Abstract
首先呢写本篇博客的灵感来源于我在学习RNN(循环神经网络)时对于如何解决其循环结构,参数共享带来的长期依赖问题,我将在(一)中简要叙述RNN引出本文主角ESN(回声状态网络)。其次在(二)中将会从最基本的问题:什么是ESN出发,到最后我们掌握并且可以进行单方面对于解决长期依赖问题相比较于不更改网络模型而去调整初始化权重矩阵,激活函数,加入正则化项的优势以及存在的问题,又或是更改网络架构,比如LSTM等之间进行比较,优势互补,并且可以用代码来实现我们要做的模型。ESN中的关键的reservior层(储层,水库,储备池),在物理层面比如把逻辑放到伽马阵列,在激光上实现延迟循环,超导电子学等等,传统的储层可以做很多东西,在这里只介绍循环神经网络层面。结尾还有我赠送给大家的好礼(三)中将会总结在对于序列问题,RNN部分有关学习的一些建议(可供参考)。
注:该博客为博主自己总结思考,当然其中会有我借鉴大佬们的部分,不过我都会标注,如果有问题还望指正,一起研讨,博主万分感激。
(一)引出ESN的前言:RNN长期依赖问题
因为本片重点在ESN上,所以这里就先草草的写下几笔,没学过RNN的小白建议先去学习,网络上有很多资源,e.g.stanford的cs231n啊,花书啊等等。博主是花书+paper+遇到某一个点不会时Google看大佬们的解释,all right。下面简单带一下RNN的一些:
一.RNN
1.简单回顾循环神经网络(RNN)
1.1 RNN结构图
对于RNN我们会涉及到计算图将input和parameters映射到output和Loss的计算,要去了解RNN中不同的网络结构表达形式(如图1举例花书中的一部分,图2是列举不在花书的图) 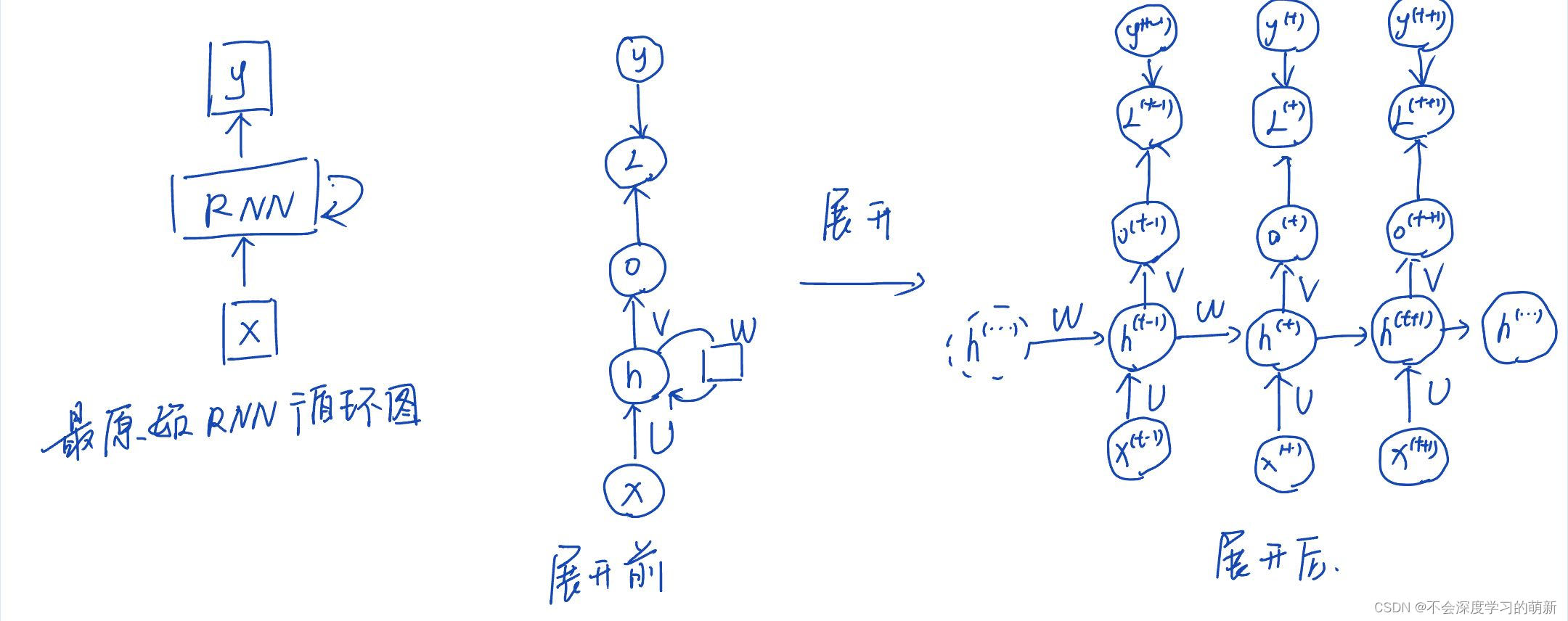
图1
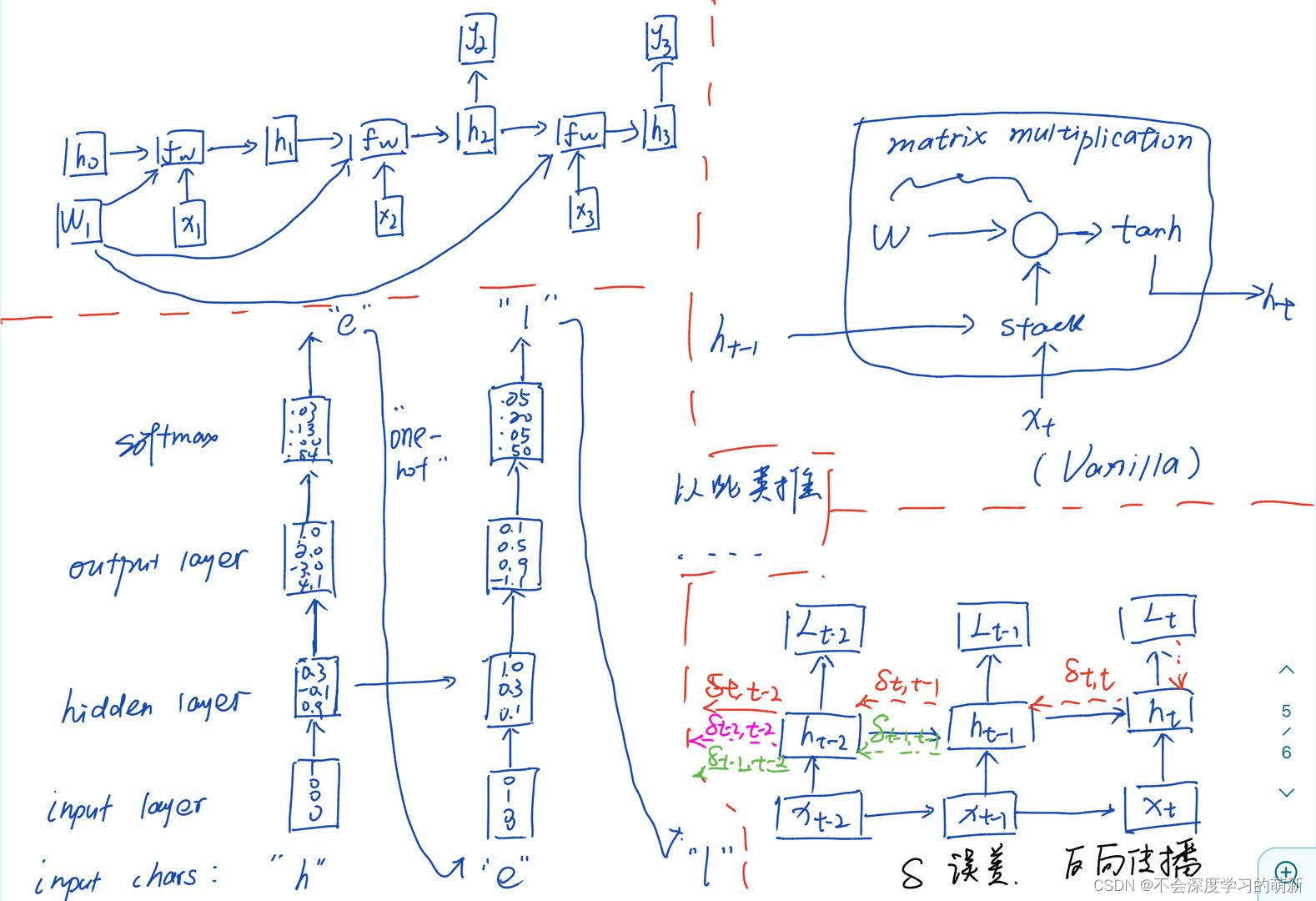
图2
还包括单向RNN(权值共享)和双向RNN(不仅仅只和过去信息相关,还和后续有关,即联系上下文)
1.2 RNN的三种模式:
(1)tensor到可变长度序列
(2)可变长度序列到tensor
(3) 不定长序列到不定长序列(e.g.seq2seq就是两部分(Many-to-one:encoder,one-to-Many:decoder))
1.3 RNN中的参数学习
相信看过花书的小伙伴都知道前向传播这个过程,这并不难很好理解,我就不多赘述了。
–然后就是梯度下降反向传播求Loss,并不断优化参数。
其中涉及两个算法:
BPTT(随时间反向传播算法):参数梯度需要在完整前向传播,反向传播计算得到,并进行参数更新,需要保留中间梯度,空间复杂度高。
RTRL(实时循环学习):可以实时计算Loss关于参数梯度,空间复杂度低
然后具体的反向传播推导就不赘述了,不过我这有一个numpy做RNN的反向传播code分享给大家(实际代码和手推是有很大区别的)
http://gist.github.com/karpathy/d4dee566867f8291f086(一个min-char-rnn的实例)
1.4 RNN实际应用
比如情感分析,机器翻译,处理序列数据比如(文章里的文字内容,语音里的音频内容,股票市场中的价格走势),生成图像描述等等,蛮有趣的。同样也不做过多举例了。
2.1 对产生的长期依赖问题分析
2.1.1 从前向传播角度:
假设我们虑没有input和激活函数的RNN结构,前向传播公式为 , t=1,2,..,
对于之前某一个时刻,
,
根据矩阵Jordan分解,可知随时间t增加时,W中幅值小于1,特征值会不断向零衰减,幅值大于1,特征值将不断发散,会导致前向传播时消失,发散现象。
2.1.2 从梯度下降,反向传播角度:
同样是上述网络,记t时刻Lt
