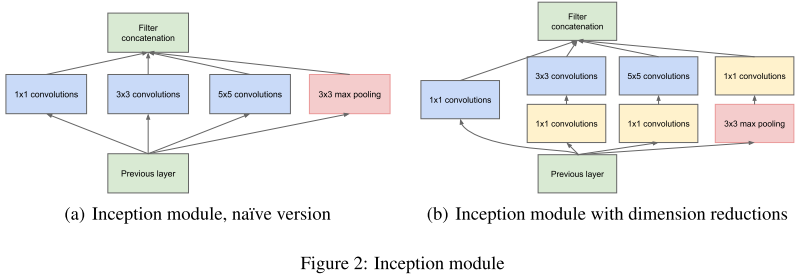
Inception控制了计算量和参数量的同时,获得了很好的性能,top-5错误率6.67%,只有约500万的参数量,Alexnet有6000万的参数。
GoogLeNet的关键点:
1、采用多分支结构(多分支分别计算,再级联结果),模块化结构(Inception)
2、采用1×1卷积的主要是为了减少维度;
3、使用average pooling(平均池化)来代替FC(全连接层);
4、为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练很有裨益。而在实际测试的时候,这两个额外的softmax会被去掉。
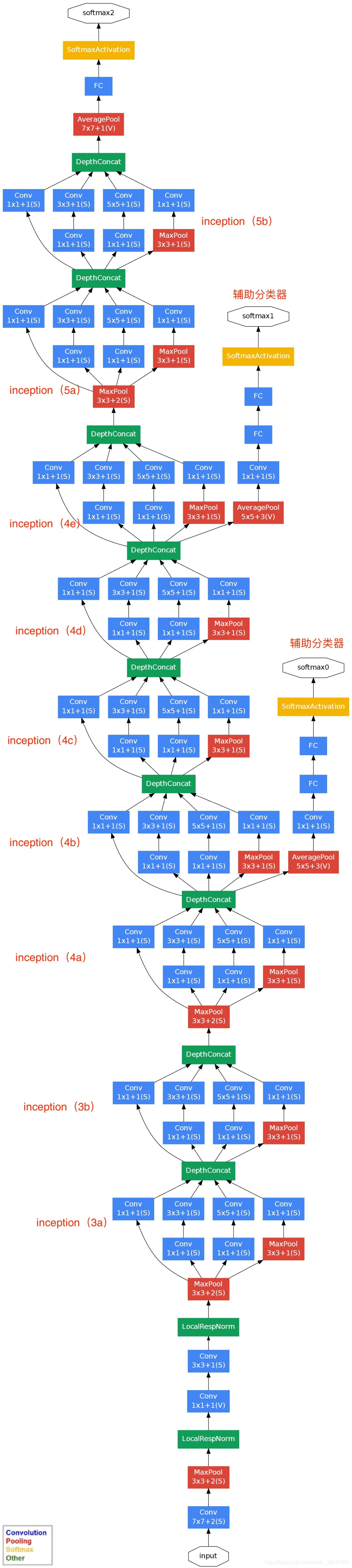
网络结构说明:
- GoogLeNet具有9个Inception模块,22层深(27层包括pooling),并在最后一个Inception模块使用全局池化。
- 由于网络深度,将存在梯度消失vanishing gradient的问题。
- 为了防止网络中间部分消失,作者提出了两个辅助分类器auxiliary classifiers,总损失是实际损失和辅助损失的加权求和。
# The total loss used by the inception net during training.
total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
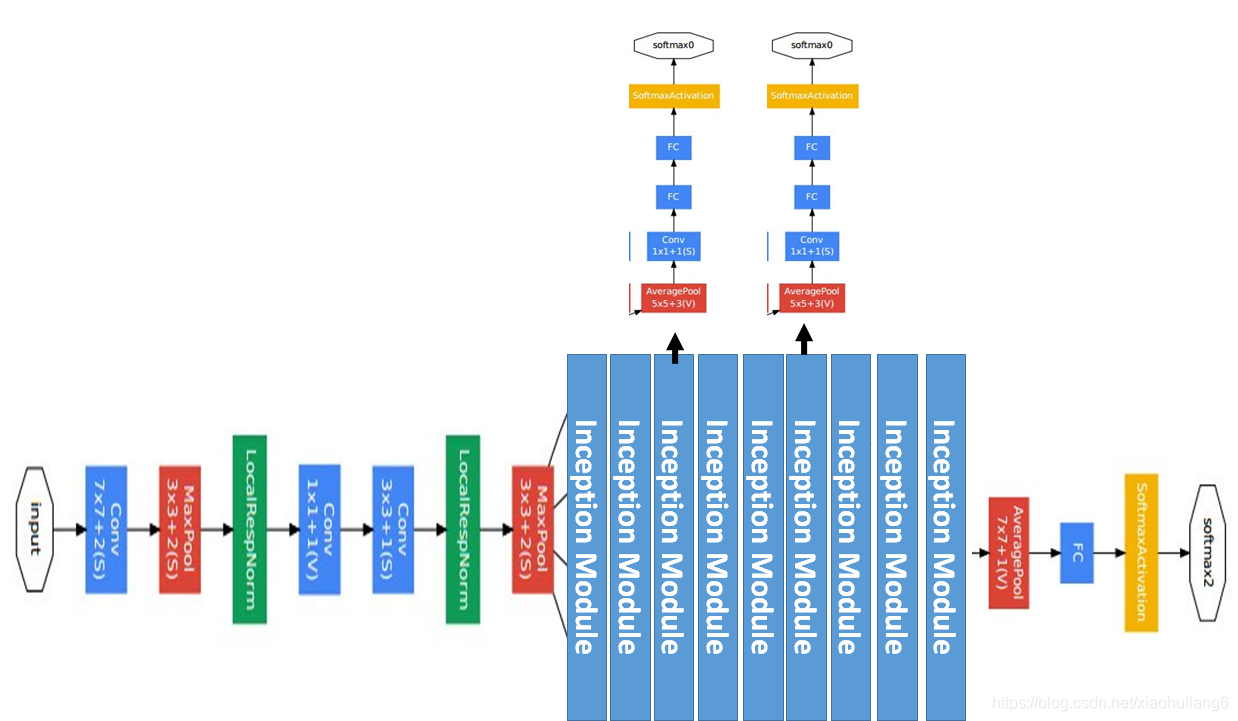
Inception Module中,1*1的卷积比例最高,3*3和5*5的卷积比例稍低,整个网络会有多个Inception Module。我们希望靠后的Inception Module可捕捉更高阶的抽象特征,因此靠后的Inception Module的卷积的空间集中度应该降低,这样可捕获大面积的特征。靠后的Inception Module中,3*3和5*5的占比更多。
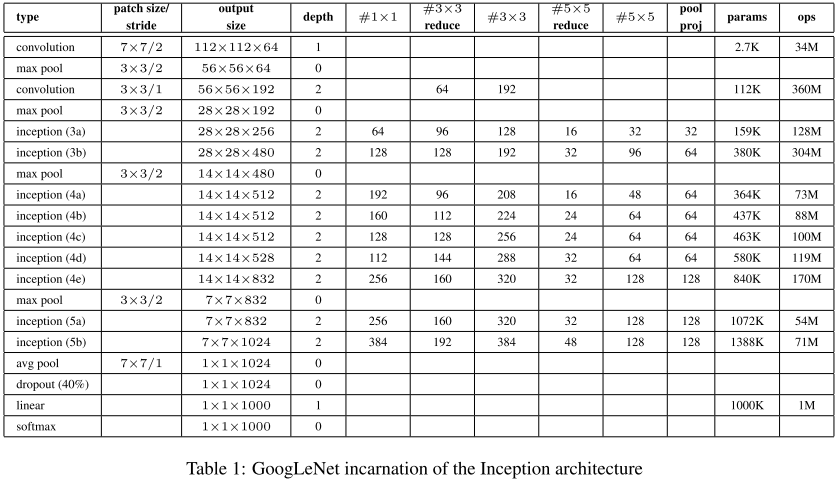
4.3 Inception-v2 (2015,更确切地说是BN-inception)
涉及到两篇论文:
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
《Rethinking the Inception Architecture for Computer Vision》
google这边对于inception v2是属于哪篇论文有些不同观点,本博客是以下面第二种解释为准:
- 在《Rethinking the Inception Architecture for Computer Vision》中认为:基于inception v1进行结构的改进是inception v2;在inception v2上加上BN是inception v3;
- 在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中将《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》认为是inception v2(即inception v1 上进行小改动再加上BN);《Rethinking the Inception Architecture for Computer Vision》认为是inception v3
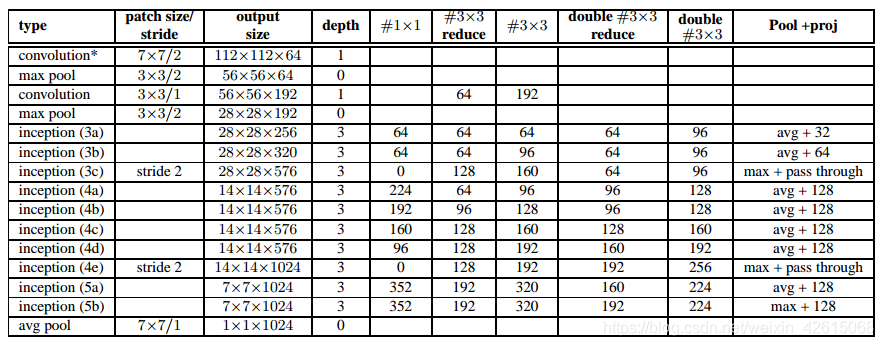
从google实现的Inception V1源码可以看出V2的改进主要是以下两点:
-
使用了Batch Normalization。BN带来的好处有: 对每一层的输入做了类似标准化处理,能够预防梯度消失和梯度爆炸,加快训练的速度;减少了前面一层参数的变化对后面一层输入值的影响,每一层独立训练,有轻微正则化效果
-
用两个3x3Convolution替代一个5x5Convolution。
另外一些细微的改变有:
- Inception 3模块的数量从原来啊的两个变为三个;
- 在Inception模块内部有的使用Max Pooling 有的使用Max Pooling;
- 两个Inception模块群之间没有明显的池化层,采用步长为2 的卷积代替,例如3c 和4e 层concatenate之前。

对比 网络结构之 GoogleNet(Inception V1):
- [1] 5×5 卷积层被替换为两个连续的 3×3 卷积层. 网络的最大深度增加 9 个权重层. 参数量增加了大约 25%,计算量增加了大约 30%。两个 3×3 卷积层作用可以代替一个 5×5 卷积层;
- [2] 28×28 的 Inception 模块的数量由 2 增加到了 3;
- [3] Inception 模块,Ave 和 Max Pooling 层均有用到;
- [4] 两个 Inception 模块间不再使用 pooling 层;而在模块 3c 和 4e 中的 concatenation 前采用了 stride-2 conv/pooling 层;
- [5] 网络结构的第一个卷积层采用了深度乘子为 8 的可分离卷积(separable convolution with depth multiplier 8),减少了计算量,但训练时增加了内存消耗.
4.3 Inception-v3 (2015)
Inception-v2 更确切地说是BN-inception,4.3节中的Inception_v2指的是《Rethinking the Inception Architecture for Computer Vision》论文中的Inception_v2和Inception_v3。两者的区别在于《Rethinking the Inception Architecture for Computer Vision》这篇论文里提到了多种设计和改进技术,使用其中某部分结构和改进技术的是Inception_v2,全部使用了的是Inception_v3。
模型设计原则
Inception_v1结构由于比较复杂,很难在其基础上有所改变,如果随意更改其结构,则很容易直接丧失一部分计算收益。同时,Inception_v1论文中没有详细各个决策设计的因素的描述,这使得它很难去简单调整以便适应一些新的应用。为此,Inception_v2论文里详细介绍了如下的设计基本原则,并基于这些原则提出了一些新的结构。
1.避免表示瓶颈,特别是在网络的浅层。一个前向网络每层表示的尺寸应该是从输入到输出逐渐变小的。(当尺寸不是这种变化时就会出现瓶颈)
2.高维度的表示很容易在网络中处理,增加激活函数的次数会更容易解析特征,也会使网络训练的更快。(这条原则的意思是表示维度越高,越适合用网络来处理,像二维平面上的数据分类反而就不适合用网络来处理,增加激活函数的次数会使得网络更容易学到其表示特征)
3. 可以在较低维的嵌入上进行空间聚合,而不会损失很多表示能力。例如,在执行更分散(例如3×3)的卷积之前,可以在空间聚集之前(浅层)减小输入表示的尺寸,而不会出现严重的不利影响。我们假设这样做的原因是,如果在空间聚合环境中(中高层)使用输出,则相邻单元之间的强相关性会导致在尺寸缩减期间信息损失少得多。鉴于这些信号应易于压缩,因此减小尺寸甚至可以促进更快的学习。
4. 平衡网络的宽度和深度。通过平衡每个阶段的滤波器数量和网络深度,可以达到网络的最佳性能。增加网络的宽度和深度可以有助于提高网络质量。但是,如果并行增加两者,则可以达到恒定计算量的最佳改进。因此,应在网络的深度和宽度之间以平衡的方式分配计算预算。
一些特殊的优化结构:
01 卷积分解
一个5×5的卷积核可通过两个连续的3×3卷积核来代替,其中第一个是正常的3×3卷积,第二个卷积是在上一层3×3卷积的基础上进行全连接。这样做的好处是既实现了5×5卷积该有的感受野,又实现了更小的参数2×9/25,大概缩小了28%。具体如下左图fig1所示。更进一步,采用非对称分解,将一个3×3的卷积分解为3×1和1×3。具体如下右图fig2.
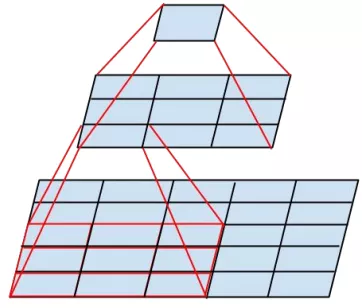
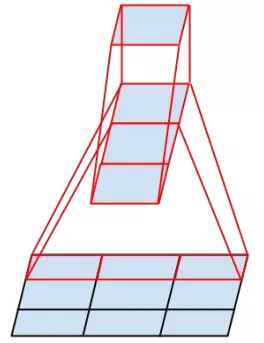
因此原来的Inception结构(左图fig3)就可以变成如下所示的结构(中图fig5)和(右图fig6)。

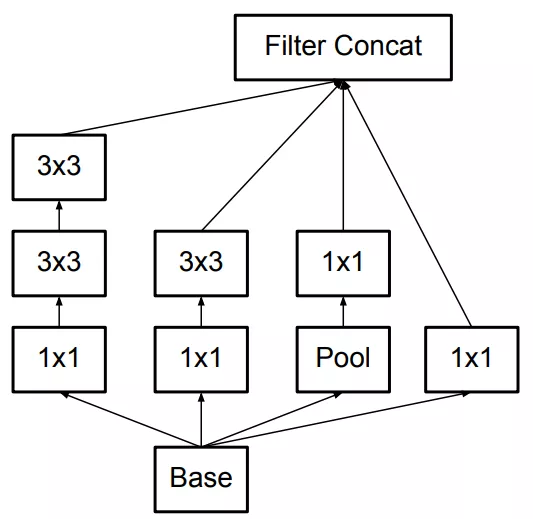
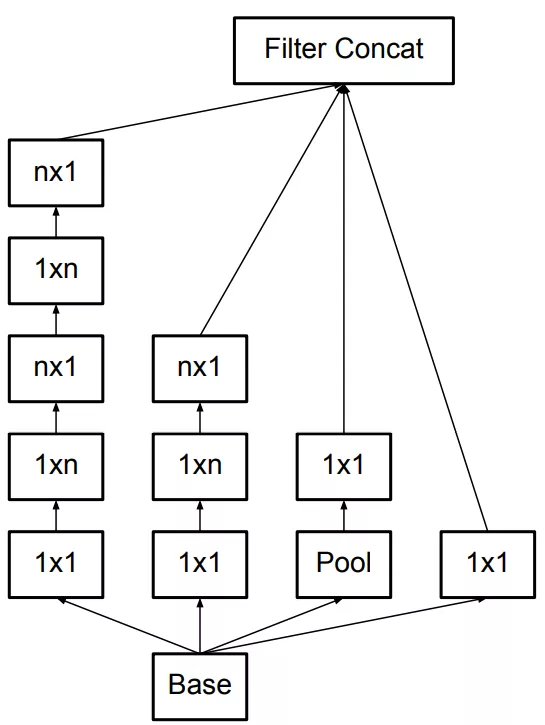
最终还衍生出了如下图所示(fig7)一种混合两种分解方式的结构。
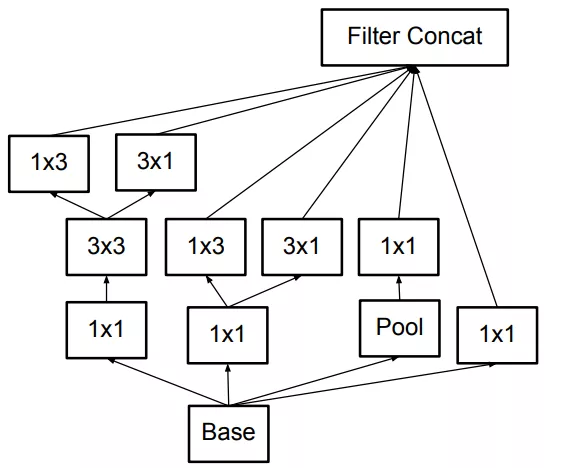
在实际应用中,使用这样的分解结构在网络低层的效果并不好。它在中等尺寸大小(mxm的feature map 其中m在12到20范围内)的层中会有比较好的效果。这是考虑到第二条原则,这样的Inception结构将会放在网络中间层,而在网络低层仍然使用一般卷积网络的结构。
02 辅助分类器的效用
辅助分类器在训练的前期并没有起什么作用,到了训练的后期才开始在精度上超过没有辅助分类器的网络,并达到稍微高的平稳期。并且,在去除这两个辅助分类器后并没有不利的影响,因此在Inception_v1中提到的帮助低层网络更快训练的观点是有问题的。如果这两个分支有BN或Dropout,主分类器的效果会更好,这是BN可充当正则化器的一个微弱证据。
03 高效降低Grid Size
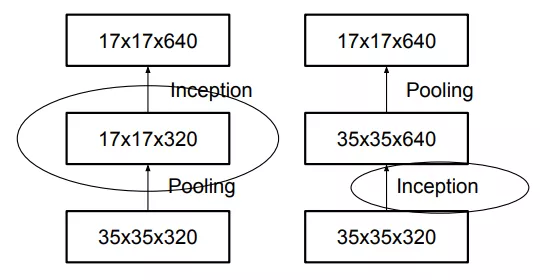
关于降低Grid Size大小的方式,有如上图所示两种做法。左边这种违背了第一条原则,即尺寸应该逐层递减,否则会出现bottleneck。右图符合第一条原则,然而这样参数量巨大。为此作者提出了一种如下图(fig10)所示的新方式。即并行操作,利用步长都为2的卷积和池化操作,在不违背第一条原则的基础上实现降低Grid Size。
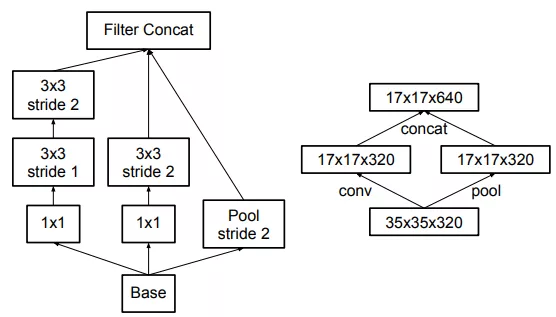
完整的Inception_v2结构图如下:
整个结构中都没有用到padding, 提出的fig10结构用在了中间每个Inception模块之间。
04 通过标签平滑化的模型正则化
如果模型在训练过程中学习使得全部概率值给ground truth标签,或者使得最大的Logit输出值与其他的值差别尽可能地大,直观来说就是模型预测的时候更自信,这样将会出现过拟合,不能保证泛化能力。因此标签平滑化很有必要。
![]()
前面的δk,y 是狄拉克函数,即类别k = y,即为1,否则为0。原本的标签向量q(k|x) = δk,y。而标签平滑化后的标签向量变为如下公式。
这里的∈为超参数,u(k)取1/k,k表示类别数。即新的标签向量(假定是三分类)将变为(∈/3, ∈/3, 1-2∈/3 ),而原来的标签向量是(0,0,1)。
结论
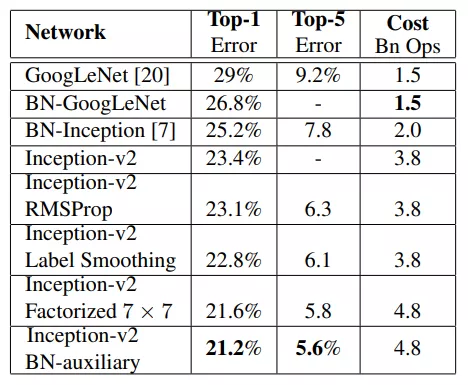
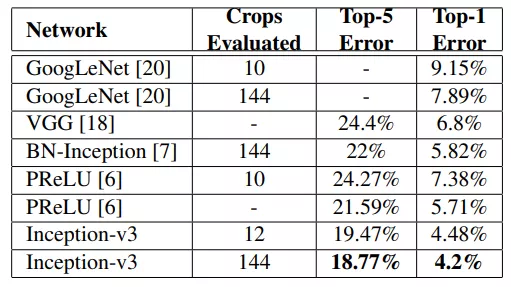
实际效果如图所示,在这里说明该论文中的Inception_v2与Inception_v3的区别,Inception_v2指的是使用了Label Smoothing 或BN-auxiliary或RMSProp或Factorized技术中的一种或多种的Inception模块。而Inception_v3指的是这些技术全用了的Inception模块。
4.4 (1)Inception-v4: (2017)
Inception V4源于论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
这篇文章结合ResNet和Inception提出了三种新的网络结构
- Inception-ResNet-v1:混合版Inception,和InceptionV3有相同计算成本。
- Inception-ResNet-v2:计算成本更高,显著提高performance。
- InceptionV4:纯Inception变体,无residual连接,媲美Inception-ResNetV2
核心思想:
- InceptionV4是对原来的版本进行了梳理,因为原始模型是采用分区方式训练,而迁移到TensorFlow框架后可以对Inception模块进行一定的规范和简化。
网络架构:
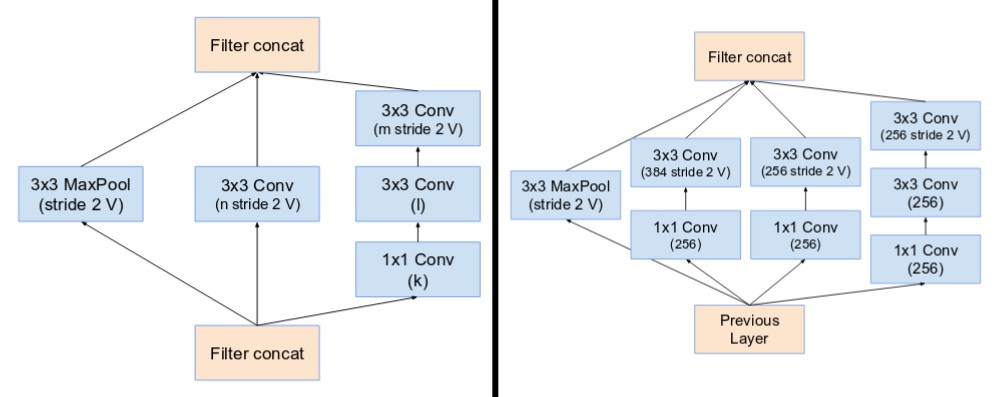
- Stem:Inception-ResNetV1采用了top,Inceptionv4和Inception-ResNetV2采用了bottom。
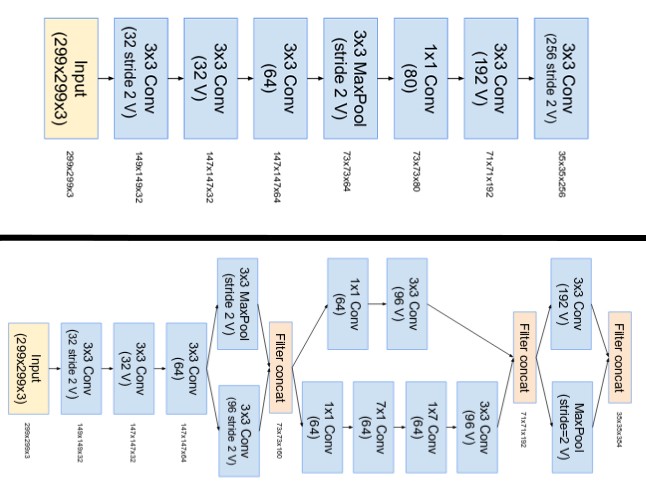
- Inception modules A,B,C
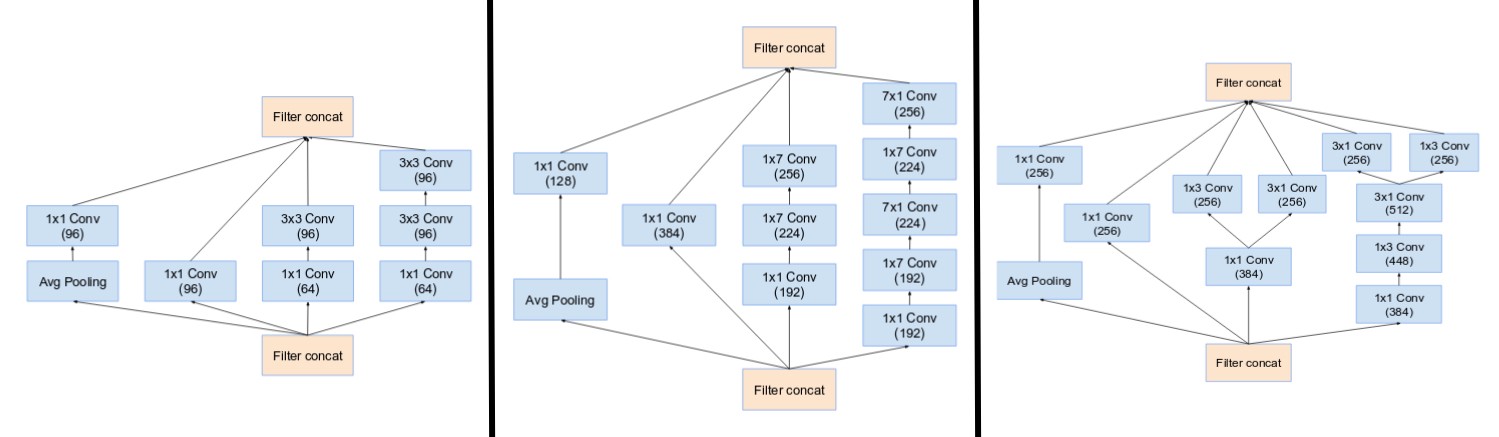
- Reduction Blocks A,B
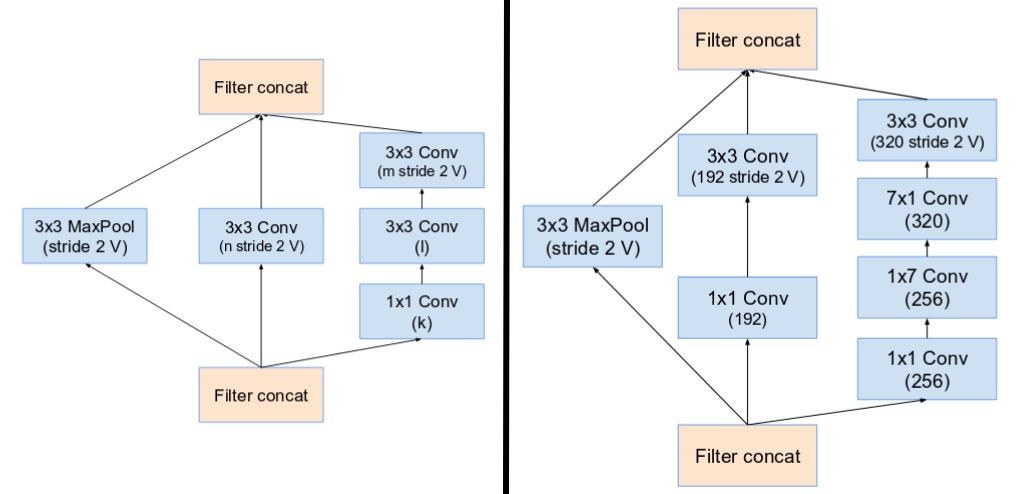
- Network
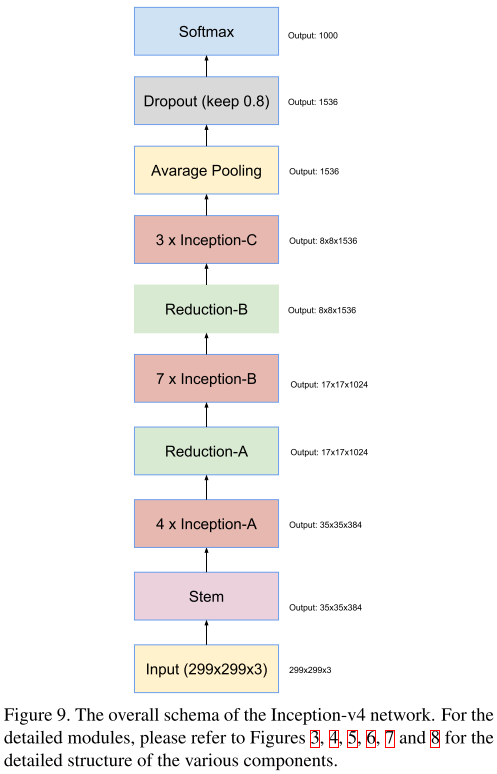
4.5 (2)Inception-resnet-v2: (2017)
同样源于论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
核心思想:
- 受ResNet启发,提出一种混合版的Inception。Inception-ResNet有v1、v2版本。
- Inception-ResNetV1计算量与InceptionV3相似,Inception-ResNetV2计算量与InceptionV4相似。
- 它们有不同的steam。
- 它们的A、B、C模块相同,区别在于超参数设置。
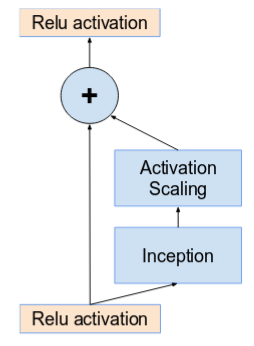
当卷积核数量超过1000时,更深的单元会导致网络死亡。因此为了增加稳定性,作者对残差激活值进行0.1-0.3的缩放。
网络架构:
- Steam:见 InceptionV4
- Inception-ResNet Module A,B,C
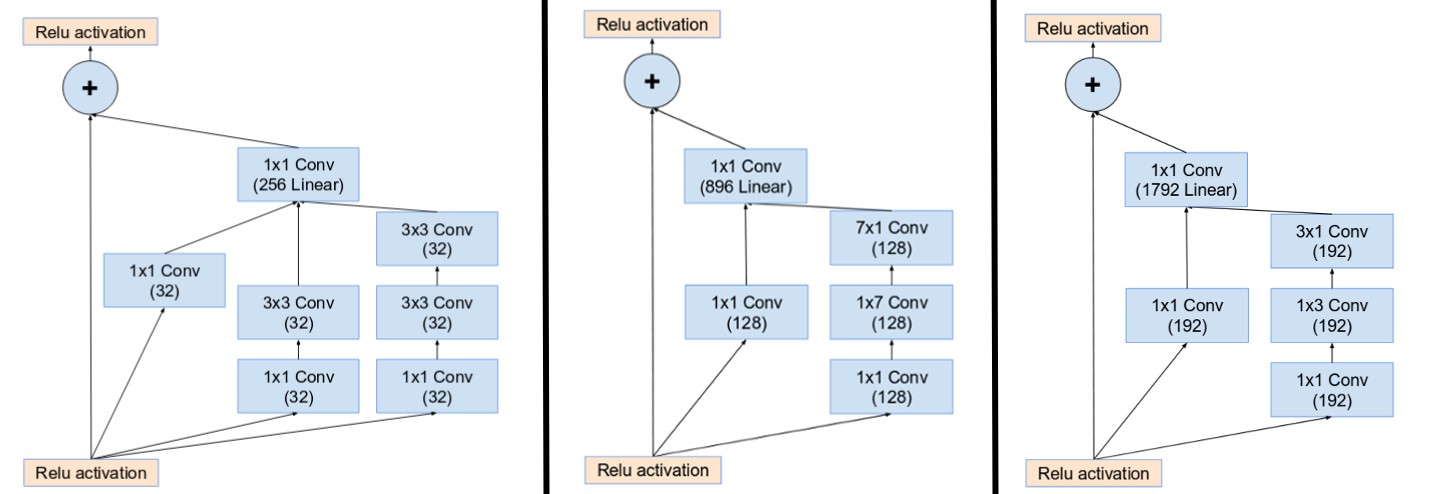
- Residual Blocks A,B
- Network
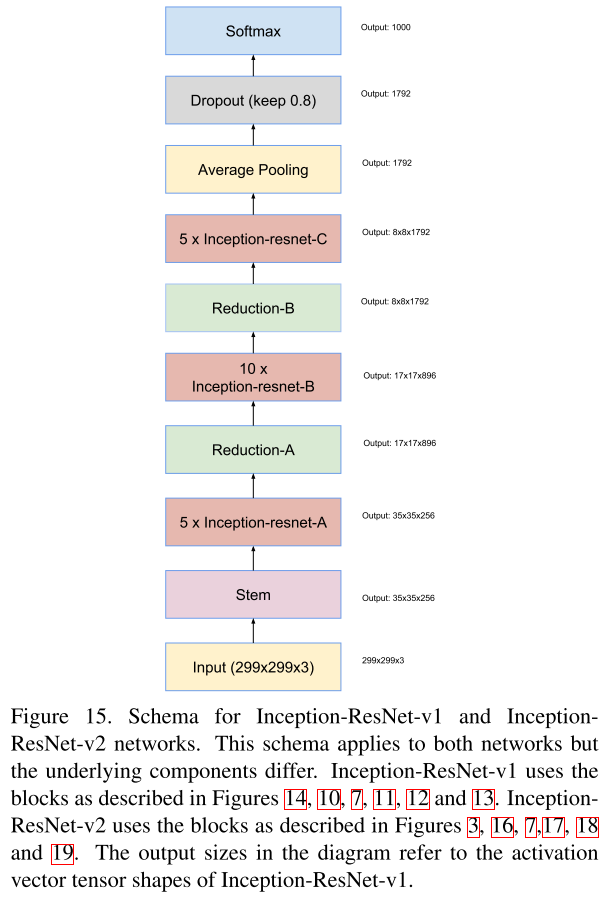
5. Resnet: (2016)
https://ieeexplore.ieee.org/document/7780459
网络越深,越难训练,这是因为存在梯度消失和梯度爆炸问题
残差连接时,先加法运算,再激活
随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
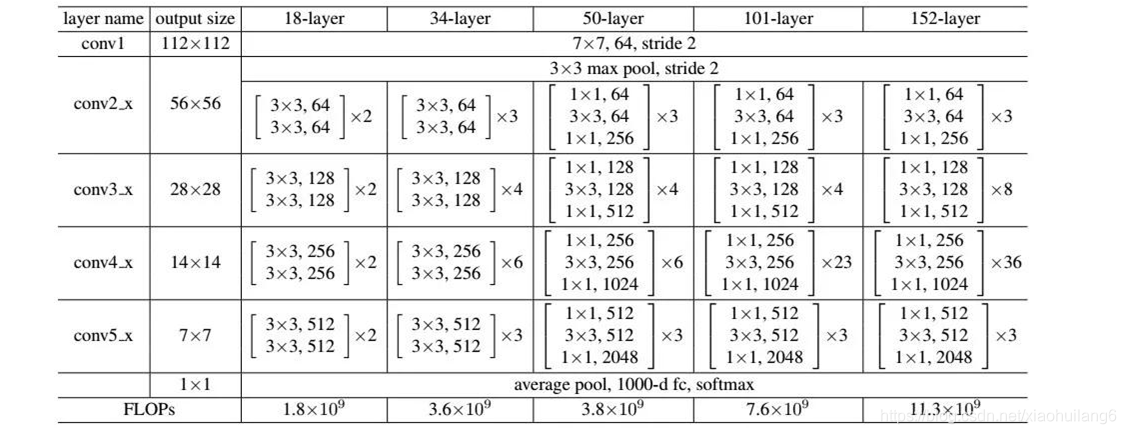

