一、图像增强
大型数据集是成功应用深度神经网络的先决条件。 图像增强(Image Augmentation)在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。此外,应用图像增强的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
例如,我们可以以不同的方式裁剪图像,使感兴趣的对象出现在不同的位置,减少模型对于对象出现位置的依赖。 我们还可以调整亮度、颜色等因素来降低模型对颜色的敏感度。 可以说,图像增强技术对于 AlexNet 的成功是必不可少的。
本文将基于 torchvision 工具箱介绍常用的图像增强方法,有关该工具箱的介绍请看这篇文章。
二、torchvision.transforms 介绍
torchvision.transforms 中提供了大量的用于图像变换/增强的类,绝大多数的类有其相对应的函数版本,它们可以在 torchvision.transforms.functional 中找到(好比 torch.nn 与 torch.nn.functional 之间的关系)。函数版本和类版本的区别在于,函数版本不包含用于其参数的随机数生成器,即你需要指定所有的参数才能够使用。此外,函数版本所产生的结果通常是可复现的。类版本通常采用的是随机变换,但是它会对同一个 batch 中的所有样本采用相同的随机变换,且调用类版本将导致结果不可复现。
由于之前我们已经介绍了函数版本(链接),故本文将主要聚焦于类版本的使用。
二、图像展示
先导入本文所需要的包:
from torchvision import transforms
import matplotlib.pyplot as plt
from PIL import Image
为方便接下来更加直观地展示图像,这里定义一个图像展示器。它接受 PIL 图像作为输入参数,调用 apply 方法可对相应的图像应用图像增强并展示结果。
class ImageDisplay:
def __init__(self, img):
self.img = img
def apply(self, aug):
_, axes = plt.subplots(1, 4)
for i in range(4):
axes[i].imshow(aug(self.img))
axes[i].axes.get_xaxis().set_visible(False)
axes[i].axes.get_yaxis().set_visible(False)
plt.show()
之后,我们将以下面这张图为基准,对其进行图像增强:

假设该图路径为 ./pics/1.jpg。
三、翻转与旋转
3.1 随机水平翻转
使用格式:
transforms.RandomHorizontalFlip(p=0.5)
以概率 水平翻转给定的图像。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomHorizontalFlip()
imgdp.apply(aug)
效果:

因为默认概率是 ,所以最终结果是有一半图片水平翻转了,另有一半没有翻转。
3.2 随机垂直翻转
使用格式:
transforms.RandomVerticalFlip(p=0.5)
以概率 垂直翻转给定的图像。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomVerticalFlip(0.75)
imgdp.apply(aug)
效果:

因为概率为 ,所以有三张图片翻转了。但需要注意的是,概率并不代表真实情况,也有可能一张都不翻转。
3.3 随机旋转
使用格式:
transforms.RandomRotation(degrees, center=None, fill=0)
degrees为元组或标量。当degrees为元组(min, max)时,会随机从其中挑选一个角度值进行旋转。当degrees为标量时,范围变为(-degrees, degrees)。center为一个元组,代表围绕哪一个点进行旋转,默认为原图的中心。轴方向沿图像的宽,
轴方向沿图像的高。
fill为填充值,默认为0,即黑色。fill可以为 RGB 元组也可以为标量,为标量时代表灰度。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomRotation(45, fill=(255, 0, 0))
imgdp.apply(aug)
这段代码表示将原图在 内围绕原图中心随机旋转,并以红色填充其他区域。效果如下:

四、缩放与裁剪
4.1 调整大小
使用格式:
transforms.Resize(size)
size 为形如 (H, W) 的元组。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomVerticalFlip(0.75)
imgdp.apply(aug)
效果:

4.2 中心裁剪
使用格式:
transforms.CenterCrop(size)
作用是裁剪图像的中心区域,且区域大小为 (H, W)。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.CenterCrop((200, 200))
imgdp.apply(aug)
效果:

4.3 随机裁剪
使用格式:
transforms.RandomCrop(size)
随机裁剪图像中的某个区域,且区域大小为 size。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomCrop((200, 200))
imgdp.apply(aug)
效果:

4.4 随机裁剪缩放
使用格式:
transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.333))
以默认参数来解释。首先随机裁剪一个面积为原始面积 到
的区域,该区域的宽高比从
到
之间随机取值,最后将该区域调整为指定的
size。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))
imgdp.apply(aug)
效果:

五、亮度、对比度、饱和度等
5.1 随机改变亮度、对比度、饱和度和色调
使用格式:
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
有点懒得码字了,这里直接放官网的截图:

img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
imgdp.apply(aug)
效果:

5.2 随机转化为灰度图
使用格式:
transforms.RandomGrayscale(p=0.1)
以概率 将一张图转化为灰度图。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomGrayscale(p=0.5)
imgdp.apply(aug)
效果:

5.3 随机翻转图像颜色
使用格式:
transforms.RandomInvert(p=0.5)
以概率 翻转图像的颜色。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomInvert(p=0.5)
imgdp.apply(aug)
效果:

5.4 随机调整锐度
使用格式:
transforms.RandomAdjustSharpness(sharpness_factor, p=0.5)
以概率 调整图像的锐度。
sharpness_factor 为锐度因子, 代表模糊,
代表原图,值越大代表锐度越高,没有上限。
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
aug = transforms.RandomAdjustSharpness(100)
imgdp.apply(aug)
效果:

六、组合多种图像增强
img = Image.open('./pics/1.jpg')
imgdp = ImageDisplay(img)
augs = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2)),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
])
imgdp.apply(augs)
效果:

七、归一化(标准化)
使用格式:
transforms.Normalize(mean, std)
对张量图像进行归一化操作(不支持 PIL 图像)。
假设有 个通道,则
mean=(mean[1], ..., mean[n]),std=(std[1], ..., std[n]) 。输出为 output[channel] = (input[channel] - mean[channel]) / std[channel] 。
from PIL import Image
from torchvision.transforms import ToTensor, ToPILImage, Normalize
pic = Image.open('./pics/1.jpg')
img2tensor, tensor2img = ToTensor(), ToPILImage()
normalizer = Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
pic = tensor2img(normalizer(img2tensor(pic)))
pic.show()
对图像进行归一化的效果如下:

八、在 CIFAR-10 上应用图像增强
使用 ResNet-18,在 CIFAR-10 上应用图像增强(仅对训练集应用),观察训练/测试效果:
import torchvision
import torch.nn.functional as F
from torch import nn
from torch.utils.data import DataLoader
from torchvision import transforms
from Experiment import Experiment as E
class Residual(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, conv_1x1=False):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
)
self.conv_1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride) if conv_1x1 else None
def forward(self, x):
y = self.block(x)
if self.conv_1x1:
x = self.conv_1x1(x)
return F.relu(y + x)
class ResNet(nn.Module):
def __init__(self):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block_2 = nn.Sequential(
Residual(64, 64),
Residual(64, 64),
Residual(64, 128, stride=2, conv_1x1=True),
Residual(128, 128),
Residual(128, 256, stride=2, conv_1x1=True),
Residual(256, 256),
Residual(256, 512, stride=2, conv_1x1=True),
Residual(512, 512),
)
self.block_3 = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.block_1(x)
x = self.block_2(x)
x = self.block_3(x)
return x
def init_net(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
if __name__ == '__main__':
train_augs = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
transforms.ToTensor()
])
test_augs = transforms.Compose([transforms.Resize(224), transforms.ToTensor()])
train_data = torchvision.datasets.CIFAR10('/mnt/mydataset', train=True, transform=train_augs, download=True)
test_data = torchvision.datasets.CIFAR10('/mnt/mydataset', train=False, transform=test_augs, download=True)
train_loader = DataLoader(train_data, batch_size=128, shuffle=True, num_workers=4)
test_loader = DataLoader(test_data, batch_size=128, num_workers=4)
resnet = ResNet()
resnet.apply(init_net)
e = E(train_loader, test_loader, resnet, 20, 0.05)
e.main()
e.show()
在 NVIDIA GeForce RTX 3090 上的运行结果如下:
Epoch 20
--------------------------------------------------
Train Avg Loss: 0.054338, Train Accuracy: 0.982660
Test Avg Loss: 0.789593, Test Accuracy: 0.811900
--------------------------------------------------
3054.1 samples/sec
--------------------------------------------------
Done!
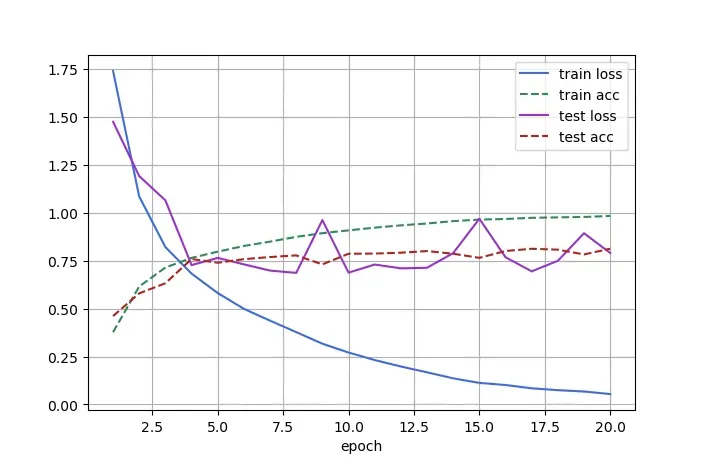
九、最后
本文仅介绍了部分图像增强的手段,如需了解更多,可前往官方文档进一步学习。
文章出处登录后可见!