《繁凡的深度学习笔记》第 3 章分类问题与信息论基础 (中)(逻辑回归、信息论基础、Softmax回归)(DL笔记整理系列)
3043331995@qq.com
https://fanfansann.blog.csdn.net/
https://github.com/fanfansann/fanfan-deep-learning-note
作者:凡凡
version 1.0 2022-1-20
陈述:
1)《繁凡的深度学习笔记》是我自学完成深度学习相关的教材、课程、论文、项目实战等内容之后,自我总结整理创作的学习笔记。写文章就图一乐,大家能看得开心,能学到些许知识,对我而言就已经足够了 ^q^ 。
2)因个人时间、能力和水平有限,本文并非由我个人完全原创,文章部分内容整理自互联网上的各种资源,引用内容标注在每章末的参考资料之中。
3)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除,非常感谢各位为知识传播做出的贡献!
4)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
5)本文由我个人( CSDN 博主 「繁凡さん」(博客) , 知乎答主 「繁凡」(专栏), Github 「fanfansann」(全部源码) , 微信公众号 「繁凡的小岛来信」(文章 P D F 下载))整理创作而成,且仅发布于这四个平台,仅做交流学习使用,无任何商业用途。
6)「我希望能够创作出一本清晰易懂、可爱有趣、内容详实的深度学习笔记,而不仅仅只是知识的简单堆砌。」
7)本文《繁凡的深度学习笔记》全汇总链接:《繁凡的深度学习笔记》前言、目录大纲
8)本文的Github 地址:https://github.com/fanfansann/fanfan-deep-learning-note/ 孩子的第一个 『Github』!给我个 嘛!谢谢!!o(〃^▽^〃)o
9)此属 version 1.0 ,若有错误,还需继续修正与增删,还望大家多多指点。本文会随着我的深入学习不断地进行完善更新,Github 中的 P D F 版也会尽量每月进行一次更新,所以建议点赞收藏分享加关注,以便经常过来回看!
如果觉得还不错或者能对你有一点点帮助的话,请帮我给本篇文章点个赞,你的支持是我创作的最大动力!^0^
没有人喜欢就慢慢更新>_<
《繁凡的深度学习笔记》第 3 章 分类问题与信息论基础(上)目录
第 3 章 分类问题 (逻辑回归、Softmax 回归、信息论基础)
3.1 手写数字分类问题
3.1.1 手写数字图片数据集
3.1.2 构建模型
3.1.3 误差计算
3.1.4 非线性模型
3.1.4 手写数字图片识别实战
3.1.4.1 TensorFlow2.0 实现
3.1.4.2 PyTorch 实现
3.2 逻辑回归(Logistic Regression, LR)
3.2.1 决策边界
3.2.2 逻辑回归模型
3.2.3 代价函数
3.2.4 优化方法
《繁凡的深度学习笔记》第 3 章 分类问题与信息论基础(下)目录
3.4 Softmax 回归
3.4.1 Softmax 回归模型
3.4.2 优化方法
3.4.3 权重衰减
3.4.4 Fashion-MNIST 数据集图片分类实战
3.5 Softmax 回归与逻辑回归的关系
3.5.1 Softmax 回归与逻辑回归的关系
3.5.2 多分类问题的 Softmax 回归与 k 个二元分类器
3.6 面试问题集锦
