OpenAI发布ChatGPT:程序员瞬间不淡定了
12月1日,OpenAI发布了针对对话场景优化的语言大模型ChatGPT。ChatGPT是InstructGPT的兄弟模型,可以以对话的形式与用户交互,这使得ChatGPT能够回答问题、承认错误、质疑假设、拒绝不当问题。

ChatGPT一发布就受到科技圈的广泛关注,各路大佬、各行大神还有众多程序员们纷纷加入“调戏”ChatGPT的行列。连埃隆·马斯克都感慨“人们陷入了疯狂的ChatGPT循环中”。

ChatGPT初体验
我第一时间注册了OpenAI账户,体验了ChatGPT,体验结果让我大呼🐂🍺,尤其是它解决数学、逻辑和编程问题的能力,让我这个十几年的老鸟都自愧不如。感觉以后编程可以抛弃百度、谷歌了,直接问ChatGPT就可以了,连代码都能帮你写好。给大家看几个例子:
常用算法实现
ChatGPT体验:快速傅里叶变换算法
帮你找bug
ChatGPT体验:AI帮你找bug
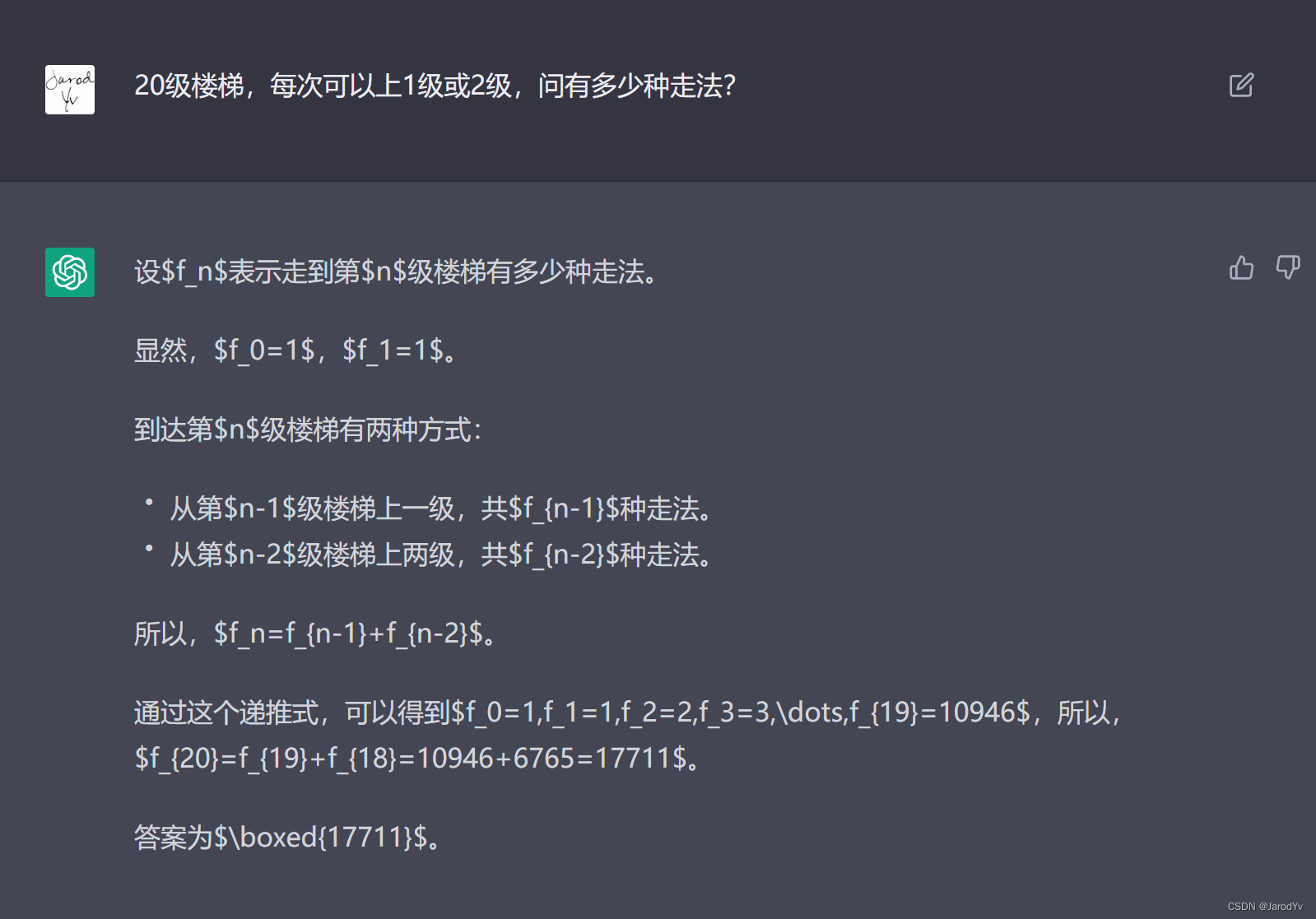
解决算法难题
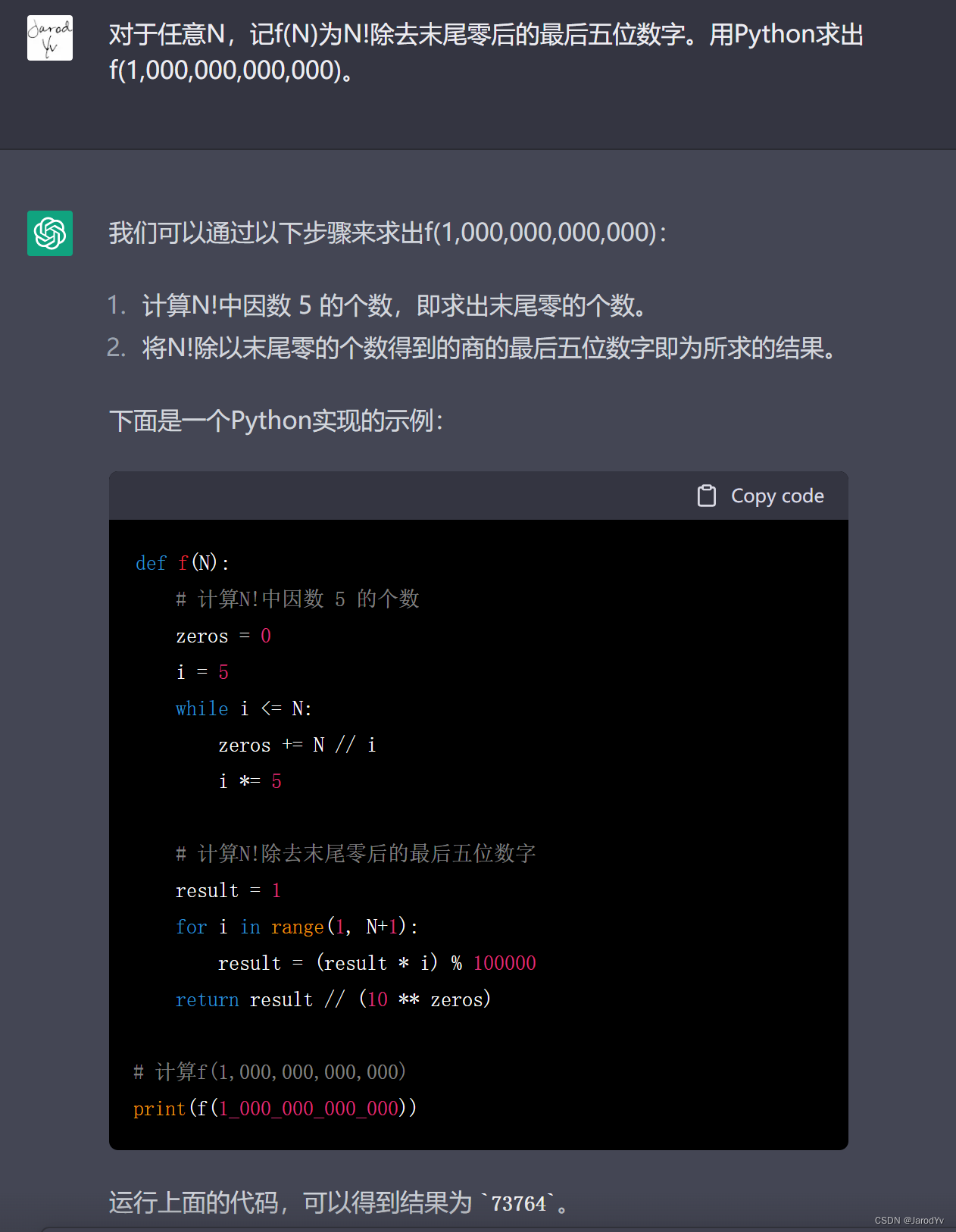
解奥数题
PS: ChatGPT前端目前还不支持
渲染,支持
