摘要
本文讲解了39个数据集,关于高空卫星图和低空无人机航拍图像。
本文汇总了25篇CVPR2020年和2021年的论文。
本文详细介绍了这25篇论文的任务是什么,难点是什么,场景是什么。
同时,本文在需要的地方解释了一些卫星图和航拍图的入门常识和前置知识,比如digital surface model的含义。
目前有许多研究生毕业论文是做CV这个领域的,模型创新十分困难,于是许多同学转而寻找场景创新。阅读本文,你可以了解到目前学界最优秀的学者在卫星图和航拍图这个领域是如何切入的,做什么任务的。通过看他们是如何寻找场景创新的,也许你就可以依葫芦画瓢,寻找到你的场景创新的灵感。
祝各位研究生都能写出论文、顺利通过答辩!
遥感=Remote Sensing;航拍=Aerial Image
遥感图像一般来自卫星,航拍图像可能来自大型飞机、无人机、直升机等。
目录
一、 高空卫星遥感地图
二、 低空无人机航拍图
三、 选场景的思路
1 高空卫星遥感地图
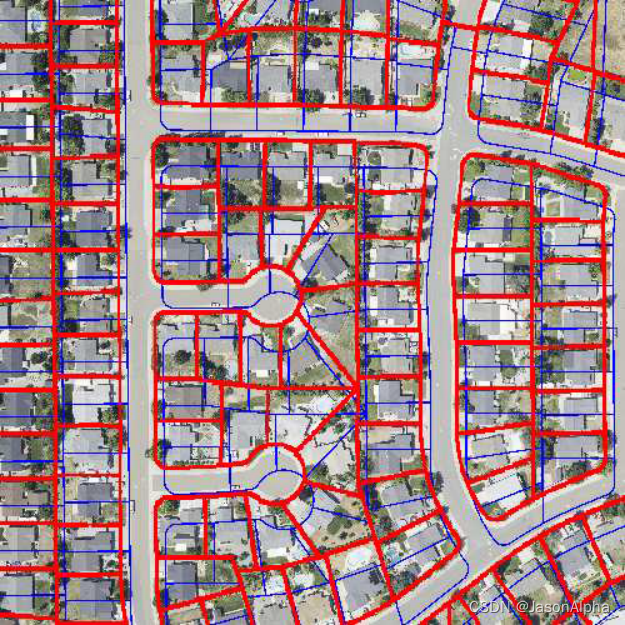
4-图像分割
东西在哪,是什么,轮廓是像素级的
[1]2020_Zheng_Cite=72_Supplementary Material of Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery
地理目标语义分割,航拍地图语义分割,遥感目标检测:检测建筑物、水域、河流、车辆、船舶
数据集:iSAID:A Large-scale Dataset for Instance Segmentation in Aerial Images
https://captain-whu.github.io/iSAID/
场景:HSR(high spatial resolution)) remote sensing imagery.
[1]什么是spatial resolution: Spatial resolution is the detail in pixels of an image or how detailed objects are in an image. .;放一个热气球在天上,热气球上带着摄像头,不断地在拍照片。随着热气球的下降,你会发现照片里面的object变得shaper了,更清晰了,也就是你的spatial resolution变得finer-更精细了。
[2] high spatial resolution:这里的high不是说你在高空拍照片,而是指的清晰度resolution。更高的清晰度,意味着这个摄像头所在的位置距离地面更近,意味着图片中有更多的detail,你这个图片所表示的这个区域gird cell size自然会更小。因此HSR一般是无人机drone拍出的照片
[3] low spatial resolution:清晰度低的,距离地面较低的摄像头拍出来的。

任务:instance segmentation
特色:largest dataset 对于HSR这个场景,而且是第一个实例分割数据集
细节:包含2,806张 HSR remote sensing images.是由multiple sensors and platforms收集的 图片的 resolutions分辨率有大有小,图片尺寸也有大有小,从800 × 800 pixels到4000 × 13000 pixels.的图片都有。一共15 categories(是 important and commonly occurring categories)。这接近三千张图片上,,一共有655,451 instances (每个类别的实例很多,每张图片上的实例很多)。在这个数据集上,你分割出来这个实例,大小的变动比较大huge object scale variation,一张图片里包含下面这三种大小的实例,small, medium and large objects。
数据集图片样例:

[2]2021_Li_Cite=30_PointFlow Flowing Semantics Through Points for Aerial Image Segmentation
航拍图像分割
三个不同的航空分割数据集上做的试验、
难点:航空图像分割是一个特殊的语义分割问题,具有一般语义分割所不具备的几个挑战性特点。其中有两个关键问题:前后景分布不均衡;复杂背景下的多个小物体。过度引入背景上下文使得模型性能下降
数据集1:iSAID dataset
在航拍图上用mask来做语义分割(车这个category用深蓝色,运动场这个category用浅蓝色表示)

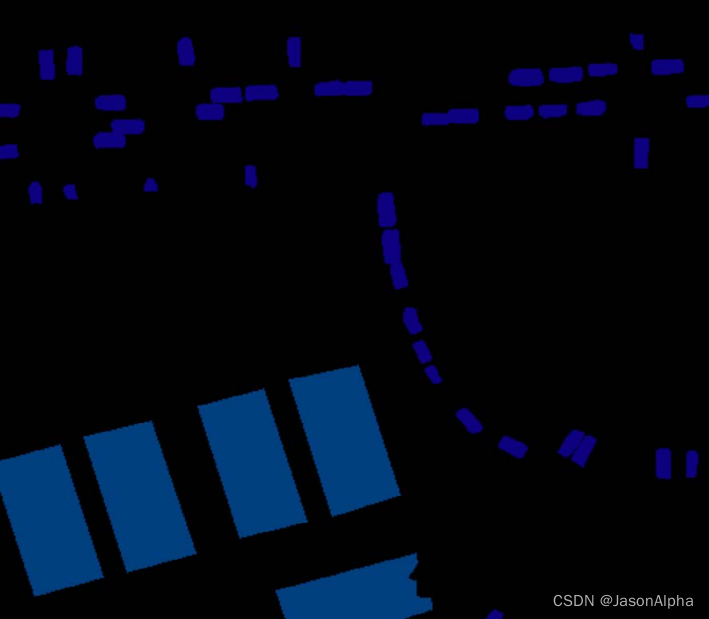
这些点有什么用啊?代表什么呀?
Visualization of sampled points for both point flows.(抽啥样啊?抽样干什么呀?)
我猜测是这样,测试集的地图是没有ground truth的,需要人工去标注,但是没那么多人力,所以用红点标记(也可能是错的)
Top: Salient显著的主要的 Flow points.(我没看出上面这个显著和主要在哪里?)

