之前,向大家介绍过3D分子生成模型 GeoLDM。

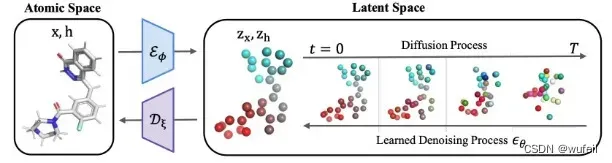
GeoLDM按照Stable Diffusion架构,将3D分子生成的扩散过程运行在隐空间内,优化了基于扩散模型的分子生成。可能是打开Drug-AIGC的关键之作。让精确控制分子生成有了希望。
详见:分子生成领域的stable diffusion – GEOLDM-CSDN博客)
作者提供了GitHub代码:https://github.com/MinkaiXu/GeoLDM。
因此,我特意测试了一下代码质量。
一、代码测试
首先 git clone 项目代码:
git clone https://github.com/MinkaiXu/GeoLDM.git项目目录为:
.
├── LICENSE
├── README.md
├── build_geom_dataset.py
├── configs
├── data
├── egnn
├── equivariant_diffusion
├── eval_analyze.py
├── eval_conditional_qm9.py
├── eval_sample.py
├── main_geom_drugs.py
├── main_qm9.py
├── qm9
├── requirements.txt
├── train_test.py
└── utils.py
6 directories, 11 files其中,qm9文件夹包含了qm9数据集预处理到dataloader的方法,qm9数据集会自动下载train, valid, test分割好的数据集;drug数据则需要自己下载,然后执行build_geom_dataset.py(见下文)。
1.1 环境安装
安装torch及其组件, rdkit, numpy,tqdm等(macOS系统):
conda install pytorch::pytorch torchvision torchaudio -c pytorch
conda install -c conda-forge rdkit
conda install numpy pandas scipy tqdm
conda install imageio
pip install msgpack # 时序数据库安装过程比较简单,没有遇到任何问题。
1.2.1 下载数据集及预处理
在git clone下来的代码中,并没有包含数据集,无法直接进行模型的预测或者训练。
qm9数据的下载链接要参考之前edm文章。
drugs数据集的数据下载链接:https://dataverse.harvard.edu/file.xhtml?fileId=4360331&version=2.0
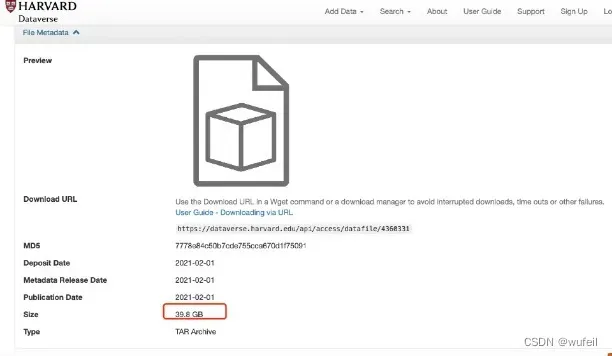
下载文件很大,压缩文件39.8G。
数据集文件,要下载到/data/geom目录。
cd ./data/geom
# -t 0 -c 断点接续下载
wget -t 0 -c https://dataverse.harvard.edu/api/access/datafile/4360331要下载这个数据集,请务必科学上网,在6MB/s的速度下,我下载了2h。
下载完成后,解压:
tar -xzvf 43603311.2.2 预训练checkpoint
作者提供了训练好的模型checkpiont,包括QM9和Drug数据集的两个checkpoint,下载链接为:
https://drive.google.com/drive/folders/1EQ9koVx-GA98kaKBS8MZ_jJ8g4YhdKsL

其中, Drug数据集是 GEOM-DRUG (Geometric Ensemble Of Molecules) datase,由更大的有机化合物组成,最多有 181 个原子,平均有 44.2 个原子,有 5 种不同的原子类型。 它涵盖了大约 450,000 个分子的 3700 万个分子构象,并标有能量和统计分子质量。
这两个checkpoint的训练超参数与作者提供的训练模型的超参数完全一致,除了–latent_nf参数值为2,但是结果应该与值为1相近,没有差别。
注意:下载完成的checkpoint要放置在./outputs/pretrained文件夹内,该文件夹是新建的。当使用模型时,应该将–model_path参数设置为:./outputs/pretrained。
1.3 使用checkpoint模型测试
我们尝试直接使用作者提供的checkpoint进行模型的测试。
1.3.1 评估模型生成分子的正确率与新颖性
python eval_analyze.py \
--model_path outputs/pretrained \
--n_samples 10但是会报错:
FileNotFoundError: [Errno 2] No such file or directory: ‘outputs/pretrained/args.pickle’
这个是因为下载的模型checkpiont文件是压缩tar文件,需要解压:
tar -zxvf drugs_latent2.tar
tar -zxvf qm9_latent2.tar 然后再次执行,需要指定评估的是哪个模型,这里指明是drugs_latent2:
python eval_analyze.py \
--model_path outputs/pretrained/drugs_latent2 \
--n_samples 10会输出报错:
./data/geom/geom_drugs_30.npy
查看了一下,确实没有这个目录。这个可能是Drug数据集数据处理以后才能有的。
在执行完2.2.1下载数据集及预处理部分drugs数据集的预处理以后,即可运行。在等待数据划分和加载的2分钟左右时间以后,输出为:
Namespace(exp_name='rld_fixsig_enc1_latent2_geom_drugs', train_diffusion=True, ae_path=None, trainable_ae=True, latent_nf=2, kl_weight=0.01, model='egnn_dynamics', probabilistic_model='diffusion', diffusion_steps=1000, diffusion_noise_schedule='polynomial_2', diffusion_loss_type='l2', diffusion_noise_precision=1e-05, n_epochs=3000, batch_size=32, lr=0.0001, break_train_epoch=False, dp=True, condition_time=True, clip_grad=True, trace='hutch', n_layers=4, inv_sublayers=1, nf=256, tanh=True, attention=True, norm_constant=1, sin_embedding=False, ode_regularization=0.001, dataset='geom', filter_n_atoms=None, dequantization='argmax_variational', n_report_steps=50, wandb_usr=None, no_wandb=False, online=True, no_cuda=False, save_model=True, generate_epochs=1, num_workers=0, test_epochs=1, data_augmentation=False, conditioning=[], resume=None, start_epoch=0, ema_decay=0.9999, augment_noise=0, n_stability_samples=500, normalize_factors=[1, 4, 10], remove_h=False, include_charges=False, visualize_every_batch=10000, normalization_factor=1.0, aggregation_method='sum', filter_molecule_size=None, sequential=False, cuda=True, context_node_nf=0, current_epoch=13, device=device(type='mps'))
Entropy of n_nodes: H[N] -3.718651056289673
Autoencoder models are _not_ conditioned on time.
alphas2 [9.99990000e-01 9.99988000e-01 9.99982000e-01 ... 2.59676966e-05
1.39959211e-05 1.00039959e-05]
gamma [-11.51291546 -11.33059532 -10.92513058 ... 10.55863126 11.17673063
11.51251595]
# 以下为输出的评估结果
10/10 Molecules generated at 70.12 secs/sample
Validity over 10 molecules: 100.00%
Uniqueness over 10 valid molecules: 100.00%
{'mol_stable': 0.0, 'atm_stable': 0.8647540983606558}
#输出
Validity 1.0000, Uniqueness: 1.0000, Novelty: 0.0000
Val NLL , iter: 0/21633, NLL: -188.43
Val NLL , iter: 50/21633, NLL: -313.57
Val NLL , iter: 100/21633, NLL: -354.71
Val NLL , iter: 150/21633, NLL: -376.12
Val NLL , iter: 200/21633, NLL: -379.55
Val NLL , iter: 250/21633, NLL: -385.54
Val NLL , iter: 300/21633, NLL: -391.25
... ...
inal test nll -765.8581615602465
Overview: val nll -653.3101636028102 test nll -765.8581615602465 {'mol_stable': 0.0, 'atm_stable': 0.8647540983606558}评估结果显示,drugs模型生成分子的稳定性为100%, 原子的稳定性为0.86。在10个分子的测试中,分子有效率为100%,独特率为100%, 在有效的分子中,新颖分子的比例是0.0% ?(这有点奇怪)。
qm9模型可以直接运行,无需数据预处理,因为测试所需的处理好的数据文件geom_permutation.npy, 在./data/geom/目录下有,所以可以直接测试。因此,接下来,我们直接评估qm9模型:
python eval_analyze.py \
--model_path outputs/pretrained/qm9_latent2 \
--n_samples 10在经历一长串的obabel输出以后,会出现评估的结果,如下:
# obabel输出示例
[09:39:51] Explicit valence for atom # 4 N, 4, is greater than permitted
[09:39:52] Explicit valence for atom # 5 N, 4, is greater than permitted
[09:39:52] Explicit valence for atom # 3 N, 4, is greater than permitted
[09:39:52] Explicit valence for atom # 3 N, 4, is greater than permitted
[09:39:53] Explicit valence for atom # 2 C, 5, is greater than permitted
## 以下为评估输出结果
Validity over 10 molecules: 90.00%
Uniqueness over 9 valid molecules: 100.00%
Novelty over 9 unique valid molecules: 66.67%
{'mol_stable': 0.9, 'atm_stable': 0.9890710382513661}
Validity 0.9000, Uniqueness: 1.0000, Novelty: 0.6667
## 再然后,会有一系列漫长的输出:
Test NLL , iter: 17/205, NLL: -329.98
Test NLL , iter: 18/205, NLL: -330.06
Test NLL , iter: 19/205, NLL: -330.09
Test NLL , iter: 20/205, NLL: -329.89
Test NLL , iter: 21/205, NLL: -329.95
Test NLL , iter: 22/205, NLL: -330.03
Test NLL , iter: 23/205, NLL: -329.87
## 最终输出
Test NLL , iter: 204/205, NLL: -331.61
Final test nll -331.6104668697505
Overview: val nll -332.37032418705627 test nll -331.6104668697505 {'mol_stable': 0.9, 'atm_stable': 0.9890710382513661}评估结果显示,qm9模型生成分子的稳定性为0.9, 原子的稳定性为0.98。在10个分子的测试中,分子有效率为90%,独特率为100%, 在有效的分子中,新颖分子的比例是66.7%。
在测试评估过程中,会在qm9文件夹下,新建一个tmp的文件夹,用于保存生成的文件,运行结束后,tmp的内容如下:
├── qm9
│ ├── dsgdb9nsd.xyz.tar.bz2
│ ├── test.npz
│ ├── train.npz
│ └── valid.npz
└── qm9_smiles.pickle接下来对刚才的评估结果可视化:
python eval_sample.py --model_path outputs/pretrained/qm9_latent2 --n_samples 10输出结果示例:
Average distance between atoms 2.941699266433716
Average distance between atoms 3.102877378463745
Average distance between atoms 3.127577066421509
Average distance between atoms 3.1570422649383545
... ...
Sampling visualization chain.
Found stable molecule to visualize :)
Creating gif with 108 images
Found stable molecule to visualize :)
Creating gif with 108 images
Found stable molecule to visualize :)
... ... 输出非常慢。。。当然也可能是我待机的原因其中出图是一个很慢的过程。输出的可视化结果,保存在/outputs/pretrained/qm9_latent2/eval/molecules路径。其文件目录结构如下:
.
├── chain_0
├── chain_1
├── chain_2
├── chain_3
├── chain_4
├── chain_5
├── chain_6
├── chain_7
├── chain_8
├── chain_9
....
└── molecules其中, molecules为所有的分子。chain_x为去噪过程中,生成分子的图片记录,每个文件夹下均有一个gif文件,为每个分子的动态生成过程,即每一个chain_x对应一个分子的生成过程。每个gif都有108张图片生成。进行到一半,我就kill了,太耗时间了。
注意,生成的分子是txtx格式,即xyz格式。作者通过matplotlib作图可视化(这一过程很慢),并没有转化成我们熟悉的sdf格式。以下是生成分子的例子。
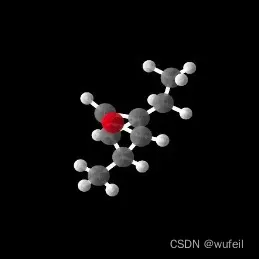
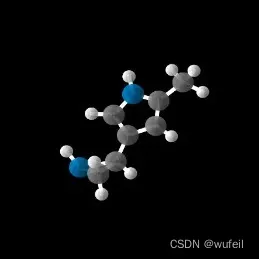
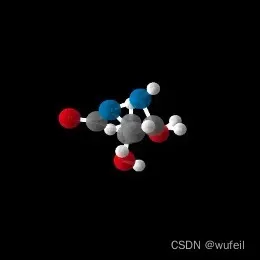
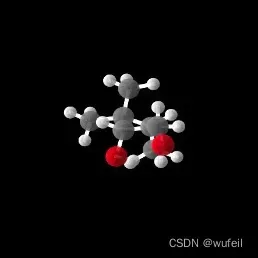

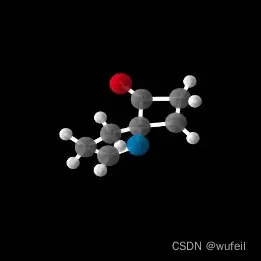
生成的xyz.txt格式也有一些问题,不能直接转化为sdf文件。
1.3.2 训练条件 GeoLDM
由于作者没有提供训练好的条件模型,因此条件模型需要我们自己训练:
以qm9为例,
python main_qm9.py \
--exp_name exp_cond_alpha \
--model egnn_dynamics \
--lr 1e-4 \
--nf 192 \
--n_layers 9 \
--save_model True \
--diffusion_steps 1000 \
--sin_embedding False \
--n_epochs 3000 \
--n_stability_samples 500 \
--diffusion_noise_schedule polynomial_2 \
--diffusion_noise_precision 1e-5 \
--dequantization deterministic \
--include_charges False \
--diffusion_loss_type l2 \
--batch_size 64 \
--normalize_factors [1,8,1] \
--conditioning alpha \
--dataset qm9_second_half \
--train_diffusion \
--trainable_ae \
--latent_nf 1其中, –conditioning alpha中的alpha, 可以替换成为:alpha, gap, homo, lumo, mu Cv中的任意一个。这里我们仍保持不变。
1.3.3 训练 qm9模型
在GeoLDM主目录下执行:
python main_qm9.py --n_epochs 10 \
--n_stability_samples 10 \
--diffusion_noise_schedule polynomial_2 \
--diffusion_noise_precision 1e-5 \
--diffusion_steps 1000 \
--diffusion_loss_type l2 \
--batch_size 64 --nf 256 \
--n_layers 9 \
--lr 1e-4 \
--normalize_factors '[1,4,10]' \
--test_epochs 20 \
--ema_decay 0.9999 \
--train_diffusion \
--trainable_ae \
--latent_nf 1 \
--exp_name geoldm_qm9 \
--wandb_usr geoldm其中,exp_name是实验名称。–wandb_usr geoldm是我添加的,我在wandb里面新建一个geoldm的team,在训练的时候,会将训练过程上传到wandb中。
运行后,会生成wandb 目录,保存训练过程。同时在output目录下,会生成我们此次实验名称的文件夹,即geoldm_qm9,用于保存我们训练好的模型。为了节省时间,且我们仅仅是尝试代码是否可以正常运行,我们epoch设置为10。
输出示例:
... # 训练
Epoch: 0, iter: 1127/1563, Loss 2.67, NLL: 2.67, RegTerm: 0.0, GradNorm: 6.6
Epoch: 0, iter: 1128/1563, Loss 2.63, NLL: 2.63, RegTerm: 0.0, GradNorm: 6.3
Epoch: 0, iter: 1129/1563, Loss 2.68, NLL: 2.68, RegTerm: 0.0, GradNorm: 3.2
... # 训练结果
Epoch took 27095.8 seconds.
