目录
前言
本文专注于padim算法在自制数据集上的训练过程,博主水平有限,对神经网络模型秉持能用就行的态度,所以文中不涉及网络结构和论文细节的解读,想看这些的同学请另寻资料哈~
一、无监督学习缺陷检测 Anomalib介绍
组里最近给的新任务,对金属材质表面的各种缺陷进行检测。之前使用的是有监督的yolov5网络,标数据集着实痛苦无比。而且工业缺陷数据有一个比较显著的特征:样本不平衡。绝大部分采集得到的工业数据都是没有缺陷的,这样一来,正样本的数据在模型训练中根本没有起到作用,负样本又太少,很难训练得到有效的模型。使用有监督学习的方法还有一个问题:负样本的出现是十分偶然的,可能在数据集中根本没有出现某一类型的负样本,如此训练得到的模型很有可能翻车,所以只能另寻他法。
查阅资料,发现无监督的算法更适合工业缺陷检测的场景。无监督算法只使用正样本进行训练,网络经过大量的正样本学习,在遇到负样本时,就会知道负样本和正样本“长得不一样”,然后输出和原图尺寸相同的一张概率分布图,来表示某处是异常区域的概率大小。
无监督学习方法虽好,但作为伸手党应该去哪里要代码呢?个人感觉最好的地方就是Anomalib,它使用Python实现,资料完备易懂,目前仍然在更新。链接如下:GitHub – openvinotoolkit/anomalib: An anomaly detection library comprising state-of-the-art algorithms and features such as experiment management, hyper-parameter optimization, and edge inference.![]() https://github.com/openvinotoolkit/anomalib
https://github.com/openvinotoolkit/anomalib

看到英文名字就可以知道:这是一个异常检测(Abnormal)的库(library),里面的内容的确十分丰富,集成了十余种近年来准确率较高的缺陷(异常)检测算法,基本都是无监督学习的方法,诸如padim算法、fastflow算法等。

找到这个宝库,我们下一步需要探索它的代码结构和用法。
二、Anomalib代码结构
我在本地使用Pycharm编程,新建项目后Anomalib的代码结构如下:
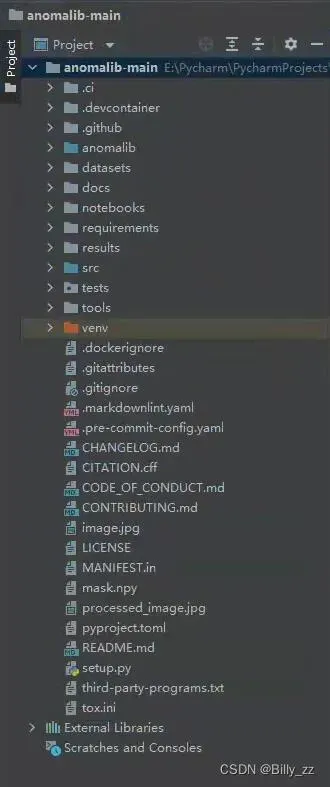
若想理清楚该项目的代码结构,方便后面的训练和部署,需要一点点进行分析。其中,比较重要的几个部分是:
1. anomalib文件夹:事实上本文件夹就是该团队发布的库的源码,我们同样可以通过pip install的方法来进行安装,
1.1 该文件夹下的models子文件夹包含了十余种缺陷检测的算法,可供读者任意调用;
1.2 pre_processing和post_processing子文件夹分别是预处理和后处理功能,最终显示推理结果就使用了post_processing下的visualizer。
