IP核_DDR4_SDRAM的详细介绍
- 内核架构
- 内存控制器
- ECC
- 地址奇偶校验
- Clamshell 拓扑
- 迁移功能
- MicroBlaze MCS ECC
- Memory 设置
- 内核设计
- 协议描述
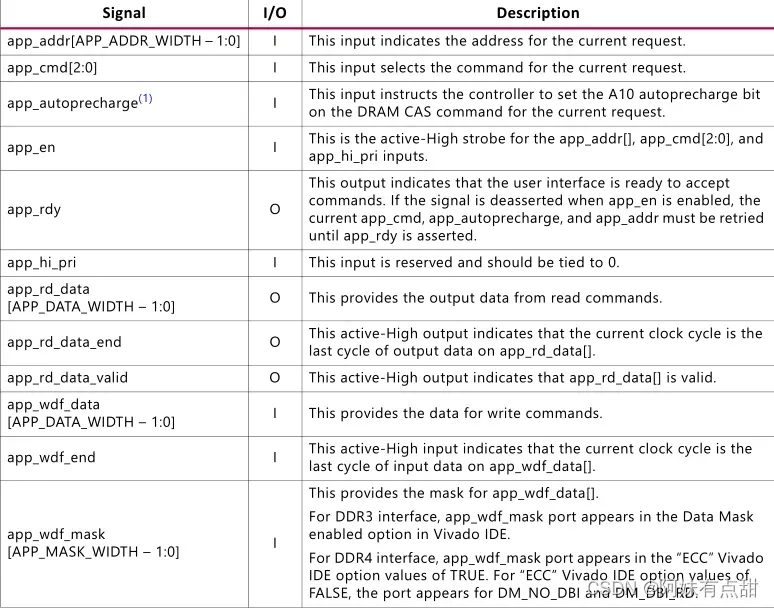
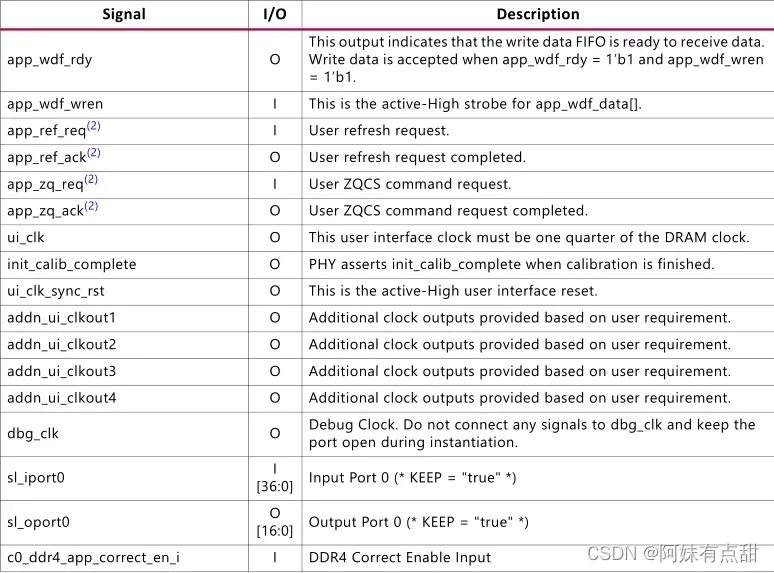
- APP接口
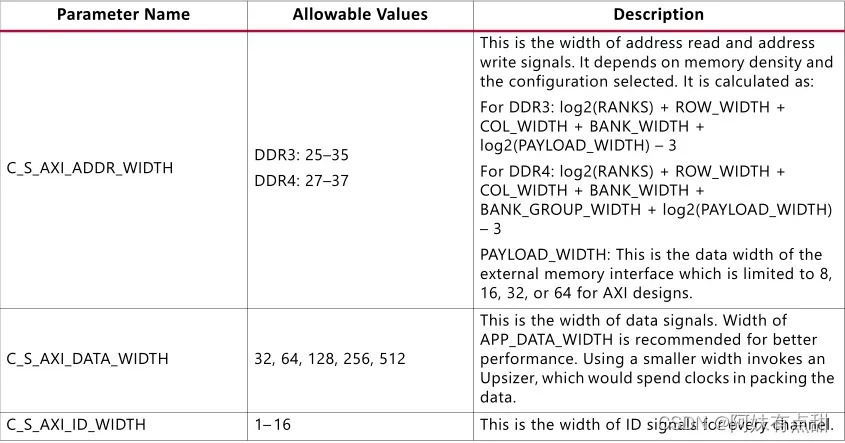
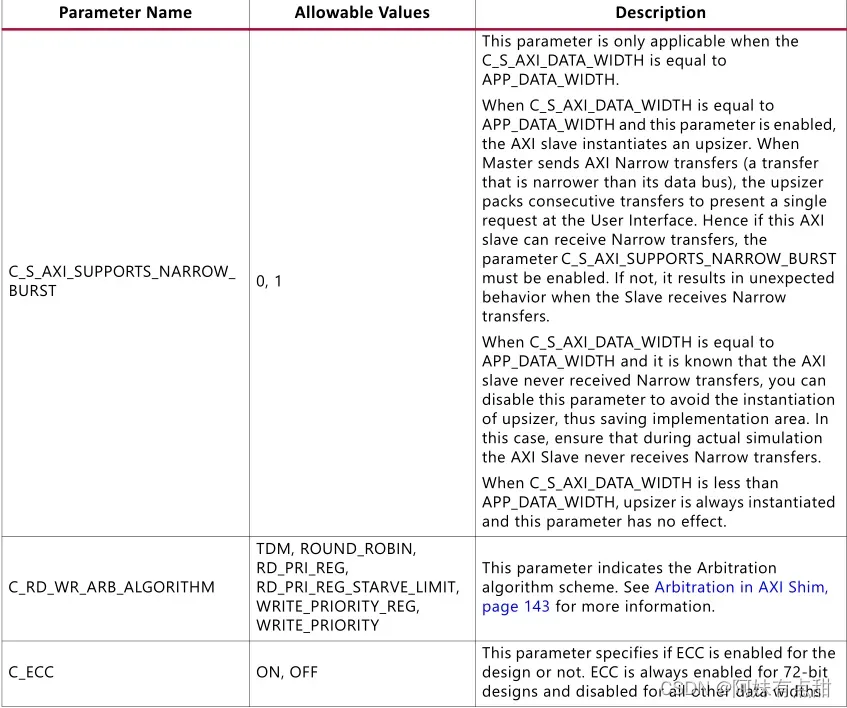
- 信号app_addr[APP_ADDR_WIDTH – 1:0]
- 信号app_cmd[2:0]
- 信号app_autoprecharge
- 信号app_en
- 信号app_wdf_data[APP_DATA_WIDTH – 1:0]
- 信号app_wdf_end
- 信号app_wdf_mask[APP_MASK_WIDTH – 1:0]
- 信号app_wdf_wren
- 信号app_rdy
- 信号app_rd_data[APP_DATA_WIDTH – 1:0]
- 信号app_rd_data_end
- 信号app_rd_data_valid
- 信号app_wdf_rdy
- 信号app_ref_req
- 信号app_ref_ack
- 信号app_zq_req
- 信号app_zq_ack
- 信号ui_clk_sync_rst
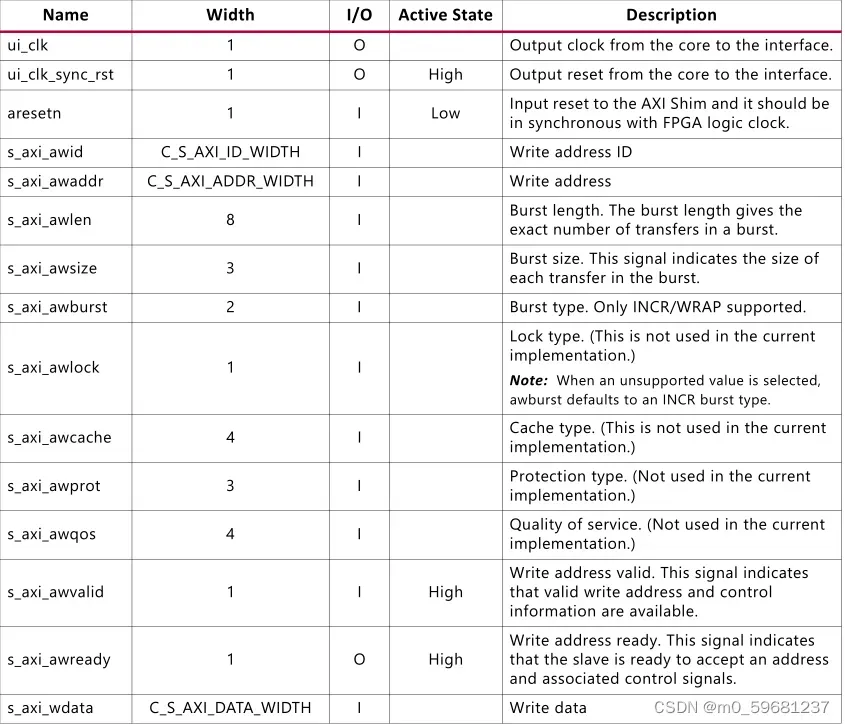
- 信号ui_clk
- 信号init_calib_complete
- 命令路径
- 写入路径
- 读取路径
- 维护命令
- AXI4 Slave接口
- 性能体现
- DIMM配置
- IP核配置流程
- 测试平台
内核架构
这个IP核相当于提供给了用户一个有关SDRAM存储器类型接口的解决方案,它支持完整的内存控制器和仅物理层(PHY)解决方案。DDR3\DDR4核的Ultra Scale体系架构分为以下高级块:
1、控制器:控制器接收来自用户接口的突发事务,并生成与SDRAM之间的事务,控制器负责SDRAM定时参数和刷新。它合并了读和写事务,以减少相关总线陷入死循环的次数,控制器还会重新排序指令以提高SDRAM数据总线的利用率。
2、物理层:物理层为SDRAM提供高速接口,该层包括FPGA内部的硬件模块和软件模块校准逻辑,目的是确保SDRAM硬件模块接口的最佳时序。
硬件模块包括数据序列化和传输;数据的捕获与反序列化;高速时钟的生成和同步;每个pin脚具有电压和温度跟踪的粗延迟元件和细延迟元件;
软件模块包括内存初始化(校准模块为特定内存类型提供符合JEDEC@的初始化例程);校准模块提供了一种完整的方法来设置硬件模块和软件IP中的所有延迟,以便与内存接口一起工作,每一位都经过单独训练,然后进行组合,以确保最佳的接口性能。
应用接口:用户接口层提供了一种类似于简易FIFO的接口,数据被缓存,读取的数据按照要求的顺序呈现,该用户接口在控制器的本地接口之上,本地接口不能由用户接口访问,并且当从SDRAM接收返回数据时没有缓冲,然后用户接口缓冲读写数据,并根据需要重新排序数据。
下面这张图就是提供的解决方案:
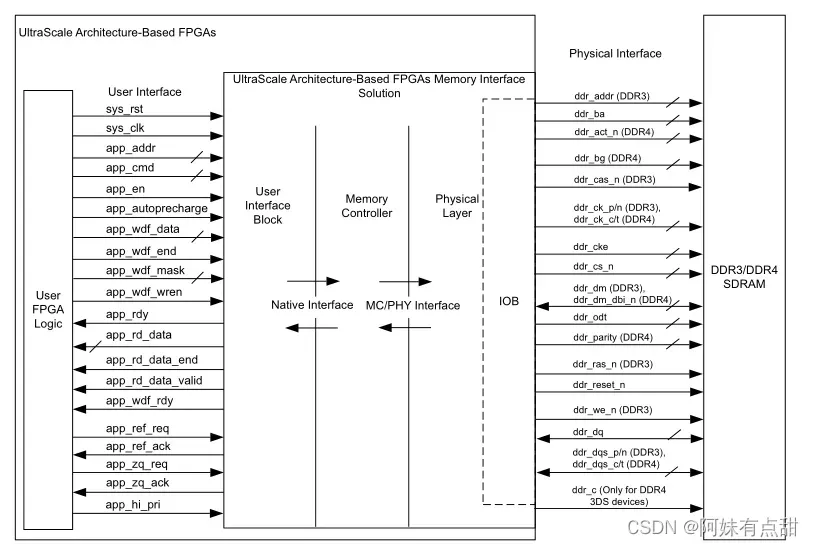
我们可以了解一下DDR4 SDRAM的特点总结:
1、component支持8到80位的接口宽度(RDIMM、LRDIMM、UDIMM、SODIMM也支持);
2、component支持高达32GB的容量,LRDIMMs支持64GB,RDIMMs支持128GB,SODIMMs和UDIMMs支持16GB,通过自定义部件选择可获得内存设备支持的其他容量;
3、AXI4从接口:基于x4的component不支持AXI4,而基于x4的RDIMM和LRDIMM支持AXI4;
4、支持x4、x8、x16组件;
5、DDR4 RDIMMs, SODIMMs, LRDIMMs, and UDIMMs支持双插槽;
6、支持8_word突发传输;
7、支持9到24个周期的列地址选通(Column Address Strobe CAS)延迟(CL,是CAS潜伏期,从CAS与读取命令发出到第一笔数据输出的时间段);
8、支持ODT(On-Die Terminaton Die指的就是DDR颗粒,DDR颗粒上的终端电阻,ODT作用就是防止信号在电路上形成反射);
9、支持3DS RDIMM和LRDIMM;
10、支持3DS component;
11、支持9到18个周期的CAS写入延迟;
12、4:1的存储器与FPGA逻辑接口时钟比率;
13、支持非AXI4 72位接口的可选纠错码(ECC);
14、不支持写操作的CRC;
下面这张图是FPGA内存接口解决方案:
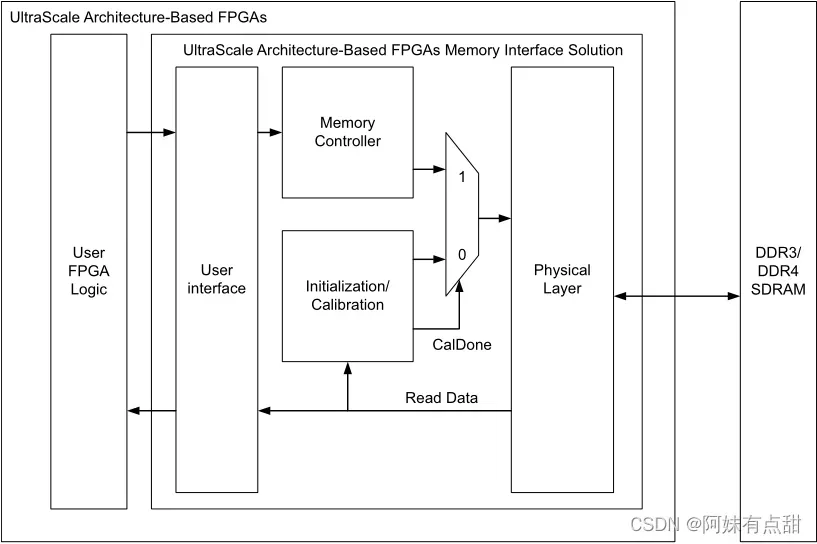
内存控制器
Memory Controller简称MC,被设计用来从User interface简称UI中获取读、写和读-修改-写事务,并以低延迟高效地将它们发送到存储器,满足所有的DRAM协议和时序要求,同时使用最少的FPGA资源,控制器以4:1的DRAM与系统时钟比运行,并可以在每个系统时钟周期上发出一个激活、一个CAS和一个预充电命令。该控制器支持开放页面策略,可以在具有高效空间局部性的工作负载中实现非常高的效率。该控制器还支持封闭页面策略和重新排序事务的能力,以有效地调度具有更随机性地地址模式的工作负载。控制器还允许在每个事务的基础上使用用于预充电的UI控制信号以及可用于确定何时发出DRAM刷新命令的信号对低级功能进行一定程度的控制。
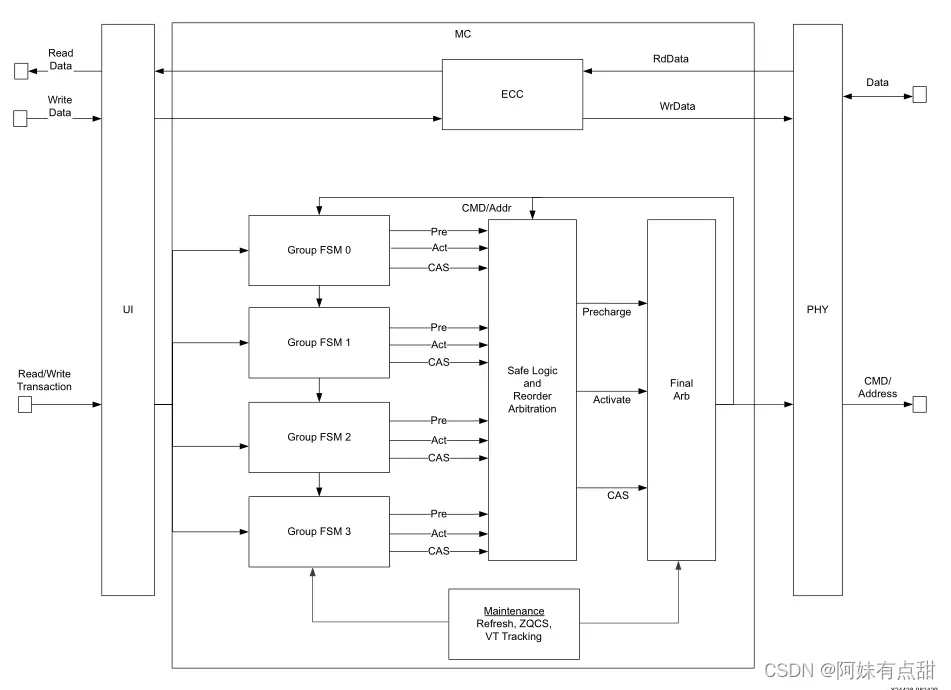
MC命令路径的关键块包括:
1、将事务排队、检查DRAM计时并决定何时请求预充、激活和CAS DRAM命令的FSM(有限状态机)组;
2、“安全”逻辑和仲裁单元:基于额外的DRAM时序检查对FSM组之间的事务进行重新排序,同时确保所有的DRAM命令请求的进度;
3、最终仲裁器:对向PHY发出的命令作出最终的决定,并将结果反馈给前一阶段。
控制器命令路径的维护块包括:
1、生成刷新和ZQCS命令的模块;
2、VT tracking所需的命令;
3、为72位宽数据总线实现SECDED ECC的可选块。
下面这张图就是内存控制器的框图:
本机接口
UI通过本地接口连接到内存控制器,并为控制器提供地址解码和读\写数据缓冲。在写入时,控制器在需要数据之前一个周期通过在本地接口上显示数据缓冲区地址来请求数据。该数据预计将在下一个周期由UI模块提供。因此,不存在任何类型的数据缓冲。
在读取时,MC在其可用的周期内提供数据,读取数据以及缓冲区地址一经准备好就显示在本机接口上,UI模块必须接收数据。
基于来自UI模块的解码地址的Bank地址和group Bank,读和写事务被映射到一个mcGroup实例,虽然在DDR3里没有Group,但是在DDR4 x4和x8设备中Group组表示真实存在的组(为该组的四个Bank提供服务),对于DDR3,每个Group将服务两个Bank。
在DDR4 x16的接口中,mcGroup表示1 bit组(x16中仅有一组位)和1bit Bank,因此mcGroup服务两个Bank。
未完成的请求总数取决于mcGroup实例的数量,以及从控制器到内存的往返延迟,当控制器向内存发送SDRAM CAS命令时,mcGroup实例可以接收新请求,而以前的CAS命令,读取返回数据或写入数据可能仍然在运行中。
控制与数据路径
控制路径
控制路径从mcGroup实例开始,SDRAM group和Bank地址到mcGroup实例的映射确保了同一完整地址的事务映射到同一mcGroup实例。因为每个mcGroup实例都按照顺序处理它接收的事务,所以防止了写后读和写后写的危险。
数据路径
读写数据通过内存控制器,如果启用ECC,则在写入时生成SECDEC,并在读取时检查。MC向mcRead和mcWrite模块提供必要的控制信号,告诉他们读取和写入数据的时序。这两个模块在适当的时间获取或提供所需要的数据。
读写合并
启用重新排序时,控制器将读取优先于写入,如果读写CAS命令都可以安全地在SDRAM命令总线上发出,则控制器只选择读CAS命令进行仲裁。当读取CAS出现问题时,写入CAS命令会被参数tRTW指定的几个SDRAM时钟阻塞。发出读取CAS命令后,写入CAS变得安全所需要的额外时间允许在命令总线上发出读取组,而不会被挂起的写入中断。
重新排序
映射到同一mcGroup的请求永远不会重新排序。mcGroup实例之间的重新排序由ORDERING参数控制。当设置为“NORM”时,将启用重新排序,仲裁器将执行循环优先级计划,使用可安全发送到SDRAM的命令在mcGroup中按优先级顺序进行选择。安全向SDRAM发出命令的时间可能因目标银行或银行组及其页面状态而异。这通常有助于重新排序。当ORDERING参数设置为“STRICT”时,所有请求都会按照本地接口接受请求的顺序发出其CAS命令。严格排序会覆盖所有其他控制器机制,例如合并读取请求的趋势,因此会降低某些工作负载中的数据带宽利用率。
组状态机
在内存控制器中,有四个组状态机。这些状态机的分配取决于技术(DDR3或DDR4)和宽度(x4、x8和x16)。下面总结了对每个组计算机的分配。在本说明中,GM表示组机器(0至3),BG表示group地址,BA表示Bank地址。
注意,组状态机上下文中的组表示概念group,不一定指实际group(DDR4的情况除外,部分x4和x8)。