{'log_SNR_max': 11.51291561126709, 'log_SNR_min': -11.512516021728516}
Analyzing molecule stability at epoch 0...
Validity over 100 molecules: 100.00%
Uniqueness over 100 valid molecules: 1.00%
Novelty over 1 unique valid molecules: 100.00%
... # 验证
Val NLL epoch: 0, iter: 24/278, NLL: 621.18
Val NLL epoch: 0, iter: 25/278, NLL: 615.10
Val NLL epoch: 0, iter: 26/278, NLL: 619.27
Val NLL epoch: 0, iter: 27/278, NLL: 622.72
Val NLL epoch: 0, iter: 28/278, NLL: 614.12
... # 测试
Test NLL epoch: 0, iter: 100/205, NLL: 513.01
Test NLL epoch: 0, iter: 101/205, NLL: 511.20
Test NLL epoch: 0, iter: 102/205, NLL: 510.97
Test NLL epoch: 0, iter: 103/205, NLL: 512.93
... # epoch 验证和测试结果
Val loss: 562.9518 Test loss: 543.4572
Best val loss: 562.9518 Best test loss: 543.4572
训练结束以后,模型参数会在./output目录下生成geoldm_qm9文件夹。文件夹下的内容为:
.
├── args.pickle
├── args_0.pickle
├── generative_model.npy
├── generative_model_0.npy
├── generative_model_ema.npy
├── generative_model_ema_0.npy
├── optim.npy
└── optim_0.npy
1 directory, 8 files二、代码简析
2.1 数据准备
数据准备,drug数据集,下载完成后都需要先进行数据准备。下载下来的数据集是xyz格式的,且数据保存在字典里面。数据准备的目的是将分子表示成x和h,以便输入模型。(qm9数据集似乎没有提供下载方式,但是有已经训练好的模型。drug数据集对应的模型作者也提供了训练好的模型,但是我们也可以自己训练)
接下来是drugs数据集的准备,在项目主目录下运行:
python build_geom_dataset.py运行输出:
Unpacking file 0...
Unpacking file 1...
Unpacking file 2...
Unpacking file 3...
Unpacking file 4..
... 很长很长
... 最后输出
Total number of conformers saved 6922516
Total number of atoms in the dataset 322877623
Average number of atoms per molecule 46.64165788854804
Dataset processed.运行时间大约是1个小时,该数据集包含了692W 多的分子构象,平均每个分子含有46个原子。运行输出的文件仍然保存在数据目录:/data/geom,一共生成了geom_drugs_30.npy, geom_drugs_n_30.npy, geom_drugs_smiles.txt三个文件目录。
下面是代码解析。首先是参数,在__mian__中:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# 每个分子生成的构象数,默认 30
parser.add_argument("--conformations", type=int, default=30,
help="Max number of conformations kept for each molecule.")
# 是否保留H,默认保留
parser.add_argument("--remove_h", action='store_true', help="Remove hydrogens from the dataset.")
# 原始数据保存路径,即下载来的数据路径,默认修改为:./data/geom/
parser.add_argument("--data_dir", type=str, default='./data/geom/') # 注意输入路径
# 数据文件名,默认为:drugs_crude.msgpack
parser.add_argument("--data_file", type=str, default="drugs_crude.msgpack")
args = parser.parse_args()
extract_conformers(args)extract_conformers函数:
实现从drugs数据集的压缩文件中,提取分子构象(每个分子能量最低的30个构象),即xyz文件(坐标,元素),并设置分子id。
分子的smiles保存在geom_drugs_smiles.txt文件,每个分子对应的原子数保存在geom_drugs_n_30.npy文件,分子的构象信息保存在geom_drugs_30.npy文件(该文件是python eval_analyze.py方法分析drug_latent_2模型所需的数据集,也是训练drug模型所需的数据集)。
def extract_conformers(args):
drugs_file = os.path.join(args.data_dir, args.data_file)
save_file = f"geom_drugs_{'no_h_' if args.remove_h else ''}{args.conformations}"
smiles_list_file = 'geom_drugs_smiles.txt'
number_atoms_file = f"geom_drugs_n_{'no_h_' if args.remove_h else ''}{args.conformations}"
# 解压数据文件
unpacker = msgpack.Unpacker(open(drugs_file, "rb"))
# 保存smiles和构象
all_smiles = []
all_number_atoms = []
dataset_conformers = []
mol_id = 0
for i, drugs_1k in enumerate(unpacker):
print(f"Unpacking file {i}...")
for smiles, all_info in drugs_1k.items():
all_smiles.append(smiles) # smiles
conformers = all_info['conformers'] # 构象
# Get the energy of each conformer. Keep only the lowest values
all_energies = []
for conformer in conformers:
all_energies.append(conformer['totalenergy'])
# 按照能量排序,提取最低能量top 30的分子构象
all_energies = np.array(all_energies)
argsort = np.argsort(all_energies)
lowest_energies = argsort[:args.conformations]
for id in lowest_energies:
conformer = conformers[id]
coords = np.array(conformer['xyz']).astype(float) # n x 4, xyz格式
if args.remove_h:
mask = coords[:, 0] != 1.0
coords = coords[mask]
n = coords.shape[0]
all_number_atoms.append(n)
mol_id_arr = mol_id * np.ones((n, 1), dtype=float) # 分子id
id_coords = np.hstack((mol_id_arr, coords)) # 分子 id, 及其坐标
dataset_conformers.append(id_coords)
mol_id += 1
print("Total number of conformers saved", mol_id)
all_number_atoms = np.array(all_number_atoms)
dataset = np.vstack(dataset_conformers)
print("Total number of atoms in the dataset", dataset.shape[0])
print("Average number of atoms per molecule", dataset.shape[0] / mol_id)
# Save conformations
# 构象信息保存到npy文件中,文件:geom_drugs_30.npy
np.save(os.path.join(args.data_dir, save_file), dataset)
# Save SMILES, 保存到txt文件中 geom_drugs_smiles.txt
with open(os.path.join(args.data_dir, smiles_list_file), 'w') as f:
for s in all_smiles:
f.write(s)
f.write('\n')
# Save number of atoms per conformation, 文件:geom_drugs_n_30.npy
np.save(os.path.join(args.data_dir, number_atoms_file), all_number_atoms)
print("Dataset processed.")
2.2 GeoLDM 模型代码(训练和采样)
当我们要训练GeoLDM模型时,以QM9数据集为例, 在主目录下运行:
python main_qm9.py --n_epochs 10 \
--n_stability_samples 10 \
--diffusion_noise_schedule polynomial_2 \
--diffusion_noise_precision 1e-5 \
--diffusion_steps 1000 \
--diffusion_loss_type l2 \
--batch_size 64 --nf 256 \
--n_layers 9 \
--lr 1e-4 \
--normalize_factors '[1,4,10]' \
--test_epochs 20 \
--ema_decay 0.9999 \
--train_diffusion \ # 默认为True?
--trainable_ae \
--latent_nf 1 \
--exp_name geoldm_qm9 \
--wandb_usr geoldm注意,我们的目的是为了测试代码,所以我们将n_epochs设置为10,原作者设置为3000,同时使用了自己的geoldm 的wandb 的team,这两个参数大家按需设置。
以下是代码解析。
首先倒入相关模块:
# Rdkit import should be first, do not move it
try:
from rdkit import Chem
except ModuleNotFoundError:
pass
import copy
import utils
import argparse
import wandb
from configs.datasets_config import get_dataset_info
from os.path import join
from qm9 import dataset
from qm9.models import get_optim, get_model, get_autoencoder, get_latent_diffusion
from equivariant_diffusion import en_diffusion
from equivariant_diffusion.utils import assert_correctly_masked
from equivariant_diffusion import utils as flow_utils
import torch
import time
import pickle
from qm9.utils import prepare_context, compute_mean_mad
from train_test import train_epoch, test, analyze_and_save2.2.1 训练超参数配置
训练模型的参数,非常多,
python main_qm9.py --n_epochs 10 \
--n_stability_samples 10 \
--diffusion_noise_schedule polynomial_2 \
--diffusion_noise_precision 1e-5 \
--diffusion_steps 1000 \
--diffusion_loss_type l2 \
--batch_size 64 --nf 256 \
--n_layers 9 \
--lr 1e-4 \
--normalize_factors '[1,4,10]' \
--test_epochs 20 \
--ema_decay 0.9999 \
--train_diffusion \
--trainable_ae \
--latent_nf 1 \
--exp_name geoldm_qm9 \
--wandb_usr geoldm2.2.2 训练GeoLDM模型代码
首先,获取数据集,wandb,GPU等信息及预设:
# 获取数据集的预设
dataset_info = get_dataset_info(args.dataset, args.remove_h)
# 将元素符号转为数字的 dict
atom_encoder = dataset_info['atom_encoder']
# 将数字转为元素符号的 list
atom_decoder = dataset_info['atom_decoder']
# args, unparsed_args = parser.parse_known_args()
# 提取 wandb 的项目名,填入参数即可覆盖,每次实验🉑设置不同名字,分开保存
# 相同名字,则记录第几次run
args.wandb_usr = utils.get_wandb_username(args.wandb_usr)
# 设置 GPU 的使用,这里使用mps
# args.cuda = not args.no_cuda and torch.cuda.is_available()
# device = torch.device("cuda" if args.cuda else "cpu")
args.cuda = not args.no_cuda and torch.backends.mps.is_available() # wufeil mps训练
device = torch.device("mps" if args.cuda else "cpu")
dtype = torch.float32然后,设置接续训练:# 如果接续训练
if args.resume is not None:
exp_name = args.exp_name + '_resume' # 实验名称添加_resume
start_epoch = args.start_epoch # 接续 epoch
resume = args.resume
wandb_usr = args.wandb_usr
normalization_factor = args.normalization_factor
aggregation_method = args.aggregation_method
with open(join(args.resume, 'args.pickle'), 'rb') as f:
# 加载参数
args = pickle.load(f)
args.resume = resume
args.break_train_epoch = False
args.exp_name = exp_name
args.start_epoch = start_epoch
args.wandb_usr = wandb_usr
# Careful with this -->
if not hasattr(args, 'normalization_factor'):
args.normalization_factor = normalization_factor
if not hasattr(args, 'aggregation_method'):
args.aggregation_method = aggregation_method
print(args)
创建保存训练模型结果目录,及wandb初始化配置:
# 创建output及其实验名称的文件夹,用于保存训练好的模型
# 默认放在./output中
utils.create_folders(args)
# print(args)
# Wandb config
if args.no_wandb:
mode = 'disabled' # 是否使用wandb
else:
mode = 'online' if args.online else 'offline' # wandb是offline还是online
# wandb的参数
kwargs = {'entity': args.wandb_usr, 'name': args.exp_name, 'project': 'e3_diffusion_qm9', 'config': args,
'settings': wandb.Settings(_disable_stats=True), 'reinit': True, 'mode': mode}
# wandb 初始化,先在conda环境中设置私钥
wandb.init(**kwargs)
wandb.save('*.txt')数据dataloader准备:
# Retrieve QM9 dataloaders, 取回qm9的dataloader,暂时略过
# 数据路径 ./qm9/temp/qm9
dataloaders, charge_scale = dataset.retrieve_dataloaders(args)
data_dummy = next(iter(dataloaders['train']))context维度设置及计算每个批次的均值,使用compute_mean_mad函数。
#如果有条件属性
if len(args.conditioning) > 0:
print(f'Conditioning on {args.conditioning}')
# 计算属性的数据集均值,及每一个批次中均值与数据集均值偏差的绝对值
property_norms = compute_mean_mad(dataloaders, \
args.conditioning, args.dataset)
# 将 条件,例如: ev等,写入context中,
# 1维(bs, )为分子层面属性,
# 2维或者3维(bs, node, propeties)为原子层面属性
context_dummy = prepare_context(args.conditioning,
data_dummy, property_norms)
context_node_nf = context_dummy.size(2) # context的维度
else:
context_node_nf = 0
property_norms = None
# context的维度,最后体现在输入模型中的future中
args.context_node_nf = context_node_nf 根据是否训练diffusion模型,创建VAE模型或者GeoLDM模型
# Create Latent Diffusion Model or Audoencoder
if args.train_diffusion: # 默认是训练train_diffusion模型,
# 如果args中有ae模型保存路径(args.ae_path,'args.pickle'),
# 否则加载ae模型, 否则为第一次运行 (默认是没有以训练过的VAE模型的)
model, nodes_dist, prop_dist = get_latent_diffusion(args, device, dataset_info, dataloaders['train'])
else:
# 只训练VAE模型
model, nodes_dist, prop_dist = get_autoencoder(args, device, dataset_info, dataloaders['train'])如果有属性分布,即有属性作为condition, 即context,需要进行归一化
if prop_dist is not None:
# 属性每一个批次归一化
prop_dist.set_normalizer(property_norms)模型加载到GPU,设置优化器,梯度剪裁设置
model = model.to(device)
optim = get_optim(args, model)
# print(model)
# 梯度剪裁设置
gradnorm_queue = utils.Queue()
gradnorm_queue.add(3000) # Add large value that will be flushed.然后,就会执行到 main()函数。
首先是,接续训练设置。
# 如果接续训练
if args.resume is not None:
flow_state_dict = torch.load(join(args.resume, 'flow.npy'))
optim_state_dict = torch.load(join(args.resume, 'optim.npy'))
model.load_state_dict(flow_state_dict)
optim.load_state_dict(optim_state_dict)多卡GPU数据平行训练设置
# 多GPU卡,数据平行训练dp,其实可以使用pytorch_lightning设置
# Initialize dataparallel if enabled and possible.
if args.dp and torch.cuda.device_count() > 1:
print(f'Training using {torch.cuda.device_count()} GPUs')
model_dp = torch.nn.DataParallel(model.cpu())
model_dp = model_dp.cuda()
else:
model_dp = model模型权重指数平移平均(即,ema)模型副本,
if args.ema_decay > 0:
# 参数指数移动平均值的模型副本, 即 ema 模型
model_ema = copy.deepcopy(model)
# 参数指数平移对象,用于对模型参数的指数平移平均操作
ema = flow_utils.EMA(args.ema_decay)
if args.dp and torch.cuda.device_count() > 1:
model_ema_dp = torch.nn.DataParallel(model_ema)
else:
model_ema_dp = model_ema
else:
ema = None
model_ema = model
model_ema_dp = model_dp模型训练,测试,验证步,保存最优模型和训练过程模型,打印loss, wandb记录。
best_nll_val = 1e8
best_nll_test = 1e8
for epoch in range(args.start_epoch, args.n_epochs):
start_epoch = time.time()
# 训练步
train_epoch(args=args, loader=dataloaders['train'], epoch=epoch, model=model, model_dp=model_dp,
model_ema=model_ema, ema=ema, device=device, dtype=dtype, property_norms=property_norms,
nodes_dist=nodes_dist, dataset_info=dataset_info,
gradnorm_queue=gradnorm_queue, optim=optim, prop_dist=prop_dist)
print(f"Epoch took {time.time() - start_epoch:.1f} seconds.")
