C++ 哈希思想应用:位图,布隆过滤器,哈希切分
- 一.位图
-
- 1.位图的概念
-
- 1.问题
- 2.分析
- 3.位图的概念
- 4.演示
- 2.位图的操作
- 3.位图的实现
-
- 1.char类型的数组
- 2.int类型的数组
- 3.解决一开始的问题
-
- 位图开多大呢?
- 小小补充
- 验证
- 4.位图的应用
-
- 1.给定100亿个整数,设计算法找到只出现一次的整数?
-
- 1.位图开多大?
- 2.思路
- 3.代码
- 4.验证
- 2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 3.一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数
- 4.给定100亿个整数,0.5G内存,设计算法找到只出现一次的整数?
-
- 1.思路
- 2.验证代码实现
- 二.布隆过滤器
-
- 1.布隆过滤器的提出
- 2.布隆过滤器的概念
- 3.布隆过滤器的应用场景
-
- 1.能够容忍误判的场景
- 2.无法容忍误判的场景
- 4.代码实现
-
- 1.选择字符串哈希函数
- 2.推导出布隆过滤器长度
- 3.大致结构
- 4.具体实现
- 5.测试
-
- 1.小型测试
- 2.大型测试
- 5.标准非STL容器 : bitset
-
- 验证
- 改造
- 6.布隆过滤器的优缺点
- 三.哈希切分
-
- 1.给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
-
- 1.近似算法
- 2.精确算法
- 2.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
- 四. 如何扩展BloomFilter使得它支持删除元素的操作?
-
- 1.布隆过滤器删除的局限及其问题
- 2.代码
- 3.验证布隆过滤器删除的坑点
- 4.使用额外的数据结构来进行扩展
-
- 1.如何做呢?
- 2.代码
- 3.验证
一.位图
1.位图的概念
1.问题
给你40亿个不重复的无符号整数,没排过序.给一个无符号整数,如何快速判断一个数是否在这40亿个数中?
2.分析
1 Byte = 8 bit
1KB = 1024 Byte
1MB = 1024KB = 10241024 大约= 10的6次方Byte
1GB = 1024MB = 102410的6次方 大约= 10的9次方Byte = 10亿字节
因此4GB 约等于40亿字节
其实最快的方式就是记住1GB约等于10亿字节,这种题就好算了
我们知道40亿个整数,大概就是16GB
如果用排序+二分,
排序需要开16GB大的数组,就算用外排序(归并排序)排完序了,但是二分也需要数组啊…
如果用AVL树红黑树和哈希表
红黑树:三叉链结构+颜色 AVL树:三叉链结构+平衡因子 哈希表:负载因子每个节点的next指针等问题
内存当中更存不下
因此就需要用到位图了
3.位图的概念

4.演示
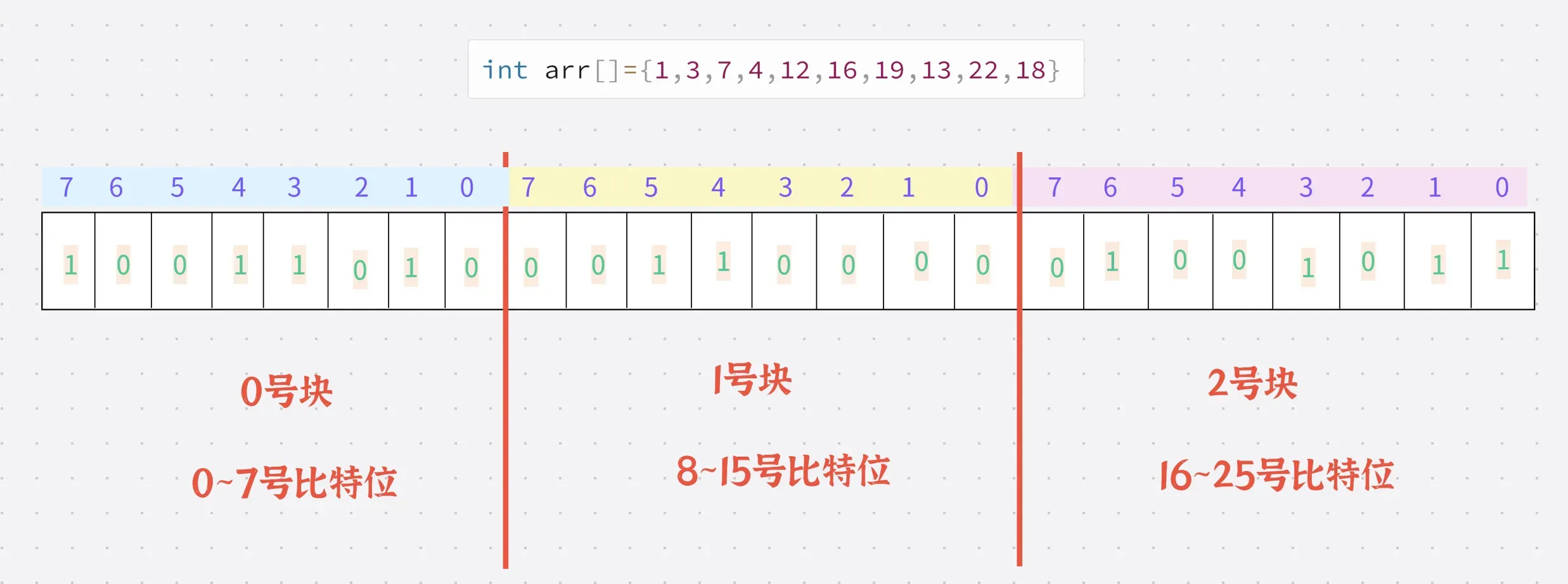
假设我们的位图使用一个char类型的数组实现的话
我们这个arr数组的最大值是22,因此只需要22个比特位即可
因此我们用一个char类型的数组,数组中有3个char即可
存放之前:
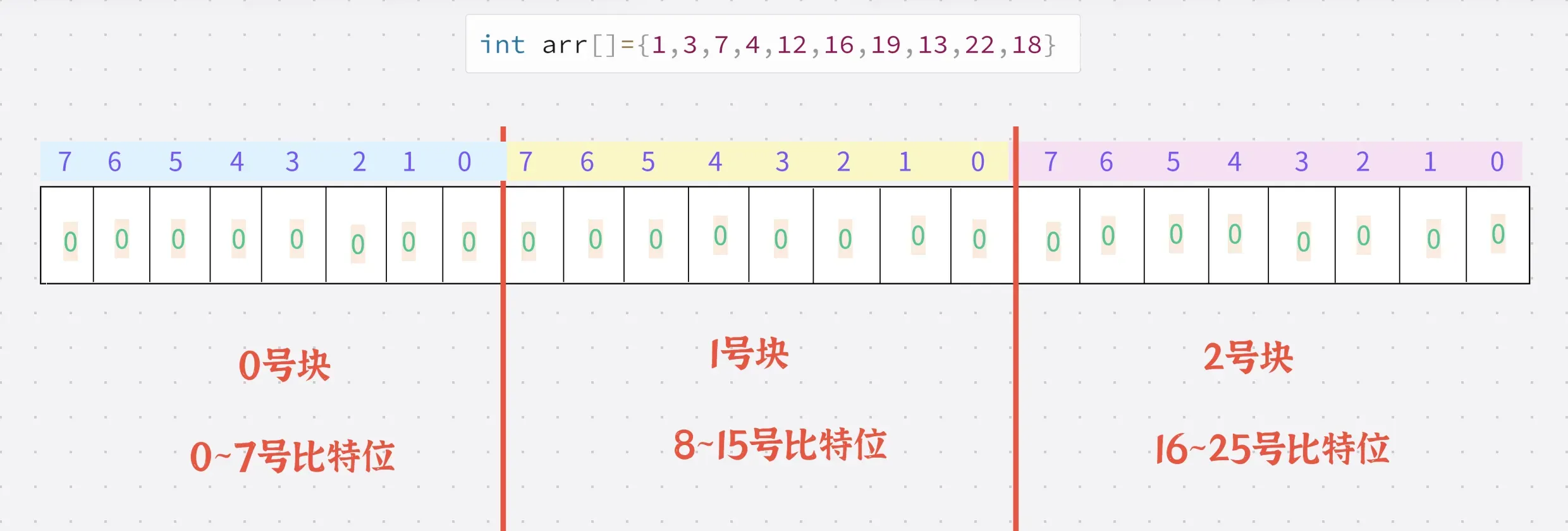
存放方式:

存放过程:
存放完毕后:
2.位图的操作
位图的三个核心操作:
set将x对应的比特位设置为1
将某一个比特位置为1,同时不影响其他比特位:
按位或一个数,这个数对应的那个比特位为1,其余比特位为0
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
reset将x对应的比特位设置为0
将某一个比特位置为0,同时不影响其他比特位:
按位与一个数,这个数对应的那个比特位为0,其余比特位为1
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
test检查x在不在
跟一个数进行按位与
按位与一个数,这个数对应的那个比特位为1,其余比特位为0
如果结果
为0:说明不存在,
不为0说明存在
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1<<j);
}
3.位图的实现
1.char类型的数组
实现了set reset test之后
位图其实就已经实现完毕了
namespace wzs
{
// N是需要多少比特位
template<size_t N>
class bitset
{
public:
bitset()
{
_bits.resize(N/8+1, 0);
}
void set(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
_bits[i] &= ~(1 << j);
}
bool test(size_t x)
{
size_t i = x / 8;
size_t j = x % 8;
return _bits[i] & (1<<j);
}
private:
vector<char> _bits;
};
}
2.int类型的数组
也可以采用int类型的数组来搞
此时就不是除8模8了
而是除32模32了
因为一个int类型有32个比特位
namespace wzs
{
// N是需要多少比特位
template<size_t N>
class bitset
{
public:
bitset()
{
//_bits.resize(N/32+1, 0);
_bits.resize((N>>5) + 1, 0);
}
void set(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] |= (1 << j);
}
void reset(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
_bits[i] &= ~(1 << j);
}
bool test(size_t x)
{
size_t i = x / 32;
size_t j = x % 32;
return _bits[i] & (1<<j);
}
private:
vector<int> _bits;
};
}
3.解决一开始的问题
因此对于一开始的那个问题:

位图开多大呢?
注意: 使用位图,且没有指定范围时,我们要按照该数据的范围大小来开位图
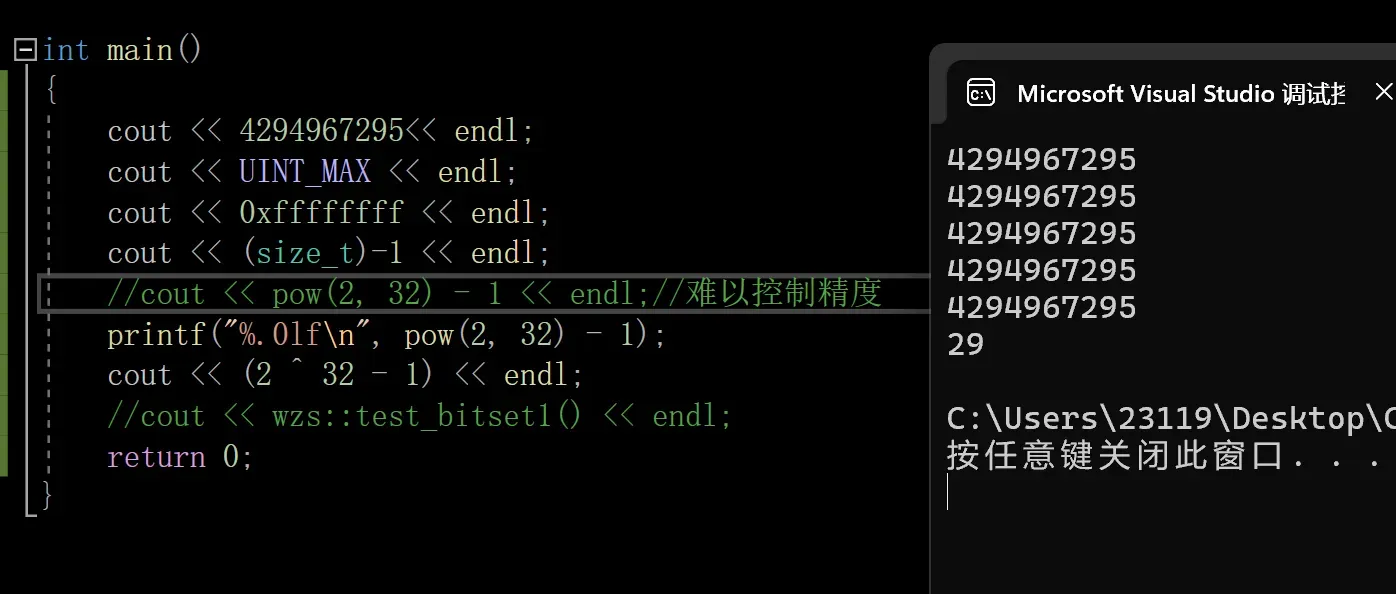
无符号整数的范围是0~4,294,967,295
因此我们需要开0~4,294,967,295大的范围
0~2的32次方-1的范围
一共有2的32次方个整数,
2的10次方是1024
2的30次方就是1024*1024*1024=1024*1024K=1024M=1G
因此2的32次方就是4G个整数
而我们使用一个比特位表示一个整数的,一个字节有8个比特位
因此我们只需要4G/8=0.5G个字节即可
因此我们的位图大小就是0.5G,正常情况下内存当中完全能存的下
无需担心
小小补充
而这个数字也不好记,其实它还有下面3种写法
- (size_t)-1 将-1强转为无符号整形
- UINT_MAX (unsigned_intMAX)
- 0xffffffff(16进制:8个f)
- pow(2,32)-1
一定注意:^在C++/C当中是异或,不是幂
因此(2^32)-1不等于那个数字
pow的返回值类型是double类型
验证
下面我们来验证一下位图能否完成这一任务
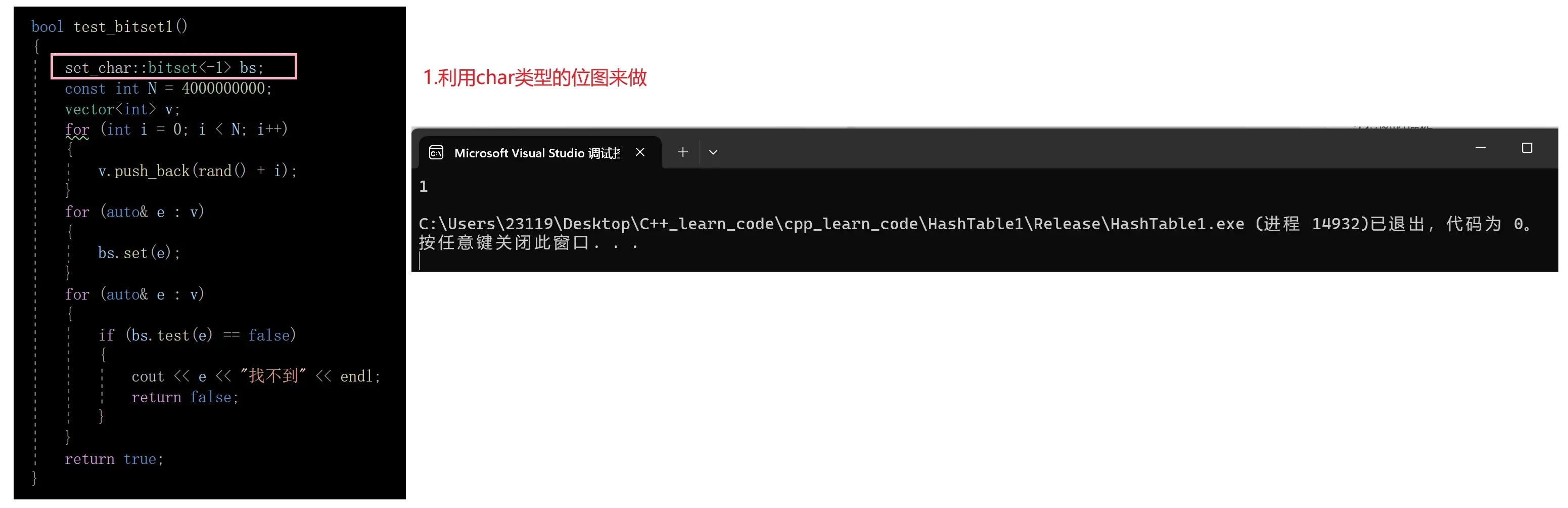
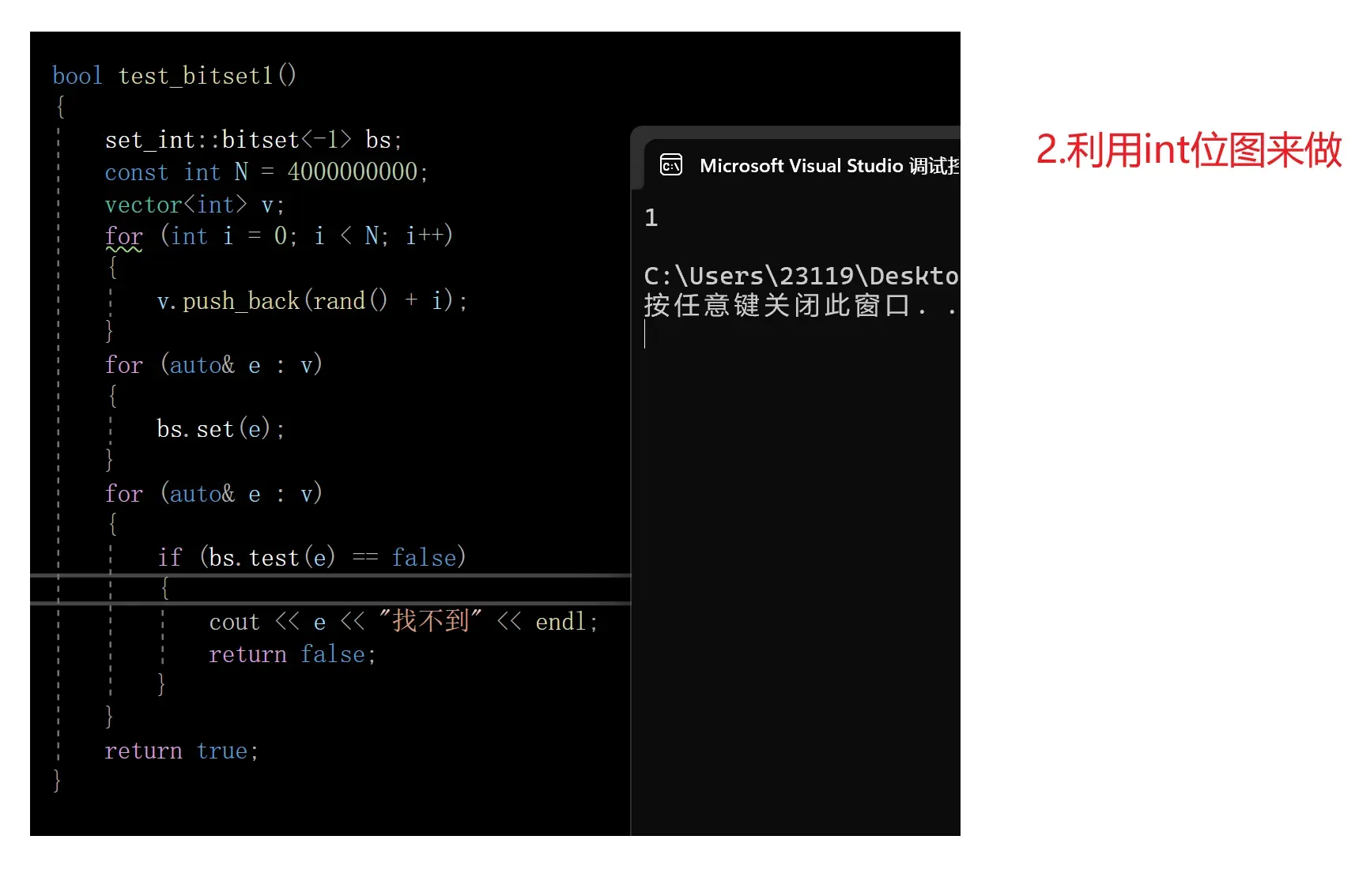
4.位图的应用
1.给定100亿个整数,设计算法找到只出现一次的整数?
1.位图开多大?
我们先算一下100亿个整数要占多少G的内存?
一个比特位映射一个整数,一个字节有8个比特位
100亿个整数=100亿个比特位=100亿/8个字节=12.5亿字节=1.25G
我们真的要用1.25G的空间吗?
并不是!!!
而是刚才我们算的0.5G就足以
因为我们只存范围
如果要求必须使用位图来做,就算只有2个整数,不给我们范围,还是要用0.5G大小的位图
2.思路
找到只出现一次的整数,因为一个比特位只有0和1这两种状态,因此无法表示出现了1次以上的数字的状态
那么怎么办?
如果用2个比特位来表示一个整数的状态呢?
00就是出现0次
01就是出现1次
10就是出现2次
出现2次以后这个数我们就不再统计次数了
因此我们可以:
1.修改上面的位图,用2个比特位来表示一个整数
此时位图的大小就要乘以2,成为1G
2.用2个位图来做,每个位图依然是0.5G
只不过set,test函数要修改一下即可
下面我们就按照第2种来做吧,这个清晰易懂
3.代码
因为我们没有统计2次以上的次数,因此我们不允许进行reset操作
//利用组合来进行封装
template<size_t N>
class two_bitset
{
public:
void set(int x)
{
//00 -> 01
if (_bits1.test(x) == false && _bits2.test(x) == false)
{
_bits2.set(x);
}
//01 -> 10
else if (_bits1.test(x) == false && _bits2.test(x) == true)
{
_bits1.set(x);
_bits2.reset(x);
}
//10,不记录了
}
//返回x出现了多少次
//返回2表示2次及以上
int test(int x)
{
if (_bits1.test(x) == false && _bits2.test(x) == false)
{
return 0;
}
else if (_bits1.test(x) == false && _bits2.test(x) == true)
{
return 1;
}
return 2;
}
private:
bitset<N> _bits1;
bitset<N> _bits2;
};
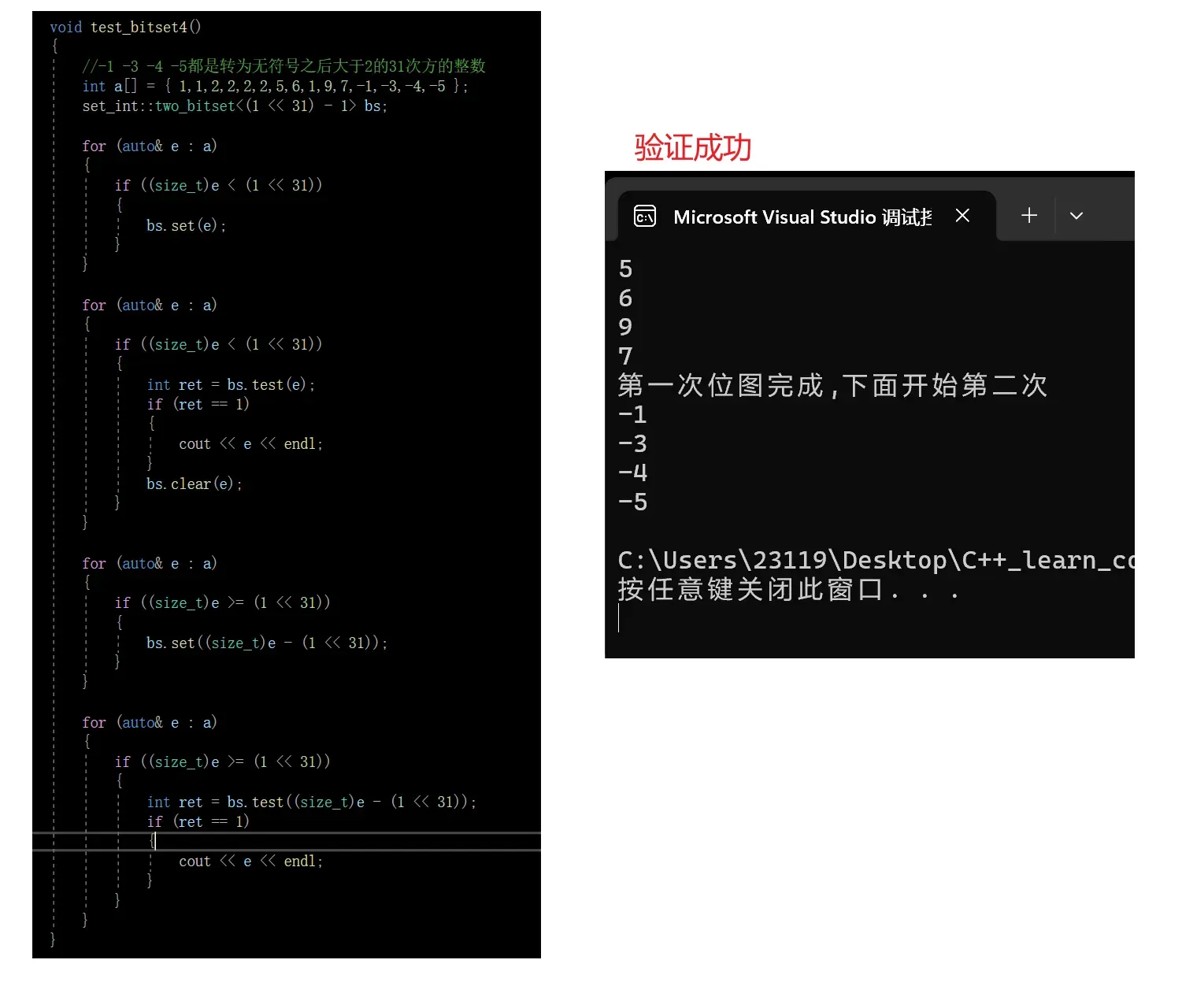
4.验证
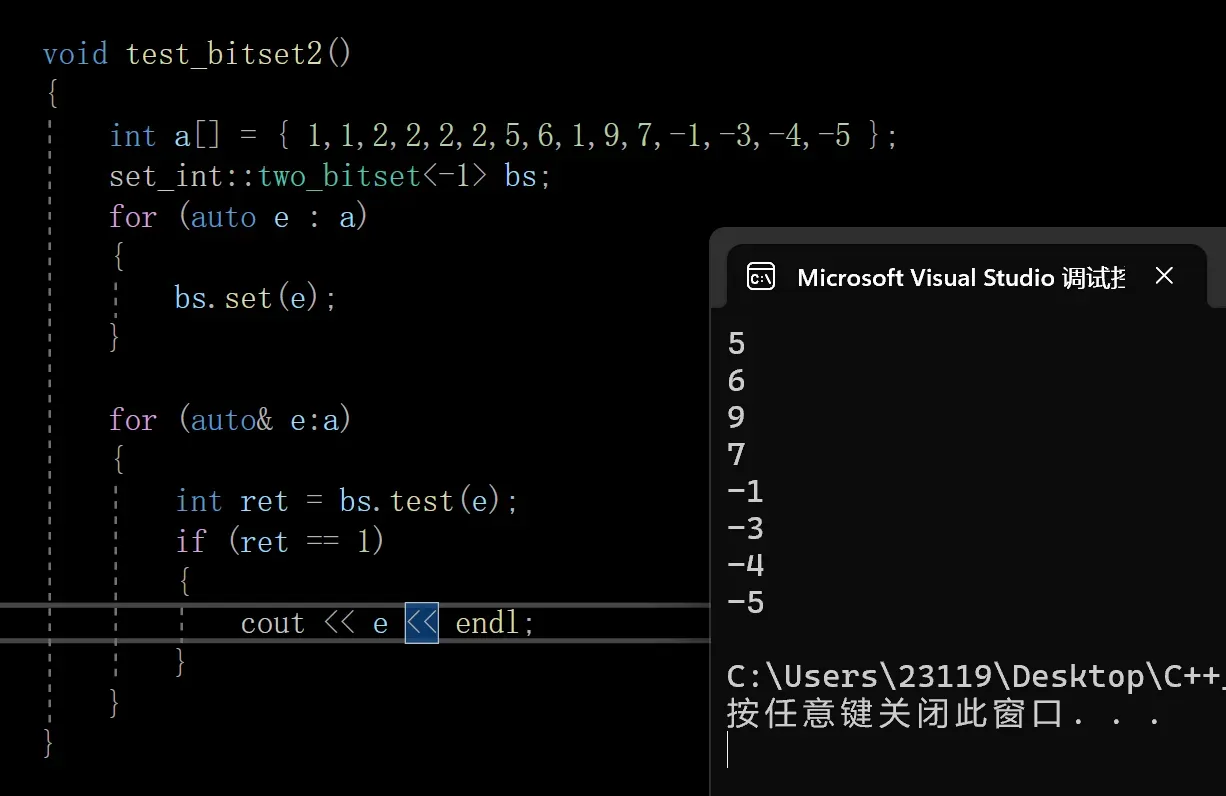
成功
2.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
经过刚才的那道题
我们已经能够很轻松的解决了
管你100亿还是200亿,统统开0.5G的位图
因为有2个文件,因此开2个位图,正好1个G
每个文件当中的每个整数还是按照一个比特位来映射
只不过取交集的时候要求两个位图当中的test都为true才是交集
因此我们直接用一开始的位图即可,不用再去写位图了

