1. 什么是机器学习?
- Arthur Samuel 将其描述为:“这一研究领域使计算机能够在没有明确编程的情况下进行学习。”这是一个古老的非正式定义。
- 汤姆·米切尔提供了一个更现代的定义:“一个计算机程序被认为从经验E中学习关于某些类别的任务T和性能测量P,如果它在任务T中的表现,由P测量,随着经验E的提高。”
- 一般来说,任何机器学习都可以分为:监督学习和无监督学习。
2. 监督学习
- 在监督学习中,我们得到一个数据集并且已经知道我们的正确输出应该是什么样子,因为我们知道输入和输出之间存在关系。
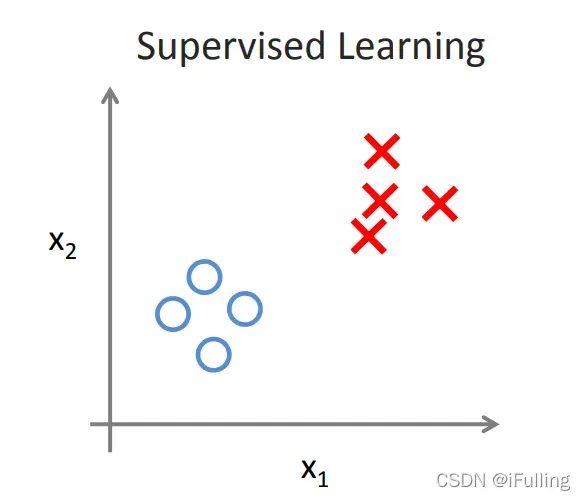
监督学习问题分为“回归”问题和“分类”问题:
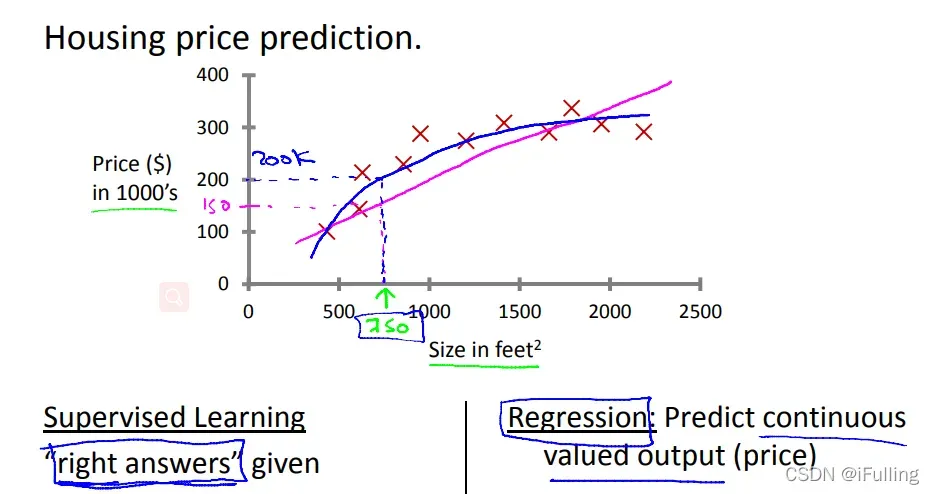