# 测试步
if epoch % args.test_epochs == 0:
if isinstance(model, en_diffusion.EnVariationalDiffusion):
wandb.log(model.log_info(), commit=True)
# 如果训练的diffusion模型
if not args.break_train_epoch and args.train_diffusion:
analyze_and_save(args=args, epoch=epoch, model_sample=model_ema, nodes_dist=nodes_dist,
dataset_info=dataset_info, device=device,
prop_dist=prop_dist, n_samples=args.n_stability_samples)
# 验证步 valid
nll_val = test(args=args, loader=dataloaders['valid'], epoch=epoch, eval_model=model_ema_dp,
partition='Val', device=device, dtype=dtype, nodes_dist=nodes_dist,
property_norms=property_norms)
# 测试步 test
nll_test = test(args=args, loader=dataloaders['test'], epoch=epoch, eval_model=model_ema_dp,
partition='Test', device=device, dtype=dtype,
nodes_dist=nodes_dist, property_norms=property_norms)
# valid 损失更小,则保存模型
if nll_val < best_nll_val:
best_nll_val = nll_val
best_nll_test = nll_test
# 保存最优模型
if args.save_model:
args.current_epoch = epoch + 1
utils.save_model(optim, 'outputs/%s/optim.npy' % args.exp_name)
utils.save_model(model, 'outputs/%s/generative_model.npy' % args.exp_name)
if args.ema_decay > 0:
utils.save_model(model_ema, 'outputs/%s/generative_model_ema.npy' % args.exp_name)
with open('outputs/%s/args.pickle' % args.exp_name, 'wb') as f:
pickle.dump(args, f)
# 保存 epoch 模型,记录
if args.save_model:
utils.save_model(optim, 'outputs/%s/optim_%d.npy' % (args.exp_name, epoch))
utils.save_model(model, 'outputs/%s/generative_model_%d.npy' % (args.exp_name, epoch))
if args.ema_decay > 0:
utils.save_model(model_ema, 'outputs/%s/generative_model_ema_%d.npy' % (args.exp_name, epoch))
with open('outputs/%s/args_%d.pickle' % (args.exp_name, epoch), 'wb') as f:
pickle.dump(args, f)
print('Val loss: %.4f \t Test loss: %.4f' % (nll_val, nll_test))
print('Best val loss: %.4f \t Best test loss: %.4f' % (best_nll_val, best_nll_test))
wandb.log({"Val loss ": nll_val}, commit=True)
wandb.log({"Test loss ": nll_test}, commit=True)
wandb.log({"Best cross-validated test loss ": best_nll_test}, commit=True)train_epoch函数执行了GeoLDM模型训练的任务,并保存模型,代码如下:
def train_epoch(args, loader, epoch, model, model_dp, model_ema, ema, device, dtype, property_norms, optim,
nodes_dist, gradnorm_queue, dataset_info, prop_dist):
'''
训练GEOLDM模型,一个epoch
'''
model_dp.train()
model.train()
nll_epoch = []
n_iterations = len(loader)
for i, data in enumerate(loader):
x = data['positions'].to(device, dtype)
node_mask = data['atom_mask'].to(device, dtype).unsqueeze(2)
edge_mask = data['edge_mask'].to(device, dtype)
one_hot = data['one_hot'].to(device, dtype)
charges = (data['charges'] if args.include_charges else torch.zeros(0)).to(device, dtype)
x = remove_mean_with_mask(x, node_mask)
# args.augment_noise 增强添加噪音
if args.augment_noise > 0:
# Add noise eps ~ N(0, augment_noise) around points.
eps = sample_center_gravity_zero_gaussian_with_mask(x.size(), x.device, node_mask)
x = x + eps * args.augment_noise
# 随机旋转
x = remove_mean_with_mask(x, node_mask)
if args.data_augmentation:
x = utils.random_rotation(x).detach()
# mask 维度检查
check_mask_correct([x, one_hot, charges], node_mask)
# 质心归零检查
assert_mean_zero_with_mask(x, node_mask)
# 节点特征 h
h = {'categorical': one_hot, 'integer': charges}
# context 条件(分子层面)
if len(args.conditioning) > 0:
context = qm9utils.prepare_context(args.conditioning, data, property_norms).to(device, dtype)
assert_correctly_masked(context, node_mask)
else:
context = None
optim.zero_grad()
# transform batch through flow 计算损失
nll, reg_term, mean_abs_z = losses.compute_loss_and_nll(args, model_dp, nodes_dist,
x, h, node_mask, edge_mask, context)
# standard nll from forward KL
# 损失,nll 损失 + reg_term 回归项
loss = nll + args.ode_regularization * reg_term
loss.backward()
# 梯度剪裁
if args.clip_grad:
grad_norm = utils.gradient_clipping(model, gradnorm_queue)
else:
grad_norm = 0.
optim.step()
# Update EMA if enabled. 如果指数平移平均 权重
if args.ema_decay > 0:
ema.update_model_average(model_ema, model)
if i % args.n_report_steps == 0:
print(f"\rEpoch: {epoch}, iter: {i}/{n_iterations}, "
f"Loss {loss.item():.2f}, NLL: {nll.item():.2f}, "
f"RegTerm: {reg_term.item():.1f}, "
f"GradNorm: {grad_norm:.1f}")
nll_epoch.append(nll.item())
# 保存模型
if (epoch % args.test_epochs == 0) and (i % args.visualize_every_batch == 0) and not (epoch == 0 and i == 0) and args.train_diffusion:
start = time.time()
if len(args.conditioning) > 0:
save_and_sample_conditional(args, device, model_ema, prop_dist, dataset_info, epoch=epoch)
save_and_sample_chain(model_ema, args, device, dataset_info, prop_dist, epoch=epoch,
batch_id=str(i))
sample_different_sizes_and_save(model_ema, nodes_dist, args, device, dataset_info,
prop_dist, epoch=epoch)
print(f'Sampling took {time.time() - start:.2f} seconds')
vis.visualize(f"outputs/{args.exp_name}/epoch_{epoch}_{i}", dataset_info=dataset_info, wandb=wandb)
vis.visualize_chain(f"outputs/{args.exp_name}/epoch_{epoch}_{i}/chain/", dataset_info, wandb=wandb)
if len(args.conditioning) > 0:
vis.visualize_chain("outputs/%s/epoch_%d/conditional/" % (args.exp_name, epoch), dataset_info,
wandb=wandb, mode='conditional')
wandb.log({"Batch NLL": nll.item()}, commit=True)
if args.break_train_epoch:
break
wandb.log({"Train Epoch NLL": np.mean(nll_epoch)}, commit=False)其中,compute_loss_and_nll为计算GeoLDM的损失,调用GeoLDM的forward函数。值得注意的是,损失仅为nll项,reg_term的值为0。compute_loss_and_nll代码如下:
def compute_loss_and_nll(args, generative_model, nodes_dist, x, h, node_mask, edge_mask, context):
# 计算GeoLDM模型的损失
bs, n_nodes, n_dims = x.size()
if args.probabilistic_model == 'diffusion':
edge_mask = edge_mask.view(bs, n_nodes * n_nodes)
assert_correctly_masked(x, node_mask)
# Here x is a position tensor, and h is a dictionary with keys
# 'categorical' and 'integer'.
nll = generative_model(x, h, node_mask, edge_mask, context)
N = node_mask.squeeze(2).sum(1).long()
log_pN = nodes_dist.log_prob(N)
assert nll.size() == log_pN.size()
nll = nll - log_pN
# Average over batch.
nll = nll.mean(0)
reg_term = torch.tensor([0.]).to(nll.device)
mean_abs_z = 0.
else:
raise ValueError(args.probabilistic_model)
return nll, reg_term, mean_abs_z
2.2.2.1 GeoLDM 模型 (EnLatentDiffusion)
在qm9_main.py 中,关于模型加载的代码如下:
if args.train_diffusion: # 默认是训练train_diffusion模型
model, nodes_dist, prop_dist = get_latent_diffusion(args, device, dataset_info, dataloaders['train'])
else:
model, nodes_dist, prop_dist = get_autoencoder(args, device, dataset_info, dataloaders['train'])
args.train_diffusion默认为true, 训练 VAE 和 Diffusion 模型一起训练,即重头完整训练 GeoLDM 模型。
接下来,就分开介绍get_latent_diffusion获取GeoLDM模型和get_autoencoder获取VAE模型, 分别看看他们的模型结构。
一个完整的GeoLDM模型由VAE模型和SE3等变网络组成。
现在来看一下,获取GeoLDM模型的get_latent_diffusion部分的代码:
- 加载VAE模型的参数pickle文件;
- get_autoencoder,根据VAE模型参数,实例化VAE模型;
- first_stage_model.load_state_dict(flow_state_dict)),根据VAE模型的权重文件是否存在,加载/实例化VAE模型;
- EGNN_dynamics_QM9,实例化一个SE3等变网络模型;
- EnLatentDiffusion,基于VAE模型和等变网络模型,创建几何隐式扩散模型 GeoLDM。
def get_latent_diffusion(args, device, dataset_info, dataloader_train):
# Create (and load) the first stage model (Autoencoder).
# 如果有AE模型参数pickle文件(训练过),则加载参数
# args.ae_path 默认是 None,即AE模型参数,使用默认值
if args.ae_path is not None:
with open(join(args.ae_path, 'args.pickle'), 'rb') as f:
first_stage_args = pickle.load(f)
else:
first_stage_args = args
# CAREFUL with this -->
# 判断first_stage_args 参数中,是否包含 normalization_factor 和 aggregation_method属性
if not hasattr(first_stage_args, 'normalization_factor'):
first_stage_args.normalization_factor = 1
if not hasattr(first_stage_args, 'aggregation_method'):
first_stage_args.aggregation_method = 'sum'
# device 已经是传参进来了,无需自定义
# device = torch.device("cuda" if first_stage_args.cuda else "cpu")
# 实例化AE模型,latent向量为维度为latent_nf
first_stage_model, nodes_dist, prop_dist = get_autoencoder(
first_stage_args, device, dataset_info, dataloader_train)
first_stage_model.to(device)
# 如果AE模型已经训练过(args.ae_path),则加载AE模型参数
if args.ae_path is not None:
fn = 'generative_model_ema.npy' if first_stage_args.ema_decay > 0 else 'generative_model.npy'
flow_state_dict = torch.load(join(args.ae_path, fn),
map_location=device)
first_stage_model.load_state_dict(flow_state_dict)
# Create the second stage model (Latent Diffusions).
# AE模型输出的向量维度是,latent_nf,Latent Diffusions以此作为输入
args.latent_nf = first_stage_args.latent_nf
in_node_nf = args.latent_nf
if args.condition_time:
# 时间条件
dynamics_in_node_nf = in_node_nf + 1
else:
print('Warning: dynamics model is _not_ conditioned on time.')
dynamics_in_node_nf = in_node_nf
# 实例化一个SE3等变网络模型,EGNN_dynamics_QM9
net_dynamics = EGNN_dynamics_QM9(
in_node_nf=dynamics_in_node_nf,
context_node_nf=args.context_node_nf,
n_dims=3, device=device,
hidden_nf=args.nf,
act_fn=torch.nn.SiLU(),
n_layers=args.n_layers,
attention=args.attention,
tanh=args.tanh,
mode=args.model,
norm_constant=args.norm_constant,
inv_sublayers=args.inv_sublayers,
sin_embedding=args.sin_embedding,
normalization_factor=args.normalization_factor,
aggregation_method=args.aggregation_method)
# 基于之前实例好的SE3等变网络模型,EGNN_dynamics_QM9, 和 VAE 网络,
# 创建一个 GeoLDM 网络, 即, 几何隐式扩散模型, vdm
if args.probabilistic_model == 'diffusion':
vdm = EnLatentDiffusion(
vae=first_stage_model, # VAE 模型
trainable_ae=args.trainable_ae,
dynamics=net_dynamics, # SE3等变网络模型
in_node_nf=in_node_nf,
n_dims=3,
timesteps=args.diffusion_steps,
noise_schedule=args.diffusion_noise_schedule,
noise_precision=args.diffusion_noise_precision,
loss_type=args.diffusion_loss_type,
norm_values=args.normalize_factors,
include_charges=args.include_charges
)
return vdm, nodes_dist, prop_dist
else:
raise ValueError(args.probabilistic_model)EnLatentDiffusion类是GeoLDM模型,继承于EnVariationalDiffusion类。因为GeoLDM模型是在SE3等变扩散网络上,再添加了一个VAE模块(由参数vae传入),所以在EnLatentDiffusion类中,需要添加了几个方法,以覆盖EnVariationalDiffusion的方法,比如forwad计算损失,sample, sample_chain采样/生成分子。EnVariationalDiffusion类和EnHierarchicalVAE类构成了GeoLDM模型(EnLatentDiffusion)。
EnLatentDiffusion完整代码如下:
class EnLatentDiffusion(EnVariationalDiffusion):
'''
几何隐式扩散网络 GeoLDM
继承等变扩散网络 EnVariationalDiffusion
'''
"""
The E(n) Latent Diffusion Module.
"""
def __init__(self, **kwargs):
# 参数中如果有vae模型,则返回给vae变量,从参数中删除
vae = kwargs.pop('vae')
# 参数中如果有trainable_ae则返回给trainable_ae变量,从参数中删除。如果没有,则trainable_ae为False
trainable_ae = kwargs.pop('trainable_ae', False)
super().__init__(**kwargs)
# Create self.vae as the first stage model.
self.trainable_ae = trainable_ae
self.instantiate_first_stage(vae) # VAE 模型初始化设置, 梯度设置(需要梯度/无需梯度)
def unnormalize_z(self, z, node_mask):
# 啥都不做,只是为了覆盖之前的unnormalize_z, 用在sample_chain;
# Overwrite the unnormalize_z function to do nothing (for sample_chain).
# Parse from z
x, h_cat = z[:, :, 0:self.n_dims], z[:, :, self.n_dims:self.n_dims+self.num_classes]
h_int = z[:, :, self.n_dims+self.num_classes:self.n_dims+self.num_classes+1]
assert h_int.size(2) == self.include_charges
# Unnormalize ???为什么注释掉了??
# x, h_cat, h_int = self.unnormalize(x, h_cat, h_int, node_mask)
output = torch.cat([x, h_cat, h_int], dim=2)
return output
def log_constants_p_h_given_z0(self, h, node_mask):
"""Computes p(h|z0)."""
batch_size = h.size(0)
n_nodes = node_mask.squeeze(2).sum(1) # N has shape [B] B为每个分子的原子数 (N,B)
assert n_nodes.size() == (batch_size,)
degrees_of_freedom_h = n_nodes * self.n_dims
zeros = torch.zeros((h.size(0), 1), device=h.device)
gamma_0 = self.gamma(zeros)
# Recall that sigma_x = sqrt(sigma_0^2 / alpha_0^2) = SNR(-0.5 gamma_0).
log_sigma_x = 0.5 * gamma_0.view(batch_size)
return degrees_of_freedom_h * (- log_sigma_x - 0.5 * np.log(2 * np.pi))
def sample_p_xh_given_z0(self, z0, node_mask, edge_mask, context, fix_noise=False):
"""Samples x ~ p(x|z0)."""
zeros = torch.zeros(size=(z0.size(0), 1), device=z0.device)
gamma_0 = self.gamma(zeros)
# Computes sqrt(sigma_0^2 / alpha_0^2)
sigma_x = self.SNR(-0.5 * gamma_0).unsqueeze(1)
net_out = self.phi(z0, zeros, node_mask, edge_mask, context)
# Compute mu for p(zs | zt).
mu_x = self.compute_x_pred(net_out, z0, gamma_0)
xh = self.sample_normal(mu=mu_x, sigma=sigma_x, node_mask=node_mask, fix_noise=fix_noise)
x = xh[:, :, :self.n_dims]
# h_int = z0[:, :, -1:] if self.include_charges else torch.zeros(0).to(z0.device)
# x, h_cat, h_int = self.unnormalize(x, z0[:, :, self.n_dims:-1], h_int, node_mask)
# h_cat = F.one_hot(torch.argmax(h_cat, dim=2), self.num_classes) * node_mask
# h_int = torch.round(h_int).long() * node_mask
# Make the data structure compatible with the EnVariationalDiffusion sample() and sample_chain().
h = {'integer': xh[:, :, self.n_dims:], 'categorical': torch.zeros(0).to(xh)}
return x, h
def log_pxh_given_z0_without_constants(
self, x, h, z_t, gamma_0, eps, net_out, node_mask, epsilon=1e-10):
# Computes the error for the distribution N(latent | 1 / alpha_0 z_0 + sigma_0/alpha_0 eps_0, sigma_0 / alpha_0),
# the weighting in the epsilon parametrization is exactly '1'.
log_pxh_given_z_without_constants = -0.5 * self.compute_error(net_out, gamma_0, eps)
# Combine log probabilities for x and h.
log_p_xh_given_z = log_pxh_given_z_without_constants
return log_p_xh_given_z
def forward(self, x, h, node_mask=None, edge_mask=None, context=None):
"""
train 时计算的损失(类型 l2 或 NLL)。 如果 eval 则始终计算 NLL。
Computes the loss (type l2 or NLL) if training. And if eval then always computes NLL.