下面这张图显示了一个实例的group FSM框图。组FSM块有两个主要部分,第一阶段和第二阶段,每个部分包含FIFO和FSM。阶段1与UI接口,发出预充电和激活命令,并跟踪DRAM页面状态。阶段2发布CAS命令并管理RMW流。还有一组DRAM定时器,用于FSM用于在最早的安全时间调度DRAM命令。组FSM块的设计使每个实例从UI排队多个事务,将来自多个事务的DRAM命令交错放到DDR总线上以提高效率,并严格按顺序执行CAS命令。
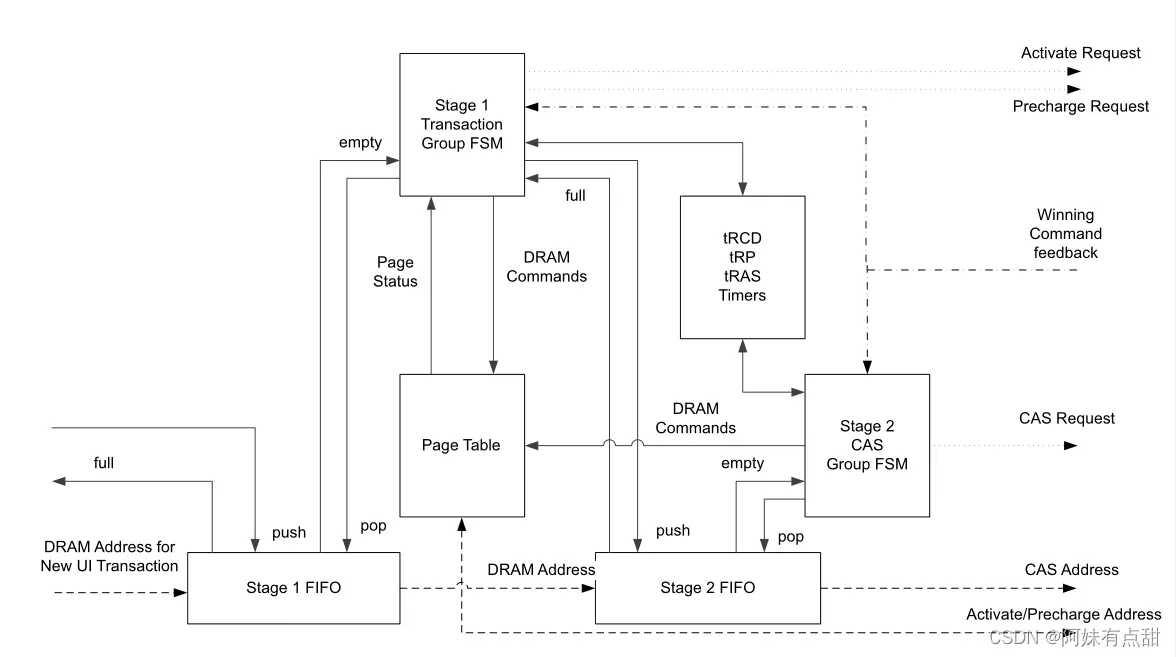
当从UI接受新事务时,它被推入第1阶段事务FIFO。检查阶段1 FIFO开头的事务的页面状态,并将其提供给阶段1事务FSM。FSM根据DRAM定时器决定是否需要发出预充电或激活命令,以及何时发出它们是安全的。当页面打开并且由于第2阶段FIFO中的未决RDA或WRA而尚未计划关闭时,事务从第1阶段FIFO转移到第2阶段。此时,阶段1 FIFO弹出,阶段1 FSM开始处理下一个事务。同时,第2阶段FSM在第2阶段FIFO的头部处理事务的CAS命令阶段。第2阶段FSM基于tRCD计时器在安全时发出CAS命令请求。第2阶段FSM还为RMW事务发出读写CAS请求。
ECC
MC支持可选的SECDED ECC方案,该方案检测并纠正每个DQ总线突发具有1位错误的读取数据错误,并检测每个突发的所有2位错误。不纠正2位错误。每个脉冲串可能检测到或可能检测不到三个或更多位错误,但永远不会被纠正。启用ECC将为所有读取增加四个DRAM时钟周期的延迟,无论是否检测到/纠正错误。当启用ECC时,还实现了读修改写(RMW)方案以支持部分写入。部分写入有一个或多个用户接口写入数据掩码位设置为高。禁用ECC的部分写入通过将数据掩码位发送到DRAM数据掩码(DM)引脚来处理,因此仅当启用ECC时才使用RMW流。启用ECC后,部分写入需要自己的命令wr_bytes或0x3,由此MC知道何时使用RMW流。
注意:启用ECC后,在执行部分写入(RMW)之前初始化(或写入)内存空间。
RMW(Read-Modify-Write)流程
当用户接口接收wr_bytes命令时,它最终会像其他写或读事务一样被分配给组状态机。组机器将部分写入分为读取阶段和写入阶段。
读取阶段执行以下操作:
1.首先从内存中读取数据。
2.检查读取数据中的错误。
3.纠正单位错误。
4.将结果存储在内存控制器中。
读取阶段的数据不会返回到用户接口。如果在读取数据中检测到错误,则在本地接口处使能ECC错误信号。在读数据存储在控制器中之后。
写阶段开始如下:
1.根据写数据掩码位将写数据与存储的读数据合并。
2.为合并的数据生成新的ECC校验位,并将校验位写入存储器。
3.当为合并数据生成新的校验位时,读取阶段中的任何多位错误导致错误在写入阶段中不可检测。这就是为什么即使数据没有返回到用户接口,ECC错误信号也会在读取阶段产生。这允许系统知道不可纠正的错误是否已转变为不可检测的错误。
当写入阶段完成时,组机器可用于处理新事务。与简单的读或写相比,RMW流占用组计算机的时间更长,因此可能会影响性能。
ECC模块
ECC模块在DDR3/DDR4内存控制器内实例化。它由五个子模块组成,如下图所示。
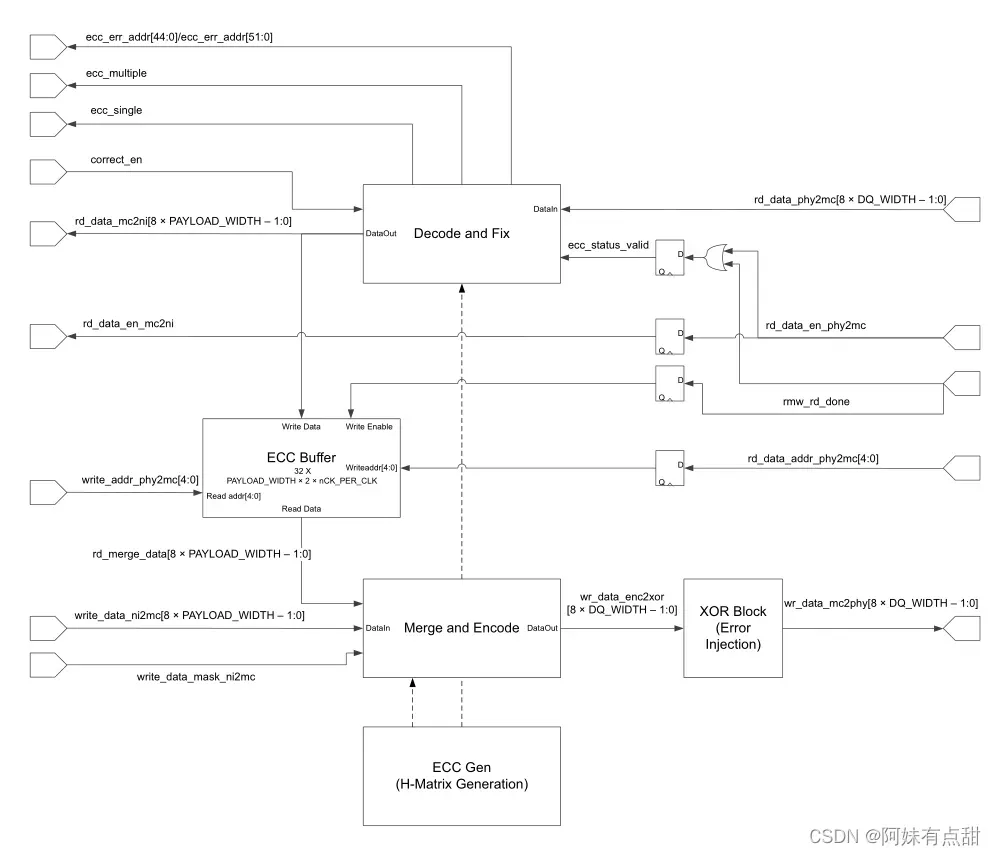
来自PHY的读取数据和校验位被发送到解码块,在下一个系统时钟周期,数据和错误指示符ecc_ingle/ecc_multiple被发送到NI。ecc_single在检测到可纠正错误并且读取的数据已被纠正时使能。当检测到不可纠正的错误时,ecc_multiple使能。
在不可纠正错误时,ECC逻辑不会修改读取数据。“周期性读取”从不使能错误指示符,这是控制器仅为VT跟踪目的而生成的读取事务,不会返回到用户界面或在RMW流中写回内存。写入数据在编码块中与存储在ECC缓冲器中的读取数据合并。合并由写入数据掩码信号以每字节为基础进行控制。所有写操作都使用此流,因此需要完全写操作才能取消所有数据掩码位的断言,以防止意外合并。在合并阶段之后,编码块生成写入数据的校验位。数据和校验位以一个系统时钟周期延迟从编码块输出。ECC Gen块实现生成用于ECC校验位生成和错误检查/校正的H矩阵的算法。生成的代码仅取决于PAYLOAD_WIDTH和DQ_WIDTH参数,其中DQ_WIDTH=PAYLOAD_WIDTH+ECC_WIDTH。目前仅支持DQ_WIDTH=72和ECC_WIDTH=8。
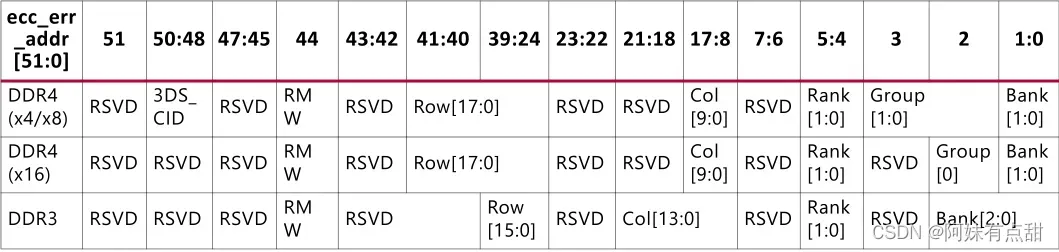
ERROR地址
每次发出读取CAS命令时,完整的DRAM地址都存储在解码块的FIFO中。当返回读取数据并检查错误时,DRAM地址从FIFO中弹出,ecc_err_addr[51:0]在与信号ecc_single和ecc_multiple相同的周期内返回,用于错误记录或调试。下图是DDR3和DDR4的通用地址定义。
时延
当参数ECC为ON时,ECC模块被实例化,通过MC的读写数据延迟增加一个系统时钟周期。当ECC关闭时,数据总线仅通过MC,所有ECC逻辑都应优化。
ECC端口描述
下图表示了DDR3和DDR4在UI接口中的端口描述


