摘要
Twitter 机器人检测已成为一项日益重要和具有挑战性的任务,以打击在线虚假信息,促进社会内容审查,并维护社会平台的完整性。
虽然现有的基于图表的 Twitter 机器人检测方法取得了最先进的性能,但它们都是基于同质性假设的,即假设拥有相同标签的用户更有可能被连接,这使得 Twitter 机器人很容易通过跟踪大量真实用户来伪装自己。
为了解决这个问题,我们提出了 HOFA,一种新的基于图形的 Twitter 机器人检测框架,它使用面向同质性的图形增强模块(Homo-Aug)和频率自适应注意模块(FaAt)来对抗异种伪装的挑战。
具体来说,Homo-Aug 提取用户表示并使用 MLP 计算一个-NN 图,并通过注入-NN 图来改进 Twitter 的同调性。
对于 FaAt,我们提出了一种自适应的注意机制,它可以作为沿着同质边缘的低通滤波器和沿着异质边缘的高通滤波器滤波器,防止用户特征被他们的邻居过度平滑。我们还引入了一个权重制导损耗来指导频率自适应注意模块。
我们的实验表明,HOFA 在三个广泛认可的 Twitter 机器人检测基准上实现了最先进的性能,它们明显优于普通的基于图表的机器人检测技术和强大的异种基准。此外,广泛的研究证实了我们的 Homo-Aug 和 FaAt 模块的有效性,以及 HOFA 的能力去神秘化异性伪装的挑战。
1 INTRODUCTION
Twitter,一个广泛使用的在线社交媒体平台,已经成为人们日常生活中不可或缺的一部分,用于分享信息和相互交流。不幸的是,Twitter 的完整性正在被自动化程序控制的账户所破坏,这些程序被称为 Twitter 机器人。Twitter 机器人通过传播错误信息[12,31,68,78] ,干预美国和欧洲的选举[27,63] ,传播极端意识形态[4,64] ,对在线社交平台构成威胁,宣扬阴谋论[28,32]。因此,迫切需要有效的 Twitter 机器人检测方法来识别 Twitter 机器人并减轻其负面影响。
为了赢得与机器人操作器的军备竞赛,Twitter 机器人检测研究人员提出了基于特征、文本和图形的检测方法,利用用户的元数据、文本信息和跟随/跟随关系来识别机器人账户。基于特征的方法从用户元数据[41,76] ,用户时间线[52]和跟踪关系[22,26]中提取特征,并将它们提供给传统的分类器,如用于机器人检测的随机森林。
然而,机器人操作者经常故意篡改手工制作的特征,以逃避基于特征的检测方法[9,11]。研究人员还提出了基于文本的方法,利用自然语言处理技术(如单词嵌入[62,74] ,递归神经网络[14,15,40]和预先训练的语言模型[18,37])来编码 tweet 内容和识别恶意意图。然而,当遇到新的 Twitter 机器人时,基于文本的方法就显得力不从心了,因为它们会在恶意的 Twitter 信息中穿插从真实用户那里窃取的普通信息[9]。随着最近的进展研究人员开发了基于图的 Twitter 机器人检测方法,该方法将 Twitter 解释为一个图,用户节点通过关注者/关注者关系连接起来。然后采用图神经网络(GNN)如 GCN [2,38] ,RGCN [26,65]和 RGT [22]来学习用户表示用于机器人检测。与基于特征和文本的方法相比,基于图的方法实现了最先进的性能,并且已被证明在检测新型机器人[22,26]和泛化[23]方面更有效。
尽管在基于图形的 Twitter 机器人检测方法方面已经取得了重大进展,但是它们仍然容易受到异种伪装的机器人帐户的攻击。现有的基于图的机器人检测方法都是建立在同质性假设的基础上的,即具有相似特征或相同标签的用户(节点)容易相互连接,并使用低通滤波器来平滑邻域内的用户特征。这个假设平滑了连接用户的表示,使得机器人帐户很容易通过跟踪真正的用户来逃避检测。图1展示了异性伪装,通过跟踪大量真实用户,一个机器人帐户的可疑特征可以通过其人类邻居来平滑,从而避开基于同性图的检测。