1.3 deploy文件夹中的inferencers则是各种推理器,想要使用pytorch的读者可以关注torch_inferencer,想要使用onnx推理的读者则应该使用openvino_inferencer。
2. datasets文件夹:顾名思义,该文件夹中应该存放待训练的数据集,如工业数据集MVTec,或者我们自制的数据集。
3. results文件夹:该文件夹存放的是训练和推理的结果,只有在完成了训练或推理任务后才会出现。
4. tools文件夹:该文件夹中的inference子文件夹存放了一系列推理代码,它们分别调用了anomalib.deploy中的不同inferencer(推理器)。该文件夹下的train.py是训练模型的入口。
总结:我们后面需要使用tools/train.py进行模型训练,使用tools/inference中的某个推理代码进行模型推理预测。有了以上预备知识,我们终于可以开始模型的训练了。
三、任务描述和模型训练推理
若读者只想在pycharm中看一个算法的效果,那么按照官方的示例,使用train.py训练后再使用lightning_inference.py进行推理即可,在新出现的result文件夹中便可以看到推理结果,十分方便,此处不予赘述。
但对于包括我在内,后续需要在其他平台部署的读者,我们需要训练自己的数据集并得到onnx模型,这样就需要对config.yaml文件进行修改,方法如下:
首先依然按照官方的方案,看Readme中训练Custom Dataset的方法:
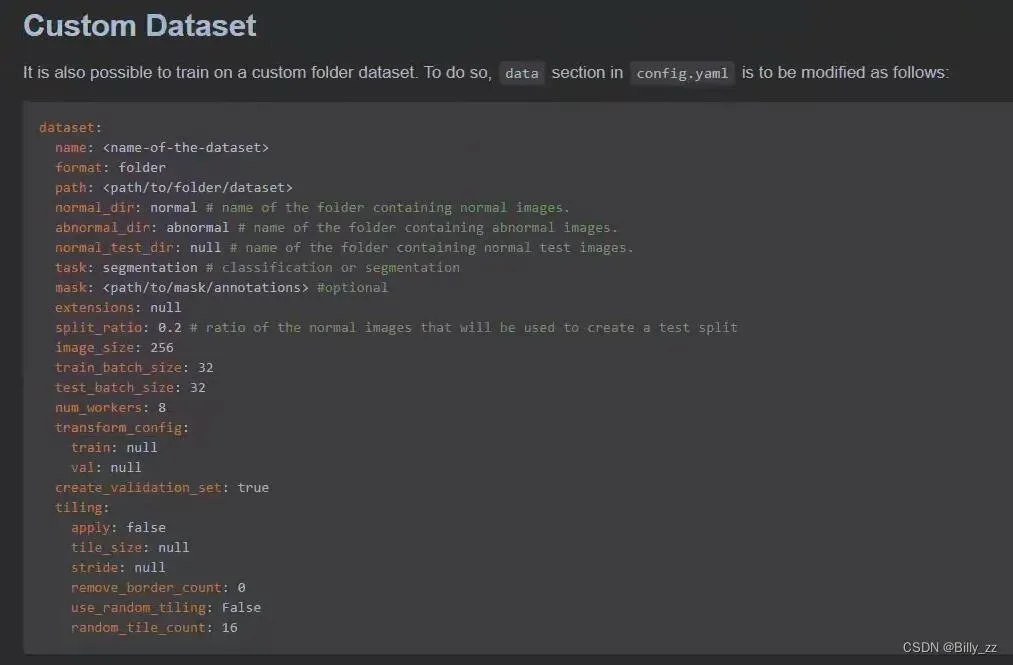 这里我们使用的是padim算法,于是我们将anomalib/models/padim/config.yaml的dataset部分按以上部分修改后在终端运行以下训练命令:
这里我们使用的是padim算法,于是我们将anomalib/models/padim/config.yaml的dataset部分按以上部分修改后在终端运行以下训练命令:
python tools/train.py --model padim --config anomalib/models/padim/config.yaml
但会报错:找不到“normalization”等属性,此时不要着急,之前的config.yaml中实际上这些属性都是在的,这里官方竟然没有写进来,可能是疏忽了,我把自己的config.yaml的datasets部分放在这里,读者可以按照自己的自制数据集的路径进行改写,需要添加和注意的地方我都做了注释:
dataset:
name: tube # 数据集的名字,如MVTec等,这个不重要
format: folder
path: ./datasets/img_192 # 自制数据集路径
normal_dir: normal # 自制数据集正样本子文件夹
abnormal_dir: abnormal # 自制数据集负样本子文件夹
mask_dir: null # 二值掩膜路径,自制数据集一般没有,填null
normal_test_dir: null # name of the folder containing normal test images.
