AIGC是什么
AIGC – AI Generated Content (AI生成内容),对应我们的过去的主要是 UGC(User Generated Content)和 PGC(Professional user Generated Content)。
AIGC就是说所有输出内容是通过AI机器人来生成产出相关内容,主要区别是过去主要是普通用户和某一领域专业用户(人)生产内容,AIGC主要是依赖于人工智能(非人类)生成内容,这个就是AIGC的核心意思。
(版权认定:UGC和PGC是有版权概念的,版权归属于负责生成内容的人,AIGC目前美国法规认为是没有版权概念的,就是内容不属于调用的人,也不属于这个AI机器,所以没有版权归属这件事。)
AIGC可以生成什么内容
目前AIGC主要可以生成文本内容和图片内容(目前视频生成有一些产品,但是没有文本和图片生成这么成熟),所以我们主要集中在文本和图片的AIGC的介绍。
AIGC在文本内容方面,主要可以通过 Q&A (提问回答)得形式进行互动,能够按照人类想要的“提问”生产输出符合人类预期的内容。
一般我们可以把AI当做一个全知全能的“高级人类”,以“文本AIGC”来抡,你可以向它提出问题(Prompt),然后它做出相应回答。所有提问和回答都可以涉及到方方面面,包括不限于 百科知识/创意文案/小说剧本/代码编程/翻译转换/论文编写/教育教学/指导建议/聊天陪伴 等等等等场景不一而足,场景都需要你去想,可以理解它是一个拥有全地球知识的“百晓生”,什么都可以问它或者跟它交流。
比如我们用大名鼎鼎的 ChatGPT 来进行提问:

对于“图片AIGC”来说,你可能脑子里有无数创意,但是自己不会绘画,无法把脑子里的Idea变成实实在在的图片,那么,“图片AIGC”能够帮助你按照你脑子想要的东西,你告诉它,然后它能够帮助你通过图片绘画的形式给你画出来,让你一下子把自己的“创意”变成了图片现实。
比如我们用非常好用的“图片AIGC” 工具 Midjourney 来画画:

AIGC底层是什么
AIGC底层主要依赖的是AI技术,AI技术本质主要是让机器拥有像人类一样的智能(Artificial Intelligence),所以就需要让机器能够像人类一些学习和思考,所以目前大部分实现AI的底层技术叫做“机器学习”(Machine Learnin)技术。
机器学习技术主要有很多应用场景,比如现在非常常用的包括 人脸识别(手机解锁/支付宝支付/门禁解锁等)、语音识别(小爱同学/小度/Siri)、美颜换脸(主播美颜/美颜相机)、地图导航、气象预测、搜索引擎、NLP(自然语言处理)、自动驾驶、机器人控制、AIGC 等等。
机器如何进行学习
机器学习可以简单理解为是模拟人类学习的过程,我们来看一下机器是如何模拟人类学习的。
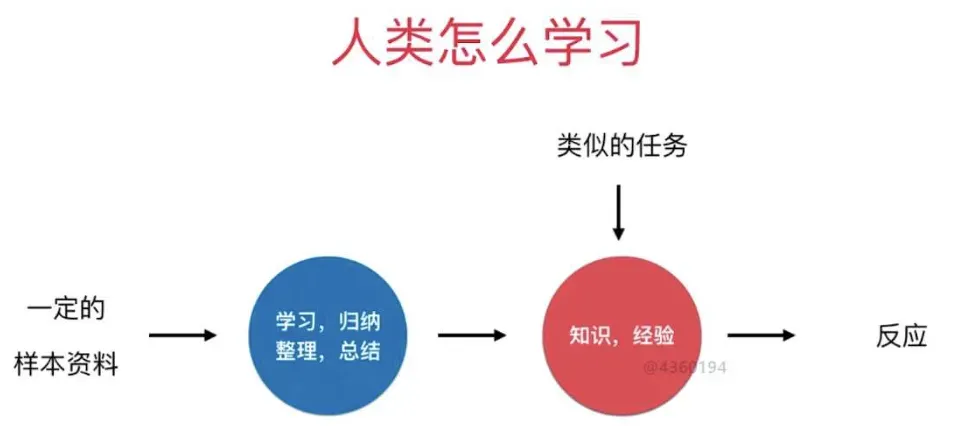
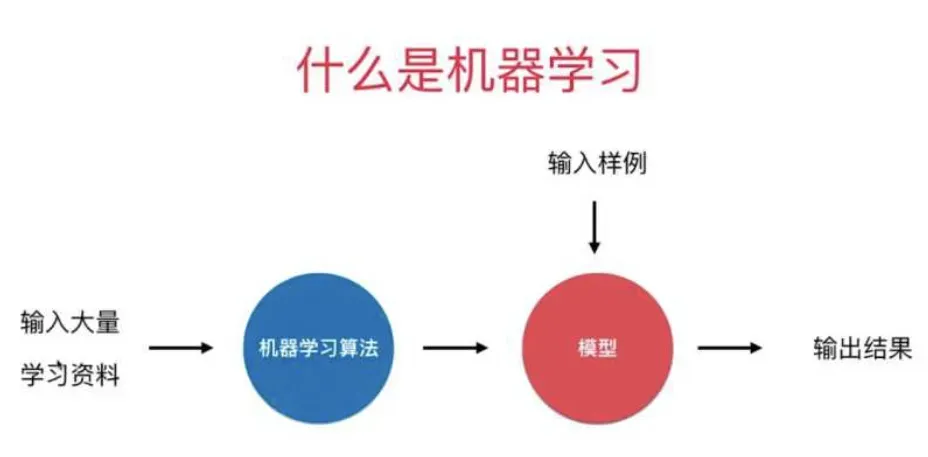
我们再看看所谓的“机器学习”:
对于人类学习来说,我们看到的事物和遇到的事物就是我们的“资料”(语料),然后我们通过“学习总结归纳”(学习算法),最后变成了“知识经验智慧”(模型),然后遇到事情的时候我们就会调用这些“知识经验方法论”做出相应的反应决策动作(预测推理);
对于机器学习来说,给它输入大量的“语料”(看到遇到的事物),然后通过机器学习算法(总结归纳抽取相似点),最后形成了“模型”(知识经验方法论),然后再遇到一些需要判断决策的时候,我们就会把要判断决策的事物给“模型”,然后就会告诉我们输出结果(推理推测结果);
从抽象层来说,我们会发现,本质来说,“人类学习”和“机器学习”内在本质是比较像的。
我们来看一个计算机里概要的机器学习的过程:
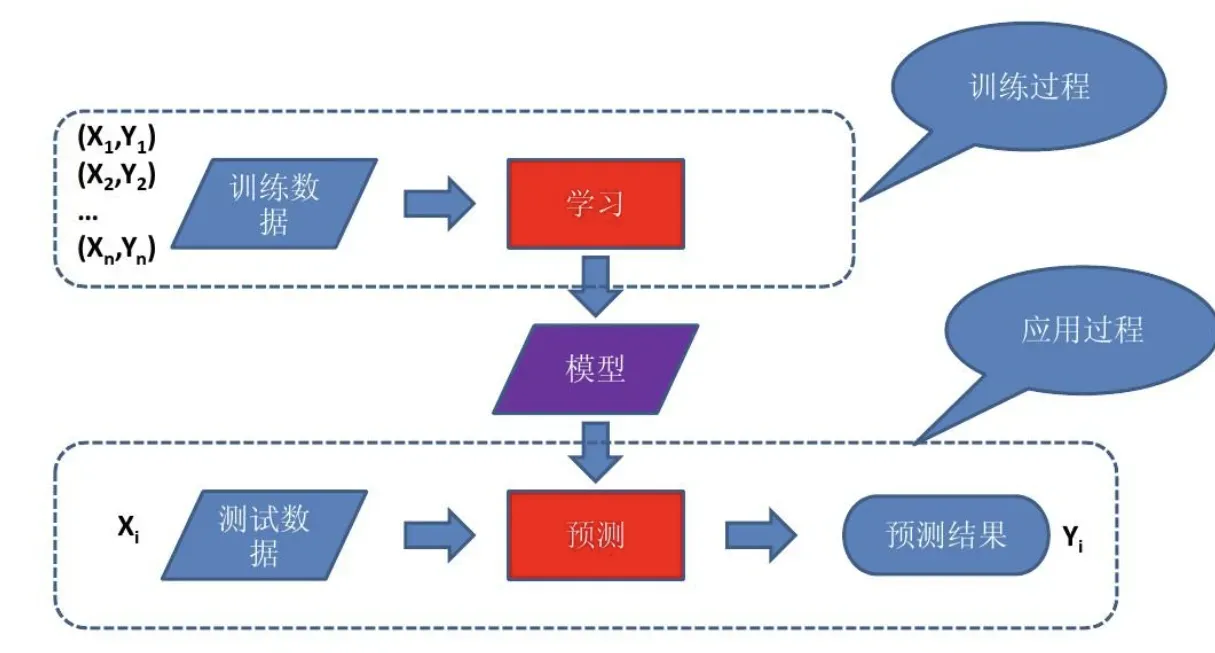
里面核心步骤就是:“训练数据 ➜ 训练算法 ➜ 模型 ➜ 预测 ➜ 输出结果”,其中最终产出物是“模型”(Model,模型文件),然后主要是前置的“训练模型”和后置的“模型预测”,然后产生对应结果。
上面这个过程我们我们可以简单理解为:“模型”就是一只小狗,饲养员就是那个“训练算法”,饲养员在场下对那个小狗通过一些指令和奖惩措施进行反复训练(训练算法),小狗就会学会一些技能(模型),一旦学会了,小狗就可以出去表演,表演的过程就是预测。
所以我们会看到,里面如果“模型”中的特征(知识经验)越多,最终在“预测”阶段就越准确,如果模型越小,或者中间的特征数据越少,可能最终预测结果准确率会降低。(类似一个人遇到的事情越多,总结的经验就越多,俗话说的“人生没有白走的路没有白踩的坑” 大概就是这个逻辑)
