一、动机
近年来,transformer在语义分割领域大行其道,这得益于self-attention对空间信息的编码能力,但transformer的计算无疑是昂贵的。相对比之下,卷积操作更为cheap。为了Make Convolutional Great Again,作者重新审视了历代SOTA模型的设计,发现了几个使分割模型性能提升的关键成分:
Strong encoder:以强大的backbone作为encoder;
Multi-scale interaction:使用多尺度信息融合;
Spatial attention:使用空间注意力;
Computational complexity:更低的计算复杂度:

于是,作者重新设计了卷积注意力并提出一个有效且高效的encoder-decoder语义分割架构。具体的,
对encoder中的每个卷积块进行重新设计,并通过一个简单的元素乘的方式提供多尺度卷积特征来唤醒空间注意力;
对decoder,使用了来自不同阶段的多级特征并使用Hamburger方法进一步提取全局信息。
通过这种方式,本文的方法能够获取从局部到全局的多尺度上下文信息、实现了空间和通道上的适应性、聚合了从低到高各个级别的信息。
二、方法
1. 卷积encoder
首先总体结构是金字塔型的,这是传统。然后,对于每个构造块,使用了一种结构与ViT类似但没有使用self-attention的注意力机制——多尺度卷积注意力(MSCA)模块,结构如图Fig. 2(b):
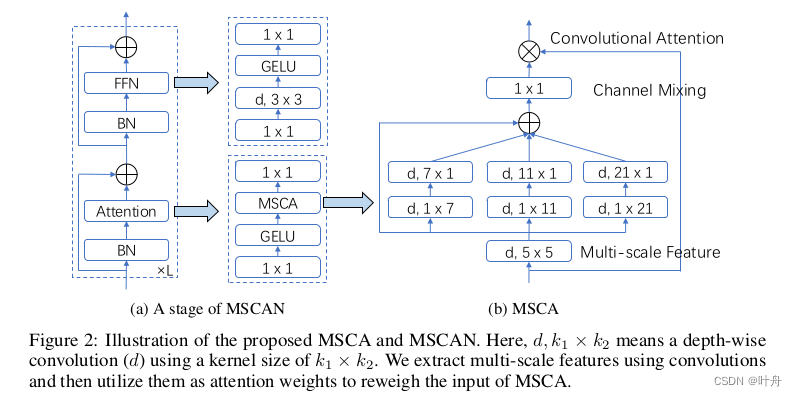
可见,MSCA包含了三个部分:
一个depth-wise卷积(Fig. 2(b)中的"d,5*5")用于聚合局部信息;
带有shortcut的多分支depth-wise条形卷积(7*1,1*7,11*1,1*11…),用于捕获多尺度上下文信息;
一个1*1卷积,用于建模通道间的关系;
MSCA的公式如下:
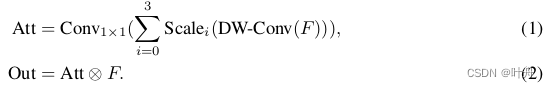