地址奇偶校验
在芯片选择断言低之后,存储器控制器产生具有一个DRAM时钟延迟的偶数命令/地址奇偶校验。此信号仅用于DIMM RCD组件需要奇偶校验的DDR4 RDIMM配置。只有DDR4 RDIMM和LRDIMM配置(包括3DS RDIMM和LR DIMM)支持地址奇偶校验。内存控制器不监控RDIMM/LRDIMM输出的Alert_n奇偶校验错误状态,并且在奇偶校验错误后,它可能会将损坏的数据返回到用户界面。要检测此问题,您需要在设计中添加一个引脚,以监视Alert_n信号。如果检测到Alert_n事件,则应认为内存内容已损坏。要从奇偶校验错误中恢复,必须重置内存控制器,并丢失所有DRAM内容。
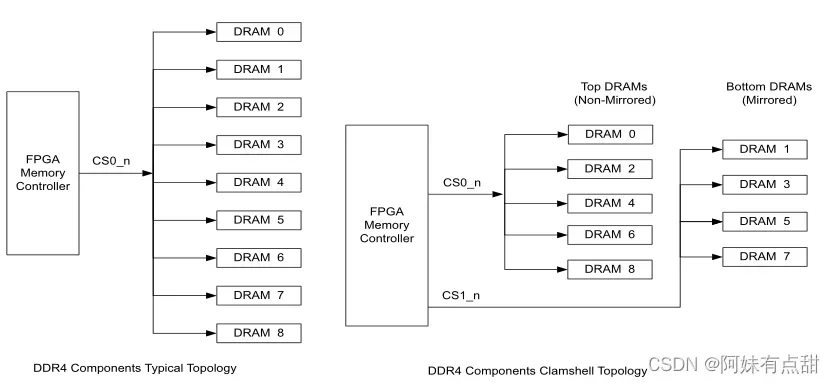
Clamshell 拓扑
控制器中的DDR4控制器/PHY模式选项支持此功能,用户界面、AXI界面和仅物理层界面的物理层下拉列表支持此功能。Clamshell拓扑支持物理层Ping Pong接口。注意:此功能仅支持DDR4单级组件。Clamshell拓扑通过将其放置在板的两侧(顶部和底部)来模拟多级RDIMM的地址镜像概念,从而节省了组件面积。地址镜像提高了地址和控制端口的信号完整性,并使PCB布线更容易。Clamshell功能在基本选项卡中可用,如下图所示。
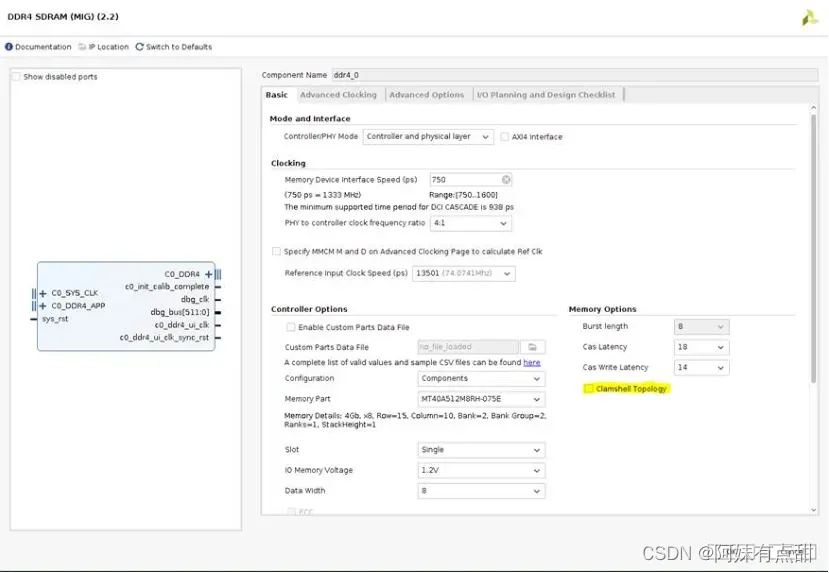
组件分为两类,即非镜像和镜像。一个附加的芯片选择信号被添加到镜像组件的设计中。下图显示了常规组件拓扑和Clamshell拓扑之间的区别,Clamshell设计的CS0_n驱动非镜像组件,而CS1_n驱动镜像组件。
迁移功能
控制器中的DDR4控制器/PHY模式选项支持此功能,用户接口、AXI接口和仅物理层接口的物理层支持此功能。
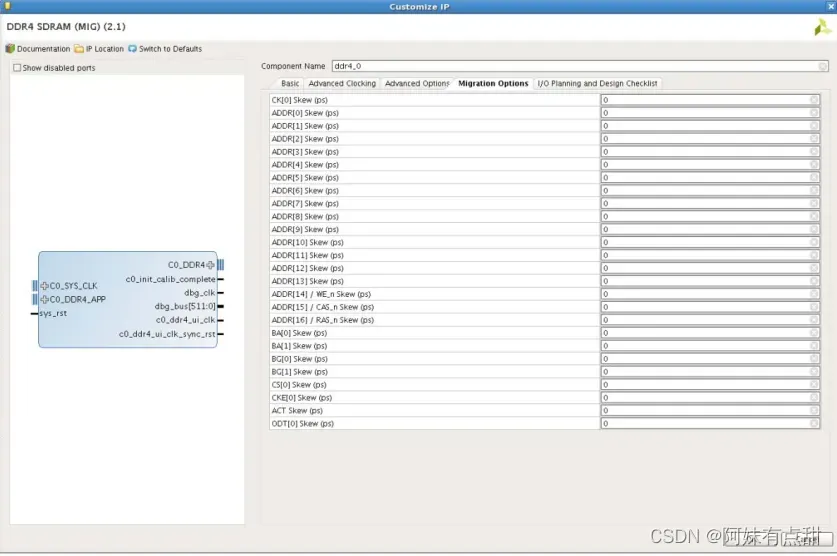
迁移不支持物理层Ping Pong接口。当将设计从现有FPGA包迁移到另一个兼容封装时,此功能非常有用。它还支持UltraScale和UltraScale+系列内部和跨系列的插针兼容软件封装。迁移选项补偿目标设备上所有地址/命令信号的封装偏移,以保持源设备的相位关系不变。由于这些信号没有校准,因此只需要地址/命令总线。数据总线(DQ和DQS)偏移不需要补偿,因为它是在常规校准序列期间完成的。该工具仅支持0到75 ps的相位差。
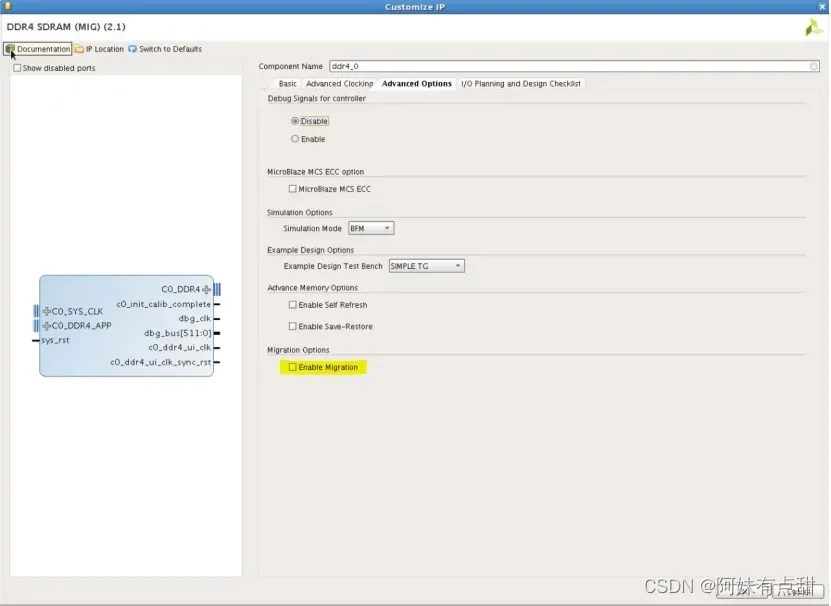
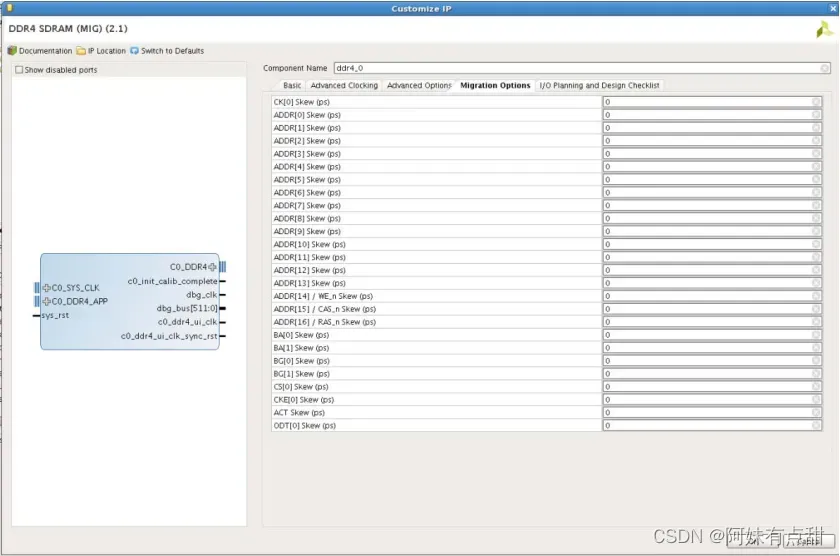
选择Enable Migration(启用迁移)后,将显示迁移选项选项卡,如图3-18所示。它包含所有地址和命令信号的条目,以输入相应引脚上的偏移值。具体的偏移值如何赋值,可以查看UG583。所有条目均以皮秒(ps)为单位:
MicroBlaze MCS ECC
MicroBlaze MCS本地存储器提供了启用纠错码(ECC)的选项。纠错纠正单位错误并检测双位错误。添加两个附加端口以指示单比特错误(LMB_CE)和双比特错误(LSB_UE)。MicroBlaze MCS ECC可从“高级选项”选项卡中的MicroBlaze MCS-ECC选项部分选择。如果选择了MicroBlaze MC的ECC选项,则块RAM大小会增加。
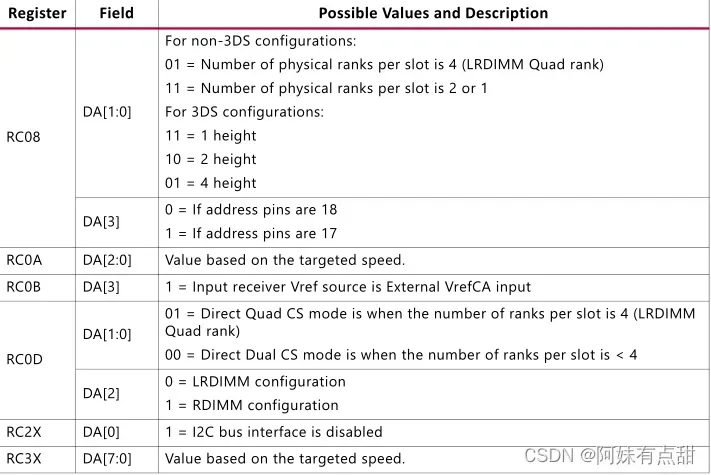
Memory 设置
DDR4寄存器模块的设置在下表中捕获。除非表中另有规定,否则寄存器内容编程为默认值0:

内核设计
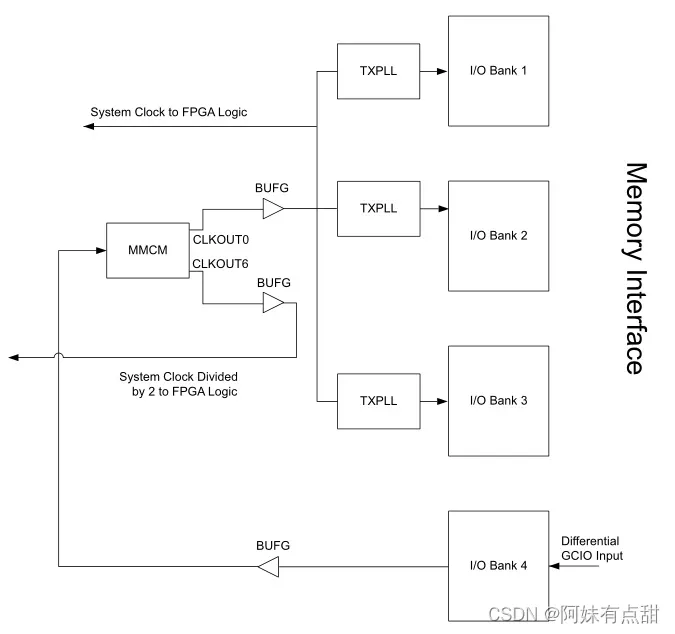
时钟
存储器接口需要一个混合模式时钟管理器(MMCM)、存储器接口使用的每个I/O组一个TXPLL和两个BUFG。这些时钟部件用于创建存储器接口正确操作所需的适当时钟频率和相移。每个Bank有两个TXPLL。如果一个Bank由两个存储器接口共享,则使用该Bank中的两个TXPLL。DDR3/DDR4 SDRAM工具为所需接口生成适当的时钟结构。不得修改此结构。允许的时钟配置如下:
1、连接到GCIO的差分参考时钟源;
2、GCIO到MMCM(位于内存接口的中央库中);
3、MMCM到BUFG(位于存储器接口的中央组)驱动FPGA逻辑和所有TXPLL;
4、接口的时钟对必须位于堆叠硅互连(SSI)技术设备的存储器接口的同一SLR中;
下图显示出了三Bank存储器接口的时钟结构的示例。GCIO驱动位于内存接口中央库的MMCM。MMCM驱动位于同一存储体中的两个BUFG。BUFG(用于向FPGA逻辑生成系统时钟)输出驱动接口的每个存储体中使用的TXPLL。
复位
提供了异步复位(sys_rst)输入,这是一个有效的高复位,sys_rst必须声明最小脉冲宽度为5ns,sys_rst可以是外部引脚也可以是内部引脚。注意:如果两个控制器共享一个Bank,则不能单独复位,两个控制器必须有一个公共的复位输入。
协议描述
APP接口
APP接口信号的描述如下图所示:
信号app_addr[APP_ADDR_WIDTH – 1:0]
此信号指示当前提交到用户接口的请求的地址。用户接口聚合外部SDRAM的所有地址字段,并呈现平坦的地址空间。MEM_ADDR_ORDER参数确定app_ADDR如何映射到SDRAM地址总线和芯片选择引脚。此映射可能会对内存带宽利用率产生重大影响。“ROW_COLUMN_BANK”是推荐的MEM_ADDR_ORDER设置。下图通过示例显示了DDR4的“ROW_COLUMN_BANK”映射。注意,app_addr的三个LSB映射到对应于SDRAM突发排序的列地址LSB。控制器不支持突发排序,因此这些低阶位被忽略,使得有效的最小app_addr步长为十六进制8。

下图为DDR4的“BANK_ROW_COLUMN”映射:

下图为DDR4的“ROW_BANK_COLUMN”映射:


注意:“+:”符号表示索引向量部件选择。例如,对于给定的输入信号input[511:0]app_addr;app_addr[255+:64]表示考虑app_addr的[255+64-1:255]。下图为DDR4 4GB(512MB X8)单Rank映射示例:

信号app_cmd[2:0]
此输入指定当前提交给用户接口的请求的命令。可用命令如下表所示。如果启用了ECC,则使用任何非零app_wdf_mask位进行写入都需要wr_bytes操作。这个wr_bytes在控制器中触发一个读-修改-写流,这仅在ECC模式下使用掩码数据进行写入时才需要。

信号app_autoprecharge
此输入指定当前提交到用户接口的请求的DRAM CAS命令的A10自动充值位的状态。当此输入为低时,内存控制器发出DRAM RD或WR CAS命令。当此输入为高时,控制器发出DRAM RDA或WRA CAS命令。该输入提供每个请求的控制,但也可以绑定以静态地配置控制器以进行打开或关闭页面模式操作。存储器控制器还具有自动确定何时发出自动预充电的选项,此选项禁用app_autoprecharge输入。
信号app_en
该输入在请求中使能。将所需的值应用于app_addr[]、app_cmd[2:0]和app_hi_pri,然后使能app_en以向用户接口提交请求。这将启动用户接口通过使能app_rdy确认的握手。
信号app_wdf_data[APP_DATA_WIDTH – 1:0]
该总线提供当前写入外部存储器的数据。当ECC被禁用(ECC参数值为OFF)时,APP_DATA_WIDTH为2×nCK_PER_CLK×DQ_WIDTH;当ECC被启用(ECC参数为ON)时,为2×nCK_PER_CLK×(DQ_WIDTH–ECC_WIDTH)。PAYLOAD_WIDTH指示用户接口数据已在其上传输的有效DQ_WIDTH。禁用ECC(ECC参数值为OFF)时,PAYLOAD_WIDTH为DQ_WIDTH。启用ECC(ECC参数为ON)时,PAYLOAD_WIDTH为(DQ_WIDTH–ECC_WIDTH)。
信号app_wdf_end
该输入指示当前周期中app_wdf_data[]总线上的数据是当前请求的最后一个数据。
信号app_wdf_mask[APP_MASK_WIDTH – 1:0]
该总线指示app_wdf_data[]的哪些位被写入外部存储器,哪些位保持在其当前状态。APP_MASK_WIDTH是APP_DATA_WIDTH/8。
信号app_wdf_wren
此输入表示app_wdf_data[]总线上的数据有效。
信号app_rdy
此输出指示当前提交给用户接口的请求是否被接受。如果在app_en被使能之后用户界面没有使能该信号,则必须重试当前请求。如果出现以下情形,app_rdy输出不会被使能。
-PHY/Memory初始化尚未完成
-所有控制器组FSM都被占用(可以视为命令缓冲区已满)。
-请求读取并且读取缓冲区已满。
-请求写入,但没有可用的写入缓冲区指针。
-正在插入定期读取。
信号app_rd_data[APP_DATA_WIDTH – 1:0]
此输出包含从外部存储器读取的数据。
信号app_rd_data_end
此输出指示当前周期中app_rd_data[]总线上的数据是当前请求的最后一个数据。
信号app_rd_data_valid
此输出表示app_rd_data[]总线上的数据有效。
信号app_wdf_rdy
该输出指示写入数据FIFO已准备好接收数据。当app_wdf_rdy和app_wdf_wren都被使能时,写入数据被接收。
信号app_ref_req
当被使能时,该信号高输入时请求存储器控制器向DRAM发送刷新命令。它必须维持一个脉冲周期才能发出请求,然后至少在app_ref_ack信号被使能以确认该请求并指示其已被发送之前取消使能。
信号app_ref_ack
当被使能时,该信号高输入确认刷新请求,并指示命令已从存储器控制器发送到PHY。
信号app_zq_req
当被使能时,该信号高输入请求存储器控制器向DRAM发送ZQ校准命令。它必须被脉冲化一个周期以发出请求,然后至少在app_zq_ack信号被使能以确认请求并指示其已被发送之前取消使能。
信号app_zq_ack
当被使能时,该信号高输入确认ZQ校准请求,并指示命令已从存储器控制器发送到PHY。
信号ui_clk_sync_rst
这是来自用户接口的重置,与ui_clk同步。
信号ui_clk
这是来自用户接口的输出时钟。它必须是输出到外部SDRAM的时钟频率的四分之一,这取决于Vivado IDE中选择的4:1模式。
信号init_calib_complete
校准完成时,PHY使能init_calib_complete。在向内存控制器发送命令之前,应用程序无需等待init_calib_complete。
命令路径
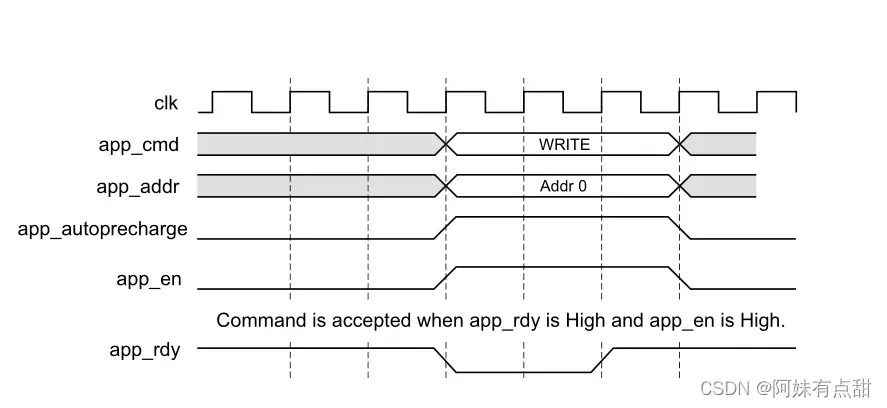
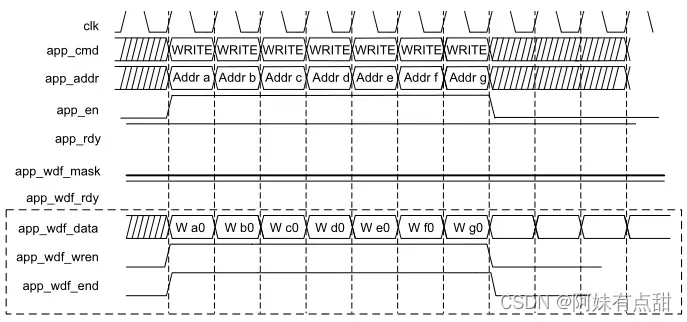
当用户逻辑app_en信号被使能并且app_rdy信号从用户接口被使能时,用户接口接受命令并将其写入FIFO。每当app_rdy被取消使能时,用户界面就会忽略该命令。用户逻辑需要将app_en与有效命令、预充电和地址值一起保持为高,直到app_rdy被使能,如下图中“write with autoprecharge”事务所示。
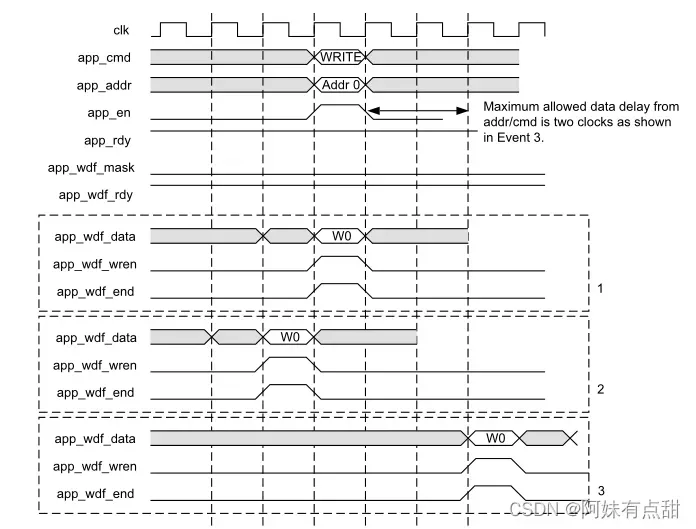
可以发出非背靠背写入命令,如下图所示。该图描述了app_wdf_data、app_wdf_wren和app_wdf_end信号的三种情况,如下所示:1.写入数据与相应的写入命令一起显示。2.在相应的写入命令之前呈现写入数据。3.写入数据在相应的写入命令之后呈现,但不应超过两个时钟周期的限制。
写入路径
当app_wdf_wren被使能且app_wdf_rdy为高时,写入数据被登记在写入FIFO中(下图)。如果app_wdf_rdy被取消使能,则用户逻辑需要保持app_wdf_wren和app_wdf_end 为高以及有效的app_wdf_data值,直到app_wdf_rdy被使能。app_wdf_mask信号可用于屏蔽要写入外部存储器的字节。
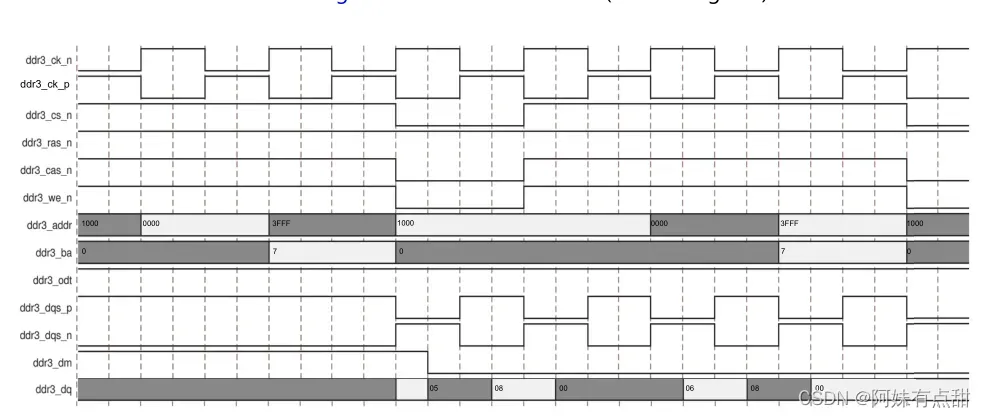
应用接口数据到DRAM输出数据的映射可以用示例来解释。对于具有8位内存的4:1内存控制器与DRAM时钟比率,在应用程序接口,如果驱动的64位数据为0000_0806_0000_0805(十六进制),则DRAM接口的数据如下图所示。这是针对BL8(突发长度8)事务的。
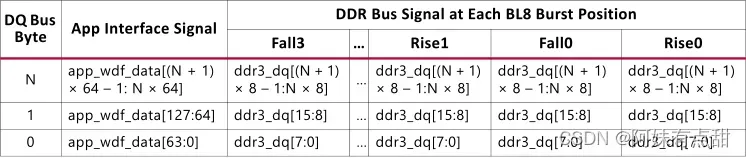
不同时钟边缘的数据值如下表所示:

下图显示了DRAM DQ总线数据如何连接以形成应用程序接口数据信号的通用表示。app_wdf_data如下图所示,但该表同样适用于app_rd_data。DQ总线的每个字节都有八个脉冲串,从Rise0(脉冲串0)到Fall3(脉冲串7),如之前在上图中所示,总共64个数据位。当与LSB位置中的Rise0和MSB位置中的Fall3级联时,形成app_wdf_data信号的64位块。
在这里讲到的是app接口的表示方式,其实这种方式同样适用于AXI接口,假设我的DQ总线位宽为64位,那IP核会自动设计AXI数据位宽为512位,此外IP核中PHY与Controller clock Speed的时钟比率为4:1,假设PHY这边的接口时钟信号(ck_c\ck_t)为1200MHz,再加上因为是DDR,所以在ck_c\ck_t的时钟沿都会传输数据,那么传输DQ数据的实际频率为2400MHz,而控制器这边的接口时钟ui_clock为300MHz,二者的比率为8:1,此外AXI数据总线的位宽为512,DQ数据位宽为64,正好也是8:1的关系,由此可得,由于IP核这两类接口时钟频率的不同,AXI数据分成了8次在DQ数据总线上传输,上表就讲述了这512位数据究竟是如何分8次传输的,当时我看了一会还是不大明白,我看完仿真波形,才逐渐懂得,我现在画张图大家就知道了,先记住一点,表中是以字节为单位进行所谓的“映射”的:
图中均是以16进制表示,将AXI数据总线的数据以16位16进制数据为一组,分为8组,DQ总线上第一次传输数据时,取每一组的低8位,也就是一个字节的数据,组成64位数据进行传输,第二次传输则是取次低8位进行传输。
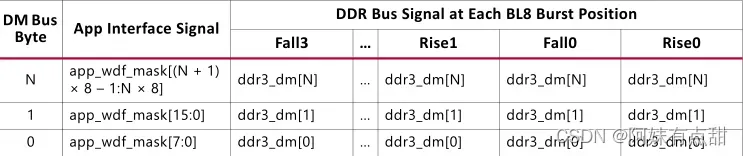
以与DQ总线映射类似的方式,DM总线通过以相同的突发顺序串联DM位映射到app_wdf_mask。DRAM总线的前两个字节的示例如下图所示,并给出了用于映射字节N的DM的公式。
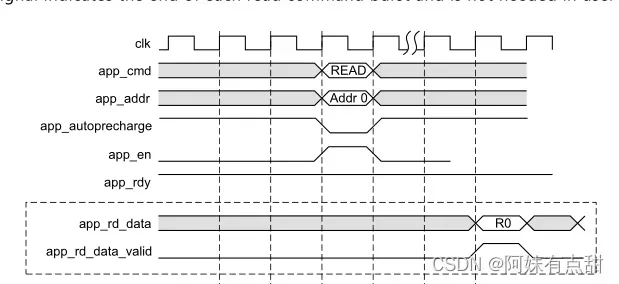
读取路径
读取的数据由用户接口按请求的顺序返回,并且在app_rd_data_valid被使能时有效。app_rd_data_end信号指示每个读命令脉冲串的结束,在用户逻辑中不需要。
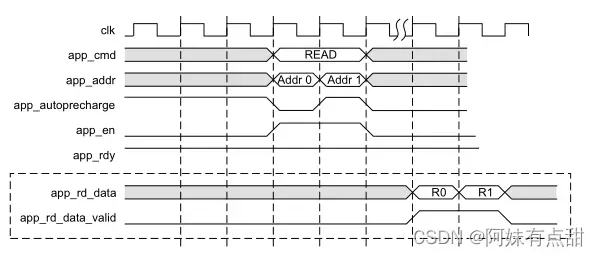
在上图中,返回的读取数据始终与地址/控制总线上的请求顺序相同。
维护命令
用户界面可由Vivado IDE配置为启用两种DRAM刷新模式。默认模式将UI和内存控制器配置为自动生成DRAM刷新和ZQCS命令,满足所有DRAM协议和时序要求。控制器定期中断正常的系统通信,以在DRAM总线上发出这些维护命令。
通过选中Vivado IDE中的Enable User Refresh(启用用户刷新)和ZQCS Input(ZQCS输入)选项,可以启用用户模式。在这种模式下,您负责在init_calib_complete信号为高电平之后,以DRAM组件规范所要求的速率发出Refresh和ZQCS命令。在UI上使用app_ref_req和app_zq_req信号来请求Refresh和ZQCS命令,并监视app_ref_ack和app_zq_ack以了解命令何时完成。控制器管理这些命令的所有DRAM定时和协议,而不是总刷新率或ZQCS速率,就像默认DRAM刷新模式一样。这些请求/确认端口独立于其他UI命令端口(如app_cmd和app_en)运行。相对于常规的读写事务,控制器可能无法保持呈现给UI的维护事务的确切顺序。当您请求刷新或ZQCS时,控制器会中断系统通信,就像在默认模式下一样,并插入维护命令。为了充分利用此模式,您应该在控制器空闲或至少不太忙时请求维护命令,记住不能违反DRAM刷新率和ZQCS速率要求。
下图显示了如何使用用户模式端口以及它们如何影响DRAM命令总线。此图显示了关于此操作模式的一般概念,但计时不准确。假设DRAM在所有Bank关闭的情况下处于空闲状态,在app_ref_req或app_zq_req在一个系统时钟周期内被使能为高之后的短时间内,控制器在DRAM命令总线上发出所请求的命令。app_ref_req和app_zq_req可以在相同的周期或不同的周期上使能,并且它们不必以相同的速率断言。在一个系统时钟的请求信号被使能为高之后,您必须保持其不使能,直到确认信号(ack)使能。
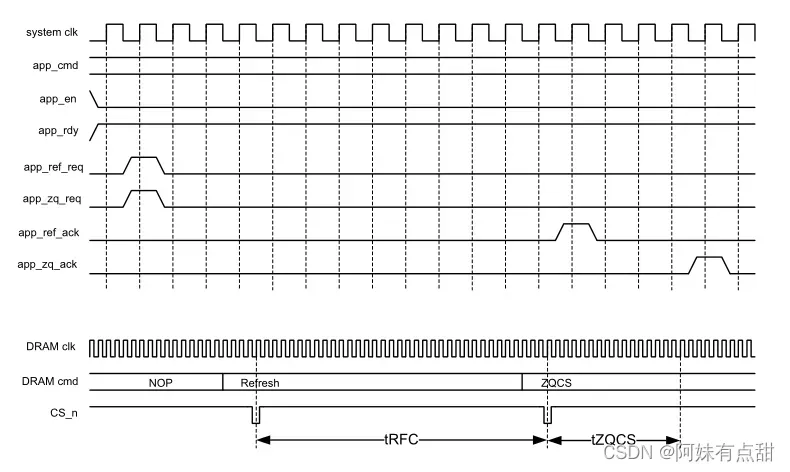
下图显示了当app_ref_req和app_zq_req被使能时,app_en被使能并且读取事务被连续呈现给UI的情况。控制器按照DRAM协议和时序要求中断DRAM流量,发出刷新和ZQCS,然后继续发出读取事务。请注意,app_rdy信号在此序列期间无效。由于在tRFC或tZQCS期间控制器命令队列很容易填满,因此很可能在这样的序列期间取消使能。在发出维护命令并恢复总线上的正常业务之后,app_rdy信号使能,新的事务再次被接受到控制器中。
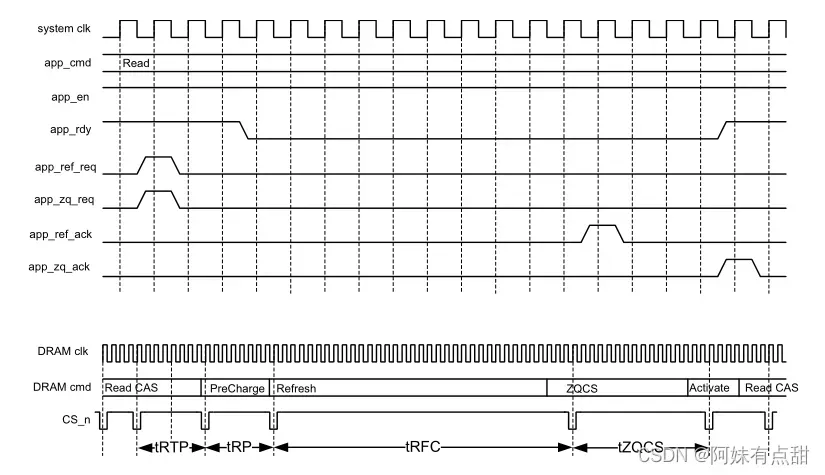
上图显示了单个Rank的操作。在多Rank系统中,一个刷新请求对每个Rank生成一个DRAM刷新命令,按tRFC/2交错排列。刷新命令是交错的,因为它们是相对高功耗的操作。ZQCS命令请求向所有列并行生成ZQCS指令。
AXI4 Slave接口
总体设计由单独的块组成,以处理每个AXI通道,这允许独立的读写事务。UI的读写命令依赖于一个简单的循环仲裁器来处理同时请求。地址读/地址写模块负责将AXI4 incr/wrap请求分割成四个或八个较小的内存大小突发长度,并将较小的突发长度传送给读/写数据模块,以便它们能够与用户界面交互。不支持固定突发类型。如果启用了ECC,所有启用了任何掩码位的写命令都将作为读-修改-写操作发出。此外,如果启用ECC,则所有未启用掩码位的写入命令都将作为写入操作发出。下面这张表则是列出了AXI4从属性接口参数:
AXI地址
AXI主机的AXI地址是TRUE字节地址。AXI垫片根据AXI SIZE和内存数据宽度将地址从AXI主机转换为内存。AXI字节地址的LSB被屏蔽为0,这取决于存储器阵列的数据宽度。如果内存阵列为64位(8字节)宽,AXI地址[2:0]将被忽略,并被视为0。如果内存阵列是16位(2字节)宽的,则AXI地址[0]将被忽略并被视为0。DDR3/DDR4 DRAM以DRAM突发块访问,此内存控制器始终使用固定的突发长度8。UI数据宽度始终是PAYLOAD_Width的八倍。下面这张图就是AXI字节地址的映射关系:

下表列出了AXI4从属接口特定信号。从存储器控制器向接口提供ui_clk和ui_clk_sync_rst。AXI接口与ui_clk同步。
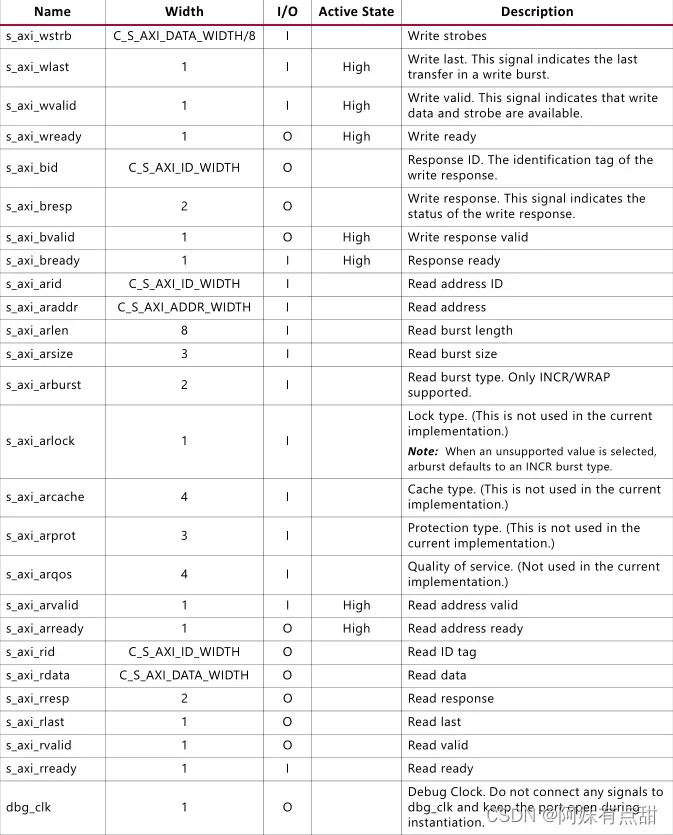
下面也是给出了相关示例:
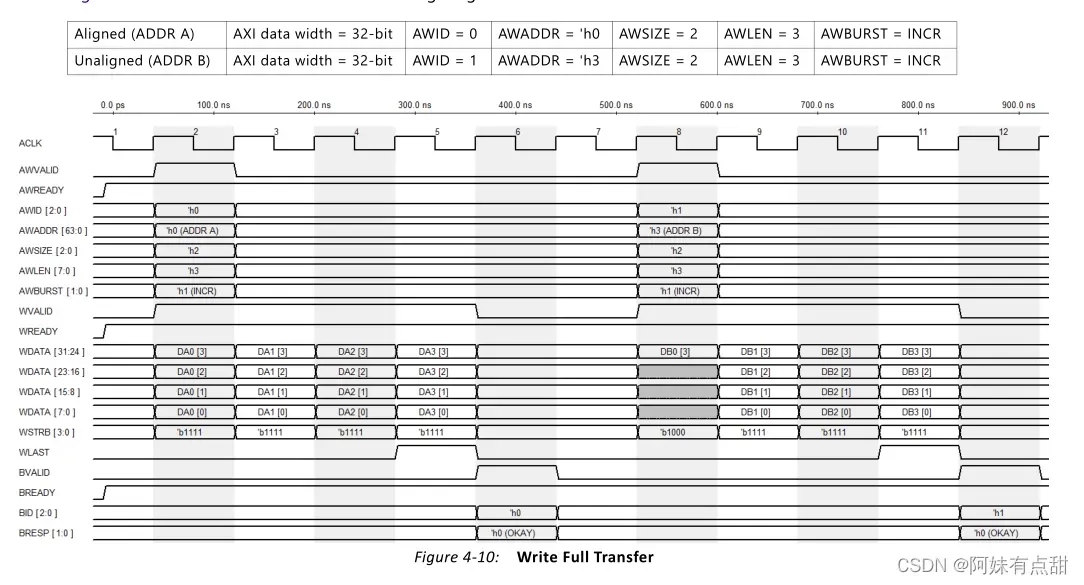
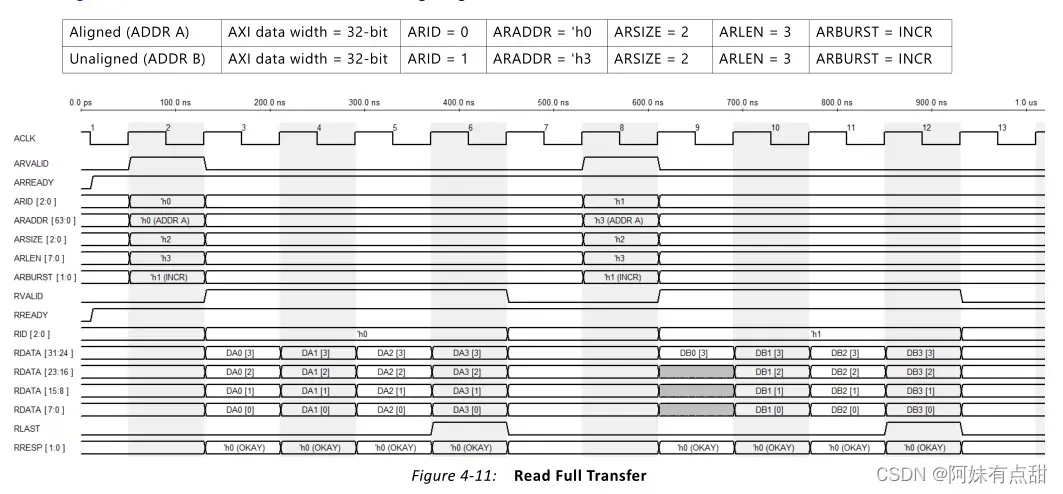

AXI4协议要求独立的读写地址通道。内存控制器有一个地址通道。以下仲裁选项可用于读取和写入地址通道之间的仲裁:
1、时分复用(TDM)
在此模式下,读取和写入地址通道具有同等优先级。对读和写地址通道的授权在每个时钟周期交替。AXI主机的读或写请求与授权无关。例如,即使在没有写请求的情况下,读请求也会以交替的时钟周期提供服务。插槽是固定的,它们只在各自的插槽中提供服务。
2、Round-Robin
在此模式下,读取和写入地址通道具有同等优先级。对读和写通道的授权取决于从AXI主机授权的最后一个服务请求。例如,如果上一次执行的操作是写操作,那么它将为读操作提供优先于写操作的服务。类似地,如果最后执行的操作是读取的,那么它会优先于读取操作提供写入操作。
3、读取优先级(RD_PRI_REG)
在此模式下,读取和写入地址通道具有同等优先级。当发生以下情况之一时,将处理来自写地址通道的请求:没有来自读地址通道的未决请求;达到256读取饥饿限制,仅在突发结束时检查;达到读取等待限制16。以类似的方法处理来自读地址通道的请求。
4、读取优先级(带饥饿限制)(RD_PRI_REG_Starve_Limit)
在这种模式下,读取地址通道总是被赋予优先权。当没有来自读地址通道的未决请求或达到读取的饥饿限制时,处理来自写地址通道的请求。
5、写入优先级(Write_Priority、Write_PORIORITY_REG)
在此模式下,写入地址通道始终具有优先级。当没有来自写地址通道的未决请求时,处理来自读地址通道的请求。仲裁输出以WRITE_PRIORITY_REG模式注册。
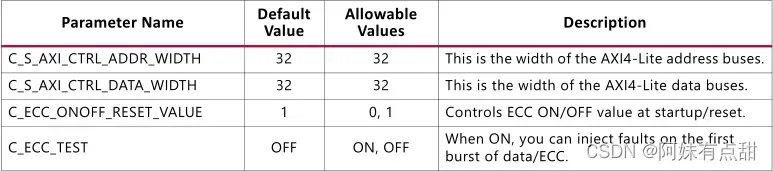
AXI4 Lite从属控制/状态寄存器接口块
AXI4 Lite从属控制寄存器块为ECC存储器选项提供处理器可访问的接口。当启用ECC且主从接口为AXI4时,该接口可用。该块提供中断、中断启用、ECC状态、ECC启用/禁用、ECC可纠正错误计数器、第一个故障可纠正/不可纠正数据、ECC和地址。当ECC_TEST_FI_XOR(C_ECC_TEST)参数为ON时,提供用于软件测试的故障注入寄存器。AXI4 Lite接口固定在32个数据位,信令遵循标准AMBA AXI4 Lite规范。
AXI4 Lite控制/状态寄存器接口块与AXI4内存映射接口并行实现。该块监视本地接口的输出,以捕获可纠正(单位)和不可纠正(多位)错误。当发生可纠正和/或不可纠正错误时,接口还捕获故障的字节地址以及故障数据位和ECC位。错误注入是在ECC编码发生后由放置在写入数据路径中的XOR块提供的。
只有事务中的第一个内存节拍才能插入错误。例如,在数据宽度为72且模式寄存器设置为突发长度8的存储器配置中,只有前72位可通过故障注入接口损坏。基于可纠正或不可纠正错误的中断生成可通过寄存器接口独立配置。如果出现不可纠正的错误(如果启用了ECC),则在读取响应总线(rresp)上看到SLVERR响应。
下表列出了AXI4 Lite从属机接口参数:
下表列出了AXI4从属接口特定信号。接口时钟/复位由内存控制器提供:
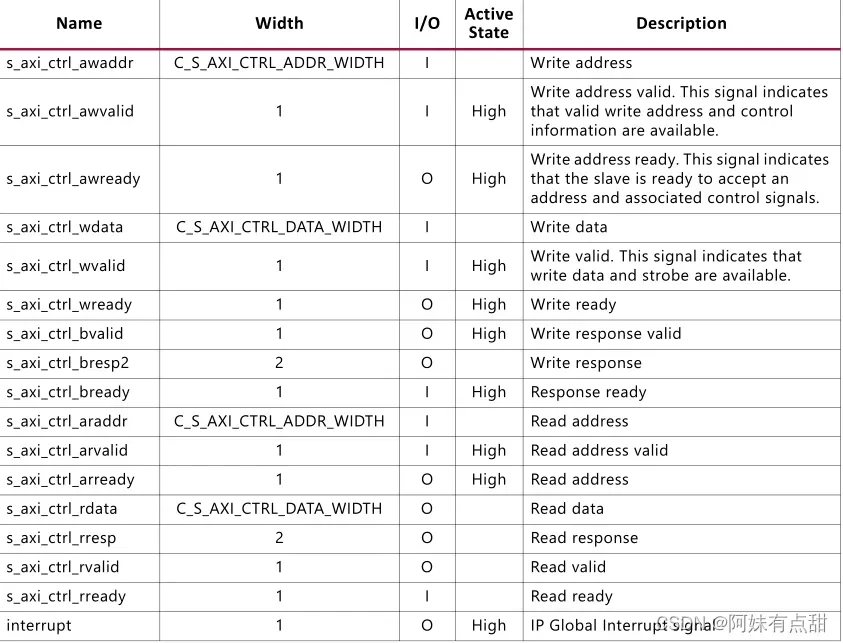
ECC寄存器映射如下表所示。寄存器映射为Little Endian。忽略对只读或保留值的写入访问。对只读或保留值的读取访问返回值0xDEADEAD。
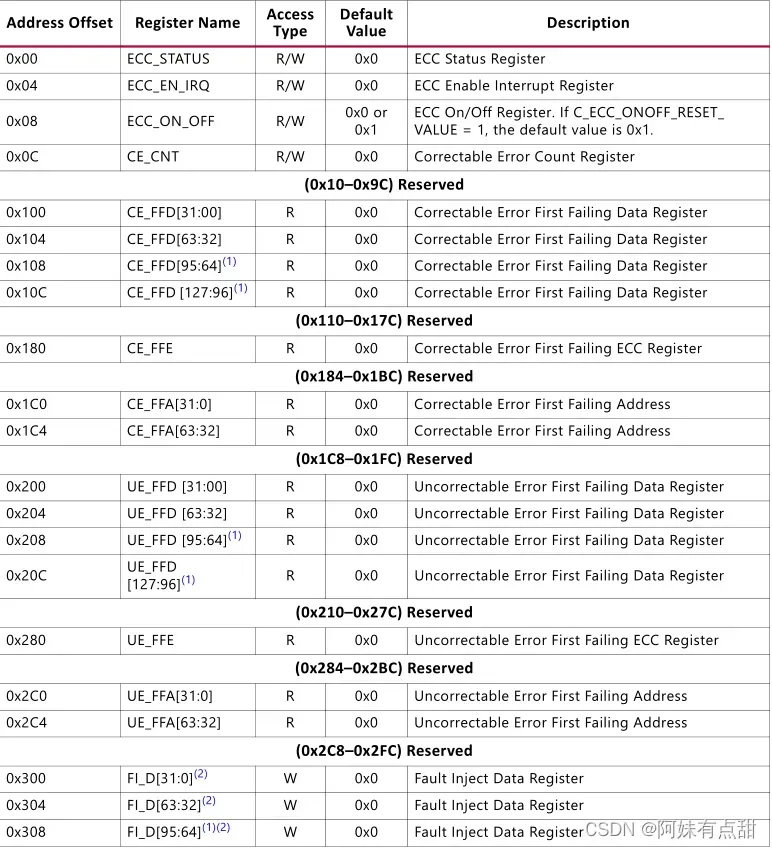