同样会有权重矩阵的幂,因为每一次都是权值参数共享,会产生梯度爆炸或者梯度消失现象(一般来看,梯度消失会多一些,因为通常大多数值与微小的导数相关联,重复组合非线性函数,RNN这里是线性双曲正切层,结果是高度非线性的,就会导致梯度消失)
2.2 对于普通的RNN:
在前向传播时有输入数据和激活函数,由于输入数据的激活函数存在,信息发散或者衰减现象可能会有所缓解,但如果激活函数是Relu且取值大于0,仍然会有之前问题。
在反向传播中,由于公式:
中有一项激活函数导数,考虑到激活函数导数一般取值不超过1,因此在某种程度上能缓解梯度爆炸,但可能会加快梯度消失,长期依赖问题依然存在。
2.2 如何解决RNN长期依赖问题
在不更改网络框架层面:选择合适初始化权重矩阵,激活函数,加入正则化项…
更改网络结构层面:在时间维度上跳跃连接,可以构造出较长延迟的RNN,换网络模型,比如门控RNN,回声状态网络,用的最多的LSTM(但是并不代表回声状态网络不好)
http://proceedings.mlr.press/v28/pascanu13.pdf![]() http://proceedings.mlr.press/v28/pascanu13.pdf
http://proceedings.mlr.press/v28/pascanu13.pdf
上边这个是一篇paper,我读完觉得比较好的,解决RNN中梯度问题
上边这些至只是一点饭前开胃小菜,下面的才是硬菜,让我们一起畅游echo state network的海洋吧!出发!!!
(二)新世界的大门:回声状态网络(ESN)
1.回声状态网络(ESN)
1.1 什么是回声状态网络,又是怎么引出来的呢
很多博主呢,都会直接讲解分析这一网络,而不是去从根本上学习其来源以及能解决掉的问题,所以我就把这细说一下:
在当时9几年不同人员发现RNN存在梯度消失和梯度爆炸的问题,有人想通过仅仅处理梯度消失或爆炸的参数空间避免该问题,为了储存之前的记忆,小扰动对网络模型影响不大,大的变化也不会给网络模型带来灾难性影响(鲁棒性),RNN必须进入参数空间中梯度消失区域。然而在试验中,当我们修改或者增加网络跨度时对于梯度优化问题影响越来越明显,SGD在某些长度序列的概率直接归零。
递归神经网络的训练通过权值直接优化来实现的,收敛速度慢,易陷入局部最优,麻烦的优化的问题也随即出现。同时也发现当RNN中隐藏单元循环权重映射和输入到隐藏单元的权重映射往往是困难的需要学习的参数,在零几年研究者们就发现,为避免该问题,设定循环隐藏单元,固定前面这两个权重,只学习输出权重。解决的是RNN的权值难定的问题,间接可以改变RNN前向传播信息消失,反向传播梯度消失/爆炸的问题。
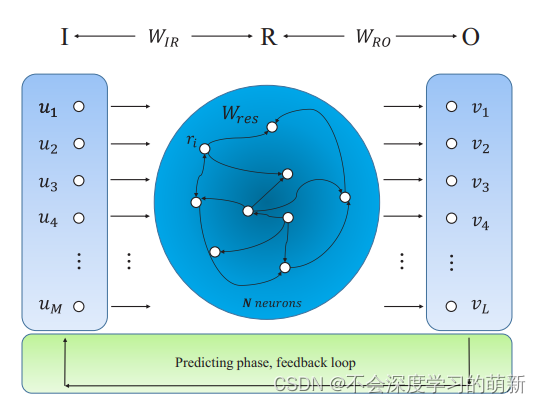
1.2 回声状态网络的网络结构
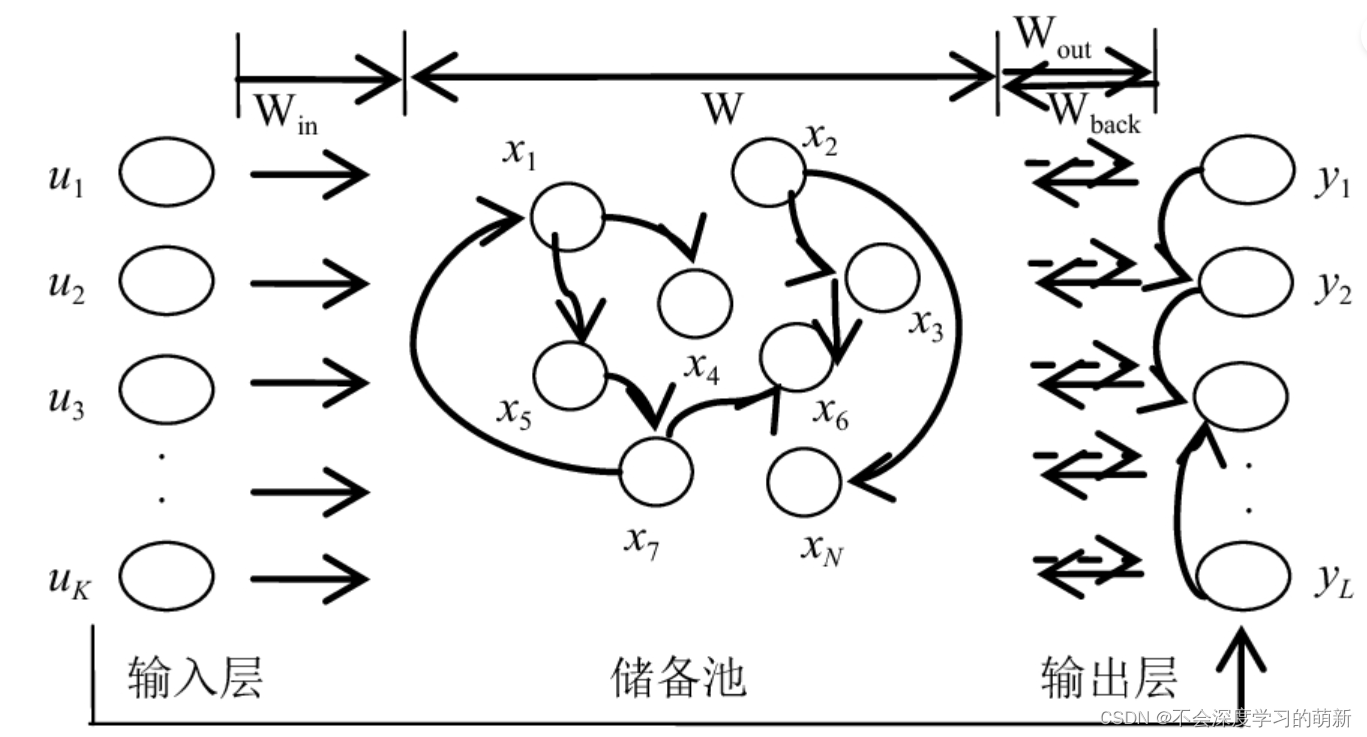
不难由图可以看出,基本由三部分构成,输入层(input),储备池/储层/水库(reservoir),输出层(output)。
输入层:通过输入K×1的tensor,再通过与权重矩阵进行乘积输入到储层
储层(N个节点网络):里面每一个节点都对应一种状态,我们用表示,储层中也存在hidden->hidden layer的内部神经元连接权重矩阵W
输出层:通过将在储层中输出与权重矩阵乘积得到target(y)
输入层u(t) , 储层神经元隐藏状态x(t),输出层y(t)分别在t时刻的值:
(K维)
(N维)
(L维)
1.3 回声状态网络传播具体流程
前向传播过程:
(1)(input->reservoir):*u(t)
(2) reservoir(N个节点网络):
f函数为储层内部激活函数
(3) (reservoir->output):
*x(t)