3.7 参考资料
《繁凡的深度学习笔记》第 3 章(中)分类问题与信息论基础
3.3 信息论基础
信息论是一个非常庞大的学科,这里仅对机器学习中常用的简单信息论基础进行清晰易懂的简要讲解。如果对信息论感兴趣想要深入学习,请继续阅读Thomas M。Cover 的 《Elements of Information Theory》 (信息论经典之作)以及其中译本《信息论基础》,详见 我的Github 项目《繁凡的深度学习笔记》免.费深度学习书籍 。
3.3.1 信息论
信息论是应用概率论和数理统计的方法,研究信息熵、通信系统、数据传输、数据压缩等问题的应用数学学科。主要研究是量化一个信号可以提供多少信息。信息论涉及尽可能简洁地编码、解码、发送和处理信息或数据。主要研究对象是关于随机变量的信息熵和通道。
3.3.1.1 自信息与信息量
信息量(amount of information),指信息多少的量度。我们需要知道,信息是用来减少随机不确定性的东西,也即不确定性的减少。
自信息(self-information),又译为信息本体,由克劳德 · 香农(Claude Shannon)提出,用来衡量单一事件发生时所包含的信息量多寡。任何事件都会承载着一定的信息量,包括已经发生的事件和未发生的事件,只是它们承载的信息量会有所不同。
例如,对于已知的昨天下雨的事件,因为它是一个已经发生的事件,是一个给定的事实,那么它的信息量是。对于明天会下雨的事件,因为还没有发生,所以关于这个事件的信息量很大。我们可以发现,信息量是一个与事件发生概率相关的概念。对于一个事件,它发生的概率越大,确定性越强,显然它所包含的信息量就越低。事件发生的概率越低,不确定性越大,它包含的信息量就越大。
到目前为止,信息论假设信息量只与随机变量的概率分布有关,并且满足可加性等性质。
定义事件的自信息为
其中, 为随机变量,
为随机变量的某个取值,
为
的概率分布:
,
表示事件的个数,参数
不同时对应的结果单位不同,在公式中可忽略。在机器学习中,用自然对数
为底,单位为 奈特(
),用
为底,单位为比特(
)。至于我们为什么会这样定义自信息,我们将在下一节 《繁凡的深度学习笔记》3.3.2 香农熵 中进行详细探讨。
我们还可以定义事件的联合自信息:
如果和
相互独立,则:
直观地说,我们需要自我信息来满足以下属性:
- 连续性,即事件的自信息
可见,信息的本质是消除不确定性。
3.3.2 香农熵
3.3.2.1 熵
我们首先在信息学中引入熵的概念。
熵 (Entropy),本是热力学中的概念,1948 年,克劳德 · 香农(Claude Shannon)将热力学中的熵的概念引入到信息论中,因此也被称为 信息熵 或香农熵 (Shannon Entropy),用来衡量信息的不确定度。不准确点说,熵是用来衡量混乱程度的。越混乱,熵越大,代表不确定性越大,要弄清楚情况所需要的信息量越多。
一个栗子,一个袋子里有个球。如果有
红球和
白球,这是混乱。如果有
红球和
白球,则没有混淆。可以这样理解,如果各种物品的比例相同,不同物品的概率非常高,那么我很难判断包里是什么东西,整体信息量会很大,这会很混乱。如果包里只有一件东西,那么我很容易判断包里是什么,这不会造成混淆。即一个集合中每个部分的比例越平衡,越混乱,越极化的部分越不混乱。
那么如何用数学来衡量混沌呢?我们明显发现,当总项数不变时,两项的乘积越大越乱,越小越不乱。那么我们显然可以用这个乘法结果来衡量数据的混乱程度。既然如此,如果袋子里有多个球,我们可以乘以它们的概率。