"""
# Encode data to latent space. 将x,h 编码到隐空间,分别得到x和h的均值和标差
z_x_mu, z_x_sigma, z_h_mu, z_h_sigma = self.vae.encode(x, h, node_mask, edge_mask, context)
# Compute fixed sigma values.
t_zeros = torch.zeros(size=(x.size(0), 1), device=x.device)
gamma_0 = self.inflate_batch_array(self.gamma(t_zeros), x)
sigma_0 = self.sigma(gamma_0, x)
# Infer latent z.
z_xh_mean = torch.cat([z_x_mu, z_h_mu], dim=2)
diffusion_utils.assert_correctly_masked(z_xh_mean, node_mask)
z_xh_sigma = sigma_0
# z_xh_sigma = torch.cat([z_x_sigma.expand(-1, -1, 3), z_h_sigma], dim=2)
z_xh = self.vae.sample_normal(z_xh_mean, z_xh_sigma, node_mask)
# z_xh = z_xh_mean
z_xh = z_xh.detach() # Always keep the encoder fixed.
diffusion_utils.assert_correctly_masked(z_xh, node_mask)
# Compute reconstruction loss.
if self.trainable_ae:
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# Decoder output (reconstruction).
x_recon, h_recon = self.vae.decoder._forward(z_xh, node_mask, edge_mask, context)
xh_rec = torch.cat([x_recon, h_recon], dim=2)
loss_recon = self.vae.compute_reconstruction_error(xh_rec, xh)
else:
loss_recon = 0
z_x = z_xh[:, :, :self.n_dims]
z_h = z_xh[:, :, self.n_dims:]
diffusion_utils.assert_mean_zero_with_mask(z_x, node_mask)
# Make the data structure compatible with the EnVariationalDiffusion compute_loss().
z_h = {'categorical': torch.zeros(0).to(z_h), 'integer': z_h}
if self.training:
# Only 1 forward pass when t0_always is False.
loss_ld, loss_dict = self.compute_loss(z_x, z_h, node_mask, edge_mask, context, t0_always=False)
else:
# Less variance in the estimator, costs two forward passes.
loss_ld, loss_dict = self.compute_loss(z_x, z_h, node_mask, edge_mask, context, t0_always=True)
# The _constants_ depending on sigma_0 from the
# cross entropy term E_q(z0 | x) [log p(x | z0)].
neg_log_constants = -self.log_constants_p_h_given_z0(
torch.cat([h['categorical'], h['integer']], dim=2), node_mask)
# Reset constants during training with l2 loss.
if self.training and self.loss_type == 'l2':
neg_log_constants = torch.zeros_like(neg_log_constants)
neg_log_pxh = loss_ld + loss_recon + neg_log_constants
return neg_log_pxh
@torch.no_grad()
def sample(self, n_samples, n_nodes, node_mask, edge_mask, context, fix_noise=False):
"""
Draw samples from the generative model.
"""
z_x, z_h = super().sample(n_samples, n_nodes, node_mask, edge_mask, context, fix_noise)
z_xh = torch.cat([z_x, z_h['categorical'], z_h['integer']], dim=2)
diffusion_utils.assert_correctly_masked(z_xh, node_mask)
x, h = self.vae.decode(z_xh, node_mask, edge_mask, context)
return x, h
@torch.no_grad()
def sample_chain(self, n_samples, n_nodes, node_mask, edge_mask, context, keep_frames=None):
"""
Draw samples from the generative model, keep the intermediate states for visualization purposes.
"""
chain_flat = super().sample_chain(n_samples, n_nodes, node_mask, edge_mask, context, keep_frames)
# xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# chain[0] = xh # Overwrite last frame with the resulting x and h.
# chain_flat = chain.view(n_samples * keep_frames, *z.size()[1:])
chain = chain_flat.view(keep_frames, n_samples, *chain_flat.size()[1:])
chain_decoded = torch.zeros(
size=(*chain.size()[:-1], self.vae.in_node_nf + self.vae.n_dims), device=chain.device)
for i in range(keep_frames):
z_xh = chain[i]
diffusion_utils.assert_mean_zero_with_mask(z_xh[:, :, :self.n_dims], node_mask)
x, h = self.vae.decode(z_xh, node_mask, edge_mask, context)
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
chain_decoded[i] = xh
chain_decoded_flat = chain_decoded.view(n_samples * keep_frames, *chain_decoded.size()[2:])
return chain_decoded_flat
def instantiate_first_stage(self, vae: EnHierarchicalVAE):
'''
VAE 模型初始化设置, 梯度设置
'''
if not self.trainable_ae:
# VAE 模型不可训练, 无需梯度
self.vae = vae.eval()
self.vae.train = disabled_train
for param in self.vae.parameters():
param.requires_grad = False
else:
# VAE 模型可训练, 需梯度
self.vae = vae.train()
for param in self.vae.parameters():
param.requires_grad = True
作为一个生成模型,我们非常关心,模型的损失是什么?怎么计算的?分子是如何生成的?
EnLatentDiffusion中,模型损失由forwad函数完成,下面详细介绍一下。在forwad函数中:
(1)将xh输入到编码器,输出x和h的均值和标准差z_x_mu, z_x_sigma, z_h_mu, z_h_sigma;
(2)基于z_x_mu和z_h_mu,VAE模型sample_normal采样新的z_xh;
(3)如果训练VAE模型,那么计算VAE模型重构损失,由VAE模型的compute_reconstruction_error完成;
(4)拆分z_xh为z_x和z_h,然后输入到SE3等变扩散模型中,由SE3等变扩散模型的compute_loss计算SE3等变扩散模型的损失;
(5)计算z_0时刻的常数项负对数损失;
(6)合并所有损失;
采样由sample函数完成,调用了SE3等变扩散模型的sample函数,采样隐式向量z_x, z_h。然后经过VAE的解码器,获得生成的x和h。基于x和h就可以利用obabel转化成分子(这一部分包含在分子生成部分的代码中)。
2.2.2.2 SE3等变扩散模型(EnVariationalDiffusion)
下面开始详细介绍EnVariationalDiffusion。
EnVariationalDiffusion是z_x,z_h隐向量的扩散模型,和之前介绍的分子生成模型的扩散模型很像,包含了phi,unnormalize, normalize等方法,我们快速简单介绍一下,这一部分,大家其实直接使用即可,在调整模型时,基本上不会动。借此机会,我们也简单介绍一下基于SE3等变网络的代码架构,特别是计算损失和采样。
首先,模型的定义,EnVariationalDiffusion __init__():定义了分子生成SE3扩散模型,SE3网络来自于EGNN_dynamics_QM9。输入参数有:
in_node_nf: 表示输入节点的特征数;
n_dims: 表示坐标的维度,通常为 3;
timesteps: 扩散步数,默认为 1000;
parametrization: 参数化的方式,此处似乎只支持 ‘eps’,即SE3预测的是噪音还是x,h;
noise_schedule: 噪音调度策略,可以是 ‘learned’ 或其他预定义的策略;
noise_precision: 噪音精度,默认为 1e-4;
norm_values: 正则化值的元组,用于规范化输入数据;
norm_biases: 正则化偏差的元组,也用于规范化输入数据;
include_charges: 一个布尔值,表示节点特征中是否包含电荷信息;
class EnVariationalDiffusion(torch.nn.Module):
"""
等变扩散类
The E(n) Diffusion Module.
"""
def __init__(
self,
dynamics: models.EGNN_dynamics_QM9, in_node_nf: int, n_dims: int,
timesteps: int = 1000, parametrization='eps', noise_schedule='learned',
noise_precision=1e-4, loss_type='vlb', norm_values=(1., 1., 1.),
norm_biases=(None, 0., 0.), include_charges=True):
super().__init__()
# 损失类型
assert loss_type in {'vlb', 'l2'}
self.loss_type = loss_type
# 节点特征是否包含电荷charge
self.include_charges = include_charges
# 噪音调度器noise_schedule是否可训练;
# 可训练为 GammaNetwork()
# 不可训练为 PredefinedNoiseSchedule()
if noise_schedule == 'learned':
assert loss_type == 'vlb', 'A noise schedule can only be learned' \
' with a vlb objective.'
# Only supported parametrization.
assert parametrization == 'eps'
if noise_schedule == 'learned':
self.gamma = GammaNetwork()
else:
self.gamma = PredefinedNoiseSchedule(noise_schedule, timesteps=timesteps,
precision=noise_precision)
# The network that will predict the denoising.
# 预测噪音的模型,即SE3模型
self.dynamics = dynamics
# 节点原子类型数,含电荷
self.in_node_nf = in_node_nf
# 坐标维度,3
self.n_dims = n_dims
# 原子种类数
self.num_classes = self.in_node_nf - self.include_charges
# 扩散步数
self.T = timesteps
self.parametrization = parametrization
# 正则化参数, norm_values, norm_biases
self.norm_values = norm_values
self.norm_biases = norm_biases
self.register_buffer('buffer', torch.zeros(1))
# 检查正则化norm_values是否合适
if noise_schedule != 'learned':
self.check_issues_norm_values()
在看模型时,我们非常关心损失,模型的损失是什么?怎么计算的?EnVariationalDiffusion模型的损失是在forward 函数中。关于,EnVariationalDiffusion.forward函数:
(1)正则化输入的x,h;
(2)调用compute_loss计算负对数损失或者l2损失。如果是训练时,t0_always=True,否则t0_always为False;
def forward(self, x, h, node_mask=None, edge_mask=None, context=None):
"""
训练时,计算l2损失或者是负对数损失NLL,否则计算负对数损失
Computes the loss (type l2 or NLL) if training. And if eval then always computes NLL.
"""
# Normalize data, take into account volume change in x.
# 正则化输入数据,x,h,为了减少体积的影响
x, h, delta_log_px = self.normalize(x, h, node_mask)
# Reset delta_log_px if not vlb objective.
if self.training and self.loss_type == 'l2':
delta_log_px = torch.zeros_like(delta_log_px)
# 计算损失
if self.training:
# Only 1 forward pass when t0_always is False.
loss, loss_dict = self.compute_loss(x, h, node_mask, edge_mask, context, t0_always=False)
else:
# Less variance in the estimator, costs two forward passes.
loss, loss_dict = self.compute_loss(x, h, node_mask, edge_mask, context, t0_always=True)
neg_log_pxh = loss
# Correct for normalization on x.
assert neg_log_pxh.size() == delta_log_px.size()
neg_log_pxh = neg_log_pxh - delta_log_px
return neg_log_pxhEnVariationalDiffusion.compute_loss()具体计算损失,计算损失的流程。
(1)初始化,随机时间t,通过self.alpha, self.sigma生成噪音eps;
(2)将噪音整合到z_x,z_h中,即代码:z_t = alpha_t * xh + sigma_t * eps,生成特定时间步步含有噪音状态的z_t;
(3)SE3网络预测噪音,即net_out;
(4)调用compute_error计算net_out和eps之间的l2或者mse损失;l2损失为mse损失正则化惩罚的结果;
(5)计算负对数常数损失(z_0);
(6)计算xh的KL损失;
(7)estimator_loss_terms损失;
合并所有损失返回loss,其中,error为模型预测噪音部分的损失。因此,SE3等变扩散网络的损失包含了:噪音的预测的mse/l2损失,模型的常数项负对数损失,xh的KL散度损失;
def compute_loss(self, x, h, node_mask, edge_mask, context, t0_always):
# 扩散模型的损失,输入x, h
"""Computes an estimator for the variational lower bound, or the simple loss (MSE)."""
# This part is about whether to include loss term 0 always.
if t0_always:
# loss_term_0 will be computed separately.
# estimator = loss_0 + loss_t, where t ~ U({1, ..., T})
lowest_t = 1
else:
# estimator = loss_t, where t ~ U({0, ..., T})
lowest_t = 0
# 1. 随机初始化t,生成噪音
# Sample a timestep t.
t_int = torch.randint(
lowest_t, self.T + 1, size=(x.size(0), 1), device=x.device).float()
s_int = t_int - 1
t_is_zero = (t_int == 0).float() # Important to compute log p(x | z0).