集合是具有互异性的,而我们的位图是天然去重的,因此无需担心交集当中出现重复值
下面我们来玩一下
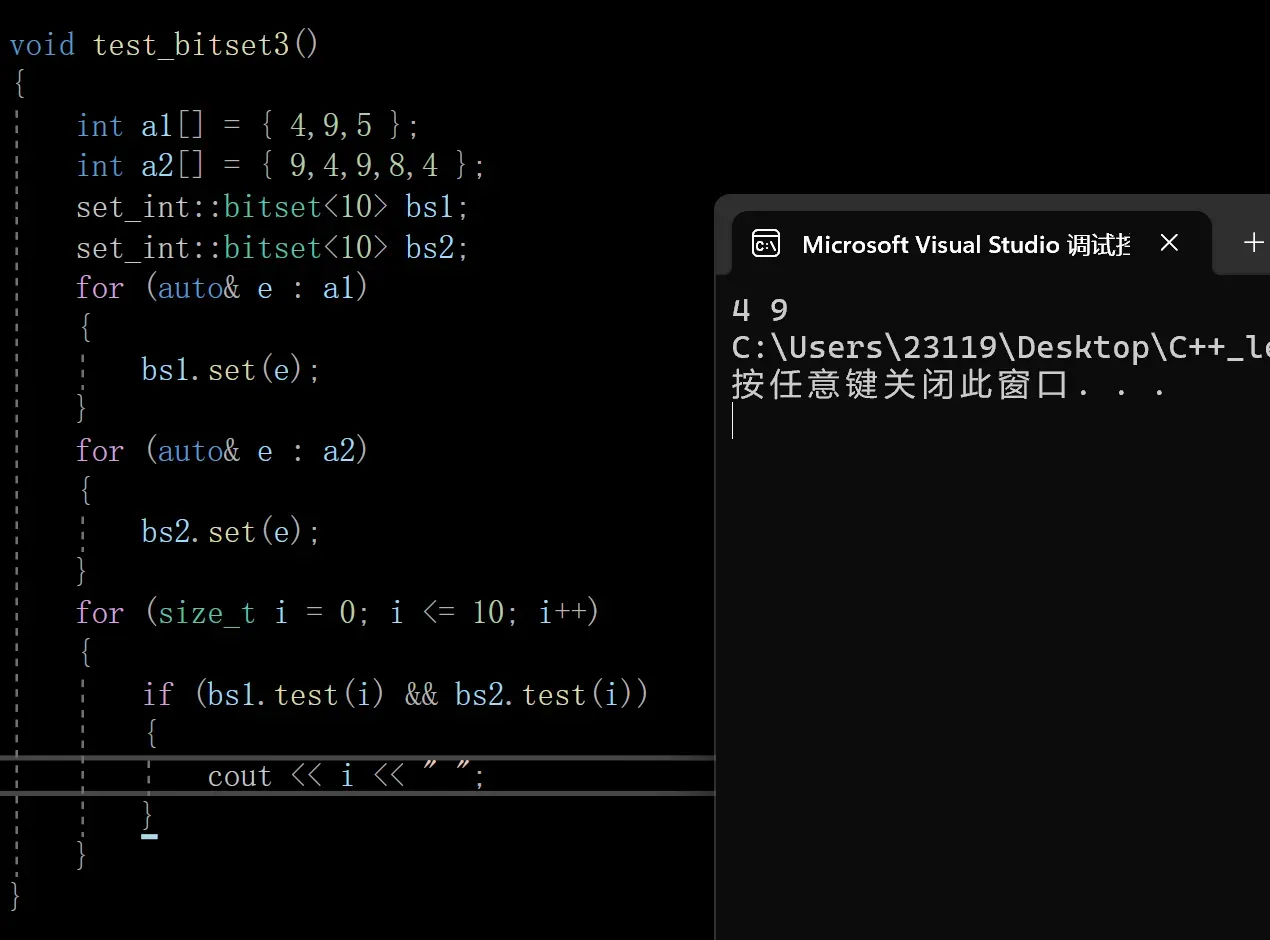
3.一个文件有100亿个整数,1G内存,设计算法找到出现次数不超过2次的所有整数
跟第一个问题的思路一样,只不过找的条件不一样
此时就需要记录超过2次的次数了
可以用11表示出现3次即以上的次数
然后稍稍改一下即可,这里就不赘述了
4.给定100亿个整数,0.5G内存,设计算法找到只出现一次的整数?
1.思路
这不还是第1题吗?
不是的,因为这里只有0.5G,而我们的一个位图是0.5G,需要使用2个位图才可以
因此按照第1题的思路来做的话,内存当中是存不下的
怎么办?
首先我们要知道:我们一定还是需要2个位图的,一个位图搞不定
而一共就只有0.5G内存,分配给2个位图的话
一个位图才只有0.25G啊,存不下0~2的32次方-1这么大的范围,只能存一半
此时我们发现,只能存一半,那么我一次存一半,一共存2次不就行了吗?
第一次位图当中只查找0到2的31次方-1的范围当中只出现1次的整数
第二次位图当中只查找2的31次方到2的32次方-1的范围当中只出现1次的整数不就行了吗?
只不过第二次存的时候,只存大于等于2的31次方的值,而且所有的值要先减去2的31次方再存入,然后取的时候取出来再加上2的31次方
因此我们就可以这样玩
2.验证代码实现
因为第一次存完之后,存第二次之前要先把位图当中的原有数据清空
因此我们要提供一个clear操作,将位图当中的x对应的比特位置为0
void clear(int x)
{
_bits1.reset(x);
_bits2.reset(x);
}
void test_bitset4()
{
//-1 -3 -4 -5都是转为无符号之后大于2的31次方的整数
int a[] = { 1,1,2,2,2,2,5,6,1,9,7,-1,-3,-4,-5 };
set_int::two_bitset<(1 << 31) - 1> bs;
for (auto& e : a)
{
if ((size_t)e < (1 << 31))
{
bs.set(e);
}
}
for (auto& e : a)
{
if ((size_t)e < (1 << 31))
{
int ret = bs.test(e);
if (ret == 1)
{
cout << e << endl;
}
bs.clear(e);
}
}
cout<<"第一次位图完成,下面开始第二次"<<endl;
for (auto& e : a)
{
if ((size_t)e >= (1 << 31))
{
bs.set((size_t)e - (1 << 31));
}
}
for (auto& e : a)
{
if ((size_t)e >= (1 << 31))
{
int ret = bs.test((size_t)e - (1 << 31));
if (ret == 1)
{
cout << e << endl;
}
}
}
}
二.布隆过滤器
这是知乎的一位大佬写的关于布隆过滤器的文章的开头的内容
我也觉得这句话写的特别好,分享给大家