但是我们发现乘法后很难推导。例如,要区分,我们需要对其进行扩展。一个很明显的想法就是取乘积的对数,把乘法变成加法,这样既使求导更加方便,又不改变原来的单调性。
但是我们发现取对数后,虽然是单调递增的,但是概率
不能取
。我们知道概率范围是
,当
时,极限是负无穷
是没有意义的。考虑
是否可以乘以负无穷,得到
,于是我们得到一个衡量混淆程度的指标:
,这次是
,
。此时,
单调增加,
单调减少。乘法是单调递减的。由于我们希望概率越大,不确定性越小,也就是熵越小,所以可以取负号。至此,我们得到了香农熵的形式,也被香农在数学上证明了满足信息熵的三个条件。的随机变量不确定性测度函数具有独特的形式:
信息论之父克劳德·香农总结了信息熵的三个性质:
单调性,即发生概率越高,其携带的信息熵越低。极端情况是“太阳从东方升起”,因为它不携带任何信息量来确定事件。从信息论的角度来看,相信这句话并没有消除任何不确定性。非负性,即信息熵不能为负。这很容易理解,因为负面信息,即当你知道某事但增加了不确定性时,是不合逻辑的。可加性,即多个随机事件同时发生的总不确定性的度量,是可以表示为每个事件的不确定性度量之和的度量。
所以我们定义事件的信息内容
,此时信息内容的期望是熵,即:
其中,是
的概率质量函数,
代表事件的个数。当参数
不同时,对应的结果单位不同。在机器学习中,以自然对数
为底,单位为骑士(
),底为
,单位为位(
)。对于连续变量,它称为微分熵。
随机变量的熵
的大小可以理解为事件信息的比特数。
这里以 为底举个例子,对于
分类问题,如果某个样本的真实标签是第
类,one-hot 编码为
,即这张图片的分类是唯一确定的,它属于第
类的概率
,不确定性为
,它的熵可以简单的计算为
也就是说,对于确定性分布,熵为,即不确定性最低。如果它预测的概率分布是
,它的熵可以计算为
考虑一个随机分类器,它预测每个类的概率相等:,这种情况下的熵约为
。
由于 ,因此熵总是大于等于
。当熵取得最小值
时,不确定性为
。分类问题的 One-hot 编码的分布就是熵为 0 的例子。我们可以使用 math.log 来组合计算熵。
对于 0-1 分布问题,二值随机变量的香农熵、伯努利分布熵,随机变量 的取值为
,此时熵的计算可以简化为
的另一个经典例子是:在一场赌马比赛中,有马
,获胜的概率为
,将哪匹马获胜视为随机变量
属于
。假设我们需要使用尽可能少的二元问题来确定随机变量
的值,即我们可以给出几个问题,而每组问题只能得到两种答案:真或假。要知道哪匹马最终获胜,您需要通过的最少问题数是多少?
例如:问题 1 : 获胜了吗?问题 2 :
获胜了吗?问题 3 :
获胜了吗?最后我们可以通过最多
个二元问题,来确定
的取值,也即最终是哪一匹马获得了胜利。
如果最终是 获得胜利,也即
,那么只需要问
次(问题 1 ) 即可得到答案,
获胜的概率为
。
如果最终是 获得胜利,也即
,那么需要问
次(问题 1 以及问题 2 ),
获胜的概率为
。
如果最终是 获得胜利,也即
,那么需要问
次(问题 1,问题 2,问题 3 ),
获胜的概率为
。
如果最终是 获得胜利,也即
,那么需要问
次(问题 1 ,问题 2 ,问题 3 ),
获胜的概率为
。
那么确定值的二元问题的预期数量为:
然后我们把它带入信息熵公式中,选择的基为
,我们可以得到:
在二进制计算机中,一个位是 或
,它实际上代表了一个二进制问题的答案。平均码长为
,其中
为概率,
为码长。在计算机中,我们对哪匹马获胜的事件进行编码,所需的平均码长为