注意:当要生成AXI4 Lite从属控制/状态寄存器接口块时,必须在IP输出产品中手动将ECC_TEST参数设置为ON。
关于ECC相关寄存器可以查看Xilinx官方文档PG150的148页至158页,在这里不多叙述。
性能体现
存储器系统的效率受到许多因素的影响,包括由于存储器的限制,例如单个存储体内的循环时间(tRC)或到相同DDR4存储体组的激活到激活间隔(tRRD_L)。当给定要处理的多个事务时,存储器控制器将命令调度到DRAM,以尽量减少这些DRAM定时要求的影响。但由于内存控制器架构本身,也存在一些限制。本节介绍了关键控制器的限制和用于获得控制器最佳性能的选项。
地址映射
IP核设置界面中描述了DRAM地址映射的app_addr。其中包括六个映射选项:
1、ROW_COLUMN_BANK
2、ROW_ BANK_COLUMN
3、Bank_Row_COLUMN
4、ROW_COLUMN_LRANK_BANK
5、ROW_LRANK_COLUMN_BANK
6、ROW_COLUMN_BANK_INTLV
对于用户接口上的纯随机地址流,所有选项都会产生类似的效率。对于连续的app_addr地址流,或任何在app_addl内存空间中具有较小跨度的工作负载,ROW_COLUMN_BANK映射通常提供更好的总体效率。这是由于内存控制器架构和组FSM之间的事务交织。即使在DRAM定时不限制效率的情况下,也应考虑控制器架构对效率的影响。下表显示了4 Gb(x8)DRAM组件的两个映射选项。
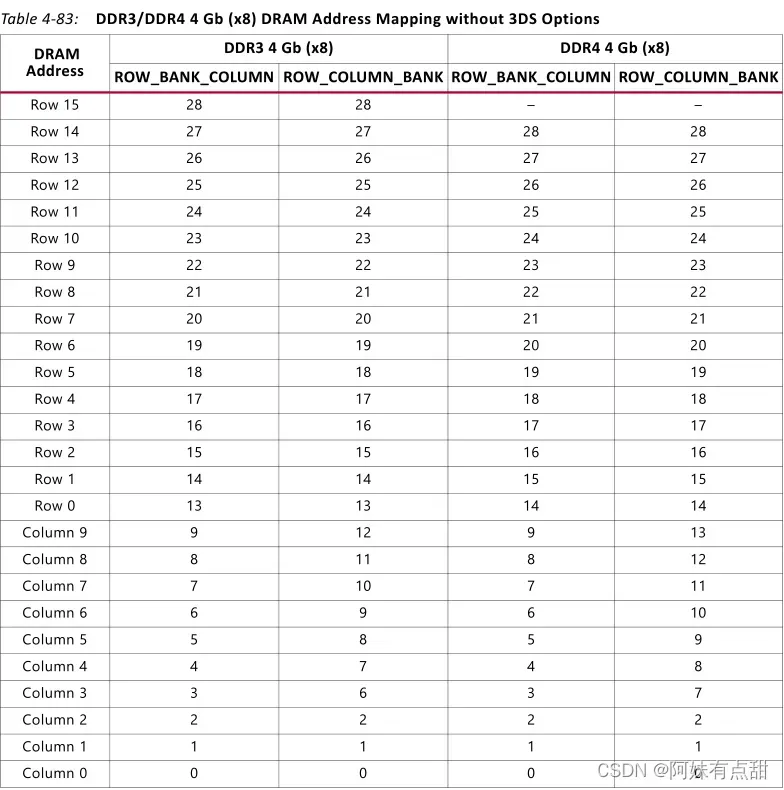

表中黑框框选的位是用来映射到控制器中组FSMs的地址。关于这张表格该怎样理解,可以看看上面关于信号app_addr[APP_ADDR_WIDTH – 1:0]这一节的内容,那个示例刚好与这对应。
从DDR3映射中,您可能会期望使用具有简单地址增量模式的ROW_BANK_COLUMN选项获得合理的效率。增量模式将生成对单个Bank的页面点击,DDR3可以将其作为背靠背CAS命令流进行处理,从而提高效率。从下表还可以看出,地址增量模式还将长的页面命中流映射到同一控制器组FSM。例如,下面的示例显示了前12个app_addr地址如何解码到DRAM地址并映射到两个映射选项的组FSM。ROW_BANK_COLUMN选项仅映射到此地址范围内的组FSM 0。
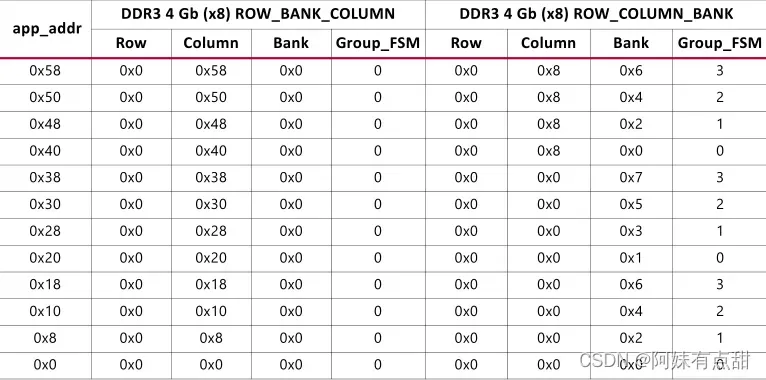
DIMM配置
DDR3/DDR4 SDRAM内存接口支持多插槽配置中的UDIMM、RDIMM、LRDIMM和SODIMM。在以下配置中,不使用空插槽,可以选择在板上实现。
DDR3/DDR4 UDIMM/SODIMM
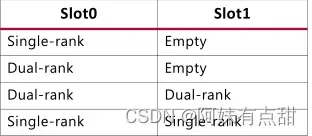
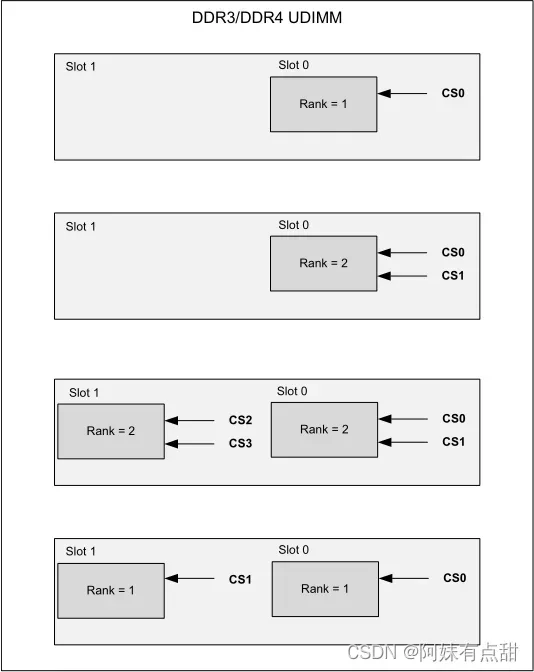
下面的图和表显示了DDR3\DDR4 UDIMM\SODIMM支持的四种配置。对于双列DIMM、双插槽配置,请遵循下图所示的芯片选择顺序,其中CS0和CS1连接到插槽0,CS2和CS3连接到插槽1。
DDR4 RDIMM
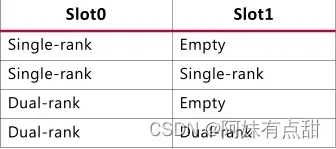
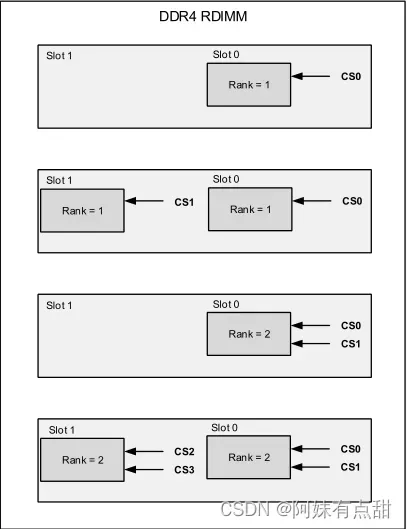
下面的表和图显示了DDR4 RDIMM支持的四种配置。对于双列DIMM、双插槽配置,请遵循下图所示的芯片选择顺序,其中CS0和CS1连接到插槽0,CS2和CS3连接到插槽1。
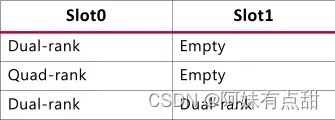
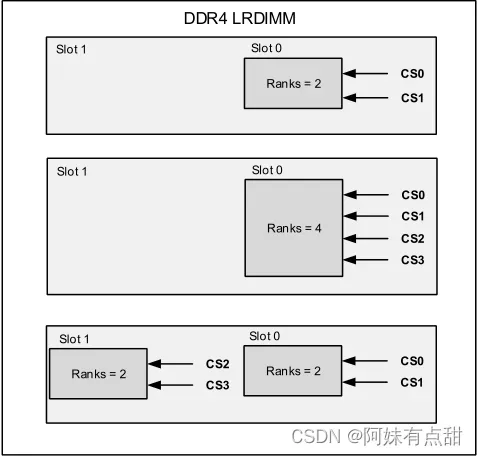
DDR4 LRDIMM
下面的表和图显示了DDR4 LRDIMM支持的三种配置。对于双插槽、双列配置,请遵循下图所示的芯片选择顺序,其中CS0和CS1连接到插槽0,CS2和CS3连接到插槽1。
IP核配置流程
本章描述了定制和生成核心、约束核心以及特定于此IP核心的模拟、合成和实现步骤。
自定义和生成核心
直接在IP Catalog里面搜索DDR4即可找到。
Basic Tab
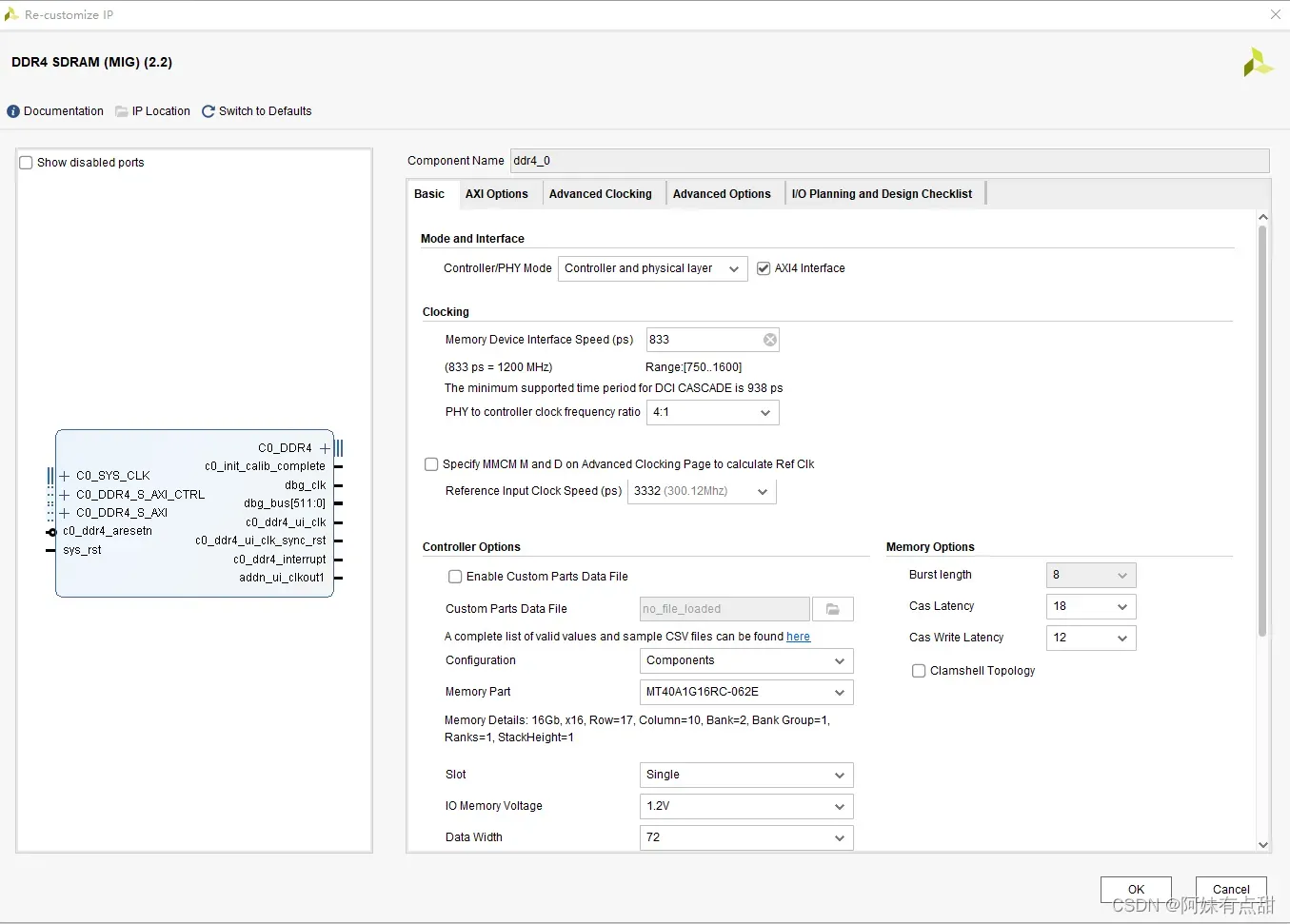
1、在下拉菜单里添加控制器后,选择控制器的模式和接口。选择AXI4接口或选择仅生成PHY组件。
2、选择时钟、控制器选项、内存选项和高级用户请求控制器选项中的设置。在“时钟”中,“内存设备接口速度”设置接口的速度。输入的速度驱动可用的参考输入时钟速度。在控制器选项中的Configuration这一栏中Components表示的是内存颗粒的意思,而下拉的其他选项表示内存条。
3、要使用默认情况下无法通过DDR3/DDR4 SDRAM Vivado IDE使用的内存部件,您可以按照AR:63462中的规定创建自定义部件CSV文件。必须在启用自定义部件数据文件选项后提供该CSV文件。选择此选项后。您可以看到自定义内存部件以及默认内存部件。请注意,自定义零件不支持模拟。自定义零件仿真需要手动将内存模型添加到仿真中,并且可能需要修改测试台实例。
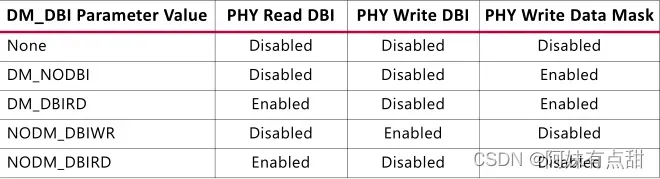
4、下表中描述了数据掩码和DBI的所有可用选项及其功能。启用写DBI时,将禁用数据掩码。DM_DBI参数仅配置PHY,还必须设置MRS参数以配置DM/DBI的DRAM。