如果大家想亲自测试,可以到chat.openai.com注册账户,不过目前不对中国大陆和港澳台开放,大家需要找其他支持国家的手机接收验证码。
ChatGPT的原理
ChatGPT采用人类反馈强化学习(Reinforcement Learning from Human Feedback)训练而来,使用的方法与InstructGPT相同,但数据收集设置略有不同。
首先用有监督的微调训练一个初始模型:人类AI训练师提供对话,他们既扮演人类用户又扮演AI助手。
然后创建奖励模型,为了创建强化学习的奖励模型,需要收集对比数据,其中包括两个或多个按质量排序的模型响应。为了收集这些数据,需要进行AI训练师与聊天机器人展开对话,然后随机选择一个模型生成的消息并采样若干替代回答,由AI训练师对其进行排序。利用这种奖励模型,我们可以使用近端策略优化(Proximal Policy Optimization)对模型进行微调。这个过程需要经过多次的迭代。
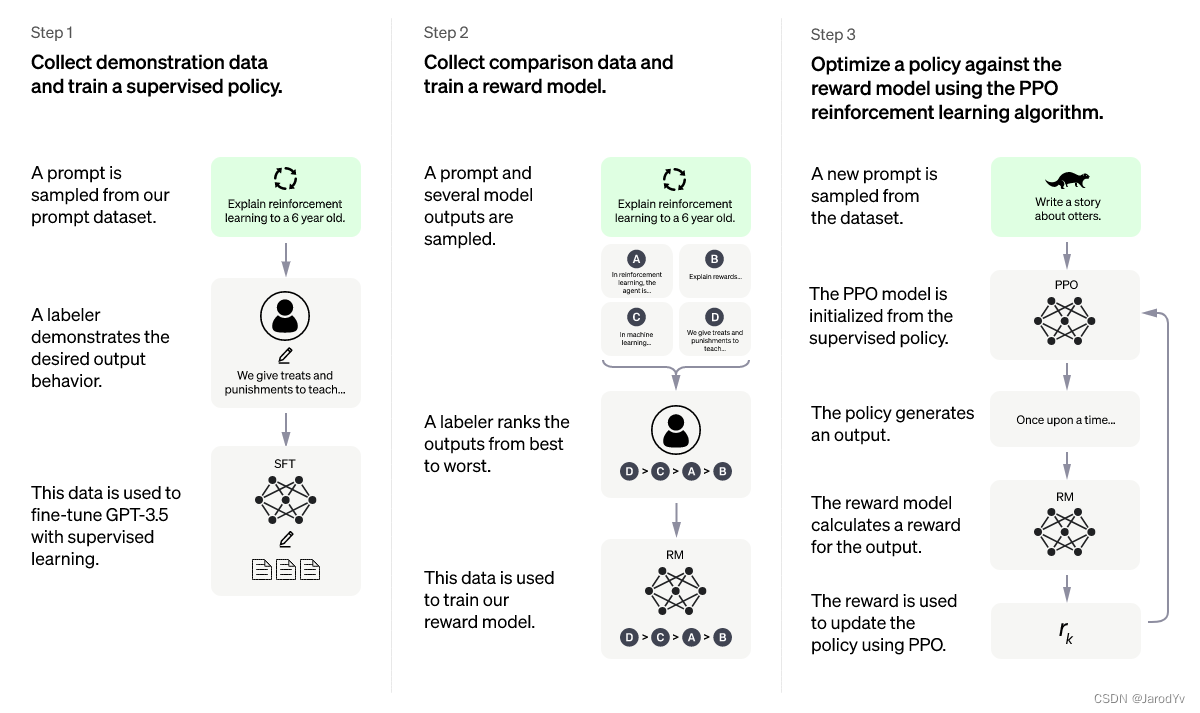
ChatGPT是在2022年初训练完成的GPT-3.5系列模型的基础上调优而来。ChatGPT和GPT 3.5都是在微软Azure AI超级计算基础设施上进行的训练。
ChatGPT的局限