Bottom: Boundary Flow points.边界这个是可以理解的,这些点也确实是在边界

数据集2:The Vaihingen dataset.
数据集下载地址:https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx(除了这个和下一个,多伦多的数据集也有;多伦多和上面这两个地方的3D语义分割也有,3D重建也有)
场景:Vaihingen,德国的一个不知名的村庄,是一个相对较小的村庄,有许多独立的建筑和小的多层建筑
任务:语义分割,将航拍照片中的,object分割出来,进行分类,label的话有下面六种,代表土地覆盖类别,颜色也放在了后面。
①不透水面 (RGB: 255, 255, 255)
②建筑物(RGB: 0, 0, 255)
③低矮植被 (RGB: 0, 255, 255)
④树木 (RGB: 0, 255, 0)
⑤汽车(RGB: 255, 255, 0)
⑥背景 (RGB: 255, 0, 0)
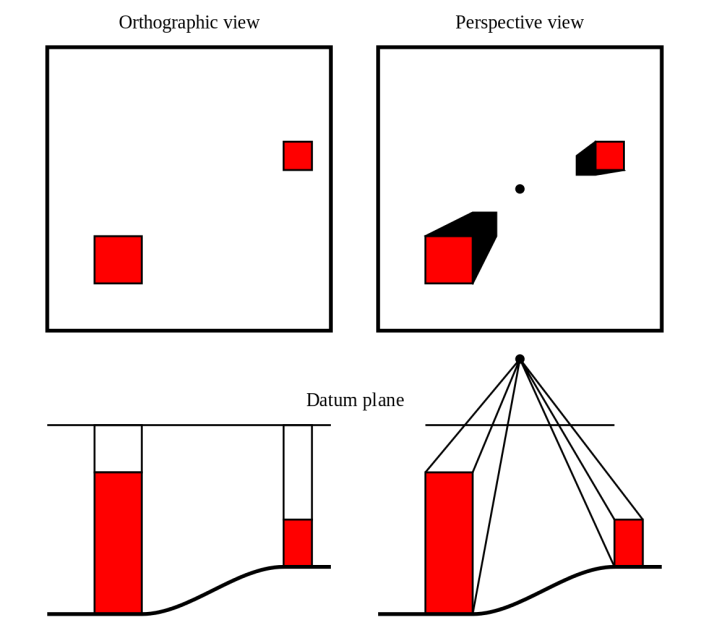
特色:数据集里的图是true orthophoto (TOP)正射影像图。TOP图是一种经过几何纠正(比如使之拥有统一的比例尺)的航摄像片。与没有纠正过的航摄像片不同的是,人们可以使用正射影像量测实际距离,因为它是通过像片纠正后得到的地球表面的真实描述。Google 地球就是使用正射影像。传统的航拍影像是perspective projection透视投影来做的图,从一点出发做投影拍摄,因为地面建筑的高度不同,如果直接用地图上的距离是不准确的。比如下面的右图,因为两栋楼的房顶高度不同,原本的距离会被高估或低估(这里我也不知道是高估还是低估)
细节:
33幅(一幅=patch)不同大小的遥感图像,每幅图像都是从一个更大的顶层正射影像图片提取的
顶层影像和DSM的空间分辨率为9 cm。;遥感图像由近红外、红色和绿色3个波段组成
把每张图片裁剪成这么多的碎片cropping into 768×768 patches.(是每张吗?)
——38张图从哪来?这个33张图来自于,切成38个patch(但是他上面说是33幅图,多了五张图,多出来的五张图是测试集–应该是分割的结果并没有公开)
样例:分割结果
给了两组数据(a) true orthophoto, (b) DSM某个多边形区域海拔高,应该是建筑物,所以就赋予建筑物的label–这个高度数据对于做分割和labeling是有帮助的。朝着C这幅图的方向去优化 (c) ground truth
DSM=Digital Surface Model,是指包含了地表建筑物、桥梁和树木等高度的地面高程模型。和DEM相比,DEM(Digital Elevation海拔高程 Model)只包含了地形的高程信息,并未包含其它地表信息(建筑物和桥梁),DSM是在DEM的基础上,进一步涵盖了除地面以外的其它地表信息(建筑物房顶和桥梁)的高程。在一些对建筑物高度有需求的领域,得到了很大程度的重视。DSM表示的是最真实地表达地面起伏情况,可广泛应用于各行各业
——这里的DSM的图,其实很粗糙,高度越高越白,高度越低约黑

数据集3:The Potsdam dataset
场景:Postdam,波茨坦,德国城市,就是签署波茨坦公告的那个地方,是一个典型的历史城市,有着大的建筑群、狭窄的街道和密集的聚落结构
任务:和上面那个都是ISPRS(the International Society for Photogrammetry摄影测量 and Remote Sensing)这个学会做的,任务和categories都是一样的。
细节:
38幅相同size的图像,其实是一副大图像切割成的

顶层影像和DSM的空间分辨率为5 cm
提供了归一化DSM,即在地面过滤之后,每个像素的地面高度被移除
分割样例

把图片裁剪成这么多的碎片896×896 patches.
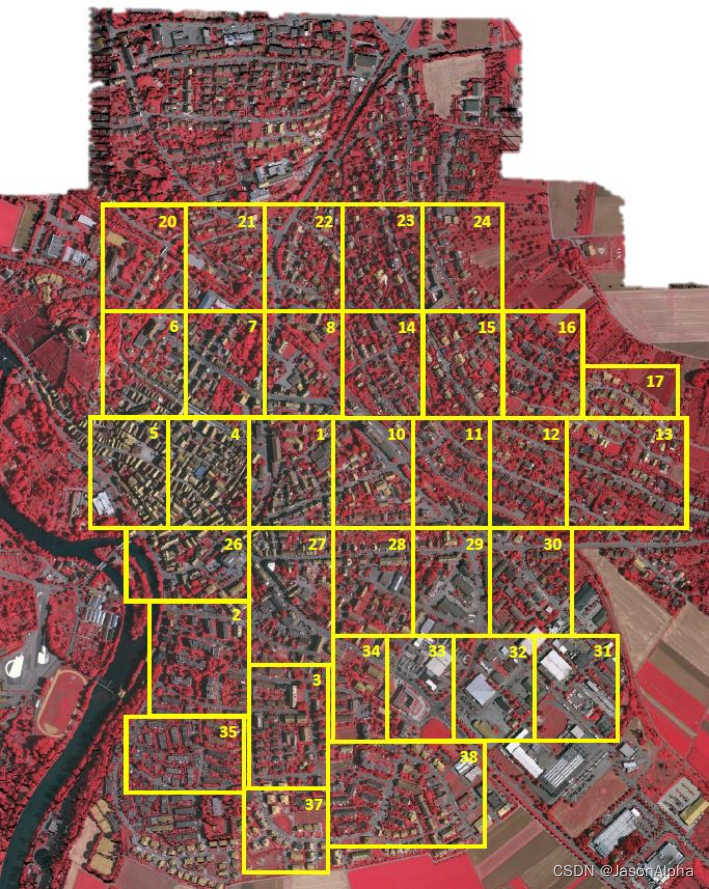
数据集4:Cityscapes
场景:德国50个城市的城市街景street scenes,三个季节具有季节特色的图片。
任务:语义分割,类别如下
特色:
图片和large,5000张精细标注的图片fine annotations(实际用了1525张图,因为这些图比较fine精细),20000张粗略标注的图片annotated images with coarse annotations
类别多、质量高的像素级语义分割标注,high quality pixel-wise annotations for 19 classes(实际是有30个class)。这1500+张图片的总的annotation数量为2975,500
图片清晰度高-像素高,像素值=2048 × 1024。
拍照时间为白天,天气状况为Good/medium
数据集图片样例

数据集5: BDD100K (Berkeley DeepDive)
https://doc.bdd100k.com/usage.html
https://arxiv.org/abs/1805.04687
场景:road scene街景,driving videos行车记录仪拍下的录像
任务:可以做语义分割,也可以做目标检测
特色:
8000张图
various weather conditions,time, and scene types.
细节:
数据集图片样例:

数据集6:ADE20k
类似的数据集还有SUN和Places
https://groups.csail.mit.edu/vision/datasets/ADE20K/
场景:房屋内部图片、行车道路图片、酒吧内部图片
任务:语义分割
特色:
他这个类别的annotation做的特别细,比如一个水瓶bottle,里面的零件都会被识别出来,比如base水瓶底座,cap水瓶上面的帽子,label水瓶上的塑料纸,neck水瓶的脖子
scene parsing dataset
类别很多,150 classes;图片多达20k张
数据集图片样例

他在展示performance score的时候除了展示了上面这三个数据集,也列出了Param(M),GFlops(G),这两个表示什么意思?是新的数据集吗(但是论文和supp都查不到这两个东西是代表一个新的数据集还是一个组件数据集的方法)
[3]2020_Tan_Cite=41_VecRoad: Point-Based Iterative Graph Exploration for Road Graphs Extraction(Tan,2020)
(中国的城市没做过,我把卫星图拿下来,做了叫不叫创新,他们主要拿着美国纽约)
数据集:RoadTracer Dataset
场景:aerial image 航拍图 the urban center of 40 cities across six countries.
任务:道路轮廓与道路网络提取extraction of road networks from aerial images,地点
特色:暂无
细节:每张图表示的地表实际面积是:24 km2 coverage per image。图片的清晰度和每个像素代表的地面实际距离:Each aerial image contains 4096×4096 pixels with the precision of 60 centimeters per pixel.——数据来源:The aerial images are collected from Google(从谷歌拿到的是航拍卫星地图), and the ground-truth is from Open-StreetMap (OSM) project(这上面标记好了真实的道路的线)。——label的标记是像素级的–和语义分割的ground-truth是一样,OSM is rather pixel-labeling images,
卫星图数据集-RoadTracker:https://roadmaps.csail.mit.edu/roadtracer/
Ground truth:https://www.openstreetmap.org/#map=16/22.5316/114.0517