比特。
为了尽可能地减少代码长度,我们需要将较短的代码长度分配给发生概率较大的事件
。这就引出了霍夫曼编码的概念。
那么四个事件可以分别用
来表示,显然我们要把最短的代码
分配给发生概率最高的事件
,以此类推。得到的平均码长为
比特。如果我们坚持做相反的事情并将最长的代码
分配给事件
,那么平均代码长度变为
位。
霍夫曼编码利用了将短码分配给高概率事件的思想,可以证明这种编码方式是最优的。我们可以证明:
- 为了得到信息熵为
的随机变量
的样本,需要平均
- 信息熵的大小是数据压缩过程中可以达到的一个临界值。
3.3.2.2 联合熵
与联合自信息一样,我们可以将两个随机变量和
的联合熵定义为:
在物理意义上,它衡量一个联合分布的随机系统的不确定性,观察随机系统的信息内容。
当事件同时发生且相互独立时,有
,信息熵为
也就是说,当随机变量相互独立时,我们有
3.3.2.3 互信息
两个随机变量和
的互信息定义为:
当不相互独立时:
互信息表示一个随机变量在另一个随机变量中包含多少信息的量度。它的物理意义表明两个事件单独发生的信息量是重复的。互信息衡量了这种重复中的信息量。在点对点通信系统中,发送端的信号为,经过信道后,接收端接收到的信号为
,则通过信道传输的信息量为互信息
。基于这个概念,香农提出了一个非常棒的公式,香农公式,它给出了关键通信传输速率的值,即信道容量:
3.3.2.4 条件熵
两个随机变量和
的条件熵定义为:
条件熵衡量随机变量在已知随机变量
的条件下的不确定性,即在
已知的条件下,得到
对于整体信息量的增加,有:
它们组成的 Venn 图如图 3.11 所示:
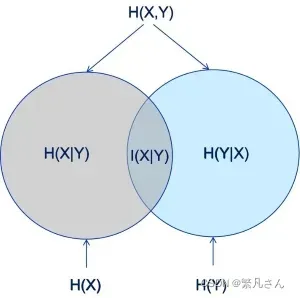
图 3.11 信息熵
3.3.2.5 信息熵的链式法则
三个随机变量的互信息可以表示为:
那么对于随机变量
和
,它们的信息熵可以用链式法则表示为:
3.3.3 相对熵(KL 散度)
相对熵(Relative Entropy),也叫 KL 散度 (Kullback-Leibler Divergence),具有非负的特性。用于衡量两个分布之间距离的指标,用 分布近似
的分布,相对熵可以计算这个中间的损失,但是不对称(
对
和
对
不相等),因此不能表示两个分布之间的距离,这种非对称性意味着选择
还是
影响很大。当
时, 相对熵(
散度)
取得最小值
。
如果同一个随机变量有两个独立的概率分布
和
,我们可以用
散度来衡量两个分布之间的差异。
散度越小,真实分布与近似分布的匹配度越好。
在
范围内的分布紧密度呈正相关。
我们对散度公式进行变形得到:
为保证
散度的连续性,约定:
当时,两者的相对熵为
中的
表示使用分布
对分布
进行编码所需的平均码数
,
表示使用分布
对分布
进行编码所需的最小码数
。因此,相对熵的含义可以理解为:
表示对于分布
的
个数,使用
分布编码相比使用真实分布
进行编码(即最优编码),即两种分布的差值差异.
在机器学习中,常用于表示样本的真实分布,
用于表示模型预测的分布,那么
散度可以计算出两种分布的差值,即损失函数
:
离散的:
连续:
我们可以用不等式证明
的散度一定大于
:
考虑一个连续的散度,有两个概率密度
,假设
,有
散度:
认证
更多 散度图像上的直观解释详见:初学机器学习:直观解读KL散度的数学概念
3.3.4 交叉熵
我们在上一节 3.3.3 相对熵(KL 散度) 中得到 散度的公式:
其中表示使用分布
对分布
进行编码所需的平均代码数
