文章目录
Sequence数据的处理
Self-Attention是用来处理Sequence数据的。
输入是Vector Set(Sequence)。
比如:
- 输入是一段文字:每个字会对应一个vector。(编码方式:①one-hot编码;②word embedding)
- 输入是一段声音信号:设置window(一般window的大小是25ms),每个window中的声音信号作为一个vector。(例:如果window滑动的step=10ms,window大小是25ms,那么1s的声音信号可以转化为100个vector的集合)
- 输入是一个Graph:每个node是一个vector。(向量是node的特征)
输出是什么?
- 每个输入的vector对应一个label:词性标注任务
- 整个sequence输入一个label:情感分析、语者辨认
- 机器决定输出的label的个数(Seq2Seq任务):翻译
Sequence Labeling(输入和输出的大小一样)
希望网络可以考虑整个sequence的信息。
首先想到全连接网络,但是每个输入的sequence的长度是不确定的,因此如果想要使用全连接网路哈哈哈没法确定神经元的个数~~
所以,使用Self-Attention:可以实现每个输出都会考虑整个Sequence的信息。
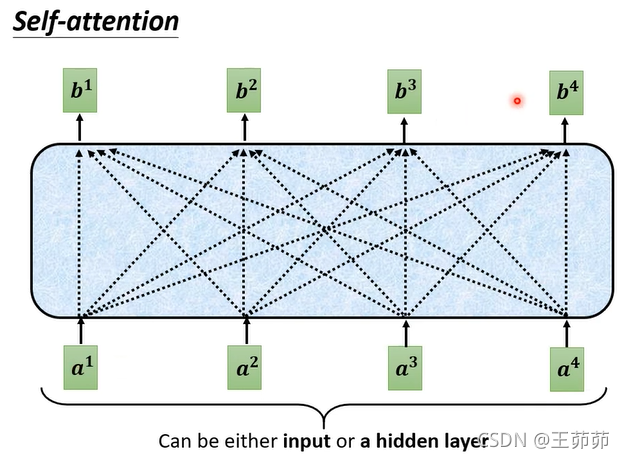
如图所示,一个Self-Attention块的输入是input sequence或者是上一层的输出。
每个输出b都会考虑整个输入序列的信息。
Self-Attention内部机理
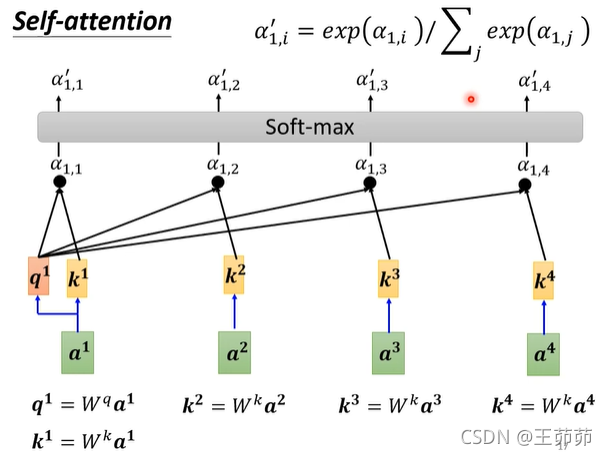
如何求解b?
