算法简介
DBSCAN(density-based spatial clustering of applications with noise),即“具有噪声的基于密度的空间聚类应用”。它的原理是识别特征空间的“拥挤”区域中的点,在这些区域中许多点靠在一起,这些区域称为特征空间中的密集区域。密集区域最终将有相对较空的区域分隔开。
在密集区域的点称为核心点,由DBSCAN的两个重要参数半径eps和最小采样点个数min_sample确定,其定义如下:如果在距一个给定数据点eps距离内至少有min_sample个数据点,那么这个数据点就是核心点。DBSCAN最终会将彼此距离小于eps的核心点分到同一簇中。
算法过程描述
首先任取一个点,找到这个点的距离小于等于eps的所有点,如果距起始点的距离在eps之内的数据点个数小于min_sample,那么这个点被标记为噪音点,也就是说它不属于任何簇。如果距离在eps之内的数据点个数大于min_sample,则这个点被标记为核心点,并分配一个新的簇标签。然后访问该点的所有eps以内的邻居,如果它们还没有被分配簇,那么就将刚才的簇标签分配给它们,如果它们也是核心点,那么继续依次访问其邻居,以此类推,否则即为边界点,不再访问其邻居。簇逐渐增大,直到簇的eps距离内没有更多的核心点为止。然后选取另一个尚未被访问的点,重复相同的过程。
最后,一共有三种类型的点:核心点、边界点、噪音点。如果DBSCAN算法在特定数据集运行多次,那么核心点的聚类始终相同,同样的点也始终被标记为噪音点。但边界点可能与不止一个簇的核心点相邻,这与数据点的访问顺序有关。一般情况下,边界点较少,因此这种歧义并不是很重要。
从上述描述中可以看到,DBSCAN算法不需要设置簇的个数,只需要确定两个参数eps、min_sample,实际上它们可以隐式地控制找到簇的个数。eps决定了点与点之间“接近”的含义,将eps设置过小,意味着没有核心点出现,可能导致所有点被标记为噪音点;eps设置过大,可能导致所有点形成单个簇。min_sample主要用于判断稀疏区域内点被标记为异常值还是形成自己的簇,决定了簇的最小尺寸。因此,两个参数的选取还是至关重要的。
注:采用缩放技术使数据特征具有相似的范围,有时会更便于找到eps较好的取值。
DBSCAN算法可视化展示

DBSCAN聚类算法在二维平面中对数据点进行聚类的简化过程如图所示,选取min_sample=2,此时图中蓝色为噪音点,不属于任何簇;红色为核心点,黄色为边界点,它们均划分在同一簇中。
国外有个网站,可以把DBSCAN的过程以动图展示出来,可以选择几种不同的数据集,还可以自行设置参数,很有趣.
DBSCAN可视化网站
算法实现
算法流程

算法实现
DBSCAN可在python中的sklearn库调用实现,以下给出两个简单实例对算法的聚类效果进行展示.
实例一:半圆形数据分簇
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
#将数据缩放成平均值为0、方差为1
scaler = StandardScaler()
scaler.fit(X)
X_scaled = scaler.transform(X)
dbscan = DBSCAN()
clusters = dbscan.fit_predict(X_scaled)
#绘制簇分配
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters, s=60)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
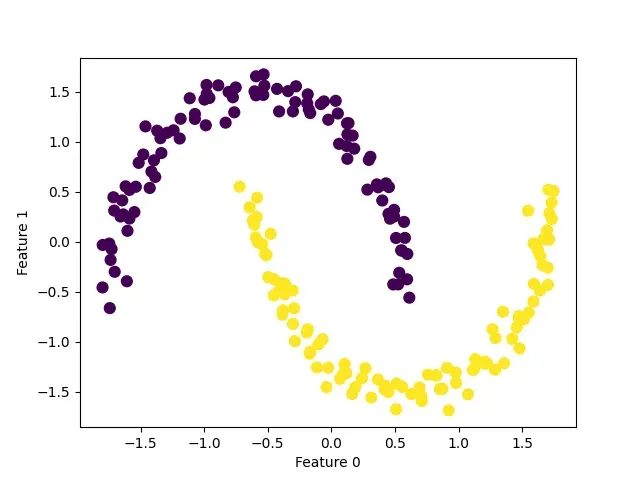
上图展示了在two_moons数据集上运行DBSCAN的结果,利用默认设置(eps=0.5),算法找到了两个半圆形并将其分开.由于算法得到了2个簇,默认参数的设置效果似乎很好,若eps=0.2,将会得到8个簇,显然太多了;若eps=0.7,则会导致只有1个簇.
