踩坑记录
- 通过GitHub以及csdn开始安装
- 安装Anaconda,编译器以及CUDA、Cudnn
- 编译器
- CUDA与Cudnn安装,**涉及电脑显卡的版本配置问题**
- 本地部署
- 踩坑实录
- 常见问题
- Pytorch版本问题
- 显卡问题,自己配置Pytorch版本
- Pytorch版本导致的包不兼容
- Pytorch版本导致的丐版模型语句修改
- 现在进度
- 开始填坑第一弹
- 升级NVIDIA驱动
- 再次安装CUDA与对应Cudnn
- 配置pytorch以及其他所需包
- 出图是绿图,或者是黑图
- 现在的话已经可以画图了,但是效果不好!待我再炼丹然后尝试安装stable-diffusion-webui后回来继续填坑!!!
- 兄弟们已经可以用了,webui版本的我也搞定了,不得不说有个UI界面好用多了,模型上传也方便,强烈推荐搞webui版本!这个版本我准备卸载了
- 更新安装webui版本
通过GitHub以及csdn开始安装
先是进行搜索如何本地安装,找到了两种安装方法:一个是结合WebUI来进行本地部署;还有一个就是直接安装到本地通过代码段进行绘图。因为之前做毕设已经有过配置环境的经验,于是选择第二种,开始了踩坑。
这里主要是借鉴了一下二位大佬的安装记录,这里插入一下二位的指导链接。
链接: AI专业教您保姆级在暗影精灵8Windows11上本地部署实现AI绘画:Stable Diffusion(万字教程,多图预警).
链接:当我让AI描绘古代男子谪仙外貌。。。
安装Anaconda,编译器以及CUDA、Cudnn
这里的话,大多数博主都是有教程的,我上面发的第一个链接也有详细的过程,这里就不再赘述。主要讲讲编译器的选择。
编译器
编译器的话可以选择Pycharm,但这个要么用盗版,要么你去搞个社区版都可以;也可以选择vscode,开源软件,直接下载插件进行编译也可以。**从颜值来说我个人更喜欢vscode,配置也不复杂,而且有轻量化的优点。**编译器的选择看个人喜好,没有什么区别,Pycharm编译会更加好,很多时候vscode会报错而Pycharm就可以直接执行。
CUDA与Cudnn安装,涉及电脑显卡的版本配置问题
不同显卡的cuda对应版本可以通过win+R再输入cmd,键入以下命令来看:
nvidia-smi
会显示如下信息:
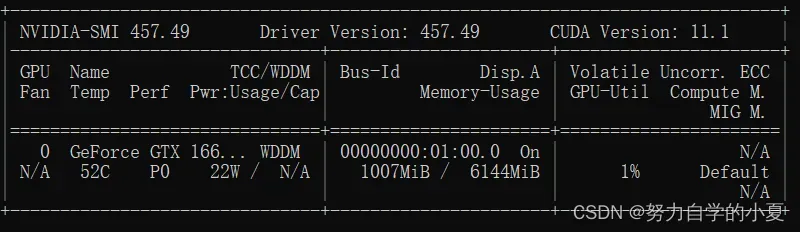
其中Driver Version就是驱动版本,可以通过以下NVIDIA官网自行查阅兼容的CUDA版本:
CUDA与显卡Driver Version对应版本查阅
Cudnn则通过以下连接查询对应的CUDA版本下载:
Cudnn的下载以及对应CUDA版本的查询
再之后的安装可以参考其他博主这里不赘述。这里安装的是cuda11.1还有cudnn8.0.5。
本地部署
按照教程开始部署,总结来说为以下几步:
-
git克隆项目到本地(没有安装Git就直接Download ZIP);
-
进入官网https://huggingface.co/CompVis/stable-diffusion-v-1-4-original下载sd-v1-4.ckpt权重模型(根据我查到的资料,还可以去添加其他模型,这个暂时还没尝试,因为还没通过这个模型抛出满意结果);
