doi : 10.3969/j.issn.1003-3114.2021.02.001
引用格式:孔令军,王茜雯,包云超,等.基于深度学习的医疗图像分割综述[J].无线电通信技术,2021,47(2):121-130.
本文选自

摘要:自 2006 年深度学习这一概念提出以来,各研究领域对于深度学习技术的研究热度一直高居不下。 深度 学习的出现,对计算机视觉领域的发展起到了重要推动作用。 计算机视觉的主要研究任务是对图像、视频等进行目标 的检测、识别以及分割等,目前已经广泛应用于医疗、金融和工业领域中。 其中最常见的应用场景是医学图像处理。 图像分割是医学图像处理任务中一个重要的研究方向,目前已经出现了很多图像分割方法,其中包含传统的分割方法 和基于深度学习模型的分割方法。 首先介绍了阈值分割法、区域生长法以及图割法等传统的图像分割方法;其次总结 了 FCN、U-Net、U-Net++、SegNet 以及 DeepLab 系列的网络架构,并对其优缺点进行了分析;同时,着重阐述了图像分割 方法在医疗图像处理中的应用;最后讨论了未来基于深度学习的医学图像分析将要面临的挑战和发展机遇 。
关键词: 人工智能;深度学习;医疗图像;图像分割
以下仅标注学习中遇到的重要内容。
0.引言
深度学习与传统机器学习的对比,凸显优点,本文主要描述基于深度学习的医疗图像分割。
深度学习有别于其他编程算法的主要特点是通过神经网络对输入数据进行特征提取,而不需要过 多的人为参与。 传统的机器学习系统通常要通过专业人员对输入数据进行人工特征提取,将原始的输入数据转化为系统能够识别的形式,而深度学习减 弱了对人工提取特征的要求,原始数据在通过神经网络之后,可以自主学习到有用的信息,使得系统可以得到最优的输出。