- 在回归问题中,我们试图预测连续输出的结果,这意味着我们试图将输入变量映射到连续函数。
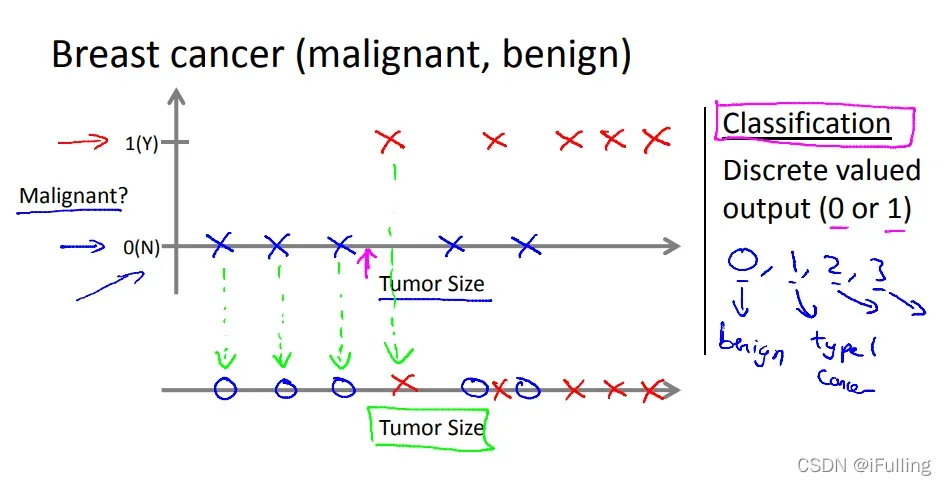
示例:给定房子的大小,我们使用大小来预测售价。- 在分类问题中,我们试图预测离散输出的结果。换句话说,我们尝试将输入变量映射为离散变量。
示例:对于患有肿瘤的患者,我们预测肿瘤是恶性的还是良性的。
3. 无监督学习
- 无监督学习:无监督学习使我们能够在几乎不知道结果应该是什么样子的情况下解决问题。我们可以在不需要知道变量的影响的情况下从数据中推导出结构,并且可以通过基于数据中变量之间的关系对数据进行聚类来推导出这种结构。
- 在无监督学习中,没有基于预测结果的反馈。
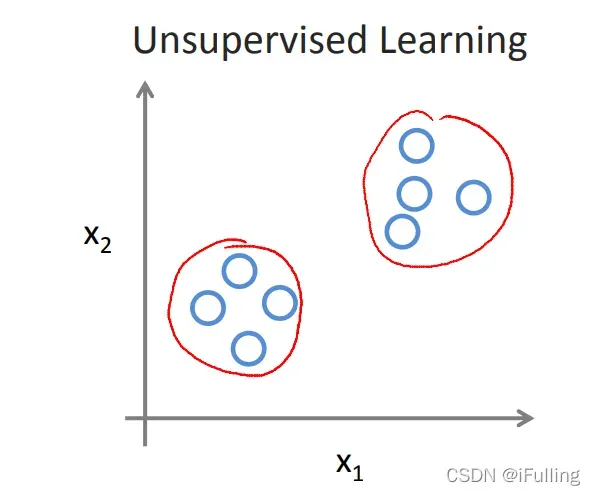