我觉得不仅仅布隆过滤器是这句话的代表,我们后面要讲的哈希切分更是这句话典型的代表
完美的体现了对于数据结构选择的灵活性
1.布隆过滤器的提出
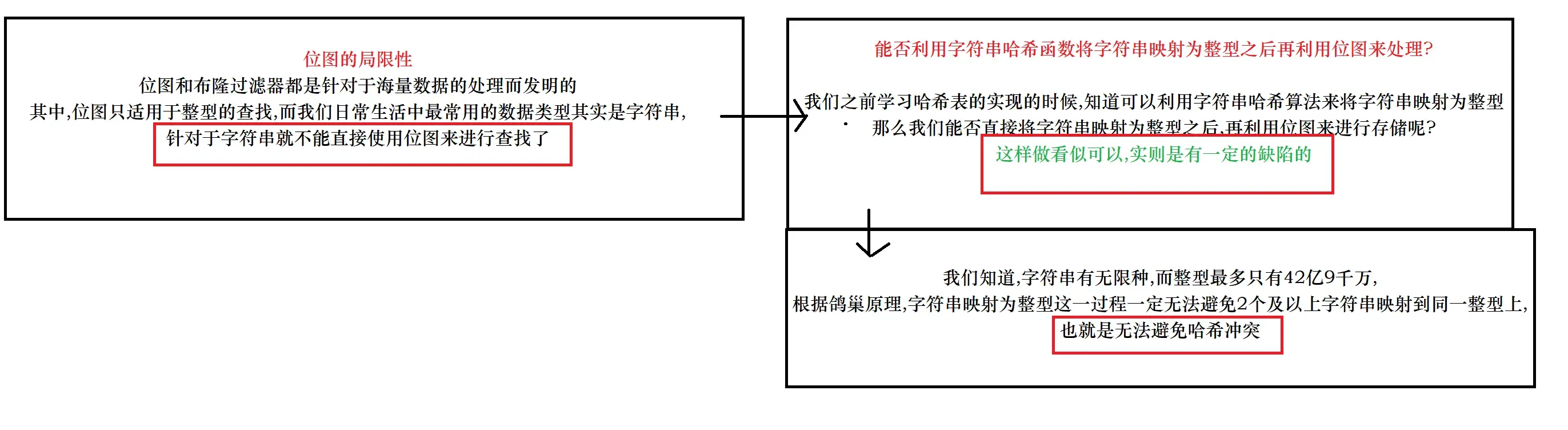
下面我们来分析一下,这种方法的准确性到底如何?
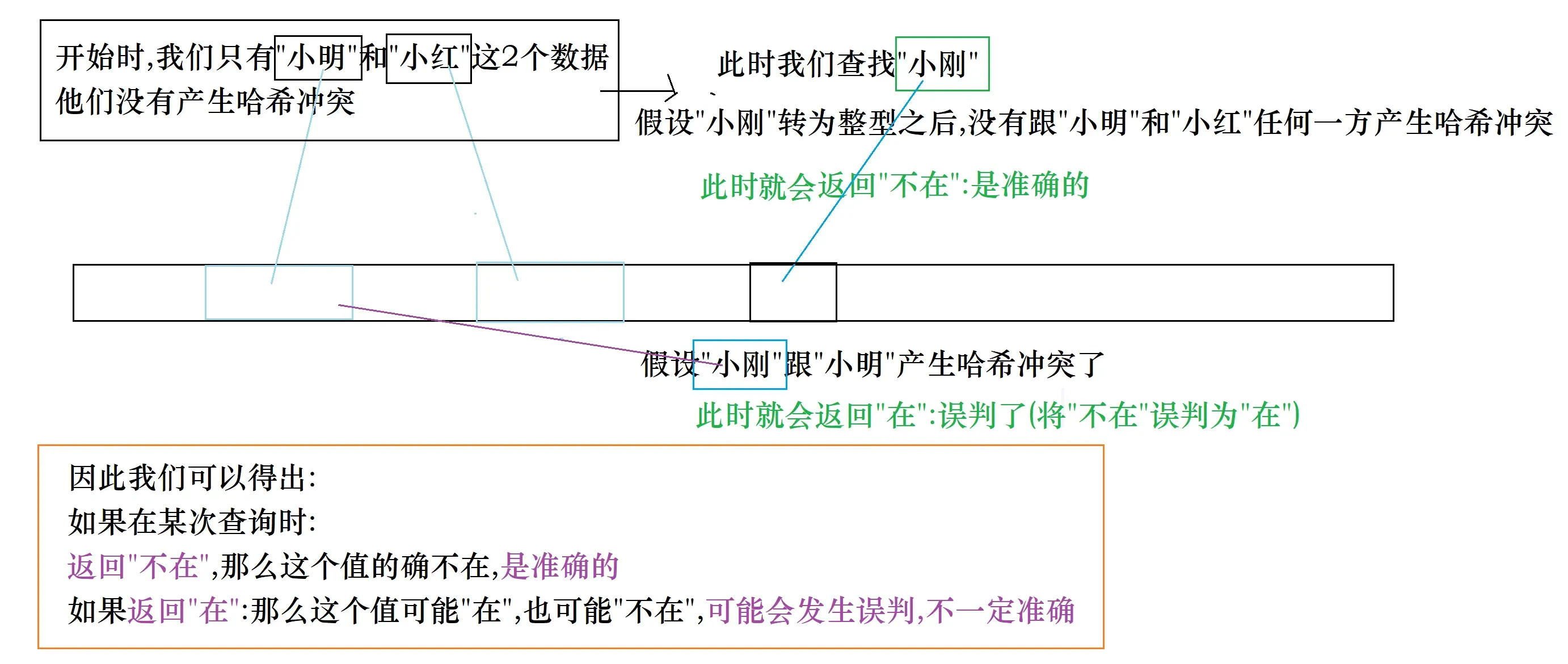
也就是说这个方法是走不通的,因为存在误判的可能
2.布隆过滤器的概念
但是布隆这个大佬是这么考虑的:
这个方法的确是行不通,但是这个方法对于不在的判定结果是准确的
那么我能否利用这个方法来进行一层过滤,把不在的完全过滤出去呢
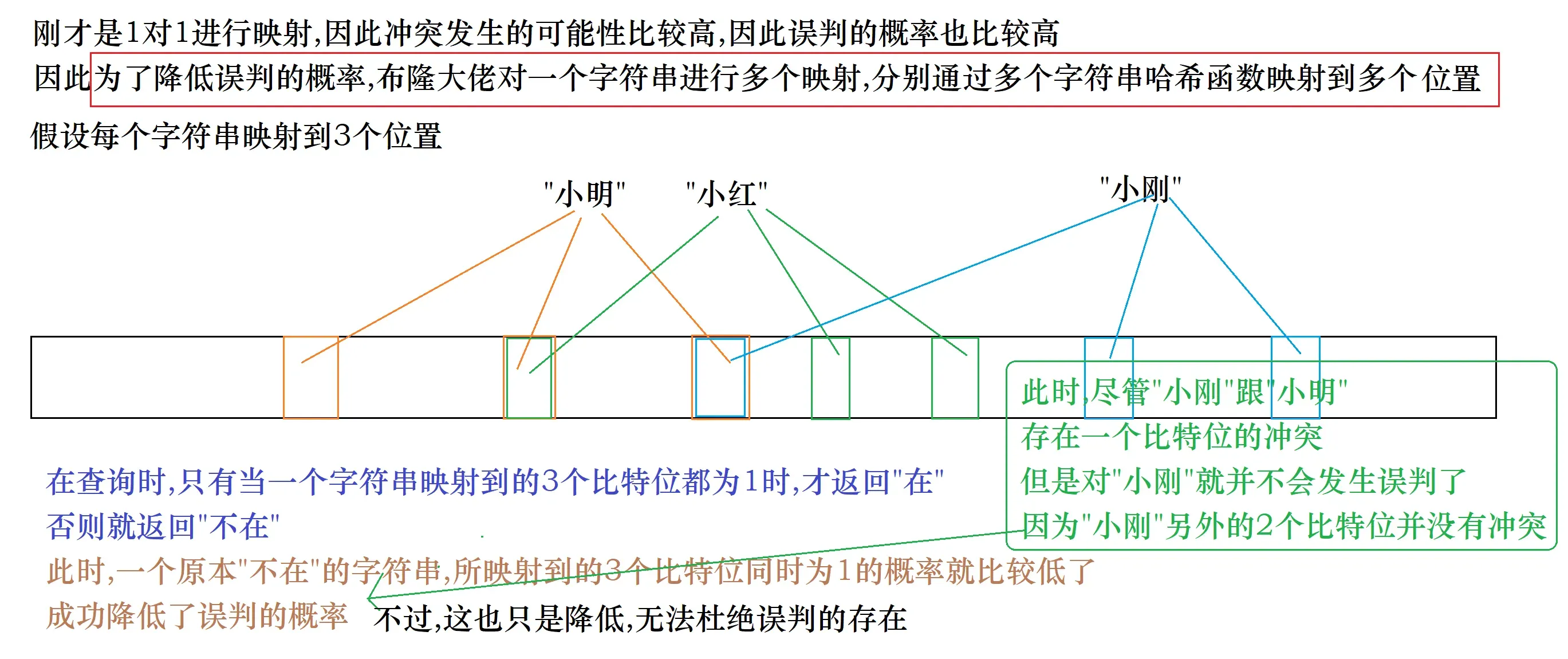
而这就是我们今天要介绍的布隆过滤器

3.布隆过滤器的应用场景
1.能够容忍误判的场景
对于一些能够容忍误判的场景(也就是能够接受把不在误判为在),这个方法完全可以
比如说:


2.无法容忍误判的场景
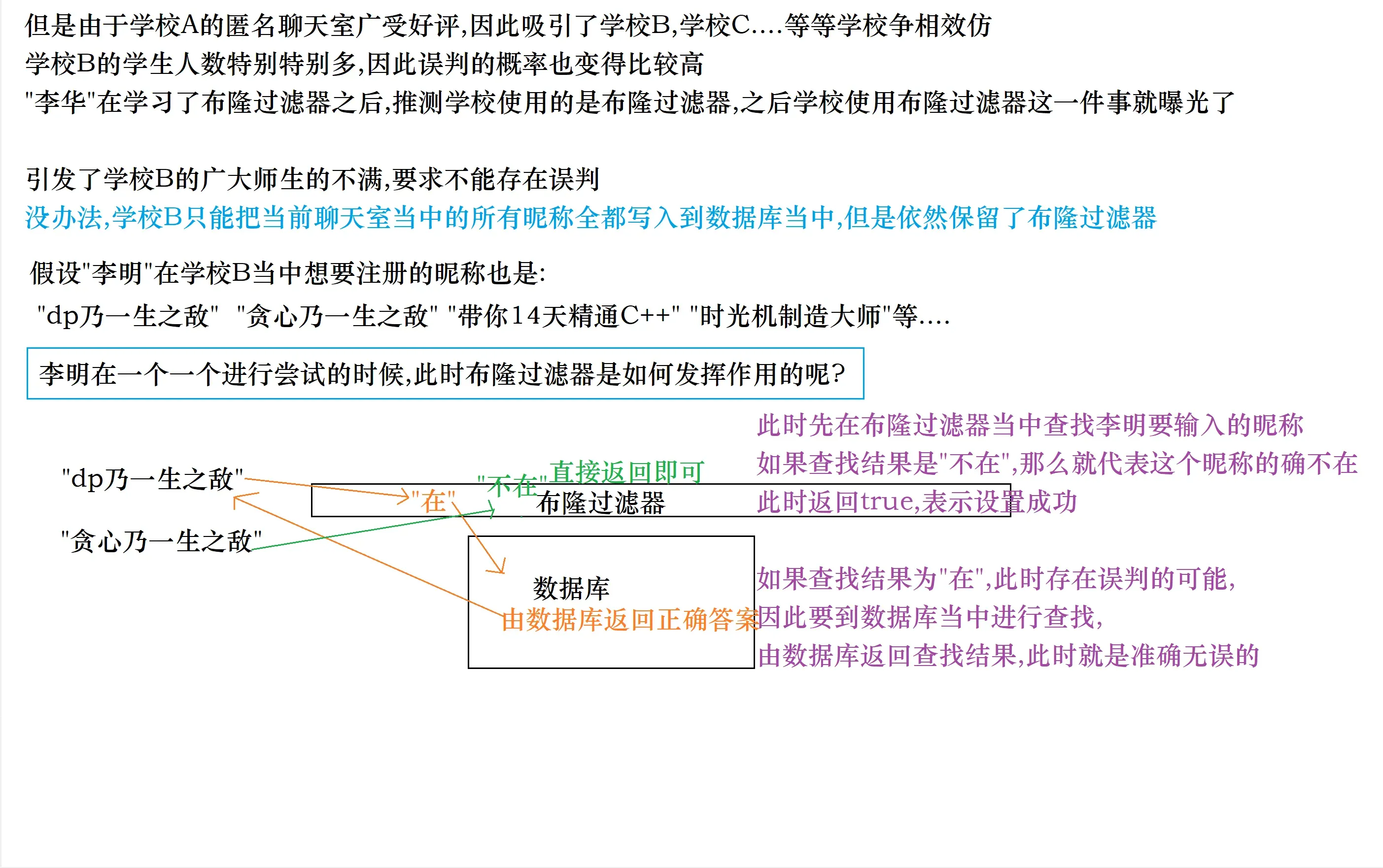
对于一些无法容忍误判的场景,这个方法可以提高我查询的效率
也就是如果判定为不在,那么这个字符串一定不在,直接返回即可
如果判断为在,那么我再去相应的数据库当中进行查找,看看这个字符串到底是不是真的存在
因此布隆过滤器才叫做”过滤器”嘛
4.代码实现
下面我们来一起实现一下布隆过滤器吧
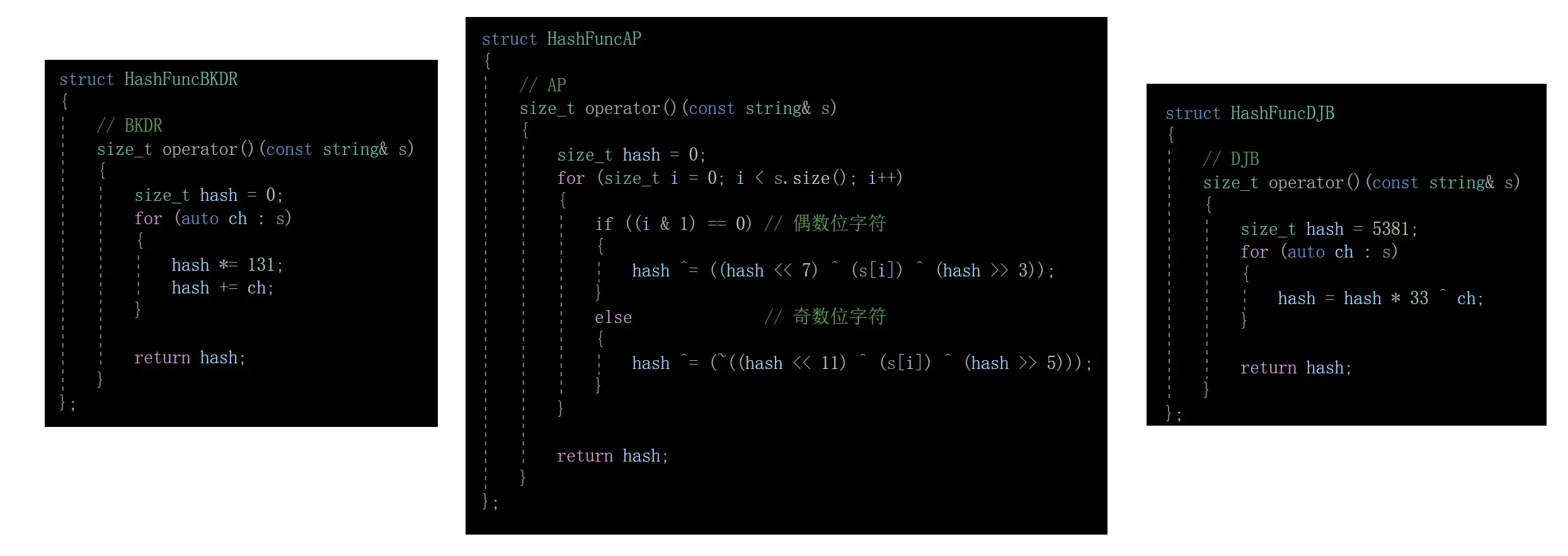
1.选择字符串哈希函数
很多大佬设计的很多字符串哈希算法:字符串哈希函数
我们就选上3个哈希函数吧
2.推导出布隆过滤器长度
这是知乎上的一位大佬写的关于布隆过滤器的一篇文章,感兴趣的话大家可以看一看
详解布隆过滤器的原理,使用场景和注意事项