由深度学习引出研究方向:图像分割,并明确图像分割在医疗影像处理中的应用和目的。着重找出感兴趣区域(Region of Interest)
图像分割可以提取出影像图像中的特定组织或结构,给医生提供特殊组织的定量信息。 图像经过分割,可以应用于 各种场合,例如定位病变组织、实现精准注射以及组 织结构清晰化呈现等。
在医生做诊断时,只需要对医学影像中的部分 组织或结构进行分析,这部分图像被称为感兴趣区 域(Region of Interest,ROI),这些 ROI 通常对应于不同的器官、病理或者是其他的某些生物学结构。 医疗图像分割的目的即为分割出影像图片中的 ROI, 除去无用信息。
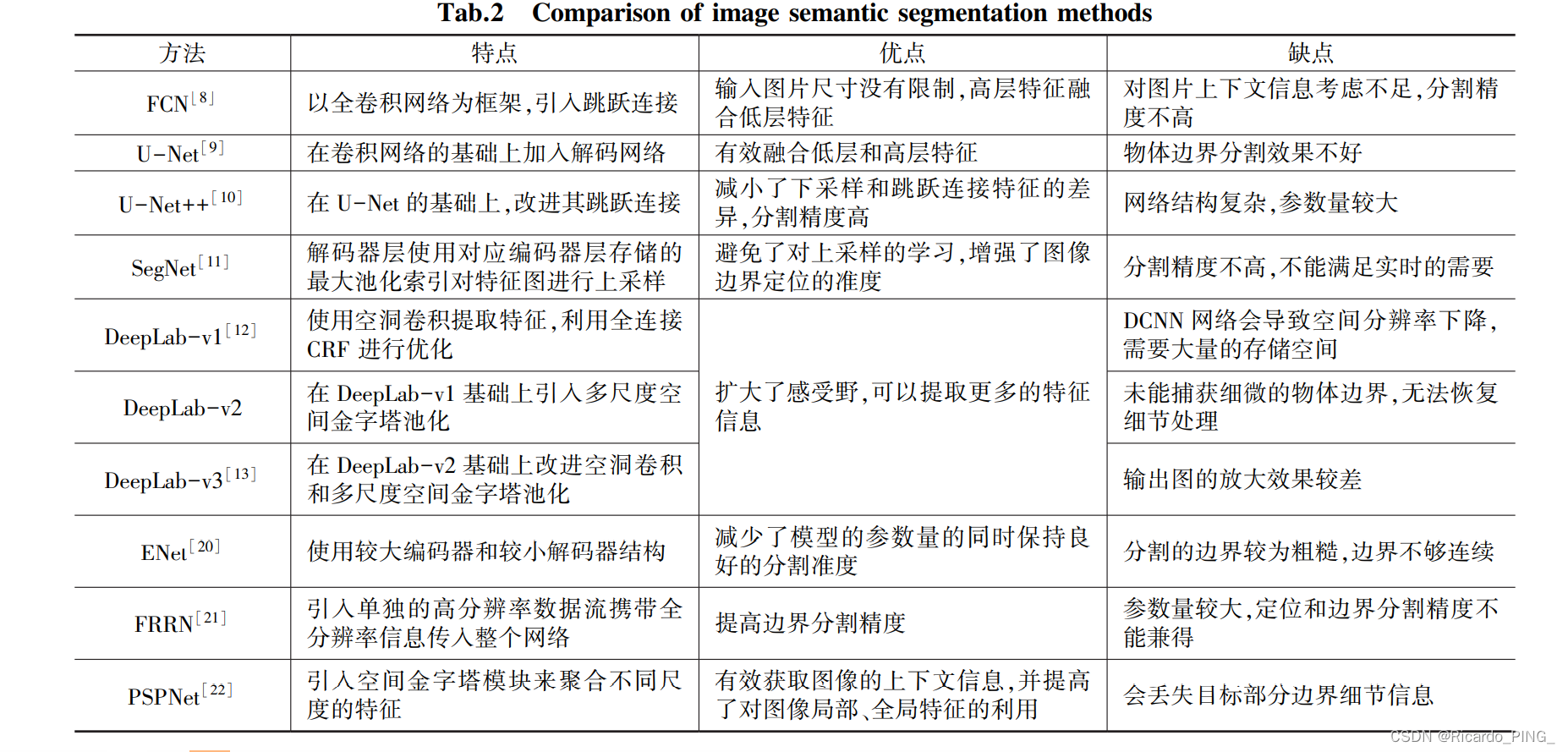
1.传统图像分割方法
首先举例三种传统的图像分割方法,通过原理-应用场景-优缺点这种模式写的比较清楚。
阈值分割法
阈值分割法是传统图像分割方法中最基本的图 像分割法,因其计算复杂度小,易于实现,且分割结 果直观而成为图像分割方法中最为广泛应用的分割 法,图像二值化分割公式如式(1) 所示。 阈值分割 法中,如何选择最佳阈值是该技术的核心所在。
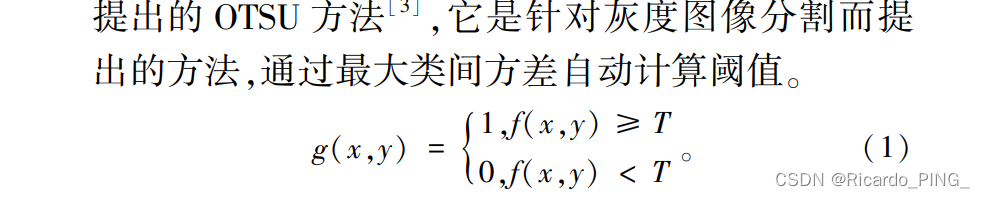
阈值分割法没有很好地利用好像素的空间 信息,使得分割结果容易受到图片内噪点的影响, 因此只适用于目标的类内方差较小的图像处理, 比如指纹。
区域生长法
区域生长法是利用图像灰度值的相似性,将相 似像素或者相似子区域集合起来形成更大区域。 区 域生长法中较为著名的是分水岭算法 。