数据集图片样例
Ground truth
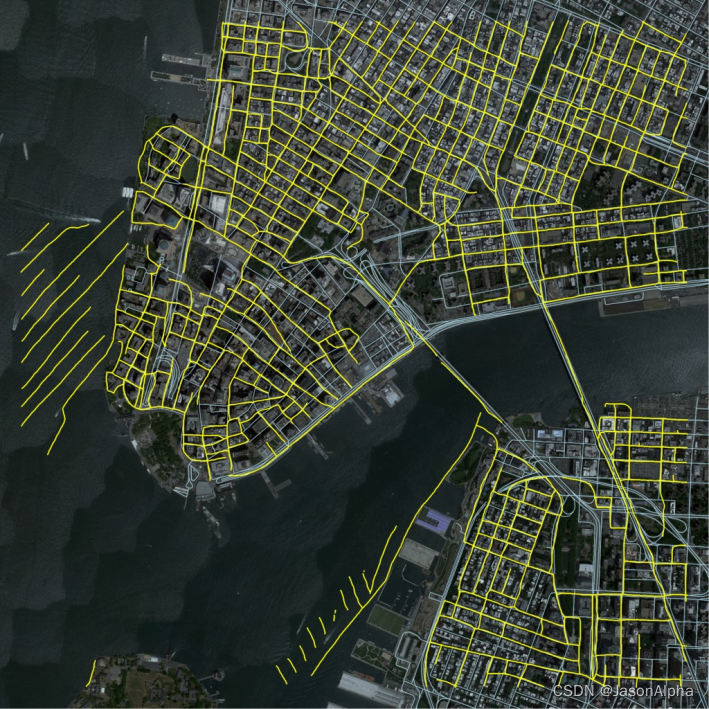
Our segmentation
[4]2020_Veeravasarapu_Cite=2_ProAlignNet Unsupervised Learning for Progressively Aligning Noisy Contours(Veeravasarapu,2020)
(不提供代码,不提供他手动标记的数据集)
任务:在图片有噪声干扰的情况下,实现图像轮廓线对齐contour alignment(这东西有什么用呢?)
数据集1:contourMNIST–toy dataset,一开始的时候做一个测试实验
改造adopt了MINIST数据集。将MINIST数据集的7w张黑白gray-scale图片的清晰度resolution从28×28放大upsampled to 128×128,把这些图转成了轮廓图converted as a contour轮廓 image,标记图像形状的边界或外形线
数据集2:Geo-parcel
场景:界定公有和私有土地边界identify public and private land property boundaries.,Parcel是一小块土地的意思–就是这里要界定的这个土地边界
任务:使得轮廓图和卫星图对齐aligning geo-parcel data to aerial images,轮廓图和卫星图叠加在一张图上,从而使得轮廓变得更加准确(最后一句是我猜的)。ground truth提取了 大马路road和人行道side work
痛点:parcel这个轮廓二值图和卫星图拍摄时候的角度略有不同due to several differences in their collection processes,因此会出现对齐上的不准确misalign,对齐上的偏移大概10 meters。下面那个图展示了偏移。
细节:
1189 对 航拍图和土地轮廓二值图的 aerial and parcel image pairs,在加州Redding的居民区residential areas
在验证集,作者手动对齐了27对parcel-aerial image,这27章图上有7000个parcel土地块上的多边形
Parcels这个数据集上的图是矢量图shapefifiles,图上是有 GPS经纬度坐标的 lat-long gps coordinates。(能不能给张数据集样例给我看看?)。这个有GPS经纬度的坐标,可以把这些土地地块的形状通过透视投影影映(perspective projection)射到航拍图的坐标系。上面这个映射的过程做出来的图,是一个二值轮廓图binary contour images(是轮廓的用1表示,不是轮廓就是0)。
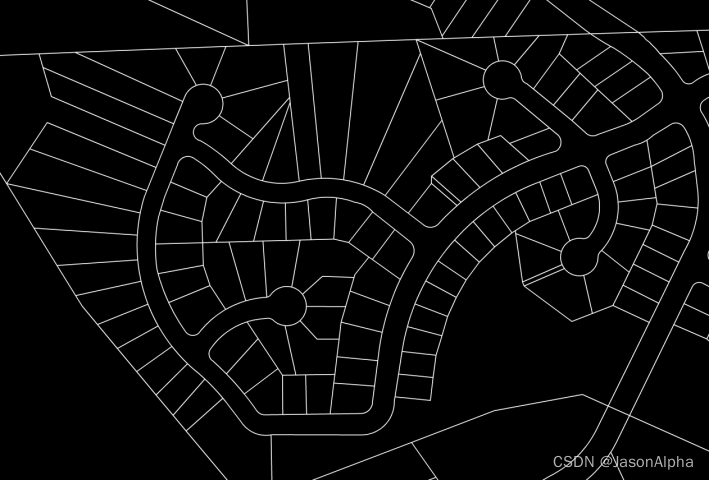

。
这是before alignment时候的一个图,展示了当时的的misalign
红色这个是ground truth,蓝色的这个是parcel这个轮廓二值图(parcel contours)直接覆盖上来划分的这个边界
右边对齐的很好,左侧就明显的偏了,像平移的一样。(原因是parcel这个二值边界图和卫星图的拍摄角度略有不同,所以对齐的就略有不同,所以)
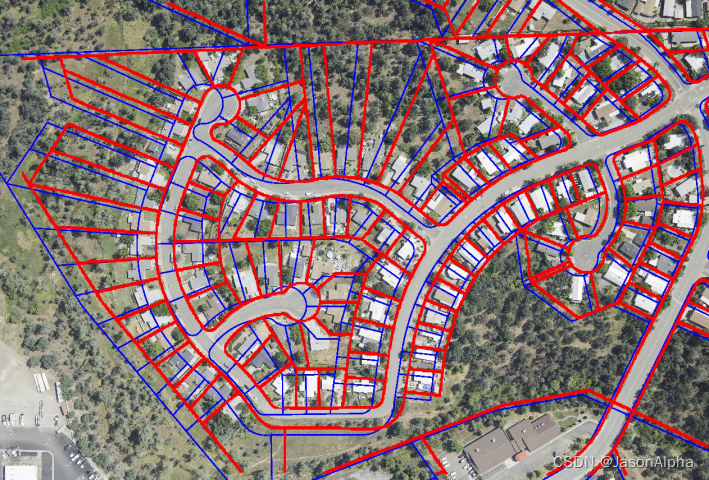
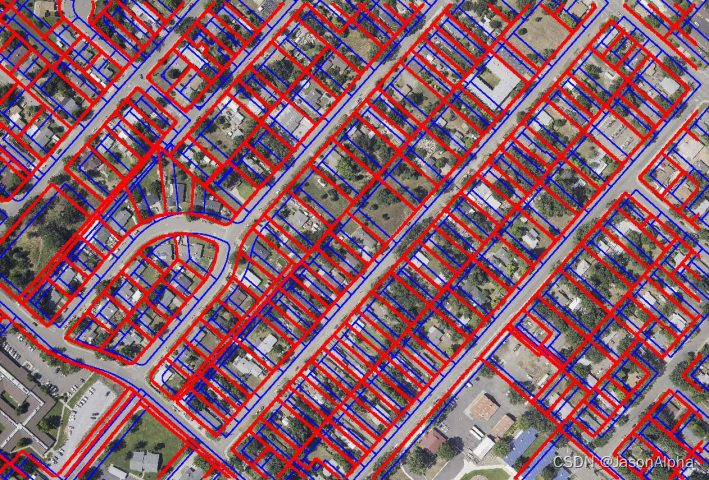
数据集图片样例
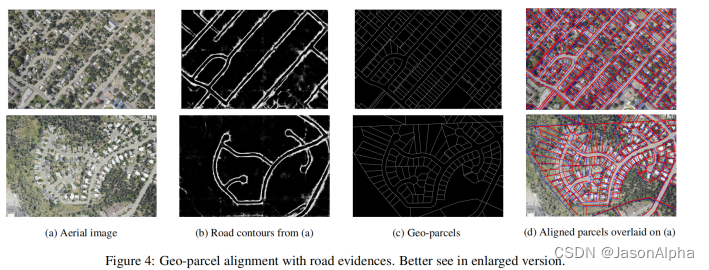
这三个例子,是说二值图和卫星图直接叠加是不行的,所以才有要改进的地方,也是这篇文章要解决的问题。

