2023.9.8更新
C++ SDK篇已经发布,点击这里传送到文章
MMDeploy 提供了一系列工具,帮助我们更轻松的将 OpenMMLab 下的算法部署到各种设备与平台上。
1.流程简介
MMDeploy 定义的模型部署流程,这里直接使用了官方文档的内容,如下图所示:

1)模型转换(Model Converter)
模型转换的主要功能是把输入的模型格式,转换为目标设备的推理引擎所要求的模型格式。
目前,MMDeploy 可以把 PyTorch 模型转换为 ONNX、TorchScript 等和设备无关的 IR 模型。也可以将 ONNX 模型转换为推理后端模型。两者相结合,可实现端到端的模型转换,也就是从训练端到生产端的一键式部署。
2)MMDeploy 模型(MMDeploy Model)
也称 SDK Model。它是模型转换结果的集合。不仅包括后端模型,还包括模型的元信息。这些信息将用于推理 SDK 中。
3)推理 SDK(Inference SDK)
封装了模型的前处理、网络推理和后处理过程。对外提供多语言的模型推理接口。
2.MMDeploy安装及环境配置
本篇文章安装环境
- i5-7400HQ+1050ti
- Win 11
- VS2022
- CUDA11.6及相应版本的cudnn(cudnn必须要)
- python 3.8
- pytorch 1.13.1
- 以及mmlab(mmcv 2.0及以上版本)基本的配置,请参考我的上一篇文章安装。
本篇文章使用mmpose1.x进行部署,起一个抛砖引玉的作用,只要是openMMLab系列的其实流程都大差不差。废话不多说了,下面正式开始:
1)mmdeploy安装
因为是在windows平台,官方建议的是使用预编译包,所以这里我们使用pip直接安装:
# 1. 安装 MMDeploy 模型转换工具(含trt/ort自定义算子)
pip install mmdeploy==1.0.0
# 2. 安装 MMDeploy SDK推理工具
# 根据是否需要GPU推理可任选其一进行下载安装
# 2.1 支持 onnxruntime 推理
pip install mmdeploy-runtime==1.0.0
# 2.2 支持 onnxruntime-gpu tensorrt 推理
pip install mmdeploy-runtime-gpu==1.0.0
mmdeploy-runtime有两个版本,因为我们要使用tensorrt,所以这里要安装gpu版本的。
然后到GitHub上去下载mmdeploy的源码,命令行输入:
git clone https://github.com/open-mmlab/mmdeploy.git下载这个源码的是因为后面模型转换需要用到。
2)onnxruntime安装
命令行输入:
# 根据是否需要GPU推理可任选其一进行下载安装
# 1. onnxruntime
pip install onnxruntime==1.8.1
# 2. onnxruntime-gpu
pip install onnxruntime-gpu==1.8.1
这里官方文档使用的是1.8.1版本,我使用的1.14版本测试后没有什么大问题。
3)tensorRT安装
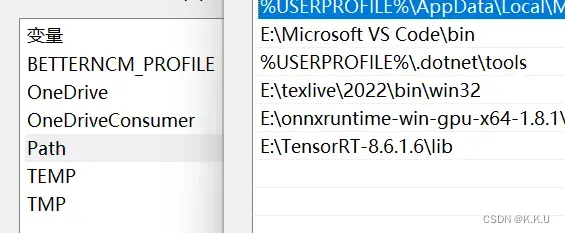
这里需要提前装好CUDA和cudnn,然后在英伟达的网站下载对应CUDA版本的tensorRT压缩包,这里我下载的是TensorRT-8.6.1.6.Windows10.x86_64.cuda-11.8.zip。解压到任意位置。
然后一定要在系统环境变量中添加TensorRT文件夹中的lib路径,如图所示:
安装pycuda
pip install pycuda打开命令行窗口,进入tensorRT目录下的python文件夹,根据自己的python版本选择安装:
因为我是python3.8,这里命令行输入:
pip install tensorrt-8.6.1-cp38-none-win_amd64.whl至此TensorRT安装完成。
3.模型转换
1)准备工作
使用tools\check_env.py检查环境配置是否正确,这里贴出我输出的信息:
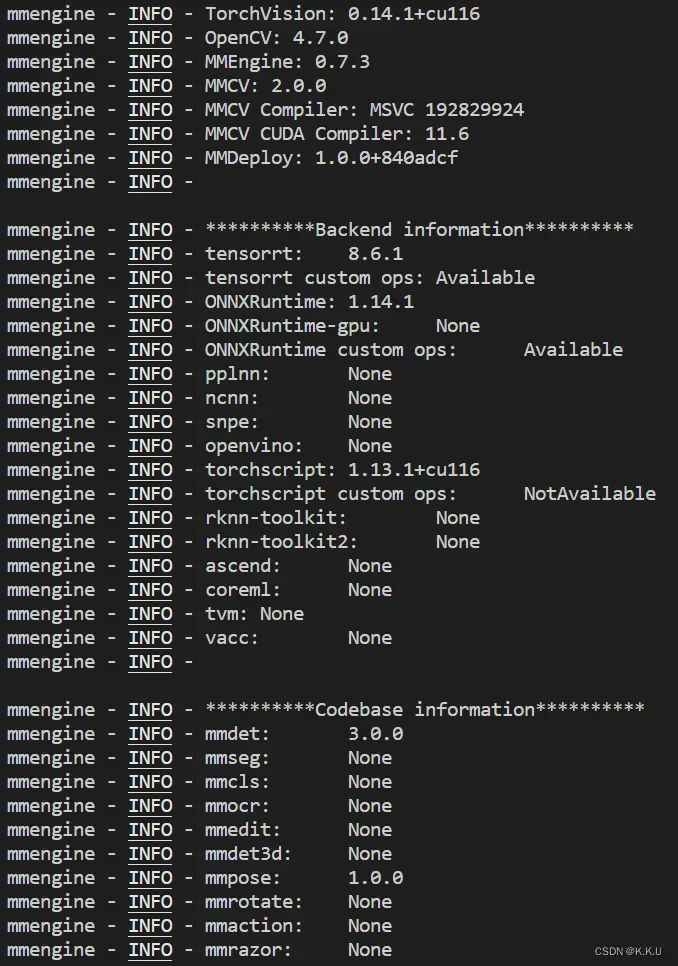
这里选择MMPose1.x的RTMPose模型做示例,理论上openMMlab的开源项目都大同小异,如果要使用自己的代码和网络,请保证它在openMMlab的开源项目中能够正确完整地进行训练和测试。我选择了RTMPose_tiny模型,将模型权重下载好后放入mmpose源码中自建的文件夹。
2)转换为onnx
进入mmdeploy源码目录,命令行输入:
python tools/deploy.py configs/mmpose/pose-detection_onnxruntime_static_RTMPose.py ../mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose-t_8xb256-420e_coco-256x192.py ../mmpose/deploy_models/rtmpose-tiny_simcc-coco_pt-aic-coco_420e-256x192-e613ba3f_20230127.pth demo/resources/human-pose.jpg --work-dir mmdeploy_models/mmpose/rtmpose_t --device cpu --dump-info第一个参数:mmdeploy的配置文件,这里我修改了源文件并重新命名加上RTMPose的后缀。
修改如下:
#修改前
onnx_config = dict(input_shape=None)
#修改后
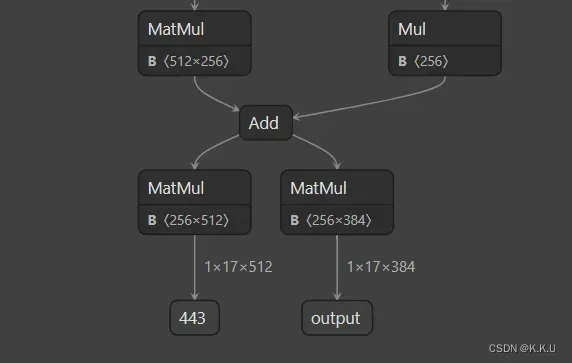
onnx_config = dict(input_shape=None,output_names=['output1','output2'],)因为RTMPose有两个输出,所以onnx输出需要有两个命名,如果不修改cfg文件的话,onnx转换是没问题的,但是在mmdeploy做可视化时会报错:

在netron中也可以看到只有一个输出有命名:
第二个参数:mmpose源码中RTMPose的配置文件;
第三个参数:RTMPose的权重文件;
第四个参数:用作输入的图片,使用demo中自带的即可;
–work-dir:后跟转换的输出文件夹;
–device:选择使用cpu还是gpu;
–dump-info:输出转换时的信息。
转换成功后,输出的文件夹中应该有如下图所示的文件:
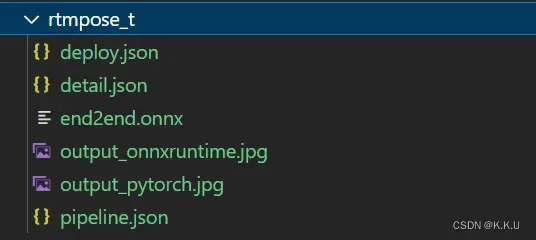
其中.onnx就是转换的onnx文件。此外,要注意查看输出文件夹中的两张图片,正常情况下应该有如下输出(左图为onnxruntime输出,右图为pytorch输出):


因为转换时没有进行量化,所以两幅图片应该是差不多的输出。如果onnxruntime没有输出或者误差很大,请仔细检查前面的步骤是否正确。
3)转换为tensorRT的模型
输入命令:
python tools/deploy.py configs/mmpose/pose-detection_tensorrt_static-256x192_RTMPose.py ../mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose-t_8xb256-420e_coco-256x192.py ../mmpose/deploy_models/rtmpose-tiny_simcc-coco_pt-aic-coco_420e-256x192-e613ba3f_20230127.pth demo/resources/human-pose.jpg --work-dir mmdeploy_models/mmpose/rtmpose_t_trt --device cuda --dump-info参数与前面是一样的,mmdeploy的配置文件同样也要对输出命名做修改。
经过一段时间转换,文件夹得到如下图所示的输出:
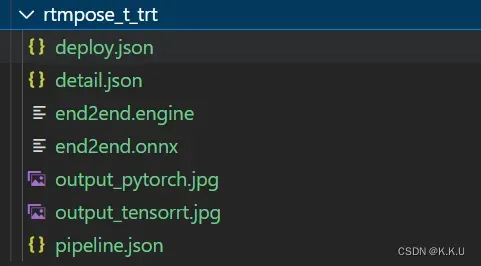
其中.engine文件即为tensorRT的模型文件。 同样要记得查看输出的图片,保证模型是正常的。
4.在python上进行推理测试