区域分割法实现简单,可以保证分割后的图像 在空间上的连续性,适用于分割连续的均匀小目标。 其缺点是需要人为参与来选择每个区域合适的种子 点,且该算法对噪声敏感,不适用于大区域的分割, 可能导致过分割或者欠分割。
图割法
图割法是一种基于图论的图像分割方法,通过 建立一种概率无向图模型来实现图像分割。 这种概 率无向图模型又被称马尔可夫随机场。
图割方法鲁棒性高,分割较为复杂的图像也能 得到很好的效果,但其具有较高的时间复杂度和空 间复杂度,通常与其他传统分割方法搭配使用。
2.基于深度学习的医疗图像分割算法
基于深度学习 的医疗图像分割法主要有基于全卷积网络( Fully Convolutional Networks,FCN)的图像分割方法、基于 U-Net 网络的图像分割方法以及基于 U-Net++网络 的图像分割等方法。
FCN
FCN 主要思想是搭建一个只包含卷积操作的网络,输入任意尺寸的图像,经过有效推理和学习可以得到相同尺寸的输出。 FCN 的网络结构是一种编码—解码的网络结构模式,将经典卷积神经网络 (Convolutional Neural Networks,CNN)中的全连接层替换为卷积层,从而使整个网络主要由卷积层和池化层组成,因此称为 FCN。
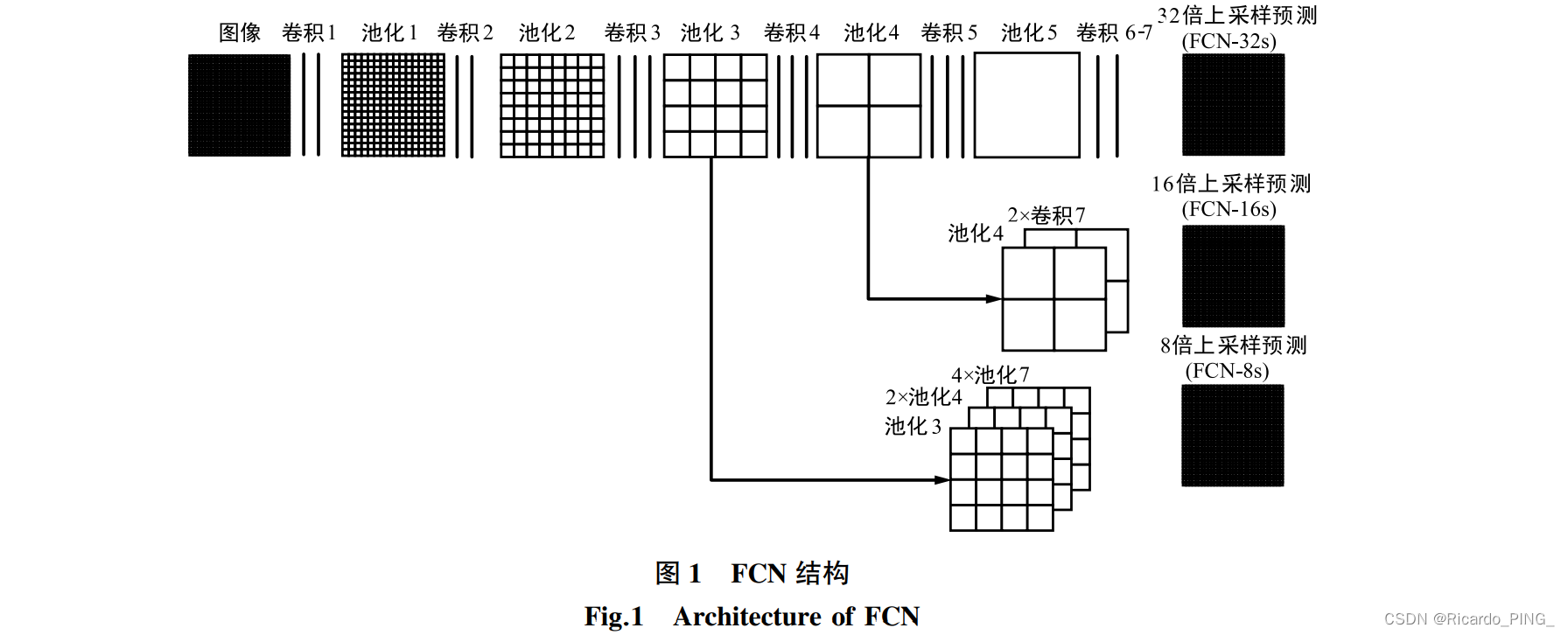
如图 1 所示。 网络结构中, 编码器部分主要作用是提取图像中的高维特征,图像经过卷积层和池化层后空间维度降低,而解码器部分则对该输出特征图进行上采样,将该特征图恢复到与输入图像相同的尺寸,同时将提取到的高维 特征映射到最终特征图的每个像素,从而可以实现像素级别的图像分割。
