一、前言
环境:
windows11 64位
Python3.9
MySQL8
pandas1.4.2
本文主要介绍 MySQL 中的窗口函数row_number()、lead()/lag()、rank()/dense_rank()、first_value()、count()、sum()如何使用pandas实现,同时二者又有什么区别。
注:Python是很灵活的语言,达成同一个目标或有多种途径,我提供的只是其中一种解决方法,大家有其他的方法也欢迎留言讨论。
二、语法对比
数据表
本次使用的数据如下。
使用 Python 构建该数据集的语法如下:
import pandas as pd
import numpy as np
df1 = pd.DataFrame({ 'col1' : list(range(1,7))
,'col2' : ['AA','AA','AA','BB','BB','BB']#list('AABCA')
,'col3' : ['X',np.nan,'Da','Xi','Xa','xa']
,'col4' : [10,5,3,5,2,None]
,'col5' : [90,60,60,80,50,50]
,'col6' : ['Abc','Abc','bbb','Cac','Abc','bbb']
})
df2 = pd.DataFrame({'col2':['AA','BB','CC'],'col7':[1,2,3],'col4':[5,6,7]})
df3 = pd.DataFrame({'col2':['AA','DD','CC'],'col8':[5,7,9],'col9':['abc,bcd,fgh','rst,xyy,ijk','nml,opq,wer']})注:直接将代码放 jupyter 的 cell 跑即可。后文都直接使用
df1、df2、df3调用对应的数据。
使用 MySQL 构建该数据集的语法如下:
with t1 as(
select 1 as col1, 'AA' as col2, 'X' as col3, 10.0 as col4, 90 as col5, 'Abc' as col6 union all
select 2 as col1, 'AA' as col2, null as col3, 5.0 as col4, 60 as col5, 'Abc' as col6 union all
select 3 as col1, 'AA' as col2, 'Da' as col3, 3.0 as col4, 60 as col5, 'bbb' as col6 union all
select 4 as col1, 'BB' as col2, 'Xi' as col3, 5.0 as col4, 80 as col5, 'Cac' as col6 union all
select 5 as col1, 'BB' as col2, 'Xa' as col3, 2.0 as col4, 50 as col5, 'Abc' as col6 union all
select 6 as col1, 'BB' as col2, 'xa' as col3, null as col4, 50 as col5, 'bbb' as col6
)
,t2 as(
select 'AA' as col2, 1 as col7, 5 as col4 union all
select 'BB' as col2, 2 as col7, 6 as col4 union all
select 'CC' as col2, 3 as col7, 7 as col4
)
,t3 as(
select 'AA' as col2, 5 as col8, 'abc,bcd,fgh' as col9 union all
select 'DD' as col2, 7 as col8, 'rst,xyy,ijk' as col9 union all
select 'CC' as col2, 9 as col8, 'nml,opq,wer' as col9
)
select * from t1;注:直接将代码放 MySQL 代码运行框跑即可。后文跑 SQL 代码时,默认带上数据集(代码的1~18行),仅展示查询语句,如第19行。
对应关系如下:
| Python 数据集 | MySQL 数据集 |
|---|---|
| df1 | t1 |
| df2 | t2 |
| df3 | t3 |
row_number()
row_number()是对检索的数据计算行号,从1开始递增。一般涉及分组字段和排序字段,每一个分组里的行号都唯一。
MySQL 的row_number()函数在 Python 中可以使用groupby()+rank()实现类似的效果。
groupby()单列聚合时,直接将列名传递进去即可,如groupby('col2');如果是多列,则传一个列表,如groupby(['col2','col6'])。rank()只能对一列进行排序,如df.col2.rank();当有多列排序的时候,可以使用sort_values(['col6','col5']先排好序,再聚合,然后使用累加函数cumcount()或排序函数rank()。
另外,需要注意一点,排序字段如果有重复值,在 MySQL 中会随机返回,而 Python 中会默认使用index列进一步排序。
具体例子如下:
1、单列分组,单列排序
当分组和排序都只有一列的时候,在 Python 中使用groupby()单列聚合加上rank()对单列进行排序即可。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘label’] = df1_1.groupby(‘col2’)[‘col5’].rank(ascending=False,method=‘first’) df1_1[[‘col2’,‘col5’,‘label’]] |
