摘要
本文介绍了Code Llama大模型的基本概括,包含了论文的摘要、结果、结论以及核心方法,对于了解和实践Code Llama有一定帮助。
论文概述
上一篇介绍了指令进化大模型WizardLM,留了一个坑,补上Code Llama论文学习,可以作为下游任务的基座模型,比如Text2SQL。目前DB-GPT-Hub分支refactor支持了Code Llama模型微调,我粗糙地跑7b基础模型使用lora方法spider数据集上能达到0.66,大家也可以去试试。
再多说一句题外话,eosphoros-ai组织最新有个新项目Awesome-Text2SQL,收集了Text2SQL+LLM领域的相关综述、基础大模型、微调方法、数据集、实践项目等等,欢迎围观尝试。
基本信息
进入正题,文章很新,开源很强,可以商用。
- 英文标题:Code Llama: Open Foundation Models for Code
- 中文标题:Code Llama:代码领域的开源基础模型
- 发表时间:2023年8月24日 v1
- 作者单位:Meta AI(Facebook)
- 论文链接:https://arxiv.org/abs/2308.12950
- 代码链接:https://github.com/facebookresearch/codellama
论文摘要
总结起来一句话:开源模型代码领域最强,可泛化。
标题也说明了要做基础模型,就像人工智能领域中的CNN一样。
- 发布了Code Llama,基于Llama 2大模型,在开源模型中表现了最先进的性能。
- 提供多种风格来覆盖广泛的应用:
- 基础模型(Code Llama)