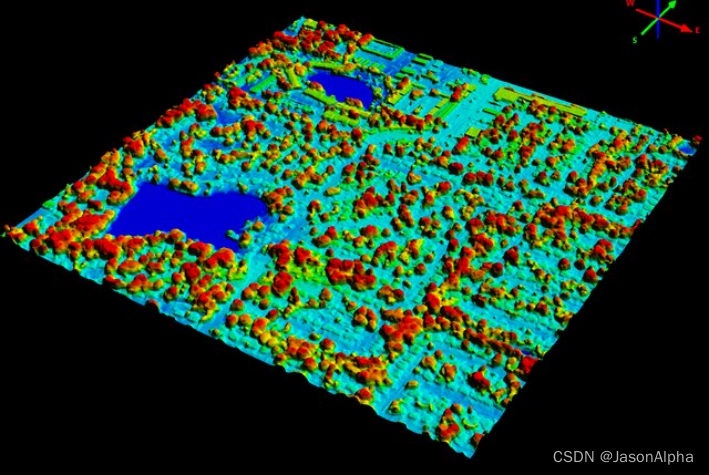
4-建筑三维重建
[1]2020_Liu_Cite=31_A Novel Recurrent Encoder-Decoder Structure for Large-Scale Multi-View Stereo Reconstruction From an Open Aerial Dataset
(文献综述写了一些3D建筑重建的数据集)
代码&数据集 | http://gpcv.whu.edu.cn/data/
WHU Dataset
场景:贵州湄潭县的城市建筑3D重建(像模拟城市那样),采集是用一个安装在无人机上的5个视角的摄像头采集的。oblique five-view camera rig mounted on an unmanned aerial vehicle (UAV).
任务:城市建筑物3D重建
细节:
1,776 virtual aerial images
each 5376 × 5376 pixels in size.
覆盖地域:covered an area of about 6.7 × 2.2 km2 overMeitan County, Guizhou Province in China with about 0.1m ground resolution.
涉及的senario dense and tall buildings, sparse factories, mountains covered with forests,and some bare ground and rivers.
数据集图片样例:
像模拟城市那样


根据建筑物的高度做的surface model,标明每个点的高度


[2]2020_Lu_Cite=24_Geometry-Aware Satellite-to-Ground Image Synthesis for Urban Areas
场景:重建的是伦敦市的建筑3D图。 centered in the City of London
任务:从高空卫星地图来用模型制作的制作的3D街景图尽可能的逼近gound truth的panorama全景图
特色:
细节:
区域面积:4km×6km area
数据集图片样例:
左边是我们的raw material,右边是根据卫星图重建出来的3D街景图
Ground truth是由stereo matching生成的,他们也下载了谷歌街景图street-view images via the Google Street View Static API1
街景图的数量是三万张
这些图都带有with longitude, latitude, and orientation information

[3]2020_Mahmud_Cite=27_Boundary-Aware 3D Building Reconstruction From a Single Overhead Image
The 2019 IEEE GRSS Data Fusion Contest dataset(GRSS DFC 2019)
http://www.classic.grss-ieee.org/community/technical-committees/data-fusion/2019-ieee-grss-data-fusion-contest-2/
场景:在美国的一些地方做的Jacksonville, Florida and Omaha, Nebraska, United States.
细节:
高空卫星图images, semantic segmentations, and nDSMs data surface model表示卫星图上建筑物高度的图
图片包括:satellite images, airborne lidar, and semantic labels
数据集图片样例:
从左到右,卫星地图,DSM标记高度,最右边就变成立体的了

USSOCOM Urban 3D dataset
The USSOCOM Urban 3D Competition
场景:是哪里的城市地图确实没说
任务:
特色:
细节:
Images and nDSMs
360 km of terrain and containing roughly 157,000 annotated building footprints
数据集图片样例:
从高度图

重建成这样
The SpaceNet Buildings Dataset v2
场景:这些城市的卫星图都有Rio de Janeiro, Las Vegas, Paris, Shanghai, Khartoum
任务:
building footprint detection,把建筑物那个块给他分割出来
但是这篇论文用来做3D重建了,我不知道ground truth是怎么来的?自己采集的?
细节:
建筑数contains over 302,701 building footprints,
这个公司高达3/8的卫星图都拿过来了。3/8-band Worldview-3 satellite imagery at 0.3m pixel res.,
across 5 cities (Rio de Janeiro, Las Vegas, Paris, Shanghai, Khartoum), and covers areas that are both urban and suburban in nature.
数据集图片样例:
footprint detection,全给你分割出来了

从单幅航拍图像中进行边界感知的三维建筑重建。
[4]2020_Zhang_Cite=29_Conv-MPN: Convolutional Message Passing Neural Network for Structured Outdoor Architecture Reconstruction
场景:这些城市的卫星图Atlanta, Paris and Las Vegas
任务:(确定要做这个再去看论文,弄懂这个,肯定写的很清楚,因为有些模型也会分错,他为了纠正划分错误花了很多力气,他不会不说清楚ground truth是怎么定下来的)到底是做什么,按照什么标准来分割?为什一个楼探出
细节:
RGB卫星图来自于SpaceNet,也是这个比赛的数据集SpaceNet Challenge
数据集图片样例:



3-地物属性-比如高度-预测
建筑三维重建的一个属性
[1]2020_Christie_Cite=15_Learning Geocentric Object Pose in Oblique Monocular Images
预测地物的高度和姿态
US3D
场景:美国两个地方的地图Jacksonville, Florida and Omaha, Nebraska,Atlanta, Georgia.
任务:predict geocentric pose,就干两件事,(1)距离地面的高度object's height above ground and (2)相对于重力而言的方向orientation with respect to gravity.
细节:
2019 Data Fusion Contest
数据集图片样例
颜色越深,就越高,
蓝色表示朝向的背面

SN4
场景:美国这地Atlanta, GA using
任务:原始数据集是用来做分割或者目标检测的,然后这个人有拿去做地物属性
特色:
细节:
数据集图片样例
原图