- 聚类:将100万个不同的基因集合起来,然后找到一种方法将这些基因自动分组,使其在某种程度上具有相似性或与不同的变量相关。比如寿命,位置,角色等等。
- 非聚类:“鸡尾酒会算法”可让您在杂乱的环境中找到结构。 (从鸡尾酒会上的各种声音中识别出不同的声音和音乐)。
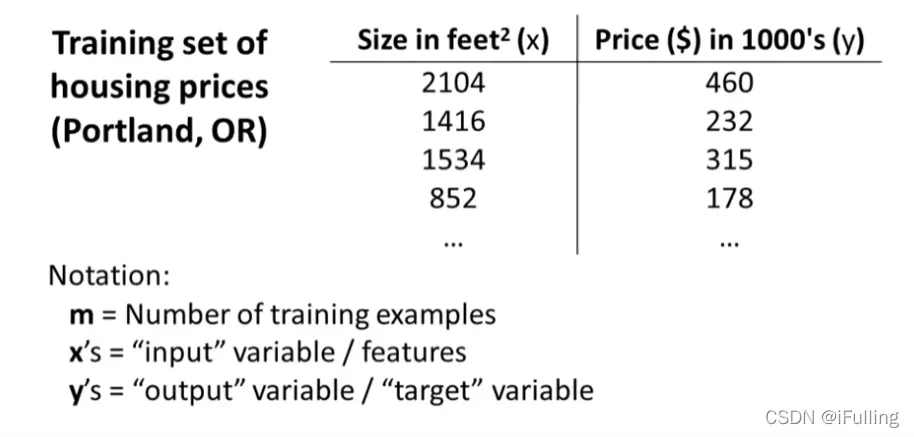
4. 线性回归模型
代表输入变量;
表示“输出”或我们试图预测的目标变量;
- 一对
代表一个训练样本;
表示训练样本数;
代表样本索引,
代表训练集。
;
;
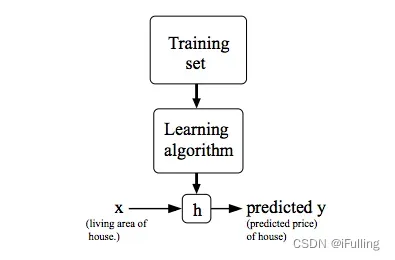
表示一个函数,代表hypothesis(假设函数);
- 假设函数:
;
- 给定一个训练集,学习一个函数
,这样
就能“很好地”预测Y的相应值;
- 输入是房子的大小,
的输入值推导出
到