# Normalize t to [0, 1]. Note that the negative
# step of s will never be used, since then p(x | z0) is computed.
s = s_int / self.T
t = t_int / self.T
# Compute gamma_s and gamma_t via the network.
gamma_s = self.inflate_batch_array(self.gamma(s), x)
gamma_t = self.inflate_batch_array(self.gamma(t), x)
# Compute alpha_t and sigma_t from gamma.
alpha_t = self.alpha(gamma_t, x)
sigma_t = self.sigma(gamma_t, x)
# Sample zt ~ Normal(alpha_t x, sigma_t) 噪音
eps = self.sample_combined_position_feature_noise(
n_samples=x.size(0), n_nodes=x.size(1), node_mask=node_mask)
# Concatenate x, h[integer] and h[categorical].
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# 2. 将噪音添加到xh中,生成z_xh
# Sample z_t given x, h for timestep t, from q(z_t | x, h)
z_t = alpha_t * xh + sigma_t * eps
diffusion_utils.assert_mean_zero_with_mask(z_t[:, :, :self.n_dims], node_mask)
# 3. se3网络预测噪音
# Neural net prediction.
net_out = self.phi(z_t, t, node_mask, edge_mask, context)
# 4. se3网络计算损失 l2 或者 mse损失;
# 4.1 L2 或者 mse 损失
# Compute the error.
error = self.compute_error(net_out, gamma_t, eps)
if self.training and self.loss_type == 'l2':
SNR_weight = torch.ones_like(error)
else:
# Compute weighting with SNR: (SNR(s-t) - 1) for epsilon parametrization.
SNR_weight = (self.SNR(gamma_s - gamma_t) - 1).squeeze(1).squeeze(1)
assert error.size() == SNR_weight.size()
loss_t_larger_than_zero = 0.5 * SNR_weight * error
# 4.2 负对数常数损失
# The _constants_ depending on sigma_0 from the
# cross entropy term E_q(z0 | x) [log p(x | z0)].
neg_log_constants = -self.log_constants_p_x_given_z0(x, node_mask)
# Reset constants during training with l2 loss.
if self.training and self.loss_type == 'l2':
neg_log_constants = torch.zeros_like(neg_log_constants)
# 4.3 xh的KL散度损失
# The KL between q(z1 | x) and p(z1) = Normal(0, 1). Should be close to zero.
kl_prior = self.kl_prior(xh, node_mask)
# Combining the terms
if t0_always:
loss_t = loss_t_larger_than_zero
num_terms = self.T # Since t=0 is not included here.
estimator_loss_terms = num_terms * loss_t
# Compute noise values for t = 0.
t_zeros = torch.zeros_like(s)
gamma_0 = self.inflate_batch_array(self.gamma(t_zeros), x)
alpha_0 = self.alpha(gamma_0, x)
sigma_0 = self.sigma(gamma_0, x)
# Sample z_0 given x, h for timestep t, from q(z_t | x, h)
eps_0 = self.sample_combined_position_feature_noise(
n_samples=x.size(0), n_nodes=x.size(1), node_mask=node_mask)
z_0 = alpha_0 * xh + sigma_0 * eps_0
net_out = self.phi(z_0, t_zeros, node_mask, edge_mask, context)
# z_0时刻的负对数常数损失
loss_term_0 = -self.log_pxh_given_z0_without_constants(
x, h, z_0, gamma_0, eps_0, net_out, node_mask)
assert kl_prior.size() == estimator_loss_terms.size()
assert kl_prior.size() == neg_log_constants.size()
assert kl_prior.size() == loss_term_0.size()
loss = kl_prior + estimator_loss_terms + neg_log_constants + loss_term_0
else:
# Computes the L_0 term (even if gamma_t is not actually gamma_0)
# and this will later be selected via masking.
loss_term_0 = -self.log_pxh_given_z0_without_constants(
x, h, z_t, gamma_t, eps, net_out, node_mask)
t_is_not_zero = 1 - t_is_zero
loss_t = loss_term_0 * t_is_zero.squeeze() + t_is_not_zero.squeeze() * loss_t_larger_than_zero
# Only upweigh estimator if using the vlb objective.
if self.training and self.loss_type == 'l2':
estimator_loss_terms = loss_t
else:
num_terms = self.T + 1 # Includes t = 0.
estimator_loss_terms = num_terms * loss_t
assert kl_prior.size() == estimator_loss_terms.size()
assert kl_prior.size() == neg_log_constants.size()
loss = kl_prior + estimator_loss_terms + neg_log_constants
assert len(loss.shape) == 1, f'{loss.shape} has more than only batch dim.'
return loss, {'t': t_int.squeeze(), 'loss_t': loss.squeeze(),
'error': error.squeeze()}对噪音预测的mse/l2损失代码如下。其中,sum_except_batch函数为将批次展开计算损失。
def compute_error(self, net_out, gamma_t, eps):
"""Computes error, i.e. the most likely prediction of x."""
eps_t = net_out
if self.training and self.loss_type == 'l2':
denom = (self.n_dims + self.in_node_nf) * eps_t.shape[1]
error = sum_except_batch((eps - eps_t) ** 2) / denom
else:
error = sum_except_batch((eps - eps_t) ** 2)
return error
def sum_except_batch(x):
return x.view(x.size(0), -1).sum(-1)计算xh的KL散度损失:
噪音调度器往xh中添加噪音时,是否保持了xh的分布的检验惩罚项。对于不可训练的噪音调度器来说,是固定的。这部分的损失可以忽略不计。
def kl_prior(self, xh, node_mask):
"""Computes the KL between q(z1 | x) and the prior p(z1) = Normal(0, 1).
对于实际上这部分损失可以忽略不计,这部分计算量较大。 但是,对其进行计算,以便在噪声表中出现错误时看到它。
This is essentially a lot of work for something that is in practice negligible in the loss. However, you
compute it so that you see it when you've made a mistake in your noise schedule.
"""
# Compute the last alpha value, alpha_T.
ones = torch.ones((xh.size(0), 1), device=xh.device)
gamma_T = self.gamma(ones)
alpha_T = self.alpha(gamma_T, xh)
# Compute means.
mu_T = alpha_T * xh
mu_T_x, mu_T_h = mu_T[:, :, :self.n_dims], mu_T[:, :, self.n_dims:]
# Compute standard deviations (only batch axis for x-part, inflated for h-part).
sigma_T_x = self.sigma(gamma_T, mu_T_x).squeeze() # Remove inflate, only keep batch dimension for x-part.
sigma_T_h = self.sigma(gamma_T, mu_T_h)
# Compute KL for h-part.
zeros, ones = torch.zeros_like(mu_T_h), torch.ones_like(sigma_T_h)
kl_distance_h = gaussian_KL(mu_T_h, sigma_T_h, zeros, ones, node_mask)
# Compute KL for x-part.
zeros, ones = torch.zeros_like(mu_T_x), torch.ones_like(sigma_T_x)
subspace_d = self.subspace_dimensionality(node_mask)
kl_distance_x = gaussian_KL_for_dimension(mu_T_x, sigma_T_x, zeros, ones, d=subspace_d)
return kl_distance_x + kl_distance_h常数项负对数损失,由log_pxh_given_z0_without_constants函数完成,代码如下。
def log_pxh_given_z0_without_constants(
self, x, h, z_t, gamma_0, eps, net_out, node_mask, epsilon=1e-10):
# Discrete properties are predicted directly from z_t.
z_h_cat = z_t[:, :, self.n_dims:-1] if self.include_charges else z_t[:, :, self.n_dims:] # 原子种类
z_h_int = z_t[:, :, -1:] if self.include_charges else torch.zeros(0).to(z_t.device) # 电荷
# Take only part over x.
eps_x = eps[:, :, :self.n_dims] # 噪音的x部分,即坐标部分
net_x = net_out[:, :, :self.n_dims] # 模型预测的噪音的x部分
# Compute sigma_0 and rescale to the integer scale of the data.
sigma_0 = self.sigma(gamma_0, target_tensor=z_t)
sigma_0_cat = sigma_0 * self.norm_values[1]
sigma_0_int = sigma_0 * self.norm_values[2]
# Computes the error for the distribution N(x | 1 / alpha_0 z_0 + sigma_0/alpha_0 eps_0, sigma_0 / alpha_0),
# the weighting in the epsilon parametrization is exactly '1'.
log_p_x_given_z_without_constants = -0.5 * self.compute_error(net_x, gamma_0, eps_x)
# Compute delta indicator masks.
h_integer = torch.round(h['integer'] * self.norm_values[2] + self.norm_biases[2]).long()
onehot = h['categorical'] * self.norm_values[1] + self.norm_biases[1]
estimated_h_integer = z_h_int * self.norm_values[2] + self.norm_biases[2]
estimated_h_cat = z_h_cat * self.norm_values[1] + self.norm_biases[1]
assert h_integer.size() == estimated_h_integer.size()
h_integer_centered = h_integer - estimated_h_integer
# Compute integral from -0.5 to 0.5 of the normal distribution
# N(mean=h_integer_centered, stdev=sigma_0_int)
log_ph_integer = torch.log(
cdf_standard_gaussian((h_integer_centered + 0.5) / sigma_0_int)
- cdf_standard_gaussian((h_integer_centered - 0.5) / sigma_0_int)
+ epsilon)
log_ph_integer = sum_except_batch(log_ph_integer * node_mask)
# Centered h_cat around 1, since onehot encoded.
centered_h_cat = estimated_h_cat - 1
# Compute integrals from 0.5 to 1.5 of the normal distribution
# N(mean=z_h_cat, stdev=sigma_0_cat)
log_ph_cat_proportional = torch.log(
cdf_standard_gaussian((centered_h_cat + 0.5) / sigma_0_cat)
- cdf_standard_gaussian((centered_h_cat - 0.5) / sigma_0_cat)
+ epsilon)
# Normalize the distribution over the categories.
log_Z = torch.logsumexp(log_ph_cat_proportional, dim=2, keepdim=True)
log_probabilities = log_ph_cat_proportional - log_Z
# Select the log_prob of the current category usign the onehot
# representation.
log_ph_cat = sum_except_batch(log_probabilities * onehot * node_mask)
# Combine categorical and integer log-probabilities.
log_p_h_given_z = log_ph_integer + log_ph_cat
# Combine log probabilities for x and h.
log_p_xh_given_z = log_p_x_given_z_without_constants + log_p_h_given_z
return log_p_xh_given_z至此,SE3等变网络的扩散模型,就介绍完成了。我们也可以看到,SE3网络换成其他的模型都是可以,不一定要用EGNN_dynamics_QM9,直接使用ENGG也没问题。因为,在整个计算损失过程中,仅用到SE3网络预测噪音而已,输入是随机添加噪音的z_x, z_h。
接下来是关于采样,这里的SE3等变扩散模型采样的是z和h的隐向量,即z_x和z_h,由sample/sample_chain函数完成(sample_chain保留了中间的采样状态)。
(1)sample_combined_position_feature_noise随机初始化采样z_t;
(2)由t到0逐步使用sample_p_zs_given_zt函数对z_t进行去噪;
(3)sample_p_xh_given_z0函数z_0时刻,去噪;
(4)检查x部分的质心,返回x,h;
代码如下:
@torch.no_grad()
def sample(self, n_samples, n_nodes, node_mask, edge_mask, context, fix_noise=False):
"""
Draw samples from the generative model.
"""
if fix_noise:
# 每一个分子的z_t相同
# Noise is broadcasted over the batch axis, useful for visualizations.
z = self.sample_combined_position_feature_noise(1, n_nodes, node_mask)
else:
# 每一个分子z_t不同
z = self.sample_combined_position_feature_noise(n_samples, n_nodes, node_mask)
diffusion_utils.assert_mean_zero_with_mask(z[:, :, :self.n_dims], node_mask)
# Iteratively sample p(z_s | z_t) for t = 1, ..., T, with s = t - 1.
# 逐步去噪 z_t -> z_t-1
for s in reversed(range(0, self.T)):
s_array = torch.full((n_samples, 1), fill_value=s, device=z.device)
t_array = s_array + 1
s_array = s_array / self.T
t_array = t_array / self.T
z = self.sample_p_zs_given_zt(s_array, t_array, z, node_mask, edge_mask, context, fix_noise=fix_noise)
# Finally sample p(x, h | z_0).
# z_0 去噪
x, h = self.sample_p_xh_given_z0(z, node_mask, edge_mask, context, fix_noise=fix_noise)
diffusion_utils.assert_mean_zero_with_mask(x, node_mask)
#质心
max_cog = torch.sum(x, dim=1, keepdim=True).abs().max().item()
if max_cog > 5e-2:
print(f'Warning cog drift with error {max_cog:.3f}. Projecting '
f'the positions down.')
# 去质心
x = diffusion_utils.remove_mean_with_mask(x, node_mask)
return x, hSE3等变扩散模型剩下还有很多函数,主要都是为了完成这两个任务(计算损失和采样)的支持函数,包括刚才提到的去噪函数sample_p_zs_given_zt,z_t初始化函数sample_combined_position_feature_noise,噪音调度器sigma, gamma等。
SE3等变扩散模型的完整代码:
class EnVariationalDiffusion(torch.nn.Module):
"""
等变扩散类
The E(n) Diffusion Module.
"""
def __init__(
self,
dynamics: models.EGNN_dynamics_QM9, in_node_nf: int, n_dims: int,
timesteps: int = 1000, parametrization='eps', noise_schedule='learned',
noise_precision=1e-4, loss_type='vlb', norm_values=(1., 1., 1.),
norm_biases=(None, 0., 0.), include_charges=True):
super().__init__()
# 损失类型
assert loss_type in {'vlb', 'l2'}
self.loss_type = loss_type
# 节点特征是否包含电荷charge
self.include_charges = include_charges
# 噪音调度器noise_schedule是否可训练;
# 可训练为 GammaNetwork()
# 不可训练为 PredefinedNoiseSchedule()
if noise_schedule == 'learned':
assert loss_type == 'vlb', 'A noise schedule can only be learned' \
' with a vlb objective.'
# Only supported parametrization.
assert parametrization == 'eps'
if noise_schedule == 'learned':
self.gamma = GammaNetwork()
else:
self.gamma = PredefinedNoiseSchedule(noise_schedule, timesteps=timesteps,
precision=noise_precision)
# The network that will predict the denoising.
# 预测噪音的模型,即SE3模型
self.dynamics = dynamics
# 节点原子类型数,含电荷
self.in_node_nf = in_node_nf
# 坐标维度,3
self.n_dims = n_dims
# 原子种类数
self.num_classes = self.in_node_nf - self.include_charges
# 扩散步数
self.T = timesteps
self.parametrization = parametrization
# 正则化参数, norm_values, norm_biases
self.norm_values = norm_values
self.norm_biases = norm_biases
self.register_buffer('buffer', torch.zeros(1))
# 检查正则化norm_values是否合适
if noise_schedule != 'learned':
self.check_issues_norm_values()
def check_issues_norm_values(self, num_stdevs=8):
# 检查正则化norm_values是否合适
zeros = torch.zeros((1, 1))
gamma_0 = self.gamma(zeros)
sigma_0 = self.sigma(gamma_0, target_tensor=zeros).item()
# Checked if 1 / norm_value is still larger than 10 * standard
# deviation.
max_norm_value = max(self.norm_values[1], self.norm_values[2])
if sigma_0 * num_stdevs > 1. / max_norm_value:
raise ValueError(
f'Value for normalization value {max_norm_value} probably too '
f'large with sigma_0 {sigma_0:.5f} and '
f'1 / norm_value = {1. / max_norm_value}')
def phi(self, x, t, node_mask, edge_mask, context):
# 预测输入x中的噪音
net_out = self.dynamics._forward(t, x, node_mask, edge_mask, context)
return net_out
def inflate_batch_array(self, array, target):
"""
Inflates the batch array (array) with only a single axis (i.e. shape = (batch_size,), or possibly more empty
axes (i.e. shape (batch_size, 1, ..., 1)) to match the target shape.
"""
target_shape = (array.size(0),) + (1,) * (len(target.size()) - 1)
return array.view(target_shape)
def sigma(self, gamma, target_tensor):
"""Computes sigma given gamma."""
return self.inflate_batch_array(torch.sqrt(torch.sigmoid(gamma)), target_tensor)
def alpha(self, gamma, target_tensor):
"""Computes alpha given gamma."""
return self.inflate_batch_array(torch.sqrt(torch.sigmoid(-gamma)), target_tensor)
def SNR(self, gamma):
"""Computes signal to noise ratio (alpha^2/sigma^2) given gamma."""
return torch.exp(-gamma)
def subspace_dimensionality(self, node_mask):
"""Compute the dimensionality on translation-invariant linear subspace where distributions on x are defined."""
number_of_nodes = torch.sum(node_mask.squeeze(2), dim=1)
return (number_of_nodes - 1) * self.n_dims
def normalize(self, x, h, node_mask):
'''
x和h的正则化,
x/norm_values[0]
h_cat = (h_cat-norm_biases[1])/norm_values[1]
h_int = (h_int-norm_biases[1])/norm_values[1]
'''
x = x / self.norm_values[0]
delta_log_px = -self.subspace_dimensionality(node_mask) * np.log(self.norm_values[0])
# Casting to float in case h still has long or int type.
h_cat = (h['categorical'].float() - self.norm_biases[1]) / self.norm_values[1] * node_mask
h_int = (h['integer'].float() - self.norm_biases[2]) / self.norm_values[2]
if self.include_charges:
h_int = h_int * node_mask
# Create new h dictionary.
h = {'categorical': h_cat, 'integer': h_int}
return x, h, delta_log_px
def unnormalize(self, x, h_cat, h_int, node_mask):
# x,h的去正则化
x = x * self.norm_values[0]
h_cat = h_cat * self.norm_values[1] + self.norm_biases[1]
h_cat = h_cat * node_mask
h_int = h_int * self.norm_values[2] + self.norm_biases[2]
if self.include_charges:
h_int = h_int * node_mask
return x, h_cat, h_int
def unnormalize_z(self, z, node_mask):
# z 去正则化
# Parse from z
x, h_cat = z[:, :, 0:self.n_dims], z[:, :, self.n_dims:self.n_dims+self.num_classes]
h_int = z[:, :, self.n_dims+self.num_classes:self.n_dims+self.num_classes+1]
assert h_int.size(2) == self.include_charges
# Unnormalize
x, h_cat, h_int = self.unnormalize(x, h_cat, h_int, node_mask)
output = torch.cat([x, h_cat, h_int], dim=2)
return output
def sigma_and_alpha_t_given_s(self, gamma_t: torch.Tensor, gamma_s: torch.Tensor, target_tensor: torch.Tensor):
"""
Computes sigma t given s, using gamma_t and gamma_s. Used during sampling.