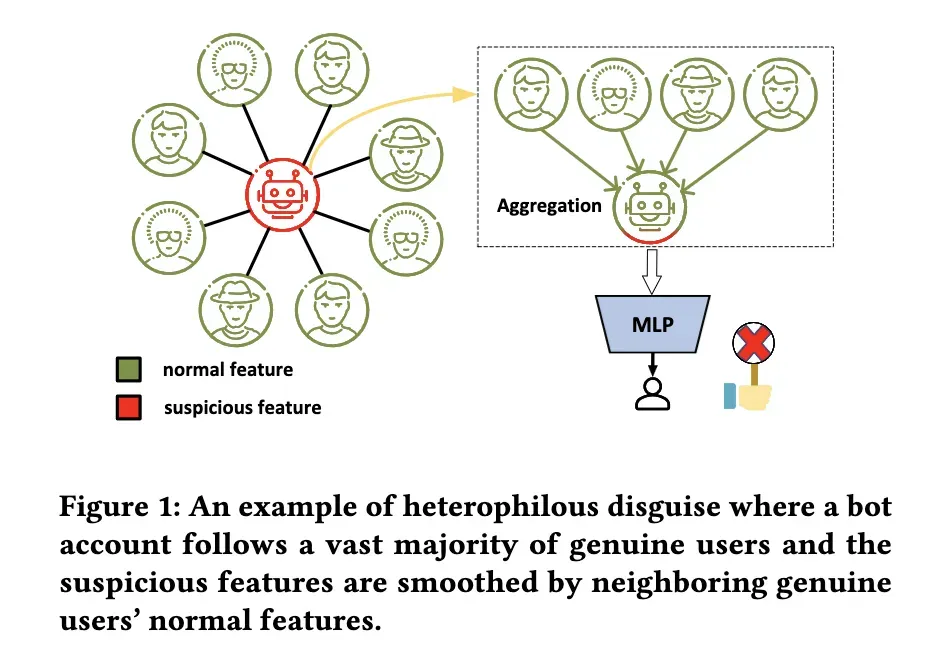
(图1: 异性伪装的一个例子,一个 bot 帐户跟随着绝大多数真实用户,可疑的特征被相邻真实用户的正常特征所平滑。)
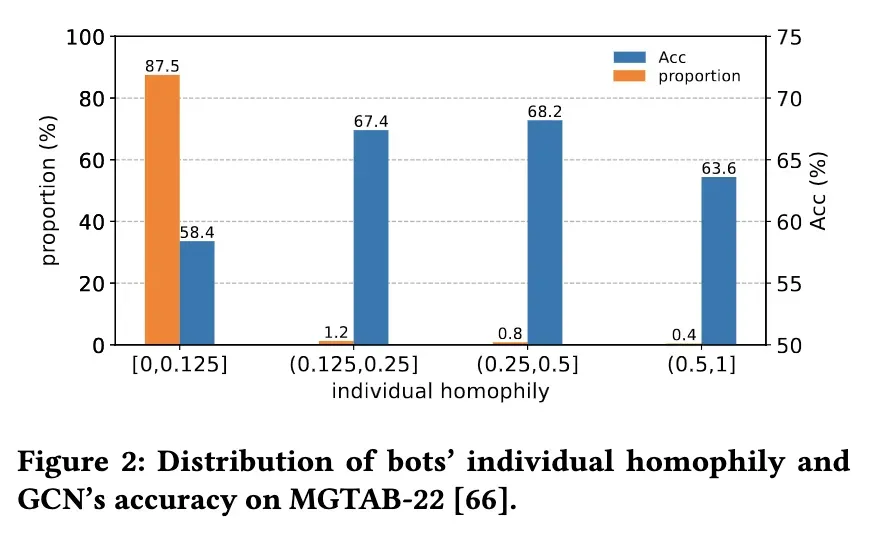
为了验证异质性伪装挑战,我们计算 MGTAB-22[66]数据集中每个机器人的个体同质性评分(在其邻近具有相同标签的用户的比率) ,并根据其同质性评分将这些机器人分为4组(数据集中没有邻居的机器人被排除在外)。我们进一步测试了 GCN 对这4组用户的 bot 检测准确性,结果如图2所示。橙色条显示大部分机器人账户的同质性得分较低,表明异质性伪装挑战的普遍存在。蓝色条表明,机器人检测性能与同质性得分密切相关,低同质性得分的用户的检测性能低于高同质性得分的用户。
为了解决异种伪装在 Twitter-ter 机器人检测中的挑战,我们提出了 HOFA,一种新颖的 Twitter 机器人检测框架,它使用面向同质性的增强模块(Homo-Aug)和频率自适应注意模块(FaAt)来对抗异种伪装。对于面向同构的增强模块,我们首先训练一个 MLP 来对训练集中的节点进行分类。有了这个 MLP,我们提取每个节点的隐藏表示,然后计算每个节点的最近邻集 基于余弦距离的节点形成-神经网络图[20]。然后通过注入-NN 图对原始图进行扩充,从而在图中引入更多的同质信息。
对于频率自适应模块,通过计算注意力权重来捕获异质环境中的低频和高频信息。与应用 softmax 将注意力权重映射到[0,1]的香草式注意力不同,我们使用 tanh 将注意力权重映射到范围[-1,1] ,其中积极的注意力权重对应于低通过过滤器,负面的权重对应于高通过过滤器[6]。为了自适应滤波节点特征,我们使用沿着同质边的低通滤波器来平滑相同标签的节点特征。相比之下,高通滤波器则希望沿着异质边缘应用,以提高不同标签节点的表示效果。为了提高性能和 HOFA 的鲁棒性,我们进一步引入了一个辅助损失来引导边缘注意权重学习。
实验结果表明,HOFA 在三个 Twitter 机器人检测基准上取得了最佳性能,明显优于现有的基于同质图的 Twitter 机器人检测方法和强异亲、质图学习基准。广泛的研究也证实了我们提出的面向同质性的增强、频率自适应注意模块的有效性,以及 HOFA 在解决异质性伪装挑战方面的优越性。总而言之,我们的贡献如下:
我们发现了 Twitter 机器人检测的一个新挑战: 异性伪装。在研究了现有的基于图形的 Twitter 机器人检测基准之后,我们确定了这种挑战的普遍性,并且它的存在对基于图形的方法的有效性造成了严重的阻碍。
作为解决机器人检测中异构伪装挑战的第一个努力,我们提出 HOFA 由一个面向同质性的图增强模块(Homo-Aug)改善原始图的同质性和频率自适应注意模块(FaAt)自适应地结合低频和高频信息来学习异构图中更好的节点表示。
借助 HOFA,我们在三个广为认可的 Twitter 机器人检测基准上取得了最先进的表现。结果表明,HOFA 优于所有 Twitter 机器人检测基线和强异种图学习基线。进一步的实验验证了所提出的面向同态的图增强模块和频率自适应注意模块的有效性。
2 2.1 Twitter Bot检测的相关工作
现有的 Twitter 机器人检测方法主要分为三类: 特征检测、文本检测和图形检测。基于特征的方法通过设计具有用户元数据[40] ,tweet [54] ,时间模式[53] ,描述[35]和关系[24]的区分特征来进行特征工程。然后将特征输入到传统的分类器中,如支持向量机(SVM)[42]、朴素贝叶斯(Naive Bayes)[8]和随机森林(Random Forest)[29] ,以识别 bot 帐户。提出了几种无监督的方法来发现社交机器人的潜在模式,如集群[3]和异常检测[55]。然而,机器人操作者越来越意识到这些基于特征的探测器,并可以通过制造机器人特征故意伪装自己[9,24]。
