一、问题:
1、CNN的局限:
CNN作为最基础的框架,存在很多的问题:
比如语义分割除了语义信息还需要细节信息,因此UNet等论文给出了解决方案。
比如语义分割需要上下文信息,因此PSPNet、Deeplab系列、基于自注意力机制的一系列方法(Non-Local、DANet、CCNet等)等被提出来获取局部、多尺度乃至全局上下文。
比如语义分割对于物体边缘的分割效果不理想,因此Gated-SCNN等方法也在着力解决这些问题。
以上这些方法的都已经开始出现边际效应了!饱和呜呜呜!
然而,除了上述的点之外,CNN的方法本质上存在着一个巨大的桎梏,就是图像初始阶段输入到网络之时,由于CNN的卷积核不会太大,所以模型只能利用局部信息理解输入图像,这难免有些一叶障目,从而影响编码器最后提取的特征的可区分性。这是使用CNN就逃脱不了的缺陷。
当然,有人会说基于自注意力机制的即插即用的模块插入到编码器和解码器之间,就能获取到全局上下文,使得模型从全局的角度理解图像进而改善特征。但是,模型如果一开始因为一叶障目获取了错误的特征,在后续利用全局上下文是否能够纠正的过来是存在一个很大的疑问的。
2、标签数据:
人工标注费时费力,小样本问题,样本不均衡、样本噪声等问题;
3、模型的泛化能力:
这不仅是分割任务上存在的问题,只要基于深度学习的任务就难免面临这么样一个窘境。辛辛苦苦训练好了一个模型,在换了一个场景的图像输入到模型之后,模型的性能往往出现一个很大下降。这个问题在实际中太常见了,以遥感图像语义分割为例,我在上海采集的城市数据集上训练好模型,在对来自成都的影像进行分割时,往往效果与随机预测的无异。这太尴尬了,要按传统方式解决这一问题的话,各个地区的测绘局都得采集一遍数据,然后标注好,才能无缝对国内所有城市的进行语义分割。这工作量,想想就很难。
4、如何简单有效区分同一类物体的不同实例?
在SOLO系列出来之前,实例分割主要分为两个大类:两阶段的MaskRCNN系列以及一阶段的Associative Embedding系列。MaskRCNN系列效果好,但是因为引入了roi_crop,proposal network等过程,会让模型变得比较复杂。Associative Embedding系列简单直接但是因为分割是像素级别的聚类,所需聚类的实例较多,不同类别之间的边界网络学得也并不清晰,所以导致最后的分割结果边界会有明显的粘连现象。当SOLO系列出来后一举改变了局面,现在的情况是一阶段的SOLO系列的论文在各个数据集上吊打MaskRCNN。
但是SOLO系列需要分割的类别是 SxSxC个类别,也就是SxSxC个通道的分数图,如果小物体较多,就需要把S设得较大,如果类别较多SxSxC这个数也就会变得很大,所以如何设计网络结构,减少SxSxC的值。以及如何简单有效区分同一类物体的不同实例?依然是一个开放的问题。
5、耗费显存问题
训练一个 ResNet101分类模型,在一张12G的GPU上 batch_size还能设到32左右,但是要是训练一个以ResNet101为基础网络框架的分割模型,那么batch_size就只能掉到4左右甚至到1。这样导致的最严重的问题便是模型收敛速度会非常的慢。一张卡训一个大一点数据集,比如COCO,一两周是没跑了。并不是每个应用场景的硬件设备都有这么大的显存,也并不是每个研究组都有服务器集群可供训练模型。
6、如何对遮挡区域进行建模(遥感方面可能不涉及)
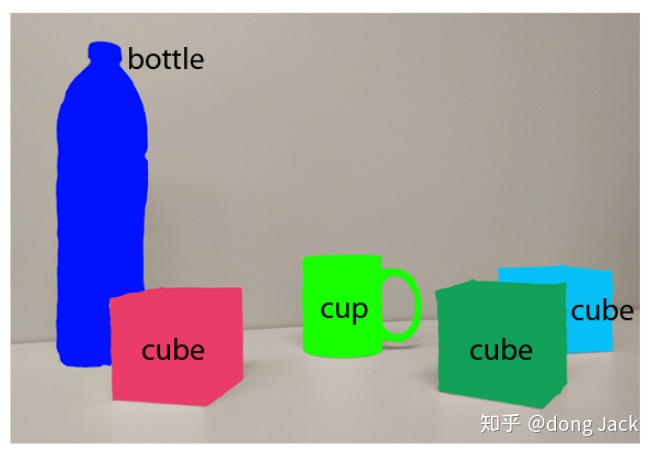
对于人类来说我们能够很好的处理遮挡问题,因为我们事先知道每一类事物的大致结构。比如图中的那只被遮挡的天蓝的方块,就算被绿色的方块遮挡到了,我们也能想象出它的大致形状。那么怎么让网络模型也具有这样的能力呢?我们是否需要对被遮挡的区域进行单独的通道进行建模?或者直接对图像进行分层解析,即是把一张图像看成有多张包含不同语义(实例)图像的组合,这些都是未可知的问题。
二、解决方法:
1、边缘问题:
- 对网络输出的分割的边界增加额外的损失;
- 让网络对边界的特征和区域内部的特征分开建模学习另外;
- 提高输入图像的输入分辨率和中间层特征图的分辨率同样也是简单有效的。