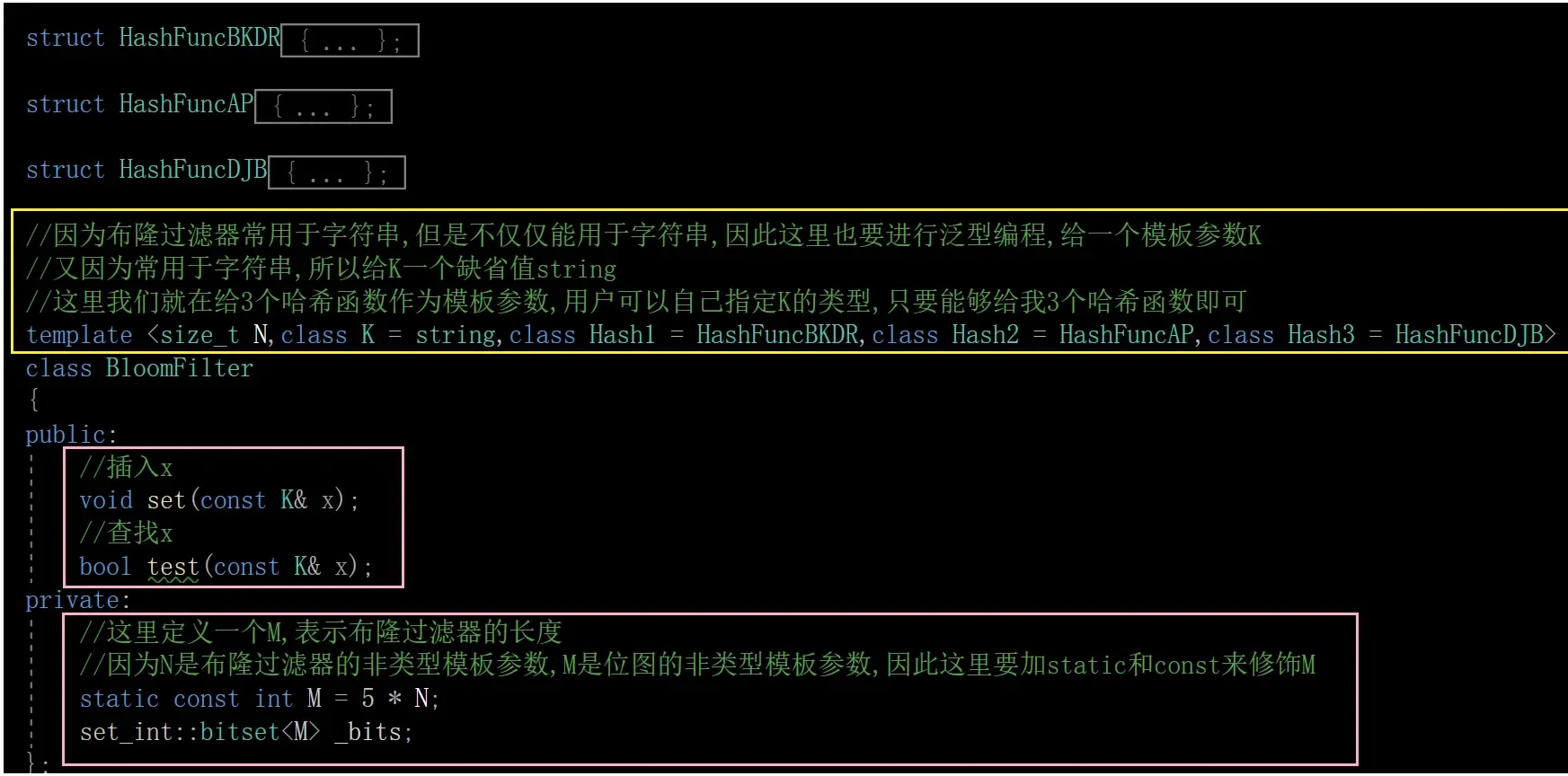
3.大致结构
下面请大家思考一个问题:布隆过滤器支持删除吗?
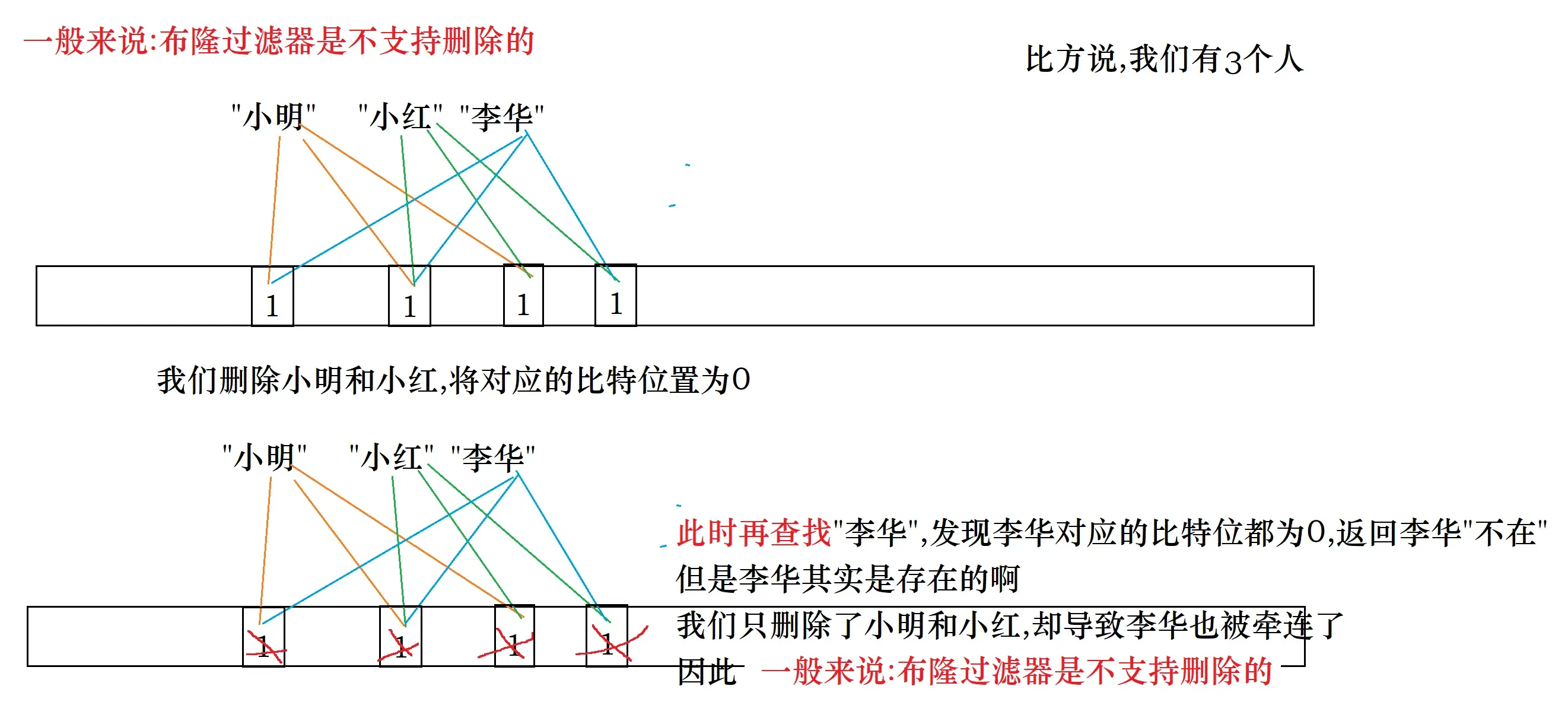
答案是:一般是不支持的
当然也可以支持,此时就不能用一个比特位来进行映射了,而要用一个char/int来进行映射,采用类似于引用计数的方式进行映射
不过那样做的缺陷是,本来一个比特位就能解决问题,现在要用8个甚至32个比特位才能解决问题,对于空间的消耗一下子扩大为8被甚至32倍
4.具体实现
1.set
//插入x
void set(const K& x)
{
//Hash1()是匿名对象,是仿函数对象,调用operator(),传入x作为参数
size_t hashi1 = Hash1()(x) % M, hashi2 = Hash2()(x) % M, hashi3 = Hash3()(x) % M;
//将3个比特位全部置为1即可
_bits.set(hashi1);
_bits.set(hashi2);
_bits.set(hashi3);
}
2.test
//查找x
bool test(const K& x)
{
//只要有一个比特位为0,就是false
//3个比特位都为1,返回true(但是存在误判)
size_t hashi1 = Hash1()(x) % M, hashi2 = Hash2()(x) % M, hashi3 = Hash3()(x) % M;
if (_bits.test(hashi1) == false) return false;
if (_bits.test(hashi2) == false) return false;
if (_bits.test(hashi3) == false) return false;
return true;
}
5.测试
1.小型测试
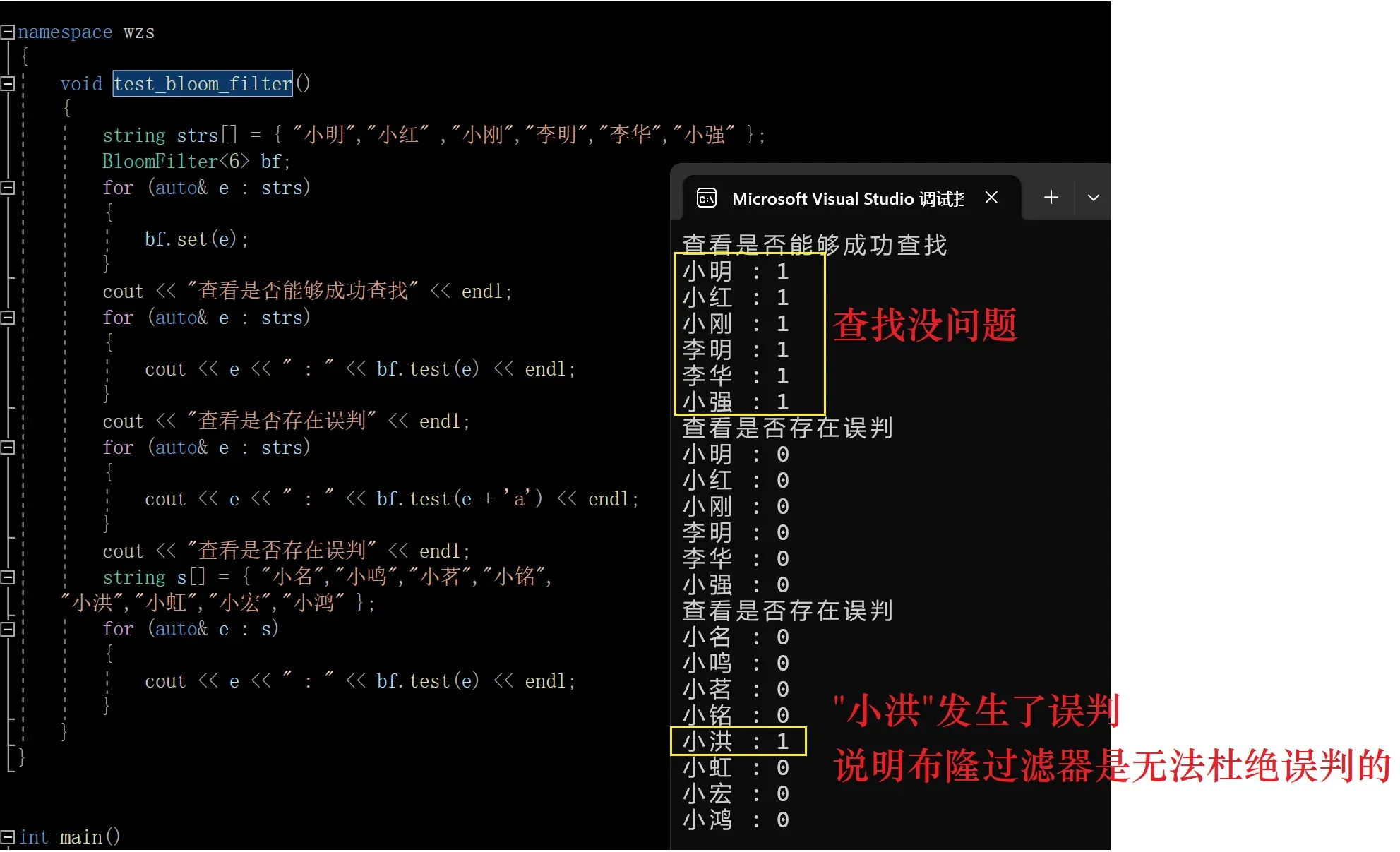
void test_bloom_filter()
{
string strs[] = { "小明","小红" ,"小刚","李明","李华","小强" };
BloomFilter<6> bf;
for (auto& e : strs)
{
bf.set(e);
}
cout << "查看是否能够成功查找" << endl;
for (auto& e : strs)
{
cout << e << " : " << bf.test(e) << endl;
}
cout << "查看是否存在误判" << endl;
for (auto& e : strs)
{
cout << e << " : " << bf.test(e + 'a') << endl;
}
cout << "查看是否存在误判" << endl;
string s[] = { "小名","小鸣","小茗","小铭",
"小洪","小虹","小宏","小鸿" };
for (auto& e : s)
{
cout << e << " : " << bf.test(e) << endl;
}
}
2.大型测试
void test_bloom_filter2()
{
srand(time(0));
const size_t N = 1000000;//N是100万
BloomFilter<N> bf;
std::vector<std::string> v1;
std::string url = "https://zhuanlan.zhihu.com/p/43263751/";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + std::to_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集(前缀一样),但是后缀不一样
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string urlstr = url;
urlstr += std::to_string(9999999 + i);
v2.push_back(urlstr);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str)) // 误判
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集 前缀后缀都不一样
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "布隆过滤器";