,
表示使用分布
对分布
进行编码所需的最小代码数
。
因此我们定义 交叉熵(Cross Entropy)
,即:
表示使用分布对分布
进行编码所需的平均代码数
。
至此,我们定义的和
之间的交叉熵
等于
的熵
和
的散度
之和:
由于
的散度是不对称的,显然交叉熵也是不对称的:
在机器学习任务中,我们希望使用分布 去拟合分布
,需要评估标签与预测值之间的差距,可以直接使用
散度,即
。而由于分布
不变,即
保持不变,交叉熵
的变化就可以直接反映出相对熵
的变化。由于相对熵
中包含定值
,是一个不可优化的常数,且实验表明交叉熵在训练时相较于相对熵更加 健壮(robust),因此我们一般直接用交叉熵作为损失函数来评估模型,而不是使用相对熵
散度。
交叉熵可以很好地衡量 个分布之间的差别,特别地,当分类问题中
的编码分布
采用 one-hot 编码时:
,此时
退化为真实标签分布 和输出概率分布
之间的
散度。
根据散度的定义,我们推导出分类问题中交叉熵的计算表达式:
其中 为 one-hot 编码中为
的索引号,也是当前输入的真实类别。可以看到,损失函数
只与真实类别
上的概率
有关,对应概率
越大,
越小,当对应概率为
时,交叉熵
取得最小值
,此时网络输出
与真实标签
完全一致,神经网络取得最优状态。最小化交叉熵的过程也是最大化正确类别的预测概率的过程。
3.3.5 JS 散度
JS 散度 (Jensen-Shannon Divergence),度量了两个概率分布的相似度,是基于
散度的变体,解决了
散度非对称的问题。
一般地,JS 散度是对称的,其取值是
到
之间。定义如下:
因而JS散度拥有对称性,并且在形式上更为平滑,更适合作为最后最大似然的函数,这点在生成对抗网络(GAN)的损失函数取得了不错的成绩。
KL 散度和 JS 散度的问题
如果两个分布
离得很远,完全没有重叠的时候,那么 KL 散度值是没有意义的,而 JS 散度值是一个常数。这在学习算法中是比较致命的,这就意味着这一点的梯度为
,出现了梯度消失现象,导致训练失败。
这里通过一个简单的分布实例来解释 JS 散度的缺陷。考虑完全不重叠 (
)的两个分布
和
,其中分布
为:
分布为:
其中 ,当
时,分布
和
重叠,两者相等;当
时,分布
和
不重叠。分布
和
的示意图如图 3.12 所示。
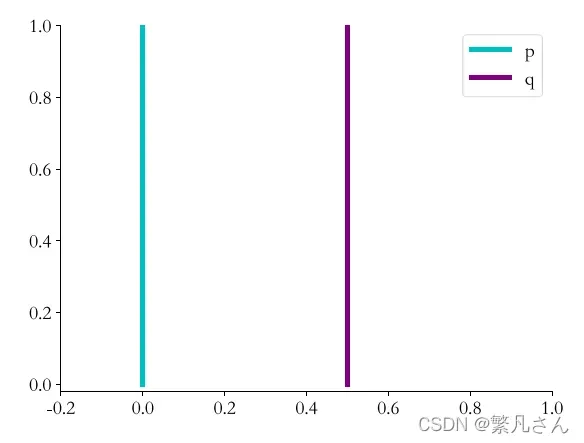
图 3.12 分布 p 和 q 的示意图
我们来分析上述分布 和
之间的 JS 散度随
的变化情况。根据 KL 散度与 JS 散度的定义,计算
时的 JS 散度
:
当 时,两个分布完全重叠,此时的 JS 散度和 KL 散度都取得最小值,即
。
至此我们可以得到和
的变化趋势:
也就是说,当两个分布完全不重叠时,无论分布之间的距离远近,JS 散度为恒定值 ,此时 JS 散度将无法产生有效的梯度信息;当两个分布出现重叠时,JS 散度才会平滑变动,产生有效梯度信息;当完全重合后,JS 散度取得最小值
。如图 3.13 中所示,红色的曲线分割两个正态分布,由于两个分布没有重叠,生成样本位置处的梯度值始终为
,无法更新生成网络的参数,从而出现网络训练困难的现象。
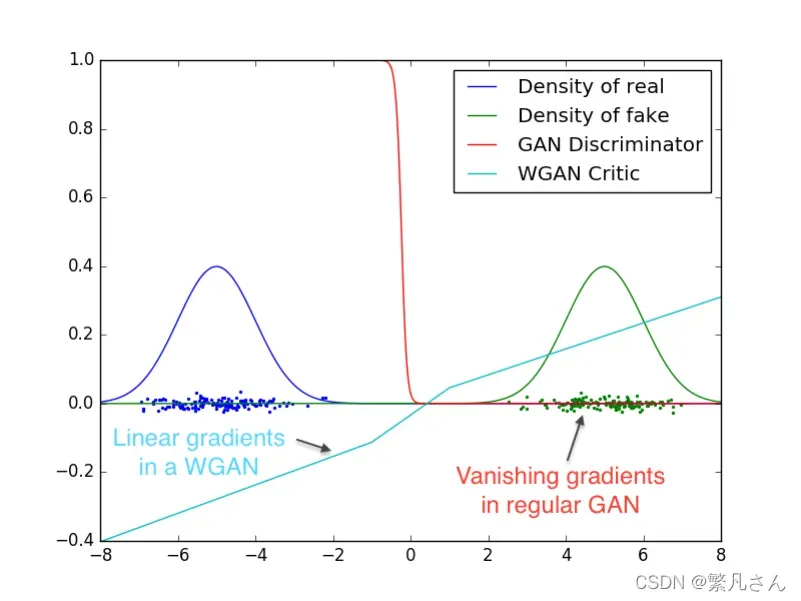
图 3.13 JS 散度出现梯度弥散现象 [21]
因此,JS 散度在分布 和
不重叠时是无法平滑地衡量分布之间的距离,从而导致此位置上无法产生有效梯度信息,出现 GAN 训练不稳定的情况。要解决此问题,需要使用一种更好的分布距离衡量标准,使得它即使在分布