从目前的的研究来看,评价边缘的方式基本靠目测,没有具有针对性的指标来评价边缘的好坏。(这个是面试时一个大佬说的)。
2、样本不均衡问题:
利用loss动态加权或者在图像二维空间上采样来解决同一张图像中不同语义的像素个数不均衡以及学习的难易程度不同的问题。
这个思路目前最受关注的文章应该就是凯明大大的PointRend: Image Segmentation as Rendering这篇文章了。注意到PointRend这篇文章的设计的难样本挖局的方法在提高边界分割准确度的同时没有增加过多的计算量,并且还能抗边界锯齿。这对降低目前大多数分割方法为了追求精确的分割边界而设计的臃肿的Decoder 有很大的启发性。
那难样本挖掘为啥就能帮助优化边界和类别不均衡呢?那是因为往往挖掘出来的难样本就是边界上的像素点,以及语义类别中样本个数较少的像素点。所以做难样本挖掘往往比做单纯的类别不均的方法更加有效。
也可以适当参考一些图像分类里面应对数据不均衡的Loss的设计比如:Focal Loss,DR Loss等。
3、标签样本问题:
利用半监督或者弱监督学习的方法减少标注昂贵的问题;利用多个标签有噪声的样本或其特征构建虚拟的标签干净的虚拟样本或特征来减少标签的噪声。对于标注数据不好获取,显然结合弱监督、无监督的思想来做语义分割是比较好的解决方案。自认为暂时CV领域还做不到像NLP领域那样巧妙设计无监督任务的程度,因此无监督语义分割暂时应该是达不到一个能看的精度。
目前来看,对于分割来说,无标签数据能够为神经网络的训练带来三点好处:
- 通过标签传播的方法增加训练数据。
- 通过无标签数据的输出构建正则项获得额外的监督信号。
- 用无标签数据来学习到数据的一些分布特征或者像素空间结构特征。
目前最看好的半监督方法是基于GAN的方法它能同时实现2和3,但是GAN的难训练以及收敛慢也是一个老难的问题,不太好保证收敛结果的稳定性,但是相信随着GAN的迭代发展,这些问题会慢慢得到解决。也可适度参考一些图像分类上的半监督方法,比如 MixMatch 系列。
目前减少训练数据比较实用的方法是弱监督和半监督学习结合的一些算法,比如说分类任务(弱监督)和分割任务(强监督)相互促进的一些算法。因为图像级别的类别能够帮模型学到很好的图像特征提取器,而少量的像素标签能够帮助模型学好如何利用底层特征恢复出高清的分割mask。
4、CNN的模型不能从全局理解输入图像的问题:
对于这一点,所给出的答案最好的当然是基于Transformer的方案,它将输入的图像Token化,然后利用自注意力机制就能在模型的一开始使得模型能够以全局的角度去理解图片。
5、增强模型的泛化能力:
增强模型的泛化能力有很多基础的方法,比如数据增强、正则化等等,但是起到的效果是有限的。这里我们分为两种情况来讨论如何增加模型的泛化能力:
1、测试集数据不可获取:
只能从模型本身出发,迫使模型能够学习到更为鲁棒的特征;
2、测试集数据可获取(没有标签):
这显然就是无监督域适应的范围了。无监督域适应语义分割主要分为三个研究方向:
1)基于对抗学习:这一类的方法出发点在于目标域与源域在同一Encoder后编码的特征能够尽量相似。主要在FCAN与ADVENT的基础上寻求突破与创新。
2)风格迁移:这一类的方法出发点在于转换源域图片的风格使得其与目标域相似。代表方法有CycleGAN。
3)自监督学习:在目标域上形成伪标签来训练模型。
6、利用合理的上下文建模机制,帮助网络猜测遮挡部分的语义信息:
参考文章:
Adaptive Pyramid Context Network for Semantic Segmentation
Learning to Predict Context-adaptive Convolution for Semantic Segmentation
7、在网络中构建不同图像之间损失或者特征交互模块:
参考文章:
Learning Attentive Pairwise Interaction for Fine-Grained Classification
相关的方向有 co-saliency,co-segmentation等。
文章出处登录后可见!