根据官方提供的代码,我们对转换的模型进行推理测试,为了测试推理速度,我做了些修改,测试5000次取平均速度:
from mmdeploy.apis.utils import build_task_processor
from mmdeploy.utils import get_input_shape, load_config
import torch
import time
deploy_cfg = 'configs/mmpose/pose-detection_tensorrt_static-256x192_RTMPose.py'
model_cfg = '../mmpose/configs/body_2d_keypoint/rtmpose/coco/rtmpose-t_8xb256-420e_coco-256x192.py'
device = 'cuda'
backend_model = ['mmdeploy_models/mmpose/rtmpose_t_trt/end2end.engine']
image = '000033016.jpg'
# read deploy_cfg and model_cfg
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
# build task and backend model
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
model = task_processor.build_backend_model(backend_model)
# process input image
input_shape = get_input_shape(deploy_cfg)
model_inputs, _ = task_processor.create_input(image, input_shape)
# do model inference
num_warmup = 5
pure_inf_time = 0
# benchmark with total batch and take the average
for i in range(5000):
start_time = time.perf_counter()
with torch.no_grad():
result = model.test_step(model_inputs)
elapsed = time.perf_counter() - start_time
if i >= num_warmup:
pure_inf_time += elapsed
if (i + 1) % 1000 == 0:
its = (i + 1 - num_warmup)/ pure_inf_time
print(f'Done item [{i + 1:<3}], {its:.2f} items / s')
print(f'Overall average: {its:.2f} items / s')
print(f'Total time: {pure_inf_time:.2f} s')
# visualize results
task_processor.visualize(
image=image,
model=model,
result=result[0],
window_name='visualize',
output_file='output_pose.png')需要配置的几个参数很简单,这里不多解释了,贴一个在我这个1050ti老笔记本上tensorRT的推理速度:
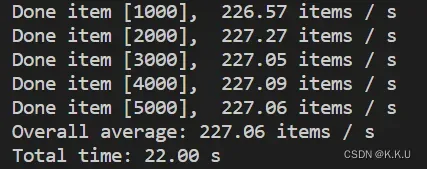
再贴一个用onnxruntime再cpu上的推理速度:
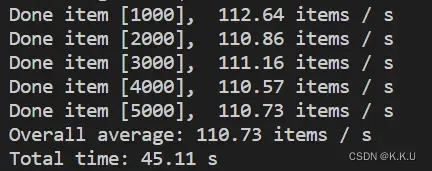
看得出来RTMPose确实挺快的。不过要注意的是,这是单人姿态估计的速度,如果要正常使用的话还要加一个detector。
5.使用mmdeploy的SDK进行推理
这里先开个坑,有时间再填,毕竟王国之泪要发售了,到时候失踪几天是必然的,哈哈。
如果觉得这篇文章对你有帮助,欢迎点赞收藏。
文章出处登录后可见!