6. ResNet变种
ResNet 出来后,大家又基于 ResNet 提出了很多改进版本,这里主要对一些效果比较好的变种进行简单介绍。
6.1 ResNeXt (2016)
作者:Saining Xie 等
Paper 原文: Aggregated Residual Transformations for Deep Neural Networks
ResNeXt 一作虽然不是何凯明,但是他依然有参与。ResNet 是结合了 Inception net 和 ResNet 的思想,提出的一种网络结构。
传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构一样)。
网络结构:
ResNet 中通过重复的堆叠 block,从而使得其结构非常的简单,这样仅仅通过控制网络的深度就可以完成超参数的选择,比如你可以选择 18 或者 50 或者其他的层数,而不用关心其内部的具体结构。
Inception net 中通过精心设计的 Inception Module,在某些数据集中可以达到好的效果,可是如果要应用到其他场景下,修改起来就比较麻烦了。Inception 系列网络,简单讲就是 split-transform-merge 的策略,但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。这里提到一个名词cardinality,原文的解释是the size of the set of transformations,如下图 右边是cardinality=32 的样子,这里注意每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)
因此作者提出了 ResNeXt,和 ResNet 一样,依然采用堆叠 block 的方式来搭建网络,但是 block 的结构和 Inception block(如下图2)的结构有些类似。和 Inception block 不同的地方在于,ResNeXt 的 block 中的每一个 path 是相同的。另外作者采用分组卷积来提升计算效率。
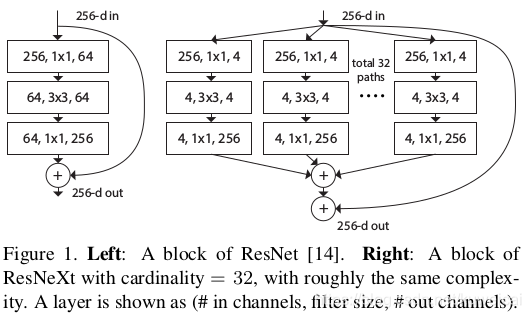
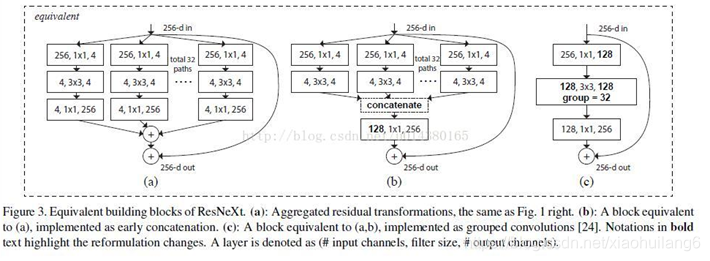 下图为 inception model。
下图为 inception model。
在 ImageNet 上,ResNeXt 取得了比 ResNet 更好的成绩,相比 GoogLeNet v4,ResNext 结构更简单,效果也更好,但是由于 ResNext 直接废除了Inception 的囊括不同感受野的特性仿佛不是很合理,在更多的环境中我们发现Inception V4的效果是优于ResNeXt的
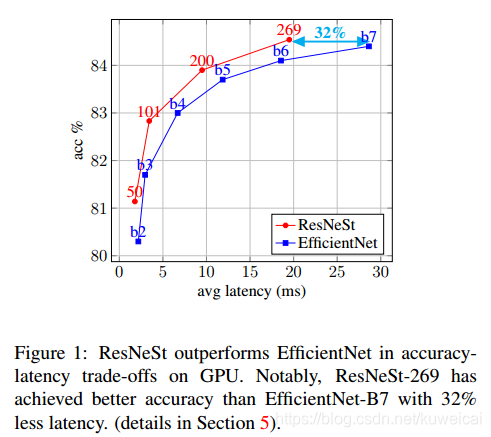
6.2 ResNeSt(2020)
作者:Hang Zhang 等
Paper 原文: ResNeSt: Split-Attention Networks
ResNeSt 应该说是集合多种网络(GoogleNet,ResNeXt,SE-Net,SK-Net)的优点和一众工程上的 trick 于一身的网络,效果上也达到了 SOTA 的水准。
参考:
【论文笔记】张航和李沐等提出:ResNeSt: Split-Attention Networks(ResNet改进版本)
ResNest 论文曾引发一系列质疑和讨论,那是学术圈的事情,但是不妨碍模型在分类、检测和分割任务上均有很好的表现。
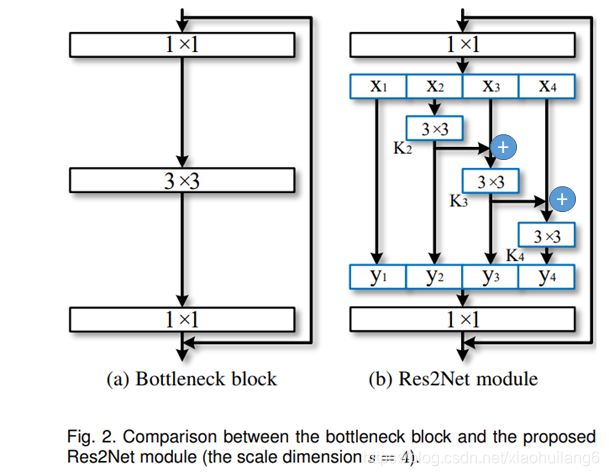
6.3 Res2Net(2019)
作者:Shang-Hua Gao等
Paper 原文: Res2Net: A New Multi-scale Backbone Architecture
具体可以参考:
Res2Net 中提出一种多尺度结构,可以方便的应用到其他网络模型中,比如替换 ResNet 中的 bottleneck block,就可以得到明显的提升。Res2Net 在检查和分割任务中提升明显。
计算负载不增加,特征提取能力更强大。卷积神经网络(CNN) backbone 的最新进展不断展示出更强的多尺度表示能力,从而在广泛的应用中实现一致的性能提升。然而,大多数现有方法以分层方式(layer-wise)表示多尺度特征。
在本文中,研究人员在一个单个残差块内构造分层的残差类连接,为CNN提出了一种新的构建模块,即Res2Net——以更细粒度(granular level)表示多尺度特征,并增加每个网络层的感受野(receptive fields)范围。
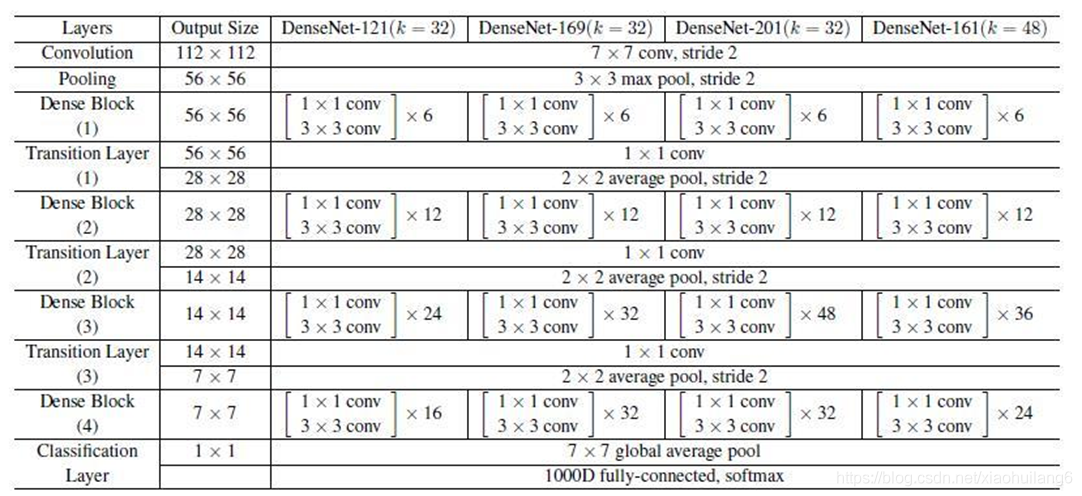
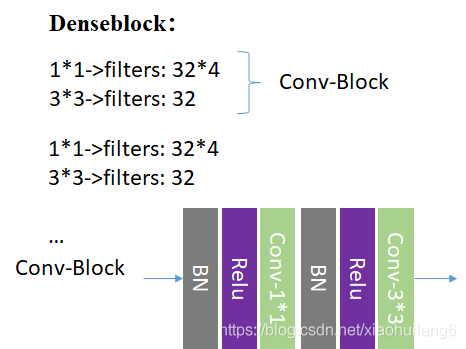
6.4 DenseNet (2017)
作者:Gao Huang等
Paper 原文: Densely Connected Convolutional Networks
具体可以参考:
这篇文章获得了 CVPR 2017, Best Paper Award。DenseNet 脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生。
主要特点在于:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上较少了参数数量
每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练
Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.
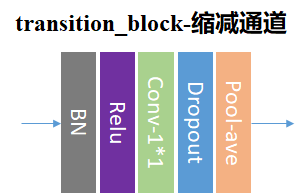
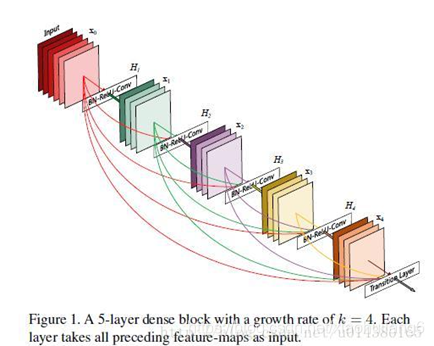

6.5 其他
除此之外还有 swsl_resnet, ssl_resnet, wide_resnet 等模型值得关注。
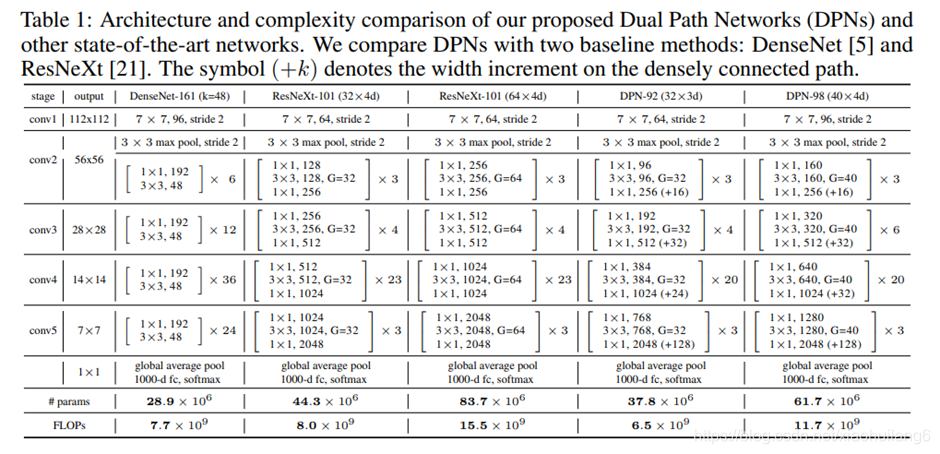
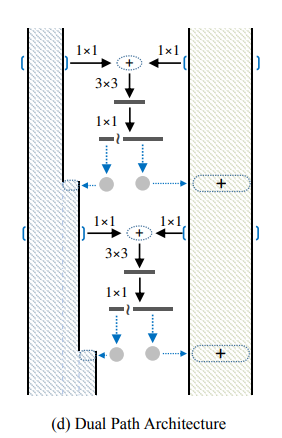
7. DPNet:(2017)
https://arxiv.org/abs/1707.01629
DPN算法简单讲就是将ResNeXt和DenseNet融合成一个网络
8. NasNet:(2018)
https://arxiv.org/pdf/1707.07012.pdf
Neural Architecture Search (NAS) framework:模型结构搜索网络
核心一:延续NAS论文的核心机制使得能够自动产生网络结构;
核心二:采用resnet和Inception重复使用block结构思想;
核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
假设:如果一个神经网络能在结构相似的小规模数据集上得到更好的成绩,那么它在更大更复杂的数据集上同样能表现得更好。
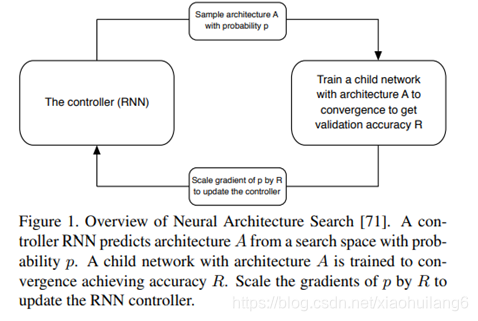
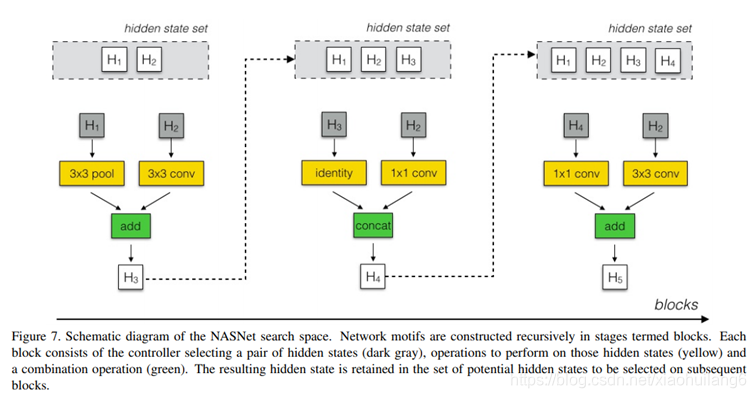
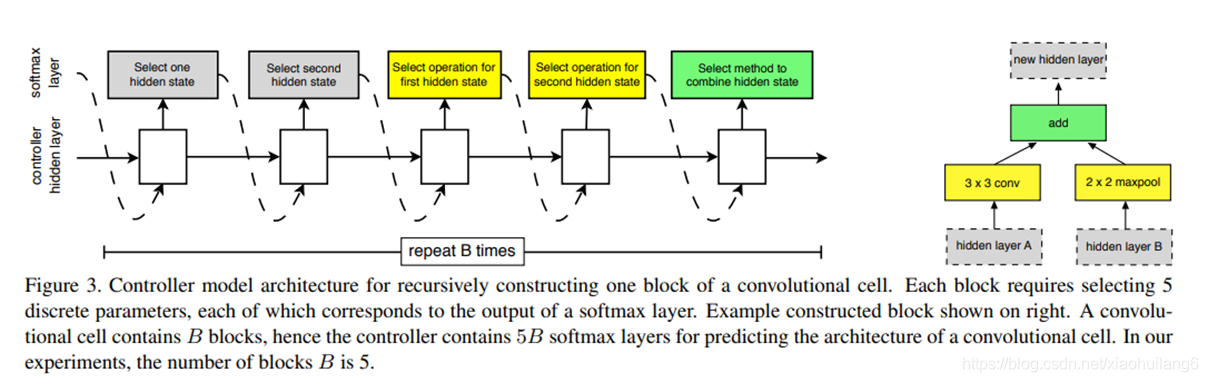
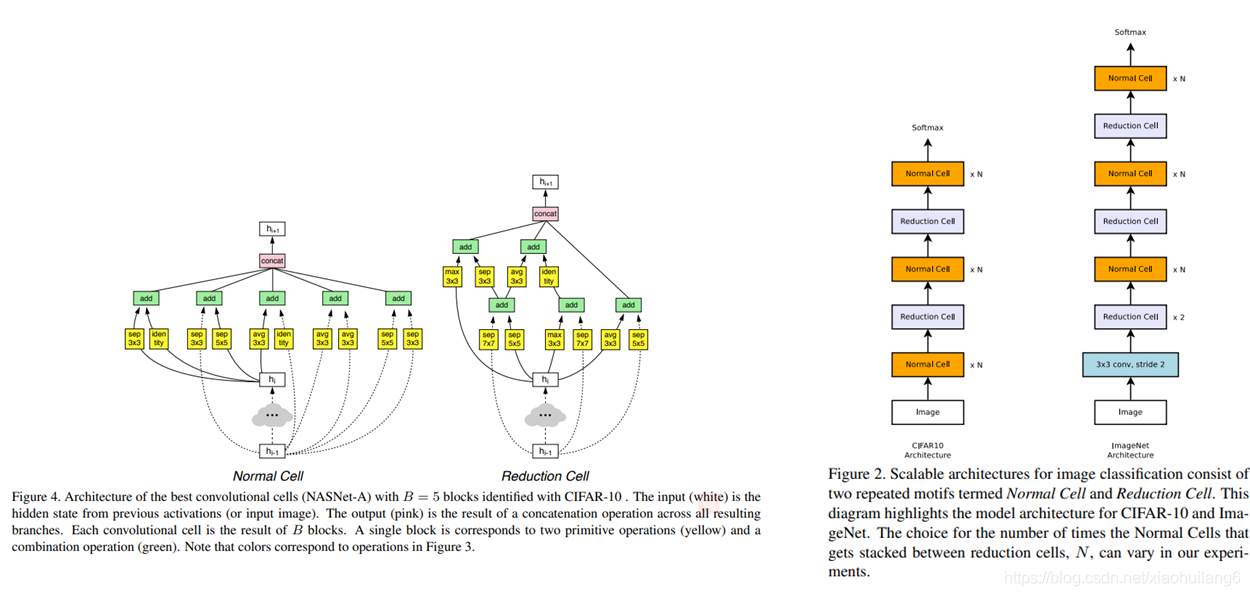
控制器依次搜索隐藏状态,隐藏状态,何种操作,何种操作,何种组合方法,这5个方法和操作的组合。其中,每种方法,每种操作都对应于一个softmax损失。这样重复B次,得到一个最终block模块。最终的损失函数就有5B个。实验中最优的B=5。