y的更新迭代过程:
(4) 损失函数计算:
损失函数的推导:
首先我们把损失函数转换成矩阵形式:
然后展开:
然后就是一步步推导,不过需要注意的是后边一次项合并因为是标量:
矩阵求导法则:
这里之前都是没有考虑正则化项,下面是加正则化项推导结果,原理相同:
损失函数第一项相当于线性回归,设计为输出权重的凸函数。第二项是bias,或者说是正则化项,用来防止过拟合等问题。
注:,W,
都是提前设定好的,随机产生,不作为超参数,而我们要学习的是
,由于输出函数是标准线性函数,所以仅可以通过最小二乘法或者MSE就能找到输出矩阵的最优解,用简单的方法即可求解,都用不到梯度下降反向传播来求解。
1.4 回声状态网络中主要参数
1.4.1 谱半径
什么是谱半径?矩阵的谱或叫矩阵的谱半径,在特征值估计、广义逆矩阵、数值分析以及数值代数等理论中,有很大的关系。矩阵的谱半径为矩阵的特征值的模的最大值。
关于矩阵的谱(半径)的一个重要性质即是:任意复数域上的矩阵的谱半径不大于其任意一种诱导范数。
谱半径即矩阵特征值模的最大值,简单的矩阵可以求出所有的特征值然后比较出最大者即为谱半径。维数较大矩阵需要尝试迭代算法求。
在这里是使hidden->hidden layer的权重矩阵的最大特征值,最初想法是使状态到状态转换函数的jacobian矩阵的特征值接近于1。
当谱半径小于1时,且以tanh作为激活函数,回声状态网络的输入和储层状态在经过足够长的时间后对网络的影响会消失。反之的话,网络的状态或输入在经过许多次迭代后会越来越大,将导致混乱甚至是ESN的故障。由于储层里面是随机连接,谱半径<1可以让保证网络收敛。
谱半径的推导以及具体选择个人建议还是最好读paper来学习,我这有几个读过推荐的paper
ASU的研究非线性动力学,复杂网络的大佬Ying-Cheng Lai的一篇研究reservoir的谱半径在回声状态网络中的应用:https://scholar.google.com/citations?view_op=view_citation&hl=en&user=42cK_xMAAAAJ&cstart=100&pagesize=100&citation_for_view=42cK_xMAAAAJ:4QKQTXcH0q8C![]() https://scholar.google.com/citations?view_op=view_citation&hl=en&user=42cK_xMAAAAJ&cstart=100&pagesize=100&citation_for_view=42cK_xMAAAAJ:4QKQTXcH0q8C
https://scholar.google.com/citations?view_op=view_citation&hl=en&user=42cK_xMAAAAJ&cstart=100&pagesize=100&citation_for_view=42cK_xMAAAAJ:4QKQTXcH0q8C
插图:
内容很不错,推荐读一下。
1.4.2 储层的规模,深度
往往在储层都是大规模的,即x(n)个数,或者说N维向量,N数值越大,精度会越高,不过效率会降低,会产生过拟合现象。我们需要初始化确定好储备池的规模神经元的个数,节点数N越多,拟合能力越强,由于在回声状态网络中仅仅需要学习输出权值来线性拟合输出结果,所以一般回声状态网络需要远大于常规神经网络的节点规模,即N>K。
2.搭建回声状态网络
(1)初始化 ,储层大小里面神经元节点数,谱半径,储层里面的随机稀疏连接,调整需要学习的参数即
l来对储层输出进行线性拟合