5. 代价函数(平方误差函数)
- 成本函数也称为平方误差函数或平方误差成本函数。
- 我们可以使用成本函数来衡量假设函数的准确性。它需要所有假设结果的平均差(实际上是平均数的一个奇特版本)。
- 我们的目标是得到尽可能好的线(线由
和
确定,需要梯度下降来找到
的小值)。最佳直线是散点到该直线的平均垂直距离的平方最小的直线。理想情况下,这条线应该穿过训练数据集中的所有点。在这种情况下,
。
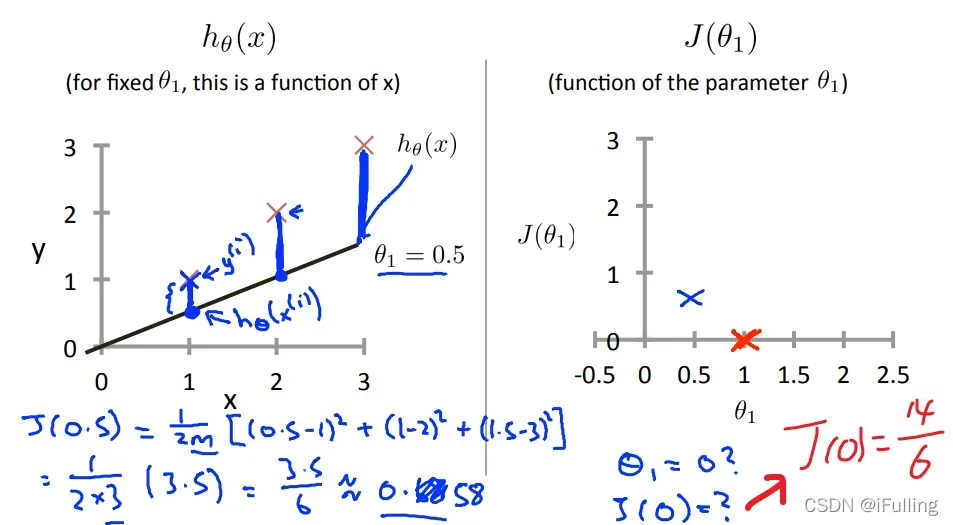
(1)单参图像直观展示
- 下图是一个理想的情况,直线通过了数据集所有点,当
时,代价函数为0。
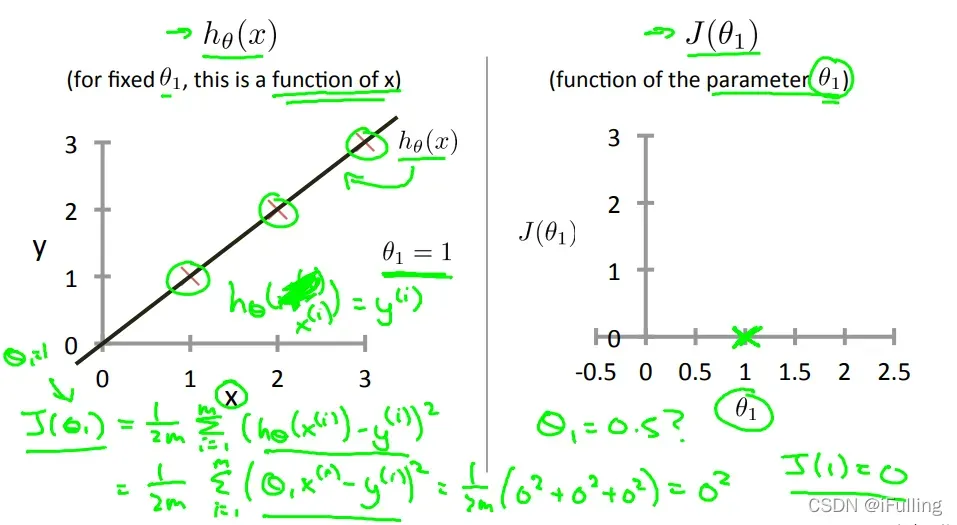
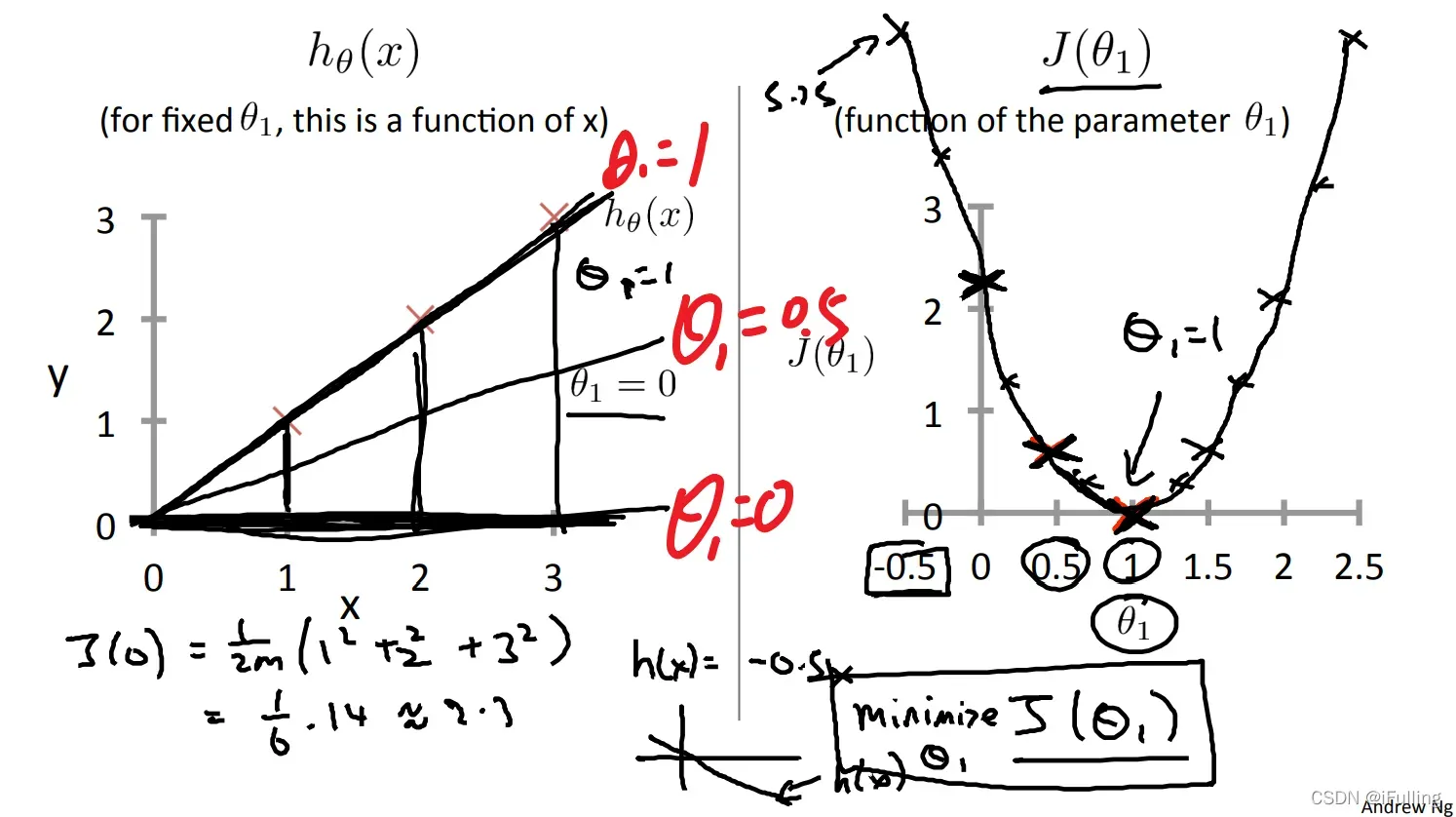
当