These are defined as:
alpha t given s = alpha t / alpha s,
sigma t given s = sqrt(1 - (alpha t given s) ^2 ).
"""
sigma2_t_given_s = self.inflate_batch_array(
-expm1(softplus(gamma_s) - softplus(gamma_t)), target_tensor
)
# alpha_t_given_s = alpha_t / alpha_s
log_alpha2_t = F.logsigmoid(-gamma_t)
log_alpha2_s = F.logsigmoid(-gamma_s)
log_alpha2_t_given_s = log_alpha2_t - log_alpha2_s
alpha_t_given_s = torch.exp(0.5 * log_alpha2_t_given_s)
alpha_t_given_s = self.inflate_batch_array(
alpha_t_given_s, target_tensor)
sigma_t_given_s = torch.sqrt(sigma2_t_given_s)
return sigma2_t_given_s, sigma_t_given_s, alpha_t_given_s
def kl_prior(self, xh, node_mask):
"""Computes the KL between q(z1 | x) and the prior p(z1) = Normal(0, 1).
对于实际上这部分损失可以忽略不计,这部分计算量较大。 但是,对其进行计算,以便在噪声表中出现错误时看到它。
This is essentially a lot of work for something that is in practice negligible in the loss. However, you
compute it so that you see it when you've made a mistake in your noise schedule.
"""
# Compute the last alpha value, alpha_T.
ones = torch.ones((xh.size(0), 1), device=xh.device)
gamma_T = self.gamma(ones)
alpha_T = self.alpha(gamma_T, xh)
# Compute means.
mu_T = alpha_T * xh
mu_T_x, mu_T_h = mu_T[:, :, :self.n_dims], mu_T[:, :, self.n_dims:]
# Compute standard deviations (only batch axis for x-part, inflated for h-part).
sigma_T_x = self.sigma(gamma_T, mu_T_x).squeeze() # Remove inflate, only keep batch dimension for x-part.
sigma_T_h = self.sigma(gamma_T, mu_T_h)
# Compute KL for h-part.
zeros, ones = torch.zeros_like(mu_T_h), torch.ones_like(sigma_T_h)
kl_distance_h = gaussian_KL(mu_T_h, sigma_T_h, zeros, ones, node_mask)
# Compute KL for x-part.
zeros, ones = torch.zeros_like(mu_T_x), torch.ones_like(sigma_T_x)
subspace_d = self.subspace_dimensionality(node_mask)
kl_distance_x = gaussian_KL_for_dimension(mu_T_x, sigma_T_x, zeros, ones, d=subspace_d)
return kl_distance_x + kl_distance_h
def compute_x_pred(self, net_out, zt, gamma_t):
"""Commputes x_pred, i.e. the most likely prediction of x."""
if self.parametrization == 'x':
x_pred = net_out
elif self.parametrization == 'eps':
sigma_t = self.sigma(gamma_t, target_tensor=net_out)
alpha_t = self.alpha(gamma_t, target_tensor=net_out)
eps_t = net_out
x_pred = 1. / alpha_t * (zt - sigma_t * eps_t)
else:
raise ValueError(self.parametrization)
return x_pred
def compute_error(self, net_out, gamma_t, eps):
"""Computes error, i.e. the most likely prediction of x."""
eps_t = net_out
if self.training and self.loss_type == 'l2':
denom = (self.n_dims + self.in_node_nf) * eps_t.shape[1]
error = sum_except_batch((eps - eps_t) ** 2) / denom
else:
error = sum_except_batch((eps - eps_t) ** 2)
return error
def log_constants_p_x_given_z0(self, x, node_mask):
"""Computes p(x|z0)."""
batch_size = x.size(0)
n_nodes = node_mask.squeeze(2).sum(1) # N has shape [B]
assert n_nodes.size() == (batch_size,)
degrees_of_freedom_x = (n_nodes - 1) * self.n_dims
zeros = torch.zeros((x.size(0), 1), device=x.device)
gamma_0 = self.gamma(zeros)
# Recall that sigma_x = sqrt(sigma_0^2 / alpha_0^2) = SNR(-0.5 gamma_0).
log_sigma_x = 0.5 * gamma_0.view(batch_size)
return degrees_of_freedom_x * (- log_sigma_x - 0.5 * np.log(2 * np.pi))
def sample_p_xh_given_z0(self, z0, node_mask, edge_mask, context, fix_noise=False):
"""Samples x ~ p(x|z0)."""
zeros = torch.zeros(size=(z0.size(0), 1), device=z0.device)
gamma_0 = self.gamma(zeros)
# Computes sqrt(sigma_0^2 / alpha_0^2)
sigma_x = self.SNR(-0.5 * gamma_0).unsqueeze(1)
net_out = self.phi(z0, zeros, node_mask, edge_mask, context)
# Compute mu for p(zs | zt).
mu_x = self.compute_x_pred(net_out, z0, gamma_0)
xh = self.sample_normal(mu=mu_x, sigma=sigma_x, node_mask=node_mask, fix_noise=fix_noise)
x = xh[:, :, :self.n_dims]
h_int = z0[:, :, -1:] if self.include_charges else torch.zeros(0).to(z0.device)
x, h_cat, h_int = self.unnormalize(x, z0[:, :, self.n_dims:-1], h_int, node_mask)
h_cat = F.one_hot(torch.argmax(h_cat, dim=2), self.num_classes) * node_mask
h_int = torch.round(h_int).long() * node_mask
h = {'integer': h_int, 'categorical': h_cat}
return x, h
def sample_normal(self, mu, sigma, node_mask, fix_noise=False):
"""Samples from a Normal distribution."""
bs = 1 if fix_noise else mu.size(0)
eps = self.sample_combined_position_feature_noise(bs, mu.size(1), node_mask)
return mu + sigma * eps
def log_pxh_given_z0_without_constants(
self, x, h, z_t, gamma_0, eps, net_out, node_mask, epsilon=1e-10):
# Discrete properties are predicted directly from z_t.
z_h_cat = z_t[:, :, self.n_dims:-1] if self.include_charges else z_t[:, :, self.n_dims:] # 原子种类
z_h_int = z_t[:, :, -1:] if self.include_charges else torch.zeros(0).to(z_t.device) # 电荷
# Take only part over x.
eps_x = eps[:, :, :self.n_dims] # 噪音的x部分,即坐标部分
net_x = net_out[:, :, :self.n_dims] # 模型预测的噪音的x部分
# Compute sigma_0 and rescale to the integer scale of the data.
sigma_0 = self.sigma(gamma_0, target_tensor=z_t)
sigma_0_cat = sigma_0 * self.norm_values[1]
sigma_0_int = sigma_0 * self.norm_values[2]
# Computes the error for the distribution N(x | 1 / alpha_0 z_0 + sigma_0/alpha_0 eps_0, sigma_0 / alpha_0),
# the weighting in the epsilon parametrization is exactly '1'.
log_p_x_given_z_without_constants = -0.5 * self.compute_error(net_x, gamma_0, eps_x)
# Compute delta indicator masks.
h_integer = torch.round(h['integer'] * self.norm_values[2] + self.norm_biases[2]).long()
onehot = h['categorical'] * self.norm_values[1] + self.norm_biases[1]
estimated_h_integer = z_h_int * self.norm_values[2] + self.norm_biases[2]
estimated_h_cat = z_h_cat * self.norm_values[1] + self.norm_biases[1]
assert h_integer.size() == estimated_h_integer.size()
h_integer_centered = h_integer - estimated_h_integer
# Compute integral from -0.5 to 0.5 of the normal distribution
# N(mean=h_integer_centered, stdev=sigma_0_int)
log_ph_integer = torch.log(
cdf_standard_gaussian((h_integer_centered + 0.5) / sigma_0_int)
- cdf_standard_gaussian((h_integer_centered - 0.5) / sigma_0_int)
+ epsilon)
log_ph_integer = sum_except_batch(log_ph_integer * node_mask)
# Centered h_cat around 1, since onehot encoded.
centered_h_cat = estimated_h_cat - 1
# Compute integrals from 0.5 to 1.5 of the normal distribution
# N(mean=z_h_cat, stdev=sigma_0_cat)
log_ph_cat_proportional = torch.log(
cdf_standard_gaussian((centered_h_cat + 0.5) / sigma_0_cat)
- cdf_standard_gaussian((centered_h_cat - 0.5) / sigma_0_cat)
+ epsilon)
# Normalize the distribution over the categories.
log_Z = torch.logsumexp(log_ph_cat_proportional, dim=2, keepdim=True)
log_probabilities = log_ph_cat_proportional - log_Z
# Select the log_prob of the current category usign the onehot
# representation.
log_ph_cat = sum_except_batch(log_probabilities * onehot * node_mask)
# Combine categorical and integer log-probabilities.
log_p_h_given_z = log_ph_integer + log_ph_cat
# Combine log probabilities for x and h.
log_p_xh_given_z = log_p_x_given_z_without_constants + log_p_h_given_z
return log_p_xh_given_z
def compute_loss(self, x, h, node_mask, edge_mask, context, t0_always):
# 扩散模型的损失,输入x, h
"""Computes an estimator for the variational lower bound, or the simple loss (MSE)."""
# This part is about whether to include loss term 0 always.
if t0_always:
# loss_term_0 will be computed separately.
# estimator = loss_0 + loss_t, where t ~ U({1, ..., T})
lowest_t = 1
else:
# estimator = loss_t, where t ~ U({0, ..., T})
lowest_t = 0
# 1. 随机初始化t,生成噪音
# Sample a timestep t.
t_int = torch.randint(
lowest_t, self.T + 1, size=(x.size(0), 1), device=x.device).float()
s_int = t_int - 1
t_is_zero = (t_int == 0).float() # Important to compute log p(x | z0).
# Normalize t to [0, 1]. Note that the negative
# step of s will never be used, since then p(x | z0) is computed.
s = s_int / self.T
t = t_int / self.T
# Compute gamma_s and gamma_t via the network.
gamma_s = self.inflate_batch_array(self.gamma(s), x)
gamma_t = self.inflate_batch_array(self.gamma(t), x)
# Compute alpha_t and sigma_t from gamma.
alpha_t = self.alpha(gamma_t, x)
sigma_t = self.sigma(gamma_t, x)
# Sample zt ~ Normal(alpha_t x, sigma_t) 噪音
eps = self.sample_combined_position_feature_noise(
n_samples=x.size(0), n_nodes=x.size(1), node_mask=node_mask)
# Concatenate x, h[integer] and h[categorical].
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# 2. 将噪音添加到xh中,生成z_xh
# Sample z_t given x, h for timestep t, from q(z_t | x, h)
z_t = alpha_t * xh + sigma_t * eps
diffusion_utils.assert_mean_zero_with_mask(z_t[:, :, :self.n_dims], node_mask)
# 3. se3网络预测噪音
# Neural net prediction.
net_out = self.phi(z_t, t, node_mask, edge_mask, context)
# 4. se3网络计算损失 l2 或者 mse损失;
# 4.1 L2 或者 mse 损失
# Compute the error.
error = self.compute_error(net_out, gamma_t, eps)
if self.training and self.loss_type == 'l2':
SNR_weight = torch.ones_like(error)
else:
# Compute weighting with SNR: (SNR(s-t) - 1) for epsilon parametrization.
SNR_weight = (self.SNR(gamma_s - gamma_t) - 1).squeeze(1).squeeze(1)
assert error.size() == SNR_weight.size()
loss_t_larger_than_zero = 0.5 * SNR_weight * error
# 4.2 负对数常数损失
# The _constants_ depending on sigma_0 from the
# cross entropy term E_q(z0 | x) [log p(x | z0)].
neg_log_constants = -self.log_constants_p_x_given_z0(x, node_mask)
# Reset constants during training with l2 loss.
if self.training and self.loss_type == 'l2':
neg_log_constants = torch.zeros_like(neg_log_constants)
# 4.3 xh的KL散度损失
# The KL between q(z1 | x) and p(z1) = Normal(0, 1). Should be close to zero.
kl_prior = self.kl_prior(xh, node_mask)
# Combining the terms
if t0_always:
loss_t = loss_t_larger_than_zero
num_terms = self.T # Since t=0 is not included here.
estimator_loss_terms = num_terms * loss_t
# Compute noise values for t = 0.
t_zeros = torch.zeros_like(s)
gamma_0 = self.inflate_batch_array(self.gamma(t_zeros), x)
alpha_0 = self.alpha(gamma_0, x)
sigma_0 = self.sigma(gamma_0, x)
# Sample z_0 given x, h for timestep t, from q(z_t | x, h)
eps_0 = self.sample_combined_position_feature_noise(
n_samples=x.size(0), n_nodes=x.size(1), node_mask=node_mask)
z_0 = alpha_0 * xh + sigma_0 * eps_0
net_out = self.phi(z_0, t_zeros, node_mask, edge_mask, context)
# z_0时刻的副队负对数常数损失
loss_term_0 = -self.log_pxh_given_z0_without_constants(
x, h, z_0, gamma_0, eps_0, net_out, node_mask)
assert kl_prior.size() == estimator_loss_terms.size()
assert kl_prior.size() == neg_log_constants.size()
assert kl_prior.size() == loss_term_0.size()
loss = kl_prior + estimator_loss_terms + neg_log_constants + loss_term_0
else:
# Computes the L_0 term (even if gamma_t is not actually gamma_0)
# and this will later be selected via masking.
loss_term_0 = -self.log_pxh_given_z0_without_constants(
x, h, z_t, gamma_t, eps, net_out, node_mask)
t_is_not_zero = 1 - t_is_zero
loss_t = loss_term_0 * t_is_zero.squeeze() + t_is_not_zero.squeeze() * loss_t_larger_than_zero
# Only upweigh estimator if using the vlb objective.
if self.training and self.loss_type == 'l2':
estimator_loss_terms = loss_t
else:
num_terms = self.T + 1 # Includes t = 0.
estimator_loss_terms = num_terms * loss_t
assert kl_prior.size() == estimator_loss_terms.size()
assert kl_prior.size() == neg_log_constants.size()
loss = kl_prior + estimator_loss_terms + neg_log_constants
assert len(loss.shape) == 1, f'{loss.shape} has more than only batch dim.'
return loss, {'t': t_int.squeeze(), 'loss_t': loss.squeeze(),
'error': error.squeeze()}
def forward(self, x, h, node_mask=None, edge_mask=None, context=None):
"""
训练时,计算l2损失或者是负对数损失NLL,否则计算负对数损失
Computes the loss (type l2 or NLL) if training. And if eval then always computes NLL.