(2)然后随机生成连接矩阵,不同神经元之间连接方式,以及连接的方向和权值。然后缩放矩阵实际上就是归一化的操作,有些时候我们会直接使用一个缩放因子,使用该缩放因子乘以原始的随机生成的矩阵,相比于使用特征值来缩放更加快速,但是很大程度上也丧失了精度。为什么要进行这个操作呢?原因和我们在初始化一些神经网络的权值时是类似的,对于这些神经网络,我们通常会将权重初始化为0-1之间(或着-1至1),有两个原因:(1)受激活函数的影响,sigmoid和tanh激活函数,在0与1之间区分度比较大,但是大于1之后,激活值变化不大;(2)我们对激活函数求导,可以看出在大于1时,图像比较平坦,其导数接近于0,由此在计算梯度时会导致梯度过小,无法顺利实现权重的更新。对于ESN我们不使用梯度来更新权值,主要是第一点的问题。最后随机生成输入权值V和输出权值W。
这些参数会影响到网络短期记忆时间的长短。输入权值越小而内部矩阵的谱半径越接近1,网络短期记忆时间越长。但是,增强记忆能力的同时,这种操作也造成了网络对“快速变化”系统的建模能力下降。
(3)然后进行训练,input K维向量,输入到reservoir进行反向传播,值得注意的之间有个“空转”过程,实际上就是初始化储层的状态。为什么要进行这个操作呢?因为储备池的内部连接是随机的,最开始的输入序列得到储备池状态的噪声会比较大,所以会先使用一些数据来初始化储备池的状态,从而降低噪声的影响。
线性回归确定Wout的部分推导:
详细推导见上面求损失函数推导,1.3(4)
然后这篇是我读完推导后跟我方法不太一样但也比较不错的,通过用L2范数惩罚项的最小二乘回归求解,这里对使用线性回归确定输出权值的详细推导可以看这篇博客比较详细:
https://blog.csdn.net/cassiePython/article/details/80389394![]() https://blog.csdn.net/cassiePython/article/details/803893943.回顾储层中的一些必要知识以及复杂性讨论(因为储层的关键性蛮大的,所以我就单独列了一些)
https://blog.csdn.net/cassiePython/article/details/803893943.回顾储层中的一些必要知识以及复杂性讨论(因为储层的关键性蛮大的,所以我就单独列了一些)
(1)储层里hidden->hidden的矩阵权值设置,需要允许input能够在reservoir循环状态里echo,无论是线性系统还是非线性系统,幅值的设置,谱半径的设定都会带来影响。一般我们在储层中采取非线性函数,在output输出线性回归函数。
(2)在储层中用稀疏连接很重要,而不是用同样中等大小的权重矩阵。有一些相当大的方式,几乎所有权重在hidden->hidden连接中都为0,这样做是他产生了松散的内部结构,因此信息可以在网络的一部分徘徊,无需过快的传播到网络其他部分。
(3)小心的选择隐藏连接的input规模也重要
这些连接驱动储层的状态,但不能消除储层中包含的近期有关的历史信息
(4)reservoir中的特点:随机生成,大规模,稀疏连接,没有非线性优化回导致这个训练过程非常的快。
(5)储层中的随机权重矩阵,但也或许需要一个稳定的分布,均匀高斯或正太高斯或者混合高斯,包括矩阵的稀疏度,有待商榷。
4.罗列一些其他问题
(1)因为从储层到输出层只是简单的线性回归,所以不需要对网络进行梯度下降反向传播优化参数,而需要注意的是有从输出层返回储层的连接,即权重矩阵Wback,这些连接不总是必要的,但是有助于告诉储层到目前为止产生了什么输出。
(2)储层计算研究将循环网络作为动态网络,并设定让动态系统接近稳定边缘的输入和循环权重,用离散映射描述,所以t+1时刻状态取决于过去状态和输入。
(3)这里的激活函数通常采用tanh双曲正切函数,实际上其实都可以,正则化项,偏置项bias很重要,需要对特定任务问题优化达到最佳性能。
5.ESNs优缺点分析:
5.1 good aspects:
训练非常快(线性模型)
权重初始化往往很重要
对一维时间序列有着非常令人深刻的建模
5.2 bad aspects
往往比RNN需要更多的隐藏单元(即储层里的单元)来学习输出权重矩阵
对声学系数帧/视频帧处理并不好
6.ESNs实际应用
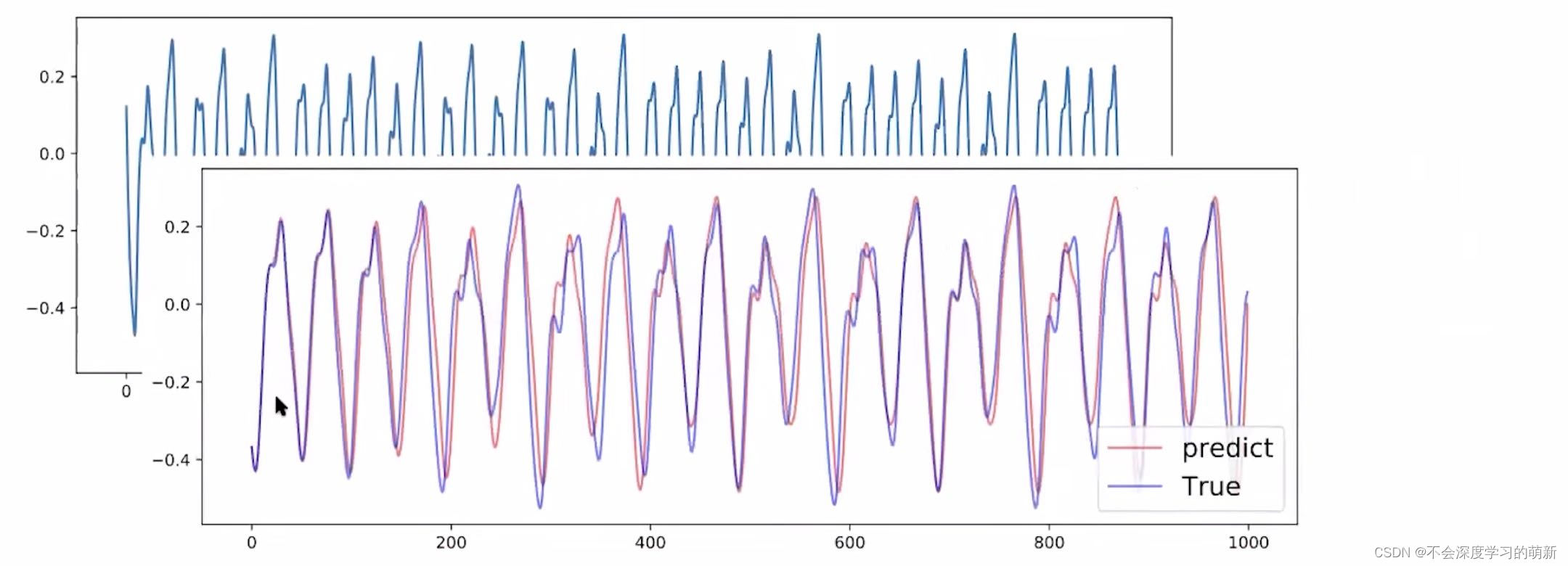
这是一个实例,预测一维动态系统时间序列,预测后1000步结果,代码如下:
https://github.com/bnuliujing/EchoStateNetworks![]() https://github.com/bnuliujing/EchoStateNetworks
https://github.com/bnuliujing/EchoStateNetworks
import pickle
import numpy as np
import matplotlib.pyplot as plt
class ESN():
def __init__(self, data, N=1000, rho=1, sparsity=3, T_train=2000, T_predict=1000, T_discard=200, eta=1e-4, seed=2050):
self.data = data
self.N = N # reservoir size 库的大小
self.rho = rho # spectral radius 谱半径
self.sparsity = sparsity # average degree 平均度 sparsity:稀疏性
self.T_train = T_train # training steps
self.T_predict = T_predict # prediction steps
self.T_discard = T_discard # discard first T_discard steps discard:丢弃
self.eta = eta # regularization constant 正则化常数
self.seed = seed # random seed
def initialize(self):
"""
对连接权矩阵W_IR和W_res进行初始化
其中W_IR(N*1)是从输入到库的连接权矩阵,W_res(N*N)是从库到输出的连接权矩阵
"""
if self.seed > 0:
np.random.seed(self.seed)
# 生成形状为N * 1的,元素为[-1, 1]之间的随机值的矩阵
self.W_IR = np.random.rand(self.N, 1) * 2 - 1 # [-1, 1] uniform
# 生成形状为N * N的,元素为[0, 1]之间的随机值的矩阵
W_res = np.random.rand(self.N, self.N)
# 将W_res中大于self.sparsity / self.N的元素置0
W_res[W_res > self.sparsity / self.N] = 0\
# np.linalg.eigvals(W_res)求出W_res的特征值,W_res矩阵除以自身模最大的特征值的模
W_res /= np.max(np.abs(np.linalg.eigvals(W_res)))
# 在乘以谱半径
W_res *= self.rho # set spectral radius = rho
self.W_res = W_res
def train(self):
u = self.data[:, :self.T_train] # traning data T_train = 2000
assert u.shape == (1, self.T_train)