机器学习的分类
机器学习(Machine Learnin)经过几十年的研究,在技术实现得种类非常多,可以从大类上面分为:基于学习策略、基于学习方法、基于学习方式、基于学习目标等进行分类。
基于学习策略的分类:主要有模拟人脑工作原理的“符号学习”和“神经网络学习”两个主要流派;另外一个学习策略的流派是基于数学统计分析得机器学习方法。
基于学习方法的分类:机器学习主要有,归纳学习、演绎学习、类比学习、分析学习,它是类似于人脑的“符号学习”得学习方法分类。
基于学习方式的分类:主要有,有监督学习(带老师指导)、无监督学习(自学)、强化学习(通过环境奖惩反馈进步)。
机器学习分类中,我们重点关注的是“学习策略”和“学习方式”为主的分类,学习策略是关注是基于“数学统计分析”的机器学习还是基于“神经网络”的机器学习。另外一个是学习方法,主要是关注 有监督学习、无监督学习和强化学习。
机器学习的发展
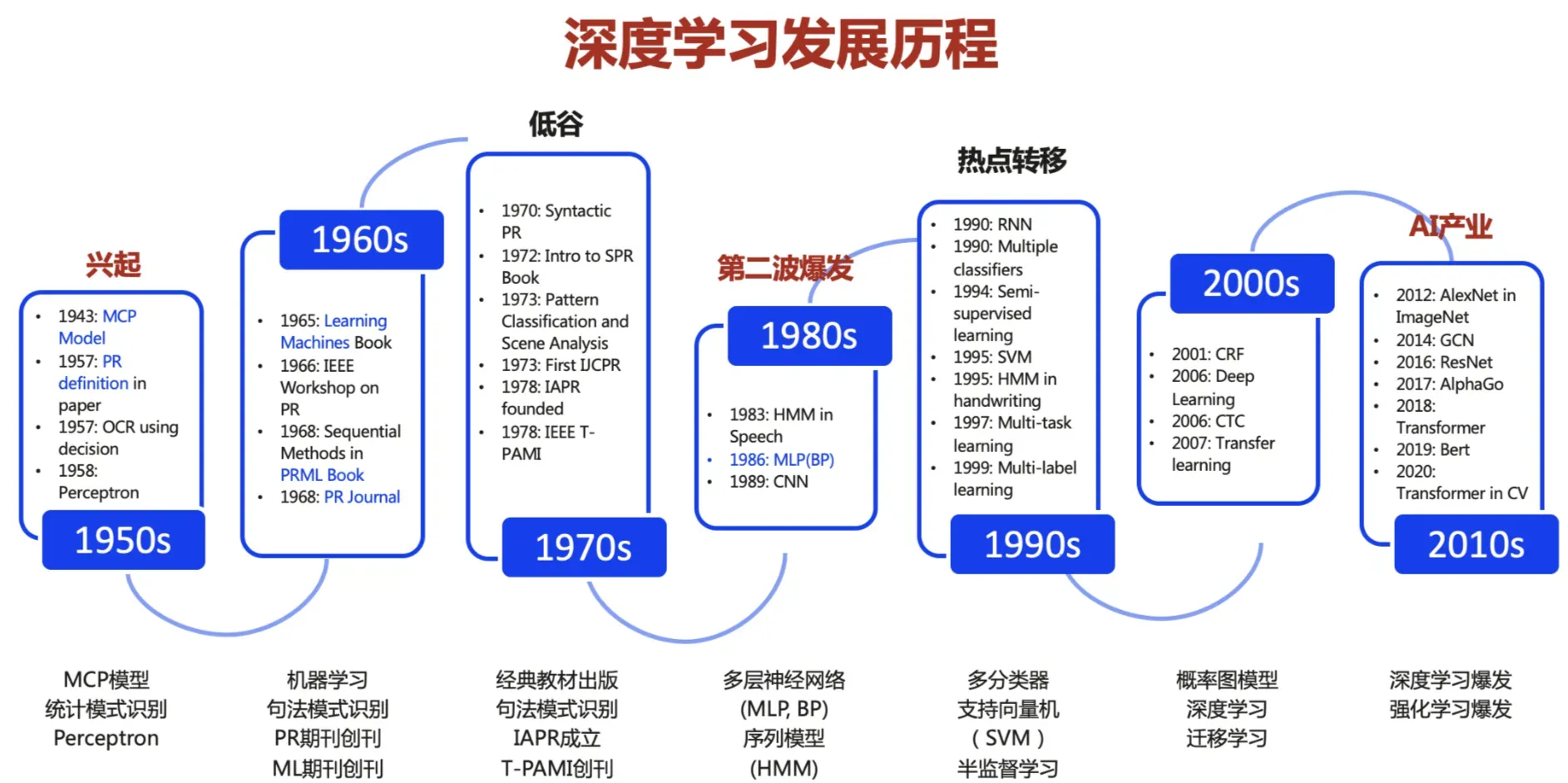
机器学习技术主要经历了从兴起到深度学习三个大技术时代,第一个是兴起时代,然后是传统的机器学习时代,最后是基于神经网络的深度学习时代,以下简单按照我个人理解做了一个发展阶段分类。
兴起阶段:1943年诞生了感知机模型(MCP),一位心理学家和一位数理逻辑学家 提出了人工神经网络的概念和人工神经元的数学模型,算开创了人工神经网络得研究时代。然后从60年代到80年代之间,有了机器学习概念和模式识别等,属于整个研究的兴起探索阶段,这个阶段各种方向的探索都在进行,百花齐放。
第一阶段:传统机器学习(Machine Learnin),从1980年召开第一届技术学习研讨会开始,虽然同步也有神经网络得研究,但是可以简单理解为大行其道的主要是基于数学和统计分析为主的方式得机器学习,特别是在1990年到2001年之间,从理论到实践都经过了很大的发展。这个时间段一直到2006年,在信息行业主要流行的传统机器学习包括 传统隐马尔可夫模型(HMM)、条件随机场(CRFs)、最大熵模型(MaxEnt)、Bboosting、支持向量机(SVM)、贝叶斯(Bayes)等等,具体实践中落地包括 线性回归、逻辑回归、SVM、决策树、随机森林、朴素贝叶斯 等等落地的算法。这些算法的因果逻辑和中间计算过程都是清晰明确的,基本是清晰可信的,不足就是最终效果有上限,可能最终“智能”效果有时候就不够。
第二阶段 V1:“深度学习”(Deep Learnin),2006年机器学习教父级人物Hinton发表了深层神经网络的论文正式开启了基于神经网络得“深度学习”的阶段,可以简单认为“深度学习”是传统机器学习的另外一条路线,它主要区别是在“学习策略”方面的路线不同,传统机器学习主要是依赖于“数学统计分析”为主的方法,过程结果可推导;深度学习主要是也依赖于让计算机模拟人脑一样神经网络连接一样的方式进行运算。
第二阶段 V2:Transformer 模型(Transformer model),2015年提出了Attention机制,2017年Google发表了论文《Attention Is All You Need》,2018年基于这篇论文在第二阶段神经网络的基础之上提出了Transformer模型,它基于encoder-decoder架构,抛弃了传统的RNN、CNN模型,仅由Attention机制(注意力机制)实现,并且由于encoder端是并行计算的,训练时间大大缩短。Transformer模型广泛应用于NLP领域,机器翻译、文本摘要、问答系统等等,最近几年比较主流的Bert和GPT模型就是基于Transformer模型构建的。
我们看一下深度学习基本的发展历史:
传统机器学习和深度学习的区别
深度学习与传统机器学习不太一样,所以它主要是用来定义不同网络框架参数层的神经网络,所以主有很多神经网络训练方式,包括 无监督预训练网络(Unsupervised Pre-trained Networks)、卷积神经网络(Convolutional Neural Networks)、循环神经网络(Recurrent Neural Networks)、递归神经网络 (Recursive Neural Networks)等等;
神经网络叫做“深度学习”主要是看里面所谓神经网络的层数,1-2层叫做浅层神经网络,超过5层叫做深层神经网络,又叫做深度学习”。
其中,应用比较多的主要 卷积网络(CNN – Convolutional Neural Networks)、循环神经网络(RNN – Recurrent Neural Networks)+递归神经网络(RNN – Recursive Neural Networks)、长短期记忆RNN(LSTM – Long short-term memory) 和为了解决 LSTM/RNN 中的一些问题的解决办法加入Attention机制的Transformer框架。