和
不重叠时,也能平滑反映分布之间的真实距离变化。
3.3.6 Wasserstein 距离
Wasserstein距离 ,度量两个概率分布之间的距离。WGAN 论文发现了 JS 散度导致 GAN 训练不稳定的问题,并引入了一种新的分布距离度量方法:Wasserstein 距离,它表示了从一个分布变换到另一个分布的最小代价,定义如下:
其中 是
和
分布组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布
,可以从中采样
得到一个样本
和
,并计算出这对样本的距离
,所以可以计算该联合分布
下,样本对距离的期望值
。在所有可能的联合分布中能够对这个期望值取到的下确界
就是 Wasserstein 距离。
直观上可以把 理解为在
这个路径规划下把土堆
挪到土堆
所需要的消耗。而 Wasserstein 距离就是在最优路径规划下的最小消耗。所以 Wesserstein 距离又称推土机距离(Earth-Mover Distance,简称 EM 距离)。
继续考虑图 3.12 中的示例,我们可以得出分布 和
之间的 EM 距离的表达式:
绘制出 JS 散度和 EM 距离的曲线,如图 3.14 所示,可以看到,JS 散度在 处不连续,其他位置导数均为
,而 EM 距离总能够产生有效的导数信息,因此 EM 距离相对于JS 散度更适合指导 GAN 网络的训练。
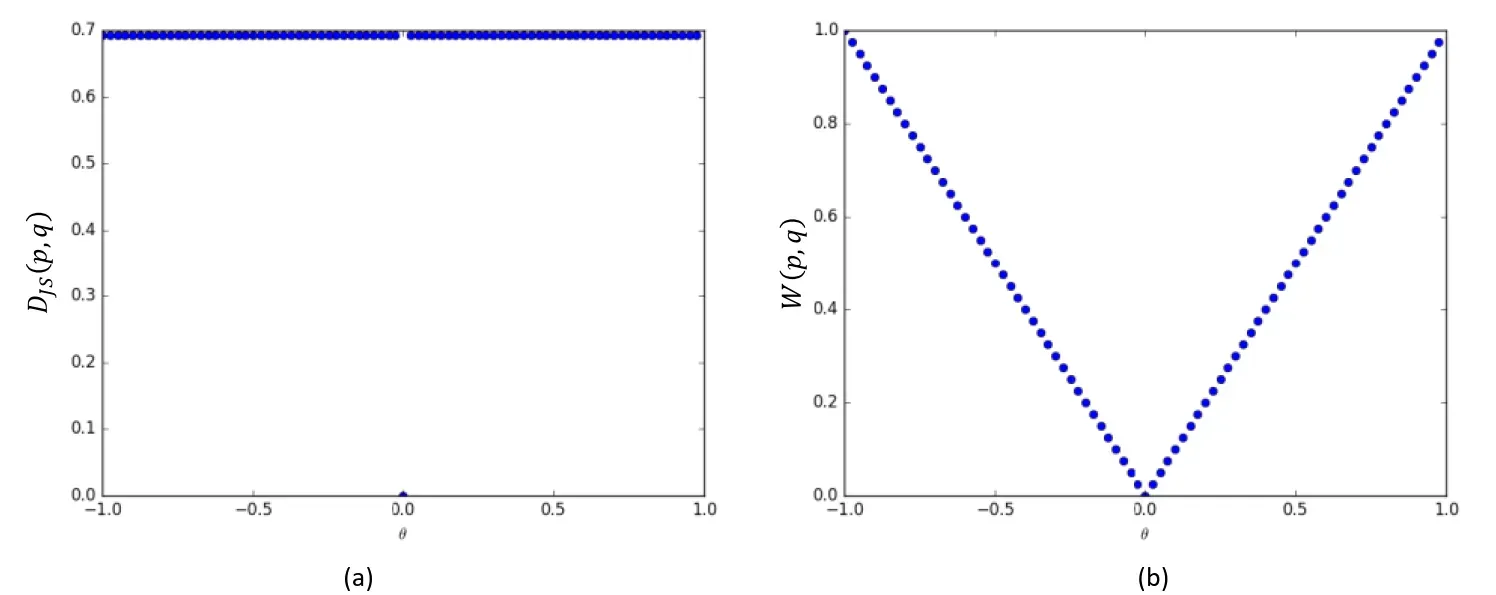
图 3.14 JS 散度和 EM 距离随 𝜃 变换曲线
Wessertein距离相比 KL 散度和 JS 散度的优势在于:即使两个分布的支撑集没有重叠或者重叠非常少,仍然能反映两个分布的远近。而 JS 散度在此情况下是常量,KL 散度可能无意义。
更多关于Wasserstein 距离的讲解详见: GAN的Loss的比较研究(3)——Wasserstein Loss理解(1) 以及 令人拍案叫绝的Wasserstein GAN
参考
[1] 《2021春机器学习课程》李宏毅
https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
[2]《TensorFlow深度学习》(龙龙老师)
https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
[3] Coursera吴恩达《神经网络与深度学习》
https://www.deeplearning.ai/
[4] 《动手学深度学习》第二版
https://zh-v2.d2l.ai/
[5] 《深度学习》(花书)
https://github.com/exacity/deeplearningbook-chinese
[6] relu函数为分段线性函数,为什么会增加非线性元素
https://www.cnblogs.com/lzida9223/p/10972783.html
[7] 【机器学习】神经网络-激活函数-面面观(Activation Function)
https://blog.csdn.net/cyh_24/article/details/50593400
[8] Logistic Regression (LR) 详解与更多相关的面试问题
https://blog.csdn.net/songbinxu/article/details/79633790