基于文本的方法使用来自自然语言处理的技术来处理用户描述和 tweet 以进行 bot 检测。这些方法用单词嵌入[74] ,循环神经网络[40] ,注意力机制[24]和预先训练的语言模型[18]来编码用户的 tweet 和描述,以进行机器人检测。进一步的研究集中在结合用户特征[7] ,学习无监督的用户表示[24] ,解决多语言问题[39]。然而,新型机器人正在越来越多地从真正的用户那里窃取文本内容,这对基于文本的方法构成了挑战。此外,冯等人 [26]发现仅仅依靠文本内容是不够健壮和准确的。
基于图的方法将 Twitter 设想为一个图,其中用户通过关注者/关注者关系连接起来,并利用图形机器学习方法进行 bot 检测。Dehghan 等[13]利用了典型的图形特征,如节点中心性、紧密中心性等。Magelinski 等[51]利用图的潜在局部结构,基于多通道直方图检测 bot 帐户。Ali Alhosseini 等人[2]使用图形神经网络(GNN)来检测机器人。最近,许多方法考虑了 Twitter 网络中固有的异构性,并使用异构图神经网络[22,26] ,实现了最先进的性能。此外,许多作品利用多模态用户信息来对抗伪装的机器人。雷等[43]提出 BIC 来促进文本-图形的交互。Liu 等[49]提出了 BotMoE,它构建了特定于模态的专家来共同利用来自元数据、文本和图形模态的信息。Tan 等[69]构建了最大的集合来探测 Twitter 上的机器人百分比。
虽然已经取得了很大的研究进展,但现有的基于图表的 Twitter 机器人检测方法是基于同质性假设的,即假设机器人账户跟随其他机器人,而人类跟随其他人类。然而,我们是第一个发现这个假设不适用于现代 Twitter 机器人检测场景的人,因此提出 HOFA 来解决这项工作中的异构挑战。
2.2异质图形学习图形神经网络(GNNs)
在各种基于图形的机器学习任务中表现出优异的性能[33,38,72]。尽管 GNN 体系结构的设计非常丰富,但是大多数都隐含地遵循同质性假设[47,80]。同态 GNN 作为低通滤波器[6,38]和沿图拓扑的平滑特征,导致相邻节点的类似预测。然而,许多现实世界的图表现出异质性,即链接节点具有不同的特征和不同的类标签,这与同质性相反[47,58,80]。许多研究发现,亲同性的 GNN 不能在非亲同性的环境中学习辨别特征[1,6]。为了应对异质性的挑战,研究人员提出了多种方法。Abu-El-Haija 等[1]确定了使用同态 GNN 学习异质图的挑战,并提出 MixHop 从多跳邻居提取特征以获得更多同态信息。Geom-GCN [60]通过预计算无监督节点嵌入并定义一个双层聚合过程。LINKX [47]是一种简单可扩展的方法,它通过分别嵌入相邻矩阵和节点特征,并使用简单的 MLP 将它们结合起来。H2GCN [80]通过自我和邻居特征分离、高阶邻居聚合和中间表示的组合三种关键设计实现异构。Bo 等人。[6]提出了频率自适应图滤波器,学习边缘级聚合权重,这可以是负的。CPGNN [79]通过一个相容矩阵建立标记相关性模型,并通过这个矩阵传播一个先验信念估计,该估计可以学习异质图的判别表示。
在异质图学习领域已经进行了大量的研究,但其在社会网络中的应用还有待探索。借鉴异构图学习的进展,本文提出了 HOFA 方法,旨在解决 Twitter 机器人检测中异构伪装的问题。
3 PRELIMINARIES
设 G = (V,E,A, R)表示一个源自 Twitter 的异构信息网络(hIN) ,其中 V 是用户集合,具有N = | V | ; E 是没有自环的边集;A ∈ R^{N*N} 是对称邻接矩阵,具有,否则,