此外,下表中提到了ECC对DM_DBI输入的依赖性,用于用户和AXI接口。
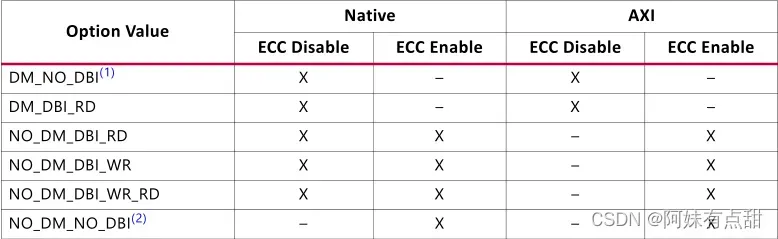
注意:上表中序号1表示ECC禁用接口的默认选项,序号2表示ECC使能接口的默认选项。
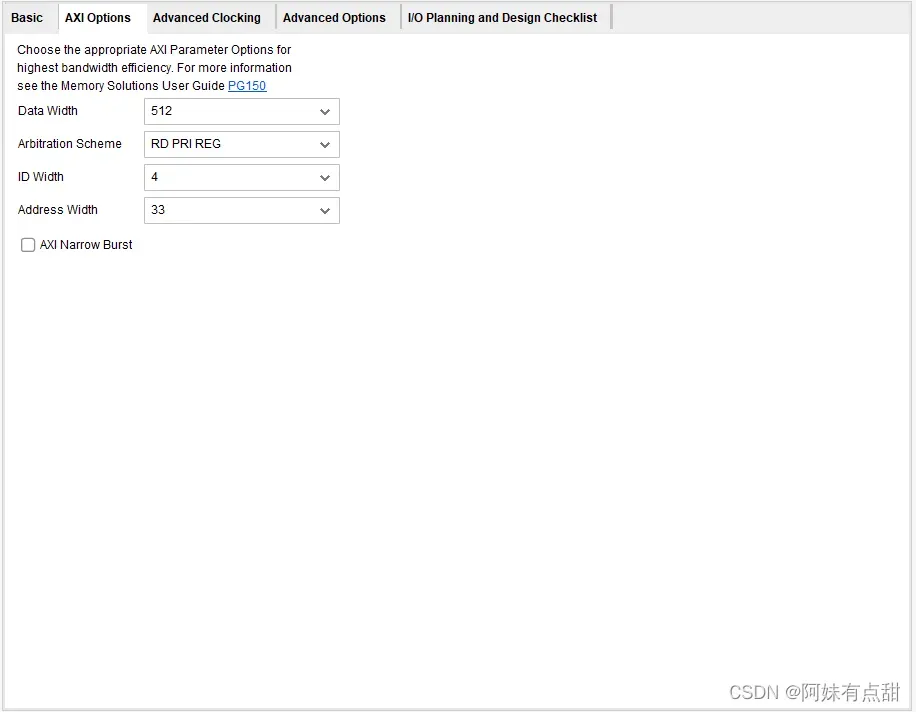
AXI Options Tab
若是在Basic界面中选择了AXI4 Interface选项,则会出现如下图所示的选项卡。
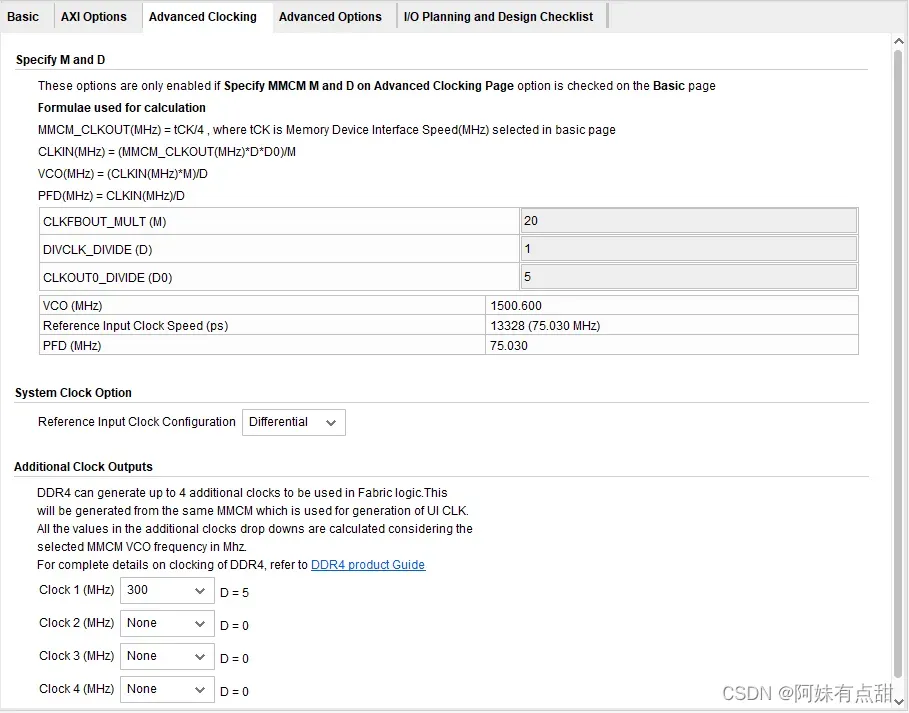
Advanced Clocking Tab
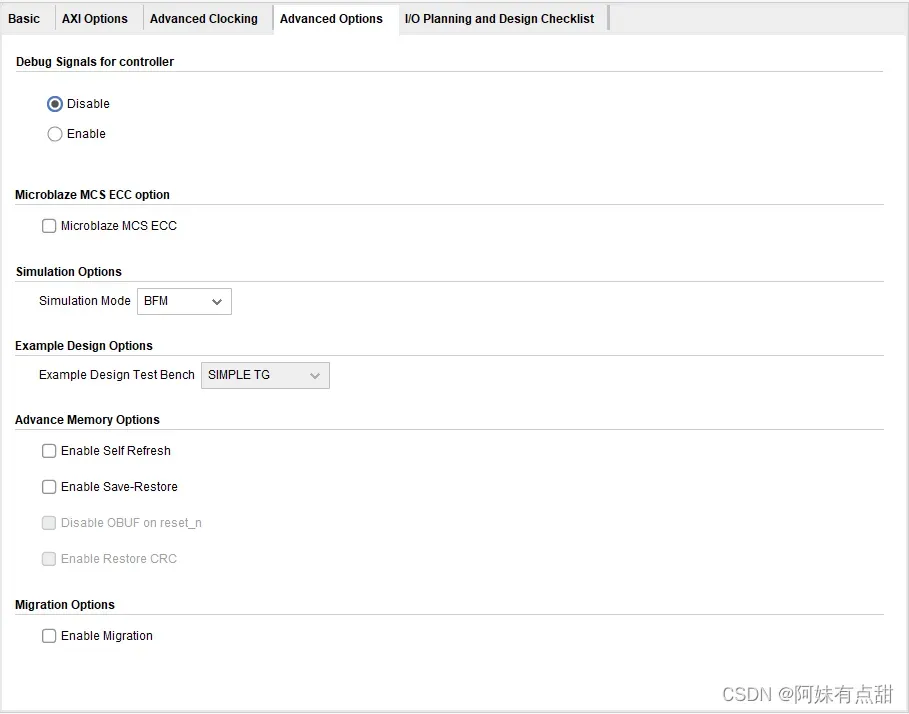
Advanced Options Tab
Migration Options Tab
下图显示了当在Advanced Options(高级选项)选项卡中选择Enable Migration(启用迁移)选项时,就会出现名为Migration Options(仅适用于DDR4)的下一个选项卡:
测试平台
打开该IP核的示例工程,由于其带有tb文件,因此可以直接进行仿真,测试台将您提供的命令和地址传递给内存控制器,并测量给定模式的效率。效率通过dq总线的占用率来衡量。测试台的主要用途是进行效率测量,因此不进行数据完整性检查。在写事务期间,静态数据被写入内存,相同的数据总是被读取。通过ddr3_v1_4_0_ddr3_stimulus向流量生成器提供刺激。txt文件。刺激包括命令、地址和命令重复计数。刺激文件中的每一行表示一个刺激(命令重复、地址和命令)。可以在一个刺激文件中提供多个刺激,并且每个刺激由新行分隔。
在仿真文件里可以看到以下文件:

激励模式
非3DS部分的刺激模式为48位,格式在下图中描述。
![]()
对于3DS部分,刺激模式为52位,在下图中描述。
![]()
非3DS和3DS部分激励模式描述在下图中显示。

命令编码(Command[3:0])

地址编码(Address[35:0]/Address[39:0])
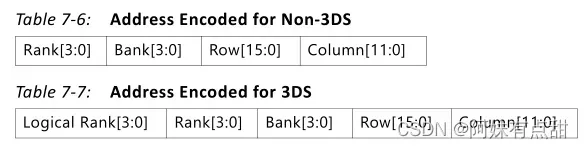
地址按照下图在激励中编码。所有地址字段都需要以十六进制格式输入。所有地址字段都是可被四整除的宽度,以十六进制格式输入。测试台只向存储器控制器发送地址字段的所需位。例如,只有八个Bank配置的Bank[2:0]被发送到存储器控制器,其余的比特被忽略。地址字段的额外位被提供用于以十六进制格式输入地址。您必须确认输入的值与给定配置的宽度相对应。
列地址(列[11:0])–激励中的列地址最多提供12位,但您需要根据设计中设置的列宽参数来解决此问题。
行地址(行[15:0])–激励中的行地址最多提供16位,但您需要根据设计中设置的行宽度参数来解决此问题
Bank地址(Bank[3:0])–l激励中的Bank 地址最多提供四位,但您需要根据设计中设置的银行宽度参数来解决此问题,注意:对于DDR4,使用2位LSB作为Bank地址,使用两位MSB作为Banlk Groups。
Rank地址(排名[3:0])–激励中的Rank地址最多提供四位,但您需要根据设计中设置的排名宽度参数来解决此问题。
逻辑Rank[3:0]–激励中的逻辑Rank最多为四位,这基于设计中设置的堆栈高度参数
地址是根据顶级MEM_ADDR_ORDER参数组装的,并发送到用户界面
命令重复(Command Repeat[7:0])
命令重复计数是在用户界面上重复相应命令的次数。每次重复的地址递增8。最大重复计数为128。测试台不检查列边界,如果在递增过程中达到最大列限制,则返回。128个命令填满了页面。对于除0以外的任何列地址,128的重复计数最终跨越列边界并环绕到列地址的开始。
参考文章:
Xiliinx官方文档PG150
什么是RDIMM和LRDIMM?
DDR中的ODT
DDR中bank,die,rank,channel的概念
DDR扫盲——DDR中的名词解析
FPGA ——DDR基础概念详解
(待优化修改)vivado DDR4 SDRAM(MIG)(2.2) IP核学习记录
DDR4读写测试(一):MIG IP核配置
DDR3基本概念1 – 存储单元结构和原理
DDR3基本概念2 – 上电复位时序
DDR3基本概念4 – 预充电和刷新,以及Lattice DDR3 SDRAM controller实战注意事项
【详解】SDRAM的地址映射方式BRC(Bank Row Column)和RBC(Row Bank Column)
DDR结构理解
深入浅出DDR系列(一)–DDR原理篇
深入浅出DDR系列(二)–DDR工作原理
美光提出3D内存封装标准“3DS” 或成DDR4基石
DDR4看这一篇就够了
文章出处登录后可见!