语义分割做的挺好的

目标检测,大的建筑物识别出来了,也有的没识别出来
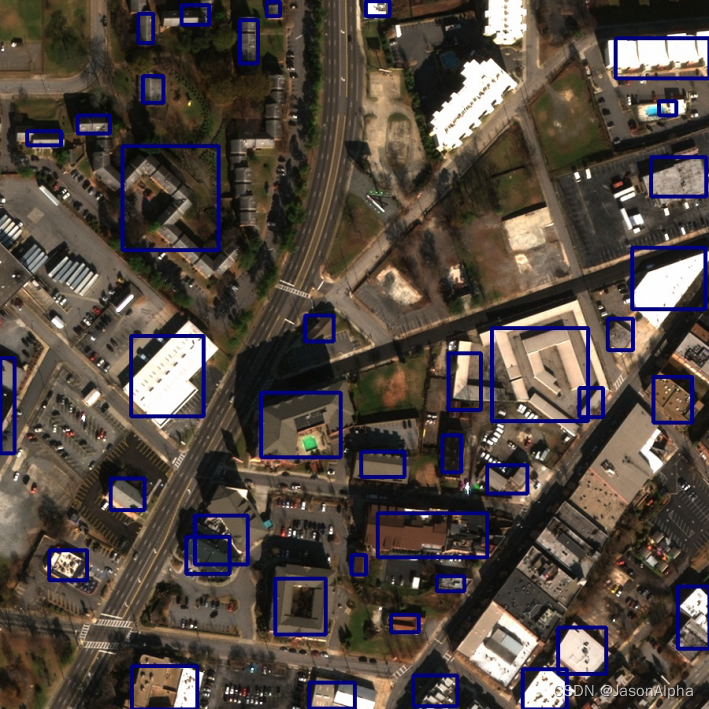
[2]2020_Shi_Cite=51_Where Am I Looking At? Joint Location and Orientation Estimation by Cross-View Matching
通过跨视角匹配进行联合位置和方向估计
CVUSA
场景:每一条数据由3幅图组成(1)全景图panoramas(2)aerial images
任务:3D场景重建
细节:
ground images全是全景图panoramas,all the ground and aerial
images are north aligned.
35, 532 training ground and aerial pairs and 8, 884testing pairs.
数据集图片样例:
森林中间一条路,两边有别墅,你站在中间,把这个场景重建了
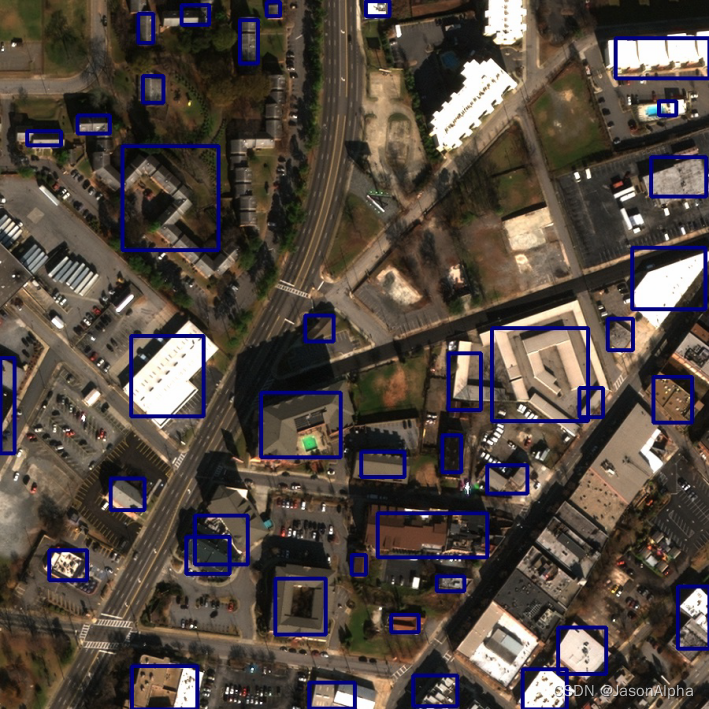

CVACT
一切同上


[3]2021_Derksen_Cite=4_Shadow Neural Radiance Fields for Multi-view Satellite Photogrammetry
多视角卫星摄影测量(我不知道他在测量什么,是地面上建筑的距离吗?)satellite imagery
WorldView-3
就是卫星地图,该怎么测量就怎么测量

3-时间序列
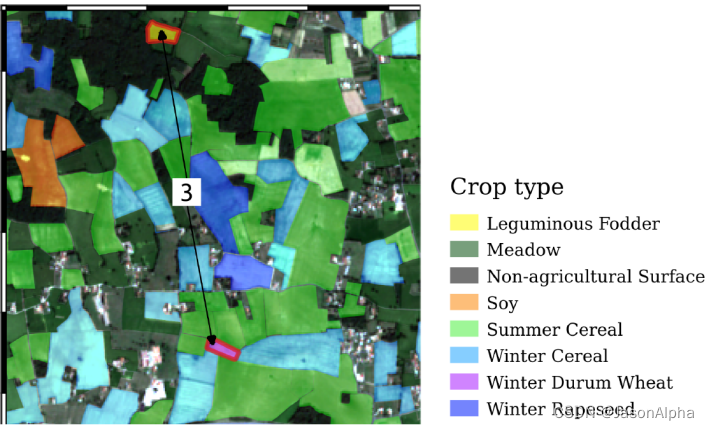
[1]2020_Garnot_Cite=63_Satellite Image Time Series Classification With Pixel-Set Encoders and Temporal Self-Attention
卫星图像时间序列分类
Sentinel-2 time series
是个农业场景,图片里的object的category有牧场Meadow Winter Cereal, SummerCereal, 葡萄藤Grapevine。
被分割成这样
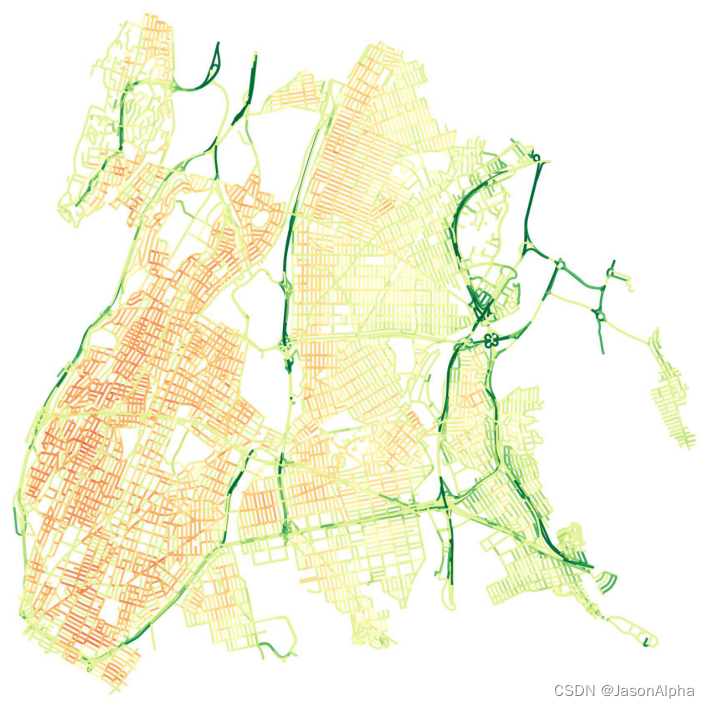
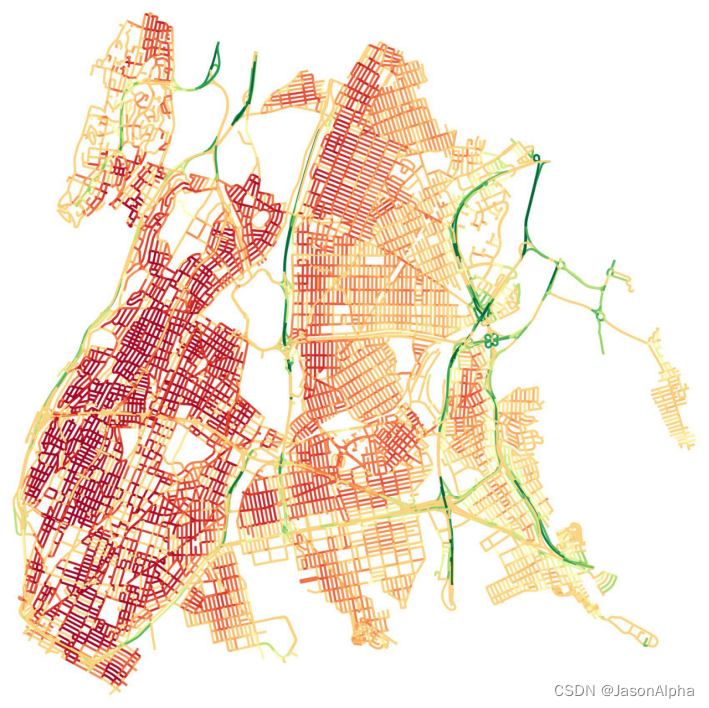
[2]2020_Workman_Cite=9_Dynamic Traffic Modeling From Overhead Imagery(Workman,2020)
The Dynamic Traffic Speeds (DTS) dataset
场景:纽约市这个区域的堵塞地图 in The Bronx, New York City.(高德上有这个功能,已经做的很完善了)
任务:预测地图上每条道路的车流速度(表示交通通畅度,是否堵车),红色表示车流速度慢,绿色表示车流速度快–通畅;通过航拍影像建立动态交通模型
数据集图片样例
下面这张图是周一凌晨四点纽约交通通畅度地图,除了西边地区比较堵,东边不堵
下面这张图是周一早八点纽约交通通畅度地图,大陆不堵,其他全堵,西边比东边堵
[3]2020_Salem_Cite=14_Learning a Dynamic Map of Visual Appearance
基于航拍图像的视觉表面属性的动态映射(不懂是什么场景)
Cross-View Time (CVT) Dataset
细节:
每组数据都包括(1)geotagged ground-level images(2)拍照图片corresponding capture time,(3)co-located overhead images——最最大的特色是,春夏冬三个季节、一天的早上 正午、凌晨都有
数据集图片样例:
(1)ground image