Scheduled Drop Path
在优化类似于Inception的多分支结构时,以一定概率随机丢弃掉部分分支是避免过拟合的一种非常有效的策略,例如DropPath[4]。但是DropPath对NASNet不是非常有效。在NASNet的Scheduled Drop Path中,丢弃的概率会随着训练时间的增加线性增加。这么做的动机很好理解:训练的次数越多,模型越容易过拟合,DropPath的避免过拟合的作用才能发挥的越有效。
9. SENet及其变体SKNet
9.1 SENet(2017)
作者:Jie Hu 等
Paper 原文: Squeeze-and-Excitation Networks
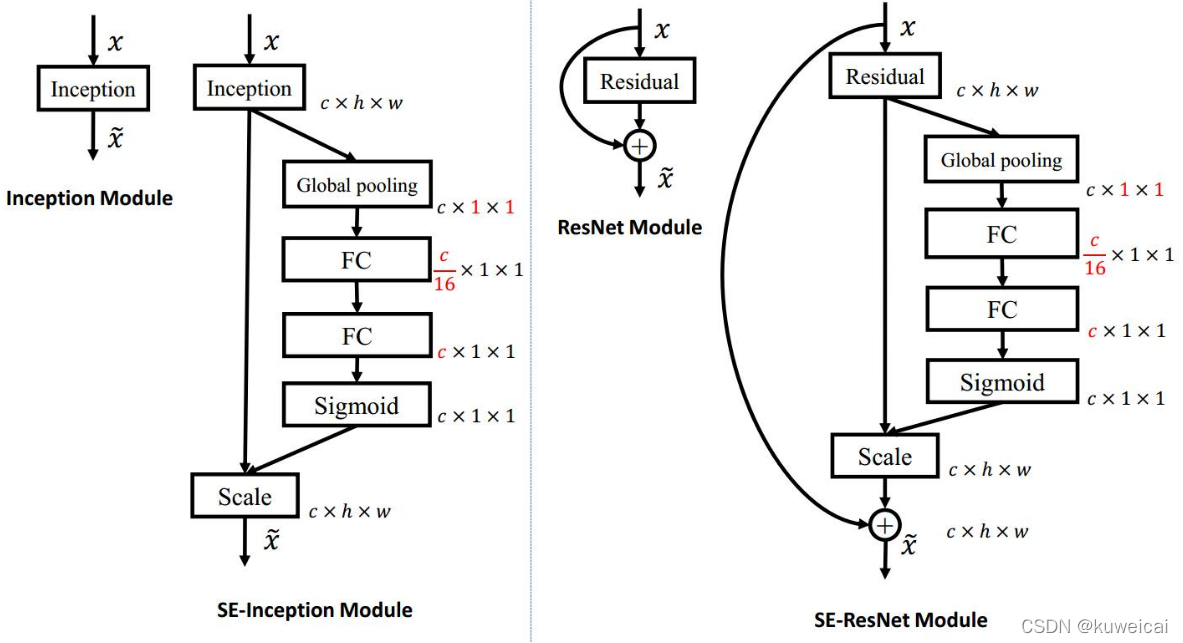
SENet 是最后一届 ImageNet 挑战赛(ILSVRC2017)的冠军。SENet 的核心是一种叫做 SE Block(Squeeze-and-Excitation) 的结构,其本质是在 channel 维度上做attention 或者 gating 操作,其创新点在于关注 channel 之间的关系,具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。此外,值得一提的是 SE Block 具有通用性,可以比较方便的拓展到其他网络结构中(如 InceptionNet,ResNet等)。
作者在文中证明,加入 SE Block 后,计算量略有增加(不到1%),但是效果会更好。
SE Block 主要有三步,分别是 Squeeze, Excitation 和 Reweight(Scale)。
首先是 Squeeze 操作,我们顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
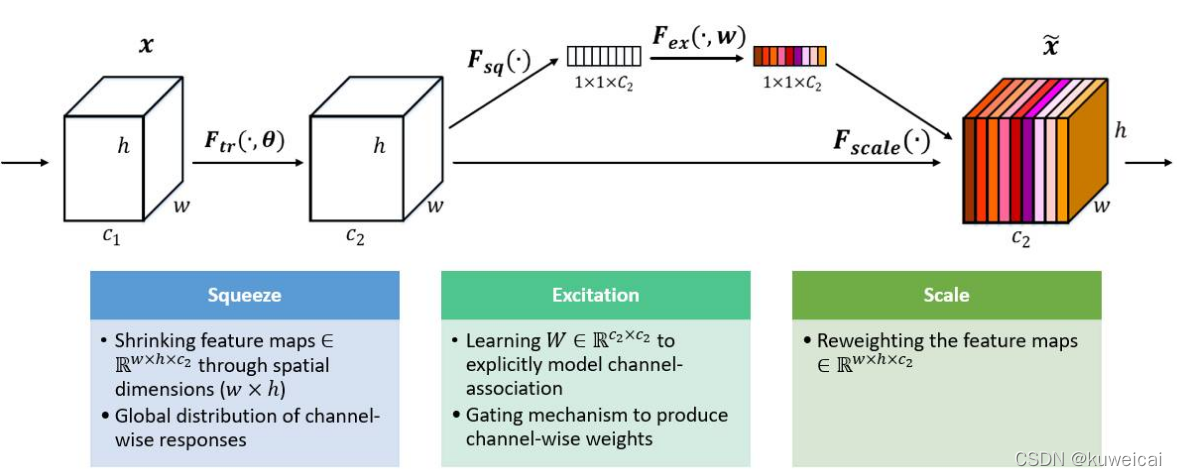
Squeeze操作
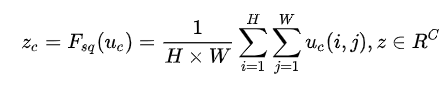
![]()
Excitation操作
![]()
为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
最后将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征。下图是将 SE Block 应用到具体网络的情况。首先使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:
-
具有更多的非线性,可以更好地拟合通道间复杂的相关性;
-
极大地减少了参数量和计算量。
然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
9.2 SKNet(2019)
参考
更深入的可以参考论文作者本人的讲解: SKNet——SENet孪生兄弟篇。
作者:Xiang Li 等
Paper 原文: Selective Kernel Networks
SKNet 是对 SENet 的改进,SENet 在 channel 维度上做 attention,而 SKNet 在 SENet 的基础上又引入了 kernel 维度上的 attention,除此之外,还利用诸如分组卷积和多路卷积的trike来平衡计算量。
(1)SK Convolution

-
Split:输入为 c ∗ h ∗ w c*h*wc∗h∗w 的特征图, F ^ , F ~ \hat{F}, \tilde{F}F^,F~ 均表示 Group Convlution。这里使用 Group Convlution 以减少计算量。注意,这里两路
Group Convlution 使用的不同大小的卷积核,原因在于提升精度。
-
Fuse:通过 Split 操作分成两路之后,再把两路结果进行融合,然后就是一个 Sequeeze and Excitation block。
-
Select:Select 模块把 Sequeeze and Excitation block 模块的结果通过两个 softmax 以回归出 Channel 之间的权重信息。然后把这个权重信息乘到 U ^ , U ~ \hat{U}, \tilde{U}U^,U~ 中。这个过程可以看做是一个 soft attention。最后把两路的特征图进行相加得到输出特征图 V VV 。
在分类和分割任务中取得比较好的效果。
10 EfficientNet 系列
10.1 EfficientNet-V1(2019)
https://arxiv.org/abs/1905.11946
卷积神经网络(ConvNets)通常是在固定的资源预算下发展起来的,如果有更多的资源可用的话,则会扩大规模以获得更好的精度,比如可以提高网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)大小。但是通过人工去调整 depth, width, resolution 的放大或缩小的很困难的,在计算量受限时有放大哪个缩小哪个,这些都是很难去确定的,换句话说,这样的组合空间太大,人力无法穷举。基于上述背景,该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)
Observation 1:对网络深度、宽度和分辨率中的任何温度进行缩放都可以提高精度,但是当模型足够大时,这种放大的收益会减弱。
Observation 2:为了追去更好的精度和效率,在缩放时平衡网络所有维度至关重要
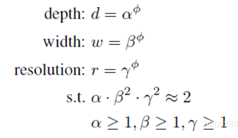
STEP 1:我们首先固定ϕ = 1 ,假设有相比于原来多了2倍的资源,我们基于等式(2)和(3)先做了一个小范围的搜索,最后发现对于EfficientNet-B0来说最后的值为α = 1.2 , β = 1.1 , γ = 1.15 ,在α ⋅ β 2 ⋅ γ 2 ≈ 2 的约束下;
STEP 2:接着我们固定α,β,γ作为约束,然后利用不同取值的ϕ 网络做放大,来获得Efficient-B1到B7;
10.2 EfficientNet-V2(2021)
Paper: EfficientNetV2: Smaller Models and Faster Training
code :https://github.com/google/automl/efficientnetv2
code : https://github.com/d-li14/efficientnetv2.pytorch
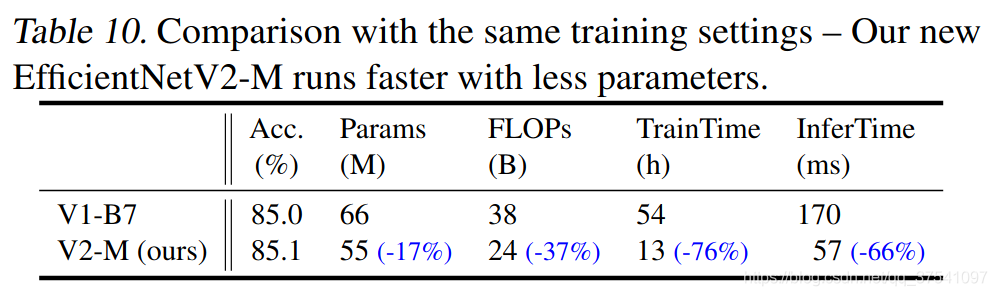
本文是谷歌的MingxingTan与Quov V.Le对EfficientNet的一次升级,旨在保持参数量高效利用的同时尽可能提升训练速度。在EfficientNet的基础上,引入了Fused-MBConv到搜索空间中;同时为渐进式学习引入了自适应正则强度调整机制。两种改进的组合得到了本文的EfficientNetV2,它在多个基准数据集上取得了SOTA性能,且训练速度更快。比如EfficientNetV2取得了87.3%的top1精度且训练速度快5-11倍。
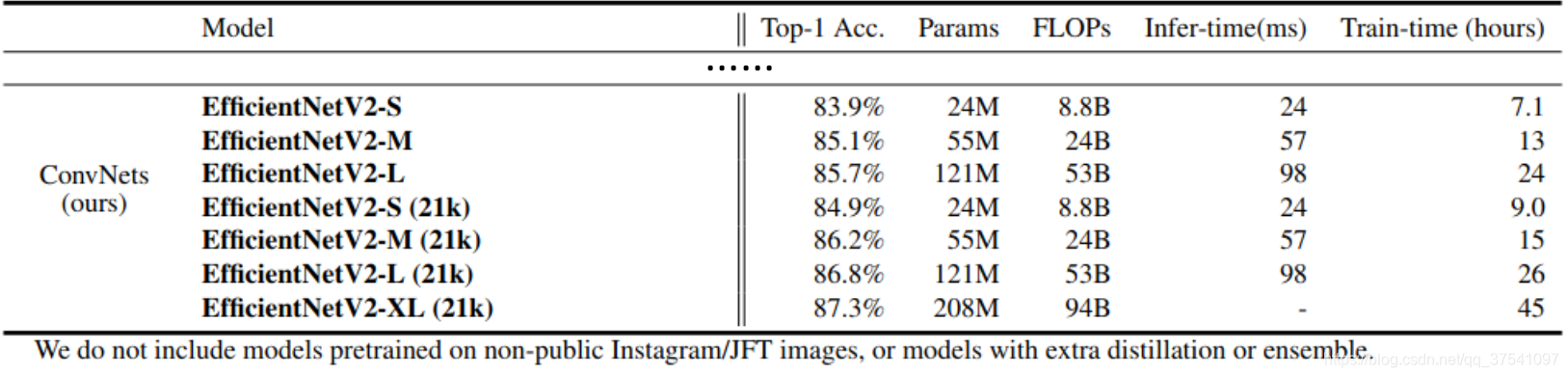
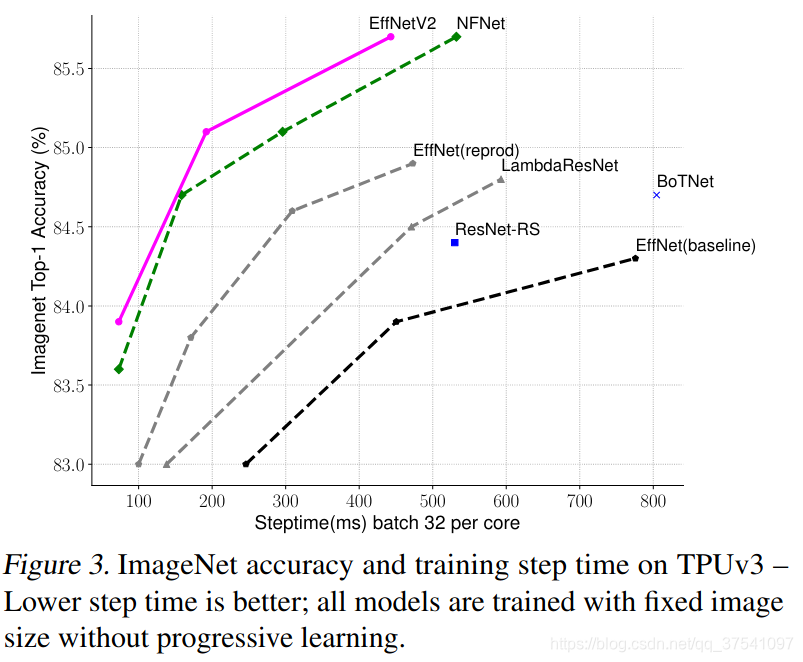
在之前的文章中有详细讲解过EfficientNetV1,地址,EfficientNetV2021年4月份发布的,但源码是这两天才放出来的,因为很多网络细节必须通过源码才能看清,所以简单阅读下源码后就来总结下这篇文章。首先放张论文中给出的EfficientNetV2的性能参数。
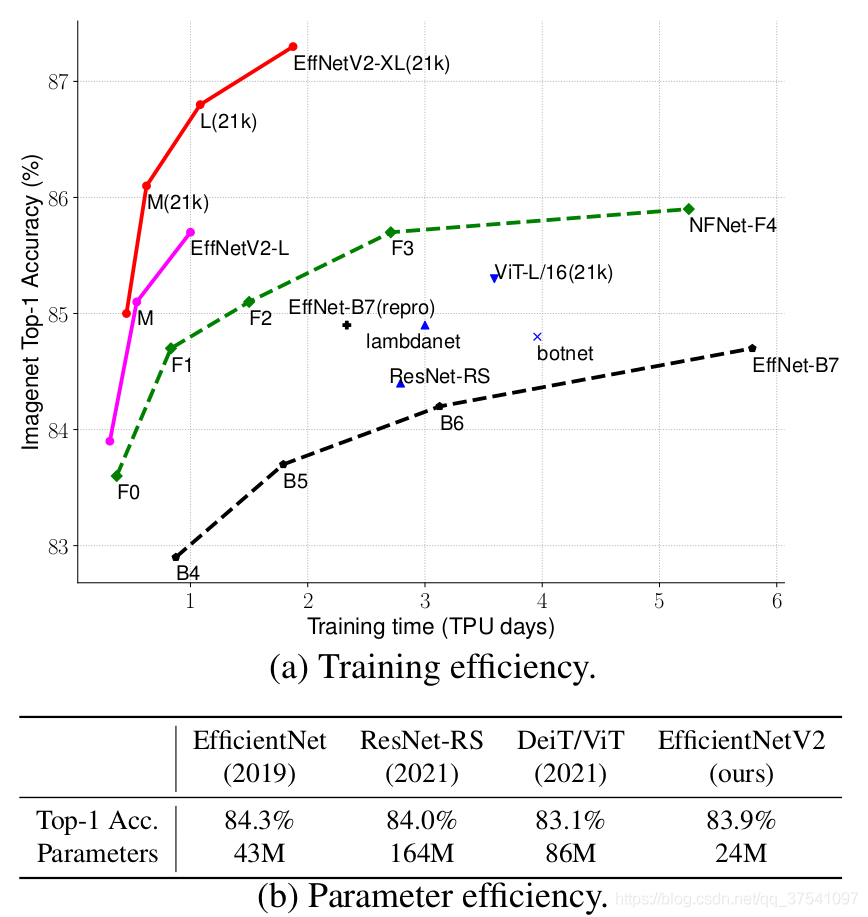
通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
(1)EfficientNetV1中存在的问题
作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
- 训练图像的尺寸很大时,训练速度非常慢。 这确实是个槽点,在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380×380时,batch_size=24还能跑起来,当训练的图像尺寸为512×512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.

- 在网络浅层中使用Depthwise convolutions速度会很慢。 虽然
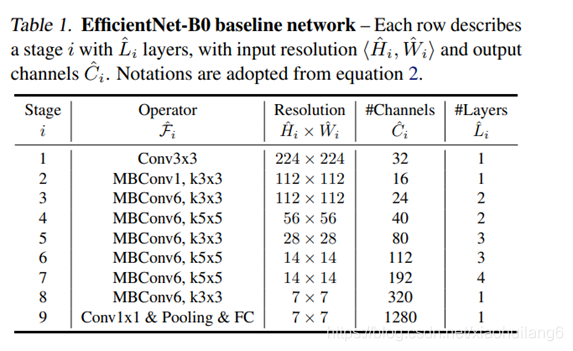
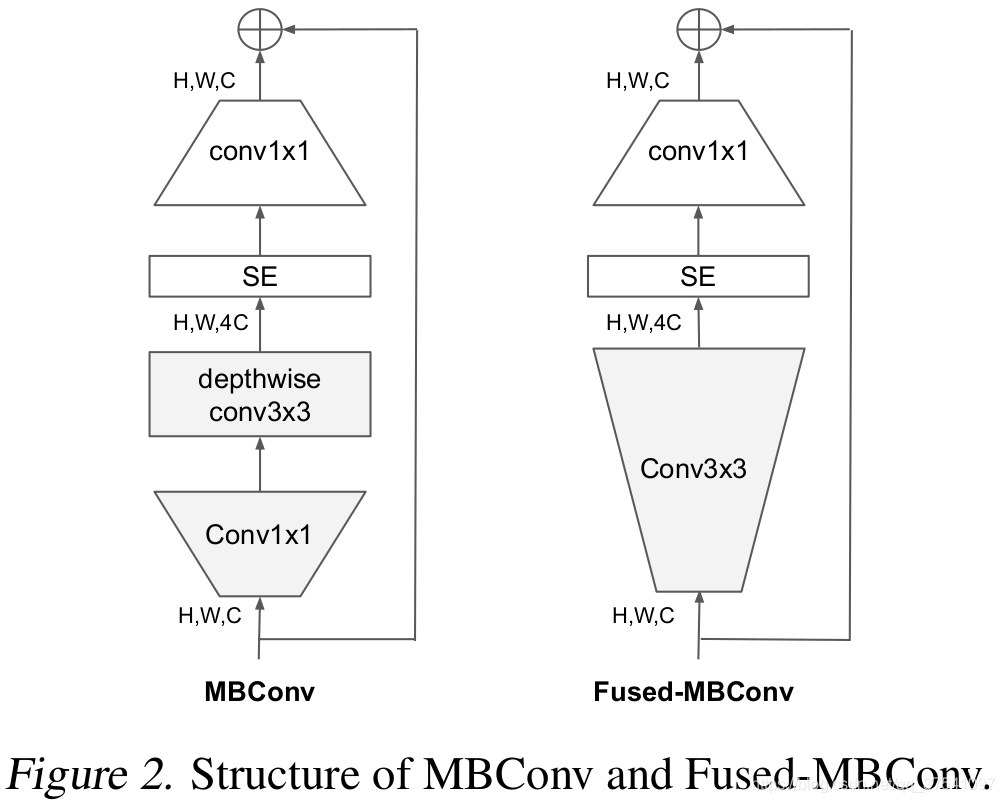
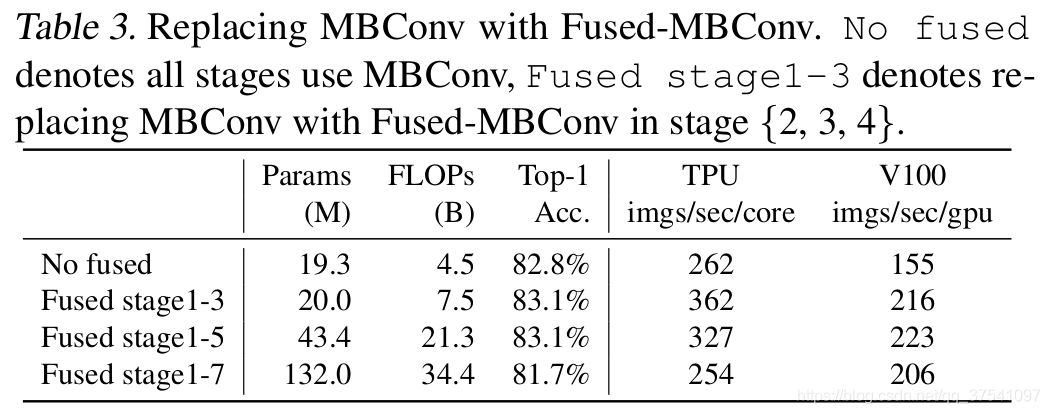
Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构(之前在将EfficientNetv1时有详细讲过)主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如表3所示,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。
- 同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
(2)EfficientNetV2中做出的贡献
在之前的一些研究中,大家主要关注的是准确率以及参数数量(注意,参数数量少并不代表推理速度更快)。但在近些年的研究中,大家开始关注网络的训练速度以及推理速度(可能是准确率刷不动了)。但他们提升训练速度通常是以增加参数数量作为代价的。而这篇文章是同时关注训练速度以及参数数量的。However, their training speed often comes with the cost of more paramters. This paper aims to significantly imporve both training and parameter efficiency than prior art.
这篇文章做出的三个贡献:
- 引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于先前的一些网络。
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如
dropout、data augmentation和mixup)。通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。 - 通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为1/6.8。
(3)NAS 搜索
这里采用的是trainning-aware NAS framework,搜索工作主要还是基于之前的Mnasnet以及EfficientNet。但是这次的优化目标联合了accuracy、parameter efficiency以及trainning efficiency三个维度。这里是以EfficientNet作为backbone,设计空间包含:
- convolutional operation type : {
MBConv,Fused-MBConv} - number of layer
- kernel size : {
3x3,5x5} - expansion ratio (
MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3): {1,4,6}
另外,作者通过以下方法来减小搜索空间的范围:
- 移除不需要的搜索选项,例如pooling skip操作(因为在EfficientNet中并没有使用到)
- 重用EfficientNet中搜索的channel sizes(需进一步补充)
接着在搜索空间中随机采样了1000个模型,并针对每个模型训练10个epochs(使用较小的图像尺度)。搜索奖励结合了模型准确率A,标准训练一个step所需时间S以及模型参数大小P,奖励函数可写成:
其中,w = − 0.07, v=-0.05。
(4)EfficientNetV2网络框架
表4展示了作者使用NAS搜索得到的EfficientNetV2-S模型框架(注意,在源码中Stage6的输出Channels是等于256并不是表格中的272,Stage7的输出Channels是1280并不是表格中的1792)。相比与EfficientNetV1,主要有以下不同:
- 第一个不同点在于EfficientNetV2中除了使用到
MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。 - 第二个不同点是EfficientNetV2会使用较小的
expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6. 这样的好处是能够减少内存访问开销。 - 第三个不同点是EfficientNetV2中更偏向使用更小(
3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过下表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。 - 最后一个不同点是移除了EfficientNetV1中最后一个步距为1的stage(就是EfficientNetV1中的stage8,不了解的可以看下我之前写的EfficientNetV1网络详解),可能是因为它的参数数量过多并且内存访问开销过大(由于网络是通过NAS搜索出来的,所有这里也是作者的猜测)。

通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
-
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN -
Fused-MBConv模块上面再讲EfficientNetV1存在问题章节有讲到过,模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,下面是我自己重绘的结构图,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。注意当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。具体可参考Deep Networks with Stochastic Depth这篇文章。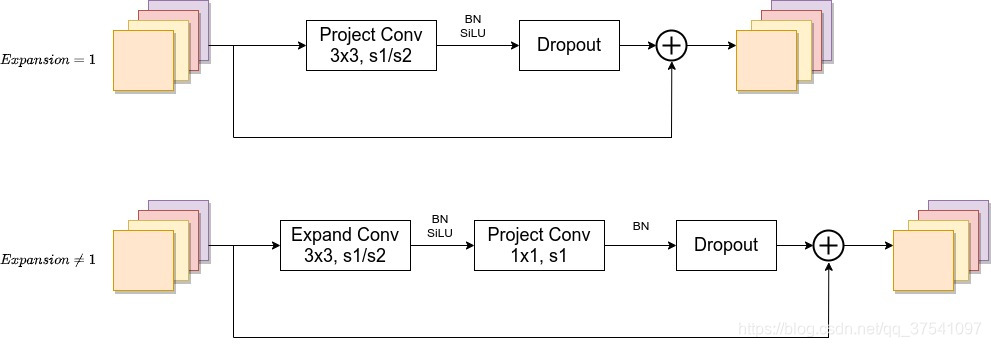
-
MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的1 4 \frac{1}{4}41详情可查看我之前的文章,下面是我自己重绘的MBConv模块结构图。注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。
Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,#Layers表示该Stage重复堆叠Operator的次数。
(4.1)EfficientNetV2-S的详细参数
首先在官方的源码中有个baseline config注意这个不是V2-S的配置,在efficientnetv2 -> effnetv2_configs.py文件中 。
#################### EfficientNet V2 configs ####################
v2_base_block = [ # The baseline config for v2 models.
'r1_k3_s1_e1_i32_o16_c1',
'r2_k3_s2_e4_i16_o32_c1',
'r2_k3_s2_e4_i32_o48_c1',
'r3_k3_s2_e4_i48_o96_se0.25',
'r5_k3_s1_e6_i96_o112_se0.25',
'r8_k3_s2_e6_i112_o192_se0.25',
]
EfficientNetV2-S的配置是在baseline的基础上采用了width倍率因子1.4, depth倍率因子1.8得到的(这两个倍率因子是EfficientNetV1-B4中采用的)。
v2_s_block = [ # about base * (width1.4, depth1.8)
'r2_k3_s1_e1_i24_o24_c1',
'r4_k3_s2_e4_i24_o48_c1',
'r4_k3_s2_e4_i48_o64_c1',
'r6_k3_s2_e4_i64_o128_se0.25',
'r9_k3_s1_e6_i128_o160_se0.25',
'r15_k3_s2_e6_i160_o256_se0.25',
]
为了方便理解,还是对照着表4来看(注意,在源码中Stage6的输出Channels是等于256并不是表格中的272,Stage7的输出Channels是1280并不是表格中的1792)。
上面给出的配置是针对带有Fused-MBConv或者MBConv模块的Stage,例如在EfficientNetV2-S中就是Stage1到Stage6. 每一行配置对应一个Stage中的信息。其中:
r代表当前Stage中Operator重复堆叠的次数k代表kernel_sizes代表步距stridee代表expansion ratioi代表input channelso代表output channelsc代表conv_type,1代表Fused-MBConv,0代表MBConv(默认为MBConv)se代表使用SE模块,以及se_ratio
比如r2_k3_s1_e1_i24_o24_c1代表,Operator重复堆叠2次,kernel_size等于3,stride等于1,expansion等于1,input_channels等于24,output_channels等于24,conv_type为Fused-MBConv。
源码中关于解析配置的方法如下:
def _decode_block_string(self, block_string):
"""Gets a block through a string notation of arguments."""
assert isinstance(block_string, str)
ops = block_string.split('_')
options = {}
for op in ops:
splits = re.split(r'(\d.*)', op)
if len(splits) >= 2:
key, value = splits[:2]
options[key] = value
return hparams.Config(
kernel_size=int(options['k']),
num_repeat=int(options['r']),
input_filters=int(options['i']),
output_filters=int(options['o']),
expand_ratio=int(options['e']),
se_ratio=float(options['se']) if 'se' in options else None,
strides=int(options['s']),
conv_type=int(options['c']) if 'c' in options else 0,
)
通过配置文件可知Stage0的卷积核个数是24(i24)
(4.2)EfficientNetV2-M的详细参数
EfficientNetV2-M的配置是在baseline的基础上采用了width倍率因子1.6, depth倍率因子2.2得到的(这两个倍率因子是EfficientNetV1-B5中采用的)。
v2_m_block = [ # about base * (width1.6, depth2.2)
'r3_k3_s1_e1_i24_o24_c1',
'r5_k3_s2_e4_i24_o48_c1',
'r5_k3_s2_e4_i48_o80_c1',
'r7_k3_s2_e4_i80_o160_se0.25',
'r14_k3_s1_e6_i160_o176_se0.25',
'r18_k3_s2_e6_i176_o304_se0.25',
'r5_k3_s1_e6_i304_o512_se0.25',
]
通过配置文件可知Stage0的卷积核个数是24(i24)
(4.3)EfficientNetV2-L的详细参数
EfficientNetV2-L的配置是在baseline的基础上采用了width倍率因子2.0, depth倍率因子3.1得到的(这两个倍率因子是EfficientNetV1-B7中采用的)。
v2_l_block = [ # about base * (width2.0, depth3.1)
'r4_k3_s1_e1_i32_o32_c1',
'r7_k3_s2_e4_i32_o64_c1',
'r7_k3_s2_e4_i64_o96_c1',
'r10_k3_s2_e4_i96_o192_se0.25',
'r19_k3_s1_e6_i192_o224_se0.25',
'r25_k3_s2_e6_i224_o384_se0.25',
'r7_k3_s1_e6_i384_o640_se0.25',
]
通过配置文件可知Stage0的卷积核个数是32(i32)
(4.4)EfficientNetV2其他训练参数
下面是源码中给出的配置信息,我们这里只简单看下efficientnetv2-s,efficientnetv2-m和efficientnetv2-l三个参数,其中的v2_s_block,v2_m_block以及v2_l_block就是上面刚刚讲到过的网络配置参数,剩下就关注下train_size, eval_size, dropout, randaug, mixup, aug即可。比如efficientnetv2-s的train_size=300(注意实际训练中train_size是会变化的,后面讲Progressive Learning中会细讲),eval_size=684,dropout=0.2,randaug=10,mixup=0,aug='randaug'.
efficientnetv2_params = {
# (block, width, depth, train_size, eval_size, dropout, randaug, mixup, aug)
'efficientnetv2-s': # 83.9% @ 22M
(v2_s_block, 1.0, 1.0, 300, 384, 0.2, 10, 0, 'randaug'),
'efficientnetv2-m': # 85.2% @ 54M
(v2_m_block, 1.0, 1.0, 384, 480, 0.3, 15, 0.2, 'randaug'),
'efficientnetv2-l': # 85.7% @ 120M
(v2_l_block, 1.0, 1.0, 384, 480, 0.4, 20, 0.5, 'randaug'),
'efficientnetv2-xl':
(v2_xl_block, 1.0, 1.0, 384, 512, 0.4, 20, 0.5, 'randaug'),
# For fair comparison to EfficientNetV1, using the same scaling and autoaug.
'efficientnetv2-b0': # 78.7% @ 7M params
(v2_base_block, 1.0, 1.0, 192, 224, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b1': # 79.8% @ 8M params
(v2_base_block, 1.0, 1.1, 192, 240, 0.2, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b2': # 80.5% @ 10M params
(v2_base_block, 1.1, 1.2, 208, 260, 0.3, 0, 0, 'effnetv1_autoaug'),
'efficientnetv2-b3': # 82.1% @ 14M params
(v2_base_block, 1.2, 1.4, 240, 300, 0.3, 0, 0, 'effnetv1_autoaug'),
}
(5)EfficientNetV2与其他模型训练时间对比
下图展示一系列模型在固定训练图像尺寸(注意,这里还没有使用渐进的学习策略)时训练每个step的时间以及最终的Accuracy曲线。通过下面曲线可以看到EfficientNetV2的训练速度更快,并且能够达到当前SOTA。
(6)Progressive Learning渐进学习策略
前面提到过,训练图像的尺寸对训练模型的效率有很大的影响。所以在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用很小的图像尺寸,后面再增大)来加速网络的训练,但通常会导致Accuracy降低。为什么会出现这种情况呢?作者提出了一个猜想:Accuracy的降低是不平衡的正则化unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。
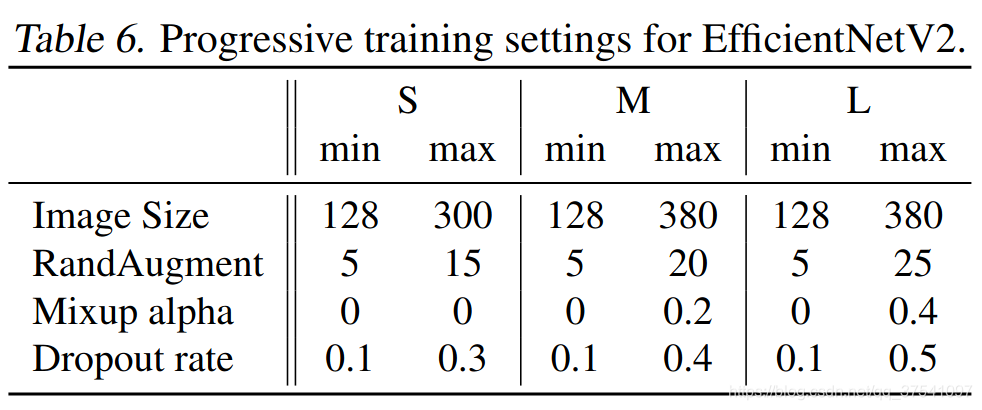
为了验证这个猜想,作者接着做了一些实验。在前面提到的搜索空间中采样并训练模型,训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强data augmentations。当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。如下表所示,当Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好:

基于以上实验,作者就提出了渐进式训练策略Progressive Learning。如下图所示,在训练早期使用较小的训练尺寸以及较弱的正则方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法adding stronger regularization。这里所说的regularization包括dropout rate,RandAugment magnitude以及mixup ratio。

接着作者将渐进式学习策略抽象成了一个公式来设置不同训练阶段使用的训练尺寸以及正则化强度。假设整个训练过程有步,目标训练尺寸(最终训练尺度)是
,正则化列表(最终正则强度)
,其中
代表
种正则方法(刚刚说了,有Dropout、RandAugment以及Mixup三种)。初始化训练尺寸
,初始化正则化强度为
。接着将整个训练过程划分成
个阶段,对于第
个阶段(
)模型的训练尺寸为
,正则化强度为
。对于不同阶段直接使用线性插值的方法递增。具体流程如下:

下表给出了EfficientNetV2(S,M,L)三个模型的渐进学习策略参数:
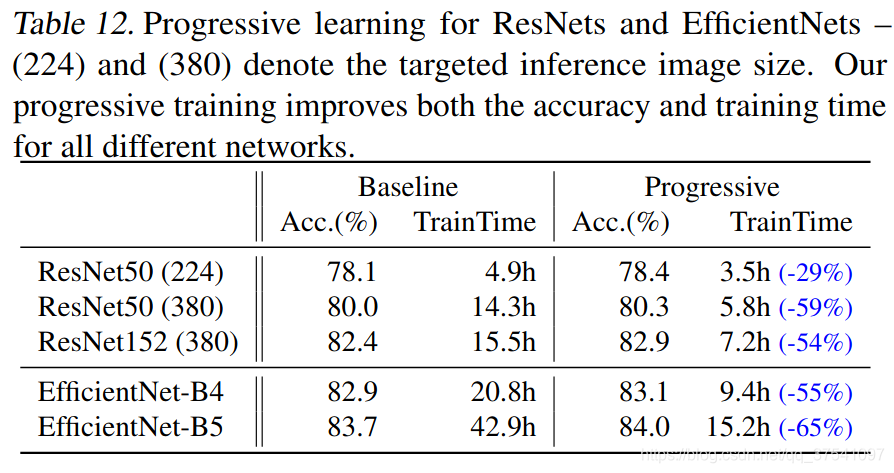
通过以上策略作者在表7中列出了一大堆模型的训练对比,由于表格太大了这里就不展示了,想看的自己翻下原文。通过对比可以看出使用渐进式学习策略确实能够有效提升训练速度。为了进一步验证渐进式学习策略的有效性,作者还在Resnet以及EfficientNetV1上进行了测试,如下表所示,使用了渐进式学习策略后确实能够有效提升训练速度并且能够小幅提升Accuracy。
讲到这,文章的大致内容就讲完了,更多详细细节建议大家仔细去阅读原论文。
11 Darknet系列
11.1 Darknet-19 (2016, YOLO v2 的 backbone)
作者:Joseph Redmon
Paper 原文: YOLO9000: Better, Faster, Stronger
网络结构:
Darknet-19 是 YOLO v2 的 backbone。Darknet-19 总共有 19 层 conv 层, 5 个 maxpooling 层。Darknet-19 吸收了 VGG16, NIN 等网络的优点,网络结构小巧,但是性能强悍。
具体的网络结构参考下图。

可以看到, Darknet-19 的 stride 为32,没有 fc 层,而是用了 Avgpool。
性能:
下图截取自 Darknet 官网。可以看到 Darknet-19 的性能基本与 Resnet34 差不多。
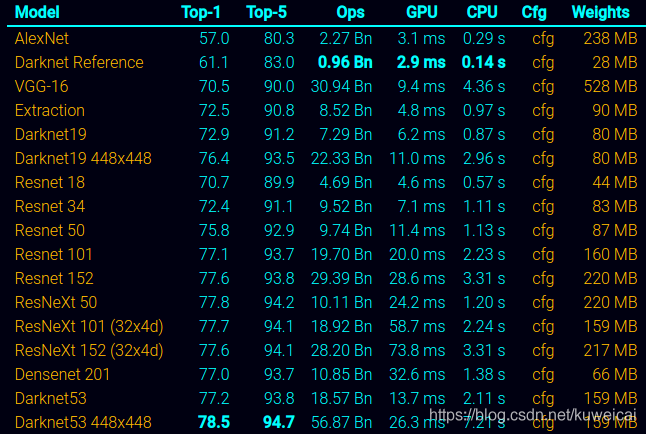
11.2 Darknet-53 (2018, YOLOv3的 backbone)
作者:Joseph Redmon
Paper 原文: YOLOv3: An Incremental Improvement
Darknet-53 是 YOLOv3 的 backbone。具体结构参考下面的图片。左侧是 Darknet-53 的完整结构图,右侧是对左侧中的 “Convolutional” 层 和 “Residual” 层的细节展示。显然 Darknet-53 借鉴了 Resnet 的设计思想,引入了 shotcut 的概念。
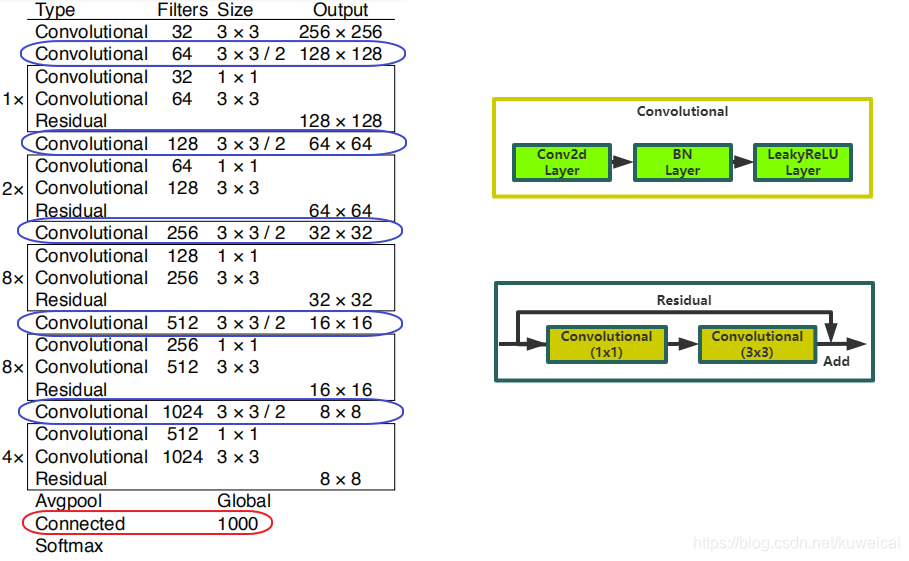
Darknet-53 顾名思意,总共有 53 个卷积层,但是上面的结构中只看到 52 个卷积层,其实 最后的 “Connected” 层也是卷积层(1×1 的卷积实现的类似 fc 的效果,所以也有资料把它称做 fc 层),“Connected” 层的具体参数如下。
[convolutional]
filters=1000
size=1
stride=1
pad=1
activation=linear
Darknet-53 输入 image size 为 256(没有 fc 层,显然可以随意修改输入 size),最后得到的 feature map size 为 8×8,stride 为 32(值得注意的是 5 次下采样,都不是通过 pooling 做的,而是通过 stride 为 2 的卷积层实现的,上图中蓝色框标出的位置,darknet-19 中是通过 max pooling)。
(2)性能
论文中给出的 Darknet-53 的性能接近 ResNet-152,但是 FPS 要高一倍。

12 DLA (2018, Deep Layer Aggregation)
论文下载: https://arxiv.org/pdf/1707.06484.pdf
论文代码: https://github.com/ucbdrive/dla
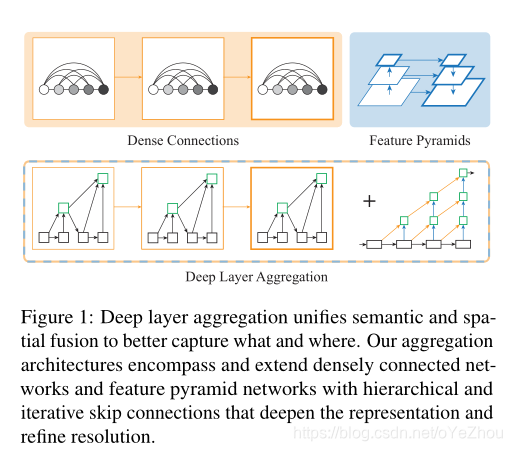
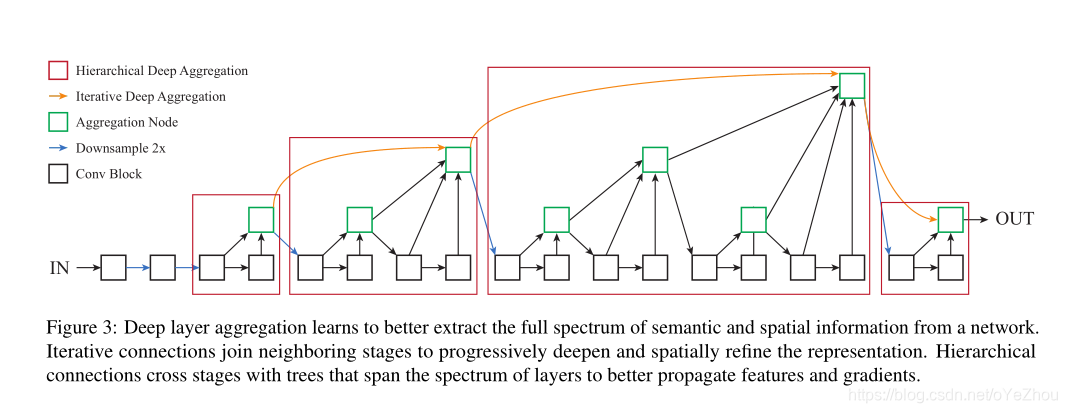
DLA是一种融合深层网络的backbone结构,通过更深层次的融合可以更好的聚合不同层的信息,深层聚合结构以迭代和分层方式合并特征层次结构,使网络具有更高的准确性和更少的参数。
采用的聚合结构和现有的特征融合结构最为类似。融合主要从空间和语义两个维度上进行。语义融合,或者说在通道和深度方向上的聚合,能够提高推断“是什么”的能力。而空间信息的融合,或者说在分辨率和尺度上的聚合,可以提高推断“在哪儿”的能力。DLA可以看作是这两种融合的组合技术。
DenseNets是语义融合网络的最具代表性的网络,设计思路为,采用将不同层级之间的特征通过skip connection级联在一起,来达到更好地传播特征与损失的目的。本文采用的HDA技术采用了类似的思想,重视短路径的应用和复用。并且将skip connection跳跃连接构造了跨越各个层级树状连接结构,从而达到了比一般级联更深的融合效果。稠密连接和深度聚合实现了更高的精度的同时,保证了更有效率的内存利用和参数利用(换句话说就是网络里的参数都是有用的)。
FPN网络是空间融合网络中最具有代表性的网络,设计思路为,通过自上而下和横向的连接,来获取更均一化的分辨率和标准化的语义信息。本文所采用的深度聚合技术同样在分辨率尺度下作用,此外通过更强非线性和更激进的函数加深了表征提取。线性并且浅层的FPN连接并不能改善它们语义方面的弱点。金字塔式和深度聚合网络,对于结构化的识别任务,可以更好地解析出“在哪儿”和“是什么”。
思考:语义融合与空间融合的区别:
语义融合:
- 融合的是不同层级间的通道内信息;
- 通道大多在通道数上不同,空间尺度上相同,不需要尺度对齐;
- 主要保留微观信息;
空间融合:
- 融合的是不同层级间的特征图信息;
- 通道数是相同的,空间尺度上等比缩放,需要尺度对齐。也就是文中所说的均一化和标准化;
- 主要保留宏观信息;
1、动机
大多CNN backbone的探索方向都集中在bottlenecks、residual、gated、特征拼接等方面。从LeNet、AlexNet、VGG的plain网络到ResNet的残差连接都是对层或者模块的堆叠,这些都没有利用不同层之间的深度融合。
因此,DLA主要探索了如何聚合不同层以更好地融合语义和空间信息来进行识别和定位,主要包括两种聚合方式:迭代深度聚合( iterative deep aggregation, IDA)和层次深度聚合( hierarchical deep aggregation, HDA)。IDA专注于聚合不同分辨率和尺度的特征,HDA专注于融合不同层和模块。
DLA聚合方式受到了DenseNet和FPN的影响,如图1所示:
2、方法
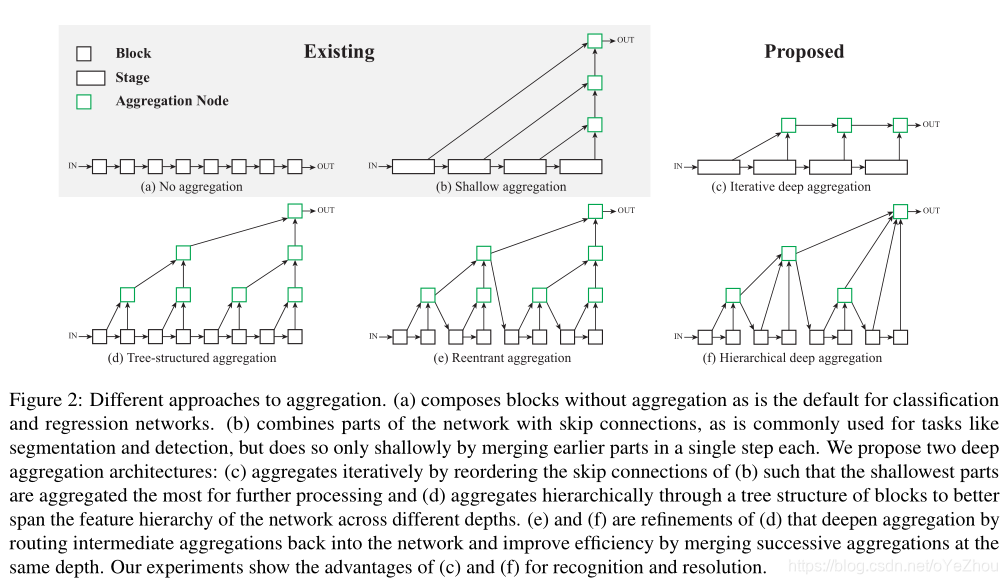
目前已有的方法和所提出的DLA相关聚合方法示意如图2所示:
上图中:
- (a)是没有聚合的plain模型;
- (b)是比较浅的聚合,仅通过跳跃连接聚合部分层,这种方式常见于语义分割、目标检测,但由于只进行了一步聚合,所以这种方式融合的信息还不够深;
- (c)即为IDA,是对(b)中的聚合方式重排列,以迭代方式进行特征融合,最浅的层被融合的次数最多;
- (d)通过块的树状结构分层聚合,以更好地跨不同深度跨越网络的特征层次;
- (e)和(f)是(d)的细化,通过将中间聚合结果与原网络中的结点再次融合来深化聚合,并对相同深度的聚合结点进行合并以提高效率;
(1)IDA
IDA是沿着backbone结构中的堆叠进行迭代聚合的。其将原网络按照不同分辨率分为不同的stage,然后从最浅层开始迭代式聚合,逐渐到达更深层,其聚合规模也越来越大,如图2(c)。按照这种方式,较浅层的特征传播到了不同的stage,并通过聚合不断细化。IDA的聚合公式为:
(1)
(2)HDA
HDA是将不同的块和stage合并到一个树状结构中,以保存、合并特征通道。HDA将更浅、更深的层结合起来,学习到更丰富的组合,跨越了更多特征层级。而IDA仍是连续的融合方式,对于整个网络来说,其融合力度还不够。但是,加上HDA之后,就可以改进融合的深度和效率。HDA不光向上聚合到上层结点,还向下聚合了backbone本身的块或stage,如图2(e)。这种将聚合块作为传播对象而不是将之前的块单独作为传播对象的方式,可以更好的保存特征。此外,为了更加高效,将父结点和左孩子结点作为相同深度进行了融合,如图2(f)。
HDA的聚合公式为:
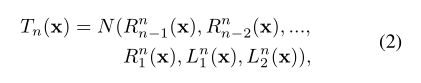
其中,分别为:
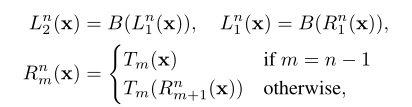
2.3、网络结构
利用IDA和HDA,可以得到DLA的整体架构:
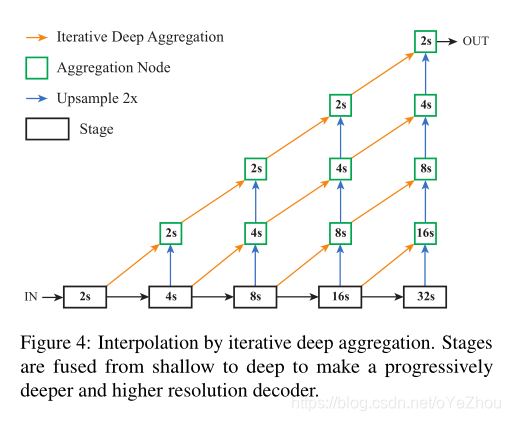
上图为DLA的分类架构,如果用于密集预测任务,如语义分割,则可以利用IDA进行上采样,形成一个decoder(即为IDA_UP):
针对不同的深度、参数量,DLA有九种变种:
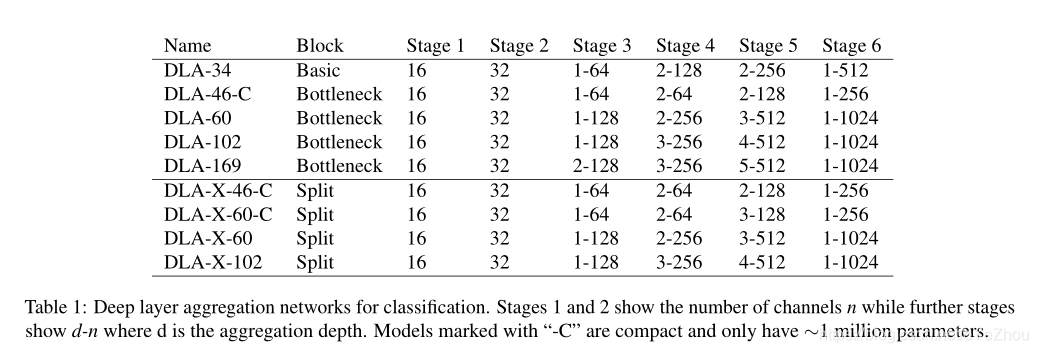
二、轻量化CNNs结构Backbone
1. SqueezeNet:(2016)
https://arxiv.org/abs/1602.07360
从LeNet5到DenseNet,反应卷积网络的一个发展方向:提高精度。这里我们开始另外一个方向的介绍:在大幅降低模型精度的前提下,最大程度的提高运算速度。
提高运算所读有两个可以调整的方向:
减少可学习参数的数量;
减少整个网络的计算量。
这个方向带来的效果是非常明显的:
减少模型训练和测试时候的计算量,单个step的速度更快;
减小模型文件的大小,更利于模型的保存和传输;
可学习参数更少,网络占用的显存更小。
SqueezeNet正是诞生在这个环境下的一个精度的网络,它能够在ImageNet数据集上达到AlexNet[2]近似的效果,但是参数比AlexNet少50倍,结合他们的模型压缩技术 Deep Compression[3],模型文件可比AlexNet小510倍。
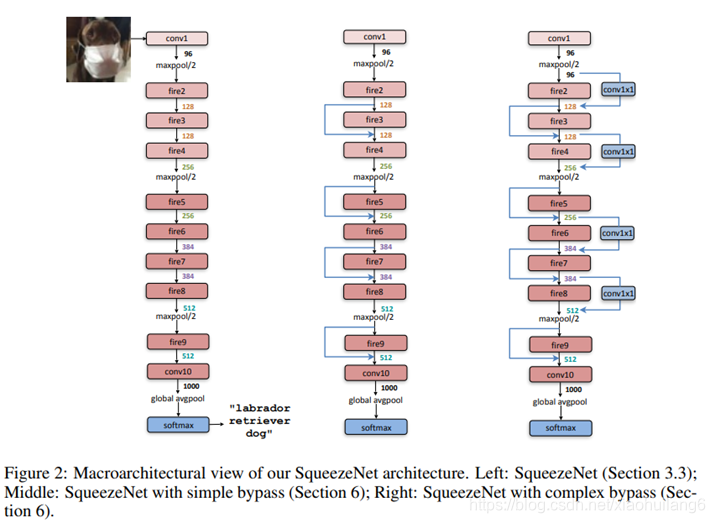
Fire模块
• 激活函数默认都使用 ReLU ;
• fire9 之后接了一个 rate 为 0.5 的 dropout ;
• 使用 same 卷积。
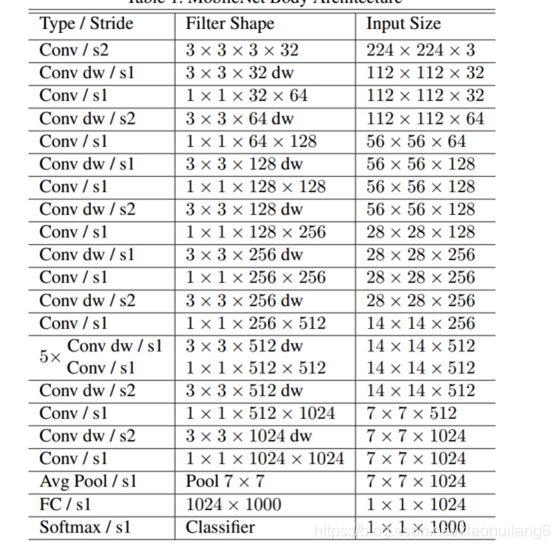
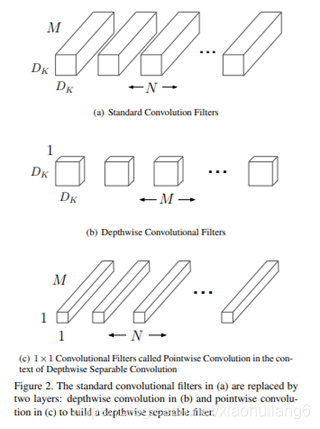
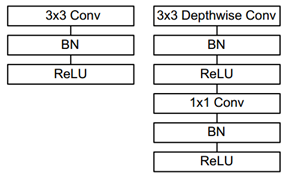
2. MobileNet-v1:(2017)
https://arxiv.org/abs/1704.04861
深度可分离卷积(depthwise separable convolution)。
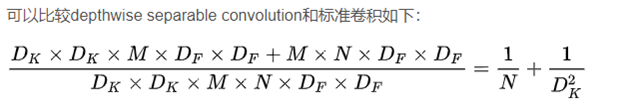
3. XCeption:(2017, 极致的 Inception)
https://arxiv.org/abs/1610.02357
同一向复杂的Inception系列模型一样,它也引入了Entry/Middle/Exit三个flow,每个flow内部使用不同的重复模块,当然最最核心的属于中间不断分析、过滤特征的Middel flow。
Entry flow主要是用来不断下采样,减小空间维度;中间则是不断学习关联关系,优化特征;最终则是汇总、整理特征,用于交由FC来进行表达。
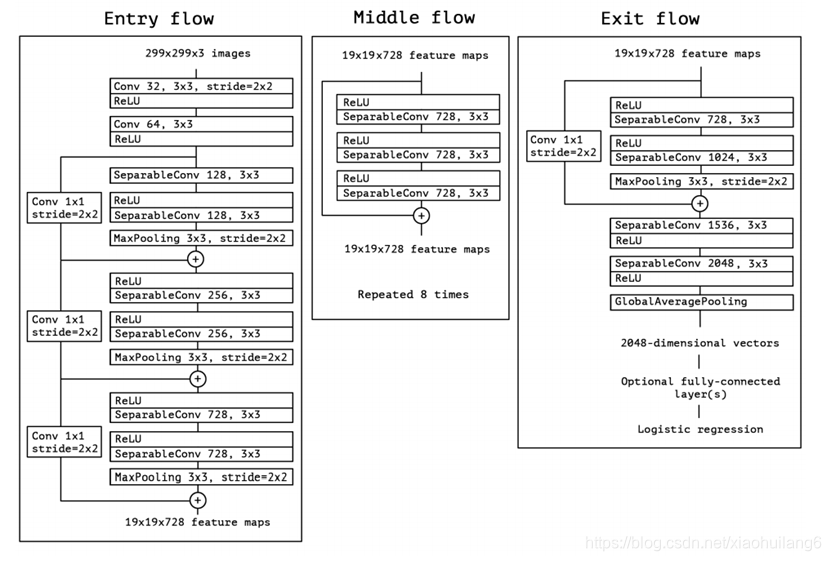
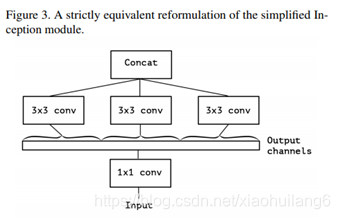
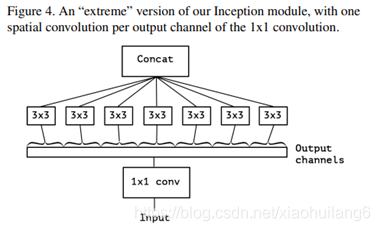
严格版本:每个通道深度可分离卷积
depthwise separable convolution深度可分离卷积
4. MobileNet V2:(2018)
https://openaccess.thecvf.com/content_cvpr_2018/papers/Sandler_MobileNetV2_Inverted_Residuals_CVPR_2018_paper.pdf
在使用V1的时候,发现depthwise部分的卷积核容易费掉,即卷积核大部分为零。作者认为这是ReLU引起的。
当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大,如下图所示。因此,认为对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少。另外一种解释是,高维信息变换回低维信息时,相当于做了一次特征压缩,会损失一部分信息,而再进过relu后,损失的部分就更加大了。作者为了这个问题,就将ReLU替换成线性激活函数。
Inverted Residuals
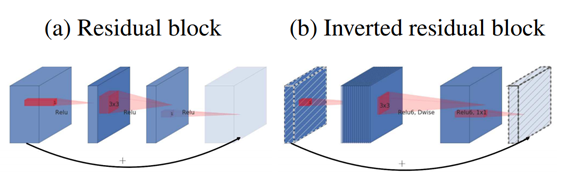
• 残差模块:输入首先经过 1*1 的卷积进行压缩,然后使用 3*3 的卷积进行特征提取,最后在用 1*1 的卷积把通道数变换回去。整个过程是“ 压缩 – 卷积 – 扩张” 。这样做的目的是减少 3*3 模块的计算量,提高残差模块的计算效率。
• 倒残差模块:输入首先经过 1*1 的卷积进行通道扩张,然后使用 3*3 的 depthwise 卷积,最后使用 1*1 的 pointwise 卷积将通道数压缩回去。整个过程是“ 扩张 – 卷积 – 压缩 ”。为什么这么做呢?因为 depthwise 卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为 6 。
Linear Bottleneck
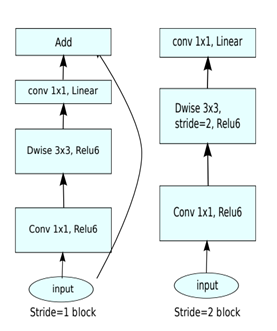
将最后一层的ReLU替换成线性激活函数,而其他层的激活函数依然是ReLU6。
5. ShuffleNet-v1:(2018)
https://arxiv.org/pdf/1707.01083.pdf
将密集的1×1卷积替换成1×1的group convolution,不过在第一个1×1卷积之后增加了一个channel shuffle操作。值得注意的是3×3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3×3的depthwise convolution之后没有使用ReLU激活函数。
下图c展示了其他改进,对原输入采用stride=2的3×3 avg pool,在depthwise convolution卷积处取stride=2保证两个通路shape相同,然后将得到特征图与输出进行连接(concat,借鉴了DenseNet?),而不是相加。极致的降低计算量与参数大小。
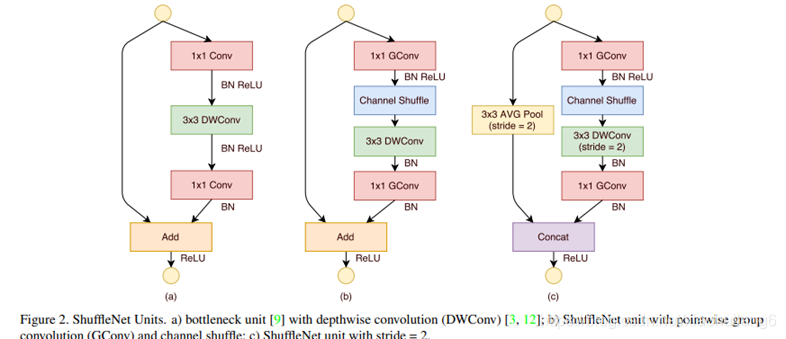
6. ShuffleNet-v2:(2018)
https://arxiv.org/abs/1807.11164v1
卷积层的输入和输出特征通道数相等时MAC最小,此时模型速度最快
过多的group操作会增大MAC,从而使模型速度变慢
模型中的分支数量越少,模型速度越快
element-wise操作所带来的时间消耗远比在FLOPs上的体现的数值要多,因此要尽可能减少element-wise操作
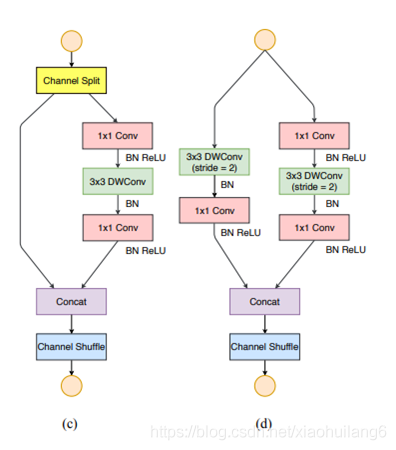
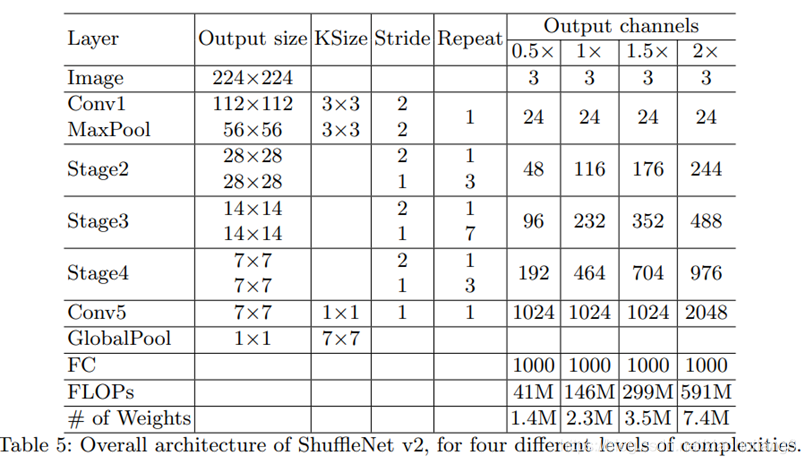
7. MnasNet:(2019)
https://arxiv.org/pdf/1807.11626v1.pdf
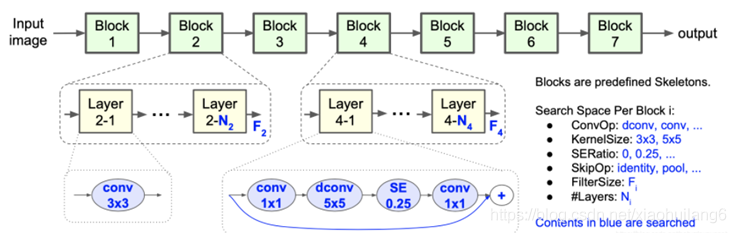
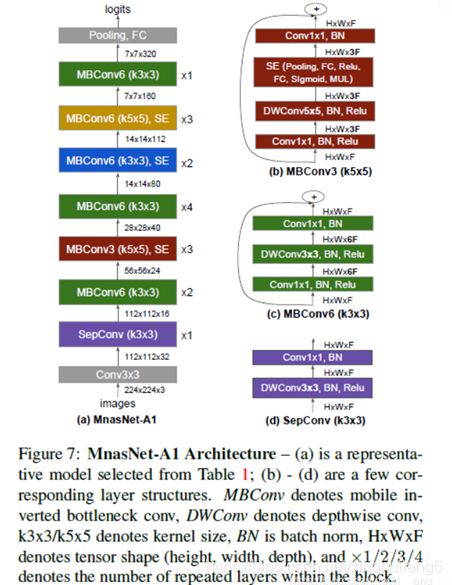
在搜索方法上,作者沿用了NASNet的强化学习方法,利用controller RNN去预测layer的六种搜索对象类型。MnasNet给强化学习的reward不只是验证集的精度Accuracy而已,还增加了latency的约束。reward的目标函数为