优缺点:相对于经典的 CNN 网络,FCN 的优点是对输入 网络的图像尺寸没有限制,但其缺点也是不可忽视 的,FCN 采用的逐像素进行分类忽视了各个像素之 间的联系,没有考虑全局上下文信息,且上采样部分 是进行了一次上采样操作,直接将特征图进行 8 倍、 16 倍、32 倍扩大会忽视图像中的细节信息,使结果较为模糊。
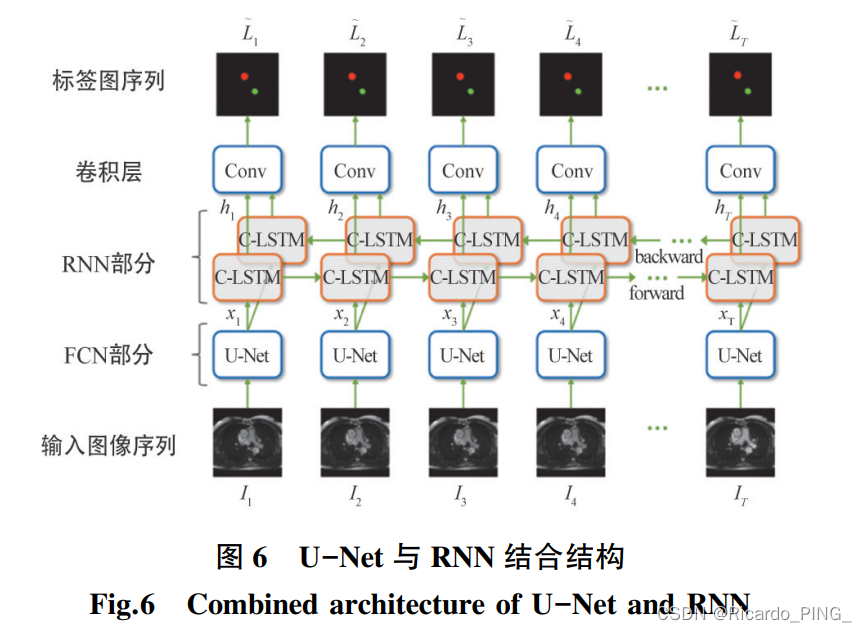
U-Net
U-Net 网络是在 FCN 基础上做了改进的版本,其网络结构 与 FCN 的结构相似,没有全连接层,由卷积层和池 化层构成,同样是分为编码器阶段和解码器阶段。
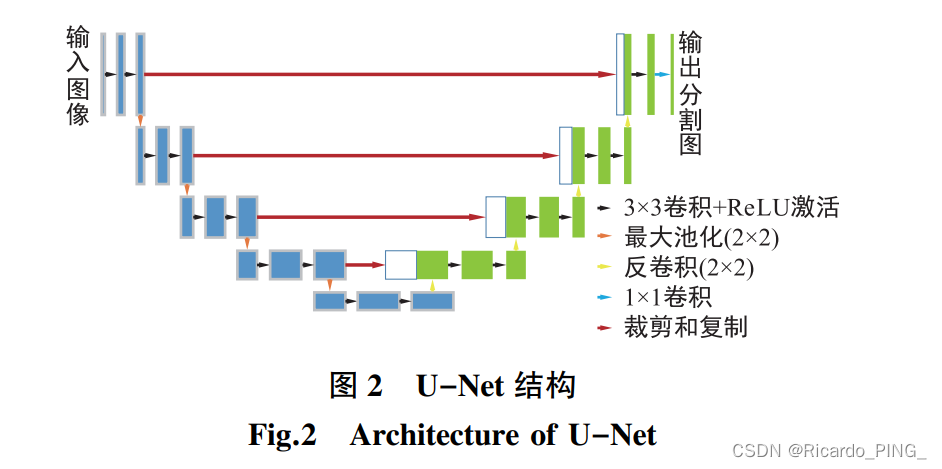
U-Net 结构如图 2 所示,网络结构主要包括下采样 部分、上采样部分以及跳跃连接部分,上采样和下采 样部分对称,网络整体形成 U 型结构。 下采样部分 主要作用为提取图像中的简单特征,而上采样部分 经过了更多的卷积层,感受野更大,提取到的特征是 更为抽象的特征,跳跃连接融合了下采样结构中的 底层信息与上采样结构中的高层信息,以此来提高 分割精度。
U-Net++
U-Net++是在 U-Net 基础 上针对原始结构中的跳跃连接部分做了进一步的改进。
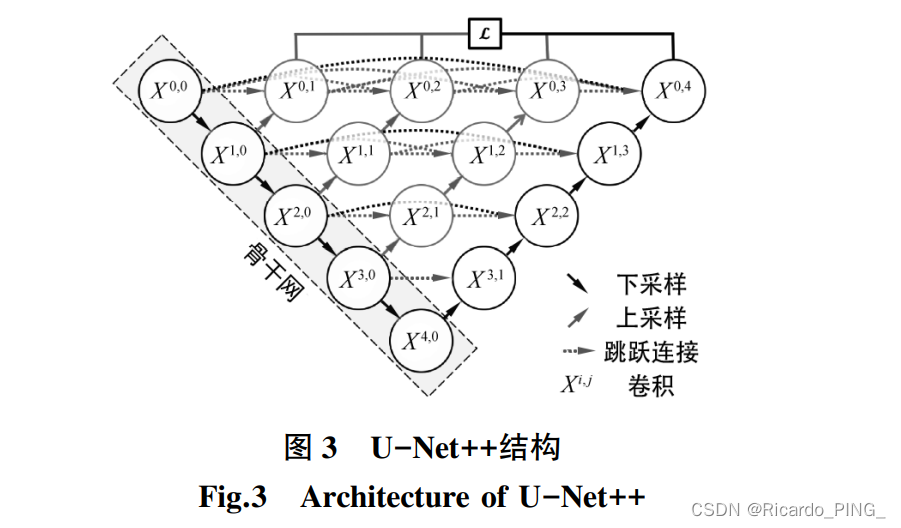
其结构如图 3 所示,X 定义为卷积操作。 原始 U-Net 结构中的跳跃连接用的是直接串联方式,而 U-Net++的跳跃连接改用密集连接方式。 采用密集 连接方式,网络得以在训练过程中自动学习不同深 度特征的重要性,从而可以根据需要选择合适的下 采样层数,在保证网络性能的条件下减少了网络参数。