select col2,col5,row_number()over(partition by col2 order by col5 desc) label from t1; |
| 结果 | 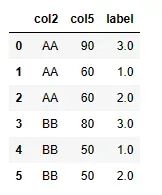 |
 |
2、多列分组,单列排序
当有多列分组,则传一个列表给groupby()函数。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘label’] = df1_1.groupby([‘col2’,‘col6’])[‘col5’].rank(ascending=True,method=‘first’) df1_1[[‘col2’,‘col6’,‘col5’,‘label’]] |
select col2,col6,col5,row_number()over(partition by col2,col5 order by col5) label from t1; |
| 结果 |  |
 |
3、单列分组,多列排序
如果是多列排序,相对复杂一些,如下【Python1】先用sort_values()排好序,然后再用groupby()聚合,然后使用rank()将排序序号加上;而【Python2】和【Python1】前2步相同,在最后一步使用了cumcount()实现编号。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | 【Python1】 df1_1 = df1.copy() df1_1[‘label’] = df1_1.sort_values([‘col6’,‘col5’],ascending=[False,True]).groupby([‘col2’])[‘col2’].rank(ascending=False,method=‘first’) df1_1[[‘col2’,‘col6’,‘col5’,‘label’]] 【Python2】 df1_1 = df1.copy() df1_1[‘label’] = df1_1.sort_values([‘col6’,‘col5’],ascending=[False,True]).groupby([‘col2’]).cumcount()+1 df1_1[[‘col2’,‘col6’,‘col5’,‘label’]] |
select col2,col6,col5,row_number()over(partition by col2 order by col6 desc,col5) label from t1; |
| 结果 |  |
 |
3、多列分组,多列排序
多列分组和多列排序,直接在【3、单列分组,多列排序】的基础上,将多个分组字段添加到groupby([])中的列表即可。不再赘述。
lead()/lag()
lead()是从当前行向后取列值,也可以理解为将指定的列向上移动;而lag()则相反,是从当前行向前取列值,也可以理解为将指定的列向下移动。
配合排序,二者可以进行互换,即:
- 正序的
lead()==倒序的lag() - 倒序的
lead()==正序的lag()
在 Python 中,可以通过shift()函数实现列值的上下移动,当传入一个正数时,列值向下移动,当传入一个负数时,列值向上移动。
注:关于单列/多列分组和单列/多列排序的情况,参考row_number(),不再赘述。
1、移动1行
移动1行时,MySQL 中直接使用lead(col1)/lag(col1)即可,使用lead(col1,1)/lag(col1,1)也没问题,再结合升降序实现列值的上下移动。
在 Python 中,则使用shift(-1)或shift(1)实现相同的效果。以下例子是将col1下移,所以使用shift(-1)。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘col1_2’] = df1_1.groupby([‘col2’]).col1.shift(-1) df1_1[[‘col2’,‘col1’,‘col1_2’]].sort_values([‘col2’,‘col1’],ascending=[True,True]) |
【MySQL1】 select col2,col1,lead(col1)over(partition by col2 order by col1) col1_2 from t1; 【MySQL2】 select col2,col1,lag(col1)over(partition by col2 order by col1 desc) col1_2 from t1; |
| 结果 |  |
 |
2、移动多行
移动多行的时候,MySQL 中需要指定移动行数,如下例子,移动2行,使用lead(col1,2)或lag(col1,2),再结合升降序实现列值的上下移动。
在 Python 中,则修改传递给shift()函数的参数值即可,如下例子,使用shift(2)向上移动2行。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘col1_2’] = df1_1.groupby([‘col2’]).col1.shift(2) # 通过shift控制 df1_1[[‘col2’,‘col1’,‘col1_2’]].sort_values([‘col2’,‘col1’],ascending=[True,True]) |
【MySQL1】 select col2,col1,lead(col1,2)over(partition by col2 order by col1 desc) col1_2 from t1; 【MySQL2】 select col2,col1,lag(col1,2)over(partition by col2 order by col1) col1_2 from t1; |