深度学习在计算机视觉(CV、如图像识别)、自然语言处理(NLP)、自动驾驶、机器人控制 等方面比传统机器学习效果更好。
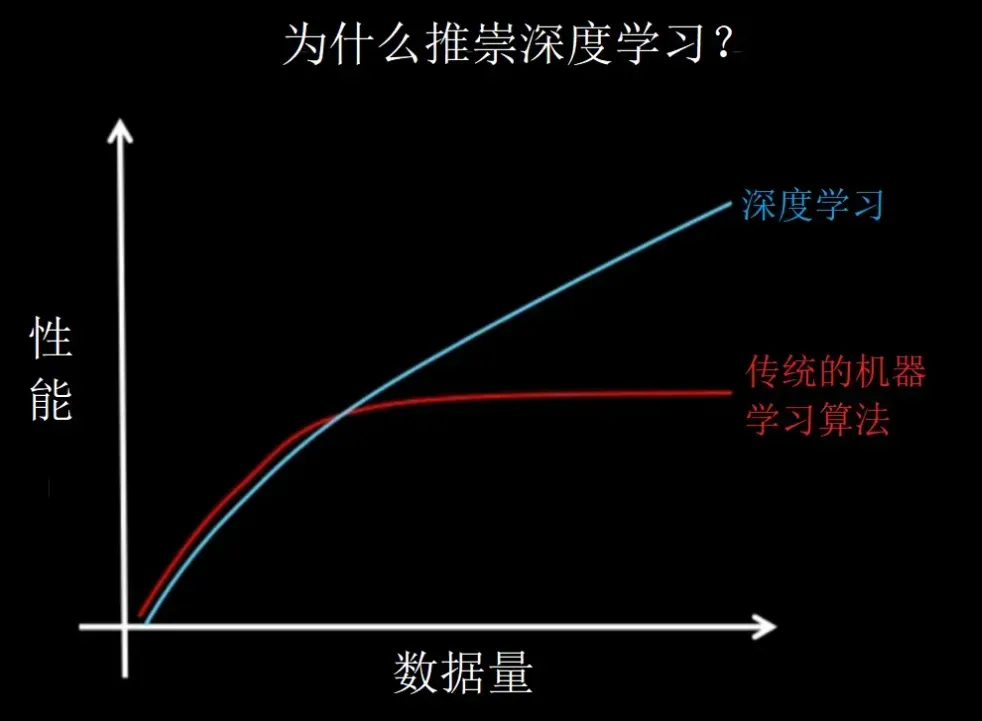
在训练数据规模比较小的情况下,传统机器学习型算法表现还可以,但是数据增加了,传统机器学习效果没有增加,会有一个临界点;但是对于深度学习来说,数据越多,效果越好。所以也是越来越逐步“深度学习”取代“传统机器学习”的过程了。
传统机器学习和深度学习的效果性能对比图:
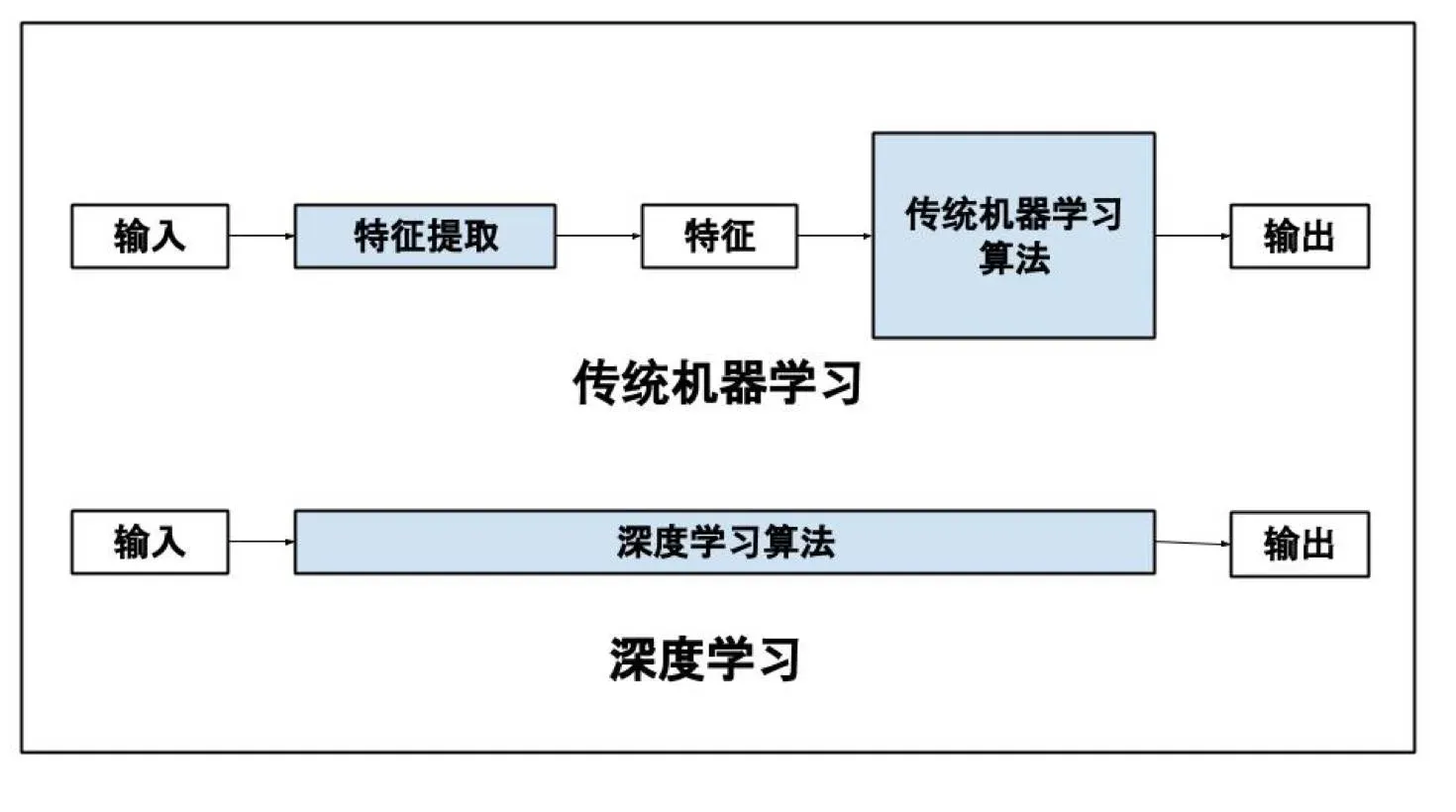
传统机器学习和深度学习的处理过程区别:(传统机器学习特征是清晰的,深度学习内部特征是黑盒)
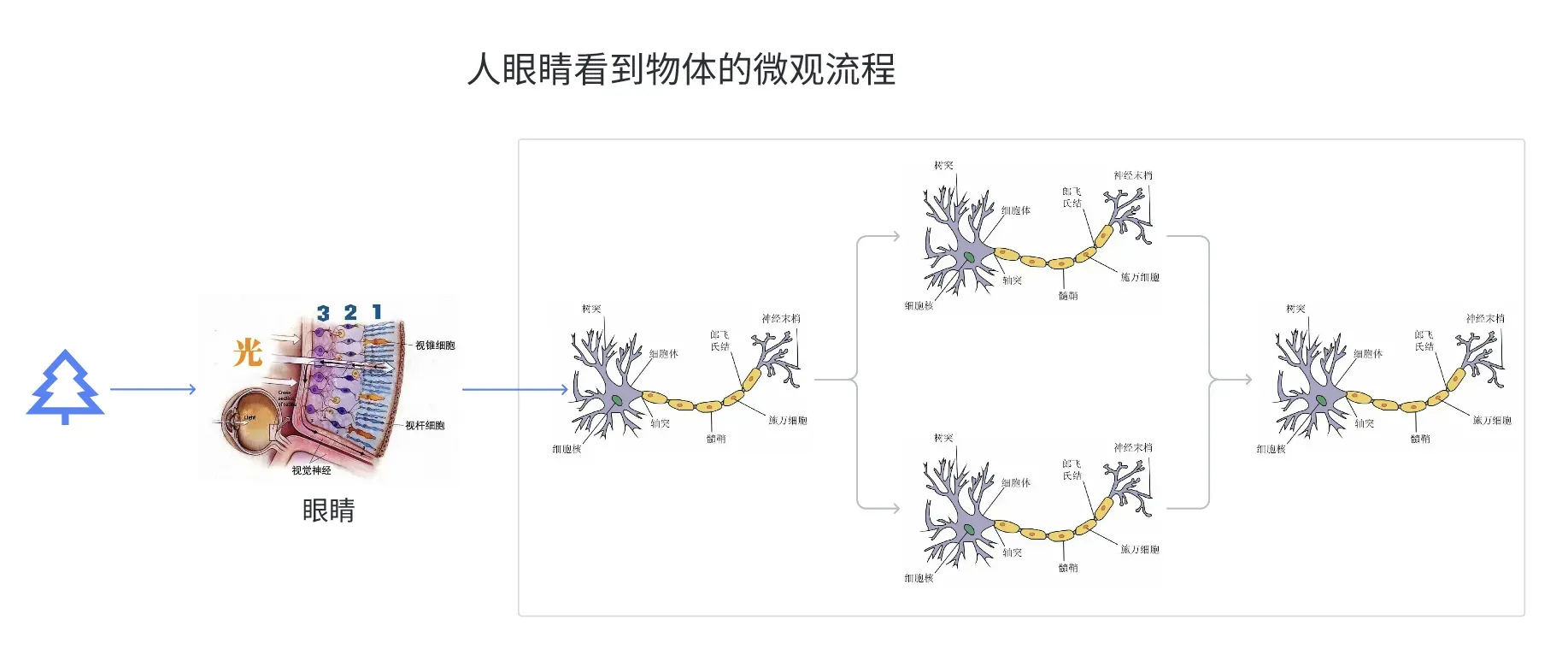
深度学习中使用的神经网络,大概的工作机制是模拟人类的脑子工作机制,比如我们通过眼睛看到一个物体的过程:
我们再看看基于神经网络得“深度学习” 进行学习的过程:
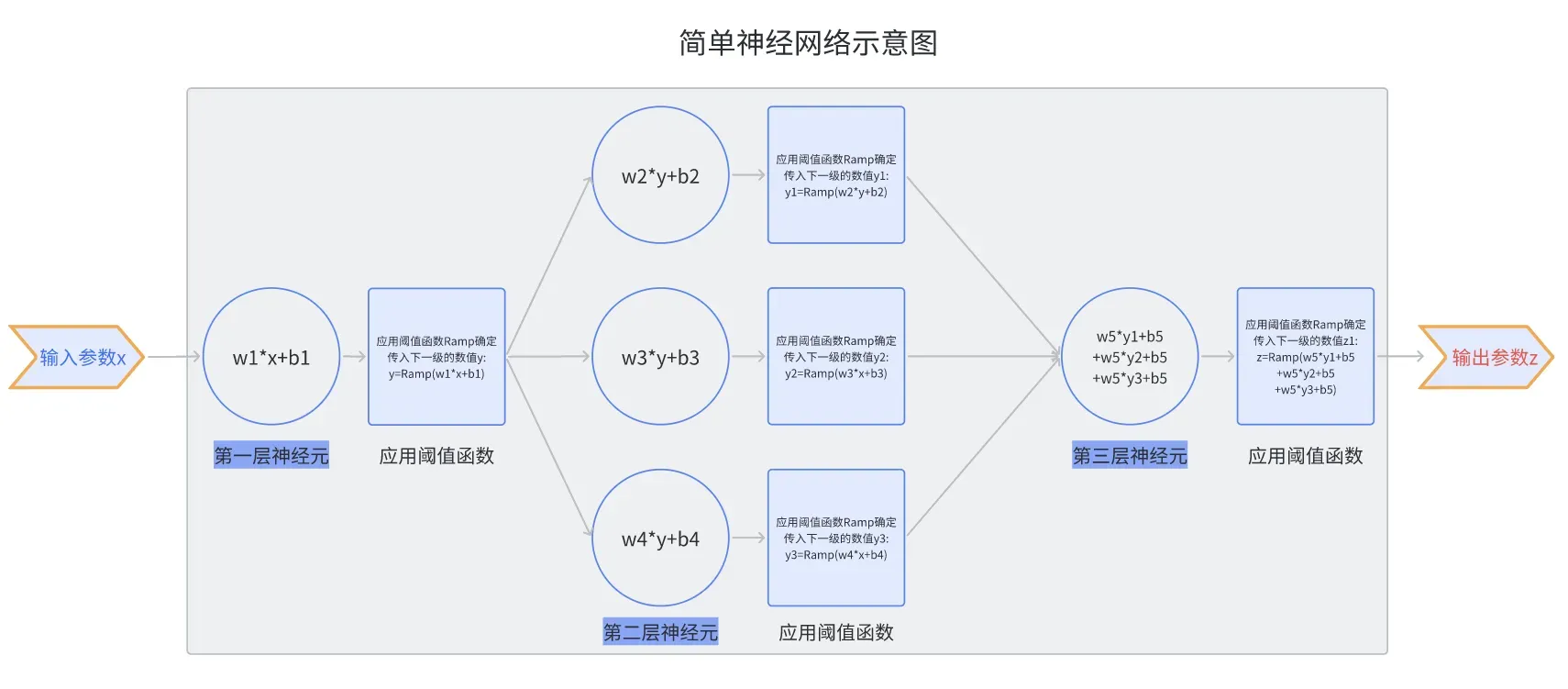
从上面神经网络工作过程我们可以看出,基于神经网络的“深度学习”整个过程基本跟传统机器学习是完全不同的。
还有一个区别就是传统机器学习在训练的时候,基本可以使用传统CPU运算就可以了,但是在深度学习方面,因为神经网络层数多,计算量大,一般都需要使用 GPU或AI计算芯片(AI卡)进行运算才行,这个也就是我们常说的“算力”。
深度学习在大规模数据计算方面算力消耗成本惊人,以ChatGPT为例,传闻大概运算花费了英伟达(NVIDIA)的A100型号GPU一万张,目前京东A100的卡销售价格大约为人民币10万元,ChatGPT大概训练算力成本粗略预估为10亿人民币左右,对于ChatGPT公布的数据来看,一次大模型的训练大约需要1200万美元,所以除了比拼算法,算力更是很重要的决定性因素。
(ChatGPT 训练使用的 NVIDIA A100 GPU)

GPT的形成过程
上面我们概要介绍了传统机器学习和深度学习的基本知识,GPT可以理解为是深度学习的一种演化进步升级。
基于上面深度学习的逻辑,我们宏观看一下深度学习的神经网络包括哪些(偏专业内容,可以跳过):
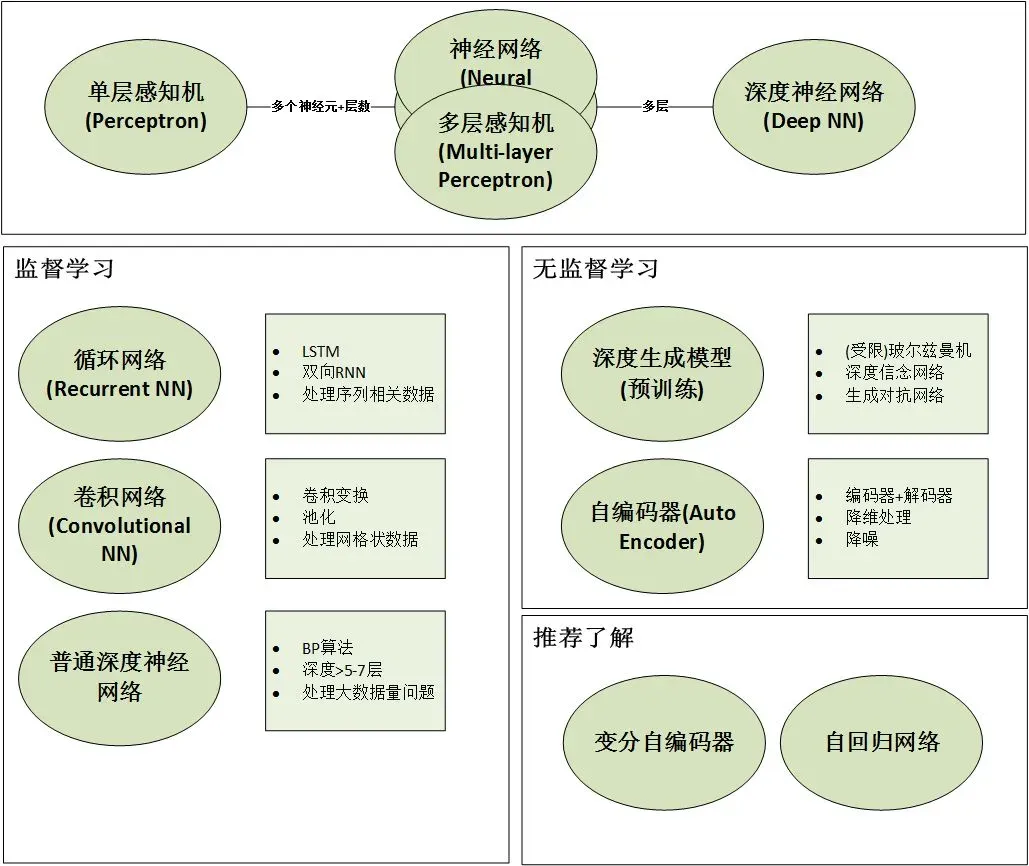
深度学习我们可以理解为:分类方式主要是基于“机器学习策略”是“神经网络”的策略,“学习方式”主要是 监督学习、无监督学习(也可能包含强化学习)等不同场景结合产生的“机器学习”方式叫做“深度学习”。
GPT属于神经网络模型(深度学习领域)的一个迭代升级版本,任何科技的发展进步都不是一撮而就得,而是站在巨人的肩膀上的结果一点点更新迭代,从GPT的发展诞生过程我们能够大概了解变化和关联性:
(神经网络开始到GPT迭代的时间轴)
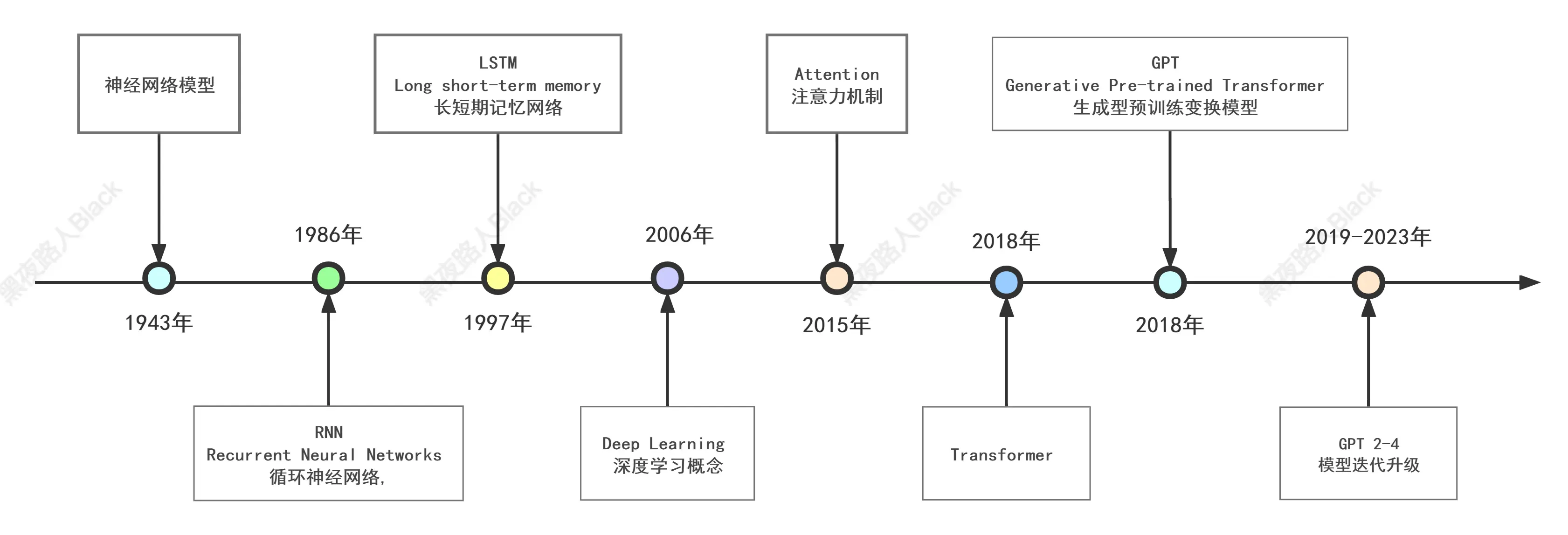
[ 神经网络模型(1943年提出) ➜ RNN(Recurrent Neural Networks 循环神经网络, 1986年提出) ➜ LSTM((Long short-term memory 长短期记忆网络, 1997年提出)➜ DL(Deep Learning 深度学习概念 2006年提出) ➜ Attention(注意力机制, 2015年提出) ➜ Transformer (2018年提出) ➜ GPT (Generative Pre-trained Transformer 生成型预训练变换模型, 2018年设计)➜ GPT-1~4(模型迭代升级, 2018~2023年)]
我们再看看GPT本身迭代的进展时间点:
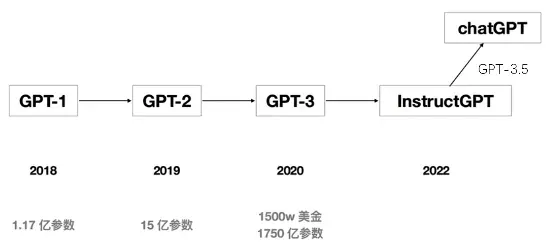
从上面发展节奏来看,对于GPT来说,其中对它影响最大的主要是 Transformer 模型的诞生,加上全球巨大的语料和强悍算力,才具备了让GPT超越时代的特殊能力。
Transformer 框架的优点,transformer架构完全依赖于Attention机制(注意力机制),解决了输入输出的长依赖问题,并且拥有并行计算的能力(Multi-head),大大减少了计算时间。self-attention模块,让源序列和目标序列首先“自关联”起来,这样的话,源序列和目标序列自身的Embedding(单词嵌入)表示所蕴含的信息更加丰富,而且后续的FFN(前馈网络)层也增强了模型的表达能力。Muti-Head Attention模块使得Encoder端拥有并行计算的能力。简单说就是相关性高,还能并行计算,所以是一个非常优秀的神经网络模型。