1、首先求解输入之间的相关性权重α。
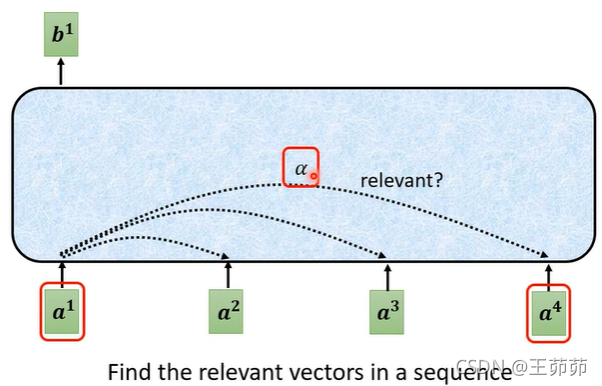
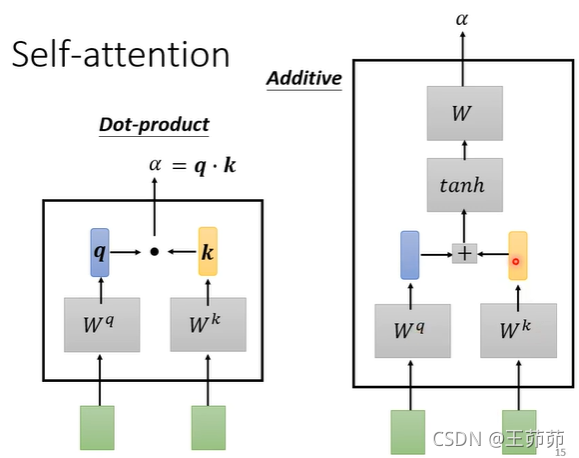
求解α的方法:
(1)Dot-product
(2)Additive
Self-Attention中的α的求解方法:
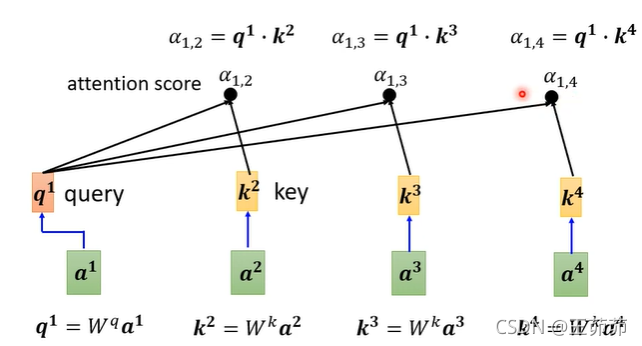
然后经过一个激活层,此处是Softmax也可以是其他的,比如ReLU。
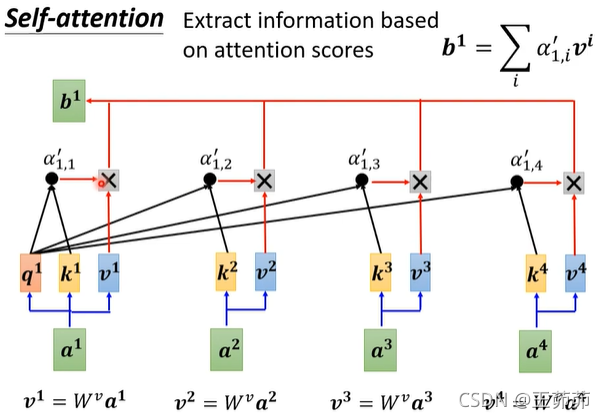
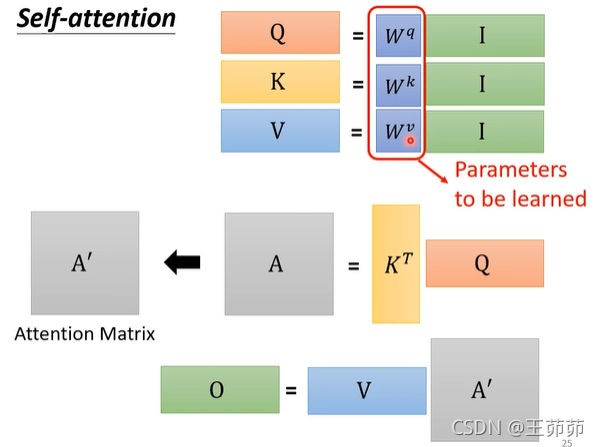
使用矩阵运算总结Self-Attention的求解机理:
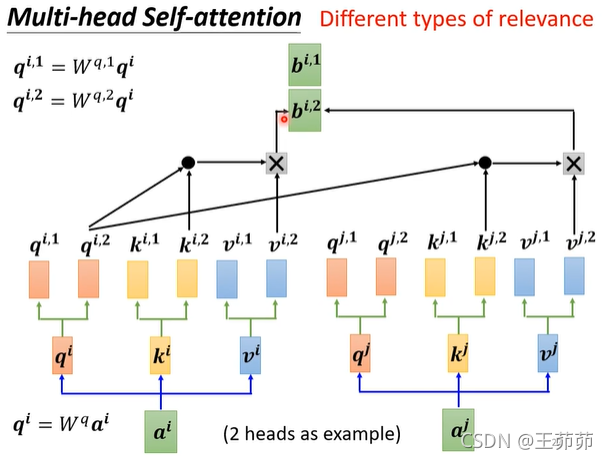
Multi-head Self-Attention
实现不同类型的relevance。

Positional Encoding
前面讲的Self-Attention中没有涉及位置信息,因此考虑加入位置编码。
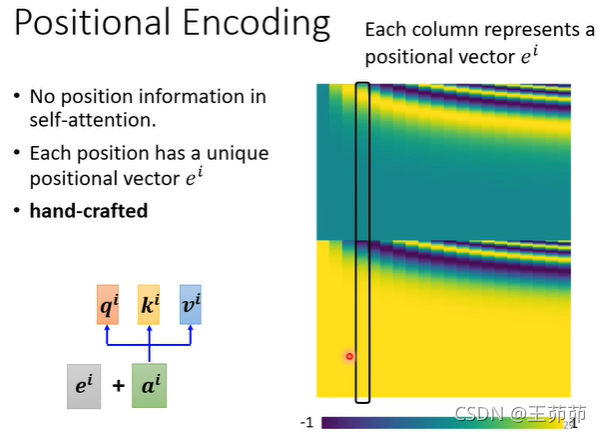
上述的positional encoding是hand-crafted的。
也有其他的positional encoding方法此处就不列举了。
Self-Attention for Image
可以将image看成一个w*h的sequence,每个像素的vector中包含的是像素的RGB三通道值。