"""
# Normalize data, take into account volume change in x.
# 正则化输入数据,x,h,为了减少体积的影响
x, h, delta_log_px = self.normalize(x, h, node_mask)
# Reset delta_log_px if not vlb objective.
if self.training and self.loss_type == 'l2':
delta_log_px = torch.zeros_like(delta_log_px)
# 计算损失
if self.training:
# Only 1 forward pass when t0_always is False.
loss, loss_dict = self.compute_loss(x, h, node_mask, edge_mask, context, t0_always=False)
else:
# Less variance in the estimator, costs two forward passes.
loss, loss_dict = self.compute_loss(x, h, node_mask, edge_mask, context, t0_always=True)
neg_log_pxh = loss
# Correct for normalization on x.
assert neg_log_pxh.size() == delta_log_px.size()
neg_log_pxh = neg_log_pxh - delta_log_px
return neg_log_pxh
def sample_p_zs_given_zt(self, s, t, zt, node_mask, edge_mask, context, fix_noise=False):
"""Samples from zs ~ p(zs | zt). Only used during sampling."""
gamma_s = self.gamma(s)
gamma_t = self.gamma(t)
sigma2_t_given_s, sigma_t_given_s, alpha_t_given_s = \
self.sigma_and_alpha_t_given_s(gamma_t, gamma_s, zt)
sigma_s = self.sigma(gamma_s, target_tensor=zt)
sigma_t = self.sigma(gamma_t, target_tensor=zt)
# Neural net prediction.
eps_t = self.phi(zt, t, node_mask, edge_mask, context)
# Compute mu for p(zs | zt).
diffusion_utils.assert_mean_zero_with_mask(zt[:, :, :self.n_dims], node_mask)
diffusion_utils.assert_mean_zero_with_mask(eps_t[:, :, :self.n_dims], node_mask)
mu = zt / alpha_t_given_s - (sigma2_t_given_s / alpha_t_given_s / sigma_t) * eps_t
# Compute sigma for p(zs | zt).
sigma = sigma_t_given_s * sigma_s / sigma_t
# Sample zs given the paramters derived from zt.
zs = self.sample_normal(mu, sigma, node_mask, fix_noise)
# Project down to avoid numerical runaway of the center of gravity.
zs = torch.cat(
[diffusion_utils.remove_mean_with_mask(zs[:, :, :self.n_dims],
node_mask),
zs[:, :, self.n_dims:]], dim=2
)
return zs
def sample_combined_position_feature_noise(self, n_samples, n_nodes, node_mask):
"""
# 对 z_x 采样以均值为中心的正态噪声,对 z_h 采样标准正态噪声
Samples mean-centered normal noise for z_x, and standard normal noise for z_h.
"""
z_x = utils.sample_center_gravity_zero_gaussian_with_mask(
size=(n_samples, n_nodes, self.n_dims), device=node_mask.device,
node_mask=node_mask)
z_h = utils.sample_gaussian_with_mask(
size=(n_samples, n_nodes, self.in_node_nf), device=node_mask.device,
node_mask=node_mask)
z = torch.cat([z_x, z_h], dim=2)
return z
@torch.no_grad()
def sample(self, n_samples, n_nodes, node_mask, edge_mask, context, fix_noise=False):
"""
Draw samples from the generative model.
"""
if fix_noise:
# 每一个分子的z_t相同
# Noise is broadcasted over the batch axis, useful for visualizations.
z = self.sample_combined_position_feature_noise(1, n_nodes, node_mask)
else:
# 每一个分子z_t不同
z = self.sample_combined_position_feature_noise(n_samples, n_nodes, node_mask)
diffusion_utils.assert_mean_zero_with_mask(z[:, :, :self.n_dims], node_mask)
# Iteratively sample p(z_s | z_t) for t = 1, ..., T, with s = t - 1.
# 逐步去噪 z_t -> z_t-1
for s in reversed(range(0, self.T)):
s_array = torch.full((n_samples, 1), fill_value=s, device=z.device)
t_array = s_array + 1
s_array = s_array / self.T
t_array = t_array / self.T
z = self.sample_p_zs_given_zt(s_array, t_array, z, node_mask, edge_mask, context, fix_noise=fix_noise)
# Finally sample p(x, h | z_0).
# z_0 去噪
x, h = self.sample_p_xh_given_z0(z, node_mask, edge_mask, context, fix_noise=fix_noise)
diffusion_utils.assert_mean_zero_with_mask(x, node_mask)
#质心
max_cog = torch.sum(x, dim=1, keepdim=True).abs().max().item()
if max_cog > 5e-2:
print(f'Warning cog drift with error {max_cog:.3f}. Projecting '
f'the positions down.')
# 去质心
x = diffusion_utils.remove_mean_with_mask(x, node_mask)
return x, h
@torch.no_grad()
def sample_chain(self, n_samples, n_nodes, node_mask, edge_mask, context, keep_frames=None):
"""
Draw samples from the generative model, keep the intermediate states for visualization purposes.
"""
z = self.sample_combined_position_feature_noise(n_samples, n_nodes, node_mask)
diffusion_utils.assert_mean_zero_with_mask(z[:, :, :self.n_dims], node_mask)
if keep_frames is None:
keep_frames = self.T
else:
assert keep_frames <= self.T
chain = torch.zeros((keep_frames,) + z.size(), device=z.device)
# Iteratively sample p(z_s | z_t) for t = 1, ..., T, with s = t - 1.
for s in reversed(range(0, self.T)):
s_array = torch.full((n_samples, 1), fill_value=s, device=z.device)
t_array = s_array + 1
s_array = s_array / self.T
t_array = t_array / self.T
z = self.sample_p_zs_given_zt(
s_array, t_array, z, node_mask, edge_mask, context)
diffusion_utils.assert_mean_zero_with_mask(z[:, :, :self.n_dims], node_mask)
# Write to chain tensor.
write_index = (s * keep_frames) // self.T
chain[write_index] = self.unnormalize_z(z, node_mask)
# Finally sample p(x, h | z_0).
x, h = self.sample_p_xh_given_z0(z, node_mask, edge_mask, context)
diffusion_utils.assert_mean_zero_with_mask(x[:, :, :self.n_dims], node_mask)
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
chain[0] = xh # Overwrite last frame with the resulting x and h.
chain_flat = chain.view(n_samples * keep_frames, *z.size()[1:])
return chain_flat
def log_info(self):
"""
Some info logging of the model.
"""
gamma_0 = self.gamma(torch.zeros(1, device=self.buffer.device))
gamma_1 = self.gamma(torch.ones(1, device=self.buffer.device))
log_SNR_max = -gamma_0
log_SNR_min = -gamma_1
info = {
'log_SNR_max': log_SNR_max.item(),
'log_SNR_min': log_SNR_min.item()}
print(info)
return info2.2.2.3 VAE模型结构 (EnHierarchicalVAE)
get_autoencoder函数在3.2加载模型和3.2.1 GeoLDM部分均出现过,其用途是加载一个VAE模型。
VAE模型由get_autoencoder函数导入,代码如下:
def get_autoencoder(args, device, dataset_info, dataloader_train):
histogram = dataset_info['n_nodes']
in_node_nf = len(dataset_info['atom_decoder']) + int(args.include_charges)
nodes_dist = DistributionNodes(histogram)
prop_dist = None
if len(args.conditioning) > 0:
prop_dist = DistributionProperty(dataloader_train, args.conditioning)
# if args.condition_time:
# dynamics_in_node_nf = in_node_nf + 1
# else:
print('Autoencoder models are _not_ conditioned on time.')
# dynamics_in_node_nf = in_node_nf
# 编码器, 也是一个ENGG网络,注意输出维度是args.latent_nf, 输入维度是in_node_nf
encoder = EGNN_encoder_QM9(
in_node_nf=in_node_nf, context_node_nf=args.context_node_nf, out_node_nf=args.latent_nf,
n_dims=3, device=device, hidden_nf=args.nf,
act_fn=torch.nn.SiLU(), n_layers=1,
attention=args.attention, tanh=args.tanh, mode=args.model, norm_constant=args.norm_constant,
inv_sublayers=args.inv_sublayers, sin_embedding=args.sin_embedding,
normalization_factor=args.normalization_factor, aggregation_method=args.aggregation_method,
include_charges=args.include_charges
)
# 解码器,也是一个ENGG网络,注意,输入的维度是args.latent_nf, 输出维度是in_node_nf
decoder = EGNN_decoder_QM9(
in_node_nf=args.latent_nf, context_node_nf=args.context_node_nf, out_node_nf=in_node_nf,
n_dims=3, device=device, hidden_nf=args.nf,
act_fn=torch.nn.SiLU(), n_layers=args.n_layers,
attention=args.attention, tanh=args.tanh, mode=args.model, norm_constant=args.norm_constant,
inv_sublayers=args.inv_sublayers, sin_embedding=args.sin_embedding,
normalization_factor=args.normalization_factor, aggregation_method=args.aggregation_method,
include_charges=args.include_charges
)
vae = EnHierarchicalVAE(
encoder=encoder,
decoder=decoder,
in_node_nf=in_node_nf,
n_dims=3,
latent_node_nf=args.latent_nf,
kl_weight=args.kl_weight,
norm_values=args.normalize_factors,
include_charges=args.include_charges
)
return vae, nodes_dist, prop_distVAE模型的编码器和解码器,都是一个EGNN_encoder_QM9网络。要注意的是编码器和解码器的输入和输出维度是对应的。编码器将分子中各原子特征嵌入至args.latent_nf维,解码器将其还原至in_node_nf维。编码器和解码器的结构是完全对应的,包括层数等。
整个VAE模型由EnHierarchicalVAE实现,与VAE模型架构基本一致,包含了(注:这部分并未包含diffusion部分)。VAE部分的代码比较简单,就不详细介绍了:
1. compute_reconstruction_error计算重构损失;
- compute_loss计算重构损失和KL散度损失之和;
- forward函数计算重构损失和KL散度损失之和;
- 编码器 encode;
- 解码器 decode(返回原子类型one-hot);
EnHierarchicalVAE代码如下:
class EnHierarchicalVAE(torch.nn.Module):
"""
VAE 模块
The E(n) Hierarchical VAE Module.
"""
def __init__(
self,
encoder: models.EGNN_encoder_QM9,
decoder: models.EGNN_decoder_QM9,
in_node_nf: int, n_dims: int, latent_node_nf: int,
kl_weight: float,
norm_values=(1., 1., 1.), norm_biases=(None, 0., 0.),
include_charges=True):
super().__init__()
self.include_charges = include_charges
self.encoder = encoder
self.decoder = decoder
self.in_node_nf = in_node_nf
self.n_dims = n_dims
self.latent_node_nf = latent_node_nf
self.num_classes = self.in_node_nf - self.include_charges
self.kl_weight = kl_weight
self.norm_values = norm_values
self.norm_biases = norm_biases
self.register_buffer('buffer', torch.zeros(1))
def subspace_dimensionality(self, node_mask):
# 计算定义 x 分布的平移不变线性子空间的维数,即
"""Compute the dimensionality on translation-invariant linear subspace where distributions on x are defined."""
number_of_nodes = torch.sum(node_mask.squeeze(2), dim=1)
return (number_of_nodes - 1) * self.n_dims
def compute_reconstruction_error(self, xh_rec, xh):
# 计算重构损失
"""Computes reconstruction error."""
bs, n_nodes, dims = xh.shape
# Error on positions. 原子坐标位置损失
x_rec = xh_rec[:, :, :self.n_dims]
x = xh[:, :, :self.n_dims]
error_x = sum_except_batch((x_rec - x) ** 2) # sum_except_batch函数 一维求和
# Error on classes. 原子类型分类,交叉熵
h_cat_rec = xh_rec[:, :, self.n_dims:self.n_dims + self.num_classes]
h_cat = xh[:, :, self.n_dims:self.n_dims + self.num_classes]
h_cat_rec = h_cat_rec.reshape(bs * n_nodes, self.num_classes)
h_cat = h_cat.reshape(bs * n_nodes, self.num_classes)
error_h_cat = F.cross_entropy(h_cat_rec, h_cat.argmax(dim=1), reduction='none')
error_h_cat = error_h_cat.reshape(bs, n_nodes, 1)
error_h_cat = sum_except_batch(error_h_cat)
# error_h_cat = sum_except_batch((h_cat_rec - h_cat) ** 2)
# Error on charges. # 电荷类型损失
if self.include_charges:
h_int_rec = xh_rec[:, :, -self.include_charges:]
h_int = xh[:, :, -self.include_charges:]
error_h_int = sum_except_batch((h_int_rec - h_int) ** 2)
else:
error_h_int = 0.
# 损失合计
error = error_x + error_h_cat + error_h_int
if self.training:
denom = (self.n_dims + self.in_node_nf) * xh.shape[1]
error = error / denom
return error
def sample_normal(self, mu, sigma, node_mask, fix_noise=False):
"""Samples from a Normal distribution."""
bs = 1 if fix_noise else mu.size(0)
eps = self.sample_combined_position_feature_noise(bs, mu.size(1), node_mask)
return mu + sigma * eps
def compute_loss(self, x, h, node_mask, edge_mask, context):
# 计算变分下界的估计量
"""Computes an estimator for the variational lower bound."""
# Concatenate x, h[integer] and h[categorical].
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# Encoder output. 编码器输出
z_x_mu, z_x_sigma, z_h_mu, z_h_sigma = self.encode(x, h, node_mask, edge_mask, context)
# KL distance. KL散度(两个正态分布之间的散度)
# KL for invariant features. 不变特征,即h
zeros, ones = torch.zeros_like(z_h_mu), torch.ones_like(z_h_sigma)
loss_kl_h = gaussian_KL(z_h_mu, ones, zeros, ones, node_mask)
# KL for equivariant features. 等变特征,即x
assert z_x_sigma.mean(dim=(1,2), keepdim=True).expand_as(z_x_sigma).allclose(z_x_sigma, atol=1e-7)
zeros, ones = torch.zeros_like(z_x_mu), torch.ones_like(z_x_sigma.mean(dim=(1,2)))
subspace_d = self.subspace_dimensionality(node_mask)
loss_kl_x = gaussian_KL_for_dimension(z_x_mu, ones, zeros, ones, subspace_d)
loss_kl = loss_kl_h + loss_kl_x
# Infer latent z.
z_xh_mean = torch.cat([z_x_mu, z_h_mu], dim=2)
diffusion_utils.assert_correctly_masked(z_xh_mean, node_mask)
z_xh_sigma = torch.cat([z_x_sigma.expand(-1, -1, 3), z_h_sigma], dim=2)
# 采样z_xh
z_xh = self.sample_normal(z_xh_mean, z_xh_sigma, node_mask)
# z_xh = z_xh_mean
diffusion_utils.assert_correctly_masked(z_xh, node_mask)
diffusion_utils.assert_mean_zero_with_mask(z_xh[:, :, :self.n_dims], node_mask)
# Decoder output (reconstruction). 解码器输出,重构损失
x_recon, h_recon = self.decoder._forward(z_xh, node_mask, edge_mask, context)
xh_rec = torch.cat([x_recon, h_recon], dim=2)
# 重构损失
loss_recon = self.compute_reconstruction_error(xh_rec, xh)
# Combining the terms 损失:KL散度+重构损失
assert loss_recon.size() == loss_kl.size()
loss = loss_recon + self.kl_weight * loss_kl
assert len(loss.shape) == 1, f'{loss.shape} has more than only batch dim.'
return loss, {'loss_t': loss.squeeze(), 'rec_error': loss_recon.squeeze()}
def forward(self, x, h, node_mask=None, edge_mask=None, context=None):
# 计算训练的 ELBOW。 如果 eval 则总是计算 Nll
"""
Computes the ELBO if training. And if eval then always computes NLL.
