想到啥些啥,都是些我遇到的,很坑,但偏偏又有点蠢的问题。
路过进来的朋友可以 ctrl+F 搜一下有没有自己苦恼的问题。
1,训练的模型使用越小(最小是yolov5n),帧数越高,自瞄间隔越短。
我一开始是用yolov5l训练,因为官方说这个综合评价最棒,结果训练出来的pt模型大小80多MB,跑程序帧数还低的一匹(我1650的显卡,垃圾的很)。后来群里有个大佬发了个13MB的,我试了一下,简直像用了海飞丝,乐死我了。一问才知道,训练出来的模型大小,是跟训练时使用官方模型大小有关,越小的越快越爽,虽然精度低了,但足够跑个fps游戏自瞄了。
(群友说10系显卡用n,20系用s)
2,打标签很辛苦,所以我一开始是找群里的大佬们打好的标签用,但总有大佬们不玩的游戏,这个时候我们可以先做小部分数据集,跑个pt出来,然后用自己的pt再去识别图片。detect.py里面有个参数“–save-txt”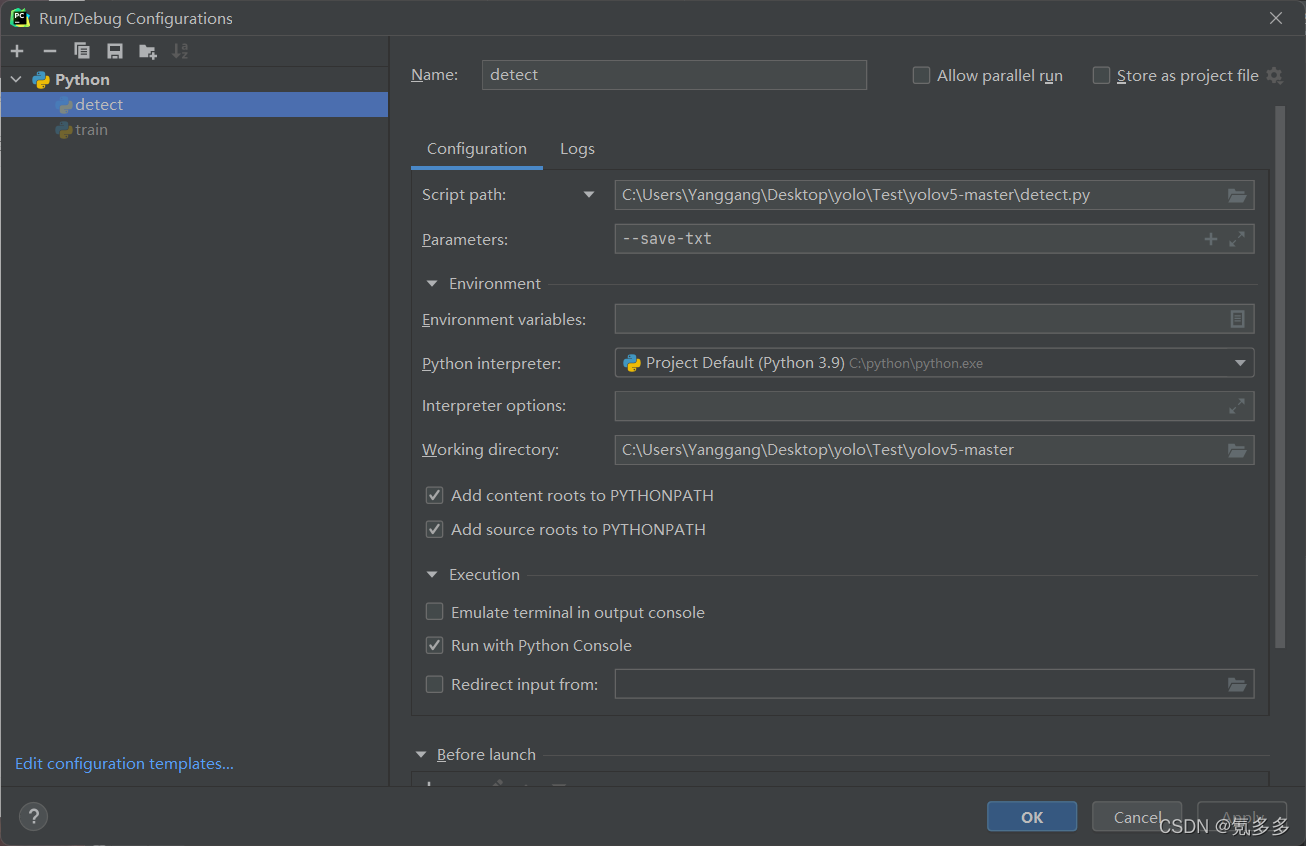
随便右键,点出这个修改运行配置的东西,吧参数名添加到图片里的那个位置保存,然后跑detect代码,就能在结果run里不仅仅有识别的图片,还有写好的txt标签。
然后再自己用labellmg,打开图片位置和标签位置,看看那些是多余的打错的,改改就能用了。