r = np.zeros((self.N, self.T_train + 1)) # initialize reservoir state r(N*(T_train + 1))
for t in range(self.T_train):
# @是Python3.5之后加入的矩阵乘法运算符
r[:, t+1] = np.tanh(self.W_res @ r[:, t] + self.W_IR @ u[:, t])
# disgard first T_discard steps r丢弃前T_discard步变成r_p
self.r_p = r[:, self.T_discard+1:] # length=T_train-T_discard
v = self.data[:, self.T_discard+1:self.T_train+1] # target
self.W_RO = v @ self.r_p.T @ np.linalg.pinv(
self.r_p @ self.r_p.T + self.eta * np.identity(self.N))
train_error = np.sum((self.W_RO @ self.r_p - v) ** 2)
print('Training error: %.4g' % train_error)
def predict(self):
u_pred = np.zeros((1, self.T_predict)) # u_pred是形状为(1, self.T_predict)的全零矩阵
r_pred = np.zeros((self.N, self.T_predict)) # r_pred是形状为(N, self.T_predict)的全零矩阵
r_pred[:, 0] = self.r_p[:, -1] # warm start 热启动
for step in range(self.T_predict - 1):
u_pred[:, step] = self.W_RO @ r_pred[:, step]
r_pred[:, step + 1] = np.tanh(self.W_res @
r_pred[:, step] + self.W_IR @ u_pred[:, step])
u_pred[:, -1] = self.W_RO @ r_pred[:, -1]
self.pred = u_pred
def plot_predict(self):
ground_truth = self.data[:,
self.T_train: self.T_train + self.T_predict]
plt.figure(figsize=(12, 4))
plt.plot(self.pred.T, 'r', label='predict', alpha=0.6)
plt.plot(ground_truth.T, 'b', label='True', alpha=0.6)
plt.show()
def calc_error(self):
ground_truth = self.data[:,
self.T_train: self.T_train + self.T_predict]
rmse_list = []
for step in range(1, self.T_predict+1):
error = np.sqrt(
np.mean((self.pred[:, :step] - ground_truth[:, :step]) ** 2))
rmse_list.append(error)
return rmse_list
if __name__ == "__main__":