按照准确率提升5%,延时变成2倍的tradeoff原则,上面公式可变换为:
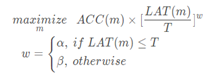 其中,α = β = − 0.07
其中,α = β = − 0.07
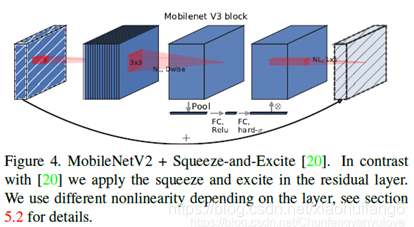
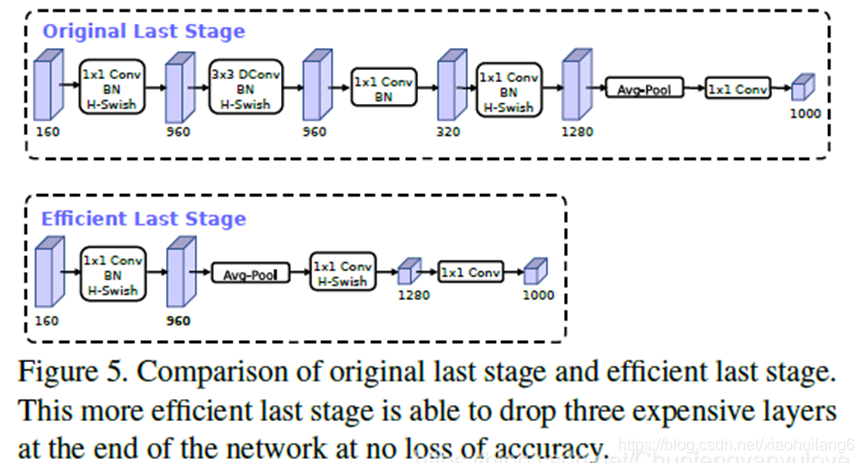
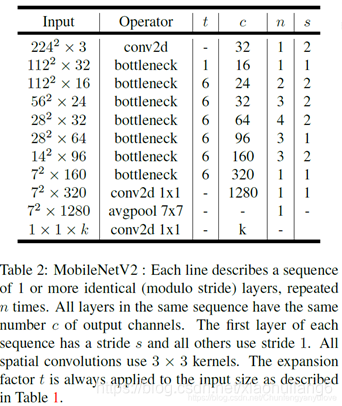
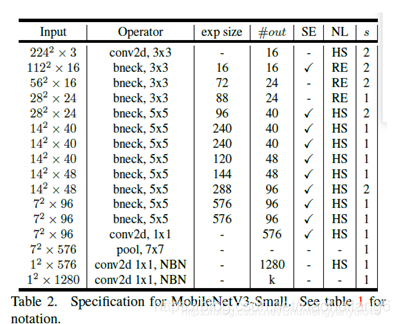
8. MobileNet V3 (2019)
https://ieeexplore.ieee.org/document/9008835/
mobilenet-v3是Google继mobilenet-v2之后的又一力作,作为mobilenet系列的新成员,自然效果会提升,mobilenet-v3提供了两个版本,分别为mobilenet-v3 large 以及mobilenet-v3 small,分别适用于对资源不同要求的情况,论文中提到,mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%,mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%,同时在分割算法上也有一定的提高。本文还有一个亮点在于,网络的设计利用了NAS(network architecture search)算法以及NetAdapt algorithm算法。并且,本文还介绍了一些提升网络效果的trick,这些trick也提升了不少的精度以及速度。
1.mobilenetv2+SE结构
2.修改尾部结构:
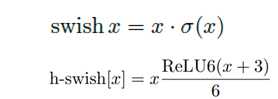
3.修改channel数量
9. CondenseNet(2017)
论文:CondenseNet: An Efficient DenseNet using Learned Group Convolutions
链接:https://arxiv.org/abs/1711.09224
代码地址:GitHub – ShichenLiu/CondenseNet: CondenseNet: Light weighted CNN for mobile devices(PyTorch)
DenseNet基于特征复用,能够达到很好的性能,但是论文认为其内在连接存在很多冗余,早期的特征不需要复用到较后的层。为此,论文基于可学习分组卷积提出CondenseNet,能够在训练阶段自动稀疏网络结构,选择最优的输入输出连接模式,并在最后将其转换成常规的分组卷积分组卷积结构。
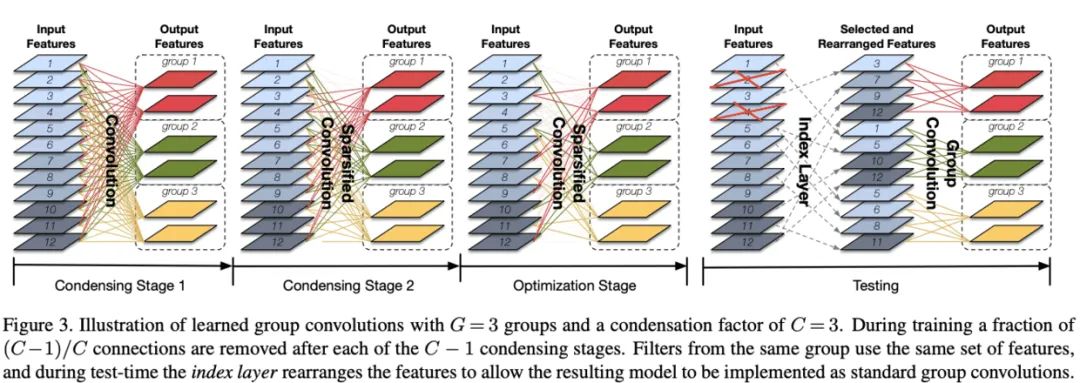
分组卷积的学习包含多个阶段,前半段训练过程包含多个condensing阶段,结合引导稀疏化的正则化方法来反复训练网络,然后将不重要的filter剪枝。后半部分为optimization阶段,这个阶段对剪枝固定后的网络进行学习。
10.ESPNet系列
ESPNet系列的核心在于空洞卷积金字塔,每层具有不同的dilation rate,在参数量不增加的情况下,能够融合多尺度特征,相对于深度可分离卷积,深度可分离空洞卷积金字塔性价比更高。另外,HFF的多尺度特征融合方法也很值得借鉴 。
10.1 ESPNet (2018)
《ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation》
Paper:https://arxiv.org/abs/1803.06815v2
Github:https://github.com/sacmehta/ESPNet
(1)引入
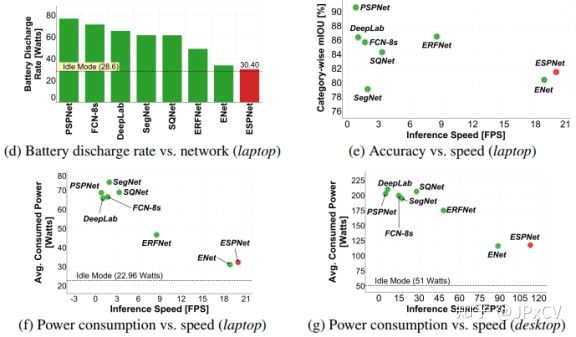
ESPNet被设计为在资源限制的高分辨率图片的快速语义分割,ESPNet是基于一个新的卷积模块:高效空间金字塔(ESP), 在计算内存和功耗上都很高效,ESPnet 比PSPnet 在GPU上快了22倍,文件缩小为180倍,同时只有8%的精度损失。ESPNet在cityscapes、 pascalVOC和其他的数据集上验证,在相同的内存和计算条件下, 在标准度量标准和新引入的性能度量标准中(度量边缘设备的效率),ESPNet优于所有当前的高效CNN网络,比如mobilenet,shufflenet和ENet。ESPNet处理cityscape高分辨率图片,NVIDIA TitanX GPU上112帧, 在TX2为9帧。ESPNet快速、小型、低功耗、低延迟 保证了分割精度的网络。
ESPNet基于卷积因子分解的原则(如下图),基于ESP模块的ESPNet可以很容易的采用到资源约束的终端设备。
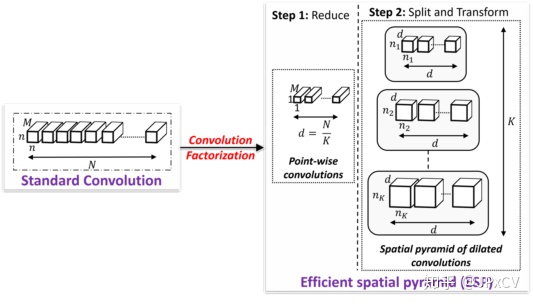
(2)ESP模块
基于卷积因子分解的原则解析标准卷积的两个步骤:
(1) point-wise convolutions 逐点卷积
(2) spatial pyramid of dilated convolutions 扩张卷积的空间金字塔
step1:对输入通道为M,卷积因子数为K,输入做1×1的卷积降维,通道d=M/K;
Step2:之后进入分组并行扩张卷积,空洞率和输出通道数如下pytorch代码:
n = int(nOut/5)
n1 = nOut - 4*n
self.c1 = C(nIn, n, 1, 1)
self.d1 = CDilated(n, n1, 3, 1, 1) # dilation rate of 2^0
self.d2 = CDilated(n, n, 3, 1, 2) # dilation rate of 2^1
self.d4 = CDilated(n, n, 3, 1, 4) # dilation rate of 2^2
self.d8 = CDilated(n, n, 3, 1, 8) # dilation rate of 2^3
self.d16 = CDilated(n, n, 3, 1, 16) # dilation rate of 2^4ESP通过逐点卷积核空间金字塔空洞卷积重采样特征图,提供了不同感受野尺度下的局部与全局语义信息,有利于像素点的类别划分;
并行扩张卷积运算有利于GPU加速。
(3)HFF模块
由ESP模块,得到不同空洞率下的特征图,HFF(Hierarchical feature fusion)模块为ESPNet的融合机制,如下图所示。
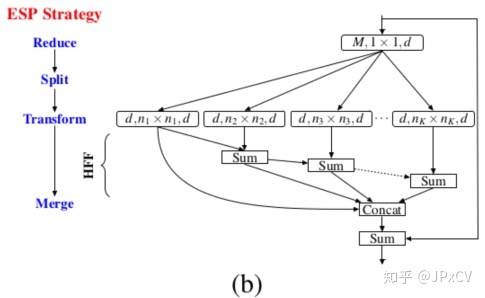
众所周知,空洞卷积的不合理使用会导致网格伪影,ESP使用大空洞率的堆叠卷积结构也容易形成伪影,论文采用HFF分层特征融合的方式,丰富了空洞卷积的使用方式,有效降低伪影的形成。
空洞核最小(n1xn1)的特征图直接输出,空洞核(n2xn2)特征图作为残差与之前输出求和作为输出,后续特征图类似此操作得到不同空洞率的融合特征,然后拼接起来,之后与原输入构成残差。
总之,HFF通过残差的方式的限制保证了输出的质量,拼接不同层特征图,保留局部细节与全局语义特征;
HFF结构允许较大空洞率卷积核的使用,加速了语义特征的提取;
HFF的融合方式:融合的特征图是通过逐层递进方式得到,与下次的空洞率卷积结果作残差的操作是否太多突兀。
(4)网络结构:
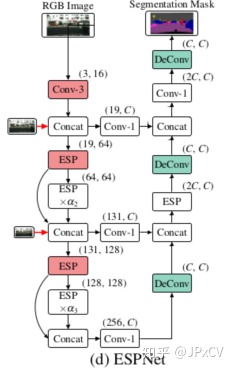
添加decoder构成语义分割的网络结构,decoder类似UNet采用逐层上采样,跳跃连接,恢复细节信息,由于残差计算的融合方式,使用PRelu激活函数,最后接softmax进行网络训练。
(5)Cityscape结果

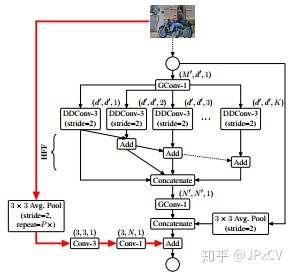
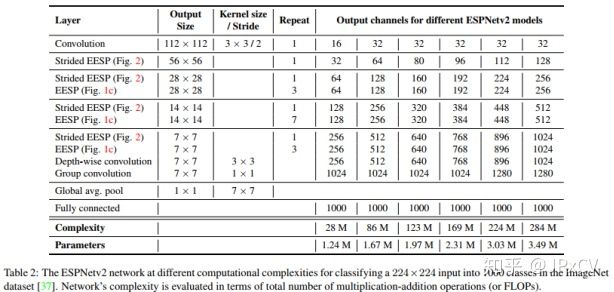
10.2 ESPNetv2 (2018)
ESPNetv2: A Light-weight, Power Efficient, and General Purpose Convolutional Neural Network
Paper:https://arxiv.org/abs/1811.11431?context=cs
Github:https://github.com/sacmehta/ESPNetv2
(1)引入
ESPNetv2是一种轻量级、能耗高效、通用的卷积神经网络,利用分组卷积核深度空洞分离卷积学习巨大有效感受野,更少浮点计算量和参数量。ESPNetv2具有3.5M参数量和284M FLOPS,ImageNet分类top-1准确率72.1%。
相比于标准空洞卷积,深度分离空洞卷积DDConv分两步:
I、对每个输入通道执行空洞率为r的DDConv,从有效感受野学习代表性特征;
II、标准1×1卷积学习DDConv输出的线性组合特征。
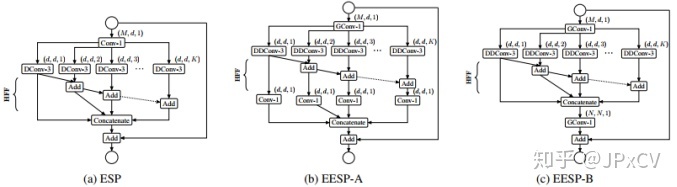
(2)EESP unit
如上图(b)所示,相比于ESPNet,输入reduce层采用分组卷积,DDConv+conv1x1取代标准空洞卷积,依然采用HFF的融合方式,(c)是(b)的等价模式。当输入通道数M=240, g=K=4, d=M/K=60,EESP比ESP少7倍的参数。
Strided EESP: shortcut执行avgpool降采样,并连接两个卷积操作,残差模块空洞分离卷积stride=2,如下图所示。
(3)网络结构
作者认为太大的空洞率可能对结果的贡献并不大,设置K=4,空洞率[1,2,3,4]
11. ChannelNets

论文提出channel-wise卷积的概念,将输入输出维度的连接进行稀疏化而非全连接,区别于分组卷积的严格分组,以类似卷积滑动的形式将输入channel与输出channel进行关联,能够更好地保留channel间的信息交流。基于channel-wise卷积的思想,论文进一步提出了channel-wise深度可分离卷积,并基于该结构替换网络最后的全连接层+全局池化的操作,搭建了ChannelNets。
12. PeleeNet
基于DenseNet的稠密连接思想,论文通过一系列的结构优化,提出了用于移动设备上的网络结构PeleeNet,并且融合SSD提出目标检测网络Pelee。从实验来看,PeleeNet和Pelee在速度和精度上都是不错的选择。
13. IGC系列
IGC系列网络的核心在分组卷积的极致运用,将常规卷积分解成多个分组卷积,能够减少大量参数,另外互补性原则和排序操作能够在最少的参数量情况下保证分组间的信息流通。但整体而言,虽然使用IGC模块后参数量和计算量降低了,但网络结构变得更为繁琐,可能导致在真实使用时速度变慢。
13.1 IGCV1
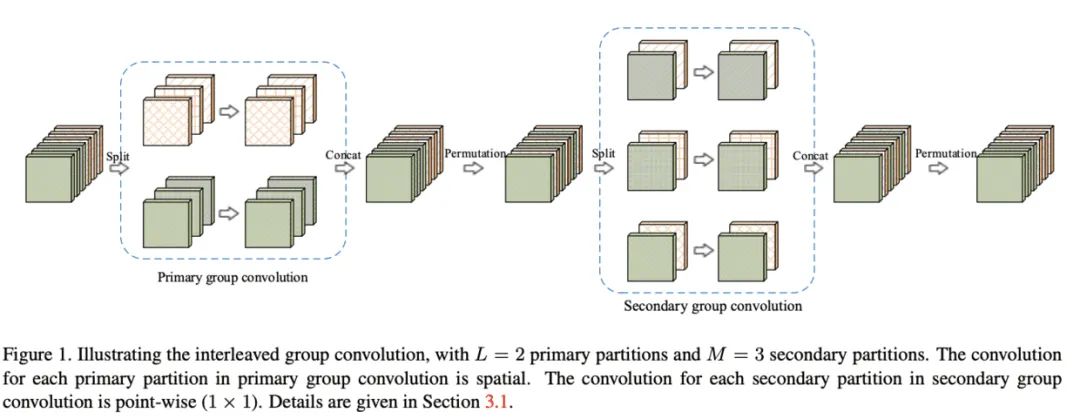
Interleaved group convolution(IGC)模块包含主分组卷积和次分组卷积,分别对主分区和次 分区进行特征提取, 主分区通过输入特征分组获得, 比如将输入特征分为 个分区, 每个分区 包含 维特征,而对应的次分区则分为 个分区, 每个分区包含 维特征。主分组卷积负责对输入特征图进行分组特征提取, 而次组卷积负责对主分组卷积的输出进行融合, 为 卷 积。IGC模块形式上与深度可分离卷积类似,但分组的概念贯穿整个模块, 也是节省参数的关键,另外模块内补充了两个排序模块来保证channel间的信息交流。
13.2 IGCV2