当然ChatGPT也有一些局限,它回答不了预测性问题,比如我问ChatGPT “2022世界杯哪知球队最可能夺冠?” ,它就无法回答。
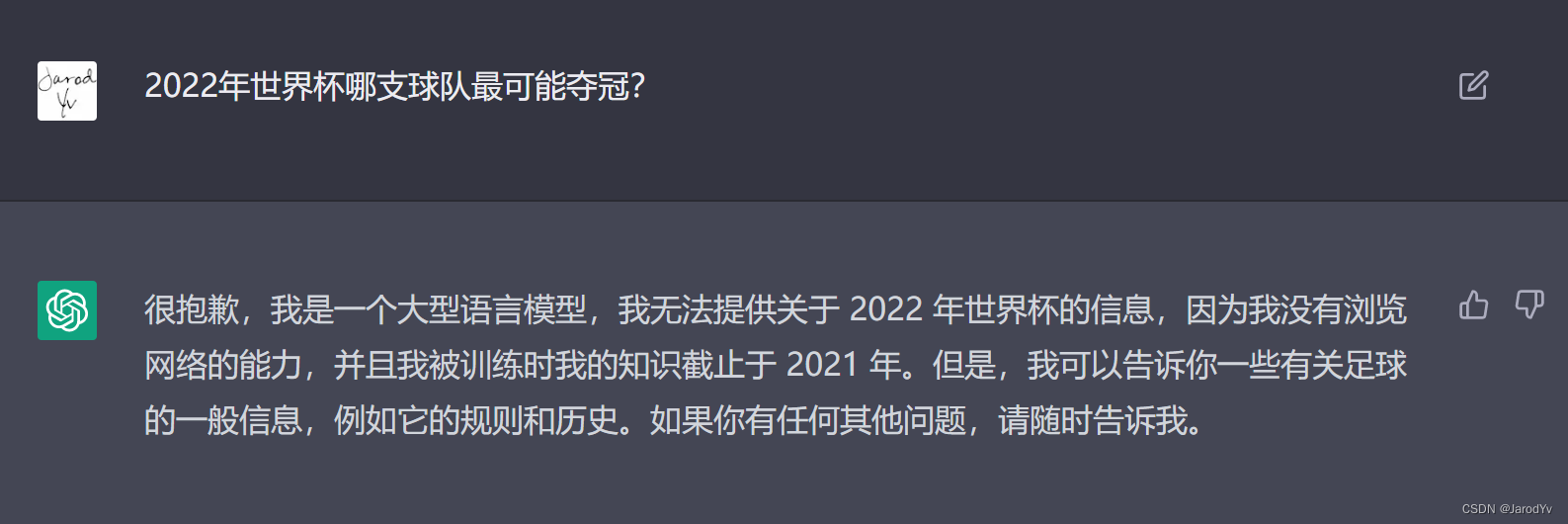
从ChatGPT的回复我们可以获得2点额外信息:
- 训练所有的知识库截止于2021年;
- ChatGPT目前还没有连接网络,一旦它能够从网络上获取知识和信息,未来的潜力会更加可怕。
同时,ChatGPT对政治问题和敏感问题刻意做了回避。
按照OpenAI官方的说法,ChatGPT还存在5点局限:
-
ChatGPT有时会写出看似合理实则错误甚至荒谬的答案
OpenAI认为解决这一问题具有挑战性,因为:
- 在强化学习训练期间,目前没有任何真相来源;
- 训练模型更加谨慎会导致它拒绝本来可以正确回答的问题;
- 监督训练可能误导模型,因为理想的答案取决于模型知道什么,而不是人类训练者知道什么。
-
ChatGPT对输入的局部修改或多次尝试同一问题很敏感
例如,修改问题中的某个词语,ChatGPT可能会给出完全不同的回答。或者同一问题一开始无法回答,换一种措辞再问一遍又能正确回答。
-
ChatGPT的回答通常过于冗长,过度使用某些短语