# http://minds.jacobs-university.de/mantas/code
data = np.load('mackey_glass_t17.npy') # data.shape = (10000,)
data = np.reshape(data, (1, data.shape[0])) # data.shape = (1, 10000)
print(data.shape)
esn = ESN(data)
esn.initialize()
esn.train()
esn.predict()
esn.plot_predict()
该代码数据集在该博客底下:
import torch.nn
from torchvision import datasets, transforms
from torchesn.nn import ESN
import time
def Accuracy_Correct(y_pred, y_true):
labels = torch.argmax(y_pred, 1).type(y_pred.type())
correct = len((labels == y_true).nonzero())
return correct
def one_hot(y, output_dim):
onehot = torch.zeros(y.size(0), output_dim, device=y.device)
for i in range(output_dim):
onehot[y == i, i] = 1
return onehot
def reshape_batch(batch):
batch = batch.view(batch.size(0), batch.size(1), -1)
return batch.transpose(0, 1).transpose(0, 2)
device = torch.device('cuda')
dtype = torch.float
torch.set_default_dtype(dtype)
loss_fcn = Accuracy_Correct
batch_size = 256 # Tune it according to your VRAM's size.
input_size = 1
hidden_size = 500
output_size = 10
washout_rate = 0.2
if __name__ == "__main__":
train_iter = torch.utils.data.DataLoader(
datasets.MNIST('./datasets', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=batch_size, shuffle=True, num_workers=1, pin_memory=True)
test_iter = torch.utils.data.DataLoader(
datasets.MNIST('./datasets', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=batch_size, shuffle=False, num_workers=1, pin_memory=True)
start = time.time()
# Training
model = ESN(input_size, hidden_size, output_size,
output_steps='mean', readout_training='cholesky')
model.to(device)
# Fit the model
for batch in train_iter:
x, y = batch
x = x.to(device)