其中,F是输入的特征,Att和Out分别是注意力map和输出 ,Att和F进行逐元素的矩阵乘得到Out;DW-Conv代表depth-wise卷积,Scale_i表示Fig. 2(b)中的分支,Scale_0表示shortcut分支。
作者使用条形卷积有两个原因:一是条形卷积比较轻量;二是在语义分割中有些目标 本身就是条形的,如人体、电线杆。
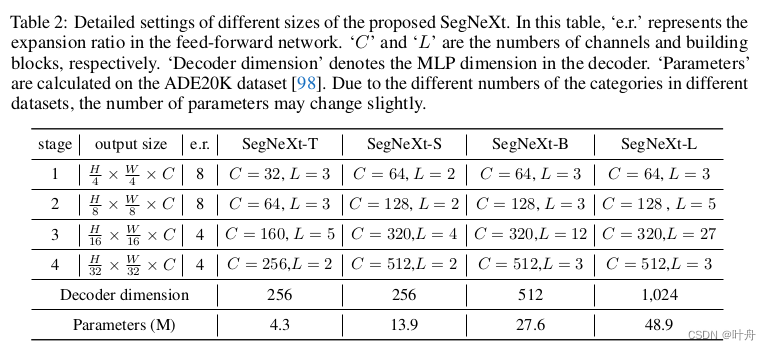
多个MSCA级联起来,就形成了一个卷积encoder——MSCAN。MSCAN的设计跟之前的各种backbone类似,也是分四个stage,每个stage下采样两倍,从1/4到1/32,结构设计如图:
2. Decoder
作者调查了三种简单的decoder架构,如图Fig.3:
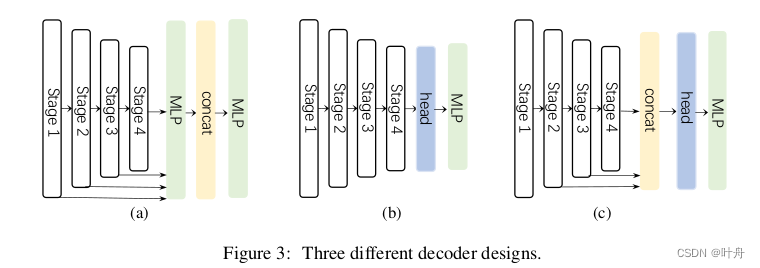
第一种是SegFormer中的,是一个纯MLP结构;第二种是个卷积模型,其将encoder的输出直接送入一个复杂的head,如ASPP、PSP等;第三种是本文的SegNext所用的,首先将后三个stage的输出concat起来,然后送入一个轻量的Hamburger来进一步建模全局上下文。
这里之所以只concat后三个stage,是因为SegNext的Encoder是卷积架构,第一个stage包含了大量低级特征,这会有损性能,而且stage1会带来大量的计算。
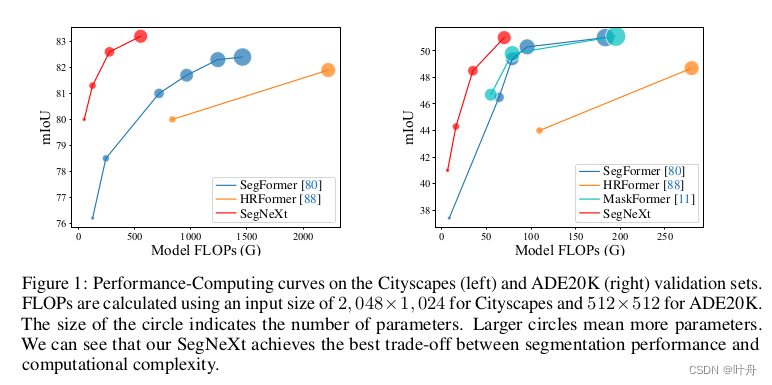
三、实验结果
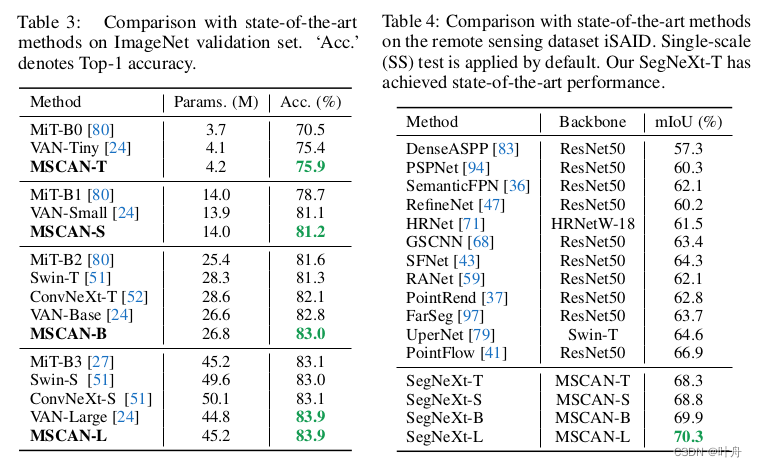
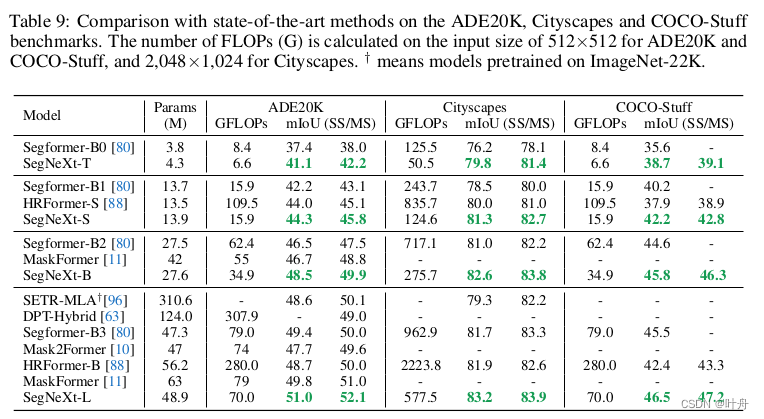
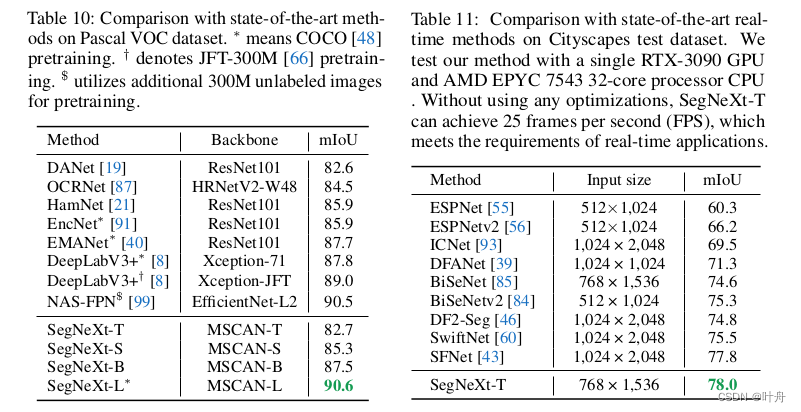
四、写在后面
这篇文章算是CNN对Transformer发起的一次反攻,其证明了通过合适的设计,CNN同样可以达到甚至超越Transformer。
不过作者也提到,这篇文章的方法也有限制,如更大规模的模型(100M+)、其他视觉任务、NLP任务等方面,还不能work。
文章出处登录后可见!