我的个人博客主页:如果’’真能转义1️⃣说1️⃣的博客主页
关于Python基本语法学习—->可以参考我的这篇博客:《我在VScode学Python》
接下来回更新一个关于urllib的文章
爬取想要的HTML
- 爬虫一个新浪博客地址
- 解释:
- 注意事项
- 网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。
- 其目的一般为编纂网络索引(英语:Web indexing)。
- 网络搜索引擎等站点通过爬虫软件更新自身的网站内容(英语:Web content)或其对其他网站的索引。
- 网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引(英语:Index (search engine))供用户搜索
。
爬虫一个新浪博客地址
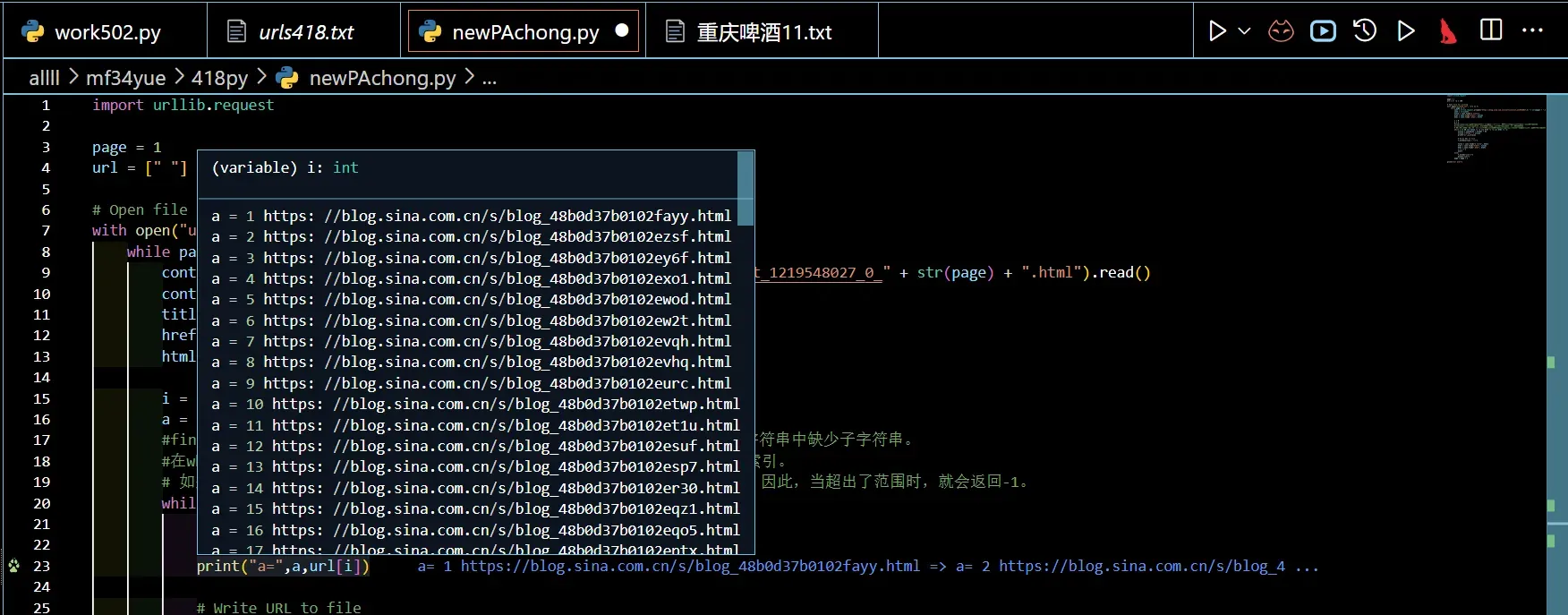
import urllib.request
page = 1
url = [" "] * 100
# Open file for writing
with open("urls418.txt", "w") as f:
while page <= 2:
cont = urllib.request.urlopen("https://blog.sina.com.cn/s/articlelist_1219548027_0_" + str(page) + ".html").read()
cont = str(cont)
title = cont.find("a title")
href = cont.find("href=", title)
html = cont.find(".html", href)
i = 0
a = 1
#find()方法在未找到子字符串时返回-1,因此值-1被用作一种约定,以指示cont字符串中缺少子字符串。
#在while循环中,title、href和html变量被更新为相应子字符串的下一个出现的索引。
# 如果这些变量中的任何一个是-1,则表示相应的子字符串未找到,循环应该终止。因此,当超出了范围时,就会返回-1。
while i <= 50 and title != -1 and href != -1 and html != -1:
url[i] = cont[href + 6:html + 5]
url[i] ="https:" + url[i]
print("a=",a,url[i])
# Write URL to file
f.write(url[i] + "\n")
title = cont.find("a title", html)
href = cont.find("href=", title)
html = cont.find(".html", href)
i = i + 1
a=a+1
else:
f.write("over\n")
print("over")
page = page + 1
print("all over")
解释:
它的目标是从一个网站中爬取URL并将它们写入文件。使用urllib.request模块进行HTTP请求。代码将page变量初始化为1,将url列表初始化为100个空字符串。然后使用with语句以写模式打开名为”urls418.txt”的文件,这可以确保在写入后正确关闭文件。