IGCV1通过两个分组卷积来对原卷积进行分解,减少参数且保持完整的信息提取。但作者发现,因为主分组卷积和次分组卷积在分组数上是互补的,导致次卷积的分组数一般较小,每个分组的维度较大,次卷积核较为稠密。为此,IGCV2提出Interleaved Structured Sparse Convolution,使用多个连续的稀疏分组卷积来替换原来的次分组卷积,每个分组卷积的分组数都足够多,保证卷积核的稀疏性。
13.3 IGCV3
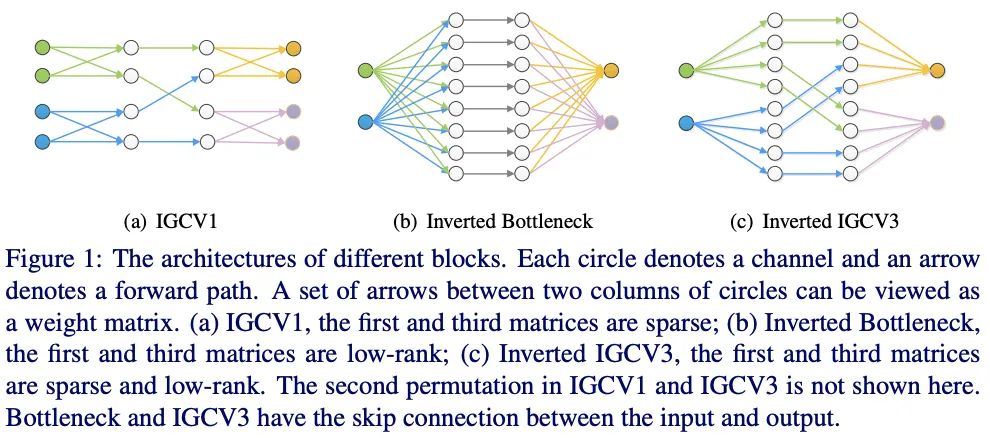
基于IGCV和bootleneck的思想,IGCV3结合低秩卷积核和稀疏卷积核来构成稠密卷积核,如图1所示,IGCV3使用低秩稀疏卷积核(bottleneck模块)来扩展和输入分组特征的维度以及降低输出的维度,中间使用深度卷积提取特征,另外引入松弛互补性原则,类似于IGCV2的严格互补性原则,用来应对分组卷积输入输出维度不一样的情况。
14 FBNet系列
FBNet系列是完全基于NAS搜索的轻量级网络系列,分析当前搜索方法的缺点,逐步增加创新性改进,FBNet结合了DNAS和资源约束,FBNetV2加入了channel和输入分辨率的搜索,FBNetV3则是使用准确率预测来进行快速的网络结构搜索。
14.1 FBNet
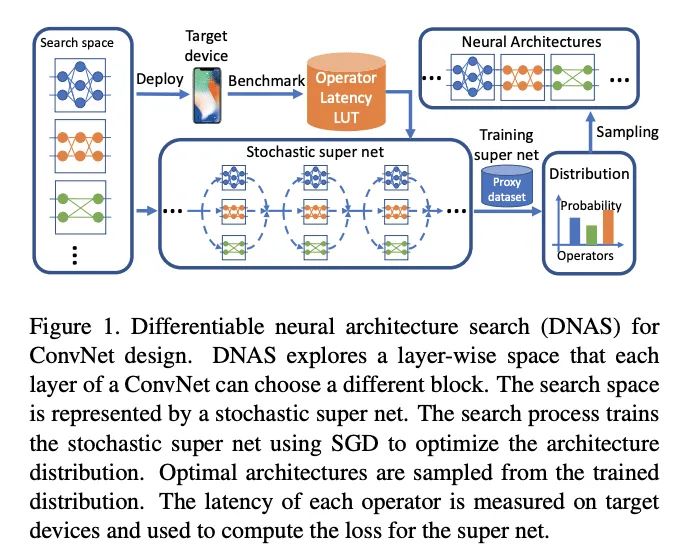
论文提出FBNet,使用可微神经网络搜索(DNAS)来发现硬件相关的轻量级卷积网络,流程如图1所示。DNAS方法将整体的搜索空间表示为超网,将寻找最优网络结构问题转换为寻找最优的候选block分布,通过梯度下降来训练block的分布,而且可以为网络每层选择不同的block。为了更好地估计网络的时延,预先测量并记录了每个候选block的实际时延,在估算时直接根据网络结构和对应的时延累计即可。
14.2 FBNetV2
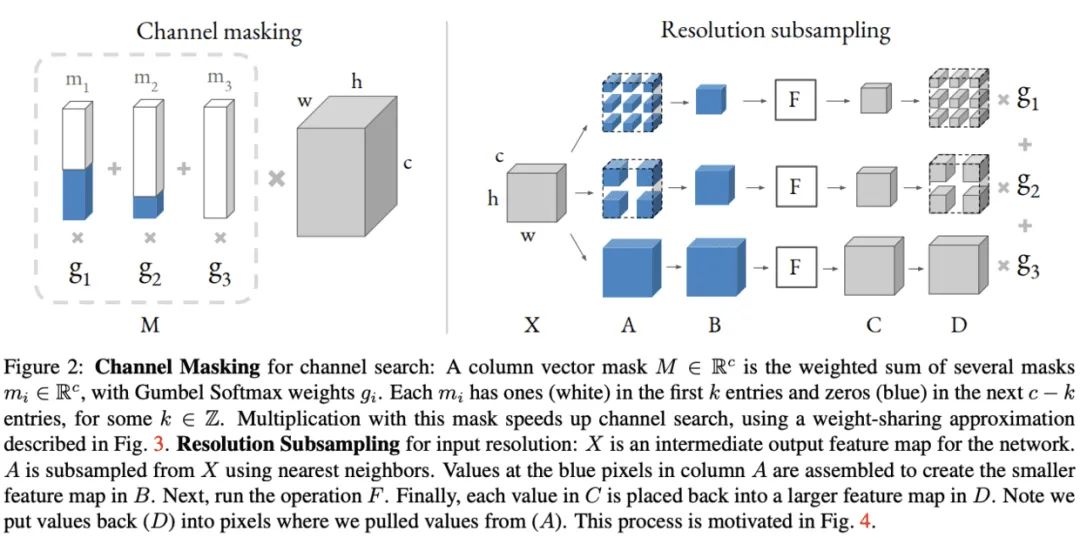
DNAS通过训练包含所有候选网络的超网来采样最优的子网,虽然搜索速度快,但需要耗费大量的内存,所以搜索空间一般比其它方法要小,且内存消耗和计算量消耗随搜索维度线性增加。为了解决这个问题,论文提出DMaskingNAS,将channel数和输入分辨率分别以mask和采样的方式加入到超网中,在带来少量内存和计算量的情况下,大幅增加 倍搜索空间。
14.3 FBNetV3

论文认为目前的NAS方法大都只满足网络结构的搜索,而没有在意网络性能验证时的训练参数的设置是否合适,这可能导致模型性能下降。为此,论文提出JointNAS,在资源约束的情况下,同时搜索最准确的训练参数以及网络结构。FBNetV3完全脱离了FBNetV2和FBNet的设计,使用的准确率预测器以及基因算法都已经在NAS领域有很多应用,主要亮点在于将训练参数加入到了搜索过程中,这对性能的提升十分重要。
15. GhostNet
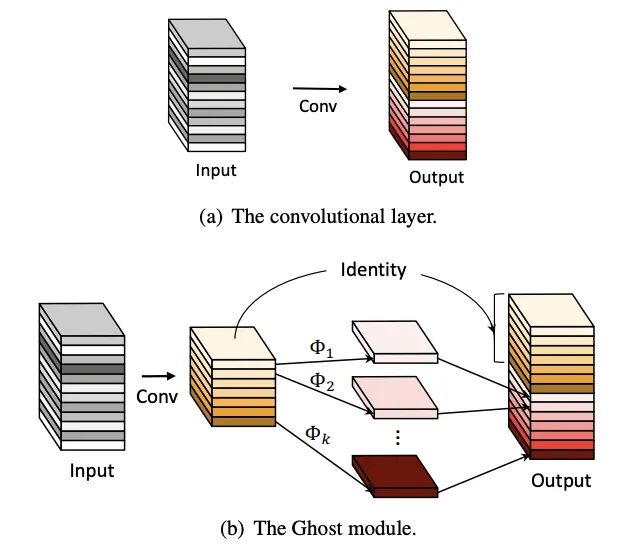
训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,相似的特征图类似于对方的ghost。但冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,于是提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图数量,Ghost模块的整体的参数量和计算量就已经降低了。
16. WeightNet
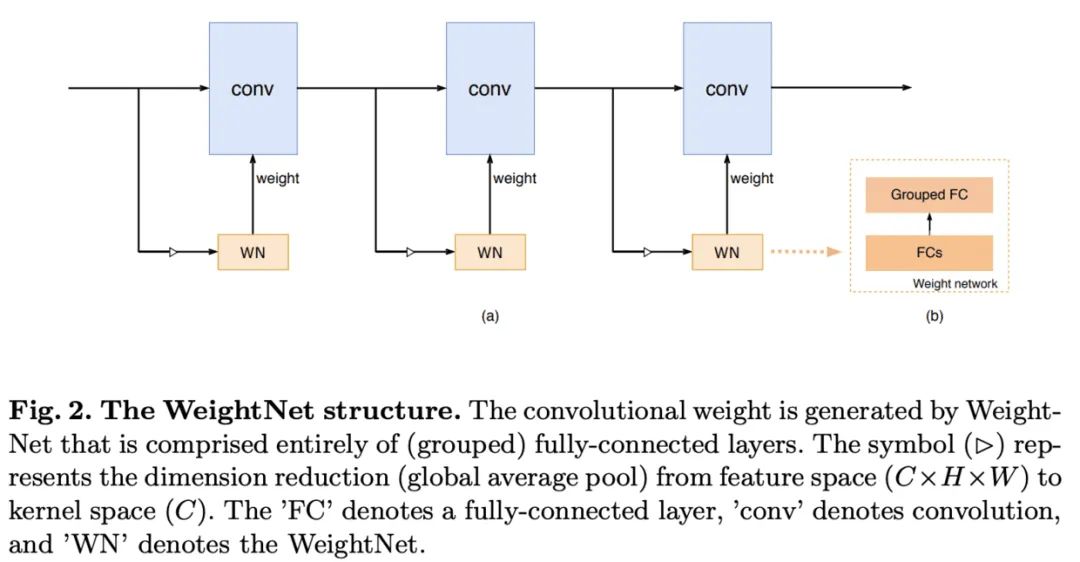
论文提出了一种简单且高效的动态生成网络WeightNet,该结构在权值空间上集成了SENet和CondConv的特点,在激活向量后面添加一层分组全连接,直接产生卷积核的权值,在计算上十分高效,并且可通过超参数的设置来进行准确率和速度上的trade-off。
17. MicroNet
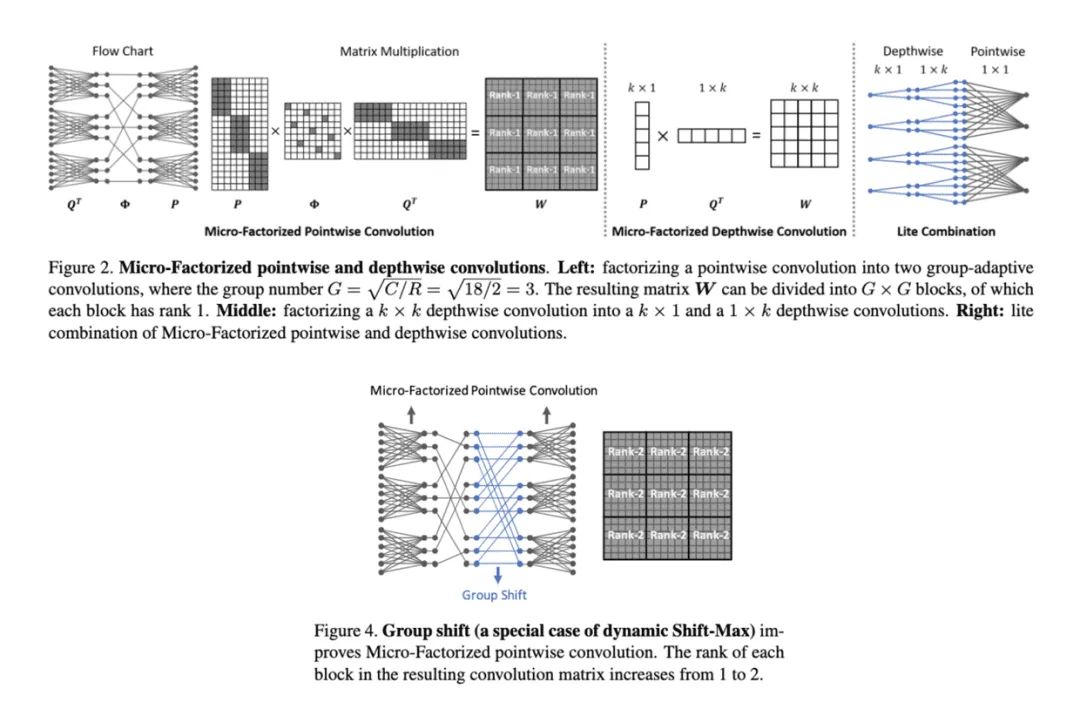
论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。
三、 ViT(Vision Transformer )结构Backbone
在过去的一年里,至少这几篇论文是很有用的工作,他们就是在于transformer构建的模型,并且在各方面的指标上超越了许多领先的传统方法:
- DETR: End-to-End Object Detection with Transformers, 使用transformer做目标检测的端到端的方法;
- ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE, 探讨transformer应用于基础的视觉任务,比如分类任务;
- Image GPT: Generative Pretraining from Pixels: 使用transformer进行图像填补;
- LDTR: transformers for lane detection: 使用transformer进行车道线检测.
1. ViT-H/14 和 ViT-L/16 (2020)
ViT 是Google团队于2021年发表在ICLR上的paper。ViT是第一个替代CNN,使用纯Transformer的结构,输入一张224×224×3的图片,ViT将其分成14×14=196个非重叠的patches,每个patch的大小是16×16×3,然后将这些patch输入到堆叠的多个transformer编码器中。
论文链接:《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》
研究者尽可能地遵循原始 Transformer 的设计。这种故意为之的简单设置具有以下优势,即可扩展 NLP Transformer 架构和相应的高效实现几乎可以实现开箱即用。研究者想要证明,当进行适当地扩展时,该方法足以超越当前最优的卷积神经网络。
(1)Vision Transformer(ViT)
该研究提出的 Vision Transformer 架构遵循原版 Transformer 架构。下图 1 为模型架构图。
标准 Transformer 接收 1D 序列的 token 嵌入为输入。为了处理 2D 图像,研究者将图像 x ∈ R^H×W×C 变形为一系列的扁平化 2D patch x_p ∈ R^N×(P^2 ·C),其中 (H, W) 表示原始图像的分辨率,(P, P) 表示每个图像 patch 的分辨率。然后,N = HW/P^2 成为 Vision Transformer 的有效序列长度。
Vision Transformer 在所有层使用相同的宽度,所以一个可训练的线性投影将每个向量化 patch 映射到模型维度 D 上(公式 1),相应的输出被称为 patch 嵌入。
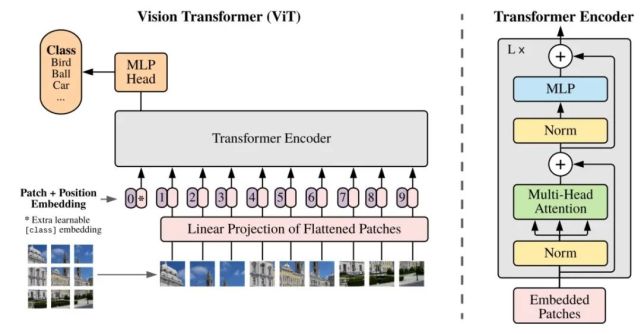
与 BERT 的 [class] token 类似,研究者在一系列嵌入 patch (z_0^0 = x_class)之前预先添加了一个可学习嵌入,它在 Transformer 编码器(z_0^L )输出中的状态可以作为图像表示 y(公式 4)。在预训练和微调阶段,分类头(head)依附于 z_L^0。
位置嵌入被添加到 patch 嵌入中以保留位置信息。研究者尝试了位置嵌入的不同 2D 感知变体,但与标准 1D 位置嵌入相比并没有显著的增益。所以,编码器以联合嵌入为输入。
Transformer 编码器由多个交互层的多头自注意力(MSA)和 MLP 块组成(公式 2、3)。每个块之前应用 Layernorm(LN),而残差连接在每个块之后应用。MLP 包含两个呈现 GELU 非线性的层。
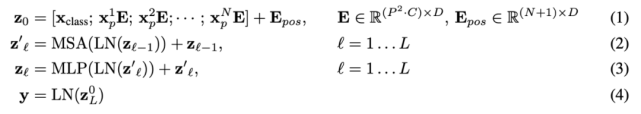
作为将图像分割成 patch 的一种替代方案,输出序列可以通过 ResNet 的中间特征图来形成。在这个混合模型中,patch 嵌入投影(公式 1)被早期阶段的 ResNet 取代。ResNet 的其中一个中间 2D 特征图被扁平化处理成一个序列,映射到 Transformer 维度,然后馈入并作为 Transformer 的输入序列。最后,如上文所述,将分类输入嵌入和位置嵌入添加到 Transformer 输入中。
(2)微调和更高分辨率
研究者在大型数据集上预训练 ViT 模型,并针对更小规模的下游任务对模型进行微调。为此,研究者移除了预训练预测头,并添加了一个零初始化的 D × K 前馈层,其中 K 表示下游类的数量。与预训练相比,在更高分辨率时进行微调通常更有益处。当馈入更高分辨率的图像时,研究者保持 patch 大小不变,从而得到更大的有效序列长度。
ViT 模型可以处理任意序列长度(取决于内存约束),但预训练位置嵌入或许不再具有意义。所以,研究者根据预训练位置嵌入在原始图像中的位置,对它们进行 2D 插值操作。需要注意的是,只有在分辨率调整和 patch 提取中,才能将 2D 图像的归纳偏置手动注入到 ViT 模型中。
2. Swin Transformer(2021)
屠榜各大CV任务!Swin Transformer:层次化视觉Transformer
作者单位:微软亚洲研究院
代码:https://github.com/microsoft/Swin-Transformer
论文:https://arxiv.org/abs/2103.1403
目前Transformer应用到图像领域主要有两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
(1)整体架构
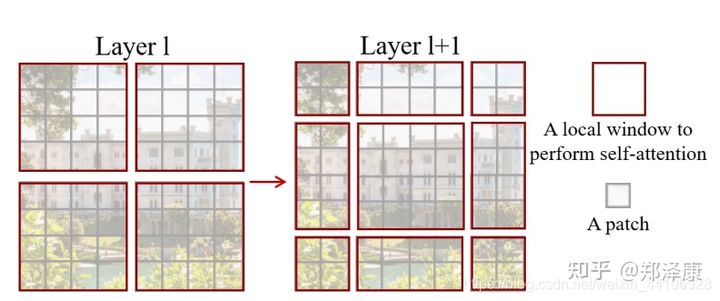
我们先看下Swin Transformer的整体架构:
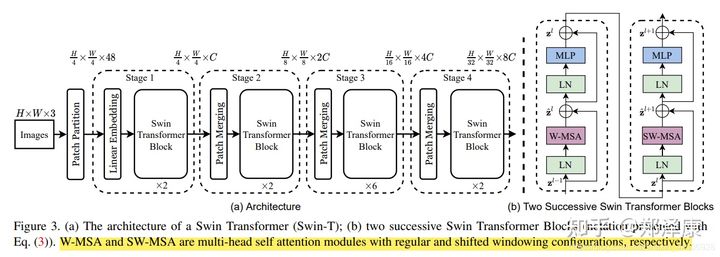
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
- 在输入开始的时候,做了一个
Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。 - 在每个Stage里,由
Patch Merging和多个Block组成。 - 其中
Patch Merging模块主要在每个Stage一开始降低图片分辨率。 - 而Block具体结构如右图所示,主要是
LayerNorm,MLP,Window Attention和Shifted Window Attention组成 (为了方便讲解,我会省略掉一些参数)
class SwinTransformer(nn.Module):
def __init__(...):
super().__init__()
...
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(...)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x其中有几个地方处理方法与ViT不同:
- ViT在输入会给embedding进行位置编码。而Swin-T这里则是作为一个可选项(
self.ape),Swin-T是在计算Attention的时候做了一个相对位置编码; - ViT会单独加上一个可学习参数,作为分类的token。而Swin-T则是直接做平均,输出分类,有点类似CNN最后的全局平均池化层
接下来我们看下各个组件的构成:。
(2)组件
(2.1)Patch Embedding
在输入进Block前,我们需要将图片切成一个个patch,然后嵌入向量。
具体做法是对原始图片裁成一个个 patch_size * patch_size的窗口大小,然后进行嵌入。
这里可以通过二维卷积层,将stride,kernelsize设置为patch_size大小。设定输出通道来确定嵌入向量的大小。最后将H,W维度展开,并移动到第一维度
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size) # -> (img_size, img_size)
patch_size = to_2tuple(patch_size) # -> (patch_size, patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
# 假设采取默认参数
x = self.proj(x) # 出来的是(N, 96, 224/4, 224/4)
x = torch.flatten(x, 2) # 把HW维展开,(N, 96, 56*56)
x = torch.transpose(x, 1, 2) # 把通道维放到最后 (N, 56*56, 96)
if self.norm is not None:
x = self.norm(x)
return x(2.2)Patch Merging
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。
在CNN中,则是在每个Stage开始前用
stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍
class PatchMerging(nn.Module):
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x下面是一个示意图(输入张量N=1, H=W=8, C=1,不包含最后的全连接层调整)

个人感觉这像是PixelShuffle的反操作
(2.3)Window Partition/Reverse
window partition函数是用于对张量划分窗口,指定窗口大小。将原本的张量从 N H W C, 划分成 num_windows*B, window_size, window_size, C,其中 num_windows = H*W / window_size,即窗口的个数。而window reverse函数则是对应的逆过程。这两个函数会在后面的Window Attention用到。
def window_partition(x, window_size):
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x(2.4)Window Attention
这是这篇文章的关键。传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
我们先简单看下公式:
主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码。后续实验有证明相对位置编码的加入提升了模型性能。
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads # nH
head_dim = dim // num_heads # 每个注意力头对应的通道数
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 设置一个形状为(2*(Wh-1) * 2*(Ww-1), nH)的可学习变量,用于后续的位置编码
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
# 相关位置编码...下面我把涉及到相关位置编码的逻辑给单独拿出来,这部分比较绕
首先QK计算出来的Attention张量形状为(numWindows*B, num_heads, window_size*window_size, window_size*window_size)。
而对于Attention张量来说,以不同元素为原点,其他元素的坐标也是不同的,以window_size=2为例,其相对位置编码如下图所示
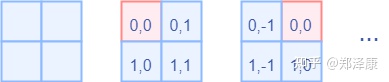
首先我们利用torch.arange和torch.meshgrid函数生成对应的坐标,这里我们以windowsize=2为例子
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.meshgrid([coords_h, coords_w]) # -> 2*(wh, ww)
"""
(tensor([[0, 0],
[1, 1]]),
tensor([[0, 1],
[0, 1]]))
"""然后堆叠起来,展开为一个二维向量
coords = torch.stack(coords) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
"""
tensor([[0, 0, 1, 1],
[0, 1, 0, 1]])
"""利用广播机制,分别在第一维,第二维,插入一个维度,进行广播相减,得到 2, wh*ww, wh*ww的张量
relative_coords_first = coords_flatten[:, :, None] # 2, wh*ww, 1
relative_coords_second = coords_flatten[:, None, :] # 2, 1, wh*ww
relative_coords = relative_coords_first - relative_coords_second # 最终得到 2, wh*ww, wh*ww 形状的张量因为采取的是相减,所以得到的索引是从负数开始的,我们加上偏移量,让其从0开始。
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1后续我们需要将其展开成一维偏移量。而对于(1,2)和(2,1)这两个坐标。在二维上是不同的,但是通过将x,y坐标相加转换为一维偏移的时候,他的偏移量是相等的。
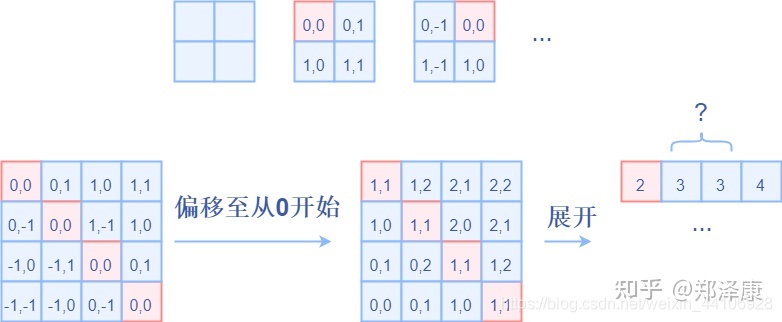
所以最后我们对其中做了个乘法操作,以进行区分

然后再最后一维上进行求和,展开成一个一维坐标,并注册为一个不参与网络学习的变量
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)接着我们看前向代码
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0) # (1, num_heads, windowsize, windowsize)
if mask is not None: # 下文会分析到
...
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x- 首先输入张量形状为
numWindows*B, window_size * window_size, C(后续会解释) - 然后经过
self.qkv这个全连接层后,进行reshape,调整轴的顺序,得到形状为3, numWindows*B, num_heads, window_size*window_size, c//num_heads,并分配给q,k,v。 - 根据公式,我们对
q乘以一个scale缩放系数,然后与k(为了满足矩阵乘要求,需要将最后两个维度调换)进行相乘。得到形状为(numWindows*B, num_heads, window_size*window_size, window_size*window_size)的attn张量 - 之前我们针对位置编码设置了个形状为
(2*window_size-1*2*window_size-1, numHeads)的可学习变量。我们用计算得到的相对编码位置索引self.relative_position_index选取,得到形状为(window_size*window_size, window_size*window_size, numHeads)的编码,加到attn张量上 - 暂不考虑mask的情况,剩下就是跟transformer一样的softmax,dropout,与
V矩阵乘,再经过一层全连接层和dropout
(2.4)Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
左边是没有重叠的Window Attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
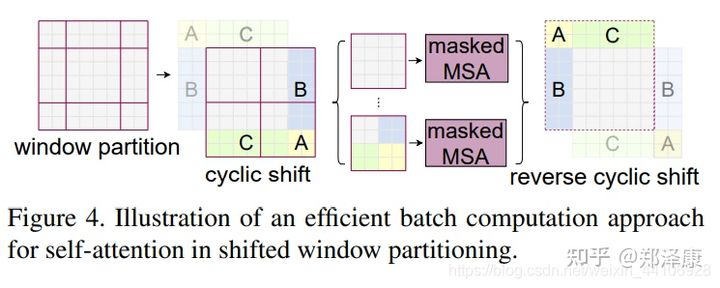
(2.5)特征图移位操作
代码里对特征图移位是通过torch.roll来实现的,下面是示意图
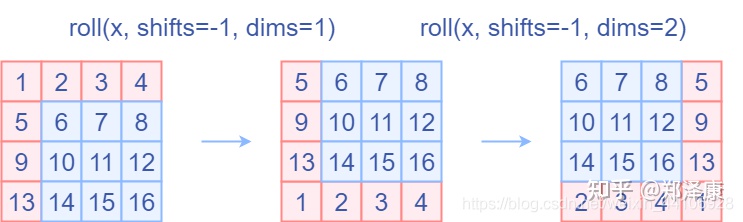
如果需要reverse cyclic shift的话只需把参数shifts设置为对应的正数值。
(2.6)Attention Mask
我认为这是Swin Transformer的精华,通过设置合理的mask,让Shifted Window Attention在与Window Attention相同的窗口个数下,达到等价的计算结果。
首先我们对Shift Window后的每个窗口都给上index,并且做一个roll操作(window_size=2, shift_size=-1)
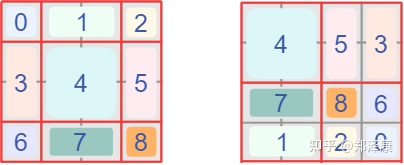
我们希望在计算Attention的时候,让具有相同index QK进行计算,而忽略不同index QK计算结果。
最后正确的结果如下图所示
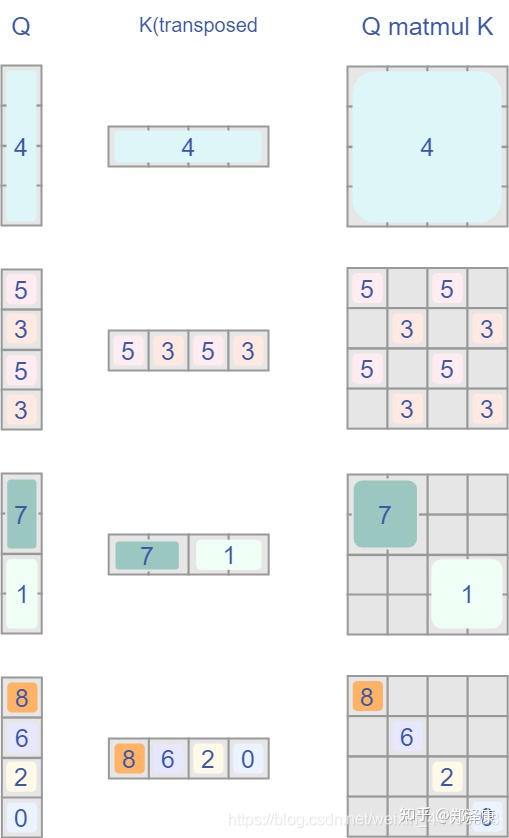
而要想在原始四个窗口下得到正确的结果,我们就必须给Attention的结果加入一个mask(如上图最右边所示)
相关代码如下:
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))以上图的设置,我们用这段代码会得到这样的一个mask
tensor([[[[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]]],
[[[ 0., -100., 0., -100.],
[-100., 0., -100., 0.],
[ 0., -100., 0., -100.],
[-100., 0., -100., 0.]]],
[[[ 0., 0., -100., -100.],
[ 0., 0., -100., -100.],
[-100., -100., 0., 0.],
[-100., -100., 0., 0.]]],
[[[ 0., -100., -100., -100.],
[-100., 0., -100., -100.],
[-100., -100., 0., -100.],
[-100., -100., -100., 0.]]]]])在之前的window attention模块的前向代码里,包含这么一段
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)将mask加到attention的计算结果,并进行softmax。mask的值设置为-100,softmax后就会忽略掉对应的值
(2.7)Transformer Block整体架构
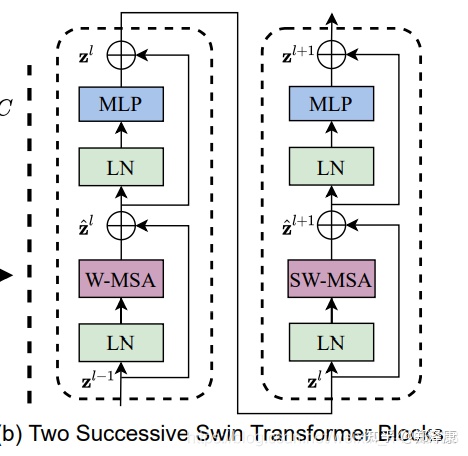
两个连续的Block架构如上图所示,需要注意的是一个Stage包含的Block个数必须是偶数,因为需要交替包含一个含有Window Attention的Layer和含有Shifted Window Attention的Layer。
我们看下Block的前向代码
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x整体流程如下
- 先对特征图进行LayerNorm
- 通过
self.shift_size决定是否需要对特征图进行shift - 然后将特征图切成一个个窗口
- 计算Attention,通过
self.attn_mask来区分Window Attention还是Shift Window Attention - 将各个窗口合并回来
- 如果之前有做shift操作,此时进行
reverse shift,把之前的shift操作恢复 - 做dropout和残差连接
- 再通过一层LayerNorm+全连接层,以及dropout和残差连接
(3)实验结果
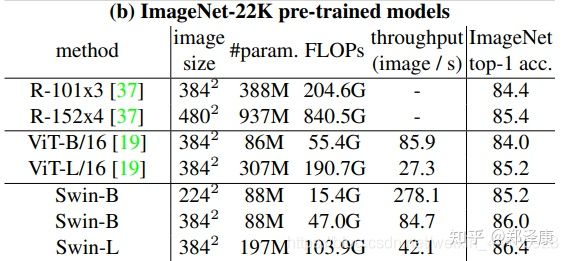
在ImageNet22K数据集上,准确率能达到惊人的86.4%。另外在检测,分割等任务上表现也很优异,感兴趣的可以翻看论文最后的实验部分。
(4)总结
这篇文章创新点很棒,引入window这一个概念,将CNN的局部性引入,还能控制模型整体计算量。在Shift Window Attention部分,用一个mask和移位操作,很巧妙的实现计算等价。作者的代码也写得十分赏心悦目,推荐阅读!
3. PVT(2021, Pyramid Vision Transformer)
PVT是把金字塔结构引入到Transformer中,使得它可以像ResNet那样无缝接入到各种下游任务中(如:物体检测,语义分割),同时也取得了非常不错的效果。
论文地址:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions
代码地址:PVT
(1)问题
首先,对于dense prediction tasks,完全无卷积的的transformer backbone少有人研究。而VIT作为用在图像分类任务的完全transformer结构,很难直接应用于像素级别的dense prediction,例如目标检测与分割。
原因:(1)只有一个尺度的低分辨率输出 (2)内存与计算复杂度限制。
为了解决完全transformer对于dense prediction的限制,提出PVT,与vit相比,
好处(1)输入输出可以更小(4×4, vit是32×32),从而产生高分辨率的输出。(2)提出渐进收缩金字塔结构(progressive shringkin pyramid)显著减少计算量 (3)提出空间减少注意力层,进一步减少计算量(spatial-reduction attention)。
与CNN相比,PVT在每一步的特征提取过程中都考虑了全局感受野。
此外,有一个小问题,作者在介绍vision transformer相关工作的时候,这句话不知如何理解。