实例二:品牌啤酒聚类分析
import pandas as pd
from matplotlib import colors
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
#导入数据
beer = pd.read_csv('beer.txt', sep=' ')
print(beer)#查看数据集
X = beer[['calories', 'sodium', 'alcohol', 'cost']]
#设置半径为10,最小样本量2
db = DBSCAN(eps=10, min_samples=2).fit(X)
labels = db.labels_
beer['cluster_db'] = labels #在数据集最后一列加上DBSCAN聚类后的结果
beer.sort_values('cluster_db')
print(beer)
#查看根据DBSCAN聚类后的分组统计结果(均值)
print(beer.groupby('cluster_db').mean())
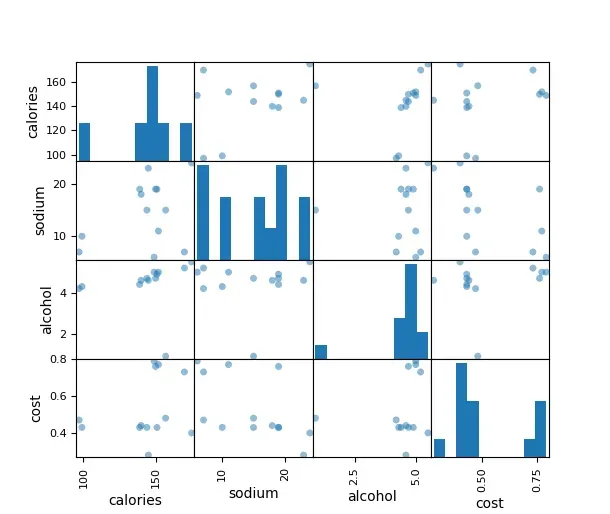
#画出在不同两个指标下样本的分布情况
print(pd.plotting.scatter_matrix(X, figsize=(10, 10), s=100))
plt.show()
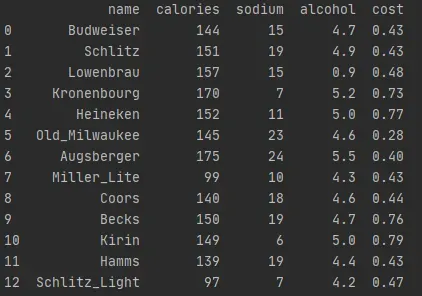
查看数据集:
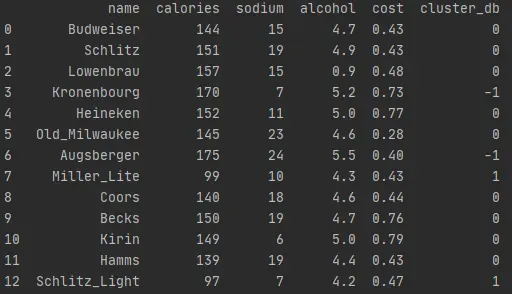
聚类结果:
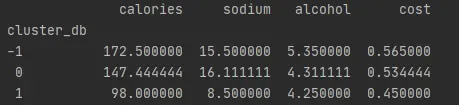
下表给出了聚类后分组的均值结果.
图中展示了在不同两个指标下样本的分布情况.
算法优缺点
优点
- 不需要先验地指定簇的个数;
- 可以处理任意形状大小的簇,且结果相对而言优于K均值聚类;
- 基于密度定义,对噪音不敏感,可检测出数据异常点.
缺点
- 高维数据有些困难;
- sklearn中效率较低
- 对于密度不均匀、距离相差较大的数据集,聚类结果较差;
- 调参较为复杂,需要多次尝试,不同的参数组合对最终结果影响较大.
算法改进:自适应的DBSCAN算法
由于DBSCAN算法对eps和min_sample两个参数十分敏感,参数的确定是既重要又困难的事情,有学者进行了自适应确定DBSCAN算法参数的研究,即通过数据集自动确定两个参数.相应论文可以在知网查阅.
李文杰, 闫世强, 蒋莹,等. 自适应确定DBSCAN算法参数的算法研究[J]. 计算机工程与应用, 2019, 55(05):1-7.