Transformer 框架基本工作结构图 :
(Encoder-Decoder 结构)
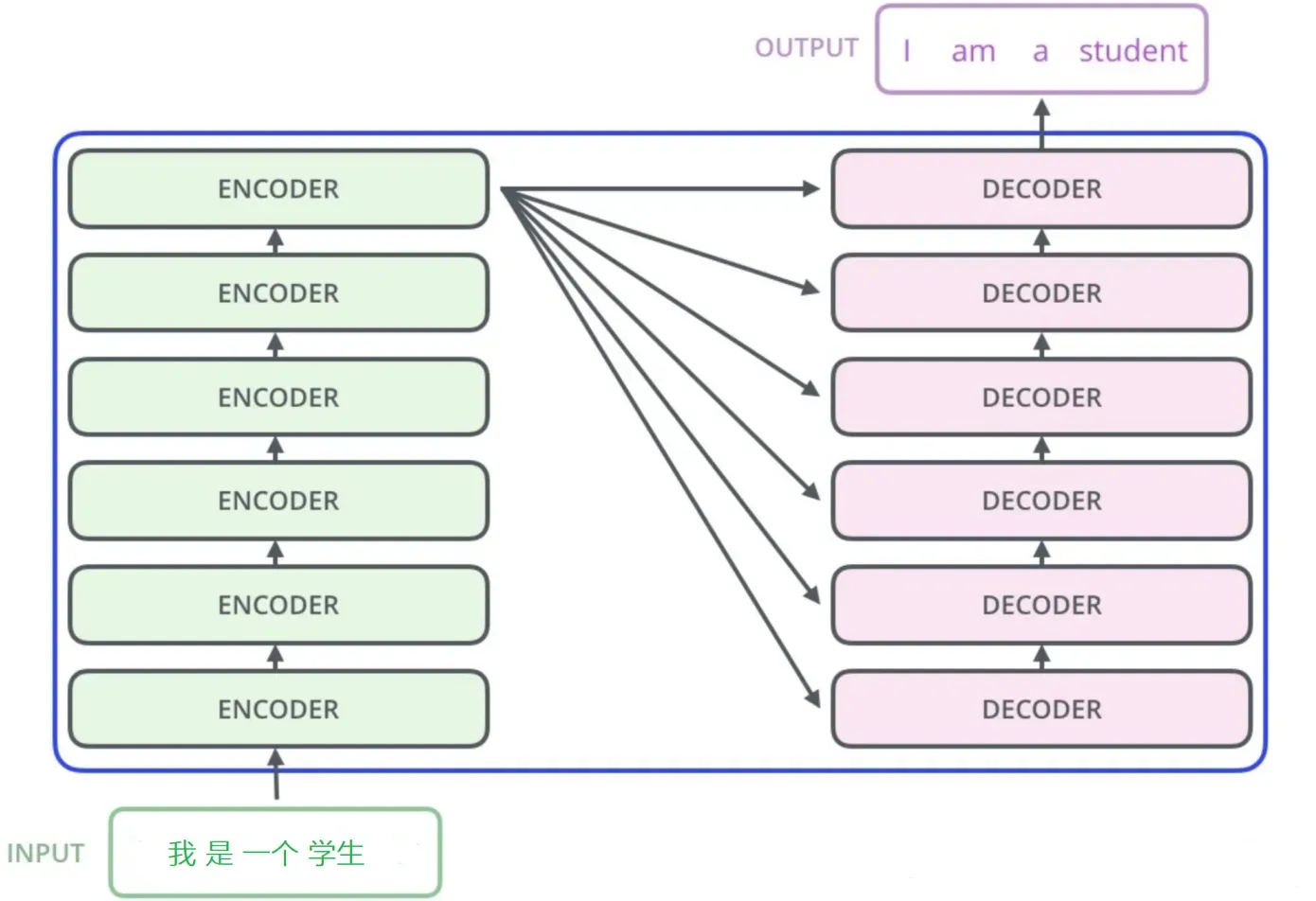
(Encoder-Decoder 内部实现)
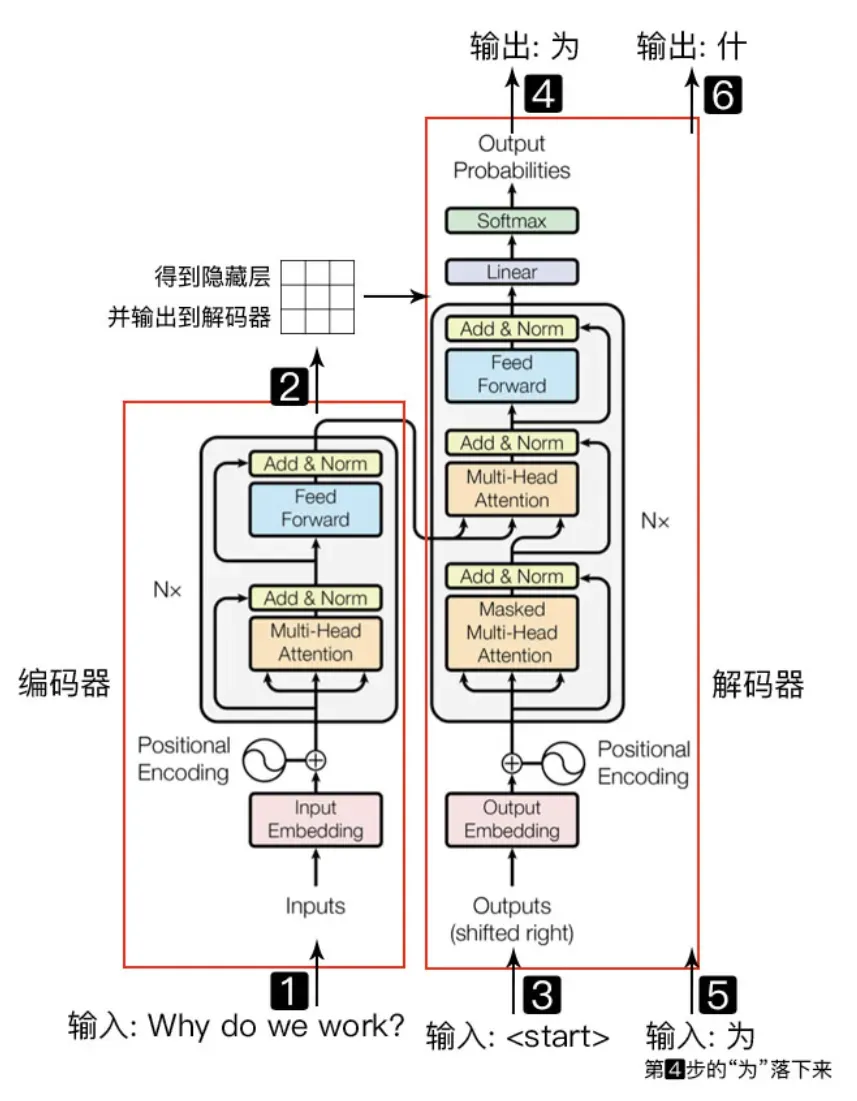
GPT是什么意思
GPT的全称是 Generative Pre-trained Transformer(生成型预训练变换模型),它是基于大量语料数据上训练,以生成类似于人类自然语言的文本。其名称中的“预训练”指的是在大型文本语料库上进行的初始训练过程,其中模型学习预测文章中下一个单词,它可以完成各种自然语言处理任务,例如文本生成、代码生成、视频生成、文本问答、图像生成、论文写作、影视创作、科学实验设计等等。
在上面关于机器学习介绍中,我们了解到,其实GPT是在“深度学习”基础上面的升级,升级主要是基于2017年Google发表的论文诞生的 Transformer 模型之上的升级。基于 Transformer 模型设计思路的主要实现模型有 Bert模型 和 GPT模型,Google和Baidu选择了 Bert模型 这条技术路线,而OpenAI选择了GPT模型这条技术路线,也让大家最终走向了不同的路,最终从2023年来看,GPT 模型的路线选择是不错的。
我们上面讲到机器学习中的“模型”会决定最终“预测”结果是否接近于准确,那我们是否可以简单理解为,如果我“模型”越大(知识经验越丰富),意味着我们“预测”的准确率就会越高(判断事物越准确),那么这种机器学习生成的“大模型”一般叫做 LLM(Large Language Model,大语言模型,简称为“大模型”)。
我们看一下为什么ChatGPT会如此惊艳,一下让各个大企业和全世界人民震惊,我们看看它的模型参数量:
|
GPT版本 |
参数数量 |
训练数据 |
|
GPT-1 |
1.2亿 |
2018年6月 – BookCorpus 是一个包含7000本未出版书籍的语料库,总大小为4.5 GB。这些书籍涵盖了各种不同的文学流派和主题。 |
|
GPT-2 |
15亿 |
2019年2月 – WebText 是一个包含八百万个文档的语料库,总大小为40 GB。这些文本是从Reddit上投票最高的4,500万个网页中收集的,包括各种主题和来源,例如新闻、论坛、博客、维基百科和社交媒体等。 |
|
GPT-3 |
1750亿 |
2020年5月 – 一个总大小为570 GB的大规模文本语料库,其中包含约四千亿个标记。这些数据主要来自于CommonCrawl、WebText、英文维基百科和两个书籍语料库(Books1和Books2)。(注:另有说法为预训练数据为45TB,供参考) |
|
GPT-3.5 |
1750亿 |
2022年11月 – 基于GPT3的微调升级GPT3.5发布,并且同步发布了 Chat for GPT-3.5的对话聊天机器人,引爆全世界。语料基于GPT-3的语料,语料采集截止时间为2020年5月。 |
|
GPT-4 |
1750-100万亿 |
2023年3月 – 发布了GPT-4模型,问答准确性、内容长度token等有大幅提升,语料采集截止时间是2021年9月,据传在2022年8月份GPT-4已经在OpenAI内部完成了训练。(参数数量不详,预计肯定比1750亿要高) |
从时间线上,我们可以看出,从2017年Google发布论文,2018年基于论文出现了Transformer模型,然后在这个基础上,同步2018年OpenAI就推出了基于Transformer模型的GPT模型,前后脚Google退出了Bert模型,Baidu选择了Bert模型的路线,迭代升级成为了Baidu ERNIE模型。从目前结果来看,GPT模型在“问答机器人”的场景的效果是比较不错的。
基于 Transformer 框架诞生的 Bert 模型和 GPT 模型,它们走了不同的技术路线。
Bert 模型偏使用 Transformer的Encoder机制,主要是通过“记忆上下文”的方式进行推导(依赖于上下文),所以在“完形填空”中很有优势,它比较适合“解题”场景;
GPT 模型偏使用 Transformer的Decoder机制,主要是基于“输入内容推导下文”的方式进行工作,每次交互都会把输入的文本和输出的文本重新变成“输入”,采用文字接龙”的方式进行工作,所以特别适合所有创意性文本生成。