url += std::to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
}
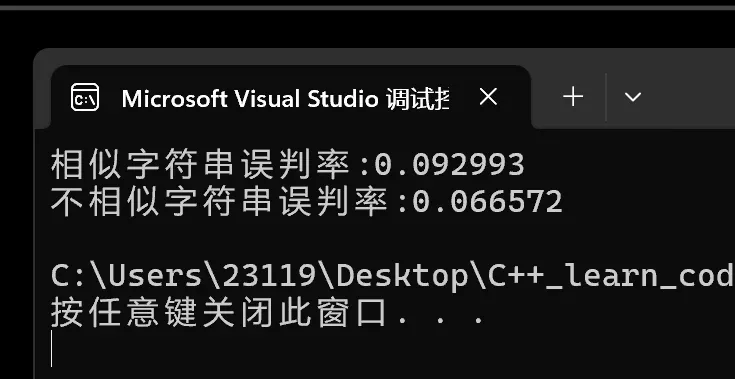
误判率大概是百分之9,百分之6左右
我们将M=5N调大一些,也就是把位图开大一些来看看
M=7N:
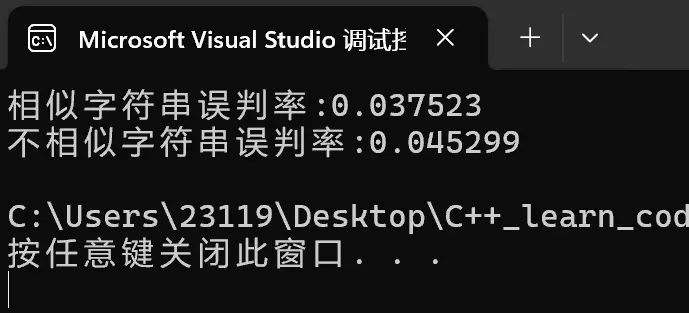
误判率大概是百分之3,百分之4左右
已经很小了
M=9*N
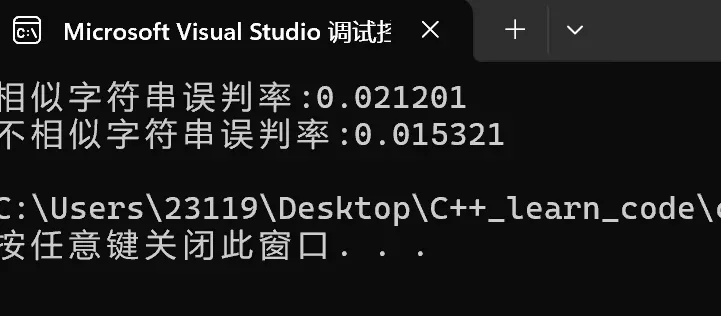
误判率大概是百分之2,百分之1左右
知乎那位大佬针对于这一点也给出了折线图分析
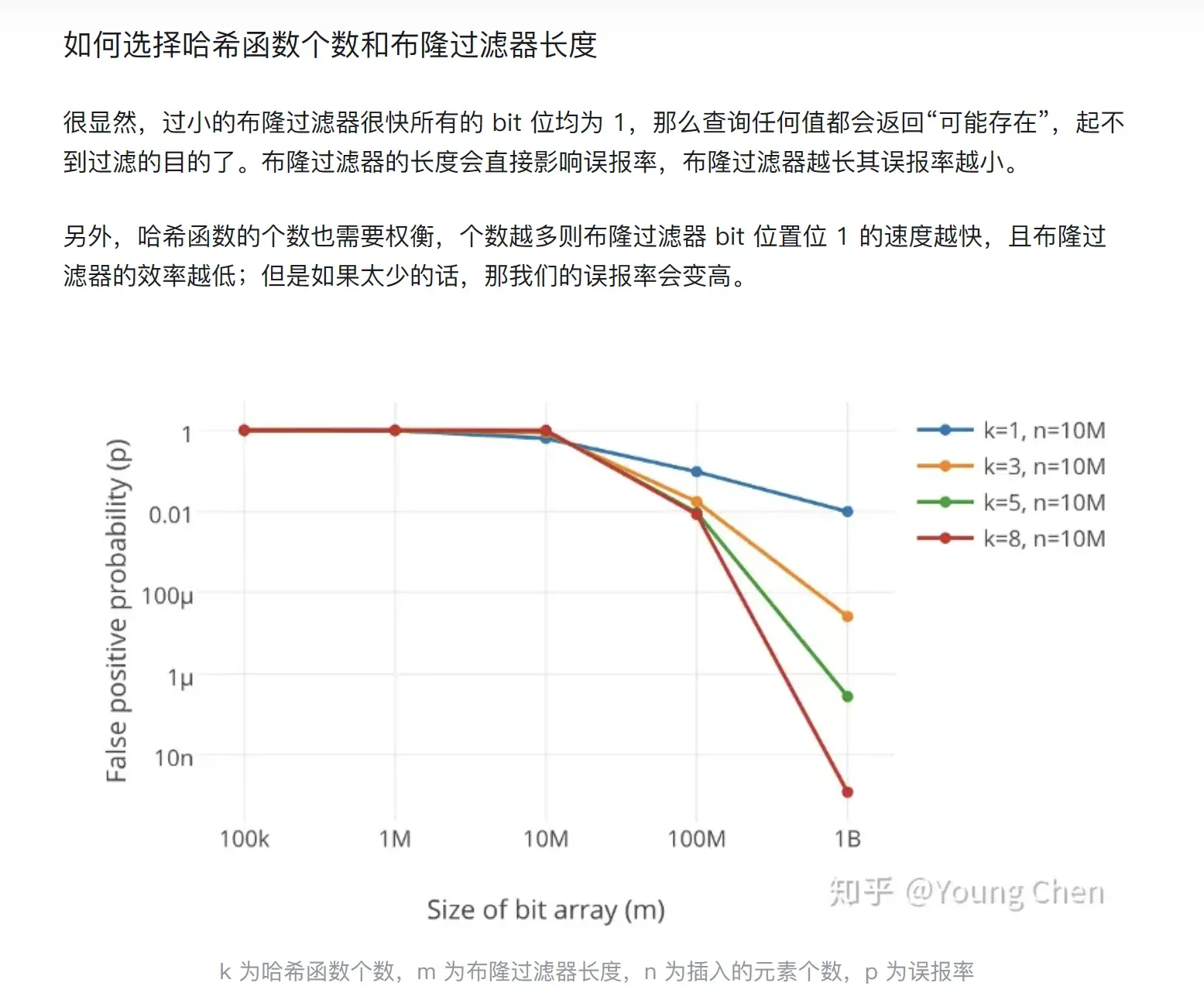
感兴趣的话大家可以看一下那篇文章
5.标准非STL容器 : bitset
下面我们来说一下一个非常容易被忽视的点:
标准非STL容器 : bitset
这是一位大佬的博客,里面详细
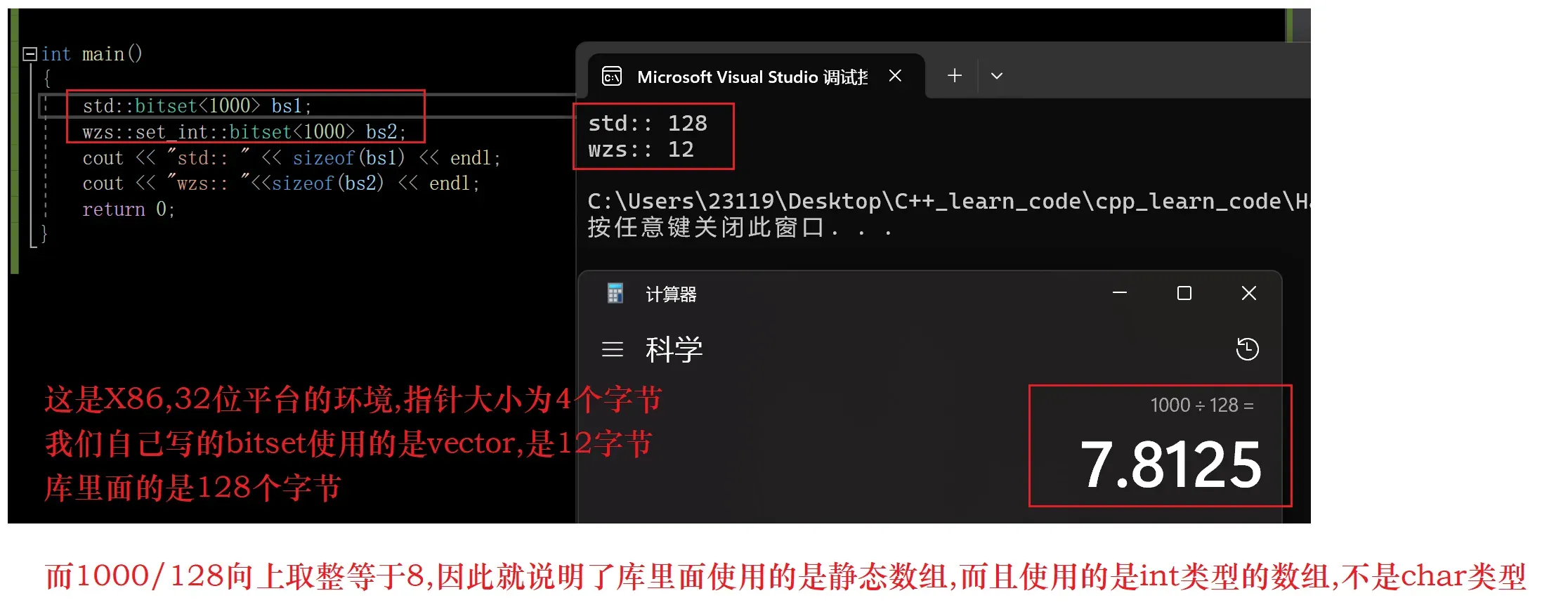
bitset其实并不满足STL的所有要求
bitset内部是使用静态数组(类似于int arr[N])分配内存的,
也就是说bitset的数组并不是开辟在堆区的,而是开辟在栈区的
所以,使用bitset时要小心栈溢出
验证
下面我们来验证一下:
我们知道,如果bitset的数组是动态数组,也就是开辟在堆区的数组
那么bitset对象当中应该就只有一个指针也就是4/8个字节
如果bitset内部使用的是vector,那么bitset对象的大小就等于vector对象的大小
而我们知道vector的底层就是3个指针
start,finish,endOfStorage
因此大小就是12/24个字节
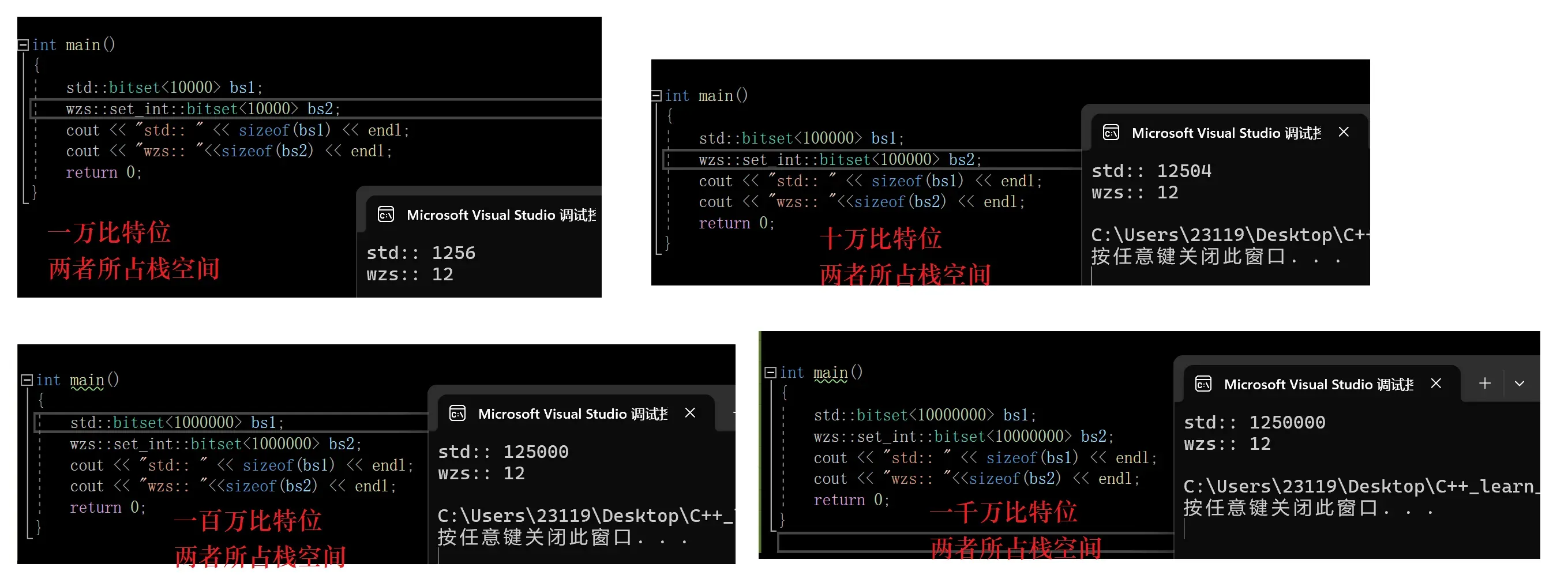
可以看出,随着位图越来越大,两者栈空间的差距也越来越大
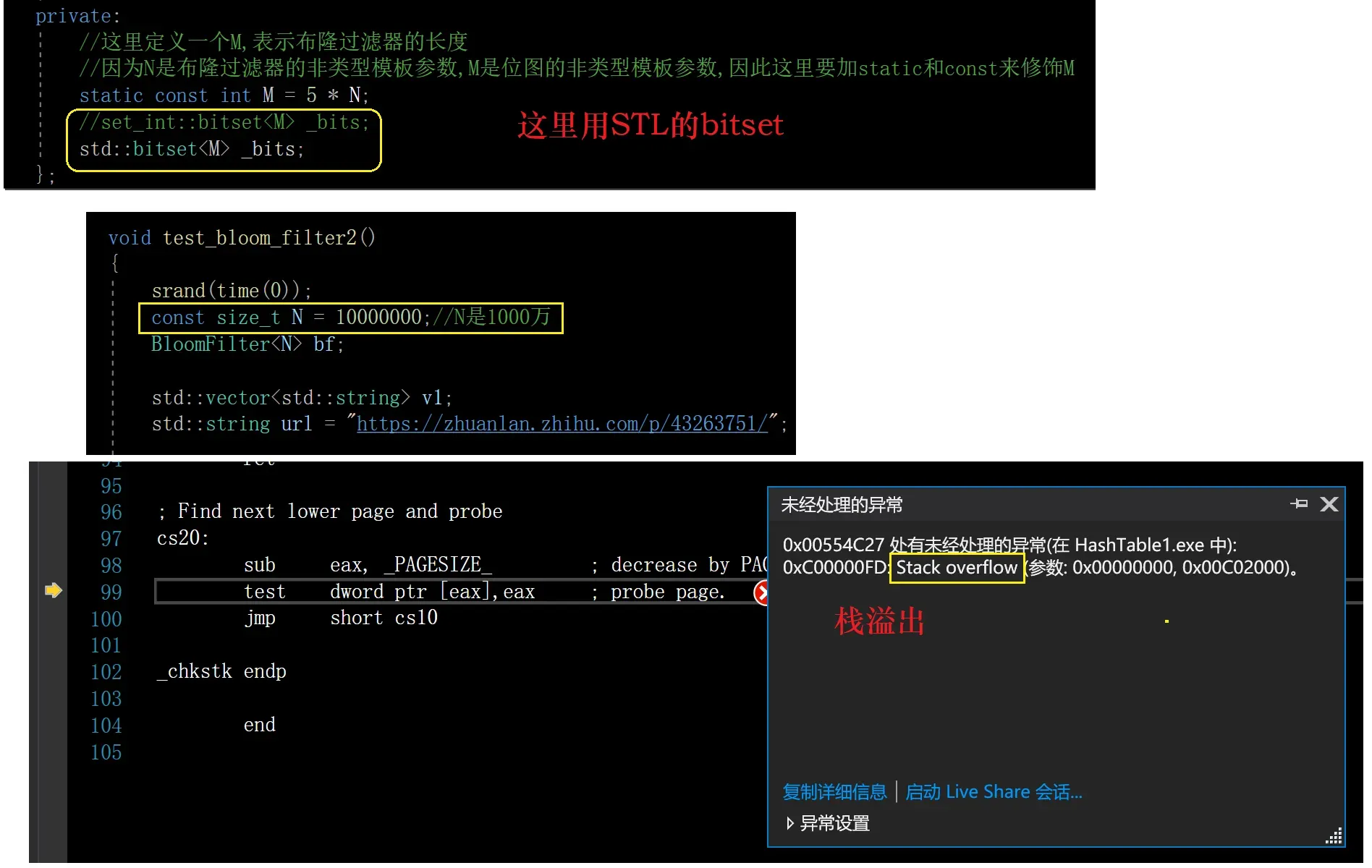
那么怎么办呢?
难不成库里面的bitset就用不成了吗?
当然不是,new一个bitset对象,解引用调用其方法即可
下面我们改造一下布隆过滤器
封装std的bitset
改造
template <size_t N,class K = string,class Hash1 = HashFuncBKDR,class Hash2 = HashFuncAP,class Hash3 = HashFuncDJB>
class BloomFilter
{
public:
//插入x
void set(const K& x)
{
//Hash1()是匿名对象,是仿函数对象,调用operator(),传入x作为参数
size_t hashi1 = Hash1()(x) % M, hashi2 = Hash2()(x) % M, hashi3 = Hash3()(x) % M;
//将3个比特位全部置为1即可
_pbits->set(hashi1);
_pbits->set(hashi2);
_pbits->set(hashi3);
}
//查找x
bool test(const K& x)
{
//只要有一个比特位为0,就是false
//3个比特位都为1,返回true(但是存在误判)
size_t hashi1 = Hash1()(x) % M;
if (_pbits->test(hashi1) == false) return false;
size_t hashi2 = Hash2()(x) % M;
if (_pbits->test(hashi2) == false) return false;
size_t hashi3 = Hash3()(x) % M;
if (_pbits->test(hashi3) == false) return false;
return true;
}
private:
//这里定义一个M,表示布隆过滤器的长度
//因为N是布隆过滤器的非类型模板参数,M是位图的非类型模板参数,因此这里要加static和const来修饰M
static const int M = 5 * N;
//set_int::bitset<M> _bits;
//std::bitset<M> _bits;
std::bitset<M>* _pbits = new bitset<M>;
};
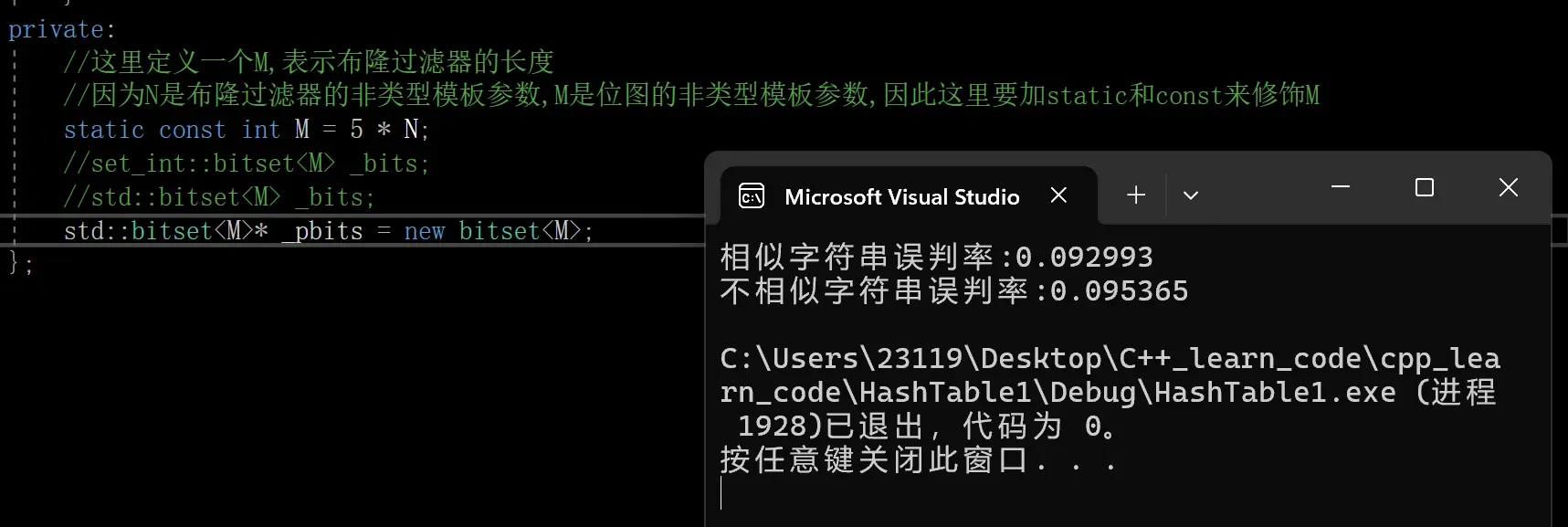
N=100万验证成功
6.布隆过滤器的优缺点