(2)方法
A、整体结构,有{F1,F2,F3,F4}四个级别的输出。
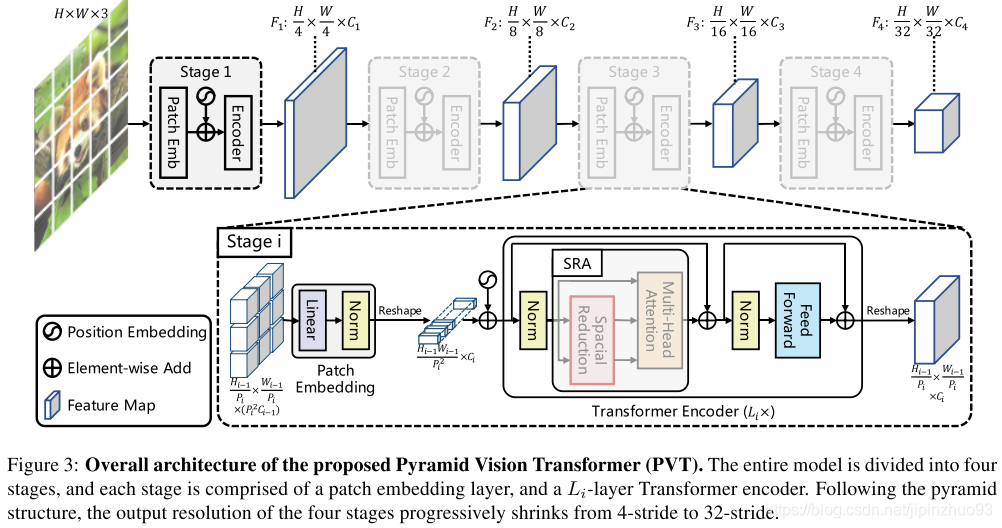
B、金字塔结构
不同stage的结构是share的,控制输出的方法如下。

C、Encoder
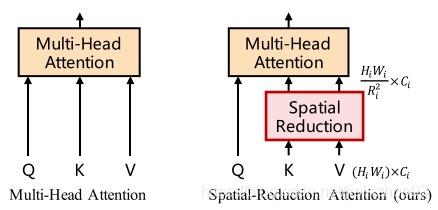

提出Spatial-Reduction Attention(SRA)替代MHA,减少计算量。不同之处在于SRA会降低K和V的大小。
4. MPViT (CVPR 2022,Multi-path Vision Transformer, 多路径 Vision Transformer)
MPViT (Multi-path Vision Transformer, 多路径 Vision Transformer) 专注于使用视觉 Transformers 有效地表示多尺度特征以进行密集预测任务。广泛的实验结果表明 MPViT 可以作为各种视觉任务的多功能骨干网络,比如在图像分类、目标检测、实例分割、和语义分割上均能取得state-of-the-art结果。作者团队开放了tiny、xsmall、small、base 几种不同大小的模型预训练权重,这些轻量的预训练模型通过较小的参数量和计算量就能取得很好的精度。
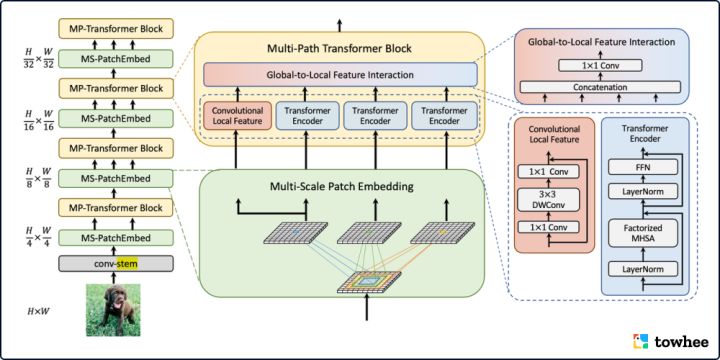
MPViT 通过探索多尺度块嵌入与多路径结构,结合重叠卷积块嵌入,可以同时对不同尺度、相同序列长度特征进行嵌入聚合。不同尺度的 Token 分别送入到不同的 Transformer 模块(即并行多路径结构)中,以构建同特征层级的粗粒度与细粒度特征的。多尺度 patch embedding 通过重叠卷积操作同时对不同大小的视觉 patch 进行 token 化,在适当调整后得到具有相同序列长度(即特征分辨率)的特征。卷积的填充/步幅。然后,来自不同尺度的 token 被独立地并行馈送到 Transformer 编码器中。每个具有不同大小 token 的 Transformer 编码器都执行全局自注意力。然后聚合生成的特征,在相同的特征级别上实现粗粒度与细粒度的特征表示。在特征聚合步骤中,引入了全局到局部特征交互(Global-to-Local Feature Interaction, GLI)过程,该过程将卷积局部特征连接到Transformer的全局特征,同时利用卷积的局部连通性和全局上下文。这样的多个 patch embedding 和 block 堆叠后就是这样一个 MPViT 的网络 backbone。
相关资料:
- 模型用例(Towhee Operator):image-embedding/mpvit
- 论文:MPViT: Multi-Path Vision Transformer for Dense Prediction
- 更多资料:
5. EdgeViTs (CVPR 2022,轻量级视觉Transformer)
论文链接: https://arxiv.org/abs/2205.03436
文章指出,目前基于VIT,做出轻量化的操作,一般有3种
- 使用具有空间分辨率(即token序列长度)的分层体系结构,在各个阶段逐步向下采样
- 用于控制输入token序列长度和参数共享的局部分组自我注意机制
- 池化注意方案以因子对key和value进行子抽样
这些的设计呢?趋势都是设计出更复杂,更强大的ViT,来挑战性能更好的CNN,但是呢还不能满足手机运行的实用效果
- 推理效率需要高(例如低延迟和能源消耗),这样运行成本就普遍负担得起,更多设备上的应用程序逗可以支持应用,这才是在实践中真正关心的直接指标。
- 模型尺寸(即参数量)对于现今的移动设备来说是负担得起的。
- 实现的简易性在实际应用中也是至关重要的。对于更广泛的部署,有必要使用通用深度学习框架(如ONNX、TensorRT和TorchScript)支持和优化的标准计算操作高效地实现模型,而不需要花费昂贵的代价为每个网络框架进行专门化设计。
本文贡献如下:
(1)从实际设备上部署和执行的角度研究轻量级ViT的设计;
(2)为了获得最佳的延展性和部署,提出了一种新的高效ViT家族,称为EdgeViT,它是基于使用标准初始模块的自注意力机制的最优分解而设计的。
(3)关于设备上的性能,为了现实部署的相关性,直接考虑不同模型的延迟和能源消耗,而不是依赖于其他标准,如FLOPs数量或参数量。
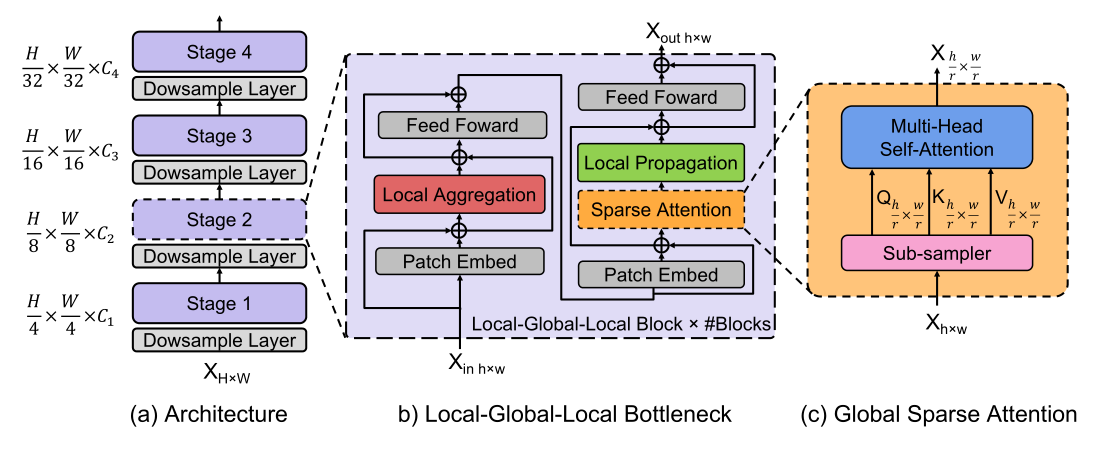
- 图a就是总体框架,类似于resnet结构。为了设计适合移动/边缘设备的轻量化ViT,我们采用最近ViT变体中使用的分层金字塔网络结构,
- 图b引入了一个开销高效的局部-全局-局部(LGL)bottleneck,LGL通过稀疏注意力模块进一步减少了自注意力的开销
- 图c,能实现更好的准确性和延迟平衡。
- Self-attention已被证明是非常有效的学习全局信息或长距离空间依赖性的方法,这是视觉识别的关键。
- 另一方面,由于图像具有高度的空间冗余(例如,附近的Patch在语义上是相似的),将注意力集中到所有的空间Patch上,即使是在一个下采样的特征映射中,也是低效的。
因此,与以前在每个空间位置执行Self-attention的Transformer Block相比,LGL Bottleneck只对输入Token的子集计算Self-attention,但支持完整的空间交互,如在标准的Multi-Head Self-attention(MHSA)中。既会减少Token的作用域,同时也保留建模全局和局部上下文的底层信息流。
这里引入了3种有效的操作:
- Local aggregation:仅集成来自局部近似Token信号的局部聚合
- Global sparse attention:建模一组代表性Token之间的长期关系,其中每个Token都被视为一个局部窗口的代表;
- Local propagation:将委托学习到的全局上下文信息扩散到具有相同窗口的非代表Token。
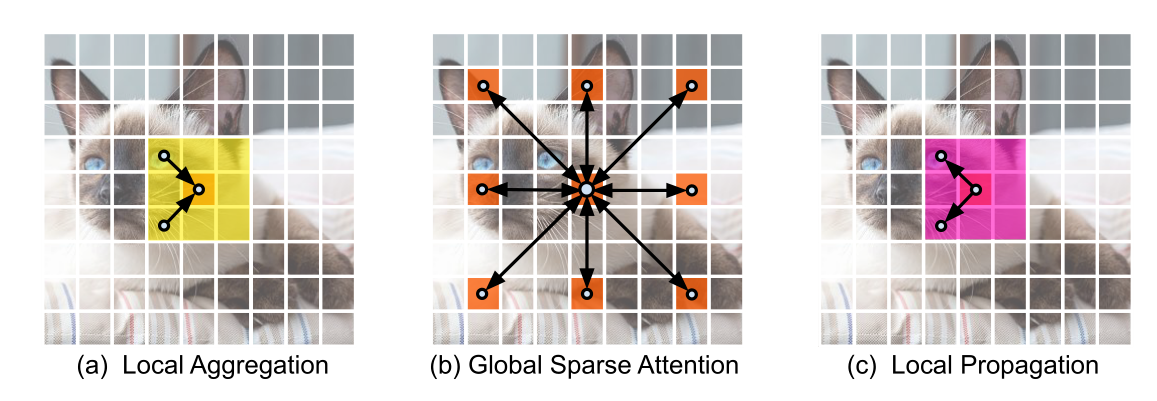
将这些结合起来,LGL Bottleneck就能够以低计算成本在同一特征映射中的任何一对Token之间进行信息交换。下面将详细说明每一个组成部分:
对于每个Token,利用Depth-wise和Point-wise卷积在大小为k×k的局部窗口中聚合信息(图3(a))。
class LocalAgg(nn.Module):
"""
局部模块,LocalAgg
卷积操作能够有效的提取局部特征
为了能够降低计算量,使用 逐点卷积+深度可分离卷积实现
"""
def __init__(self, channels):
super(LocalAgg, self).__init__()
self.bn = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层。增加非线性,提高特征提取能力
self.pointwise_conv_0 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
# 深度可分离卷积
self.depthwise_conv = nn.Conv2d(channels, channels, padding=1, kernel_size=3, groups=channels, bias=False)
# 归一化
self.pointwise_prenorm_1 = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层,增加非线性,提高特征提取能力
self.pointwise_conv_1 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.bn(x)
x = self.pointwise_conv_0(x)
x = self.depthwise_conv(x)
x = self.pointwise_prenorm_1(x)
x = self.pointwise_conv_1(x)
return x

对均匀分布在空间中的稀疏代表性Token集进行采样,每个r×r窗口有一个代表性Token。这里,r表示子样本率。然后,只对这些被选择的Token应用Self-attention(图3(b))。这与所有现有的ViTs不同,在那里,所有的空间Token都作为Self-attention计算中的query被涉及到。
class GlobalSparseAttention(nn.Module):
"""
全局模块,选取特定的tokens,进行全局作用
"""
def __init__(self, channels, r, heads):
"""
Args:
channels: 通道数
r: 下采样倍率
heads: 注意力头的数目
这里使用的是多头注意力机制,MHSA,multi-head self-attention
"""
super(GlobalSparseAttention, self).__init__()
#
self.head_dim = channels // heads
# 扩张的
self.scale = self.head_dim ** -0.5
self.num_heads = heads
# 使用平均池化,来进行特征提取
self.sparse_sampler = nn.AvgPool2d(kernel_size=1, stride=r)
# 计算qkv
self.qkv = nn.Conv2d(channels, channels * 3, kernel_size=1, bias=False)
def forward(self, x):
x = self.sparse_sampler(x)
B, C, H, W = x.shape
q, k, v = self.qkv(x).view(B, self.num_heads, -1, H * W).split([self.head_dim,self.head_dim,self.head_dim],dim=2)
# 计算特征图 attention map
attn = (q.transpose(-2, -1) @ k).softmax(-1)
# value和特征图进行计算,得出全局注意力的结果
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W)
# print(x.shape)
return x

通过转置卷积将代表性 Token 中编码的全局上下文信息传播到它们的相邻的 Token 中(图 3©)。
class LocalPropagation(nn.Module):
def __init__(self, channels, r):
super(LocalPropagation, self).__init__()
# 组归一化
self.norm = nn.GroupNorm(num_groups=1, num_channels=channels)
# 使用转置卷积 恢复 GlobalSparseAttention模块 r倍的下采样率
self.local_prop = nn.ConvTranspose2d(channels,
channels,
kernel_size=r,
stride=r,
groups=channels)
# 使用逐点卷积
self.proj = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.local_prop(x)
x = self.norm(x)
x = self.proj(x)
return x

最终, LGL bottleneck 可以表达为:
LGL 的代码为:
import torch
import torch.nn as nn
class Residual(nn.Module):
"""
残差网络
"""
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, x):
return x + self.module(x)
class ConditionalPositionalEncoding(nn.Module):
"""
条件编码信息
"""
def __init__(self, channels):
super(ConditionalPositionalEncoding, self).__init__()
self.conditional_positional_encoding = nn.Conv2d(channels, channels, kernel_size=3, padding=1, groups=channels,
bias=False)
def forward(self, x):
x = self.conditional_positional_encoding(x)
return x
class MLP(nn.Module):
"""
FFN 模块
"""
def __init__(self, channels):
super(MLP, self).__init__()
expansion = 4
self.mlp_layer_0 = nn.Conv2d(channels, channels * expansion, kernel_size=1, bias=False)
self.mlp_act = nn.GELU()
self.mlp_layer_1 = nn.Conv2d(channels * expansion, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.mlp_layer_0(x)
x = self.mlp_act(x)
x = self.mlp_layer_1(x)
return x
class LocalAgg(nn.Module):
"""
局部模块,LocalAgg
卷积操作能够有效的提取局部特征
为了能够降低计算量,使用 逐点卷积+深度可分离卷积实现
"""
def __init__(self, channels):
super(LocalAgg, self).__init__()
self.bn = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层。增加非线性,提高特征提取能力
self.pointwise_conv_0 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
# 深度可分离卷积
self.depthwise_conv = nn.Conv2d(channels, channels, padding=1, kernel_size=3, groups=channels, bias=False)
# 归一化
self.pointwise_prenorm_1 = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层,增加非线性,提高特征提取能力
self.pointwise_conv_1 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.bn(x)
x = self.pointwise_conv_0(x)
x = self.depthwise_conv(x)
x = self.pointwise_prenorm_1(x)
x = self.pointwise_conv_1(x)
return x
class GlobalSparseAttention(nn.Module):
"""
全局模块,选取特定的tokens,进行全局作用
"""
def __init__(self, channels, r, heads):
"""
Args:
channels: 通道数
r: 下采样倍率
heads: 注意力头的数目
这里使用的是多头注意力机制,MHSA,multi-head self-attention
"""
super(GlobalSparseAttention, self).__init__()
#
self.head_dim = channels // heads
# 扩张的
self.scale = self.head_dim ** -0.5
self.num_heads = heads
# 使用平均池化,来进行特征提取
self.sparse_sampler = nn.AvgPool2d(kernel_size=1, stride=r)
# 计算qkv
self.qkv = nn.Conv2d(channels, channels * 3, kernel_size=1, bias=False)
def forward(self, x):
x = self.sparse_sampler(x)
B, C, H, W = x.shape
q, k, v = self.qkv(x).view(B, self.num_heads, -1, H * W).split([self.head_dim, self.head_dim, self.head_dim],
dim=2)
# 计算特征图 attention map
attn = (q.transpose(-2, -1) @ k).softmax(-1)
# value和特征图进行计算,得出全局注意力的结果
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W)
# print(x.shape)
return x
class LocalPropagation(nn.Module):
def __init__(self, channels, r):
super(LocalPropagation, self).__init__()
# 组归一化
self.norm = nn.GroupNorm(num_groups=1, num_channels=channels)
# 使用转置卷积 恢复 GlobalSparseAttention模块 r倍的下采样率
self.local_prop = nn.ConvTranspose2d(channels,
channels,
kernel_size=r,
stride=r,
groups=channels)
# 使用逐点卷积
self.proj = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.local_prop(x)
x = self.norm(x)
x = self.proj(x)
return x
class LGL(nn.Module):
def __init__(self, channels, r, heads):
super(LGL, self).__init__()
self.cpe1 = ConditionalPositionalEncoding(channels)
self.LocalAgg = LocalAgg(channels)
self.mlp1 = MLP(channels)
self.cpe2 = ConditionalPositionalEncoding(channels)
self.GlobalSparseAttention = GlobalSparseAttention(channels, r, heads)
self.LocalPropagation = LocalPropagation(channels, r)
self.mlp2 = MLP(channels)
def forward(self, x):
# 1. 经过 位置编码操作
x = self.cpe1(x) + x
# 2. 经过第一步的 局部操作
x = self.LocalAgg(x) + x
# 3. 经过一个前馈网络
x = self.mlp1(x) + x
# 4. 经过一个位置编码操作
x = self.cpe2(x) + x
# 5. 经过一个全局捕捉的操作。长和宽缩小 r倍。然后通过一个
# 6. 经过一个 局部操作部
x = self.LocalPropagation(self.GlobalSparseAttention(x)) + x
# 7. 经过一个前馈网络
x = self.mlp2(x) + x
return x
if __name__ == '__main__':
# 64通道,图片大小为32*32
x = torch.randn(size=(1, 64, 32, 32))
# 64通道,下采样2倍,8个头的注意力
model = LGL(64, 2, 8)
out = model(x)
print(out.shape)

3. 代码
import torch
import torch.nn as nn
# edgevits的配置信息
edgevit_configs = {
'XXS': {
'channels': (36, 72, 144, 288),
'blocks': (1, 1, 3, 2),
'heads': (1, 2, 4, 8)
}
,
'XS': {
'channels': (48, 96, 240, 384),
'blocks': (1, 1, 2, 2),
'heads': (1, 2, 4, 8)
}
,
'S': {
'channels': (48, 96, 240, 384),
'blocks': (1, 2, 3, 2),
'heads': (1, 2, 4, 8)
}
}
HYPERPARAMETERS = {
'r': (4, 2, 2, 1)
}
class Residual(nn.Module):
"""
残差网络
"""
def __init__(self, module):
super().__init__()
self.module = module
def forward(self, x):
return x + self.module(x)
class ConditionalPositionalEncoding(nn.Module):
"""
"""
def __init__(self, channels):
super(ConditionalPositionalEncoding, self).__init__()
self.conditional_positional_encoding = nn.Conv2d(channels, channels, kernel_size=3, padding=1, groups=channels,
bias=False)
def forward(self, x):
x = self.conditional_positional_encoding(x)
return x
class MLP(nn.Module):
"""
FFN 模块
"""
def __init__(self, channels):
super(MLP, self).__init__()
expansion = 4
self.mlp_layer_0 = nn.Conv2d(channels, channels * expansion, kernel_size=1, bias=False)
self.mlp_act = nn.GELU()
self.mlp_layer_1 = nn.Conv2d(channels * expansion, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.mlp_layer_0(x)
x = self.mlp_act(x)
x = self.mlp_layer_1(x)
return x
class LocalAgg(nn.Module):
"""
局部模块,LocalAgg
卷积操作能够有效的提取局部特征
为了能够降低计算量,使用 逐点卷积+深度可分离卷积实现
"""
def __init__(self, channels):
super(LocalAgg, self).__init__()
self.bn = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层。增加非线性,提高特征提取能力
self.pointwise_conv_0 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
# 深度可分离卷积
self.depthwise_conv = nn.Conv2d(channels, channels, padding=1, kernel_size=3, groups=channels, bias=False)
# 归一化
self.pointwise_prenorm_1 = nn.BatchNorm2d(channels)
# 逐点卷积,相当于全连接层,增加非线性,提高特征提取能力
self.pointwise_conv_1 = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.bn(x)
x = self.pointwise_conv_0(x)
x = self.depthwise_conv(x)
x = self.pointwise_prenorm_1(x)
x = self.pointwise_conv_1(x)
return x
class GlobalSparseAttention(nn.Module):
"""
全局模块,选取特定的tokens,进行全局作用
"""
def __init__(self, channels, r, heads):
"""
Args:
channels: 通道数
r: 下采样倍率
heads: 注意力头的数目
这里使用的是多头注意力机制,MHSA,multi-head self-attention
"""
super(GlobalSparseAttention, self).__init__()
#
self.head_dim = channels // heads
# 扩张的
self.scale = self.head_dim ** -0.5
self.num_heads = heads
# 使用平均池化,来进行特征提取
self.sparse_sampler = nn.AvgPool2d(kernel_size=1, stride=r)
# 计算qkv
self.qkv = nn.Conv2d(channels, channels * 3, kernel_size=1, bias=False)
def forward(self, x):
x = self.sparse_sampler(x)
B, C, H, W = x.shape
q, k, v = self.qkv(x).view(B, self.num_heads, -1, H * W).split([self.head_dim, self.head_dim, self.head_dim],
dim=2)
# 计算特征图 attention map
attn = (q.transpose(-2, -1) @ k).softmax(-1)
# value和特征图进行计算,得出全局注意力的结果
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W)
# print(x.shape)
return x
class LocalPropagation(nn.Module):
def __init__(self, channels, r):
super(LocalPropagation, self).__init__()
# 组归一化
self.norm = nn.GroupNorm(num_groups=1, num_channels=channels)
# 使用转置卷积 恢复 GlobalSparseAttention模块 r倍的下采样率
self.local_prop = nn.ConvTranspose2d(channels,
channels,
kernel_size=r,
stride=r,
groups=channels)
# 使用逐点卷积
self.proj = nn.Conv2d(channels, channels, kernel_size=1, bias=False)
def forward(self, x):
x = self.local_prop(x)
x = self.norm(x)
x = self.proj(x)
return x
class LGL(nn.Module):
def __init__(self, channels, r, heads):
super(LGL, self).__init__()
self.cpe1 = ConditionalPositionalEncoding(channels)
self.LocalAgg = LocalAgg(channels)
self.mlp1 = MLP(channels)
self.cpe2 = ConditionalPositionalEncoding(channels)
self.GlobalSparseAttention = GlobalSparseAttention(channels, r, heads)
self.LocalPropagation = LocalPropagation(channels, r)
self.mlp2 = MLP(channels)
def forward(self, x):
# 1. 经过 位置编码操作
x = self.cpe1(x) + x
# 2. 经过第一步的 局部操作
x = self.LocalAgg(x) + x
# 3. 经过一个前馈网络
x = self.mlp1(x) + x
# 4. 经过一个位置编码操作
x = self.cpe2(x) + x
# 5. 经过一个全局捕捉的操作。长和宽缩小 r倍。然后通过一个
# 6. 经过一个 局部操作部
x = self.LocalPropagation(self.GlobalSparseAttention(x)) + x
# 7. 经过一个前馈网络
x = self.mlp2(x) + x
return x
class DownSampleLayer(nn.Module):
def __init__(self, dim_in, dim_out, r):
super(DownSampleLayer, self).__init__()
self.downsample = nn.Conv2d(dim_in,
dim_out,
kernel_size=r,
stride=r)
self.norm = nn.GroupNorm(num_groups=1, num_channels=dim_out)
def forward(self, x):
x = self.downsample(x)
x = self.norm(x)
return x
# if __name__ == '__main__':
# # 64通道,图片大小为32*32
# x = torch.randn(size=(1, 64, 32, 32))
# # 64通道,下采样2倍,8个头的注意力
# model = LGL(64, 2, 8)
# out = model(x)
# print(out.shape)
class EdgeViT(nn.Module):
def __init__(self, channels, blocks, heads, r=[4, 2, 2, 1], num_classes=1000, distillation=False):
super(EdgeViT, self).__init__()
self.distillation = distillation
l = []
in_channels = 3
# 主体部分
for stage_id, (num_channels, num_blocks, num_heads, sample_ratio) in enumerate(zip(channels, blocks, heads, r)):
# print(num_channels,num_blocks,num_heads,sample_ratio)
# print(in_channels)
l.append(DownSampleLayer(dim_in=in_channels, dim_out=num_channels, r=4 if stage_id == 0 else 2))
for _ in range(num_blocks):
l.append(LGL(channels=num_channels, r=sample_ratio, heads=num_heads))
in_channels = num_channels
self.main_body = nn.Sequential(*l)
self.pooling = nn.AdaptiveAvgPool2d(1)
self.classifier = nn.Linear(in_channels, num_classes, bias=True)
if self.distillation:
self.dist_classifier = nn.Linear(in_channels, num_classes, bias=True)
# print(self.main_body)
def forward(self, x):
# print(x.shape)
x = self.main_body(x)
x = self.pooling(x).flatten(1)
if self.distillation:
x = self.classifier(x), self.dist_classifier(x)
if not self.training:
x = 1 / 2 * (x[0] + x[1])
else:
x = self.classifier(x)
return x
def EdgeViT_XXS(pretrained=False):
model = EdgeViT(**edgevit_configs['XXS'])
if pretrained:
raise NotImplementedError
return model
def EdgeViT_XS(pretrained=False):
model = EdgeViT(**edgevit_configs['XS'])
if pretrained:
raise NotImplementedError
return model
def EdgeViT_S(pretrained=False):
model = EdgeViT(**edgevit_configs['S'])
if pretrained:
raise NotImplementedError
return model
if __name__ == '__main__':
x = torch.randn(size=(1, 3, 224, 224))
model = EdgeViT_S(False)
# y = model(x)
# print(y.shape)
from thop import profile
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input,))
print("flops:{:.3f}G".format(flops /1e9))
print("params:{:.3f}M".format(params /1e6))