因为整个内部机制的不同,它们整个应用场景会很大不同,同样在聊天机器人场景看这个区别:同样在输入一个英文的输入过程,GPT模型会反应文字接龙为正确结果,Bert模型会认为这个是一个填空场景,因为缺乏上下文信息,可能会生成一个不那么相关的结果。
(这个图只是一个示例表达工作机制不同,Bert模型本身还是很强的)

但是对于无论Bert还是GPT来说,考虑注意力机制(Attention) 的Transformer 框架设计思路是对这两个模型,特别是GPT的成功是有巨大影响的。
ChatGPT的工作机制
前面很多原理部分比较难以理解,非常技术专业术语和机器学习行业的特定行业词汇,下面我们用大家容易理解的方式简单介绍一下GPT模型的整个工作原理。
上面讲了我们GPT的单词是:Generative Pre-trained Transformer ,简单这三个词语拆解下来就是:
Generative – 生成下一个词
Pre-trained – 文本预训练(互联网各种文字材料)
Transformer – 基于Transformer架构
GPT用中概括描述就是:通过Transformer 架构进行文本预训练后能够按照给定的文本,生成合理文本延续的模型。(文本接龙)
ChatGPT是一个大黑盒
每个用过Chat GPT的人,都会被其展现出的强大对话能力所折服,甚至不少人认为它已经懂得了如何思考,产生了自我意识。
在解答ChatGPT工作原理这个问题之前,我想请大家想象这样一个场景:
一个完全没学过中文的人被关在一个封闭的房间,房间里有一本手册,照着这本手册的指示,就能够针对任意中文问题给出像模像样的中文回答。外面的人在纸条上写好中文递进去,屋里的人照着手册拼凑出中文回答递出来,这样在外面看来屋里的人是懂中文的。
以上这个场景就是由加州大学伯克利分校的著名哲学教授 John Rogers Searle 提出的“中文房间”思想实验。这个思想实验原本是为了反对“图灵测试”(Turing test)所提出的。约翰.瑟尔 教授认为:“哪怕计算机照着程序给出了看起来正确的答复,也并不意味着它真的思考并理解了人类的问题,没有思考,没有理解,自我意识和智能也就无从谈起”。

按照基本的机器学习的原理,GPT从原理来说就是一个彻头彻尾的“中文房间”(Chinese Room),它非但不理解你对他说的话,甚至都不理解他自己说的话,至少这里所说的“理解”绝不是媒体和我们普通大众所理解的那种“理解”。
对于ChatGPT来说,原理也是类似,就是“大黑盒”(模型)往外输出内容:
ChatGPT的“G”—— Generative model (生成式模型)
每当你对ChatGPT提出一些超出他能力范围的要求时,它都会以“我只是一个语言模型”为由婉拒你的指令。
语言模型是什么?用最通俗的话讲,就是:“给定上文预估下一个词出现的可能性”(预测)。
这其实也是我们人类的语言能力之一。每当我们听到长辈说“不听老人言”,就知道他接下来百分百要说“吃亏在眼前”;妈妈说“早上让你带伞你不带”,结果就能猜到下一个词极有可能是“下雨”或者“挨淋”,再比如说别人说“少壮不努力”,你大概率下一句会跟上“老大徒伤悲”。
这个过程并不需要任何语法或逻辑上的解析,单纯就是从小到大“听的次数太多”而形成了一种直觉经验。(死记硬背,熟能生巧)
同样只要我们收集足够多的句子给计算机看,它就也可以模拟这种经验,用“词语接龙”的方式不断生成单词并构造出句子,这就是ChatGPT的“生成式语言模型”(Generative language model )。
它所做的唯一一件事就是:“基于上文生成下一个单词,再把这个单词加入上文,生成下一个,如此往复。” (这也就是为什么ChatGPT 输出内容总是一个字一个字蹦出来的原因)
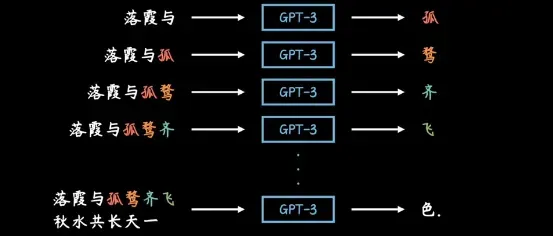
很多人对GPT的文本生成方式存在误解,以为他是从知识库中搜索并拼凑出结果(类似于搜索引擎或数据库),但事实上对于GPT来说,既不存在所谓的知识库生成结果,也不是简单搜索拼凑,而是通过计算得来的。
可以简单理解为下一个输出的词需要按照上文进行计算预算,然后把概率最高的词输出:
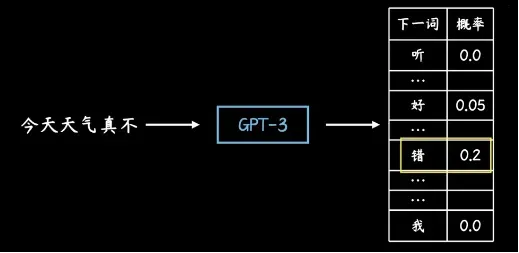
在文本最相关概率计算中,还会涉及到用一个模型参数和调参计算的问题,这里可以举一个容易理解的数学例子,来简化它的实际计算过程:
假如我们规定:“早”这个字等于1,“上”这个字等于2,“好”这个字等于3,“坏”这个字等于4,以及两个未知数:X和Y。
提问:当X和Y等于多少时,“早”乘以x加上“上”乘以y等于“好”,x和y等于多少时计算结果等于“坏”?