y = y.to(device)
x = reshape_batch(x)
target = one_hot(y, output_size)
washout_list = [int(washout_rate * x.size(0))] * x.size(1)
model(x, washout_list, None, target)
model.fit()
# Evaluate on training set
tot_correct = 0
tot_obs = 0
for batch in train_iter:
x, y = batch
x = x.to(device)
y = y.to(device)
x = reshape_batch(x)
washout_list = [int(washout_rate * x.size(0))] * x.size(1)
output, hidden = model(x, washout_list)
tot_obs += x.size(1)
tot_correct += loss_fcn(output[-1], y.type(torch.get_default_dtype()))
print("Training accuracy:", tot_correct / tot_obs)
# Test
for batch in test_iter:
x, y = batch
x = x.to(device)
y = y.to(device)
x = reshape_batch(x)
washout_list = [int(washout_rate * x.size(0))] * x.size(1)
output, hidden = model(x, washout_list)
tot_obs += x.size(1)
tot_correct += loss_fcn(output[-1], y.type(torch.get_default_dtype()))
print("Test accuracy:", tot_correct / tot_obs)
print("Ended in", time.time() - start, "seconds.")这个代码是用mnist数据集,PyTorch module的,可以多去github搜一下然后跑一跑
经过跋山涉水,终于结束了这次桃源之旅,第二部分结束之前我在把这篇非常好的paper推荐给大家,也是我唯一膜拜的学术界大佬Geoffrey Hinton参与的这篇基于动量和rmsprop的ESN的paper,话不多说,上链接:
http://proceedings.mlr.press/v28/sutskever13.pdf![]() http://proceedings.mlr.press/v28/sutskever13.pdf
http://proceedings.mlr.press/v28/sutskever13.pdf
(三)RNN的学习经验分享:
在我与我前辈在假期经验交流时,认为比较不错的点子,就是学习不只是前向传播的过程,往往还需要我们反向传播回传找最优,前者不必多言就是循渐进扎实的学,后者是则是我们要用问问题或者类似于其他形式的方法从问题出发,缕清之前学的所有知识,并进行补足更新。就拿RNN如何让解决长期依赖问题举例,我们从两个方向出发,一是原因,二是解决办法。要知道原因就必然需要我们对RNN的结构,模式,机制,损失函数,数学推导有全面的掌握才不至于分析原因时候漏点,才能更好地把握所学,还能在每一次思考中在巩固一遍。我们可以把其称为好奇心。
small question,多思考会是对所学最好的思考,善哉善哉,大家可以一起交流经验,every time is OK.
:
文章出处登录后可见!