补充内容:MATLAB代码及测试实例
% DBSCAN聚类算法
% 算法流程:
% 1.首先选择一个待处理数据;
% 2.寻找和待处理数据距离在设定半径之内的数据;
% 3.将找到的半径内的数据放到一个队列中;
% 4.从队列头数据开始作为当前待处理数据并执行步骤2;
% 5.直至遍历队列中所有数据,将它们记为一类;
% 6.从未处理数据中选择一个作为待处理数据重复步骤2-5;
% 7.直至遍历完所有数据,算法结束.
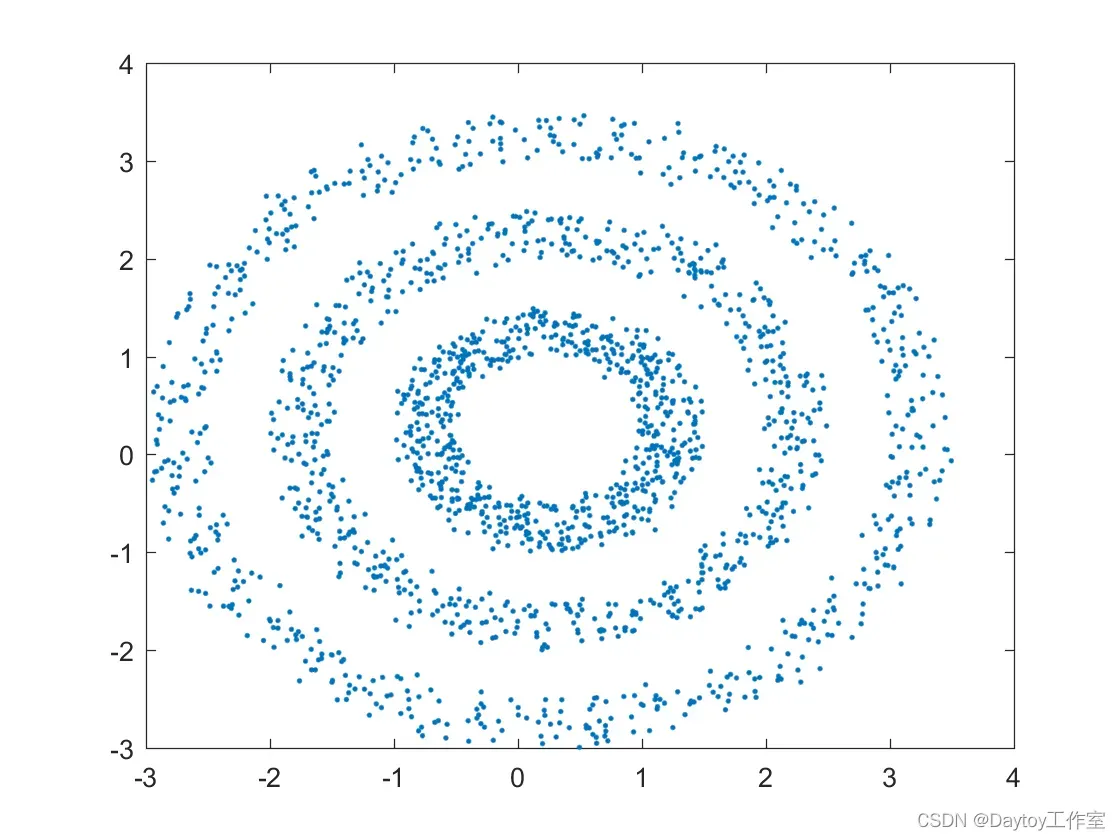
theta=0:0.01:2*pi;
p1=[3*cos(theta) + rand(1,length(theta))/2;3*sin(theta)+ rand(1,length(theta))/2]; %生成测试数据
p2=[2*cos(theta) + rand(1,length(theta))/2;2*sin(theta)+ rand(1,length(theta))/2];
p3=[cos(theta) + rand(1,length(theta))/2;sin(theta)+ rand(1,length(theta))/2];
p=[p1 p2 p3]';
randIndex = randperm(length(p))'; %打乱数据顺序
p=p(randIndex,:);
figure;
plot(p(:,1),p(:,2),'.')