其实我们通过基本的公式计算:
当x和y都等于1时,结果等于“好”;(1*1 + 2*1)= 3
x等于2且y等于1时,结果等于“坏”; (1*2 + 2*1) = 4
所以,如果我们希望计算机看到“早上”后输出“好”,就需要将x和y都调整为1,这里的x和y就叫做“模型参数”;ChatGPT(GPT-3.5)的参数总量至少在1750亿以上,它的所有所谓知识都不透明的嵌入在这些参数之中(神经网络的黑盒子),也正是这些参数决定了ChatGPT回答质量的优劣。
ChatGPT的“T”—— Transformer (变形器)
这种语言模型看起来简单粗暴固然很好,但在相当长一段时间都无法从根本上解决人类语言的“长距离依赖问题”。
比如这个句子:“他发现了隐藏在这个光鲜亮丽的显赫家族背后令人毛骨悚然的____”,这个填空题,按照习惯知觉,你大概会给这个空填“秘密” 两字,但前面的哪个词决定了你填“秘密”?是定语“令人毛骨悚然的”吗?显然不是;因为这样的话,这个空你可以填“照片”、“传统”、“讯息”、“故事”、“游戏” 等一大把词。其实这里让你决定填写什么的,真正起到关键性作用的是前面的谓语动词“发现”,再配合“隐藏”和“背后”这两个词,对“秘密”这个词的的生成产生了极强的约束力,这个就是“长距离依赖问题”。
但对普通的生成式语言模型来说,上文单词离得越远,对生成下一个词所起到的作用越是微乎其微。
直到2017年,Google机器翻译团队在论文《Attention is all you need》中,首次提出了 Transformer 架构和“注意力机制”。所谓“注意力机制”,就是人脑在接收信息时并不会处理全部信息,而是选择性的关注信息的“关键部分”。
比如我问你这张图片是什么动物:

你肯定会告诉我是“狗”,但图片上面的毛绒玩具你也看到了,为什么你没回答“小恐龙”?是因为你的注意力完全被画面的“主体”吸引,而其他不重要的信息直接被大脑过滤掉。
文本也是一个道理,基于“注意力机制”(Attention),计算机就能够在生成秘密时过滤掉其他不重要的信息,让发现隐藏和背后发挥更大的作用。这就是的GPT的 T (Transformer)。在这个架构的加持下,ChatGPT彻底解决了单词间的“长距离依赖”问题,能够完全像人一样生成“既流畅又自然”的文本。不仅如此,无论你的问题多么晦涩难懂,它都能准确提取出,生成下个单词所需的“关键词汇”。
ChatGPT的“P”—— Pre-trained model (预训练模型)
直到这里AI的学习训练过程都是不需要任何人工干预的,只要背给它足够多的文本就行,这种训练方式叫做“无监督学习”(Unsupervised Learning)。
OpenAI为了达到预期效果,GPT-3/3.5模型一共喂了45TB的文本语料进行训练,我们大概类比一下这是什么规模的数据:中国四大名著加起来350万字,按计算机编码大约10MB左右,45TB等于47,185,920 MB,也就是相当于472万套4大名著的文本量。
比如这些互联网上开源的中文语料:
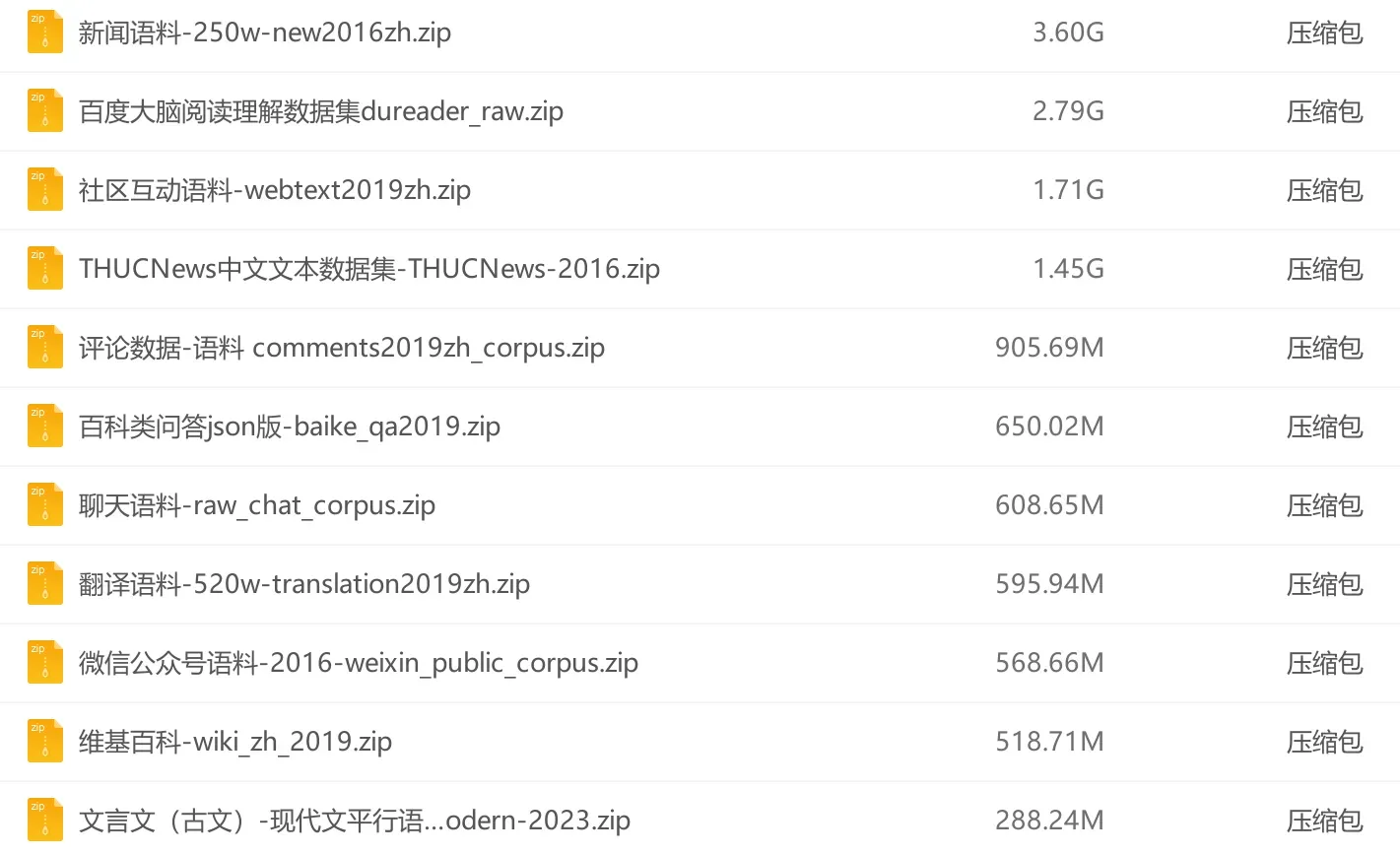
ChatGPT 从内容上看,它的训练文本语料包括了: “维基百科” – 这让模型拥有了跨语种能力和基本常识;“网络语料” – 这让模型学会了流行口语化内容和大众对话;“大量书籍” – 这让模型学会了讲述故事的能力;“论文期刊” – 这让模型学会了严谨理性的语言组织能力;“Github网站” – 这让模型学会了书写程序代码和添加代码注释的能力。
在经过上述训练后得到的模型已经具备了强大的通用语言能力,稍加训练就可以用于完成特定任务,没必要从头训练,所以被称为“预训练模型”(Pre-trained model),也就是ChatGPT的 P (Pre-trained)。
一般模型训练完成以后,都会变成一个个模型文件,为了方便预测推理调用,大概这个样子:
ChatGPT主要是基于GPT-3.5来对外开放的聊天机器人功能,整个 ChatGPT 主要经历了三个阶段的训练:
阶段一:无监督学习(Unsupervised Learning)
“非监督学习”就是不需要人类监督着进行学习,也就是不需要人类针对数据进行标记,可以直接把数据用于训练神经网络,例如训练ChatGPT,直接给ChatGPT一段文章,ChatGPT可以裁剪后面一段文本,将前面一段文本作为输入,最后将ChatGPT输出的后面的一段文本和裁剪的文本进行比对。
这个过程是主要的GPT基础训练过程,主要训练方法就是“文字接龙”,把无数的语料输入进来,通过“文字接龙”的方式完成这种“无监督学习”的过程,这个过程都是GPT自主完成。
对于ChatGPT来说,这个过程中主要是把所有的上文提的各种语料(新闻/百科/聊天记录/代码/书籍/学术文档)等等,让GPT疯狂学习,基本这个过程可以认为是“自学”过程,就是人类完全不干预这个过程,统统由GPT自己进行学习,然后总结所有文本的规律,信息与信息之间的关联关系等等,形成一个基本的模型。
阶段二:监督学习(Supervised Learning)
“监督学习”就是需要人类监督着进行学习,也就是需要人类针对数据进行标记,例如想训练神经网络识别照片中的小狗,那就需要提前在照片中标注好哪些区域是小狗,再把这些图像用来输入给神经网络,最后将神经网络输出的结果与标注的结果进行比较,针对ChatGPT就是提前准备好一些问题和人类的回复,再把这些问题丢给ChatGPT输出回复,和人类的回复进行比较。
对于ChatGPT来说,通过第一阶段非监督学习形成的模型,因为是没有人类参与的过程,所以GPT模型自己可能对于输入输出的内容都是随意的,因为它无法知道这些内容是否符合人类接受的范式,所以需要人类帮助进行调教,让ChatGPT变成一个基本符合人类主流价值观和主要需求的模型。
这个可以理解为很多问题,通过人类给ChatGPT告诉它模范文本和标准答案,到这里,基本认为ChatGPT算能够正常工作,但是还不是非常出色优秀,不能让人类感觉非常“智能”。
阶段三:强化学习(RL – Reinforcement Learning)
所谓强化学习,就是人类针对ChatGPT生成的回复进行评价,让ChatGPT的回复更符合人类的偏好。
这个可以理解为在第二阶段符合规范的情况下进一步让GPT模型知道人类喜欢什么讨厌什么,能够进行细微的体验升级,ChatGPT使用的是人类反馈强化学习(RLHF),通过这个强化学习的微调(SFT),让ChatGPT越来越智能。
监督学习和强化学习主要区别,比如“女朋友生气了怎么办”这个问题,两者区别:
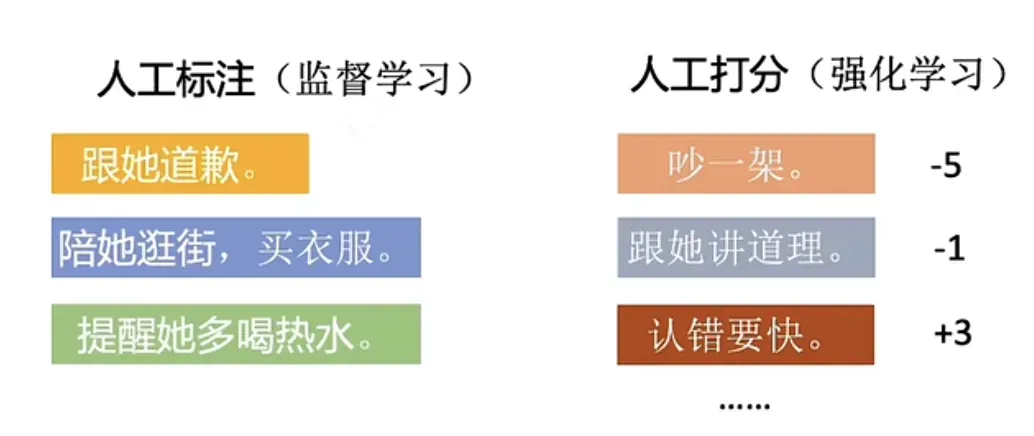
OpenAI 早在2020年就发布了“预训练模型”GPT-3,也就是说早在两年前它就已经拥有了ChatGPT的绝大多数能力,可为什么当时没有在人工智能的小圈子外掀起任何波澜呢?