- Python领域(Code Llama Python)
- 指令遵循模型(Code Llama instruction)
- 每个模型具有7B, 13B和34B参数。
- 在几个代码基准测试中,Code Llama在开放模型中达到了最先进的性能。
- 在HumanEval和MBPP上的得分分别高达53%和55%。
- Code Llama Python 7B在HumanEval和MBPP上优于Llama 2 70B,并且所有的模型在数据集MultiPL-E上都优于所有其他公开可用的模型。
- 允许在研究和商业使用的许可下使用Code Llama,模型下载地址。
结果
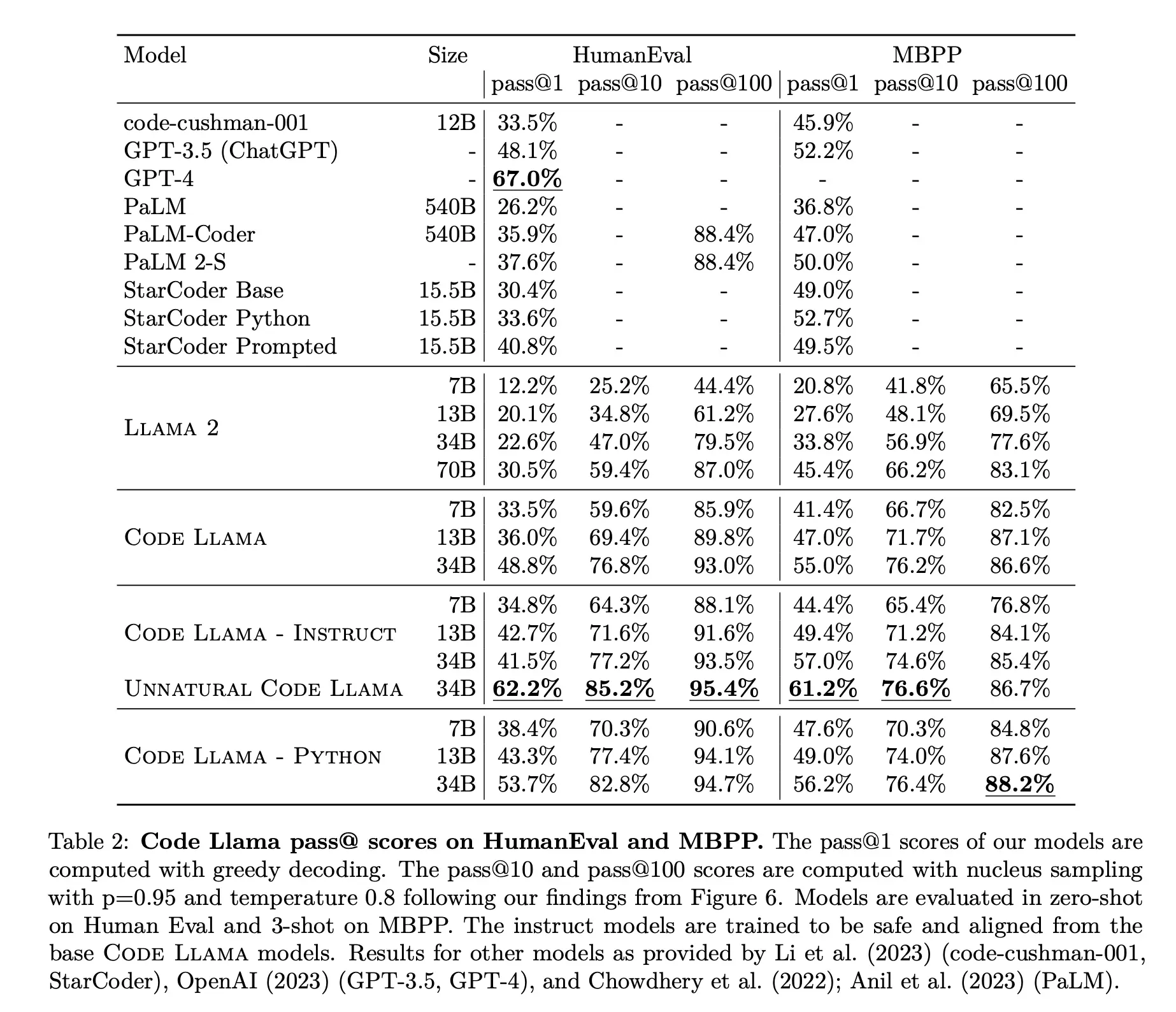
数据集HumanEval 和 MBPP
- GPT-4 在HumanEval数据集上一次生成通过率(pass@1)为67%
- GPT-3.5在HumanEval数据集上一次生成通过率(pass@1)为48.1%
- Code Llama在HumanEval数据集上一次生成通过率(pass@1)为62.2%,大于GPT3.5,比GPT4差一点。
补充一下,WizardCoder在8月26日发布了最新版本,已经超过了GPT4,HumanEval pass@1 达到73.2,简直无敌!
最新的开源大模型排行榜单,可以参考huggingface open LLM leaderboard
补充一下基础数据集知识
代码生成领域的两个重要数据集:HumanEval和MBPP,都是2021年的数据集,比较新。
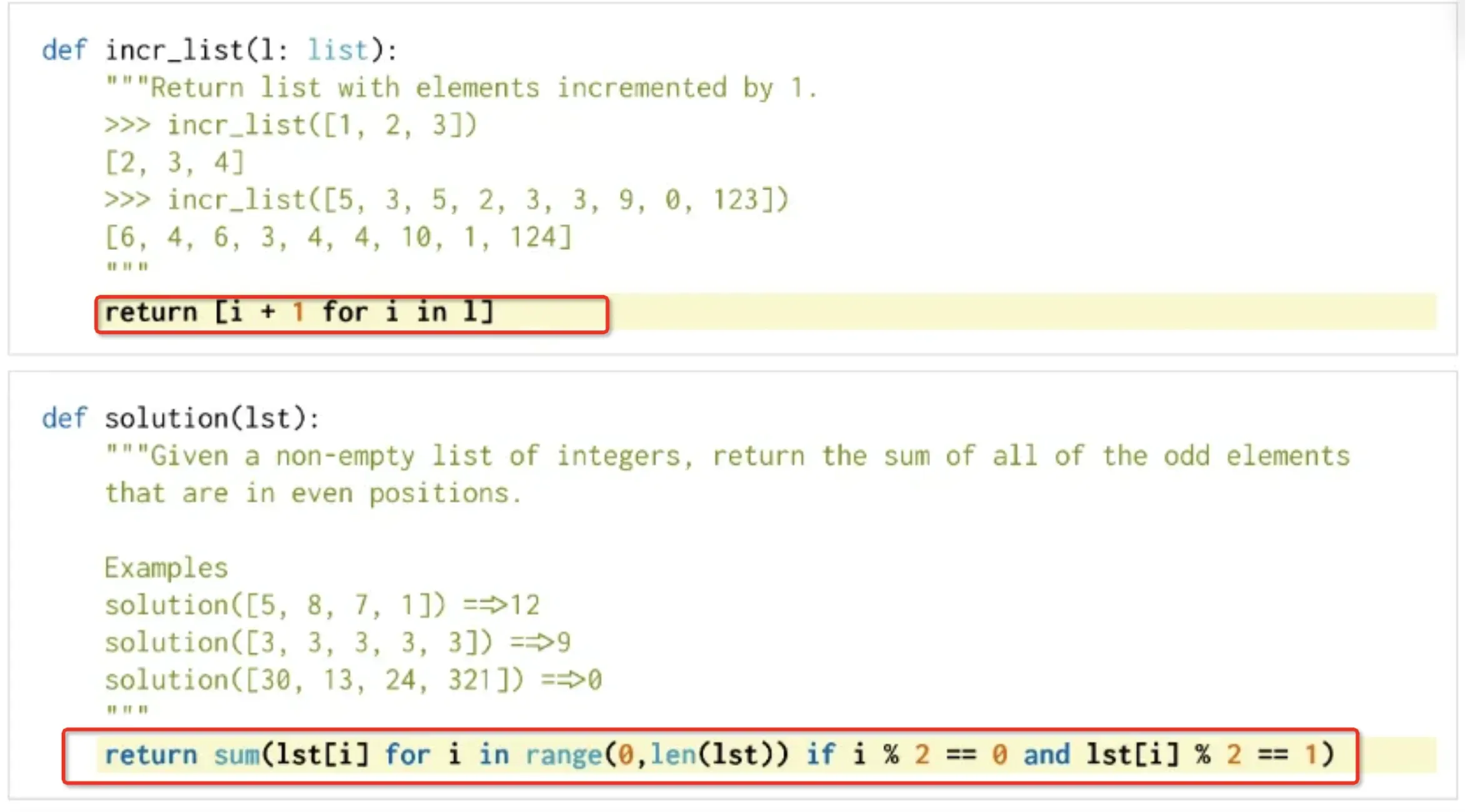