= 0; R 是边类型集合。用户v∈ V 的邻域集是 N (v) ,对边型r∈ R 指定的邻域集用
表示。用户的特征用 X ∈ R N×F 表示,其中F是每个用户的特征个数。
同质与异质的测度。同质字符表示具有相同标签的节点在图中连接的可能性。一般来说,有三个广泛使用的度量来度量同调性: 节点同调性[60] ,边同调性[80]和类不敏感的边同质性[47]。节点同质是每个节点具有相同标签的邻居的平均分数:
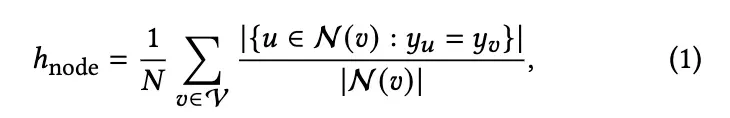
边同质性是连接具有相同标签的节点的边的分数:
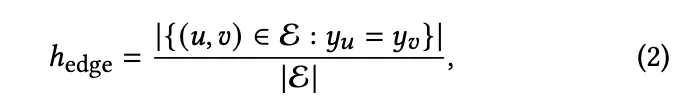
边同调进一步改进为对类的数量和每个类的大小不敏感:
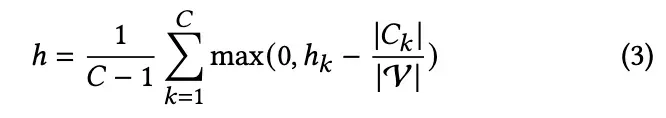
其中C是类数,是类别k的节点数,
是类k的节点的边同调。本文采用类不敏感同态作为度量,以减少类不平衡问题的影响。H 的范围是[0,1]。具有强同疏性的图的 h 值较高,接近于1,而具有强异疏性的图的 h 值较低,接近于0。具体来说,对于边独立于节点标签的图,h = 0[47]。
4方法
在本节中,我们首先介绍一种新颖的、简单的面向同态的图增强模块(Homo-Aug) ,用于改进异质图的同态性。然后我们将说明频率自适应注意模块(FaAt)自适应地捕获 Twitter 网络中的低频和高频信息来学习异种伪装帐户的鉴别表示。HOFA 的概述如图3所示。
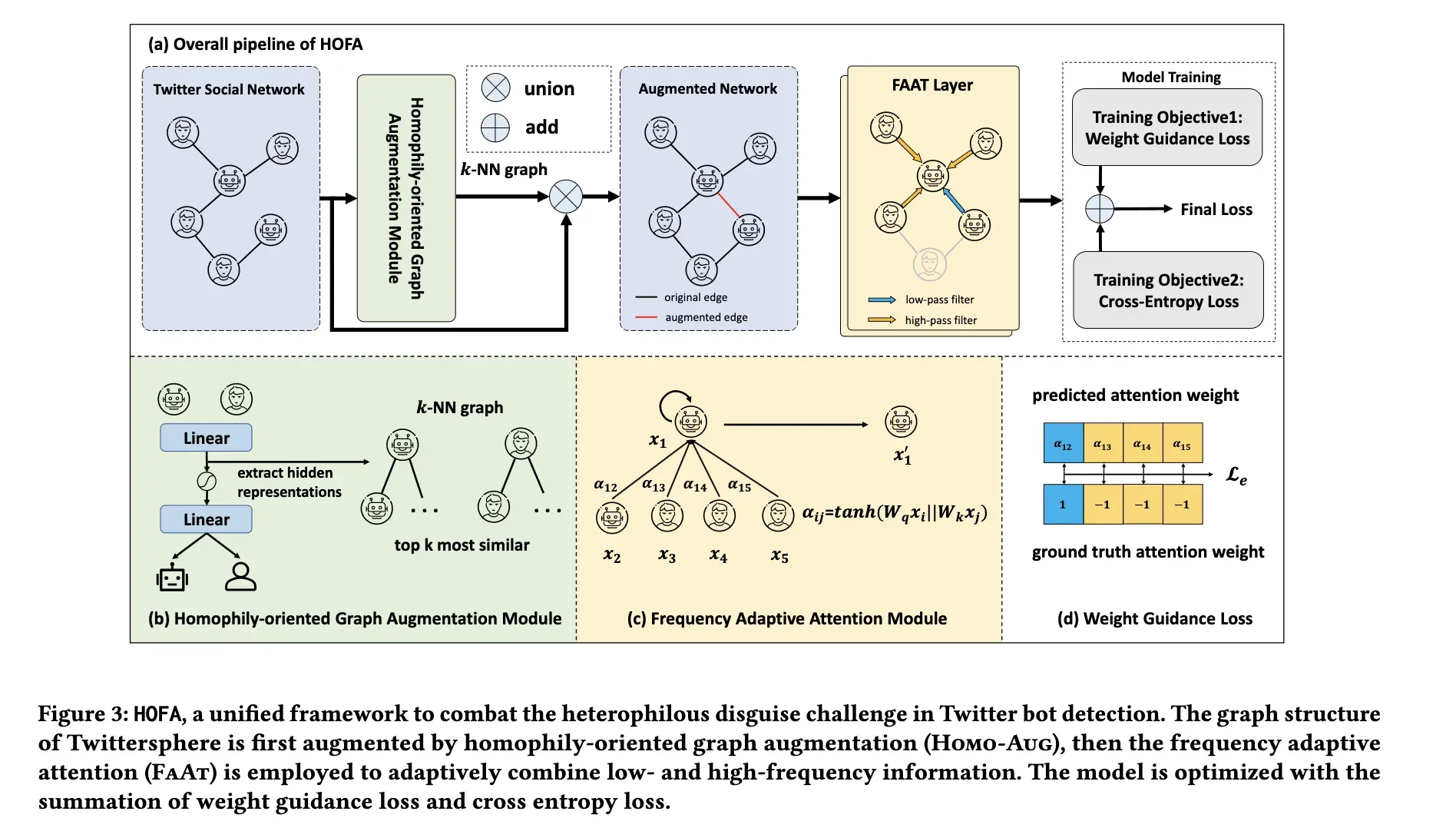
(图3: HOFA,一个统一的框架,用于对抗 Twitter 机器人检测中的异类伪装挑战。首先通过面向同质的图增强(Homo-Aug)来增强 Twitter 空间的图结构,然后利用频率自适应注意(FaAt)来自适应地组合低频和高频信息。将权值导引损失和交叉熵损失相加,对模型进行了优化)
4.1面向同构的图增强
图数据增强的目的是提高深层图模型的性能和鲁棒性。先前的图形数据增强方法包括边界扰动、节点丢失、属性掩蔽和图抽样[16,77]。在这些方法中,边界摄动已被证明对社会网络更有效[77]。然而,随机添加或去除边不能有助于异质图的学习,因为它不增强图的同质性。因此,普通 GNN 的低水平表现仍然存在。
为了提高异质图的学习效率,我们提出了一种简单的方法 Homo-Aug,通过注入同质边来改善图数据的同质性。提出的方法是双重的,我们首先训练一个两层 MLP 进行分类,并提取所有用户基于 MLP 的表示,然后使用余弦距离计算最近邻图[20]。通过将-NN 图注入到原始图中,Homo-Aug 可以有效地改善 Twitter 网络中的图同调性。
我们首先在训练集中训练一个带有标签的两层 MLP,利用交叉熵损失来获得用户表示:
![]()
其中 w1和 w2是可学习的权重矩阵,是非线性激活函数(例如 LeakyrelU [50])。由于 MLP 不利用原始图结构,基于 MLP 的用户表示不受原始图异构性的影响。然后,基于 MLP 提取的隐含表示的相似性计算最近邻图。每个用户的隐藏表示由以下方式给出:
![]()
在使用 MLP 提取用户表示之后,我们计算k-NN 图,其中用户的最近邻集是:
![]()
Cos (· ,·)表示余弦距离。通过合并原始边集和k-NN 边集来增强 Twitter 网络,从而得到一个增强图。为了保持原始图结构的完整性,我们为添加的边指定了一个新的边类型。
4.2频率自适应注意
值得注意的是,尽管 Homo-Aug 可以增强图形同质性,但 Twitter 网络中的异性恋伪装挑战可能会持续存在,用户之间可能会出现多余的边缘。为了减轻这些负面影响,以及减轻 Twittersphere 内在的异质性,我们推出FaAt。