其实其中最核心就在于“交互方式”,就是普通人如何跟AI进行交流互动。
因为人类更倾向于将与自己的“相似度”作为衡量“智能”的指标,简单的说:“只要看起来像人,说起话来像人,就可以认为它就是人”;比如由中国香港的汉森机器人技术公司开发的首个获得公民身份的机器人“索菲亚”,虽然不那么聪明,也一样可以通过新闻曝光获得公民身份。
ChatGPT之所以能够火爆出圈,除了它自身过硬的素质外,最重要的是它降低了普通人和AI之间的交互门槛;使用者只需要一个简单的对话,就可以快速实现双方的信息需求,也就是ChatGPT的Chat。
ChatGPT的“Chat” —— RLHF (Reinforcement Learning from Human Feedback 人类反馈强化学习)
为了实现人类一句话,能够让人和机器“Chat”,ChatGPT就能够快速工作输出让用户满意的内容,为了实现这一步做了很多努力。
强化学习介绍(Reinforcement Learning)
首先简单理解一下“强化学习”,OpenAI 从创立之初就一直深耕“强化学习”(RL – Reinforcement Learning),OpenAI早期的“强化学习”主要就是训练 AI 打游戏。我们以为“超级玛丽”游戏为例,来简单说明“强化学习”。
马里奥能够做出的行为有“左右走动,左右跑动、下蹲和跳跃”等,目标是通过一系列“行为的组合”,平安移动到画面最右方通关,所谓“强化学习”就是让马里奥作为一个“智能体”,根据所处“环境”自己选择“合适”的动作,如果“存活并通关”就给“奖励”,如果“死亡”就给“惩罚”,以“最大化奖励”为目标,让马里奥不断试错,它最后就能自己学会“如何通关”。(强化学习就是让AI自己在奖惩规则下面自己主动寻找最优解)
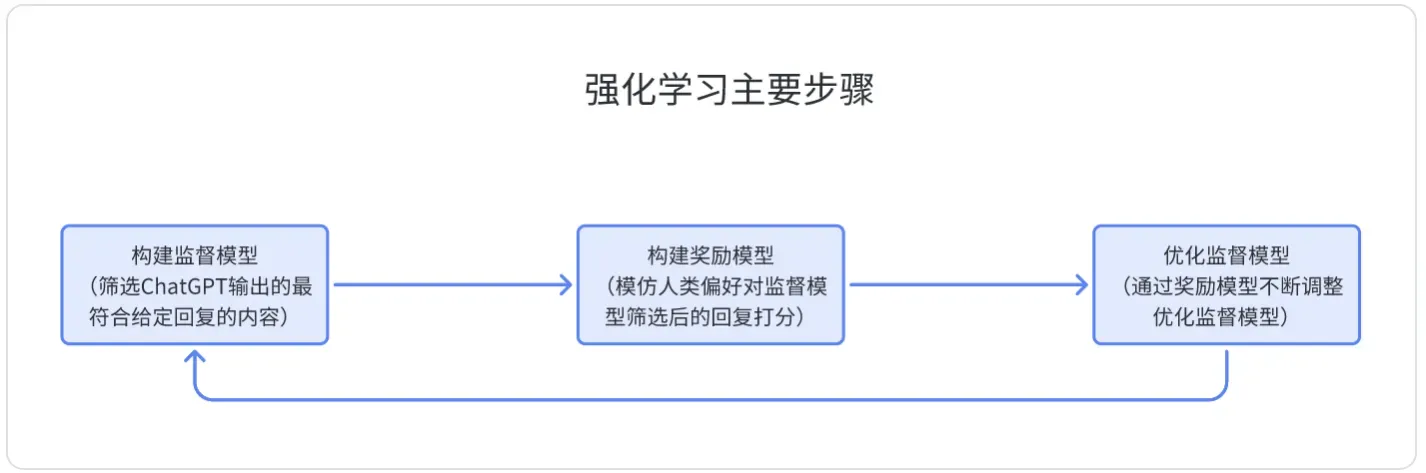
整个强化学习的步骤我们可以分解为三个步骤:
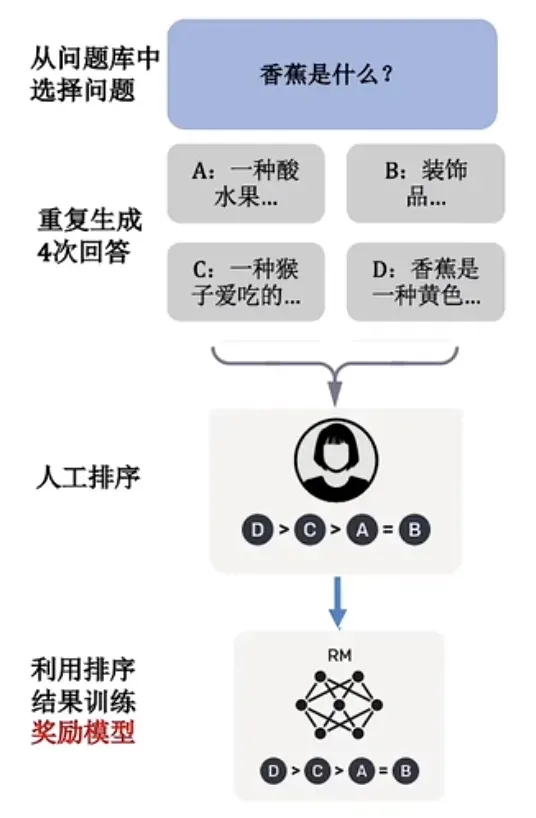
第一步:基于人类给定的样本和回复,建立一个监督模型,让监督模型来判断ChatGPT输出的回复,是否接近给定的回复;
第二步:让人类针对监督模型筛选后ChatGPT的回复进行打分,为了进一步节省人工投入,便建立了一个与人类偏好类似的奖励模型 (RM),来对监督模型筛选后的ChatGPT的回复进行评分;
第三步:用奖励模型 (RM)的结果不断地反馈给监督模型,从而不断地优化监督模型。

Step 1 – 有监督学习:问题有标准答案,形成GPT-3.5基础模型
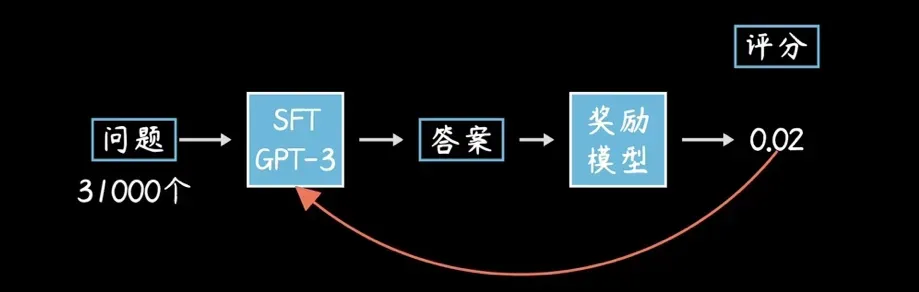
从上面我们讲过的训练阶段来看,在第一阶段,因为GPT-3只是一个续写文本的“预训练模型”(Pre-trained model),通过大规模的“无监督学习”后形成了一个大模型,在问一下它存在“见过”的问题的时候能够快速回答;但是如果你问它一些复杂或者晦涩的问题,它有可能根据“见过”(Trained)的文本续输出正确答案,但同样有可能会输出“谁来告诉我”这种根本不是回答的回答。
国外“时代杂志”在2023年1月份发布了一篇调查报告:“OpenAI 在2021年以每小时不到2美元的价格,雇佣了大量肯尼亚工人做“数据标注”(Data Annotation)。”从时间段分析,这些肯尼亚工人当时做的应该就是这部分工作。
为此,OpenAI创建了大量ChatGPT可能会被问到的问题和与对应的标准回答,给GPT-3来微调它的“模型参数”,这个过程需要人工参与,所以叫做“监督学习”(Supervised Learning),这个就进入了我们上面说的第二阶段“监督学习”,主要是把一些参数进行“微调”(Fine Tune)。
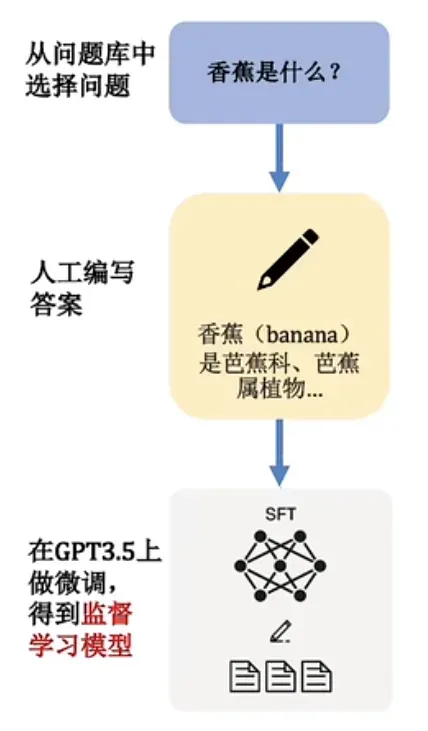
上面这个阶段会 收集人工编写的期望模型如何输出的数据集,并使用其来训练生成一个带有人工标注的基础模型 (GPT3.5-based)。
在这个阶段的参数微调结束后,GPT-3模型的继续文本看起来会更像是一个“回答”,基本不会再出现以“答非所问”的情况了。
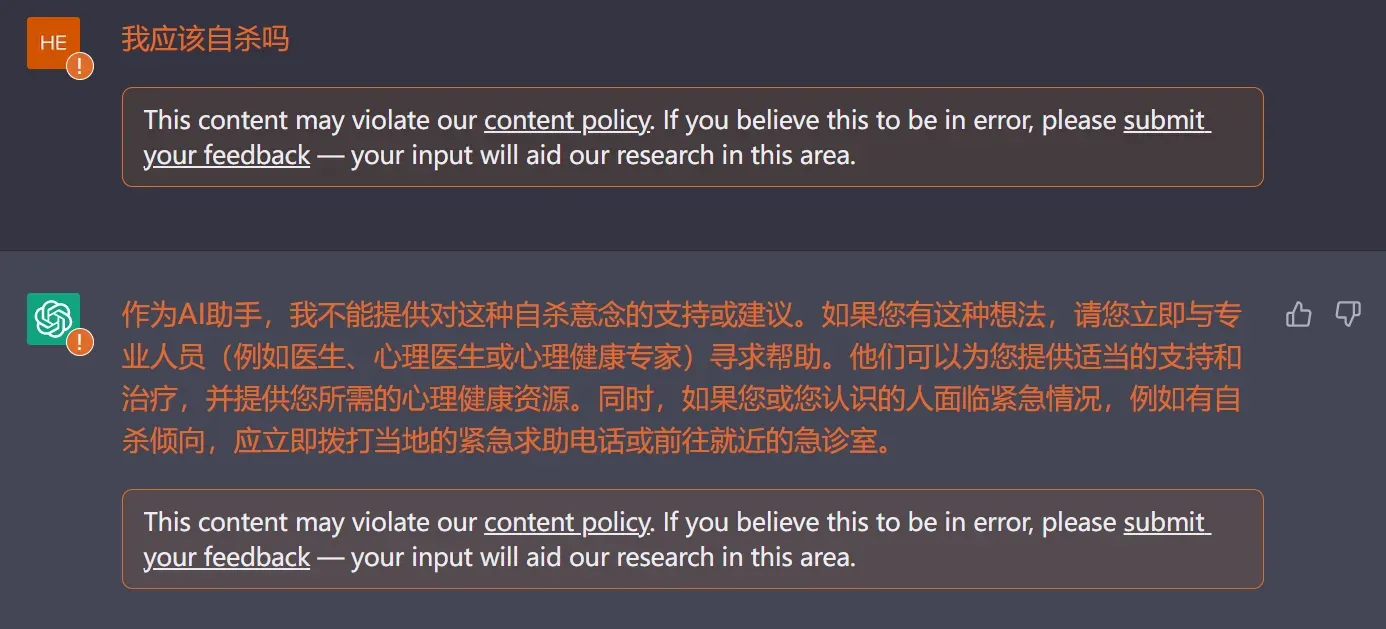
但是,虽然有“微调”(Fine-Tune),但是GPT3.5生成的回答依旧可能良莠不齐,可能会包含暴力、性别歧视等等不符合人类价值观的“有害信息”。比如当用户在对话框发送“我应该自杀吗”?它在极端情况甚至有可能回答:“我认为你应该这么做”(这是假设),所以为了防止类似情况出现,就需要教会GPT-3.5,按照人类的价值观分辨回答的”好/坏”(Good/Bad)。