| 结果 |  |
 |
rank()/dense_rank()
rank()和dense_rank()用于计算排名。rank()排名可能不连续,就是当有重复值的时候,会并列使用小的排名,而重复值之后的排名则按照重复个数叠加往后排,如一组数(10,20,20,30),按升序排列是(1,2,2,4);而dense_rank()的排名是连续的,还是上面的例子,按升序排列是(1,2,2,3)。
而在 Python 中,排序同样是通过rank()函数实现,只是method和row_number()使用的不一样。实现rank()的效果,使method='min',而实现dense_rank()的效果,使用method='dense'。除了这两种和在row_number()中使用的method='first',还有average和max。average的逻辑是所有值进行不重复连续排序之后,将分组内的重复值的排名进行平均,还是上面的例子,按升序排列是(1,2.5,2.5,4),max和min相反,使用的是分组内重复值取大的排名进行排序,还是上面的例子,按升序排列是(1,3,3,4)。
同样地,排序字段如果有重复值,在 MySQL 中会随机返回,而 Python 中会默认使用index列进一步排序。
注:关于单列/多列分组和单列/多列排序的情况,参考row_number(),不再赘述。
1、rank()
Python 中使用rank(method='min')实现 MySQL 中的rank()窗口函数。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘label’] = df1_1.groupby([‘col2’])[‘col5’].rank(ascending=True,method=‘min’) df1_1[[‘col2’,‘col5’,‘label’]] |
select col2,col5,rank()over(partition by col2 order by col5) col1_2 from t1; |
| 结果 |  |
 |
2、dense_rank()
Python 中使用rank(method='dense')实现 MySQL 中的rank()窗口函数。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘label’] = df1_1.groupby([‘col2’])[‘col5’].rank(ascending=True,method=‘dense’) df1_1[[‘col2’,‘col5’,‘label’]] |
select col2,col5,dense_rank()over(partition by col2 order by col5) col1_2 from t1; |
| 结果 |  |
 |
first_value()
MySQL 中的窗口函数first_value()是取第一个值,可用于取数据默认顺序的第一个值,也可以通过排序,取某一列的最大值或最小值。
在 Pandas 中,也有相同功能的函数first()。
不过,first_value()是窗口函数,不会影响表单内的其他字段,但first()时一个普通函数,只返回表单中的第一个值对应的行,所以在 Python 中要实现first_value()窗口函数相同的结果,需要将first()函数返回的结果,再通过表联结关联回原表(具体例子如下)。在 Python 中,还有一个last()函数,和first()相反,结合排序,也可以实现相同效果,和first()可互换,读者可自行测试,不再赘述。
注:关于单列/多列分组和单列/多列排序的情况,参考row_number(),不再赘述。
1、取最大值
MySQL 中,对col5降序,便可通过first_value()取得最大值。同样,在 Python 中,使用sort_values()对col5进行降序,便可通过first()取得最大值,然后再merge()回原表。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_2 = df1_1.sort_values([‘col5’],ascending=[False]).groupby([‘col2’]).first().reset_index()[[‘col2’,‘col5’]] # 最好加个排序 df1[[‘col2’,‘col5’]].merge(df1_2,on = ‘col2’,how = ‘left’,suffixes=(‘’,‘_2’)) |
select col2,col5,first_value(col5)over(partition by col2 order by col5 desc) col5_2 from t1; |
| 结果 |  |
 |
2、取最小值
取最小值,则是在取最大值的基础上,改变col5的排序即可,由降序改为升序。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_2 = df1_1.sort_values([‘col5’],ascending=[True]).groupby([‘col2’]).first().reset_index()[[‘col2’,‘col5’]] df1[[‘col2’,‘col5’]].merge(df1_2,on = ‘col2’,how = ‘left’,suffixes=(‘’,‘_2’)) |
select col2,col5,first_value(col5)over(partition by col2 order by col5) col5_2 from t1; |
| 结果 |  |
 |
count()/sum()