- 包含 164 个人工手写的编程问题,其中每个编程问题包括函数头、docstrings、函数体和几个用例。
- 比如红色的框就是需要模型生成的部分。
- 第一个问题:把列表每一个元素都加1
- 第二个问题:求和:偶数位置&奇数
- Mostly Basic Programming Problems 包含974个编程任务,旨在让入门级的程序员能够解决。这些问题涵盖了编程基础、标准库功能等多个方面。
- 比如下图的例子:

数据集APPS
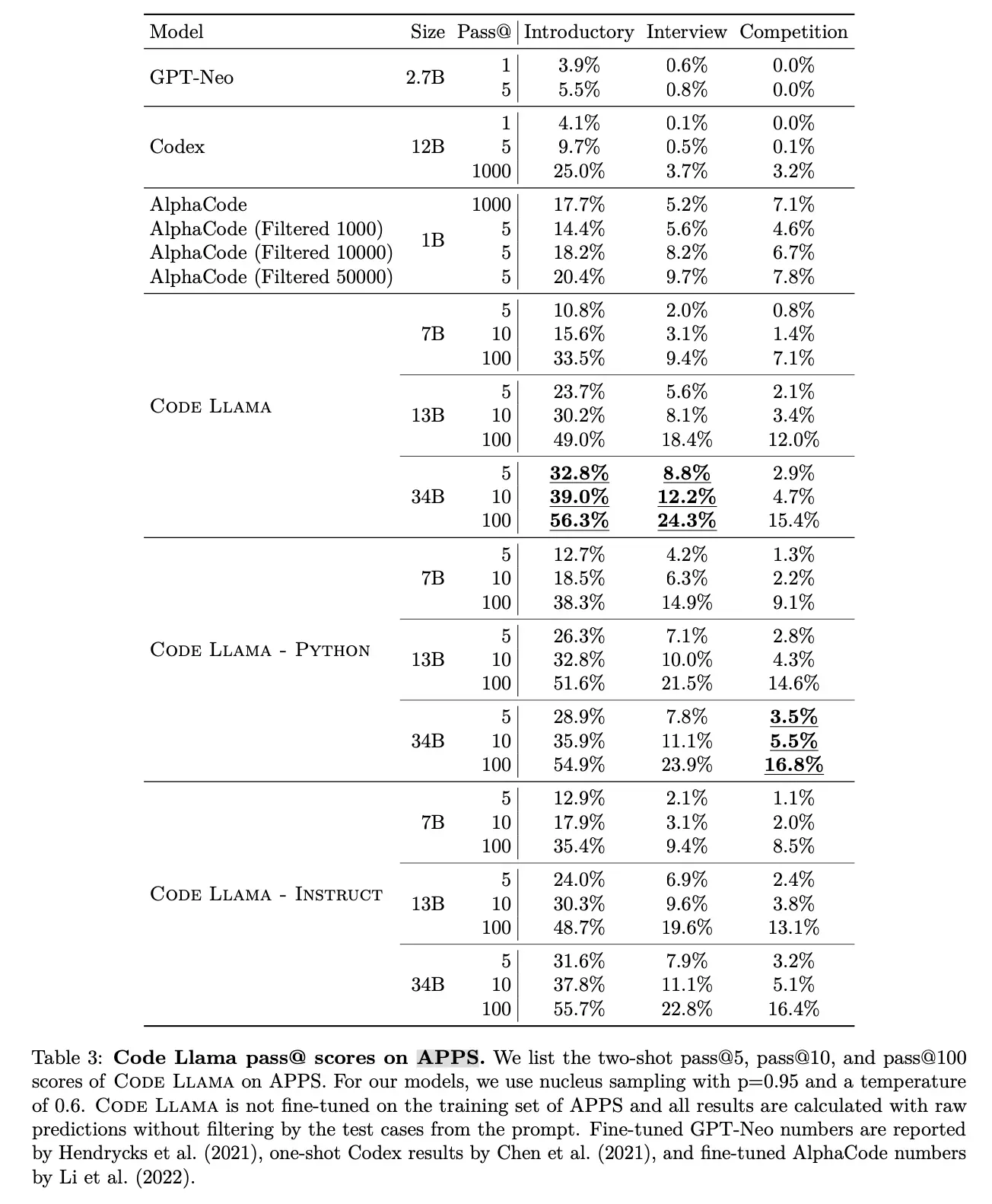
- APPS数据集是由UC Berkeley、UChicago等在2021年5月提出的,详情可以见论文地址,数据下载地址。
- APPS由10000个Python编程问题组成,分为三个类别(入门,面试,竞赛),并用面试中常见的简单的英语进行描述。其中5000个用作训练,剩下的5000个作为测试。
- 可以发现Code Llama 在入门,面试,竞赛都能取得最佳性能。
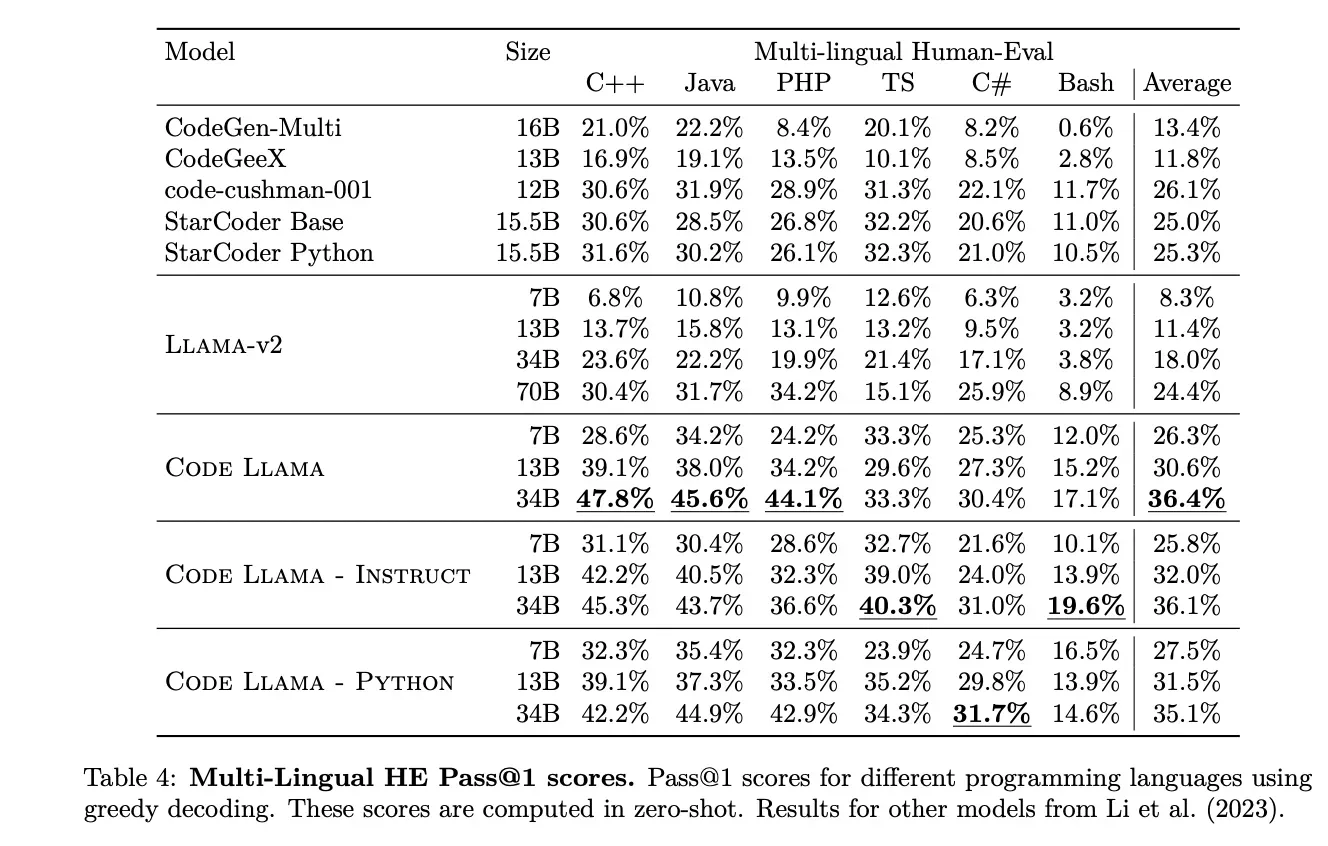
数据集MultiPL-E
- MultiPL-E数据集是2022年8月扩展HumanEval 和 MBPP的大模型多语言代码数据集,详情参考论文地址,数据集地址。
- Code Llama 基础版34b 在C++上取得了47.8%,第一,在Java、PHP、TS、C#、Bash都能取得第一,平均准确率也是第一。
结论
- 发布了针对代码领域的大模型Code Llama,基于Llama 2微调得到。
- 有3个参数规格:
- 7b (下载hugging face上面模型约为51G,去掉.git文件后约26G)
- 13b
- 34b (下载hugging face上面模型约127G,去掉.git文件后约64G)
- 每个参数都有3个类型:
- 基础版本
- python 版本
- 指令instruct 版本
- 在多个数据集上取得了开源最好的效果。
核心方法
训练的pipline
- 输入是Llama 2
- 代码填充训练
- 长上下文微调
- 直接得到基础版本Code Llama
- 再经过人工指令微调得到Code Llama-Instruct
- 使用python 代码训练 -> 长上下文微调 -> 得到Code Llama-Python版本
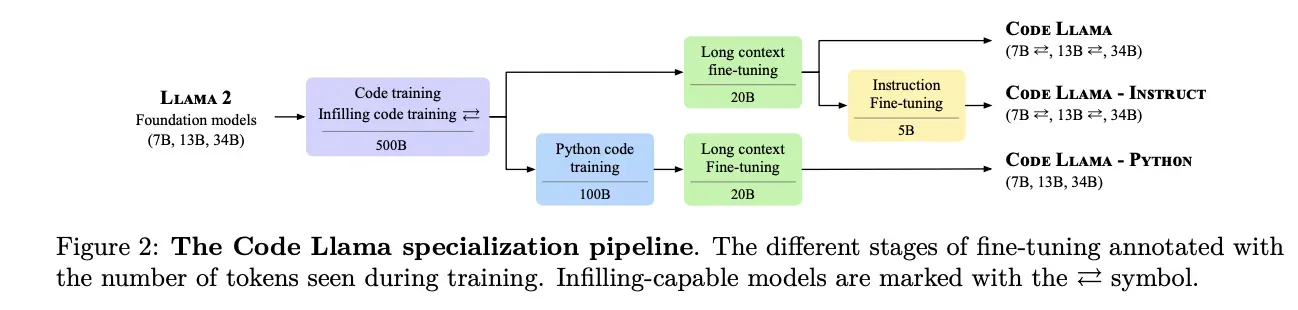
Code Llama家族
- Code Llama,是代码生成的基础模型,有7b、13b、34b三种型号。
- 其中7b和13b使用了填充目标(infilling objective)训练,适合在IDE中使用,在文件中补全代码。
- 34b没有进行填充目标训练。
- 都使用了500B的数据集训练。
- 可以处理上下文。
- Code Llama-Python
- 7b、13b、34b都没有经过填充训练
- 额外使用了100B的python数据集微调
- 可以处理上下文
- Code Llama-Instruct
- 在基础版本的基础上,额外使用了5B的人类指令微调。
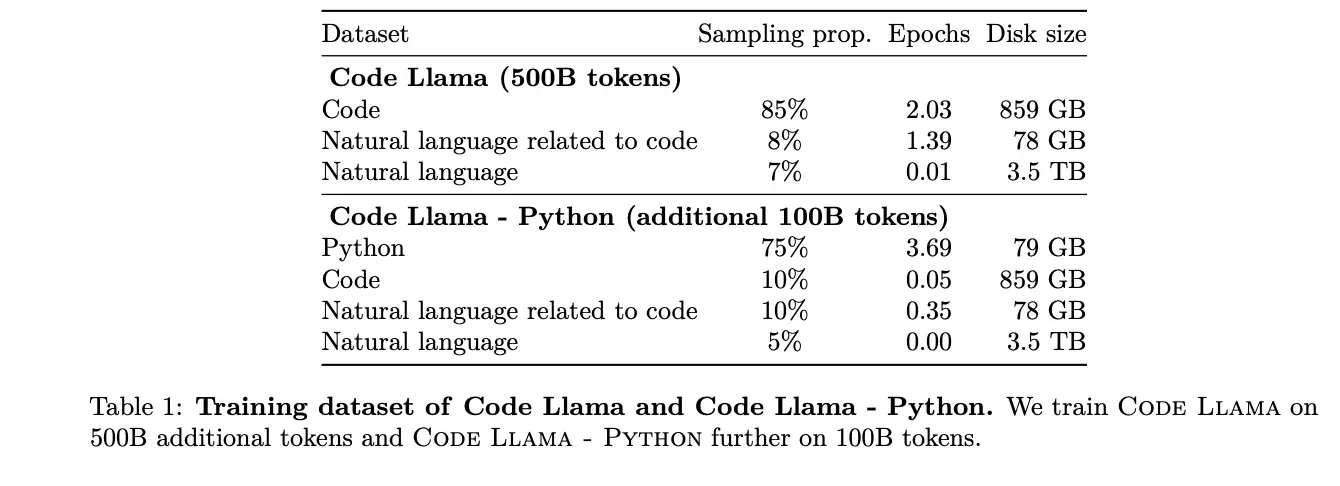
数据集
- 除了用公开的代码数据集训练,占比85%