[9] 【机器学习】逻辑回归(非常详细)
https://zhuanlan.zhihu.com/p/74874291
[10] softmax回归(Softmax Regression)
https://blog.csdn.net/u012328159/article/details/72155874
[11] 逻辑回归算法原理及用于解决多分类问题
https://blog.csdn.net/AIHUBEI/article/details/104301492
[12] 逻辑回归(Logistic Regression)(二)
https://zhuanlan.zhihu.com/p/28415991
[13] 数学基础_4——信息论
https://blog.csdn.net/CesareBorgia/article/details/120817481
[14] 信息论(1)——熵、互信息、相对熵
https://zhuanlan.zhihu.com/p/36192699
[15] 一文读懂机器学习分类算法(附图文详解)
https://zhuanlan.zhihu.com/p/82114104
[16] An in-depth guide to supervised machine learning classification
https://builtin.com/data-science/supervised-machine-learning-classification
[17] 信息熵是什么?- 知乎
https://www.zhihu.com/question/22178202/answer/223017546
[18] 熵 (信息论) – 维基百科
https://zh.wikipedia.org/wiki/%E7%86%B5_(%E4%BF%A1%E6%81%AF%E8%AE%BA)
[19] 信息熵到底是什么
https://blog.csdn.net/saltriver/article/details/53056816
[20] Visual Information Theory
https://colah.github.io/posts/2015-09-Visual-Information/#fnref1
[21] M。Arjovsky, S。Chintala 和 L。Bottou, “Wasserstein Generative Adversarial Networks,” Proceedings of the 34th International Conference on Machine Learning, International Convention Centre, Sydney, Australia, 2017.

谢谢!
转载请注明出处:https://fanfansann.blog.csdn.net/
版权声明:本文为 CSDN 博主 「繁凡さん」(博客),知乎答主 「繁凡」(专栏),Github 「fanfansann」(全部源码),微信公众号 「繁凡的小岛来信」(文章 P D F 版))原创整理的文章,遵循CC 4.0 BY-NC-SA 版权协议,转载请附上原文出处链接及本声明。
版权声明:本文为博主繁凡さん原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_45697774/article/details/122862445