时,我们得到斜率为1,它经过模型中的每一个数据点。
当时,我们看到拟合数据点的垂直距离增加。
绘制其他几个代价函数值的结果,如下图,当的值最小。
(2)双参图像直观展示
当只有一个参数
两个轴分别代表
表面的高度获得不同的成本函数
。也就是垂直方向的高度,它代表代价函数的值
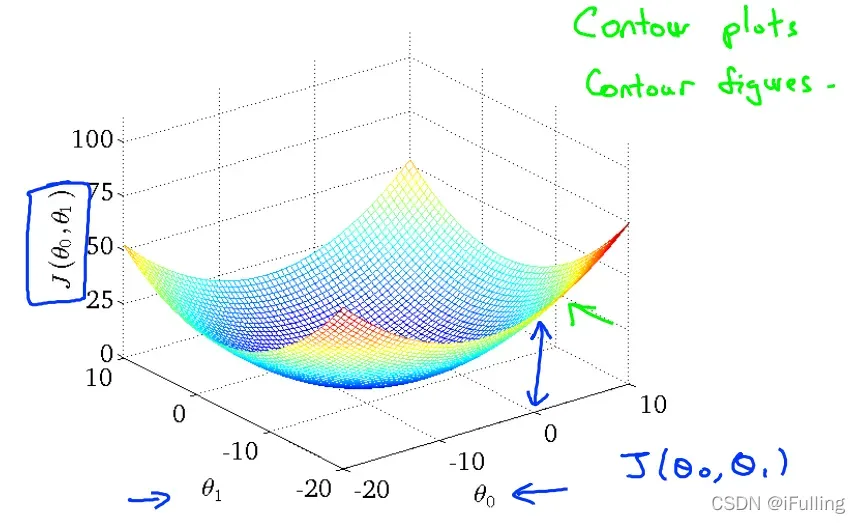
- 等高线图是包含许多等高线的图。双变量函数的轮廓在同一直线上的所有点处具有恒定值。这种图表的一个例子是右下方的图表。
- 沿着“圆圈”走,我们会期望相同的成本函数值。例如,绿线上的三个绿点对于
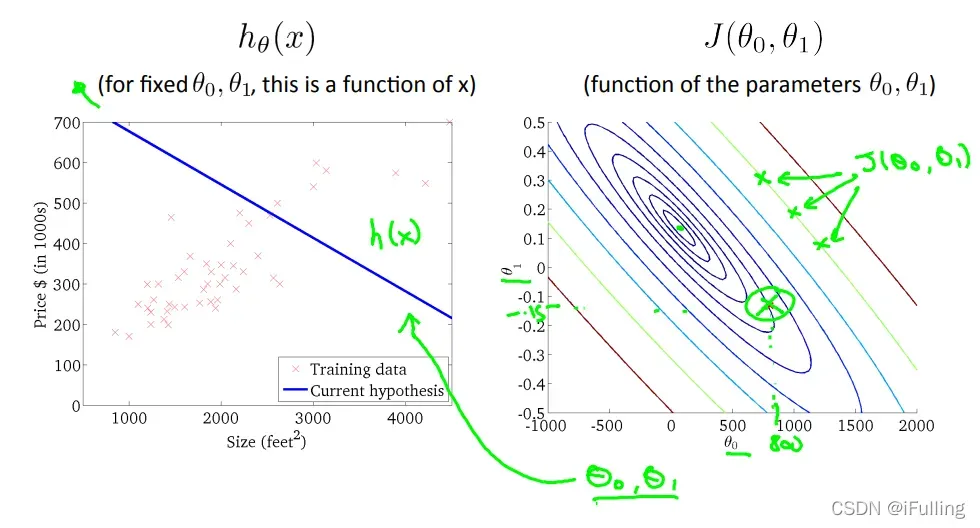
- 当
时,
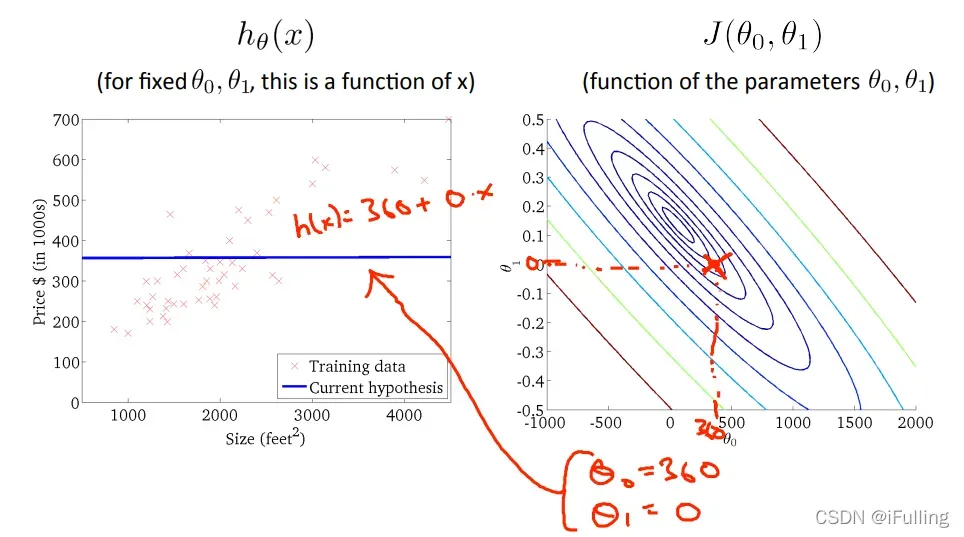
- 下图尽可能地使代价函数最小化,因此,