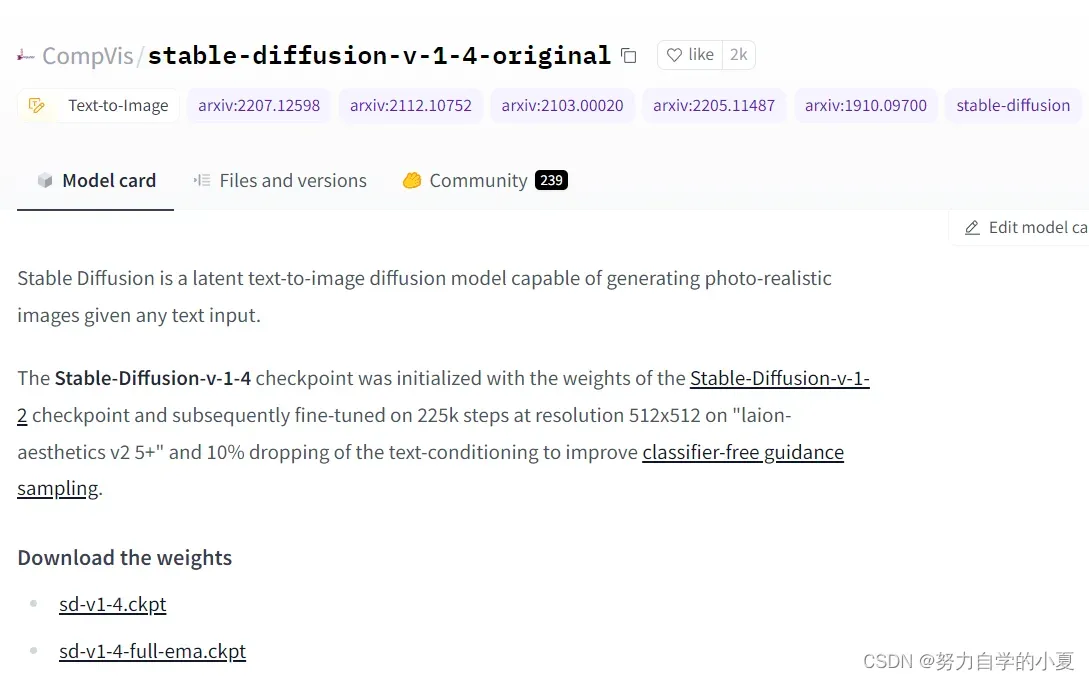
-
在克隆文件的models/ldm下自行新建stable-diffusion-v1文件夹,并把下载的ckpt文件重命名为model.dkpt放进去。
以上就是本地部署的过程,如果运气好应该就可以直接搞定,当然一般是不行的,之后开始正式记录本人的踩坑过程。
踩坑实录
常见问题
详见连接:当我让AI描绘古代男子谪仙外貌。。。
其中还会碰到一个问题说是无法import clip,这个问题也好解决,直接pip install clip就可以了。
通过丐版的模型,虽然可以运行,显存也没有爆炸,仍然无法出图,于是开始尝试以下方法。
Pytorch版本问题
本来电脑就配置过pytorch1.8.0版本,但是这个项目主要针对RTX30系以上显卡,本人的是四五年前的GTX1660Ti,显存和算力以及可用CUDA均落后不少,所以开始自行魔改。
这里有一个很重要的经验是自己踩坑踩出来的:其他包的配置与pytorch的版本兼容要事先查好!!!要么你就先装好其他包再去装pytorch也有可能可以(这个只是看到有认识这么说,我自己踩坑了没有试过)
显卡问题,自己配置Pytorch版本
首先通过clone下来的environment.yaml,直接通过GitHub上面的介绍方法直接新建环境和配置:
conda env create -f environment.yaml
然后里面包也不多,但有些就是没有下载下来装上去,所以装完了之后在键入以下命令查看已安装包,在进行手动pip。
conda activate ldm
conda list
以上为官方方法,新建虚拟环境ldm并安装所需库,配置为cudatoolkit=11.3,pytorch=1.11.0,torchvision=0.12.0。这个环境对于我的显卡是超过的,我的电脑最多支持cuda11.1。虽然可以跑但是没有出结果,所以重新安装了我的电脑可以配置的pytorch版本。
通过pytorch官网查阅Pytorch查询下载语句查到可用版本1.8.0重新安装并配置。
Pytorch版本导致的包不兼容
一共有两个。
一个是pytorch-lightning,直接pip就会把我配好的torch直接卸载,折腾了我半天,试出来可以兼容pytorch1.8.0的是pytorch-lightning=1.2.0;
另一个是最后一个kornia,试出来兼容的是kornia=0.5.8。
Pytorch版本导致的丐版模型语句修改
这个主要是因为为了缩小模型计算量,用了经典的model.half()命令,以及涉及的包的变化问题。
- autocast
在官方的版本中无问题,我改成1.8.0之后就无法import这个包,最后是吧from torch import autocast改成from torch.cuda.amp import autocast就好了; - 调用模型中的问题
代码逻辑中有一个如果使用了GPU版本就去调用half那句函数的逻辑,但是因为都是依托于autocast这个库,他版本更迭了之后不太一样,再次进行修改:
原先的with precision_scope("cuda"):改成with precision_scope(True):就可以跑起来了
现在进度
已经通过魔改在此可以运行程序,但是仍然跑不出来,跑出来就是这个样子:

现在还在找原因,等我填坑!!