task: classification # classification or segmentation
extensions: null
normalization: imagenet # 此处添加imagenet
split_ratio: 0.2 # ratio of the normal images that will be used to create a test split
image_size: 256
train_batch_size: 32
test_batch_size: 32
num_workers: 8
transform_config:
train: null
val: null
test_split_mode: from_dir # 此处添加
test_split_ratio: 0.2
val_split_mode: same_as_test
val_split_ratio: 0.5
create_validation_set: true
tiling:
apply: false
tile_size: null
stride: null
remove_border_count: 0
use_random_tiling: False
random_tile_count: 16需要特别注意的是:由于我们使用自制数据集,往往没有ground truth的二值化掩膜(mask),所以这里需要将task字段设置为classification而不是segmentation。接着将metrics部分的pixel部分删掉,否则会报错。原因是没有提供二值化掩膜,无法计算基于像素的测试准确度,只保留image部分。修改如下:
metrics:
image:
- F1Score
- AUROC
# pixel:
# - F1Score
# - AUROC
threshold:
method: adaptive #options: [adaptive, manual]
manual_image: null
manual_pixel: null我们还需要onnx模型,这里需要在config.yaml中的optimization部分加入onnx字段:
optimization:
export_mode: onnx # options: torch, onnx, openvino至此,我们就可以再次运行训练命令,开始训练了:
python tools/train.py --model padim --config anomalib/models/padim/config.yaml
padim算法的论文我并没有研读,但似乎其训练过程只需要一轮, 训练完成后,在results文件夹中可以看到如下结构:
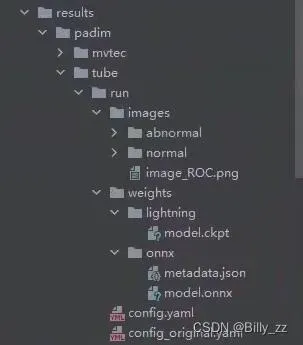
tube是博主本人数据集的名字,下面的images文件夹中有对正样本和负样本图片的测试结果,以概率热图的形式给出;weights文件夹中有pytorch-lightning的模型和我们所需的onnx模型,以及包含了训练数据集信息的metadata.json(对于部署十分重要,下一篇再说)。
做完以上步骤,我们得到了onnx模型,但在部署之前,还是看一下转换后的模型有没有精度损失,在终端输入以下命令:
python tools/inference/openvino_inference.py --weights results/padim/tube/run/weights/onnx/model.onnx --metadata results/padim/tube/run/weights/onnx/meta_data.json --input datasets/img_192/abnormal/cam0_17_04_54.jpg --output results/padim/tube/run/images --config src/anomalib/models/padim/config.yaml
得到以下推理结果:
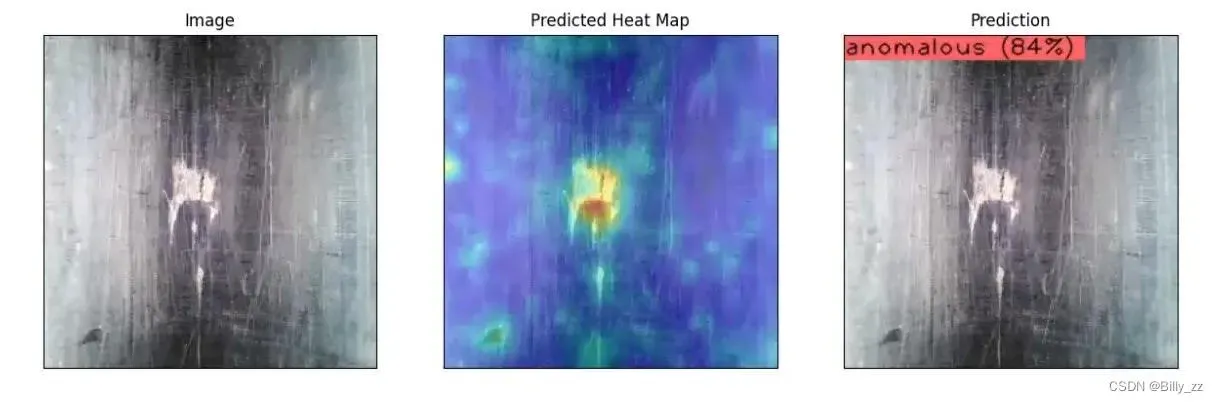
效果不错,在工业缺陷检测这方面,终于可以和yolov5说拜拜了~
四、总结与展望
我们使用padim算法在自制工业数据集上获得了良好的检测效果,通过训练得到了onnx模型;在这个过程中,最需要注意的就是配置文件config.yaml的修改,要按照官网教程、本博客和自己数据集的路径进行配置和修改,防止出错。
在得到了onnx模型后,我们想要脱离开庞大繁杂的Anomalib项目和环境,完成自己的软件算法部署,但图像数据在送入onnx模型之前需要什么预处理步骤?模型输入输出分别是什么?输出的数据需要怎样的后处理?怎么画出Anomalib中十分简洁明了的热图呢?这些都是需要我们解决的问题。
下一篇博客我们将继续从Anomalib的代码结构和流程进行分析,使用onnxruntime引擎完成onnx在C++中的部署,实现算法的落地。
版权声明:本文为博主作者:Billy_zz原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_57315535/article/details/131004027