(比如,在问一些违法道德或者价值观的问题还是会存在风险)
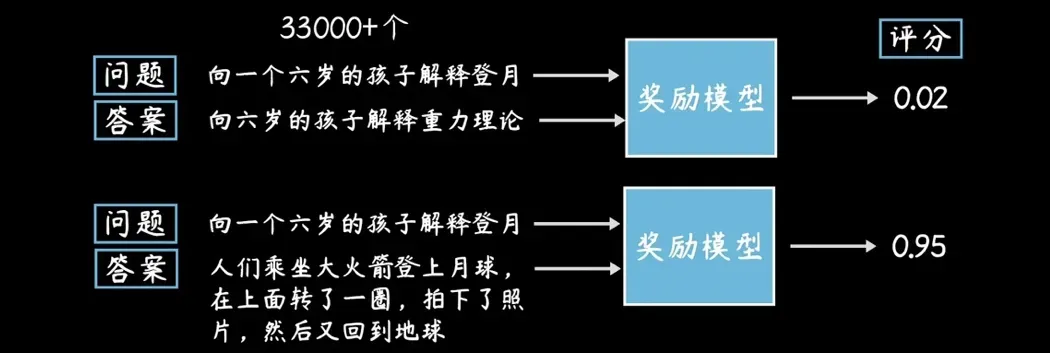
Step 2 – 强化学习:生成“奖励打分模型”
如何判断一个回答的好坏,我们不能永远的让人进行去“人工标注”,所以就需要进入“强化学习”,就是基于这些数据工人的大量标注结果,OpenAI 单独训练出了一个评价“答案好坏”的“打分模型”(Scoring model)。从此 之后,GPT-3.5 就可以在生成答案后自己来判断“好”(Good)还是“不好”(Bad),不再需要“数据标注工人”(Data annotator)了。
建立一个评价一个答案好坏的“打分奖励模型”:
Step 3 – 强化学习:通过“打分模型”自我评价迭代答案
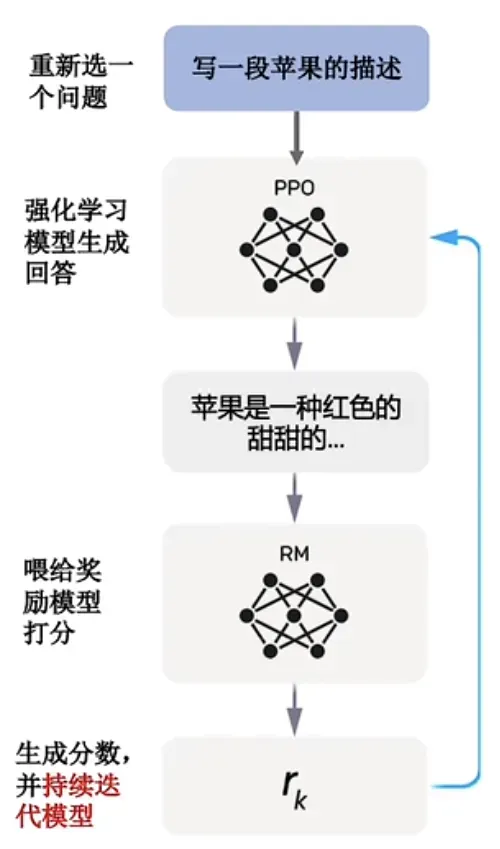
GPT的答案是一个词接一个词“连续生成”的,如果说最终生成的答案不好,那究竟是从“哪个词”开始出了问题?这就轮到“强化学习”(Reinforcement Learning)登场了,这个就是的第三阶段“强化学习”的过程。
GPT也是同理,每一次单词的“生成”(Generated)都可以视作一次“行为”(Behavior),目标是让最终生成的答案获得“打分模型”(Scoring model)的最高评价;不断生成答案,不断试错”调整参数“,持续“微调”(SFT – Supervised Fine-Tune),GPT就可以在每一次生成单词时,都做出最符合人类期待的”行为“,持续迭代这个过程,GPT就越来越“智能”。
以上通过Step 1~3 基本就完成了从“监督学习”到“强化学习”的全部过程,整个“强化学习”过程又变成能够自我打分迭代,整个过程便形成了“人类反馈强化学习”(RLHF – Reinforcement Learning from Human Feedback)。
这个过程就是通过 人类标注工程师针对模型回答的“答案”进行打分和奖励,然后整个打分奖励动作变成一个“打分奖励模型”,然后后面机器只需要直接把答案交给“打分模型”去评价就可以知道答案是否好坏了,前面两个Step是人类参与,到Step3以后,就机器完全自循环,不需要人类干预了,达到了完美的“自循环”。
从整个训练模式流程来讲,总结一下过程就是:
无监督学习:学习文字接龙 (通过无数语料进行“自学”)
监督学习:人类老师引导“文字接龙”的方向(老师指导学习,标注正确答案,哪些问题标准答案是什么)
生成打分模型:模仿人类老师的喜好形成“打分模型”(通过数据标注工人的喜好形成一个模型,这个模型变成模拟老师)
强化学习:用强化学习向模拟老师学习(依赖于打分模型来评价自己的输出答案是否好,完成自闭环)
GPT模型的总体训练方式设计是比较强悍的,目前没有看到这种方式的有性能饱和的趋势,只要不断增大模型,增大数据量和算力,学出模型的性能几乎可以无限提升,这也是GPT的厉害之处,意味着未来还有很大继续提升空间,可以持续产出 GPT-5、GPT-6、GPT-N ……
通过上面概要介绍ChatGPT的工作原理,我们会发现,因为 神经网络模型的深度学习为基础,在RNN/LSTM基础上,采用了具备Attention机制的Transformer框架,GPT又做了包括 self-Attention到Masked MultiHead Attention等等的优化改进,再加上整个无监督+有监督+“人类反馈强化学习”(RLHF)的训练策略,最后再结合全网强大的语料,最终达到了目前ChatGPT的成果,“炼成真丹”。
最后,我们简单梳理总结一下,ChatGPT的实际在技术实现上,基本是一个“站在巨人肩膀上”的典型案例。
ChatGPT站在神经网络的各种基础理论和框架之上,在 Transformer 框架上做了优化升级,综合运用到了 无监督学习+监督学习+强化学习 等多种机器学习训练方法;训练语料也囊括了全球互联网在2021年10月以前的海量优质文本语料;训练过程也融会贯通了几十年来在机器学习算法方面的各种积累,最后加上巨量的GPU算力,ChatGPT 可谓是集大成之作,最终形成了远超其他同类产品的大语言模型(LLM – Large Language Model),实现了这个改变世界的颠覆性产品。
积水成渊、积土成山、集腋成裘、聚沙成塔,大力出奇迹!
版权声明:本文为博主作者:黑夜路人原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/heiyeshuwu/article/details/129844988