(2)co-located overhead images
清晨八点-太阳还不大

9:30太阳光起来了

大正午头13:35

下雨的中午一点

下雪的太阳不大清晨,雪不大

雪很厚的凌晨4:30

2 低空无人机航拍图
4-目标检测Detection画方框
东西是什么,在哪,轮廓是方框
[1]2020_Pan_Cite=124_Dynamic Refinement Network for Oriented and Densely Packed Object Detection(Pan,2020)
SKU110KR Dataset
场景:超市货柜thousands of supermarket stores
任务:
特色:
SKU110K有11, 762 images,标注的实例有1, 733, 678 instances
various scales, viewing angles, lighting conditions,and noise levels.
图片的清晰度极高,大小是百万像素,All the images are resized into a resolution
of one megapixel
任务有挑战性:实例的排布十分紧密-分割上是有难度的。Most of the instances in the dataset are tightly packed(挤在一起,塞满)
细节:
extended version of SKU110K。基于这个数据集做了很多改动
数据增强,转换图片角度,丰富了数据集。大多数图的角度。typically of a certain orientation in the rage of [−15◦, 15◦]。perform data augmentation by rotating the images by six different angles, i.e., -45◦, -30◦, -15◦, 15◦, 30◦, and 45◦.。
数据集图片样例:

[2]2020_Yang_Cite=77_Reverse Perspective Network for Perspective-Aware Object Counting
UAV-based Vehicle Counting Dataset—自己起名叫UAVVC
(文章写得很好,很清楚,想要了解什么,很快就能让你找到)
场景:数无人机(=Unmanned Aerial Vehicle)的个数,the vehicle counting task
任务:
特色:
数据是自己收集的,不是公开数据集,(目前作者不开放数据集的下载)800张照片
场景丰富:50 different scenarios for vehicle counting
标记更详细-Precise annotations:manually annotated with 32,770 bounding boxes,用的不是那种粗略的点标记instead of traditional point annotations
拍摄图片的角度perspectives多,front-view in high latitude, front-view in low latitude, side-view, and topview.
才不同天气收集了图片,in different weather conditions,sunny, raining, fog,night, and raining night(做上面这些的目的:increase the diversity of the dataset and make it closer to the real traffic circumstances.)
frame是指的bounding box
(假设说,我这个场景创新,已有的数据集无法满足我的需求–或者已有数据集因为种种原因并不适合我用的这个模型,需要去自己收集数据的时候,可以参考这些看过的数据集的优点,尽可能我都要占)
细节:
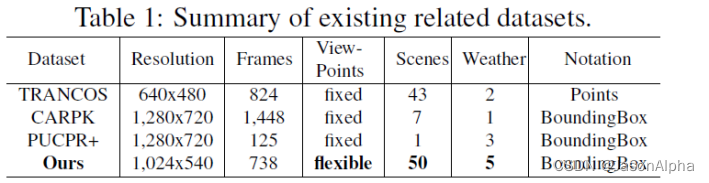
the vehicle counting task有下面几个数据集。(1)固定摄像头拍下的照片数据集:TRANCOS v3(2)用UAV拍摄的图片数据集:CARPK,PUCPR+。为啥不用他们呢?因为他们的circumstances都只有traffic这一情景,太单一了。而且图片大小的变动variation也太小了
数据集图片样例:从不同角度拍摄的道路图片,他把道路上所有的车都框出来,然后输了有多少个框-车,标记在图上

ShanghaiTech Dataset
场景:拥挤人群的人数计数crowd counting,都是人很多的那种拥挤场合,–数出人数的难度也比较大
任务:行人数量统计pedestrian counting
特色:
图片较多:1,198 images
人太密集了,画bounding box会重合在一起一大堆,根本看不清,更加没法计数。所以在每个人头顶的中央标上一个圆点,表示检测到了Each person in a crowd image is annotated with one point close to the center of the head.
对人的标记的annotation也比较多,the dataset consists of 330,165 annotated people
细节:
每张图的拍摄角度和清晰度是不同的different perspectives and resolutions
数据集有两部分,part-A是从互联网上收集来的,part-B were collected on the busy streets of Shanghai.
数据集图片样例:首先人头标红点的这个图没显示,告诉你场景都是很拥挤的,然后把多少人的ground truth数出来了,预测的是多少个也写了

WorldExpo10 Dataset
类似的crowd segmentation,crowd counting的数据集CUHK dataset
场景:这些拥挤人群的场景,马路road,排队queue,广场square,前面几个混合

任务:
可以做图像分割,分割出人群拥挤程度的区域,(high = red, medium = yellow, low = green)。segmentation的重要性Crowd segmentation is the first step towards understanding crowds, because it answers the question of where the crowds are. Crowd counting, tracking, and behavior analysis are mainly based on the results of crowd segmentation,
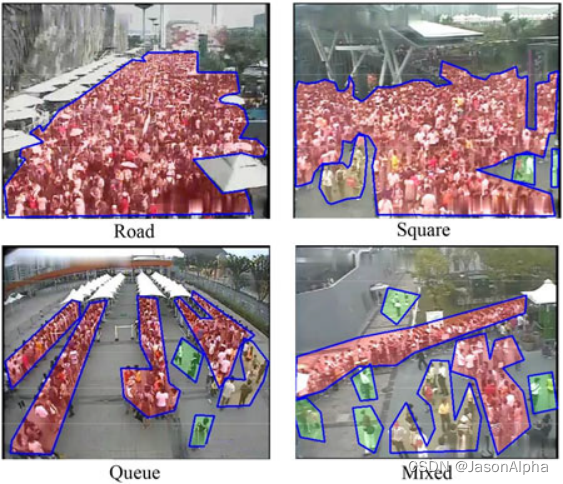
在这个数据集上还能做的其他任务
(a) 背景提取Result by background subtraction used
(b)optical flow,光流模型; 表示的是相邻两帧图像中每个像素的运动速度和运动方向;表示这个人接下来往什么方向走
(c)feature point tracking: image sequence上的motion information
(d)pedestrian detection
(e)Result by our data-driven approach-行吧,我不懂


特色:
Bounding box标记较多:3,980 annotated frames
做segmentation的时候总共从图片中分出了这么多个不同拥挤程度的多边形53 637 crowd
segments with polygon boundaries
细节:
他的annotate是区域级的不是像素级的,annotated at the region level,人工做的。
数据集图片样例:
UCSD dataset
场景:监控摄像头拍摄的图片,不是移动摄像头stationary surveillance cameras,这个摄像头的位置是一个朝向pedestrian walkways的摄像头
任务:识别 Abnormal events或者叫Anomaly (具体说就是 bikers, skaters, small cars, and people walking across a walkway or in the grass that surrounds it.轮椅和残疾人经过,A few instances of people in wheelchair were also recorded. All abnormalities are naturally occurring, i.)还是打方框,做目标检测
细节:
Bouding box 有 2,000 frames
所有照片拍摄角度都一样:same perspective
街上的人流密度是不断变化的,不是说有个固定的人流密度一直是这样,he crowd density in the walkways was variable,有时候crowd,有时候sparse