以前的基于图形的 Twitter 机器人检测方法是基于同质假设的,并作为低通过过滤器,也就是说,使得沿着边缘的用户表示变得相似[6] ,这在同质图表上运行良好。然而,我们的研究揭示了 Twitter 网络中内在的异质性(het-erophous 伪装的挑战) ,导致传统的基于同质图的方法不足。例如,使用不同标签的用户的表示在与异质边连接时会混淆。为了解决异质性伪装的难题,提出了自适应选择低通和高通滤波器的 FAAT 算法,该算法使用从 -1到1的边缘权值沿用户连接自适应地选择低通和高通滤波器。负边缘权重表示沿异质边缘应用的高通滤波器,以锐化相邻用户表示,使其更具区分性,而正边缘权重对应于沿同质边缘应用的低通滤波器,以平滑相邻用户表示。此外,我们提出了一种称为 WeGL 的辅助损失来指导边缘权值的学习。下面是具体的步骤,我们首先将用户的描述、数字和分类特性连接到:
![]()
其中是可学习的权重矩阵,
表示非线性激活函数,[ · | · ]表示连接操作,x,xnum 和 xcat 分别表示用户的描述嵌入,数字特征和冯等人采用的分类特征[26]。
频率自适应注意系数。对于每个边∈ E,FaAt 学习一个范围内的系数[-1,1] ,以作为一个自适应的低或高通滤波器。负值表示低通滤波器,正值表示高通滤波器[6]。这是基于中心用户特性
和邻居用户特性
。在l-th 层,我们 首先从
和
获得查询和关键向量:
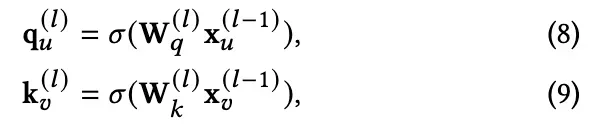
其中 W是第l层的可学习权重矩阵,然后我们计算频率自适应注意系数如下:
![]()
其中g是可训练向量,[ · ∥ · ]表示级联运算,tanh 将注意权值约束为[-1,1] ,使 FaAt 自适应地充当低通和高通滤波器
边缘级剩余连接。灵感来自何等人[36]发现注意系数上的残差连接可以提高表现,我们将残差连接纳入 HOFA 的注意系数以加速收敛。为了详细说明,我们在通过以下方法获得初始原始注意系数之后引入了残差连接:
![]()
异构邻居聚合。在获得注意系数之后,我们对社会网络中的内在异质性进行邻里信息聚合。给出了基于关系类型的中心用户相邻用户聚集范式
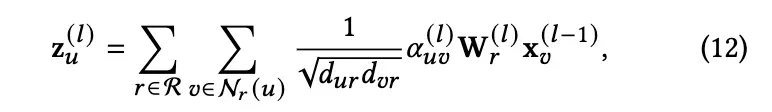
其中 W 表示关系r的可学习权矩阵,,
分别表示节点u和v的度在关系类型r下,R 表示关系类型的集合。
多头注意。受香草注意力机制[71]的启发,我们采用多头注意力来提高 HOFA 的稳定性和性能。相应的更新范例是:
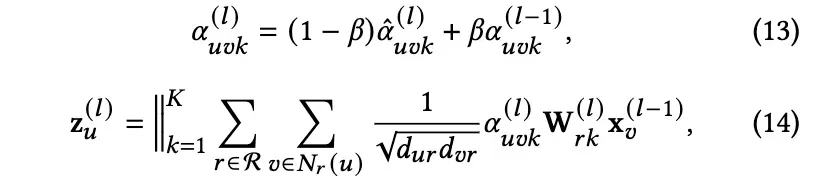
其中K表示注意头的数目,∥表示串联运算。
节点级剩余连接。先前的研究表明,GNN 经常被过度平滑和梯度消失这些臭名昭著的问题所困扰[45,75]。这些问题可以通过精心设计的预激活节点残差连接来缓解[44]。在 HOFA 中,我们提出了两种类型的节点残差连接,它们在不同的数据集之间表现出细微的性能变化:
![]()
其中 w 是一个调整前一层用户表示的线性映射。
![]()
方程16采用初始用户特征的加权和来防止过度平滑,其中∈[0,1]是一个比例因子来平衡初始用户特征和学习表示 。
4.3训练和推理
我们应用频率自适应注意模块的层次,并使用一个线性映射来获得机器人检测结果:
![]()
注意系数在该算法中起着至关重要的作用。对于边∈ E 连接具有相同标号的节点(同态) ,需要一个正注意系数(接近1)作为低通滤波器。相反,对于连接有不同标签的节点的边缘(异质性) ,负的注意力重量(接近 -1)更适合作为高通滤波器。为了确保“FaAt”功能符合预期,我们加入了一个来自已知标签的辅助损失:
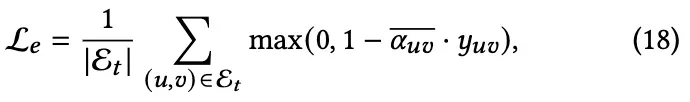
其中 E 代表边缘集,包括用户u,v在训练集,表示平均频率自适应 Furthermore,