flag = zeros(length(p),1); %聚类标记
clsnum = 0; %类的个数
disnear = 0.3; %聚类半径
for i=1:length(p)
nxtp=p(i,:); % 初始聚类半径内的邻域点队列
if flag(i)==0
clsnum=clsnum+1;
pcstart=1; % 设置队列起始指针
perflag=flag; % 聚类标记更新
while pcstart<=length(nxtp) % 判断队列是否完成遍历
curp=nxtp(pcstart,:); % 当前要处理的点
pcstart=pcstart+1;
diffp=p-repmat(curp,length(p),1);
distance=sqrt(diffp(:,1).*diffp(:,1)+diffp(:,2).*diffp(:,2)); % 判断当前点与所有数据点间的距离
ind=distance<disnear; % 得到距离小于阈值的索引
flag(ind)=clsnum; % 设置当前聚类标记
diff_flag=perflag-flag;
diff_ind=diff_flag<0; % 判断本次循环相比上次循环增加的点,新增加的点要再放入队列中
tmp=zeros(length(p),1);
tmp(diff_ind)=clsnum;
flag=flag+tmp;
perflag=flag;
nxtp=[nxtp;p(diff_ind,:)];
end
end
end
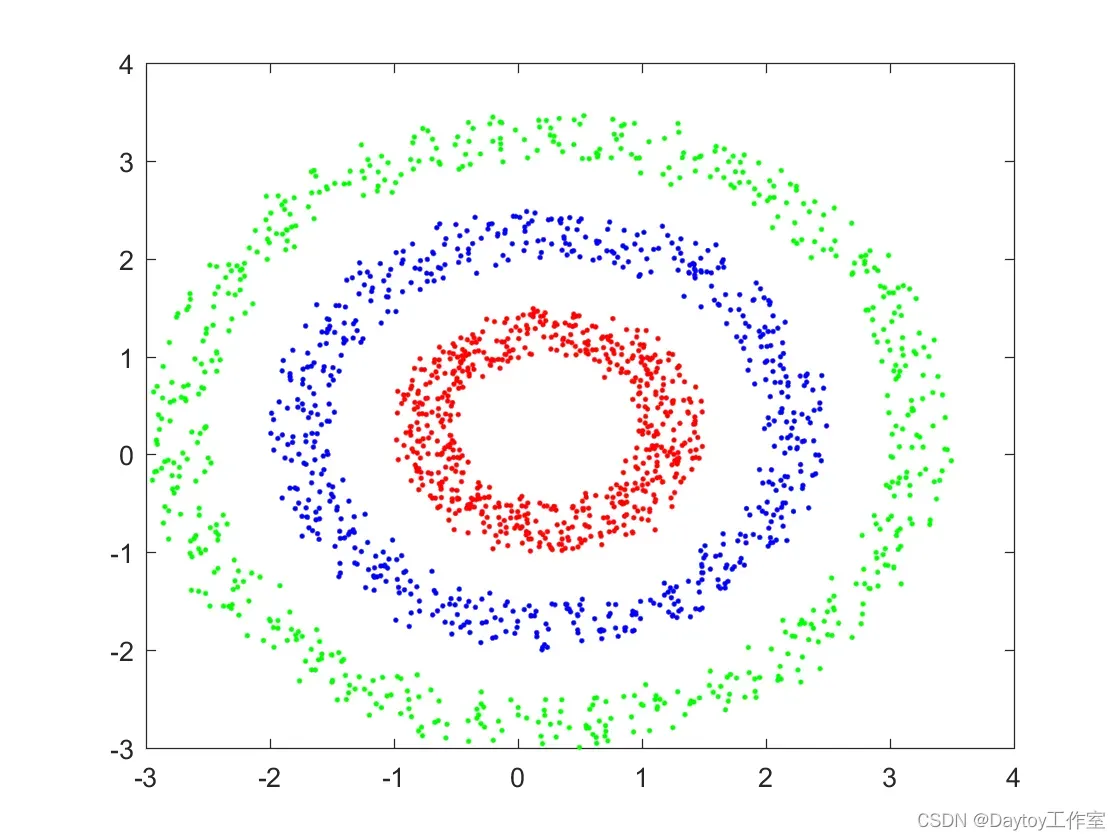
figure;
plot(p(flag==1,1),p(flag==1,2),'r.');
hold on
plot(p(flag==2,1),p(flag==2,2),'g.');
hold on
plot(p(flag==3,1),p(flag==3,2),'b.');
文章出处登录后可见!