[3]2021_Han_Cite=85_ReDet: A Rotation-equivariant Detector for Aerial Object Detection
航空影像检测,
DOTA-v1.0、DOTA-v1.5 和 HRSC2016 几个具有挑战性的航空图像数据集,
DOTA-v1.0
场景:卫星航拍图,collected from the Google Earth, GF-2 and JL-1 satellite provided by the China Centre for Resources Satellite Data and Application, and aerial images provided by CycloMedia B.V. DOTA
任务:oriented object detection(没查到解释,确定我是做这个方向的,我再去搞懂)
细节:
2806 large aerial images
with the size ranges from 800 × 800 to4000×4000 and
188, 282 instances
among 15 common categories:
类别信息:Plane (PL), Baseball diamond (BD), Bridge (BR),Ground track field (GTF), Small vehicle (SV),Large vehicle(LV), Ship (SH), Tennis court (TC), Basketball court(BC), Storage tank (ST),Soccer-ball field (SBF), Roundabout(RA), Harbor (HA), Swimming pool (SP), and Helicopter(HC).
数据集图片样例:
航拍图中的飞机
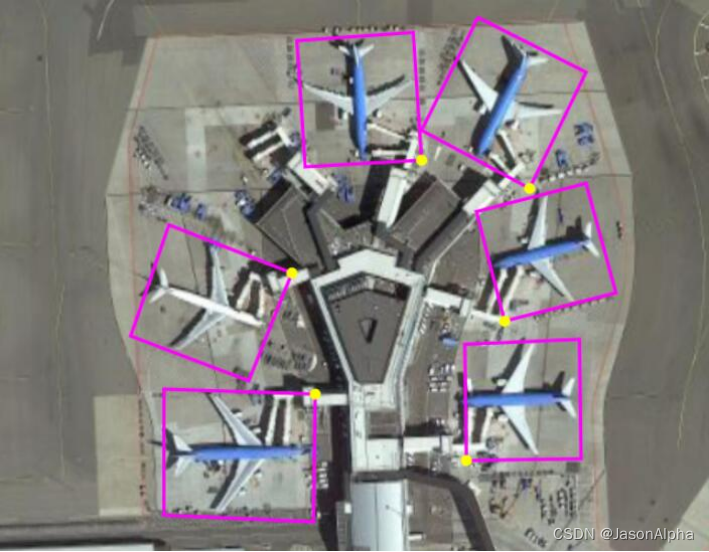
航拍图中拖着集装箱的大卡车

DOTA-v1.5
场景:是这个比赛发布的数据集DOAI Challenge 2019
特色:
有很多极端小的实例,是很难分割的extremely small instances (less than 10 pixels).
训练的时候很stable,but stable during training
细节:
with a new category, Container Crane (CC)
contains 402, 089 instances.
HRSC2016
(我们可不可以从谷歌地球上自己采集一些图片,识别一些稀奇古怪的东西,作为场景创新?)
场景:从谷歌地球上收集的航拍图collected from Google Earth.
任务:ship detection
细节:
1061 aerial images with the size ranges from 300 × 300 to 1500 × 900.
OBB annotations(不知道具体是什么,从挑选场景的角度说知道这个是什么,没多大用)
数据集图片样例:
把船在卫星图上用方框标出来

[4]2021_Ashraf_Cite=11_Dogfight: Detecting Drones from Drones Videos
(无人机追踪的用途就是像大雁南飞那样,后面的无人机可以)
(文献综述简单明了-写的不错,方法用了attention比较新)
难点:来源和目标无人机的不稳定运动、小尺寸、任意形状、大强度变化和遮挡使得该任务具有相当的挑战性。
NPS-Drones
场景:美国海军收集的published by Naval Postgraduate School (NPS)
任务:把图片中的无人机找到,并标个方框
细节:
contains 50 videos
that were recorded at HD resolutions(1920×1080 and 1280×760)
using GoPro-3 cameras
mounted on a custom delta-wing airframe.
The minimum,average and maximum size of drones are 10 × 8, 16.2 ×11.6, and 65 × 21, respectively.
The total number of frames in the dataset are 70250.
数据集图片样例:
用肉眼,即使你把图片全屏,也很难找无人机的位置。所以这个应用场景是很有价值的。因为人做不了这个事
但是我不知道,他这个方框是怎么标上去的,All right, it dosen't matter


FL-Drones
场景:indoor and outdoor的照片,照片里有个小小的无人机
任务:把图片中的无人机找到,并标个方
特色:
非常有挑战性、做起来很难,因为extreme illumination, pose, and size changes.
无人机在图片中很小,都mix在一起get mixed up in the background due to small sizeand
光照很强,看不清无人机在哪intense lighting conditions
背景复杂多样,这个模型得能在多种情境下都能吧无人机找到,complex background.
细节:
flying drones have variable shapes, and their shape is barely retained even in consecutive frames
The minimum, average, and maximum sizes of drones are: 9×9, 25.5×16.4, and 259×197, respectively and frames resolutions are 640×480 and 752×480. This dataset contains 14 videos with a total of 38948 frames
数据集图片样例:


3-跟踪任务(应该和目标检测合并)
找一个东西在哪,这个东西在移动
[1]2020_Li_Cite=173_AutoTrack: Towards High-Performance Visual Tracking for UAV With Automatic Spatio-Temporal Regularization
无人机跟着一个人的照片数据集,人在就显示在,不在就显示不在
DTB70
场景:
任务:
追踪无人机drone tracking,These sequences mostly focus on tracking people and cars,也有无人机
特色:
无人机大小不同various cluttered scenes(是说场景堆在一起?场景怎么堆在一起?) and objects with different sizes as well as aspect ratios are included.
高速运动的时候拍下的这些照片,图片是很糊的,识别和追踪起来就困难,primarily addresses the problem of severe UAV motion.
细节:
composed of 70 difficult UAV image sequences,
manually annotated the ground-truth bounding boxes in all video frames.
数据集图片样例
拍摄的无人机在高速运动,拍出来的照片很糊的,所以追踪上是有难度的
这张图片里还有其他的小赛车,也应该打方框

追踪人,只是标了一个

追踪无人机

农业场景,养的牛羊,数数

、追踪在海上冲浪的人,看看有多少个

篮球场多少个人在打球,是不是违反了Cov-19的管控条例,说好了不让聚集的
无人机进行巡逻,装个摄像头,保安不用出去走路那么费劲就巡逻了一遍,确认没有打架的、小偷爬楼,特别好

UAVDT
https://sites.google.com/view/grli-uavdt/%E9%A6%96%E9%A1%B5
场景:
任务:
(1)object detection, (2)single object tracking,(3)multiple object tracking
之前的数据集是,针对某一特定任务收集的,比如这个数据集只做无人机拍出照片里面的的目标检测,比如只追踪一个object。但这个数据集三个都能做
特色:
场景比较多、比较复杂complex ,emphasizes vehicle tracking in various scenarios.
这样做的目的是提高模型泛化性,使得我的模型不仅仅适用于traffic senario-大马路上,也能到森林公园里用,到海滨浴场用
以下这些senario都很多变动:Weather condition, flying altitude and camera view
有14个场景变动因素。up to 14 kinds of attributes (e.g., weather condition, flying altitude, camera view, vehicle category, and occlusion
高速运动的时候拍下的照片,很糊,camera motion
里面的object很密,high density
里面的object很小small object
细节:
Selected from 10 hours raw videos,
about 80, 000 representative frames are fully annotated with bounding boxes
数据集图片样例:
右下角标记了senario,白天还是晚上,天气怎么样?有没有frog雾、下没下雨rain,视角是front view还是side view,高度是特别高还是中等还是低
目标检测,小汽车 car和公交车 bus都标出来了

UAV123@10fps
2016_Mueller_Cite=1100_A Benchmark and Simulator for UAV Tracking
(还有这些目标追踪数据集:OTB50, OTB100, VOT2014,VOT2015, TC128, and ALOV300++
)
无人机拍摄出的图片的数据集,知乎一个人汇总的很好:https://zhuanlan.zhihu.com/p/421968291
场景:各种场景都有
任务:目标检测,画方框,把bike,building,car,truck,person,wakeboard水上滑板,UAV,boat船
数据集图片样例:

VisDrone2018-test-dev
2018_Zhu_Cite=94_VisDrone-DET2018: The Vision Meets Drone Object Detection in Image Challenge Results (这篇文章里汇总了很多现存数据集)
首页
场景:traffic senario也有,运动场也有,高空图像也有,低空图像也有
任务:识别行人pedestrian,汽车car,摩托车摩托车,三轮车
数据集图片样例:

[2]2020_Wen_Cite=21Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark
https://github.com/VisDrone/DroneCrowd
(梳理了存在的,人群识别和计数的数据集)
DroneCrowd
作者称这是迄今为止最大的数据集,其中包含了用于密度图估计、人群定位和无人机跟踪的头部标注轨迹。
场景:自己收集的,用drone-mounted安装好的cameras收集的。wide range of scenarios, e.g., campus, street cameras,park, parking lot, playground and plaza
任务:
(1)数人数Crowd counting and 估计密度density map estimation
(2)拥挤人群的定位和追踪.
特色:
细节:
The videos are recorded at 25 frames per seconds (FPS) with a resolution of 1920×1080 pixels.
The maximal and minimal numbers of people in each video frame are 455 and 25 respectively。and the average number of objects is 144.8.
标记量巨大:more than 20 thousands of head trajectories of people are annotated with more than 4.8 million head points in individual frames of 112 video
成本很高,20个行业专家复核了annotation2个月才搞定:Over 20 domain experts annotate and double-check the dataset using the vatic software for more than two months clips.数据量大,质量高。
数据集图片样例:
三种场景下,人群的运动轨迹

下面是四种模型,上面是估计拥挤人群在的地点-目标检测,下面是人群的移动轨迹

[3]2022_Zeng_Cite=9_Visual Reaction: Learning to Play Catch With Your Drone
预测物体轨迹,并使无人机接住运动物体
场景:living room scenes of A12-THOR
https://ai2thor.allenai.org/(是一个3D虚拟空间,十分卡通的逼真)
任务:有一个发射器launcher向空中扔东西 throws objects in the air 力度不同with different forces in 方向不同 different directions。(S1)预测运动轨迹predict the future trajectory of the object,预测的依据是:过去运动轨迹的观测数据the past observations。(S2)去接take actions at each timestep to intercept the object。那么什么叫接住了呢?catches the object, i.e. the object lies within the agent’s top-mounted basket, before the object reaches the ground.
特色:
每一条数据(每次抛出、试图去接)都保证了随机性,在房间的任何一个位置。For each episode, the agent接东西的那个小车 and the launcher还有拍图片的无人机drone都 start at a random position in the environment
这样保证了轨迹预测和接住东西这个算法的泛化性较好,在各种场景都适用,具有通用性,才有价值。
细节:
扔东西的这个场所一共有30个30 scenes in total
数据集图片样例:
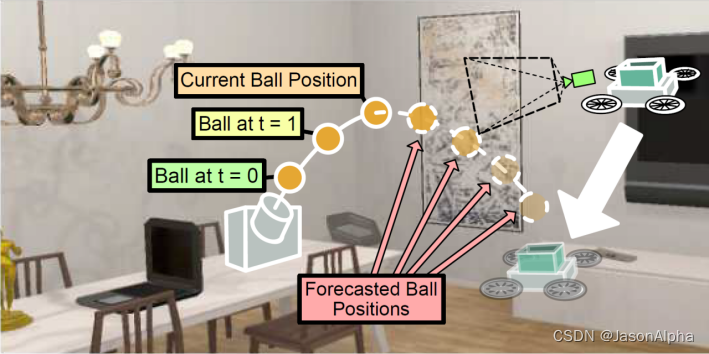
像一个3D游戏那样,有不同规格的客厅,
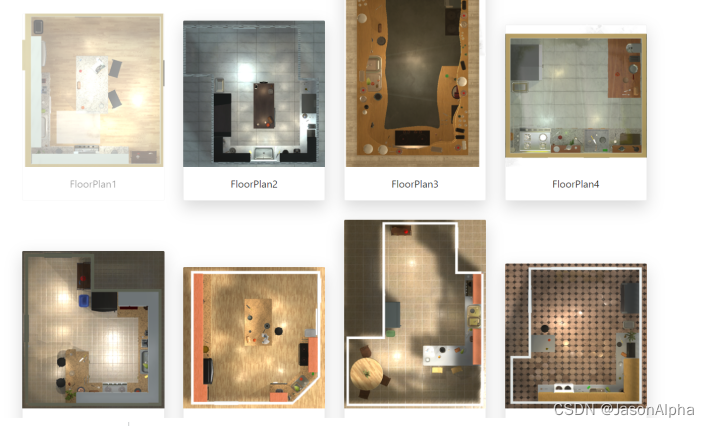
然后你可以在这个虚拟的空间里面,干各种事,和在生活里是一样的。我猜测这个扔球的轨迹是,在这3D空间里是有数据的,可以记录每次扔球每一秒钟,球的位置,以及最终球落地的位置的坐标进行试验

1-图片分类-目标识别Recognition
2021_Li_Cite=47_UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles
(感觉这个好不错哎,数据集数据量大,而且对于工业界也有用,比如警用无人机巡逻,监测是不是有人求救、是不是有打架、破坏公共设施等等犯罪行为)
UAV-Human Dataset
场景:它由一架飞行的无人机在三个月内的白天和夜晚在多个城市和农村地区收集的
任务:动作识别、姿势估计、对无人机图像的人类行为进行理解解析,分类出图片中人是在干什么?握手,锁车…
细节:
包含 67,428 个多模式视频序列和
119 个用于动作识别的目标,22,476 帧用于姿势估计,41,290 帧和 1,144个 用于人员重识别的身份,以及 22,263 帧用于属性识别
涵盖了广泛的多样性,包括对象、背景、光照、天气、遮挡、相机运动和无人机飞行姿态
数据集图片样例

1-无法归类
[2]2020_Uzkent_Cite=43_Learning When and Where to Zoom With Deep Reinforcement Learning
强化学习判断什么场景需要使用高分辨率(懂要判断什么场景需要使用超分辨率——什么场景需要高分辨率,什么场景不需要呢?)
(下面这些数据集,有的图中的object很小分类不出来需要增加清晰度,有的图中的object很大不用增加清晰度也能看清)
(1) CIFAR10, (2) CIFAR100, (3) ImageNet(4) functional map of the world (fMoW)
CIFAR10,10个类别

CIFAR100-100个类别分类
ImageNet–
可以做目标检测提供bounding boxes
20,000 categories
[3]2020_Lee_Cite_Cite=8_SIPSA-Net: Shift-Invariant Pan Sharpening with Moving Object Alignment for Satellite Imagery
Pan sharpening uses a higher-resolution panchromatic全色的 image (or raster band) to fuse with a lower-resolution multiband raster dataset

使得那种在运动中拍摄的比较糊的图片变得锐化
右下角我们做的锐化以后最清晰的。

WorldView-3
上面介绍过了
、
选场景的思路
(S1)最好是语义分割和目标检测,
(S2)哪一个能做出来的可能性最大,老师觉得从哪个切入是最好的.拉一个清单,三四个选项
(S3)这个场景数据集个数多,我用不同数据集都做做,看着工作量也挺大的
(S4)选能用的技术最多,最花哨、时髦的
(S5)从里面选一个应用上意义最大的,技术上能用花里胡哨技术的比如attention,比如图网络这类fancy的东西,
39个数据集(高空卫星照片+低空无人机照片)
iSAID
The Vaihingen dataset
The Potsdam dataset
Cityscapes
BDD100K
ADE20k
RoadTracer Dataset
Geo-parcel
WHU Dataset
center in the City of London
The 2019 IEEE GRSS Data Fusion Contest datase
USSOCOM Urban 3D dataset
The SpaceNet Buildings Dataset v2
SpaceNet Challenge
US3D
SN4
CVUSA
CVACT
WorldView-3
Sentinel-2 time series
the Dynamic Traffic Speeds (DTS) dataset
Cross-View Time (CVT) Dataset
SKU110KR Dataset
UAVVC
ShanghaiTech Dataset
WorldExpo10 Dataset
UCSD dataset
DOTA-v1.0
DOTA-v1.5
HRSC2016
NPS-Drones
FL-Drones
DTB70
UAVDT
UAV123@10fps
VisDrone2018-test-dev
DroneCrowd
A12-THOR
UAV-Human Dataset
文章出处登录后可见!