再不济可以找一些大佬写好的一键打标签的代码或者软件,都能解放双手。
3,(这时候是用的自己的电脑跑模型)batch size是个很奇怪的东西,听别人说是按自己显存一半的大小设置,我自己的电脑显存是4g,一开始我设置成4,跑不了(报错)。3,行,我就跑3了,但gpu使用率一直是50%左右。后来狠心改回16,突然就能跑了,使用率也拉满,干脆就这样吧。(2022.4.26)
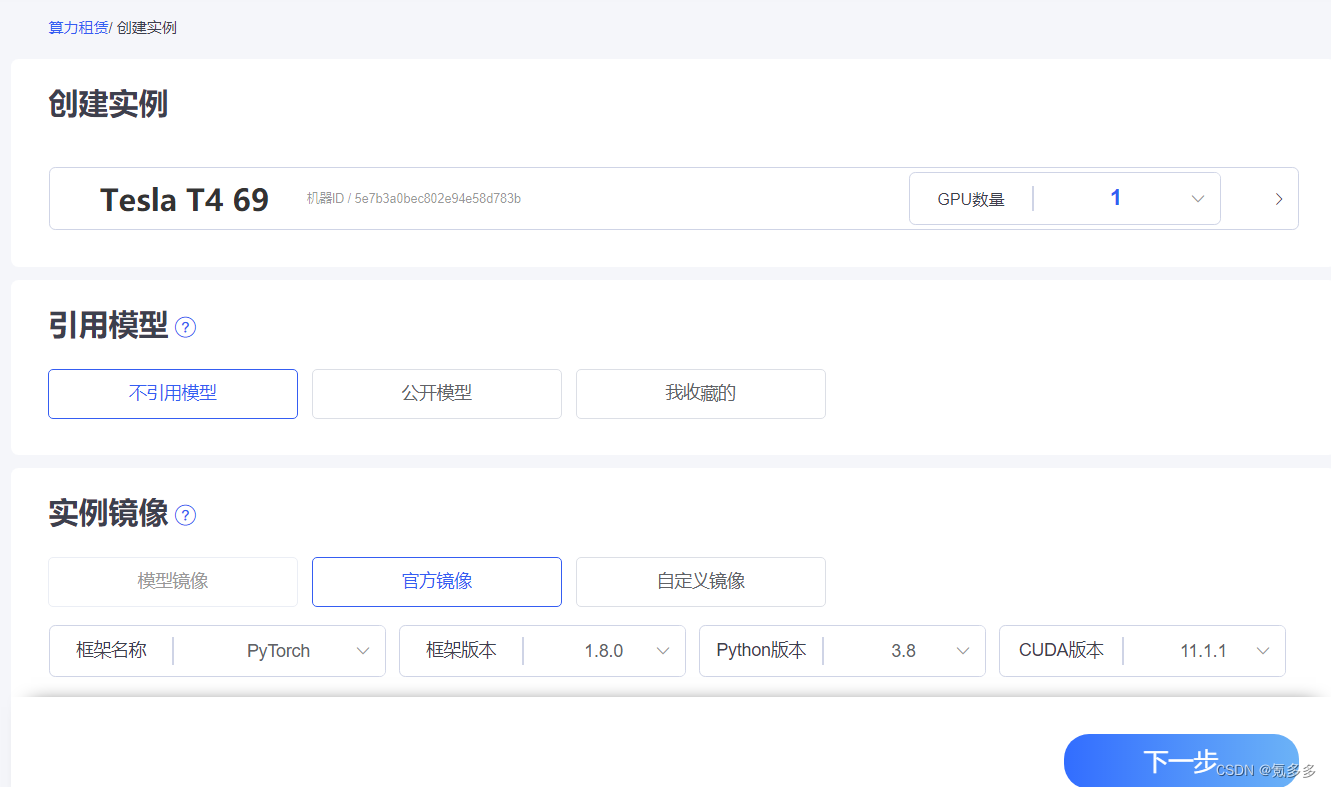
4,(开始买云服务器跑模型)在服务器(我用的极链ai云)跑训练集,先买个最便宜的卡(比如2.5一个小时),跟着你找的教程走一遍,即使报错了,花一个半个小时debug,也不会亏什么钱。
开始我以为我能一遍过,买了2个gpu的3090,10块钱一个小时,结果debug就花了一个小时,麻了,10块钱打水漂了(2022.4.28)
5,如果是在极链ai云的话,推荐用Tesla 的卡(这个是专门用来做科研类的卡,比同价位普通卡快很多)。
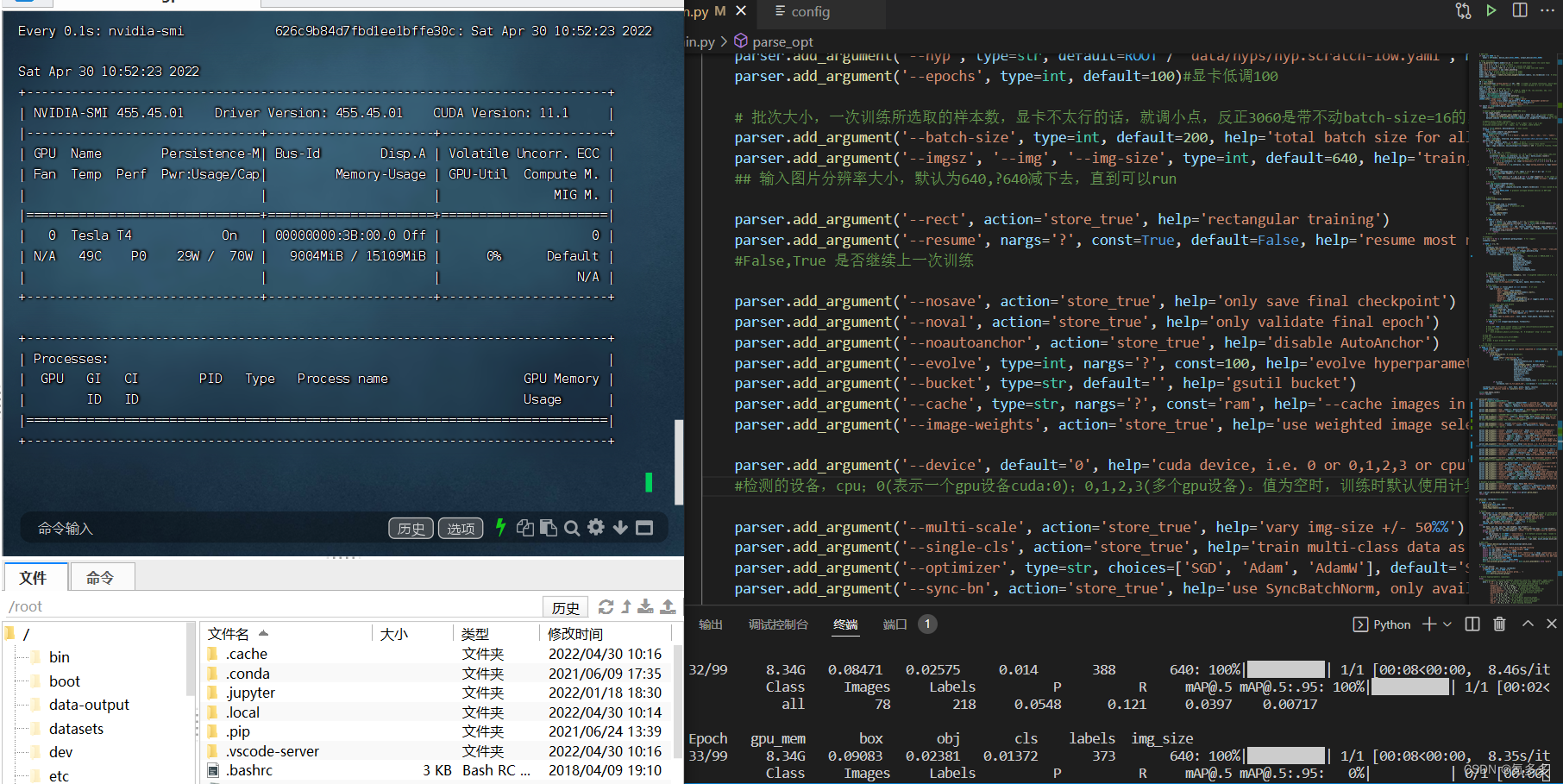
6,训练的时候发现显卡的gpu使用率很低,显存无论怎么调都用不完,那大概是你的数据集不够,搞多点数据集图片就好。