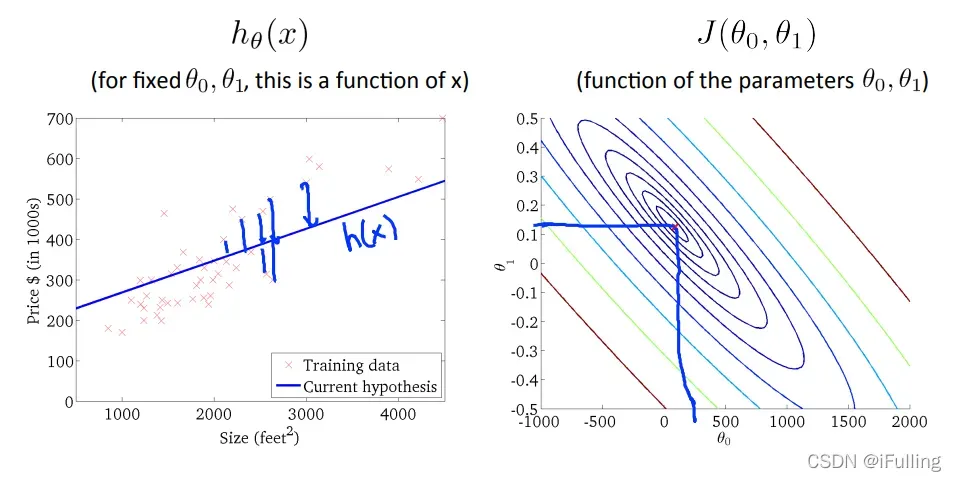
6. 梯度下降算法
- 梯度下降的作用:我们有一个假设函数和一个平方误差函数来衡量它与数据的拟合程度。现在我们需要使用梯度下降来估计假设函数中的参数
。
- 梯度下降的工作原理:首先将
,然后通过梯度下降算法不断改变
达到我们想要的最小值。
- 梯度下降算法:
代表赋值,右边的项被赋值给左边的项。
:表示特征索引号。
:称为学习率,参数α决定了每一步的大小。较小的 α 会导致较小的步长,较大的 α 会导致较大的步长。步进方向由
的偏导数决定。
我们把
放在y轴上,代价函数在垂直z轴上。图上的点是使用我们的假设和特定参数的代价函数的结果。
我们的方法是取成本函数的导数(函数的正切)。切线的斜率是这个点的导数,它会给我们一个移动的方向。我们让代价函数朝着递减速度最快的方向逐渐递减。