相较于U-Net,其改进的优缺点为:
U-Net++采用密集连接,网络 可以将来自不同层的特征进行特征叠加,减小了下 采样阶段特征和上采样阶段特征之间的语义差异, 更利于网络的优化。 更多的特征信息也有效地避免 了原始图像中的小目标和大目标边缘等信息随网络层数增加而丢失的现象。
U-Net++的另一个特点为网络共享了同一个下采样部分,使得训练过程只需要训练一次下采样网 络,不同深度的特征由对应的下采样层以对称方式 还原。 除了在跳跃连接上做改进之外,U-Net++还 增加了深监督,将网络结构各层的输出也连接到最终输出。
SegNet
SegNet 的编码网络和 VGG-16 的卷积层部 分相同,同样不含全连接层,主要作用是进行特征提取。
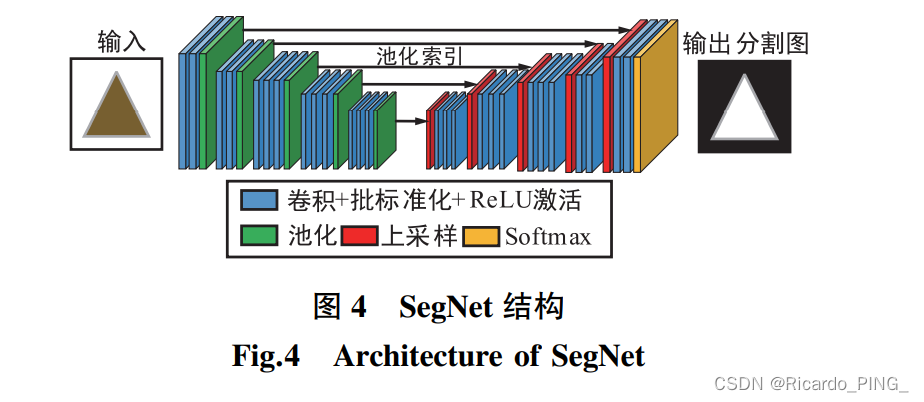
整个网络的新颖之处在 于,解码器对较低分辨率的输入特征图进行上采样。 具体地说,解码器使用从相应的编码器接收的最大池化索引来进行对输入特征图的非线性上采样。 这 种方法减少了对上采样的学习,改善了边界划分,减少了端到端训练的参数量。 由于上采样而变得稀疏的特征图随后经过可训练的卷积操作生成密集的特 征图。 最后由网络的最后一层 softmax 层来求出图 像的每一个像素在所有类别中最大的概率,从而完 成图像的像素级别分类。 SegNet 只存储最大池化索 引,并将其应用于解码网络,以此来得到更好的表 现。 因此相比于其他分割网络,SegNet 的突出优点 是更加高效。
DeepLab系列
其中DeepLab主要分为三个系列。
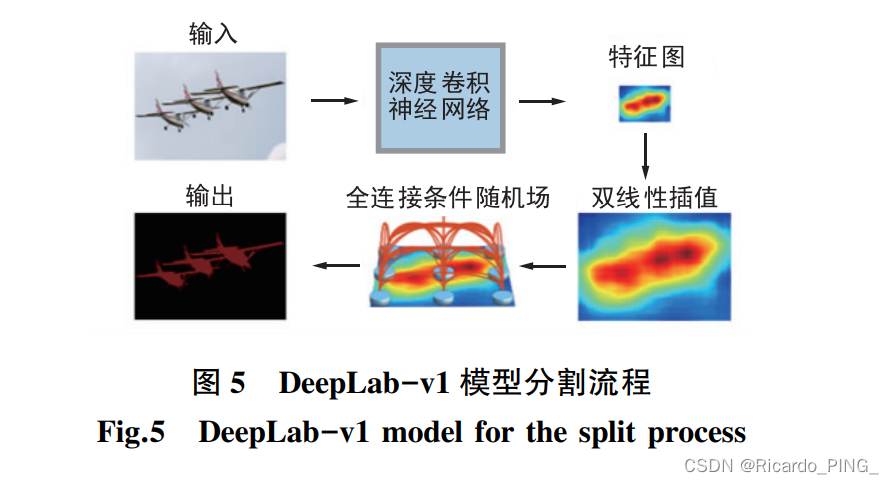