"""
loss, loss_dict = self.compute_loss(x, h, node_mask, edge_mask, context)
neg_log_pxh = loss
return neg_log_pxh
def sample_combined_position_feature_noise(self, n_samples, n_nodes, node_mask):
# 对 z_x 采样以质心为零的正态噪声,对 z_h 采样标准正态噪声
"""
Samples mean-centered normal noise for z_x, and standard normal noise for z_h.
"""
z_x = utils.sample_center_gravity_zero_gaussian_with_mask(
size=(n_samples, n_nodes, self.n_dims), device=node_mask.device,
node_mask=node_mask)
z_h = utils.sample_gaussian_with_mask(
size=(n_samples, n_nodes, self.latent_node_nf), device=node_mask.device,
node_mask=node_mask)
z = torch.cat([z_x, z_h], dim=2)
return z
def encode(self, x, h, node_mask=None, edge_mask=None, context=None):
# 编码器
"""Computes q(z|x)."""
# Concatenate x, h[integer] and h[categorical].
xh = torch.cat([x, h['categorical'], h['integer']], dim=2)
# 检查质心是否为0
diffusion_utils.assert_mean_zero_with_mask(xh[:, :, :self.n_dims], node_mask)
# Encoder output. 编码器输出
z_x_mu, z_x_sigma, z_h_mu, z_h_sigma = self.encoder._forward(xh, node_mask, edge_mask, context)
bs, _, _ = z_x_mu.size()
sigma_0_x = torch.ones(bs, 1, 1).to(z_x_mu) * 0.0032 # 标准差?
sigma_0_h = torch.ones(bs, 1, self.latent_node_nf).to(z_h_mu) * 0.0032 # 标准差?
return z_x_mu, sigma_0_x, z_h_mu, sigma_0_h
def decode(self, z_xh, node_mask=None, edge_mask=None, context=None):
# 解码器, 返回原子坐标x和原子类型h,不包括电荷特征
"""Computes p(x|z)."""
# Decoder output (reconstruction).
x_recon, h_recon = self.decoder._forward(z_xh, node_mask, edge_mask, context)
# 检查重构后x的质心是否为0
diffusion_utils.assert_mean_zero_with_mask(x_recon, node_mask)
xh = torch.cat([x_recon, h_recon], dim=2)
x = xh[:, :, :self.n_dims]
diffusion_utils.assert_correctly_masked(x, node_mask)
h_int = xh[:, :, -1:] if self.include_charges else torch.zeros(0).to(xh)
h_cat = xh[:, :, self.n_dims:-1] # TODO: have issue when include_charges is False
h_cat = F.one_hot(torch.argmax(h_cat, dim=2), self.num_classes) * node_mask
h_int = torch.round(h_int).long() * node_mask
h = {'integer': h_int, 'categorical': h_cat}
return x, h
@torch.no_grad()
def reconstruct(self, x, h, node_mask=None, edge_mask=None, context=None):
pass
def log_info(self):
"""
Some info logging of the model.
"""
info = None
print(info)
return info
def disabled_train(self, mode=True):
"""Overwrite model.train with this function to make sure train/eval mode
does not change anymore."""
return self2.3 GeoLDM分子生成代码
作者并没有直接提供生成分子的代码。而是通过评估模型的形式,发布了生成分子的方法(即分子生成和模型评估放在了一起)。要生成分子并评估模型性能,需要在./目录下执行如下代码:
python eval_analyze.py \
--model_path outputs/pretrained/drugs_latent2 \
--n_samples 10
–model_path:被评估的模型是预训练好的模型,保存在outputs/pretrained/drugs_latent2路径。
现在来看一下eval_analyze.py代码。首先是__mian__部分。
if __name__ == "__main__":
main()
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', type=str, default="outputs/edm_1",
help='Specify model path')
parser.add_argument('--n_samples', type=int, default=100,
help='Specify model path')
parser.add_argument('--batch_size_gen', type=int, default=100,
help='Specify model path')
parser.add_argument('--save_to_xyz', type=eval, default=False,
help='Should save samples to xyz files.')
eval_args, unparsed_args = parser.parse_known_args()
assert eval_args.model_path is not None
# 加载模型参数pickle文件
with open(join(eval_args.model_path, 'args.pickle'), 'rb') as f:
args = pickle.load(f)
# CAREFUL with this -->
if not hasattr(args, 'normalization_factor'):
args.normalization_factor = 1
if not hasattr(args, 'aggregation_method'):
args.aggregation_method = 'sum'
####################### by wufeil ####################################
# args.cuda = not args.no_cuda and torch.cuda.is_available()
# device = torch.device("cuda" if args.cuda else "cpu")
# 因为是macOS所以设置为mps
args.cuda = not args.no_cuda and torch.backends.mps.is_available()
device = torch.device("mps" if args.cuda else "cpu")
args.device = device
#####################################################################
dtype = torch.float32
utils.create_folders(args)
print(args)
# Retrieve QM9 dataloaders数据 dataloader
dataloaders, charge_scale = dataset.retrieve_dataloaders(args)
dataset_info = get_dataset_info(args.dataset, args.remove_h)
# Load model 加载模型
generative_model, nodes_dist, prop_dist = get_latent_diffusion(args, device, dataset_info, dataloaders['train'])
if prop_dist is not None:
property_norms = compute_mean_mad(dataloaders, args.conditioning, args.dataset)
prop_dist.set_normalizer(property_norms)
generative_model.to(device)
# 加载模型的权重
fn = 'generative_model_ema.npy' if args.ema_decay > 0 else 'generative_model.npy'
flow_state_dict = torch.load(join(eval_args.model_path, fn), map_location=device)
generative_model.load_state_dict(flow_state_dict)
# 生成分子,并计算 稳定率,有效率,独特率,新颖率
# Analyze stability, validity, uniqueness and novelty
stability_dict, rdkit_metrics = analyze_and_save(
args, eval_args, device, generative_model, nodes_dist,
prop_dist, dataset_info, n_samples=eval_args.n_samples,
batch_size=eval_args.batch_size_gen, save_to_xyz=eval_args.save_to_xyz)
print(stability_dict)
# 打印结果
if rdkit_metrics is not None:
rdkit_metrics = rdkit_metrics[0]
print("Validity %.4f, Uniqueness: %.4f, Novelty: %.4f" % (rdkit_metrics[0], rdkit_metrics[1], rdkit_metrics[2]))
else:
print("Install rdkit roolkit to obtain Validity, Uniqueness, Novelty")
# In GEOM-Drugs the validation partition is named 'val', not 'valid'.
if args.dataset == 'geom':
val_name = 'val'
num_passes = 1
else:
val_name = 'valid'
num_passes = 5
# 评估验证集和测试集的负对数似然,损失
# Evaluate negative log-likelihood for the validation and test partitions
val_nll = test(args, generative_model, nodes_dist, device, dtype,
dataloaders[val_name],
partition='Val')
print(f'Final val nll {val_nll}')
test_nll = test(args, generative_model, nodes_dist, device, dtype,
dataloaders['test'],
partition='Test', num_passes=num_passes)
print(f'Final test nll {test_nll}')
print(f'Overview: val nll {val_nll} test nll {test_nll}', stability_dict)
with open(join(eval_args.model_path, 'eval_log.txt'), 'w') as f:
print(f'Overview: val nll {val_nll} test nll {test_nll}',
stability_dict,
file=f)__mian__函数中,会加载model_path路径下的,模型配置参数pickle文件,也会加载其中的预训练的权重文件。调用analyze_and_save函数,生成分子并计算稳定率,有效率,独特率,新颖率。下面详细介绍analyze_and_save函数。
analyze_and_save函数首先会采样每个节点的原子数,即nodesxsample。然后,使用qm9。sampling中的sample函数,调用GeoLDM模型的sample函数,为原子填上原子坐标和原子属性。然后,保存成xyz文件格式(文件后缀名为txt)。最后,调用analyze_stability_for_molecules函数计算指标结果,返回测试指标结果。
def analyze_and_save(args, eval_args, device, generative_model,
nodes_dist, prop_dist, dataset_info, n_samples=10,
batch_size=10, save_to_xyz=False):
# 批次大小
batch_size = min(batch_size, n_samples)
assert n_samples % batch_size == 0
molecules = {'one_hot': [], 'x': [], 'node_mask': []}
start_time = time.time()
for i in range(int(n_samples/batch_size)):
# 模版采样,每个分子的大小初始化函数
nodesxsample = nodes_dist.sample(batch_size)
# 分子生成
one_hot, charges, x, node_mask = sample(
args, device, generative_model, dataset_info, prop_dist=prop_dist, nodesxsample=nodesxsample)
molecules['one_hot'].append(one_hot.detach().cpu())
molecules['x'].append(x.detach().cpu())
molecules['node_mask'].append(node_mask.detach().cpu())
current_num_samples = (i+1) * batch_size
secs_per_sample = (time.time() - start_time) / current_num_samples
print('\t %d/%d Molecules generated at %.2f secs/sample' % (
current_num_samples, n_samples, secs_per_sample))
# 保存成xyz文件
if save_to_xyz:
id_from = i * batch_size
qm9_visualizer.save_xyz_file(
join(eval_args.model_path, 'eval/analyzed_molecules/'),
one_hot, charges, x, dataset_info, id_from, name='molecule',
node_mask=node_mask)
molecules = {key: torch.cat(molecules[key], dim=0) for key in molecules}
# 评估分子
stability_dict, rdkit_metrics = analyze_stability_for_molecules(
molecules, dataset_info)
# return 指标
return stability_dict, rdkit_metrics接下来,看一下其中的关键,sample。 sample函数来自于qm9.sampling函数。qm9.sampling函数基于之前采样的,记录每个分子有几个原子的nodesxsample,生成node_mask(记录每个分子有几个原子,有几个dummy原子)。基于node_mask生成edge_mask。然后,根据是否有条件,初始化context。有了node_mask,edge_mask和context 这些分子生成的模版,就可以直接利用GeoLDM模型中smaple函数,对填充分子的x和h。
def sample(args, device, generative_model, dataset_info,
prop_dist=None, nodesxsample=torch.tensor([10]), context=None,
fix_noise=False):
max_n_nodes = dataset_info['max_n_nodes'] # this is the maximum node_size in QM9
# 分子可生成的最大节点(原子)数检查
assert int(torch.max(nodesxsample)) <= max_n_nodes
batch_size = len(nodesxsample)
node_mask = torch.zeros(batch_size, max_n_nodes)
# node_mask初始化
for i in range(batch_size):
node_mask[i, 0:nodesxsample[i]] = 1
# Compute edge_mask
# 生成对应edge_mask
edge_mask = node_mask.unsqueeze(1) * node_mask.unsqueeze(2)
diag_mask = ~torch.eye(edge_mask.size(1), dtype=torch.bool).unsqueeze(0)
edge_mask *= diag_mask
edge_mask = edge_mask.view(batch_size * max_n_nodes * max_n_nodes, 1).to(device)
node_mask = node_mask.unsqueeze(2).to(device)
# TODO FIX: This conditioning just zeros.
if args.context_node_nf > 0:
if context is None:
context = prop_dist.sample_batch(nodesxsample)
context = context.unsqueeze(1).repeat(1, max_n_nodes, 1).to(device) * node_mask
else:
context = None
if args.probabilistic_model == 'diffusion':
# GeoLDM基于模版(node_mask, edge_mask, context) 采样每个节点的坐标和节点类型,
x, h = generative_model.sample(batch_size, max_n_nodes, node_mask, edge_mask, context, fix_noise=fix_noise)
assert_correctly_masked(x, node_mask)
assert_mean_zero_with_mask(x, node_mask)
one_hot = h['categorical']
charges = h['integer']
assert_correctly_masked(one_hot.float(), node_mask)
if args.include_charges:
assert_correctly_masked(charges.float(), node_mask)
else:
raise ValueError(args.probabilistic_model)
return one_hot, charges, x, node_mask因此,接下来,介绍一下generative_model.sample,即GeoLDM中的sample,其代码如下。在代码中,sample函数直接通过super().sample()的调用方式,调用了其父类(EnVariationalDiffusion)的sample函数。注意,在EnVariationalDiffusion的sample函数返回的x和h不是最终的原子坐标和原子类型,还要经过解码器,即self.vae.decode的解码,猜得到最后的x和h。
@torch.no_grad()
def sample(self, n_samples, n_nodes, node_mask, edge_mask, context, fix_noise=False):
"""
Draw samples from the generative model.
"""
# super().sample()调用父类的sample,即EnVariationalDiffusion的sample
z_x, z_h = super().sample(n_samples, n_nodes, node_mask, edge_mask, context, fix_noise)
z_xh = torch.cat([z_x, z_h['categorical'], z_h['integer']], dim=2)
diffusion_utils.assert_correctly_masked(z_xh, node_mask)
x, h = self.vae.decode(z_xh, node_mask, edge_mask, context)
return x, h在EnVariationalDiffusion的sample函数中,先进行噪音采样,按照fix_noise参数设置,批次中的每一个分子是否使用相同的初始化噪音。然后逐步进行去噪(初始化时间步s,然后调用sample_p_zs_given_zt函数,逐步预测去噪后的z)。不断迭代,知道s=0,进行最后的去噪(sample_p_xh_given_z0),然后返回无噪音状态下的x和h。实际上这也是x和h的隐向量z_x和z_h的去噪过程。
@torch.no_grad()
def sample(self, n_samples, n_nodes, node_mask, edge_mask, context, fix_noise=False):
"""
Draw samples from the generative model.
"""
if fix_noise:
# 每一个分子的z_t相同
# Noise is broadcasted over the batch axis, useful for visualizations.
z = self.sample_combined_position_feature_noise(1, n_nodes, node_mask)
else:
# 每一个分子z_t不同
z = self.sample_combined_position_feature_noise(n_samples, n_nodes, node_mask)
diffusion_utils.assert_mean_zero_with_mask(z[:, :, :self.n_dims], node_mask)
# Iteratively sample p(z_s | z_t) for t = 1, ..., T, with s = t - 1.
# 逐步去噪 z_t -> z_t-1
for s in reversed(range(0, self.T)):
s_array = torch.full((n_samples, 1), fill_value=s, device=z.device)
t_array = s_array + 1
s_array = s_array / self.T
t_array = t_array / self.T
# 预测去噪以后的z_t,即z_s。
z = self.sample_p_zs_given_zt(s_array, t_array, z, node_mask, edge_mask, context, fix_noise=fix_noise)
# Finally sample p(x, h | z_0).
# z_0 去噪
x, h = self.sample_p_xh_given_z0(z, node_mask, edge_mask, context, fix_noise=fix_noise)
diffusion_utils.assert_mean_zero_with_mask(x, node_mask)
#质心
max_cog = torch.sum(x, dim=1, keepdim=True).abs().max().item()
if max_cog > 5e-2:
print(f'Warning cog drift with error {max_cog:.3f}. Projecting '
f'the positions down.')
# 去质心
x = diffusion_utils.remove_mean_with_mask(x, node_mask)
return x, h至此,GeoLDM的主要代码已经分析完毕了。
注:原代码中,存在小错误,可能是不同机器的原因。另外我这个训练的机器是mps,不是cu da.
版权声明:本文为博主作者:wufeil原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/wufeil7/article/details/135397730