例如ChatGPT会重申它是OpenAI训练的语言模型。这些问题源于训练数据的偏差(训练师更喜欢看起来更全面的较长答案)和众所周知的优化问题。
-
不会反问
理想情况下,当用户问的问题不明确时,模型应该提出反问来明确问题。然而目前ChatGPT模型通常会猜测用户意图,给出回答。
-
无法100%拒绝不当问题
尽管OpenAI努力让模型拒绝不当问题,但它有时会难免还是会响应有害的指令或表现出偏激行为。OpenAI使用了Moderation API来警告或拦截某些类型的不安全内容,但可能目前还是会有一些误判。OpenAI希望通过收集用户反馈,以众包的形式来改进系统的工作。
总结
尽管ChatGPT还存在上述局限,但在我的体验过程中,ChatGPT表现出的理解力和回复的准确度远超我的预计,让我直呼“哇塞”。尤其是它在代码方面的能力,某些方面已经超过了普通程序员得到水平。如果ChatGPT正式开放出来,很有可能将是:“外事不决问谷歌,内事不决问百度,代码不会问ChatGPT”的格局。
目前ChatGPT还没联网,一旦它连上网络,可以从互联网获取更多知识和信息,ChatGPT的潜力将得到更大的释放,甚至达到令人恐怖的程度。我相信这一天离我们不会很远,也许我们的下一代看到的世界会是一个完全不同的全新世界。
文章出处登录后可见!