之前都是 *nix 环境使用 pytorch,这次尝试了一下windows。
我们来部署下流行性高的stable diffusion和我觉得实用性比stable diffusion高多了的NeRF
Stable Diffusion
其实,我也不知道要写啥,都是按照步骤做就好了,后面等有时间了我们来写写如何训练模型吧……
https://stability.ai/stable-diffusion/
https://github.com/Stability-AI/StableDiffusion
一般,我们不用直接去捣鼓这个模型和一堆脚本,人家有webui,可以启动网页版啊…所以国内有很多就是基于这个网页版,然后再把最重要的一步Hugging Face上的模型搬运过来…我估计在国内架一个Hugging Face CDN最近会很吃香啊,随便搜索了下,bing上还是有的…
是的,最近都不怎么用Google了,Bing已经不错了…有事就问搭载GPT-4的Coplit…
扯了这么多,用得比较多得webui的github:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
看了一下,github上发布目前最新的已经只有source code了;
然而,如果你不想费周折去在windows上配置python+git,那么就直接
https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs
其他诸如AMD GPU、MacOSX、Docker可以看这里
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
把 sd.webui.zip 下载下来,解压,运行 update.bat 再 run.bat 其实就可以用了…
btw,我得windows机器是Nvida 3070,所以先去官网安装Cuda驱动,3GB,啊既然提到了GB,准备好30GB再来运行stable diffusion哦…
首先如果你 run.bat 失败了很多次,我们来看看一些可行得解决方案:
- 一个是这个pytorch,直接pip install得话只有400kb,查阅了网上得资料,打开cmd然后cd到stable diffusion webui的解压后的文件夹下,预先可以:
call enviroment.bat