MySQL 的聚合函数count()和sum()等,也可以加上over()实现窗口函数的效果。
count()可以用于求各个分组内的个数,也可以对分组内某个列的值进行累计。sum()可以用于对各个分组内某个列的值求和,也可以对分组某个列的值进行累加。
在 Python 中,针对累计和累加的功能,可以使用groupby()+cumcount()和groupby()+cumsum()实现(如下例子1和2),而针对分组内的计数和求和,可以通过groupby()+count()和groupby()+sum()实现(如下例子3和4)。
注:关于单列/多列分组和单列/多列排序的情况,参考row_number(),不再赘述。
1、升序累计
Python 中使用sort_values()+groupby()+cumcount()实现 MySQL count(<col_name>)over(partition by <col_name> order by <col_name>)效果。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘col5_2’] = df1_1.sort_values([‘col5’,‘col1’],ascending=[True,False]).groupby(‘col2’).col5.cumcount()+1 df1_1[[‘col2’,‘col5’,‘col5_2’]] |
select col2,col5,count(col5)over(partition by col2 order by col5,col1) col5_2 from t1; |
| 结果 |  |
 |
2、升序累加
Python 中使用sort_values()+groupby()+cumsum()实现 MySQL sum(<col_name>)over(partition by <col_name> order by <col_name>)效果。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_1[‘col5_2’] = df1_1.sort_values([‘col5’,‘col1’],ascending=[True,False]).groupby(‘col2’).col5.cumsum() df1_1[[‘col2’,‘col5’,‘col5_2’]] |
select col2,col5,sum(col5)over(partition by col2 order by col5,col1) col5_2 from t1; |
| 结果 |  |
 |
3、分组计数
Python 中使用sort_values()+groupby()+count()实现 MySQL count(<col_name>)over(partition by <col_name>)效果。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_2 = df1_1.sort_values([‘col5’,‘col1’],ascending=[True,False]).groupby(‘col2’).col5.count().reset_index() df1_1[[‘col2’,‘col5’]].merge(df1_2,how=‘left’,on=‘col2’,suffixes=(‘’,‘_2’)) |
select col2,col5,count(col5)over(partition by col2) col5_2 from t1; |
| 结果 |  |
 |
4、分组求和
Python 中使用sort_values()+groupby()+sum()实现 MySQL sum(<col_name>)over(partition by <col_name>)效果。
| 语言 | Python | MySQL |
|---|---|---|
| 代码 | df1_1 = df1.copy() df1_2 = df1_1.sort_values([‘col5’,‘col1’],ascending=[True,False]).groupby(‘col2’).col5.sum().reset_index() df1_1[[‘col2’,‘col5’]].merge(df1_2,how=‘left’,on=‘col2’,suffixes=(‘’,‘_2’)) |
select col2,col5,sum(col5)over(partition by col2) col5_2 from t1; |
| 结果 |  |
 |
三、小结
MySQL 的窗口函数效果,在 Python 中,基本都需要经过多个步骤,使用多个函数进行组合处理。窗口函数涉及到分组字段和排序字段,在 Python 中对应使用groupby()和sort_values(),所以基本上在 Python 中实现窗口函数的效果都需要使用到这两个函数辅助处理数据。剩下的聚合形式就根据聚合窗口函数的特性做修改,对应关系如下:
| MySQL 窗口函数 | Python 对应函数 |
|---|---|
| row_number() | rank() |
| lead()/lag() | shift() |
| rank()/dense_rank() | rank() |
| first_value() | first() |
| count() | count()、cumcount() |
| sum() | sum()、cumsum() |
到此这篇关于使用Pandas实现MySQL窗口函数的解决方法的文章就介绍到这了,更多相关Pandas 窗口函数内容请搜索aitechtogether.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持aitechtogether.com!