DeepLab-v1网络:将 FCN 与条件随 机 场 模型相结合,解决 了 FCN 分割不够精确的问题。
加入了三个创新点
其主要结构为在 FCN 之后串联完全连接的 CRF 模型。 CRF 将来自 FCN 的粗糙分割结果图进行处理,在图中的每个像 素点均构建一个 CRF 模型,以此获得图像更为精细 的分割结果。 同时,DeepLab-v1 中加入带孔算法来 扩展感受野,感受野越大则可以获得图像更多的上 下文信息,也避免了 FCN 在一步步卷积和池化过程 中特征图分辨率逐渐下降的问题。 DeepLab-v1 的 另一个改进点为添加了空洞卷积,大大提高了运行 速度。
DeepLab-v2网络:相较于v1改进的地方是使用了空洞空间卷积池化金字塔模块。
采用不同采样率的空洞卷积对特征图 进行并行采样,并将输出结果进行融合,以此可以获 得更多的空间信息。 另外,该网络将传统的 VGG- 16 模块替换为 ResNet 模块, 进一步提升了分割 效果。
DeepLab-v3网络:
该网络重点研究了网络中空洞卷积的使 用,提出将级联模块采样率逐步翻倍,同时扩充了 DeepLab-v2 模型中的 ASPP 模块,增强了其性能。 该网络在 PASCAL VOC 2012 数据集上获得了比之 前的 DeepLab 更好的分割结果。
图像分割算法优劣和性能比较
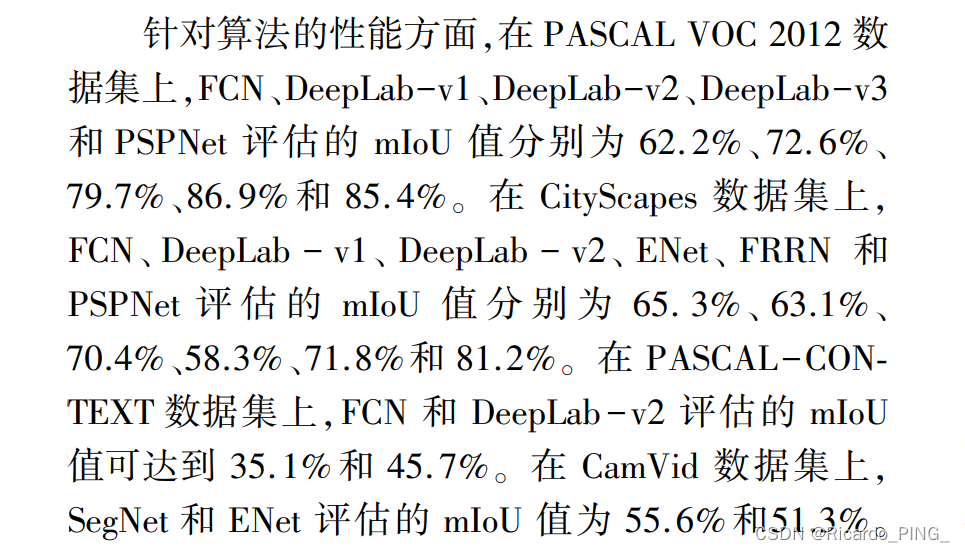
MIoU(Mean Intersection over Union)是语义分割的一个评价指标,表示平均交并比,即数据集上每一个类别的IoU值的平均。
那么什么是IoU呢,以下面这张图直观地说一下:

图中,左边的圆表示某个类的真实标签,右边的圆表示其预测结果,
- TP表示真实值为Positive,预测为Positive,称作是正确的Positive(True Positive=TP)
- FN表示真实值为Positive,预测为Negative,称作是错误的Negative(False Negative=FN)
- FP表示真实值为Negative,预测为Positive,称作是错误的Positive(False Positive=FP)
- TN表示真实值为Negative,预测为Negative,称作是正确的Negative(True Negative=TN)
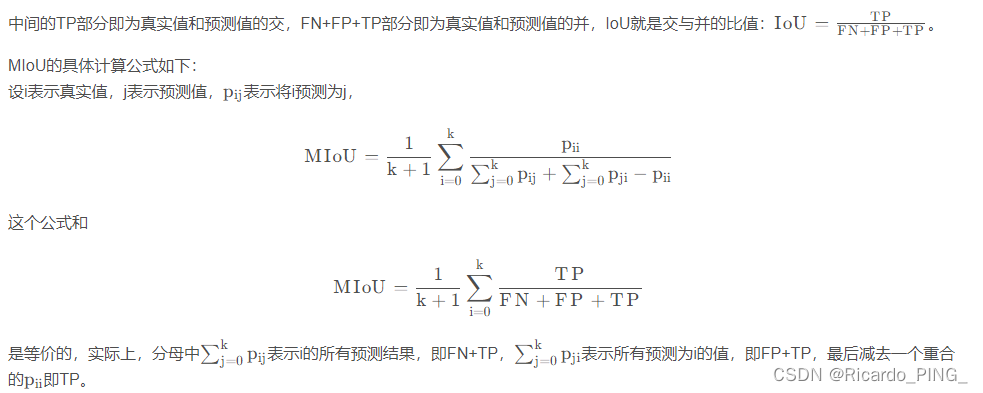
那么TP、FN、FP怎么计算呢?这就涉及到混淆矩阵了。
假设有一张图片,其所有的像素分属于4个类别。在预测分割之后,我们可以根据真实值和预测值获得一个混淆矩阵,形如:


总结一下,计算MIoU的三个步骤:
- 计算混淆矩阵
- 计算每个类别的IoU
- 对每个类别的IoU取平均
医学图像分割技术难点
医学图像具有的一些独特的特点,使得医学图 像的分割比自然影像的分割更为复杂。 具体表现为:
数据量少、目标较小、图像语义简单、多维图像、多模态
医学图像的这些特点,决定了医学图像分割必 须使用编码器-解码器结构的网络模型。 医学图像 分割技术的高难度、高复杂度,是使医学图像分割在 图像分割领域中受到特别关注的主要原因。
分割算法在医疗影像领域的应用


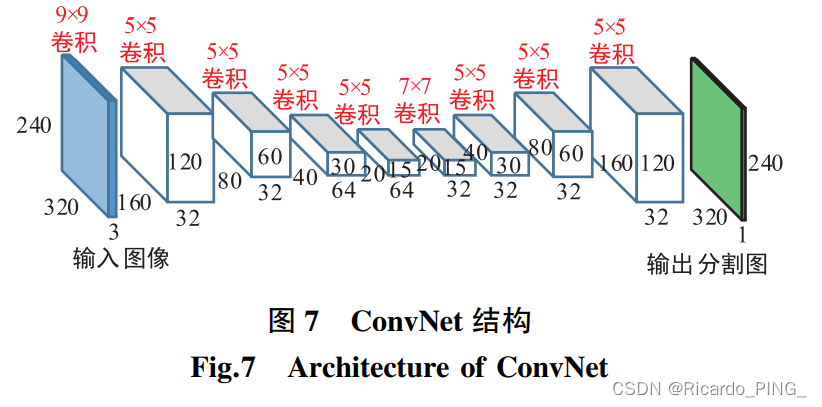