开始填坑第一弹
一开始只能用pytorch1.8.0,或者说只能用cuda11.1,是因为电脑的显卡的驱动不高,因为电脑买的比较早,所以是457多一点,只能装cuda11.1。之后研究发现cuda的驱动是可以自己去官网下载升级的!直接把驱动搞到了最新,目前也没不兼容的问题,游戏也可以照常打,下面写昨天之后的安装过程。
升级NVIDIA驱动
通过这个链接进入官网NVIDIA官网驱动,会看到如下界面,按照自己电脑的显卡填入搜索即可,具体显卡型号可以通过打开NVIDIA的控制面板,点击左下角的系统信息之后就可以看到,我的是这样:
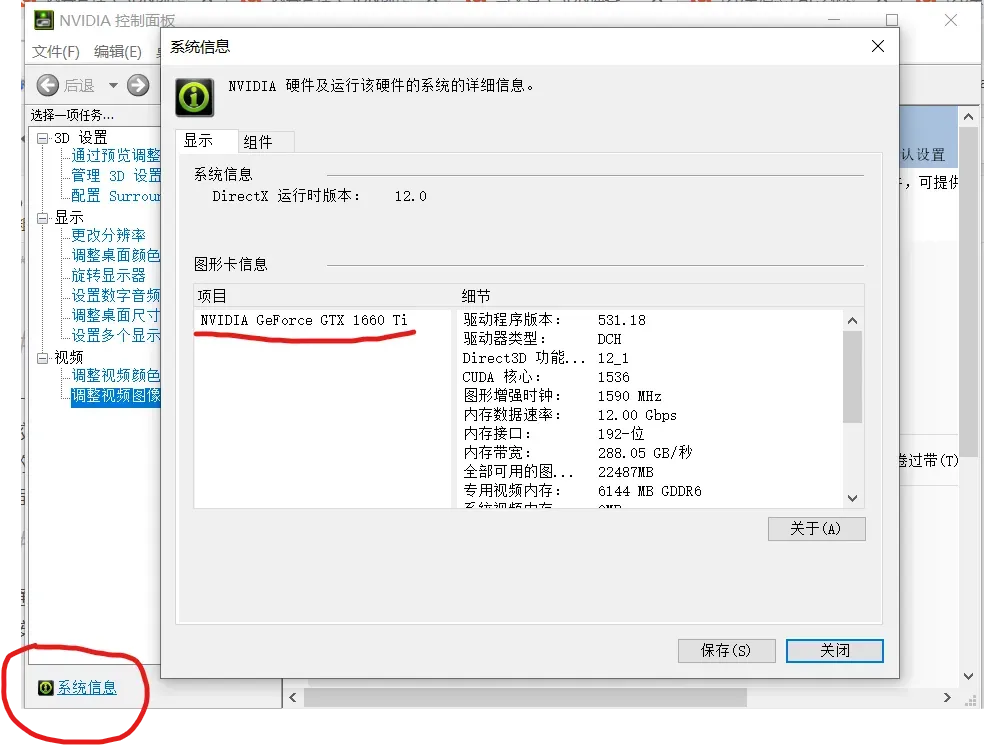
然后在官网界面填写并搜索,找到兼容的下载即可。
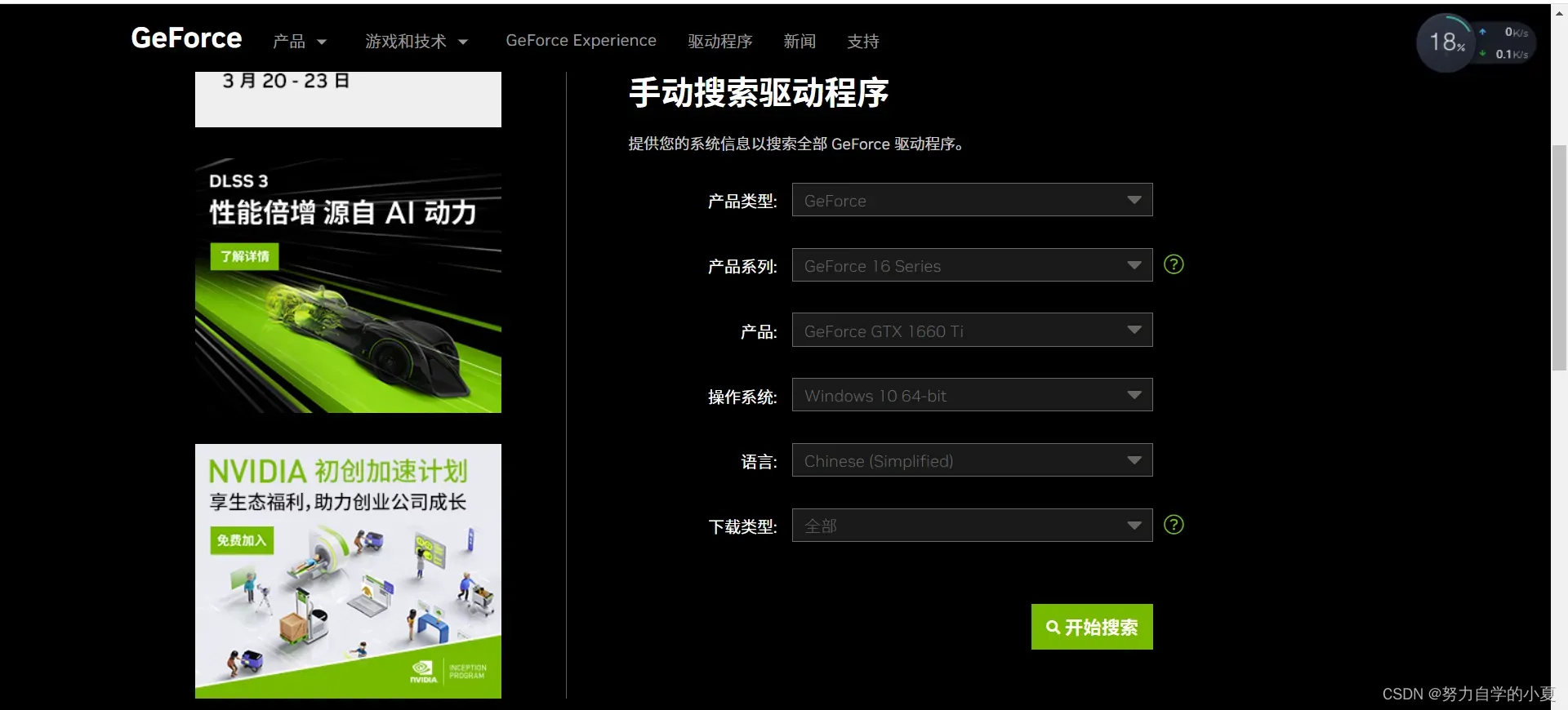

下载完成后,与cuda的安装类似,只不过这里直接精简安装就可以了,安装完你的驱动就已经是非常新的了,像我安装完之后,直接可以安装cuda12.1了。
再次安装CUDA与对应Cudnn
这个我一开始是在安装新的驱动之前,看了下cuda10.2是兼容pytorch1.11.0的,遂没有更新驱动,直接安装的cuda10.2,再次安装pytorch时却发现它安装渠道里面cuda10.2只支持到pytorch1.9,之后就都要cuda11及以上了……这里也是经验,以后安装要提前看好pytorch与cuda的对应版本到底有没有,不能直接看官网的previous version有安装语句就以为能装。
所以在升级完驱动之后,就直接安装了cuda11.3,这个版本能兼容pytorch的诸多版本,较为推荐,然后再去下载配套的cudnn就可以了,安装步骤上文已经写过了,这里我就不再多写。
配置pytorch以及其他所需包
这个就直接按照两个大佬链接里面去下载就可以了,更新完驱动这一步基本没有阻碍了,会碰到的问题之前也是都有写了。配置完成,成功能跑通,但是出来的图仍然是绿布。于是继续查有啥问题,不同的是这回我查到了而且成功解决!