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -f https://download.pytorch.org/whl/torch_stable.html
使用后就是飞一般的速度,据说有人是40MB/s,作为穷人的我还没那么非,10MB/s,几分钟就把这个2.6GB的pytorch搞定了…
- 刚才说了Hugging Face CDN,去bing上看下国内的镜像,然后下载对应model文件好了;如果更方便,就是用在
C:\Windows\System32\drivers\etc里用管理员权限编辑 huggingface.co 指像本地127.0.0.1的nginx,在nginx把huggingface接上国内镜像站就好了;哦不用这么麻烦,如果人家没用复杂的配置,直接ping拿到镜像站的ip然后直接hosts里指定就好了…嗯,基础模型也就将近4GB吧…
如果你得模型下了一半,网络挂了,最好得办法就是把下载一半的文件干掉,重新 run.bat 一下…
我们来看一下,界面其实一目了然,输入一些文字,然后”Generate”就可以出图了。
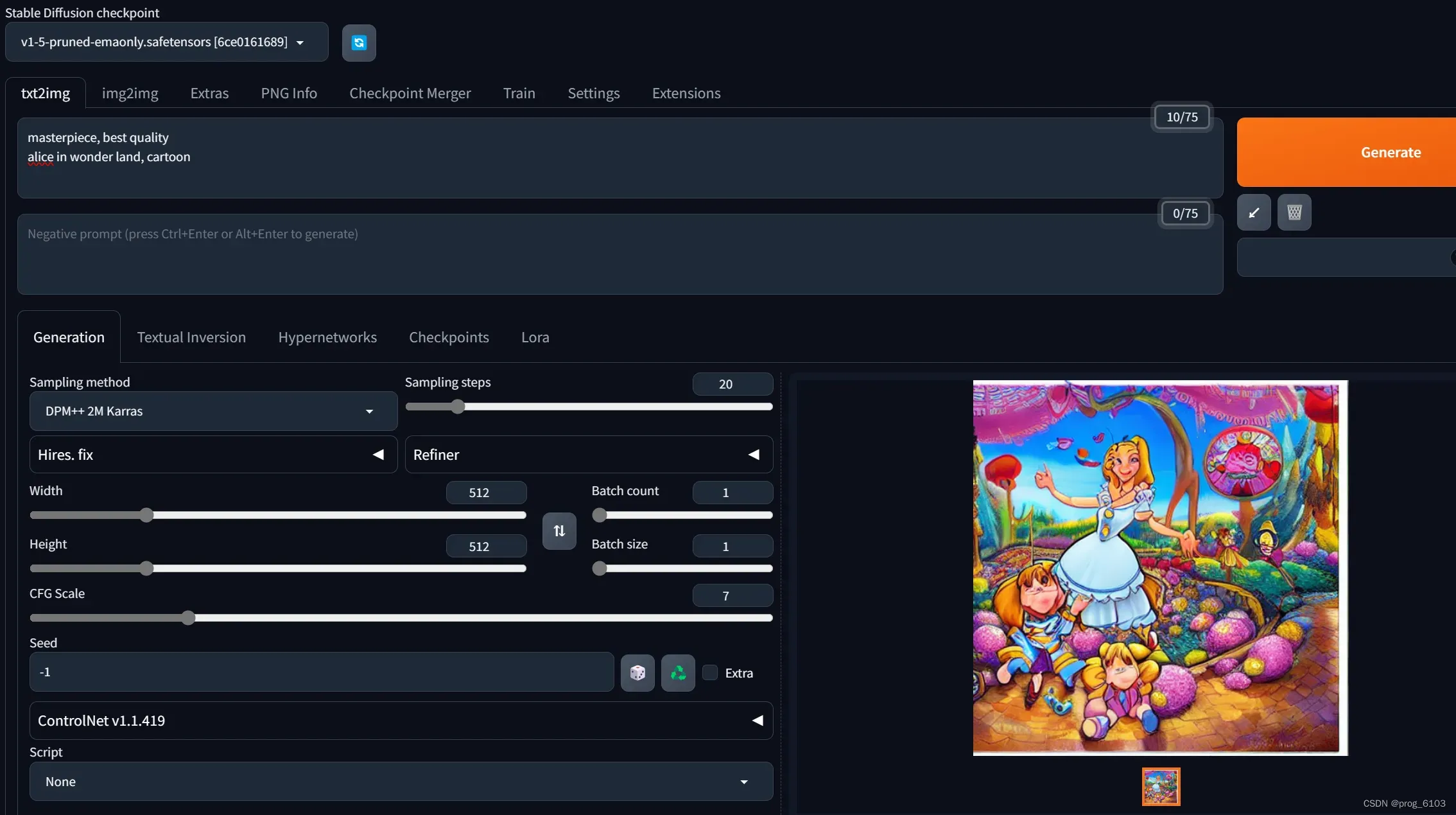 这里我们可以玩一下controlNet,画一个简笔画,让它生成图片。
这里我们可以玩一下controlNet,画一个简笔画,让它生成图片。
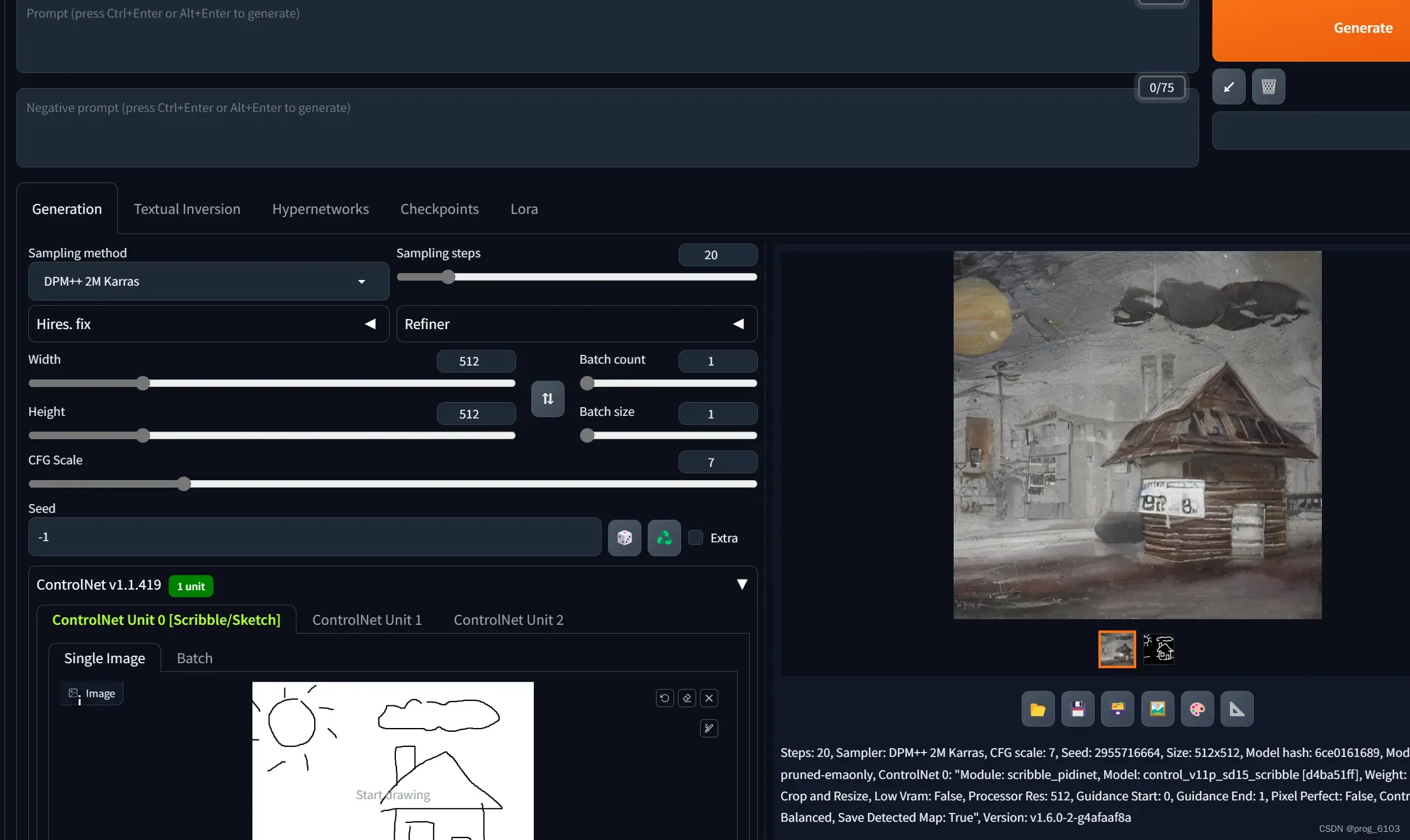 补充下,这里controlNet实际是一个插件
补充下,这里controlNet实际是一个插件
https://github.com/Mikubill/sd-webui-controlnet.git
按照它的github去操作就好了,这个的模型文件还是有点大的,因为分了不同的模块,Hugging Face上是每个模块都是1.45GB的pth模型参数文件…也就十几个吧…之后大家有兴趣,还可以自己去查LoRA插件的使用…估计网上教程漫天飞舞了…
NeRF
NeRF这个东西本身还是蛮有意思的…拍摄一系列的物体照片,通过神经网络,计算光场,相当于空间里某个点xyz上颜色的概率…就是如何让罗马在3天之内建成,可以通过在罗马拍照取样,然后计算建模生成整个3D场景;或者说我们想要3D打印一个手办,把现有的手办拍点照片,就可以生成数字化文件,直接再去打印去…
官方网址是
https://nerf.studio/
里面的过程也很详细…