参考链接
四、CNNs+Transformer/Attention结构Backbone
CNN的成功依赖于其两个固有的归纳偏置,即平移不变性和局部相关性,而视觉Transformer结构通常缺少这种特性,导致通常需要大量数据才能超越CNN的表现,CNN在小数据集上的表现通常比纯Transformer结构要好。CNN感受野有限导致很难捕获全局信息,而Transformer可以捕获长距离依赖关系,因此ViT出现之后有许多工作尝试将CNN和Transformer结合,使得网络结构能够继承CNN和Transformer的优点,并且最大程度保留全局和局部特征。
Transformer是一种基于注意力的编码器-解码器结构,最初应用于自然语言处理领域,一些研究最近尝试将Transformer应用到计算机视觉领域。在Transformer应用到视觉之前,卷积神经网络是主要研究内容。受到自注意力在NLP领域的影响,一些基于CNN的结构尝试通过加入自注意力层捕获长距离依赖关系,也有另外一些工作直接尝试用自注意力模块替代卷积,但是纯注意力模块结构仍然没有最先进的CNN结构表现好。
视觉任务attention汇总 Convolution+Transformer具体可分为:
#1 卷积中引入Transformer;
解释:Transformer 理论上比CNN能得到更好的模型表现,但是因为计算全局注意力导致巨大的计算损失,特别是在浅层网络中,特征图越大,计算复杂度越高,因此一些方法提出将Transformer插入到CNN主干网络中,或者使用一个Transformer模块替代某一个卷积模块。例如:
1 《Non-local neural networks》 2 《Attention augmented convolutional networks》 3 《Bottleneck transformers for visual recognition》 4 《Efficient attention: Attention with linear complexities》 5 《Lambdanetworks: Modeling long-range interactions without attention》 #2 Transformer中引入CNN
解释:CNN有局部性和平移不变性,局部性关注特征图中相邻的点,平移不变性就是对于不同区域使用相同的匹配规则,虽然CNN的归纳偏差使得网络在少量数据上表现较好,但是这也限制了在充分数据上的表现,因此有一些工作尝试将CNN的归纳偏差引入Transformer加速网络收敛。例如:
1 2021《Levit: a vision transformer in convnet’s clothing for faster inference》 2 2021《Tokens-to-token vit: Training vision transformers from scratch on imagenet》 3 2021 《Swin transformer: Hierarchical vision transformer using shifted windows》 4 2021 《Cvt: Introducing convolutions to vision transformers》 5 2021 《Scaling local self-attention for parameter efficient visual backbones》 6 2021 《Incorporating convolution designs into visual transformers》
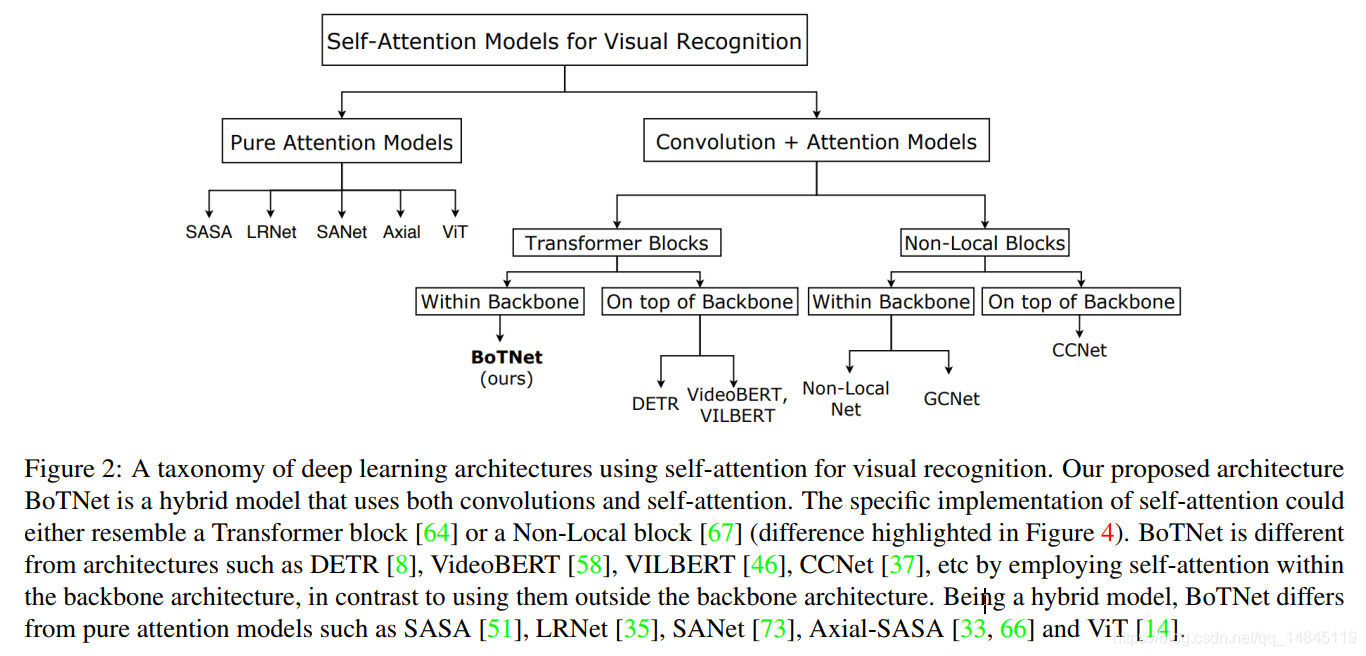
1. CoAtNet(#2 2021)
这是一个Convolution + Attention的组合模型。
Paper:CoAtNet: Marrying Convolution and Attention for All Data Sizes
核心代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/CoAtNet.py
虽然Transformer在CV任务上有非常强的学习建模能力,但是由于缺少了像CNN那样的归纳偏置,所以相比于CNN,Transformer的泛化能力就比较差。因此,如果只有Transformer进行全局信息的建模,在没有预训练(JFT-300M)的情况下,Transformer在性能上很难超过CNN(VOLO在没有预训练的情况下,一定程度上也是因为VOLO的Outlook Attention对特征信息进行了局部感知,相当于引入了归纳偏置)。既然CNN有更强的泛化能力,Transformer具有更强的学习能力,作者就想到,为什么不能将Transformer和CNN进行一个结合呢?因此,这篇论文探究了,具体怎么将CNN与Transformer做结合,才能使得模型具有更强的学习能力和泛化能力。
(2)Convolution和Self-Attention的融合
(2.1)Convolution
在卷积类型的选择上,作者采用的是MBConv(MBConv的结构见下图,关于MBConv的详细介绍可见[1])。简单的来说MBConv就是有两个特点:1)采用了Depthwise Convlution,因此相比于传统卷积,Depthwise Conv的参数能够大大减少;2)采用了“倒瓶颈”的结构,也就是说在卷积过程中,特征的通过经历了升维和降维两个步骤,这样做的目的应该是为了提高模型的学习能力。
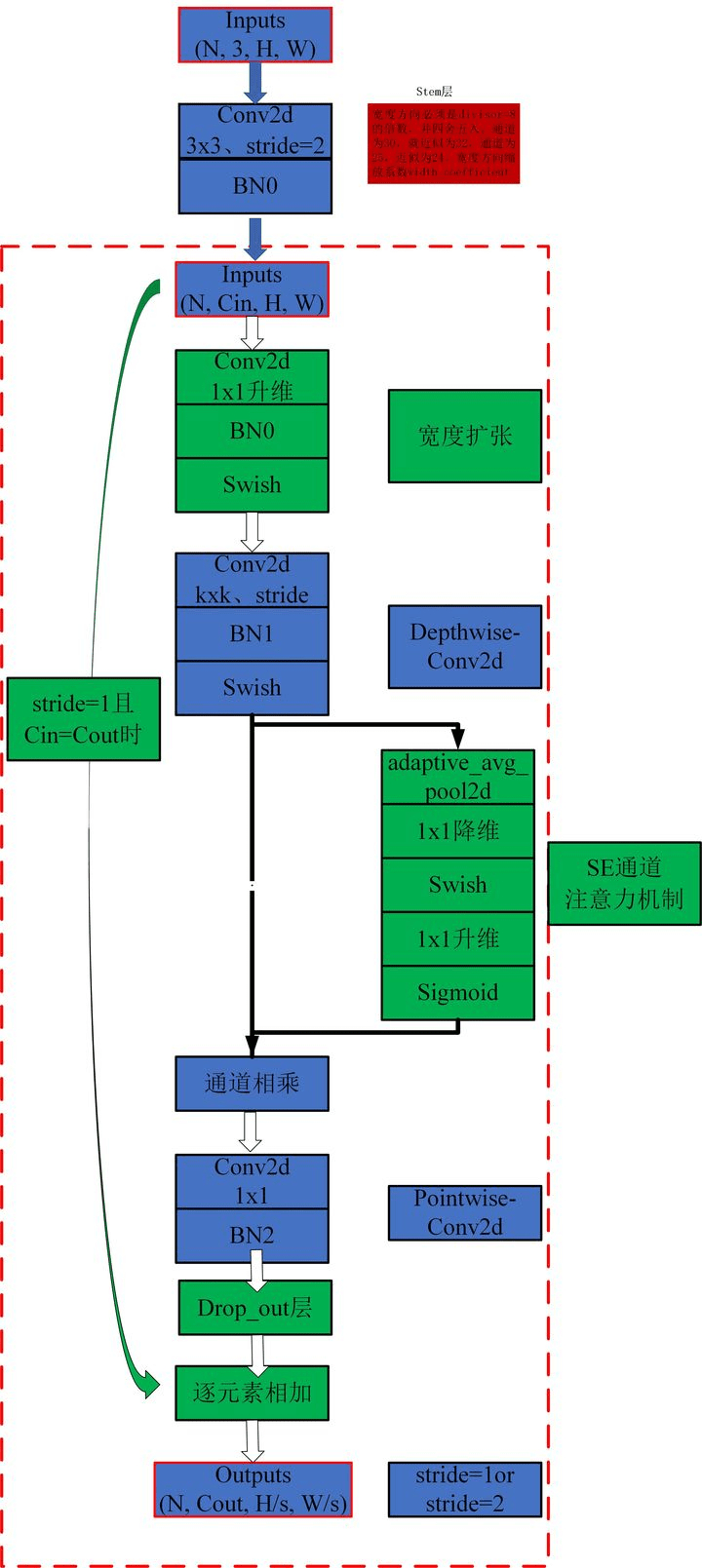
(图来自:EfficentNet详解之MBConvBlock – 知乎)
卷积起到是一个对局部信息建模的功能,可以表示成下面的公式:
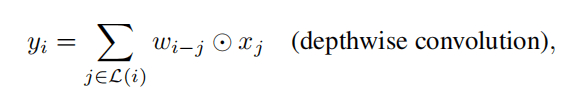
(2.2)Self-Attention
Self-Attention 的计算主要分为三步,第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;第二步是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的结果。
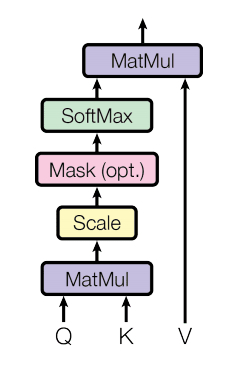
Self-Attention是进行全局信息的建模,因为Self-Attention在每一个位置进行特征映射是平等了考虑了所有位置的特征,可以表示成下面的公式:
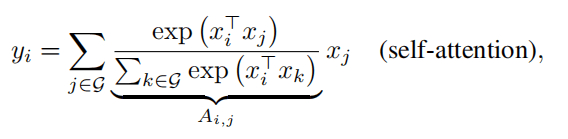
(2.3)Conv和Self-Attention的性质分析
1)Conv的卷积核是静态的,是与输入的特征无关的;Self-Attention的权重是根据Q K V动态计算得到的,所以Self-Attention的动态自适应加权的。
2)对卷积来说,它只关心每个位置周围的特征,因此卷积具有平移不变性(translation equivalence),这也是卷积具有良好泛化能力的原因。但是ViT使用的是绝对位置编码,因此Self-Attention不具备这个性质。
3)Conv的感知范围受卷积核大小的限制,而大范围的感知能力有利于模型获得更多的上下文信息。因此全局感知也是Self-Attention用在CV任务中的一个重要motivation。

(2.4) 融合
上面分析了Conv和Self-Attention几个性质,为了将Conv和Self-Attention的优点结合,可以将静态的全局和和自适应注意力矩阵相加,因此就可以表示呈下面的公式:
先求和,再Softmax:
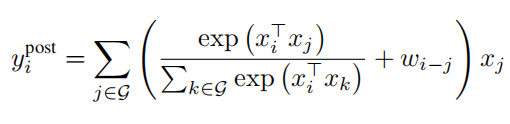
先Softmax,再求和:
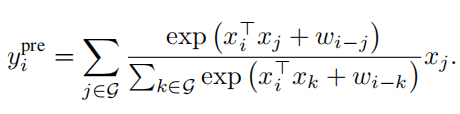
(3)垂直结构设计
由于Self-Attention是和输入数据的size呈平方关系,所以如果直接将raw image进行计算,会导致计算非常慢。因此作者提出了三种方案
(3.1)被Pass的方案
1)将于输入数据的size呈平方关系的Self-Attention换成线性的Attention
pass原因:Performance不好
2)加强局部注意力,将全局感知限制为局部感知
pass原因:在TPU上计算非常慢;限制了模型的学习能力。
(3.2)被接受的方案
进行一些向下采样,并在特征图达到合适的大小后采用全局相对关注。
对于这个方案,也有两种实现方式:
1)像ViT那样,直接用16×16的步长,一次缩小为16倍;
2)采用multi-stage的方式,一次一次Pooling。
(3.3)Multi-Stage的变种方案
因为前面我们分析了Self-Attention和Convolution各有各的优点,因此在每个Stage中采用什么结构成为了本文研究的重点,通过引入深度卷积到注意力模块中,深度卷积中一个卷积核负责一个通道,一个通道只被一个卷积核计算,相比于正常卷积,其参数和运算成本相对比较低,在浅层网络中堆叠卷积层,比较了不同的堆叠方式,对此,作者提出了四种方案:1)C-C-C-C;2)C-C-C-T; 3)C-C-T-T ;4)C-T-T-T。其中C代表Convolution,T代表Transformer。
为了比较这两种方案那个比较好,作者提出两个衡量点:1)泛化能力(genralization),2)学习能力(model capacity)。
泛化能力:当训练损失相同时,测试集的准确率越高,泛化能力越强。泛化能力用来衡量模型对于没见过数据能力的判断准确度。
学习能力:当学习数据是庞大、冗余的,学习能力强的模型能够获得更好的性能。学习能力用来衡量拟合大数据集的能力。
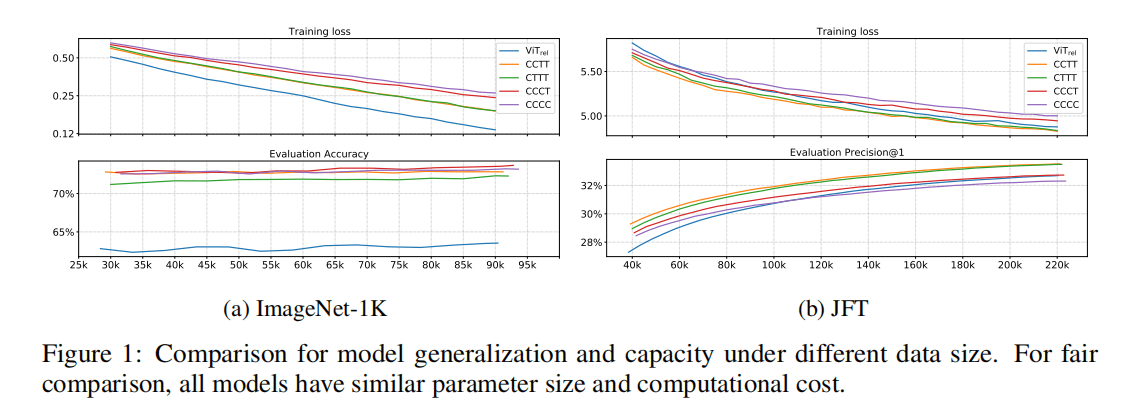
上面这张图展示了在ImageNet-1K(小数据集),JFT(大数据集)上的训练损失和验证准确率。根据对genralization和model capacity的定义,我们可以得出这样的结论:
在genralization capability 上,各个变种genralization capability 的排序如下:
![]()
对于model capacity,各个变种model capacity 的排序如下:
![]()
基于以上结果,为了探究C-C-T-T 和 C-T-T-T,哪一个比较好,作者又做了一个transferability test。在JFT上预训练后,在ImageNet-1K上再训练了30个epoch。结果如下:
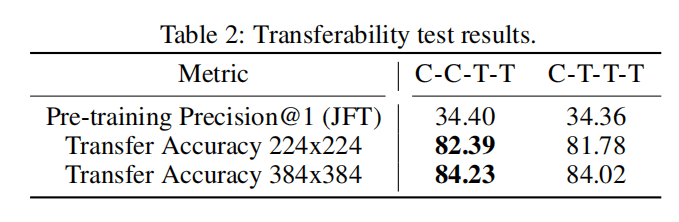
可以看出C-C-T-T的效果比较好,因此作者选用了C-C-T-T作为CoAtNet的结构。
(4)实验
(4.1)不同CoAtNet的变种
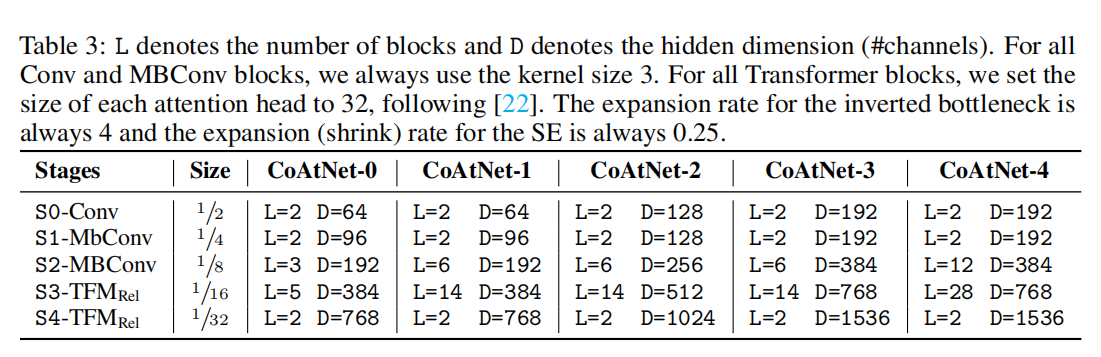
分为几个stage,每个stage的大小都变成了原来的1/2,通道维度都变大了。
(4.2) ImageNet-1K的结果
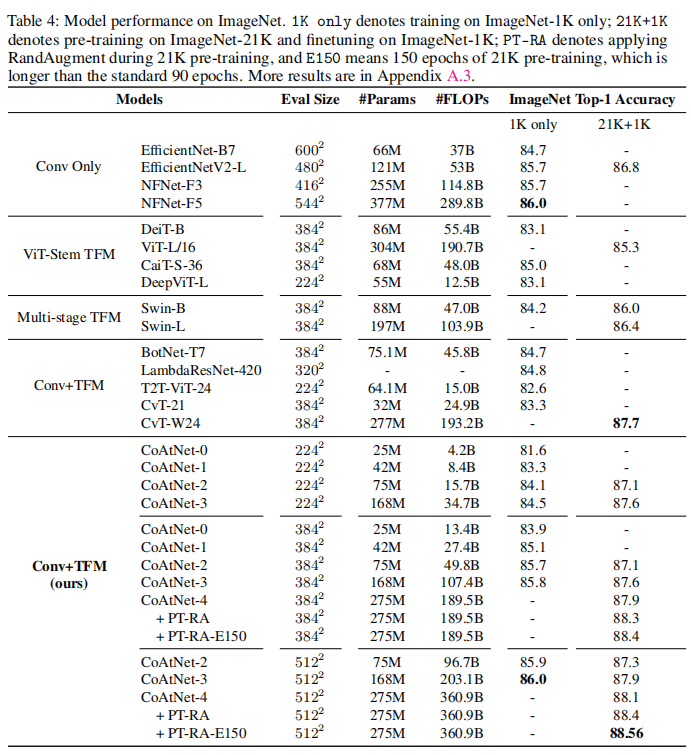
从上面的表格中可以看出CoAt的结果不同比各种ViT的性能更强,并且在不预训练的情况下,CoAtNet-3的性能也跟NFNet-F5一样
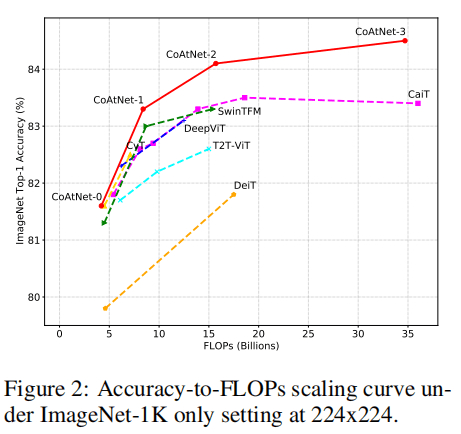
上图可以看出,在不预训练的情况下,CoAtNet能够明显优于其他ViT的变种。
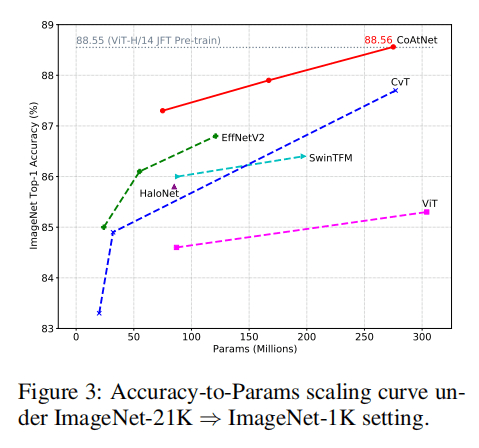
在使用ImageNet-21K的情况下,CoAtNet变体实现了88.56%的top-1精度,相比于其他CNN和ViT结构也有明显的优势。
(4.3)JFT的结果
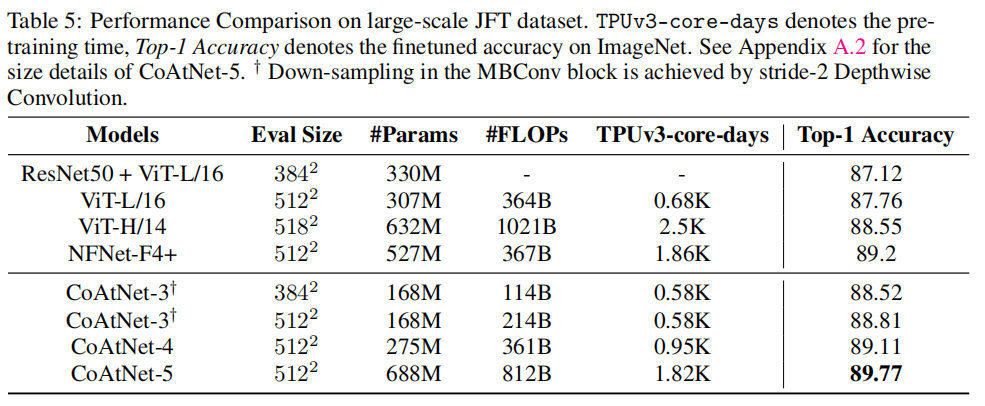
在JFT大数据集上,JFT的性能也是能够明显优于其他模型,展现了CoAtNet强大的泛化能力和模型容量。
(5) 总结
目前ViT倾向于往引入CNN的假设偏置来提高模型的学习和泛化能力,最近的VOLO这篇文章也是引入了局部感知模块,获得更加细粒度的信息。无论是VOLO还是CoAtNet都将分类任务的性能刷到了一个新的高度。
2. BoTNet(#1 2021)
论文: Bottleneck Transformers for Visual Recognition
GitHub:GitHub – leaderj1001/BottleneckTransformers: Bottleneck Transformers for Visual Recognition
distribuuuu/botnet.py at master · BIGBALLON/distribuuuu · GitHub
BoTNet 通过使用Multi-Head Self-Attention(MHSA)替代ResNet Bottleneck中的3×3卷积,其他没有任何改变,形成新的网络结构,称为Bottleneck Transformer,相比于ResNet等网络提高了在分类、目标检测等任务中的表现,在ImageNet分类任务中达到84.7%的准确率,并且比EfficientNet快1.64倍。
BoTNet中使用的MHSA和Transformer中的MHSA有一定的区别,首先,BoTNet中使用Batch Normalization,而Transformer中使用Layer Normalization,其次,Transformer中使用一个在全连接层中使用一个非线性激活,BoT(Bottleneck Transformer)模块中使用三个非线性激活,最后Transformer中的MHSA模块包含一个输出映射,而BoT中的MHSA没有。
MHSA模块:
LEFT:经典的 Transformer结构
Middle:BoT block结构
RIGHT:基于MHSA改进的resnet bottleneck
Transformer中的MHSA和BoTNet中的MHSA的区别:
- 归一化,Transformer使用 Layer Normalization,而BoTNet使用 Batch Normalization。
- 非线性激活,Transformer仅仅使用一个非线性激活在FPN block模块中,BoTNet使用了3个非线性激活。
- 输出投影,Transformer中的MHSA包含一个输出投影,BoTNet则没有。
- 优化器,Transformer使用Adam优化器训练,BoTNet使用sgd+ momentum
MHSA包含了位置的attention和内容的attention。
网络结构:
基于显存开销和计算量的考虑,只将ResNet的c5 block中的残差结构替换为MHSA结构。
文章出处登录后可见!