然后,代码进入一个while循环,只要page小于或等于2,就会一直运行。在循环内部,代码使用urllib.request.urlopen()对特定URL进行HTTP请求,并将响应读入字符串变量cont中。然后,代码使用find()方法在cont中搜索字符串”a title”的第一次出现的索引,并将其赋值给变量title。然后,它从title索引开始搜索字符串”href=“的第一次出现,并将其赋值给变量href。最后,它从href索引开始搜索字符串”.html”的第一次出现,并将其赋值给变量html。
然后,代码进入一个嵌套的while循环,只要i小于或等于50且title、href和html不等于-1,就会一直运行。在循环内部,代码使用字符串切片从cont中提取URL,并将其分配给url列表中的索引i。然后,它在URL前面添加”https:”并将其打印到控制台。代码还使用write()方法将URL写入先前打开的文件。然后,代码将title、href和html变量更新为相应字符串在cont中的下一个出现的索引,并将i和a分别增加1。
如果while循环由于i超过50或任何变量等于-1而终止,则代码将字符串”over”写入文件并将其打印到控制台。然后,将page变量增加1,并重复循环,直到page大于2。最后,代码将字符串”all over”打印到控制台。
如果要修改代码以从不同的网站中爬取URL,则可以更改传递给urllib.request.urlopen()的URL。如果要将URL写入不同的文件,则可以更改传递给open()函数的文件名。如果要修改要爬取的URL的最大数量,则可以更改嵌套的while循环中的i <= 50条件的值。如果要修改要爬取的页面范围,则可以更改外部while循环中的条件。
注意事项
urllib.request访问请求
需要 file记录内容
同样的,将里面的参数改一下知道里面是有什么样的内容了,改成< p >和< /p >的获取,就是获取内容了。
find()方法在未找到子字符串时返回-1,因此值-1被用作一种约定,以指示cont字符串中缺少子字符串。
有些甚至要用到正则表达式:
res = requests.get(url,headers=headers)
titles = re.findall('<h1>(.*?)</h1>', res.text, re.S)
numbers = re.findall('<div class="creab">.*?<span>(.*?)</div>',res.text,re.S)
contents = re.findall('<p>(.*?)</p>',res.content.decode('GBK'),re.S)
#这里就是你需要的了
for title, number,content in zip(titles,numbers,contents):
f.write(title + '\n')
f.write(number + '\n')
f.write(content+'\n') #正则获取数据写入txt文件中
zip函数用于并行迭代多个列表。在这种情况下,zip用于同时迭代titles、numbers和contents列表。
文章出处登录后可见!