首先我们可以学习上面的sd webui,里面有一些脚本配置环境,比如 environment.bat 配置了python在哪里;为了不污染各个python环境,我们可以把python的zip包下载下来后,然后安装个pip,sd webui里也有 get-pip.py 可以用。之后 pip install virtualenv把virtualenv安装好,这样用 python -m virtualenv xxxx就可以创建一个相对独立的python运行环境了;之后就是把 enviroment.bat 复制过来,把路径配置成我们virtualenv生成的python路径。按照stable diffusion描述的一些方法可以安装好另一套pytorch,这样就可以安装NeRF studio了:pip install nerfstudio
安装完成以后,按照教程
- 下载样例照片
ns-download-data nerfstudio --capture-name=poster - 使用照片训练模型
ns-train nerfacto --data data/nerfstudio/poster
嗯,训练速度么,3070要训练30k epoch大概2h(tiny-cuda-nn没安装的情况);使用官方的链接可以看到结果,但是官方给的链接是官网的地址打开连接上本地的websocket服务端…我想纯local怎么呢…反正人家官网地址viewer是static的,直接把html css js都dump一下下载到本地就好了,就可以纯本地看结果了…
训练完成以后,可以通过webui生成一下导出point cloud的命令,在cmd里运行,比如
ns-export poisson
--load-config outputs\poster\nerfacto\2023-11-29_141945\config.yml
--output-dir exports/mesh/
--target-num-faces 50000
--num-pixels-per-side 2048
--normal-method open3d
--num-points 1000000
--remove-outliers True
--use-bounding-box True
--bounding-box-min -1 -1 -1
--bounding-box-max 1 1 1
就可以导出 obj mlt ply 文件了,这个文件找一个阅读软件观看好了…

这个生成的文件其实就可以导入3D软件里编辑了,修修边,调整一下,其实可以去3D打印了。
文章出处登录后可见!