或者将image分块,每块是一个输入vector。
Self-Attention v.s. CNN
其实CNN可以看成是Self-Attention中的一种情况。
对于Self-Attention其实是针对一个query像素点求解其与其他所有像素点的k值(即relevance)通过k值得到其他像素点对该query像素点的相关性,
而CNN是使用卷积核划定了相关像素点的范围。
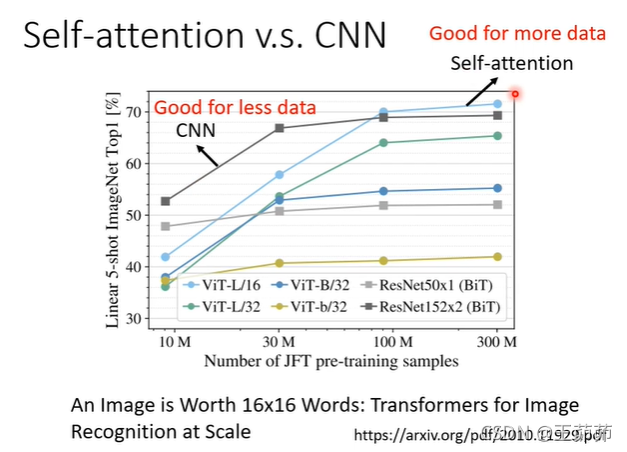
Self-Attention模型相比于CNN有更高的灵活性因此训练需要更多的数据。
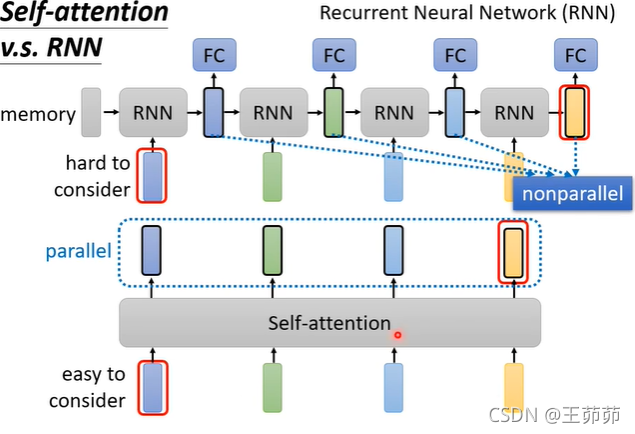
Self-Attention v.s. RNN
RNN也是一种处理序列数据的模型。
- 相比于Self-Attention,RNN也可以通过循环RNN实现每个输出与所有输入的相关性。
但是单向的RNN只能实现,后面的输出与其前的输入是相关的。 - 并且RNN后面的输出对于距离较远的输入的依赖关系比较难实现,需要一直将前面的所有输入保存在内存中,而Self-Attention只需要在内存中保存计算出的Q、K、V矩阵即可。
- RNN是一个串行的流程,Self-Attention是并行处理的。
总结
Self-Attention可以很好地处理序列数据,可以实现序列数据的全依赖。
但是Self-Attention的运算量很大!需要更多的数据训练。
文章出处登录后可见!