出图是绿图,或者是黑图
这个我是看了很多,然后在一个教装stable-diffusion-webui的教程里找到的:NovelAi + Webui + Stable-diffusion本地配置,里面的最下面写了16系显卡可能的问题,就是把autocast关掉,要用全精度去计算就可以了。
根据我自己的研究调试,他出图包括计算过程中,会有报错说数据格式不对,我查阅了一下就是在计算梯度的时候会出现nan,然后导致计算失败,是在model.half()的过程中float32强转为float16可能遇到的问题,可以理解为这个项目压根没有考虑30系显卡之前可能有的算力不足以及显存不足的问题。
现在的话已经可以画图了,但是效果不好!待我再炼丹然后尝试安装stable-diffusion-webui后回来继续填坑!!!
兄弟们已经可以用了,webui版本的我也搞定了,不得不说有个UI界面好用多了,模型上传也方便,强烈推荐搞webui版本!这个版本我准备卸载了
更新安装webui版本
webui版本,可以理解为那个丐版里面,都有一个图形化UI界面的包gradio,在我原先装的那个丐版里面就有了一个简易的UI界面,webui这个版本的更全,还可以更换checkpoint(比较大的预训练模型)以及小的辅助模型lora等。
参考链接就是GitHub的开源模型:WEBUI
安装python3.10.6以及pytorch最新版本1.13,装完之后从上述链接直接用git clone或者下载压缩包解压;然后通过cd进入解压下来的stable-diffusion-webui目录下,并使用下面的代码来进行安装其他的必须包:
pip install -r requirements.txt
顺利的话就可以直接安装,如果出现问题,就手动打开txt对着列表一个个手动pip。
需要注意极大概率需要kexue上网才可以全部安装成功,我装的时候是手动然后还开了一个github加速器,就没碰到什么问题(直接搜fastgithub就可以找到这个加速器)
全部安装完成后,通过下面代码就可以运行:
python launch.py --autolaunch
运行完之后等一会就会有这样的界面:
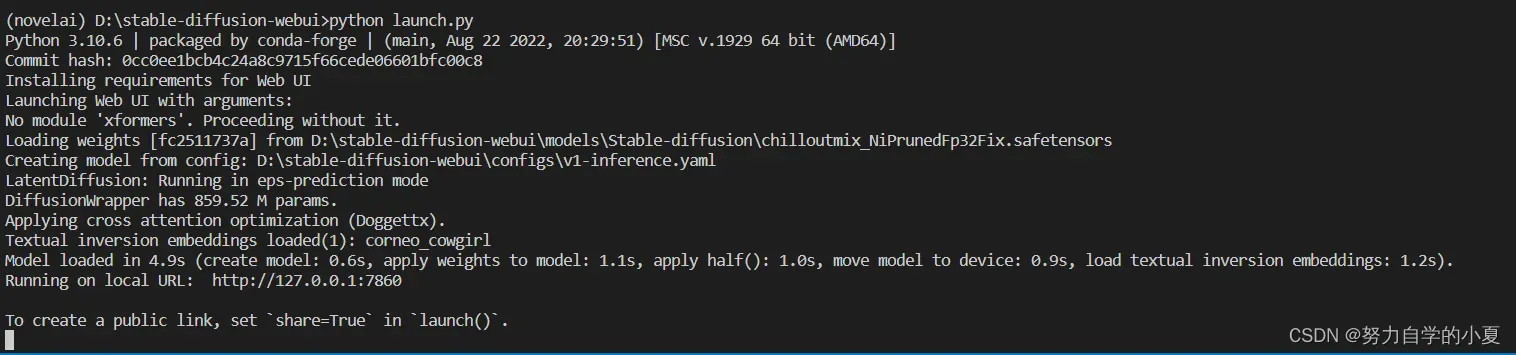
去点击那个URI链接(VSCode中需要ctrl+鼠标左键单击,PyCharm好像直接单击就可以),就会在你的默认浏览器中跳出如下的UI界面:
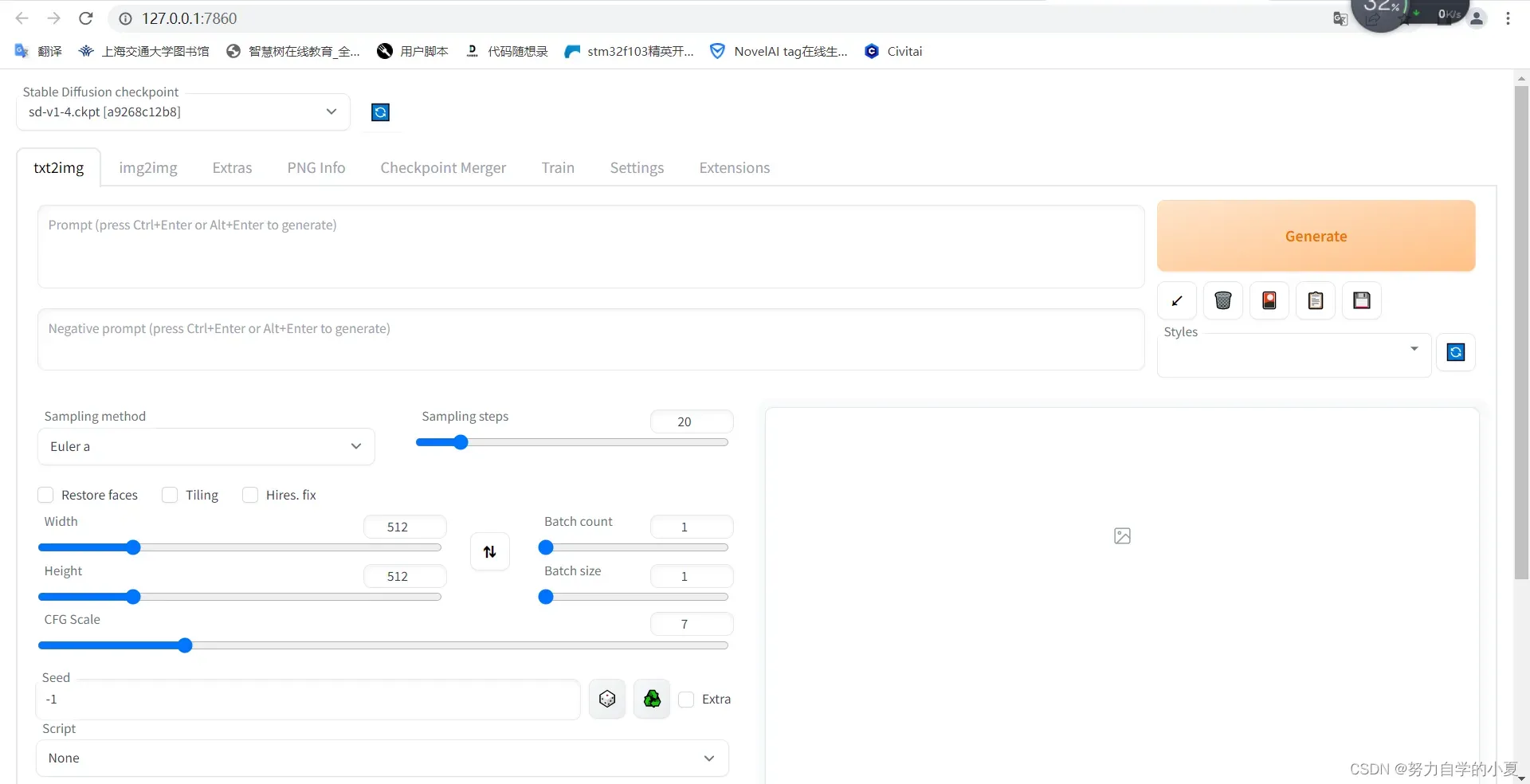
然后就自己输入文字调整参数来generate就可以啦!
文章出处登录后可见!