= 1 if
, otherwise,
= − 1。
为了训练 HOFA,我们将交叉熵损失与提出的权值导引损失相结合作为最终目标。此外,还增加了2个正则项,以减轻过度拟合。由此产生的损失函数可表示为:
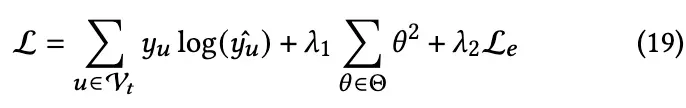
其中 表示训练用户集,
是 HOFA 的预测,Θ 包含 HOFA 的所有可训练参数,1和2是平衡三个损失项的超参数。
5 EXPERIMENTS
5.1实验设置
5.1.1数据集。我们在三个广泛认可的 Twitter bot 检测基准上评估 HOFA: Cresci15[10] ,TwiBot-20[25]和 MGTAB-22[66]。cresci-15数据集是在2015年提出的,包括5,301名 Twitter 用户和他们的关注对象。我们发现它具有同态图结构,因为当时新型机器人的异态伪装并不明显。为了复制异种伪装,我们通过在人类和机器人之间包含额外的类间连接来管理 Cresci15-H 数据集,同时保持所有其他连接不变。TwiBot-20[25]数据集涵盖了多样化的机器人和真正的用户,以更好地代表现实世界的 Twitter 领域。MGTAB-22[66]数据集包含10,199个专家注释用户和7种类型的关系。数据集统计信息见表2。与史等人的方法一致。[66,67] ,我们采用了train/val/测试比率为10%/10%/80% 的随机分割,并报告了5次运行的 av 平均性能,以及标准差,以确保 HOFA 和基线之间的公平比较。
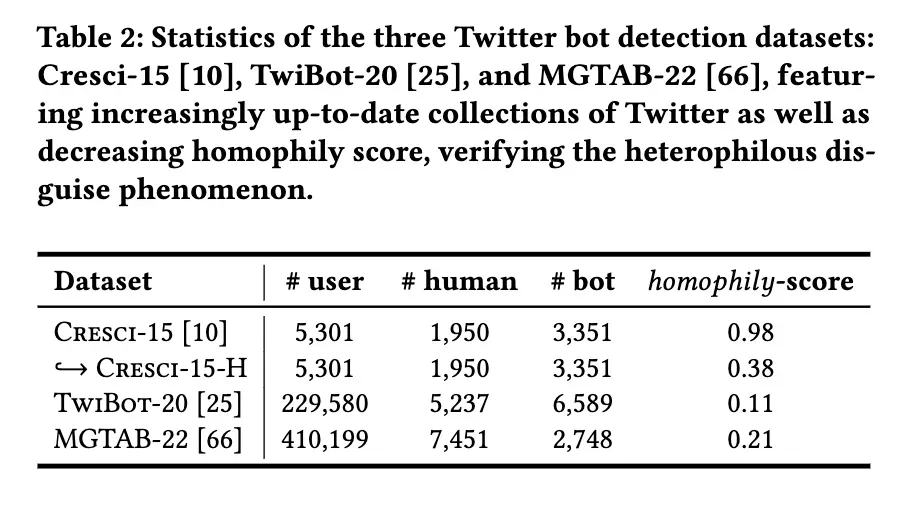
(表2: 三个 Twitter 机器人检测数据集的统计数据: Cresci-15[10] ,TwiBot-20[25]和 MGTAB-22[66] ,其特征在于越来越多的最新 Twitter 集合以及降低同质性评分,验证异质伪装现象)
5.1.2基线。我们比较了来自特征,文本和图形类别(MLP,SGBot,BotHunter,RoBERTa,LOBO,BotBuster,GCN,GraphSAGE,GAT,BotRGCN,RGT)的 HOFA 和 Twitter 机器人检测基线以及竞争性异构图学习方法(LINKX,MixHop,H2GCN,FAGCN)。
MLP.一个以用户的数字、分类和描述特征作为输入的两层 MLP。
GCN [38]同等地聚合来自邻居的特征,并将用户表示传递到 MLP 中进行分类。
GAT [72]引入了注意机制,以区分相邻用户在聚合中的重要性。学习表示被输入 MLP 进行分类。
GraphSAGE [33]分别嵌入自我和邻居用户特征,并将学到的表示传递到 MLP 中用于机器人检测。
SGBot [76]从用户的元数据中提取特征,并利用随机森林分类器进行可扩展和可推广的 bot 检测。
BotHunter [5]从元数据和文本中提取用户特征,并提出了一种分层的 bot 检测方法。
RoBERTa [48]使用预先训练的 RoBERTa 编码用户描述和 tweet,并将用户特征提供给 MLP,用于机器人识别。
LOBO [19]从用户元数据和 tweet 中提取特征,并使用随机森林来识别不同的机器人。
BotBuster [57]通过混合专家架构处理用户元数据和文本信息,增强跨平台机器人检测。
BotRGCN [26]构建了一个异构的 Twitter 社交网络,并利用关系图卷积网络进行用户表示学习和 Twitter 机器人检测。
RGT [22]利用关系图转换器模拟 Twitter 领域内在的异质性,以增强 Twitter 机器人(bot)的检测能力。
BIC [43]提出了一个文本-图形交互模块,并建立了语义一致性模型,从而提高了机器人的检测性能,防止了机器人的进化。