三.哈希切分
1.给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
query:查询,比如SQL语句,网址等等,都是一个查询
这里我们把它当成字符串即可
1.近似算法
利用布隆过滤器+分批次读取

2.精确算法
利用哈希切分+set求交集

哈希切分时间复杂度:O(N)
每个query只遍历常数次

平均切分:时间复杂度O(N^2)
文件B当中的每个query读N次
从这就可以看出哈希切分的强大之处
2.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
如何找到次数最多和TOP-K的IP地址?

如何利用linux系统命令来实现,这是文心一言给的答案

四. 如何扩展BloomFilter使得它支持删除元素的操作?
1.布隆过滤器删除的局限及其问题

将布隆过滤器中的每个比特位扩展成一个char/int,插入元素时给k个char/int加一,删除元素时,给k个char/int减一,通过多占用几倍的存储空间的代价来增加删除
但是有几个问题:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
2.代码
template <size_t N, class K = string,class Hash1 = HashFuncBKDR, class Hash2 = HashFuncAP, class Hash3 = HashFuncDJB>
class BloomFilterExtendedVersion
{
public:
BloomFilterExtendedVersion()
{
_v.resize(5 * N, 0);
}
//插入x
void set(const K& x)
{
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
_v[hashi1]++;
_v[hashi2]++;
_v[hashi3]++;
}
//查找x
bool test(const K& x)
{
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
if (_v[hashi1] == 0) return false;
if (_v[hashi2] == 0) return false;
if (_v[hashi3] == 0) return false;
return true;
}
//删除x
bool erase(const K& x)
{
if (test(x) == false) return false;
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
_v[hashi1]--;
_v[hashi2]--;
_v[hashi3]--;
}
private:
vector<int> _v;
};
3.验证布隆过滤器删除的坑点

4.使用额外的数据结构来进行扩展
1.如何做呢?
因此,仅仅只用计数器来做是不行的,那么怎么办呢?

其实跟我们上面讲的布隆过滤器在学校B无法容忍误判的场景相似
删除时先进行查找,如果不在布隆过滤器当中,那就返回false即可,
如果在布隆过滤器当中,那么就先到数据库当中查找,如果真的在,那么久把计数器–,并且在数据库当中删除该元素
此时我们用一个unordered_set/set充当数据库,存储实际的元素
下面我们写代码
2.代码
template <size_t N, class K = string,class Hash1 = HashFuncBKDR, class Hash2 = HashFuncAP, class Hash3 = HashFuncDJB>
class BloomFilterExtendedVersion
{
public:
BloomFilterExtendedVersion()
{
_v.resize(5 * N, 0);
}
//插入x
void set(const K& x)
{
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
_v[hashi1]++;
_v[hashi2]++;
_v[hashi3]++;
_us.insert(x);
}
//查找x
bool test(const K& x)
{
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
if (_v[hashi1] == 0) return false;
if (_v[hashi2] == 0) return false;
if (_v[hashi3] == 0) return false;
if (_us.count(x) == 0) return false;
return true;
}
//删除x
bool erase(const K& x)
{
if (test(x) == false) return false;
size_t hashi1 = Hash1()(x) % _v.size(), hashi2 = Hash2()(x) % _v.size(), hashi3 = Hash3()(x) % _v.size();
_v[hashi1]--;
_v[hashi2]--;
_v[hashi3]--;
_us.erase(x);
}
private:
vector<int> _v;
unordered_set<K> _us;
};
3.验证
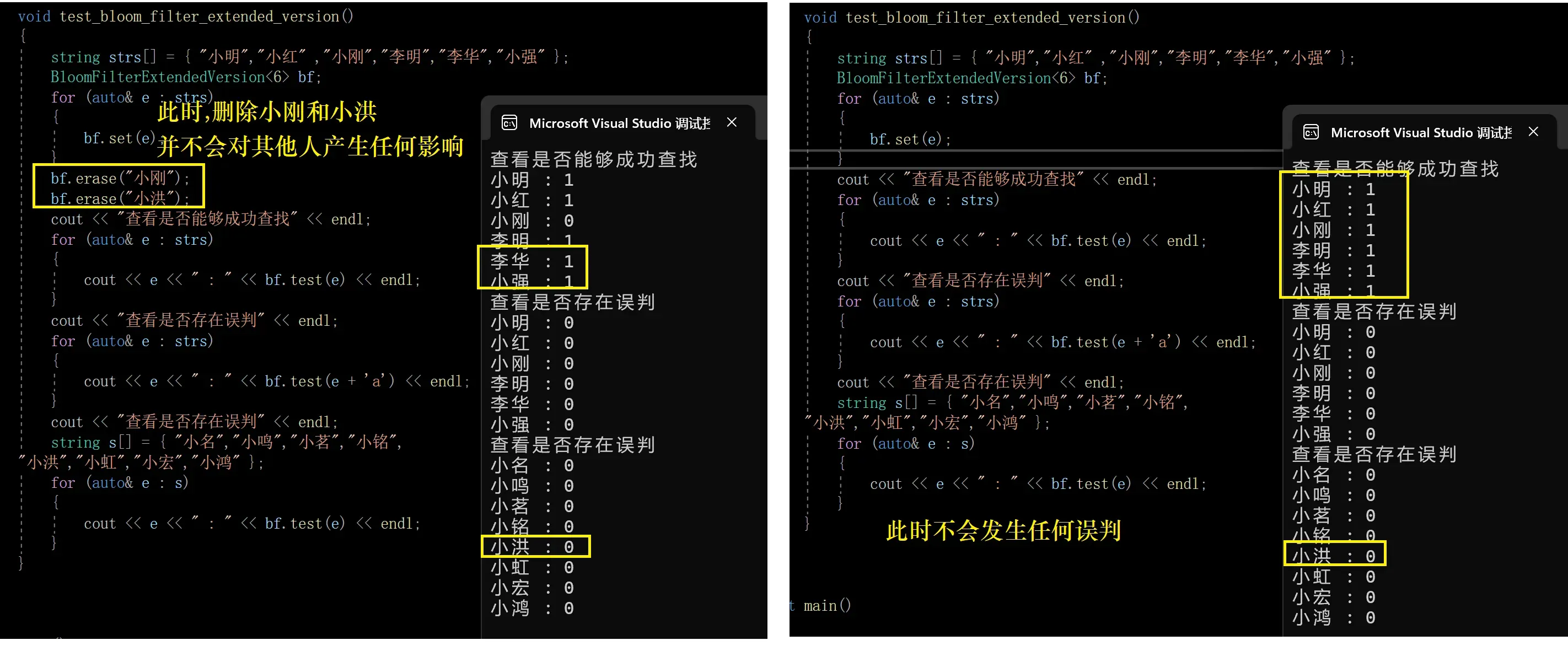
经过上面的一系列分析
我们可以得出
如果该布隆过滤器是应用在能够容忍误判的场景
那么建议不要实现删除操作,否则既浪费空间,又会产生计数回绕和误删的坑点
如果该布隆过滤器是应用在无法容忍误判的场景,
那么可以实现删除操作,唯一的不太好的点就是浪费空间,不过没有计数回绕和误删的问题了
以上就是C++ 哈希思想应用:位图,布隆过滤器,哈希切分的全部内容,希望能对大家有所帮助!!
版权声明:本文为博主作者:program-learner原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Wzs040810/article/details/135217436