例如:你的数据集是100张图片,batchsize最高也只有设置100,往上再设置,你一轮也还是一次性训练100张图片,这时候多余的显存你怎么都用不了的,就算把batchsize设置成100000,该用的显存还是batchsize=100的量。(2022.4.30)
(我这里用的Tesla T4,单gpu,训练150多张图片吧(包括训练集和测试集),设置的batchsize=200还设置大了,没啥用,显存始终就用这么多,就算batchsize设置为10000也是一样的速度8秒左右一轮。)
(顺便说一下验证集测试集 “ 比例问题 ”,我用的是coco128,官方推荐的是测试集和验证集是用的同一堆图片,我认为是对的,不用特意划分新的验证集。
上面图片的数据集,我试过两种方法区分,1是另外选几张图片分到验证集val里,2是val跟train是同一个文件夹,训练结果是第二种好,很好!第一种基本识别失败。
或许我的数据集太少,有不同意见的可以说一下)
7,服务器python环境配置问题。
如果把python导入ssh中还是找不到python环境,那就把ssh中的python安装以前的版本,比如2020年12月份的,然后再重新加载一下就有python环境了。(2022,5,1)
8,打标签classes越多,训练的时间也越多,反而反之。
但如果只有一个分类,亲测经历,训练出来的exp里pred值很高且都对了,但在实时截图运行中是识别不出任何东西的。
但是!!!对于视频和图片却又能识别成功,就很奇怪,所以还是得看用于检测什么东西?(2022.5.3)
9,依旧是参数设置,“workers”,default先设置为你数据集的大小量,能跑就行(指高性能的显卡上跑,家用普通的8清楚,我自己电脑是设的16)。
这个好像是dataloader的最大值,搜过别的博主说,最好设置成32,多了少了都会变慢速度。
但我测试过,700个数据集的情况下,workers低于700会慢,大于700即到达最极限速度,不过设置成1000的话跟700比没有变化。
10,gpu买多买少,变化不大,甚至会反而掉速。
这个原因我不清楚,反正我试过多gpu,设置到极限的batchsize和workers,跟单gpu也没什么不同,甚至还变慢了,也有可能是我的设置问题吧。
我测试的网站是极链ai,700数据集、1:9训练测试比情况下,3块钱一个小时单gpu的Tesla T4速度最快,多加gpu甚至更慢,8.5块钱一个小时单gpu的Tesla V100速度居然也一样,百思不得其解,我朋友说是边际效用的原因。(2022.5.4)
文章出处登录后可见!