不同的起点可能在不同的点结束。上图显示了两个不同的起点和在两个不同的地方结束。
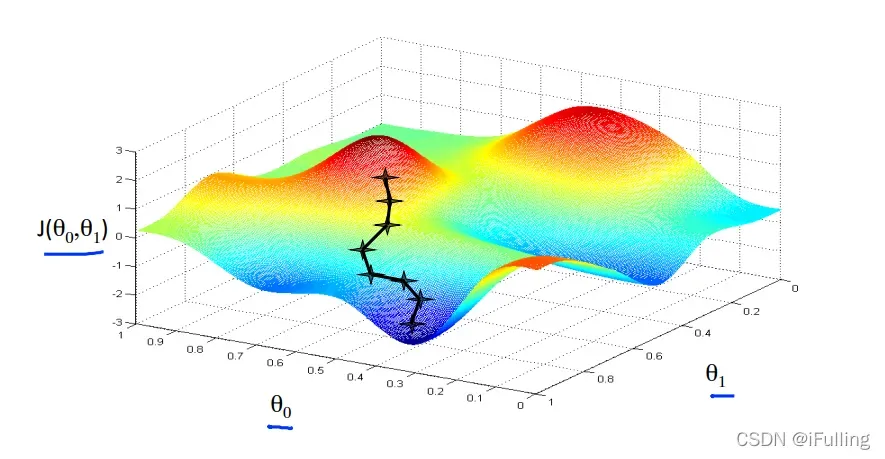
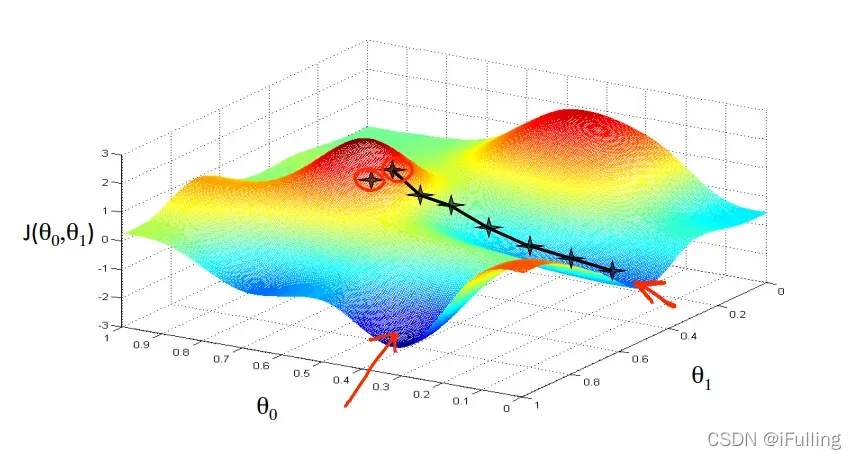
- 在每次迭代j时,应该同时更新参数
。

(1)单参
- 对于只有一个参数的梯度下降算法,公式表示为:
- 当斜率为负时,
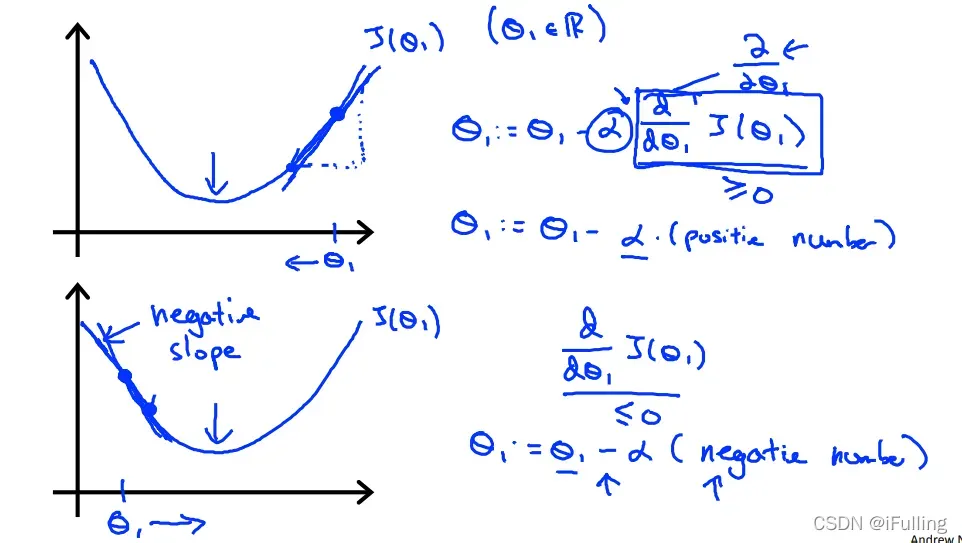
- 我们应该调整参数
以确保梯度下降算法在合理的时间内收敛。无法收敛或花费太多时间达到最小值意味着我们的步长是错误的。
图 1:如果
图2:如果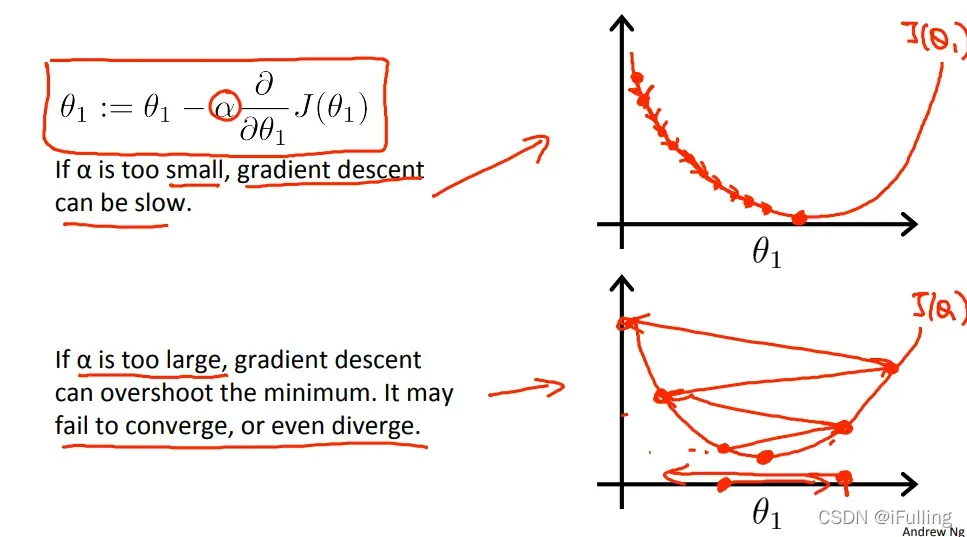
