基本内容理解的话推荐看一下这篇博客Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结,这个博主讲的很细致,比较容易理解。
这里借用一下上述博客的总结:
- 注意力可以分为两种方式分别是自主提示和非自主提示。其中非自主提示是键,自主提示是查询,物体原始向量是值。键和值是一一对应的。
- 注意力机制的评分函数可以对查询和键进行关系建模,获取查询和键的相似度匹配。其方法分为两种:加性注意力和点积注意力。常用的是点积注意力。
- 如果查询和键是同一组内的特征,并且相互做注意力机制,则称为自注意力机制或内部注意力机制。
- 多头注意力机制的多头表示对每个Query和所有的Key-Value做多次注意力机制。做两次,就是两头,做三次,就是三头。这样做的意义在于获取每个Query和所有的Key-Value的不同的依赖关系。
- 自注意力机制的优缺点简记为【优点:感受野大。缺点:需要大数据。】
我补充一下两种计算注意力的方式:
首先是加性注意力计算:
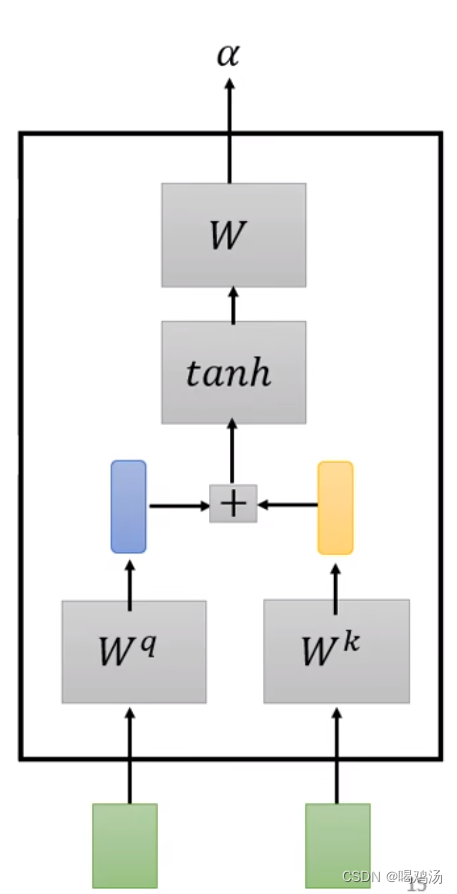
可以看到是将query与key进行线性相加后,通过tanh函数进行归一化之后得到了注意力系数矩阵。
对于点乘注意力计算
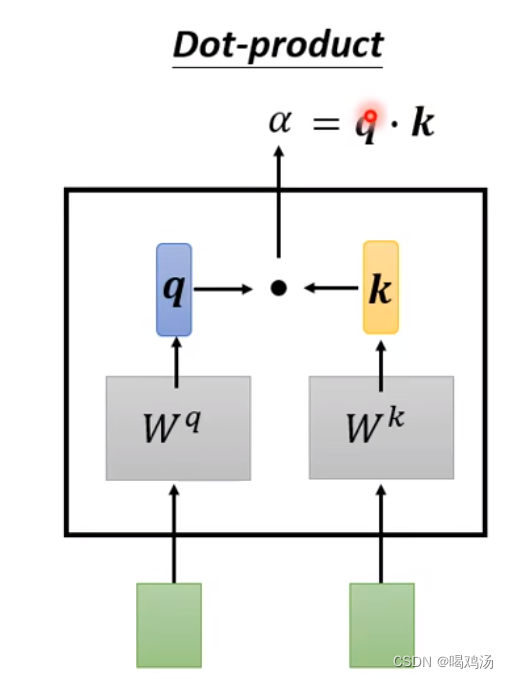
是将query与key进行相乘得到,之后会经过一层softmax进行归一化。
文章出处登录后可见!
已经登录?立即刷新