· 阅读摘要:
本文提出基于SGM模型,在Seq2Seq的基础上提出SGM模型应用于多标签文本分类。论文还提出了很多提升模型表现的细节,这是在Seq2Seq中没有的。
·参考:
[1] SGM: Sequence Generation Model for Multi-Label Classification
[2] Seq2Seq模型讲解,参考博客:【多标签文本分类】代码详解Seq2Seq模型
这篇文章的亮点很多:
1、对训练集的标签处理:高频标签放在前面,进而更好地指导整个标签的输出。此外,bos和eos符号分别添加到标签序列的头部和尾部;
2、SGM模型结构:编码器+注意力机制+解码器;
3、解码器预测生成词时,使用Masked Softmax防止重复预测;
4、上一步的生成词转为词向量,放入下一步的解码器时,采用Global Embedding全局嵌入;
5、选择生成出来的序列时,采用beam search波束搜索算法找出预测路径;
[1] SGM模型图
下图是论文中给出的模型: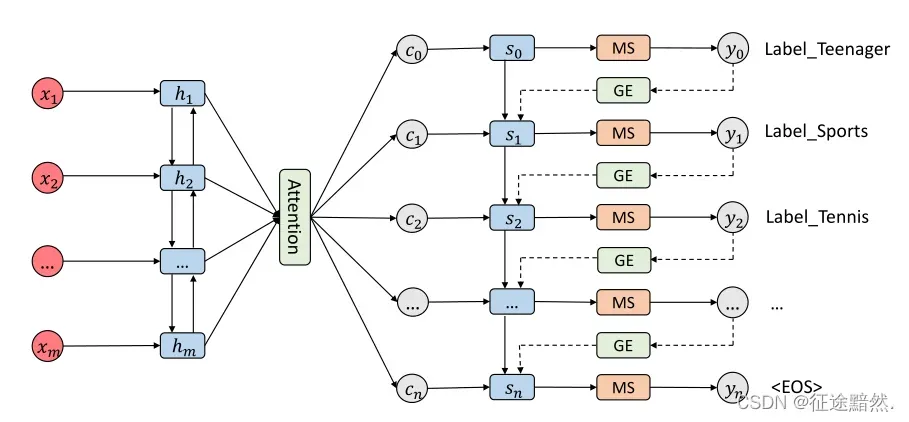
我在模型图中添加了一些注解,如下图: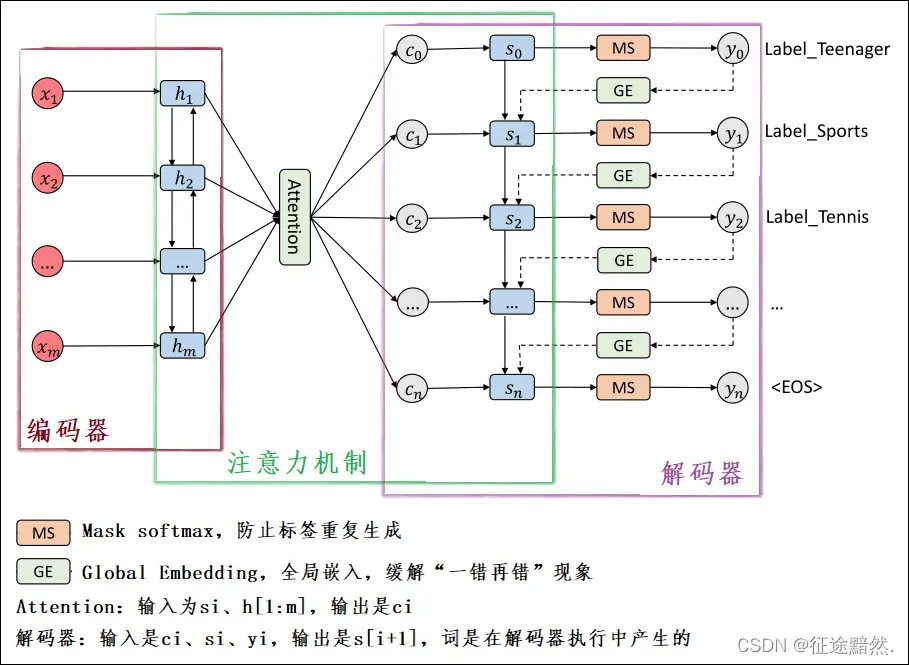
[注1]:模型介绍主要是为了帮助理解。公式推导可以参考论文原文
首先,模型架构可以分成3个部分:编码器、注意力机制、解码器。
1、编码器(Encoder):很简单,就是一个双向LSTM,输出是每一步的,即
。
2、注意力机制(Attention):此层的目的是,在当前下,挖掘
到
中与
关系比较突出的向量表示,即
。所以,此层的输入为
、
,输出是
。
【注2】:
将作为与
相同状态的数据,两者拼接在一起作为解码器的输入。
3、解码器(Decoder):基础架构也是双向LSTM。但是在Seq2Seq模型中解码器的输入为(),但是本文模型的解码器输入为(
),
表示是
、
两者的拼接,
中的函数
就是上文提到的Global Embedding思想。除此之外,为了防止生成同样的标签,在解码器预测标签时,还使用了Masked Softmax思想。
【注三】:Global Embedding、Masked Softmax会在下文阐述。
[2] 细节阐述
1、Masked Softmax解决多标签分类的输出重复问题。
解决方法:作者引入在最终
输出时去掉输出标签。
的表示如下。如果标签已经输出,那么
是负无穷大:
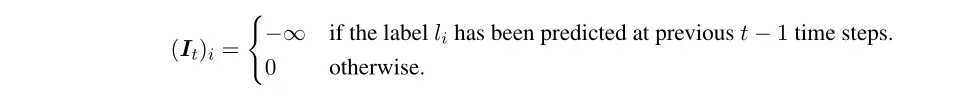
2、 Seq2Seq 中某时刻t 的输出对时刻t+1的输出影响很大,也就是说时刻t出错会对时刻 t+1之后的所有输出造成严重影响。论文称为exposure bias问题。
解决方法: 在多标签分类问题中,我们显然不想让标签间拥有如此强的关联性,于是作者提出Global Embedding来解决这个问题。
3、beam search波束搜索算法找出预测路径,优化路径搜索算法。
是 label 的 embedding,这个 label 是在
分布下的最高概率所对应标签得来的。可是,这个计算只是贪心的利用了
的最大值。在论文提出的 SGM 模型中,基于先前预测的标签来产生下一个标签。因此,如果在第t-1时刻得到了错误的预测,然后就会在预测下一个标签的时候得到了一个错误的后继标签,这也叫做 exposure bias (错上加错)。这也是为什么采用贪心法在 decoder 部分不合适的地方,这个道理不仅适用于这篇论文的任务,对于机器翻译、自动摘要等任务,仍然适用。
所以,便有了 beam search 算法的产生。beam search 算法从一定程度上缓解了这个问题,有兴趣的可以自行去搜索下 beam search 算法的原理,但是它仍然不能从根本上解决这个问题,因为 exposure bias 可能会出现在所有的路径上。
4、提升模型小技巧
考虑到出现次数更多的标签在标签相关性训练中具有更强的作用,在训练时把标签按照其出现次数进行从高到低排序作为输出序列。这么做的好处是,出现次数更多的标签可以出现 LSTM 的前面,进而更好地指导整个标签的输出。
版权声明:本文为博主征途黯然.原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_43592352/article/details/123163060