LINKX [47]是一种简单且可扩展的方法,它分别嵌入节点特征和相邻矩阵,并将它们反馈到 MLP 中,用于异构图表示学习。
MixHop [1]利用多跳邻居获取更多的同态信息,从而增强异态图学习。
H2GCN [80]分别嵌入了自我和高阶邻域特性,并在异构基准上表现出强大的性能。
FAGCN [6]采用频率自适应滤波器,通过计算可能具有负值的边缘级聚合权重。
5.1.3实施。我们使用 PyTorch [61]、 PyTorch -geo[30]、 Scikit-learn [59]和 Numpy [34]来实现 HOFA。表3列出了超参数设置,以方便复制。我们在一个拥有4个 RTX3090图形处理器、24 GB 内存、10个 CPU 核和64 GB CPU 内存的集群上进行所有实验。继 Feng 等人之后[22] ,Schlichtkrull 等人[65] ,我们利用跟随者和朋友关系来构建异构的信息网络。对于用户特性,我们使用 Cresci15[10]和 TwiBot-20[25]中的数字特性、分类属性和描述。在 TwiBot-20和 MGTAB-22中不使用未标记的支持集。在 Cresci15、 TwiBot-20和 MGTAB-22上训练 HOFA 大约需要0.5分钟、1分钟和2分钟。我们将公开所有 HOFA 实现。

5.2 Main Results
我们评估 HOFA 与16个代表性的特征,文本,图形为基础的 Twitter 机器人检测方法,以及竞争异性 GNN。如表1所示,我们发现: HOFA 在所有三个数据集中始终优于所有基线方法。具体而言,与以前的最先进的 Twitter 机器人检测方法 RGT [22]相比,HOFA 在 TwiBot-20上分别达到4.59% ,4.81% ,3.91% 的准确性,F1评分和平衡准确性改善[25]。同样,在 MGTAB-22[66]上,HOFA 在准确性,F1评分和平衡准确性方面分别比 RGT 高1.21% ,2.92% 和2.35% 。与现有的异质图学习方法 FAGCN 相比,HOFA 在 TwiBot-20上的准确率提高了1.36% ,F1得分提高了1.39% ,在 MGTAB-22上的准确率提高了1.25% ,F1得分提高了2.19% 。
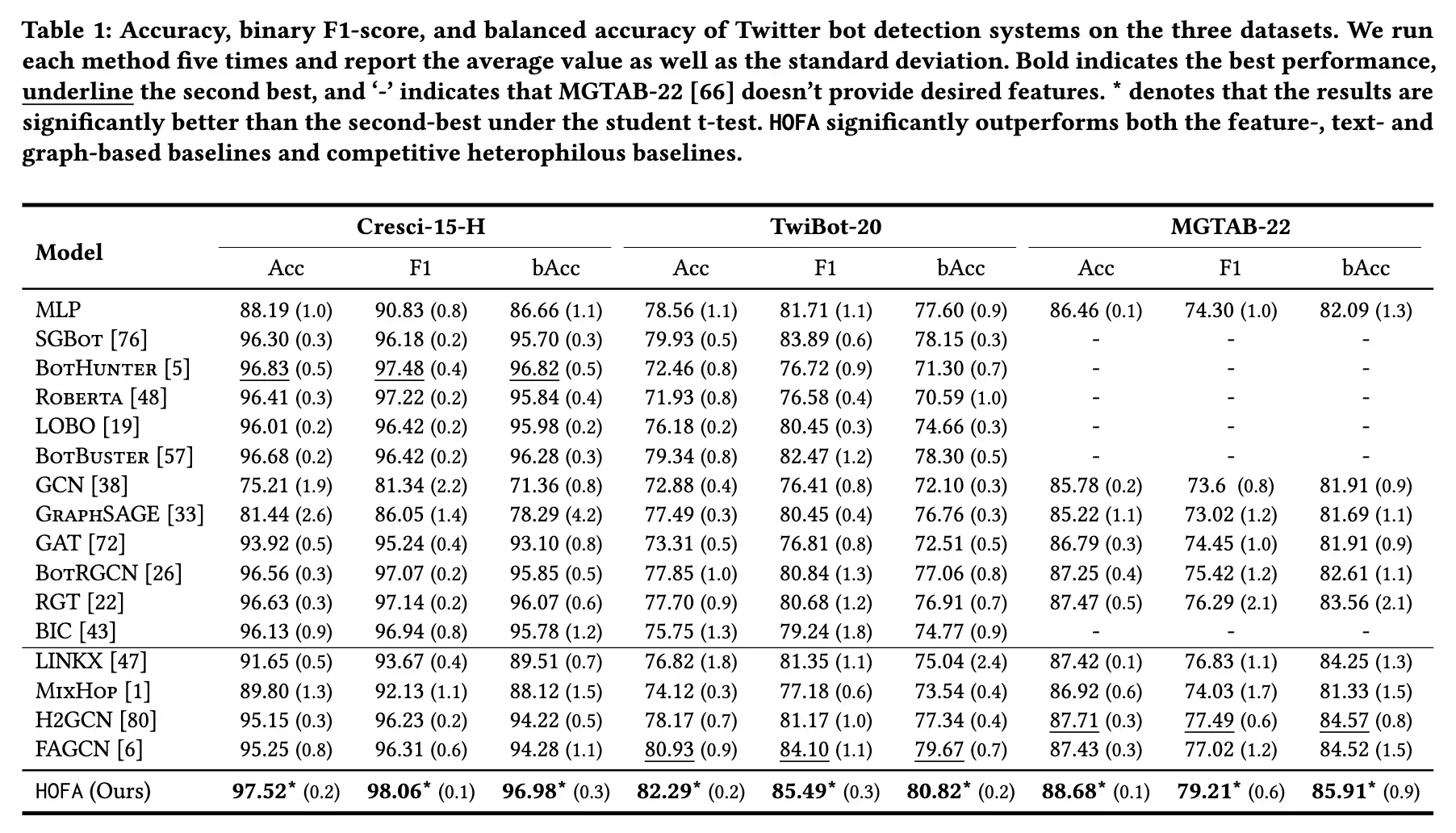
(表1: 三个数据集上 Twitter 机器人检测系统的准确性、二进制 F1得分和平衡准确性。我们每个方法运行5次,报告平均值和标准差。粗体表示性能最好,下划线表示第二好,“-”表示 MGTAB-22[66]没有提供所需的特性。* 表示在学生 t 测试中,成绩明显优于次佳。HOFA 的性能明显优于基于特征、文本和图表的基线和竞争性异构基线。)
现有的基于同质图的 Twitter 机器人检测方法与同质图学习方法相比,性能普遍较差。具体而言,以前的基于最先进的图形的方法 RGT [22]被发现不如基于 Cresci-15-H 数据集的香草特征和基于文本的方法。此外,我们的实验表明,一个简单的 MLP 可以在所有三个数据集上优于 GCN,突出了异种伪装对基于图的 Twitter 机器人检测方法的重要影响。
随着图的异质性增加,HOFA 相对于基线的优越性也随之增加。具体而言,HOFA 在 F1评分上实现了最高的改善(4.81% 和3.91%) ,平衡精度高于 TwiBot-20上的 RGT,同质性最低结果表明,该方法具有较高的机器人检测效率,并能有效地解决异种伪装的难题
5.3增强研究
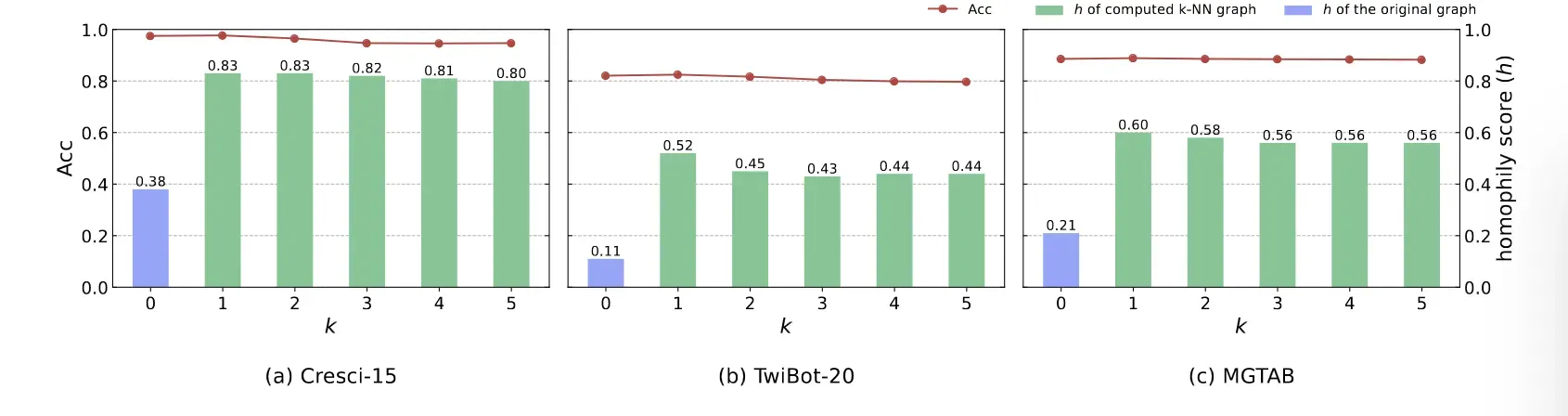
为了研究面向同调的图增强模型的有效性以及参数对模型性能的影响,我们改变了 Homo-Aug 模型中的值,并检验了注入邻域的同调评分相邻(- NN)图及相应的 HOFA 机器人检测精度。如图4所示,我们发现计算神经网络图的同质性评分显着大于原始图,表明 Homo-Aug 在改善同质性信息方面的有效性,从而提高了模型的性能。然而,随着数值的增加,-NN 图的同调度和 HOFA 的精度都降低了。我们推测这是由于在图结构中引入了更多的噪声。