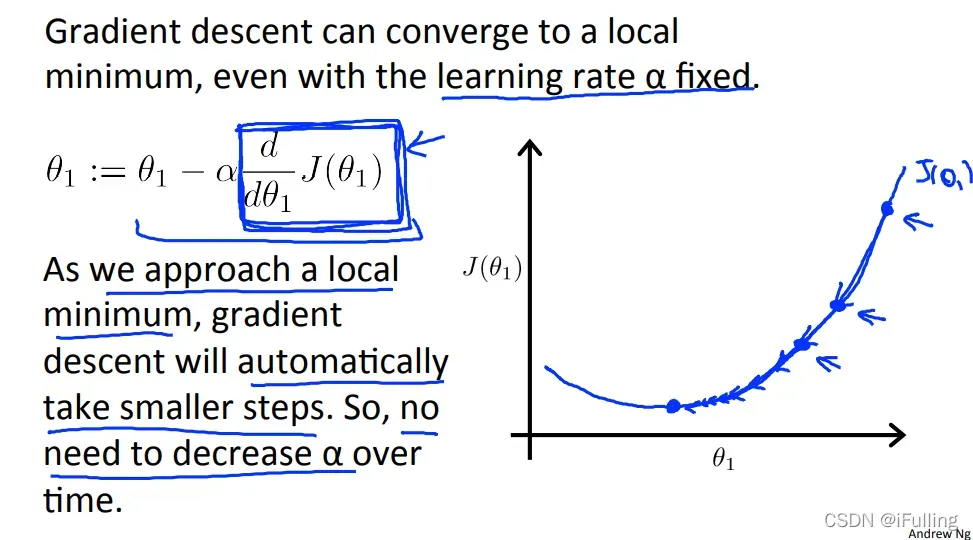
- 平方误差函数在接近凸函数的底部时
趋于0。在最小值时,导数始终为0,得到:
。
- 当我们接近局部最小值时,梯度下降将自动采取小步骤,因此无需随着时间的推移减少
(2)双参(梯度下降完整公式)
- 当专门应用于线性回归时,可以推导出一种新形式的梯度下降方程。我们可以替换我们的实际成本函数和我们的实际假设函数,并将方程修改为:
- 如果我们从假设的猜测
开始,然后反复应用梯度下降方程,我们的假设会越来越准确。
- 这种方法在整个训练集的每一步都考虑每个示例,称为批量梯度下降。
版权声明:本文为博主iFulling原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/realoser/article/details/122847867