Wang 等人[32]提出一个对伤口图像进行处 理的系统,可以实现对图像中的伤口区域自动分割 并分析伤口状况。 伤口图像输入深卷积神经网络 (ConvNet),自动分割出输入图像中的伤口区域,得 到的分割图像送入 SVM 分类器中进行判断伤口是 否感染,并通过高斯过程回归算法对伤口的愈合进 程进行预测。 ConvNet 架构如图 7 所示。
数据集与损失函数
数据集
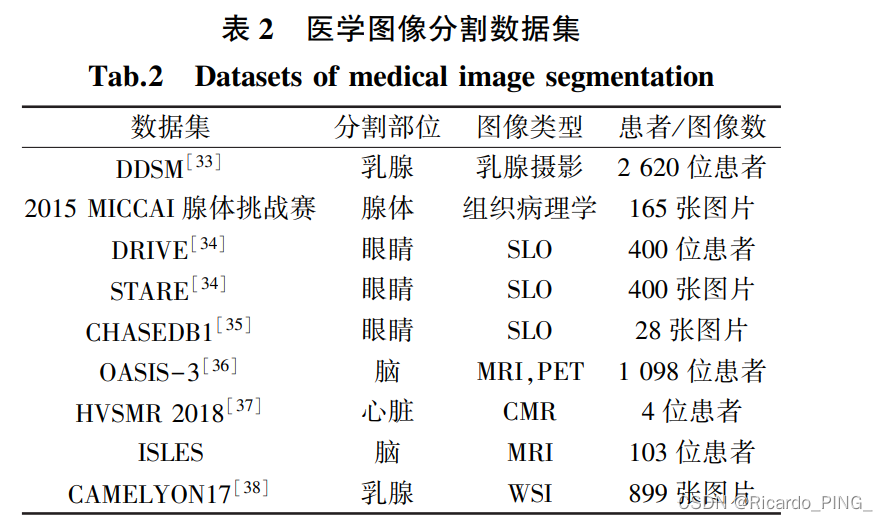
常见的深度学习分割网络属于有监督学习算 法,在训练时需要使用大量带标签的数据。本篇论文整理了医学图像处理常用的数据集。
损失函数
简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失(当然损失值越小证明模型越是成功),我们知道有许多不同种类的损失函数,这些函数本质上就是计算预测值和真实值的差距的一类型函数,然后经过库(如pytorch,tensorflow等)的封装形成了有具体名字的函数。







总结与展望
现阶段的深 度学习分割网络的发展演进存在一定的困难和挑战。未来要开始着力于探索新的创新。
半监督或无监督条件下的图像分割。 有监 督训练下的模型对于某些需要大量训练数据的模型 很难发挥其效能。 在缺乏标注数据的问题下,半监 督或无监督条件下的图像分割将是未来的主要研究 方向之一。
生成式对抗网络生成数据集。 将 GAN 框架 生成的图像数据与原始数据进行结合共同参与模型 训练可以提高模型性能,这一特性对于医学图像分 析尤为重要。 如何对原始数据和生成数据进行合理 分工以使训练模型达到最优性能是当下及未来需要 解决的一个重要问题。
文章出处登录后可见!