5.4 Heterophily Pertubation Study
如主要结果所示,HOFA 的优越性随着同质性评分的降低而增加,为了进一步研究异质性对 Twitter bot 检测性能的影响,我们通过引入不同比例的异质性边缘来修改 Cresci-15[10]数据集的图形结构,同时保持恒定数量的同质性边缘。这导致图具有不同的同调得分。我们评估了 GCN [38] ,GAT [72] ,RGT [22]和我们提出的 HOFA 在这些具有不同同质性评分的图上的表现,并在图6中显示结果。实验结果表明,异质性对同质性 GNN 的性能有显著影响,如 GCN 和 GAT 的性能随着同质性得分的降低而降低。相比之下,以前的最先进的方法 RGT [22]基于关系转换器结构,在同质性变化时表现出相对稳定的性能。我们提出的方法 HOFA 始终如一地实现最佳性能,无论图是同态的还是异态的,从而验证 HOFA 对不同程度的异态的鲁棒性及其在对抗异态伪装挑战方面的有效性。
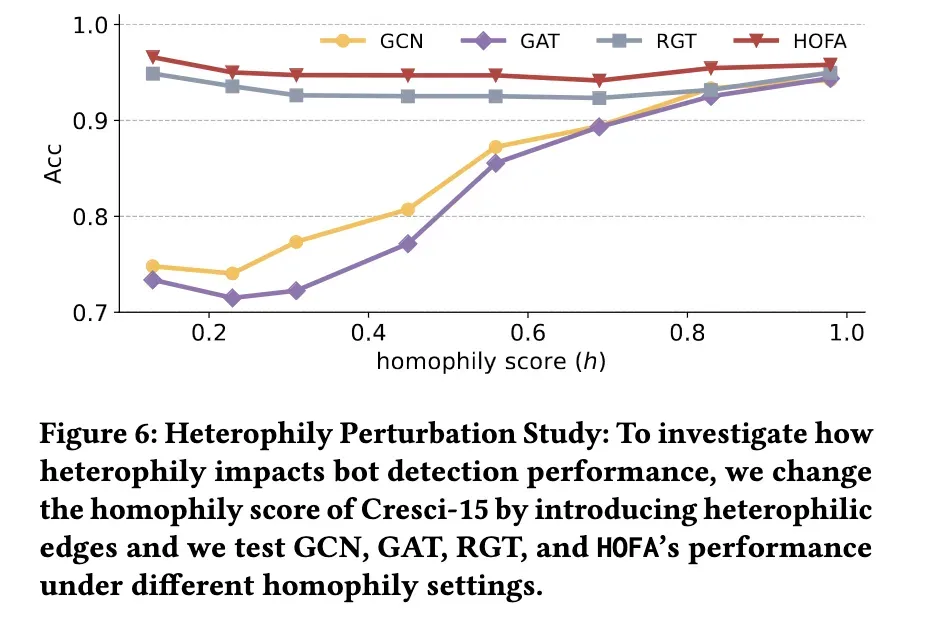
(图6: 异质性扰动研究: 为了研究异质性如何影响 bot 检测性能,我们通过引入异质性边缘来改变 Cresci-15的同质性评分,并且我们在不同的同质性设置下测试 GCN,GAT,RGT 和 HOFA 的性能)
5.5注意力系数的可视化
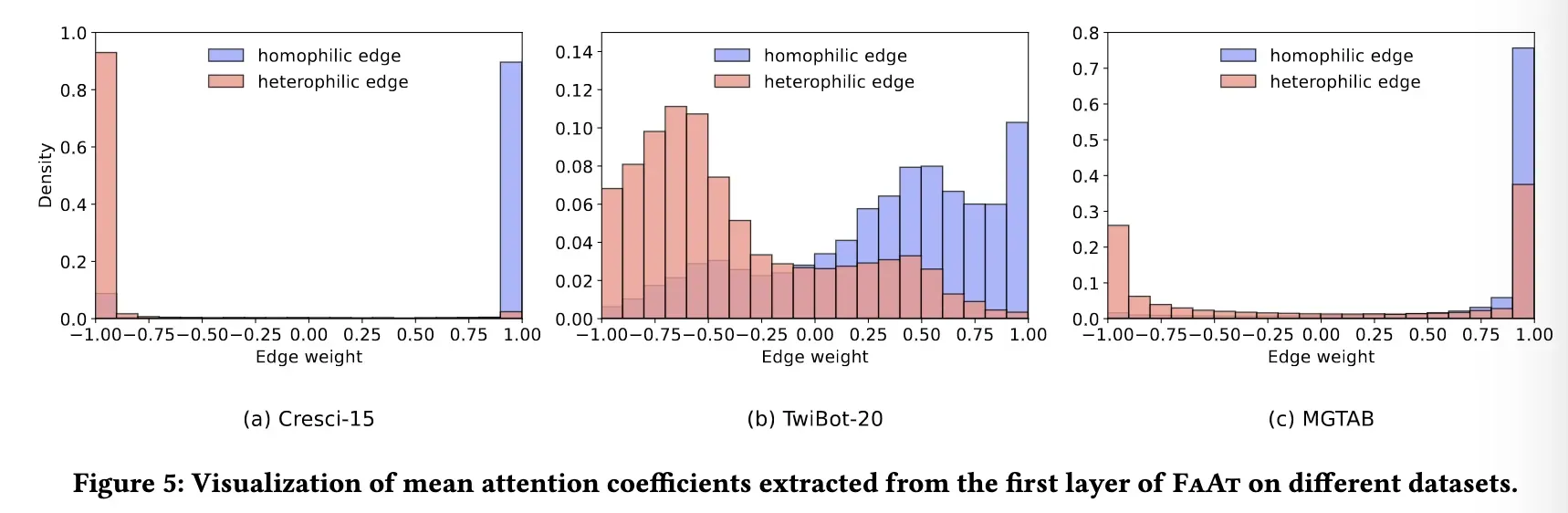
为了检验我们提出的 HOFA 可以沿着不同类型的边缘学习不同的注意力系数,我们可视化的平均注意力系数的分布从图5的第一层提取。为了提高可读性,我们根据两个连通节点是否具有相同的接地真值标签,将边分为同质边和异质边。我们的研究结果表明,大多数异质边具有负的注意系数,而大多数同质边缘具有正注意系数,这与我们沿同质边缘使用低通滤波器(具有正注意重量)和沿异质边缘使用高通滤波器(具有负注意重量)的设计意图一致
6 DISCUSSION
6.1道德声明
我们设想 HOFA 是一种辅助手段,而不是检测 Twitter 机器人的唯一终极决策者。由于 HOFA 和其他自动机器人检测框架是不完美的代理,因此需要谨慎使用,因此人工监督对于做出最终判断是必要的。首先,HOFA 可能会做出错误的正面预测,即将合法账户错误地分类为机器人,这可能给传播重要信息的企业或个人带来麻烦[70]。其次,HOFA 利用预训练语言模型(PLM)进行用户特征编码,利用 GNN 进行用户表征学习,这不可避免地会继承 PLM 和 GNN 的偏见和刻板印象。例如,PLM 的相关数据中有很大一部分包含仇恨、偏见和刻板印象[21,46,56]。此外,GNN 可能从训练数据中继承历史偏见,并导致预测中的歧视性偏见[17,73]。
6.2限制及未来工作
我们确定了 HOFA 中的两个限制。该算法首先采用两阶段训练的方法,首先对 MLP 进行图数据增强训练,然后将增强后的图和节点输入 FaAt 进行机器人识别。这两个阶段的训练范例可能会导致次优的表现。其次,由于数据来源有限,我们只能检测 Twitter 上的机器人账户,而 HOFA 对其他社交平台(如 Reddit、 Facebook 和 TikTok)的推广仍然不够。展望未来,我们计划开发一个通用的自我监督式学习机器人检测框架,可以适应不同的社交平台。
版权声明:本文为博主作者:无脑敲代码,bug漫天飞原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_40671063/article/details/136021751