- 还使用了与代码相关的自然语言数据集中获取了8%的样本数据(更好理解代码,类似于伪代码)
- 为了帮助模型保留自然语言理解技能,抽取了7%的自然语言数据集样本。
infilling填充
Code infilling代码填充:给定上下文的情况下预测程序缺失部分。
- 论文按照因果遮掩(causal masking)的概念训练填充模型[1],其中训练序列的部分被移到末尾,重新排序的序列被自回归预测。更准确地说,论文在字符级别将训练文档拆分为前缀,中间部分和后缀,拆分位置独立随机均分布。随机将一半的片段随机格式化为前缀-后缀-中间(PSM)格式,另一半则采用后缀-前缀-中间(SPM)格式。
- 论文扩展了Llama2 的tokenizer,使用四个特殊的标识,来标记
- 前缀的开始
- 中间部分
- 后缀
- 填充结束
long context fine-tuning长上下文微调LCFT
对于Code Llama,论文提出了一个专用的长上下文微调(LCFT)阶段。
- 在该阶段中,模型使用16,384个令牌序列,高于Llama 2和初始代码训练阶段使用的4,096个令牌。
- 通过将用于处理长序列的训练时间限制在微调阶段,可以在不显著增加模型训练成本的情况下获得长范围的能力。
- 论文的策略类似于最近提出的通过位置插值进行微调[2]。
instruction fine-tuning指令微调
指令微调模型Code Llama – Instruct是基于Code Llama和训练,以适当地回答问题,该模型接受三种不同类型数据的训练。
- 专有的数据集。我们使用了为Llama 2收集的指令调优数据集,该数据集由Touvron等人[3]详细描述。具体来说,使用了该论文中提到的“RLHF V5”版本,该版本是通过强化学习的几个阶段从人类反馈和人类反馈注释中收集的(详见该论文的第3节)。
- 它结合了数千个监督微调和数百万个拒绝采样示例。每个示例都包含用户和助手之间的多回合对话。对于拒绝抽样,使用奖励模型从几代中选择输出。最终的数据集包含Helpfulness和Safety数据。这使得Code Llama可以继承Llama 2的指令跟随和安全属性。
- self-instruct。人类反馈收集数据,是昂贵的,因为它需要专业开发人员的输入。论文使用执行反馈来选择数据来训练指令模型,而不是人工反馈。按照下面的方法构建了自我指导数据集,得到了约14,000个问题-测试-解决方案三元组(question – test – solution):
- 1. 通过下面的prompt生成62,000个面试式编程问题。

- 2. 通过删除完全重复的问题来消除重复的问题集,得到约52,000个问题。
- 3.对于每个问题:
- (a)通过下面的prompt 在Code Llama 7B生成单元测试

- (b)通过下面的prompt 在Code Llama 7B生成十个Python解决方案

- (c)在十个解决方案上运行单元测试。将通过测试(以及相应的问题)的第一个解决方案添加到自指导数据集。
为什么使用7b 模型去生成三元组(question -test – solution)?
论文发现在相同的计算预算下,34B模型每个问题生成更少的解决方案,7b更有效。
Rehearsal 预演。为了防止模型对一般编码和语言理解能力的回归,Code Llama Instruct还使用代码数据集(6%)和自然语言数据集(2%)中的一小部分数据进行训练。
训练细节

参考
[1] Armen Aghajanyan, Bernie Huang, Candace Ross, Vladimir Karpukhin, Hu Xu, Naman Goyal, Dmytro Okhonko, Mandar Joshi, Gargi Ghosh, Mike Lewis, and Luke Zettlemoyer. CM3: A causal masked multimodal model of the internet. arXiv:abs/2201.07520, 2022.
[2] Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. CodeT: Code generation with generated tests. In ICLR, 2023a.
[3] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton- Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. arXiv:abs/2307.09288, 2023b.
[4] Text2SQL Code Llama实践项目:https://github.com/eosphoros-ai/DB-GPT-Hub
[5] Text2SQL + LLM汇总入门:GitHub – eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, and more.
文章出处登录后可见!