网上有很多添加解耦头的博客,在此记录下我使用解耦头对YOLOv5改进,若侵权删
解耦头的介绍过段时间再写,先直接上添加方法(这篇文章写的很好,解释了解耦头的作用)
ASFF我没有使用过,但是按照下边的方法添加后也能够运行
我是在YOLOv5-7.0版本上进行修改,如果有什么不对的地方欢迎大佬指教
一、common.py文件中加入代码
这部分是解耦头的代码
对着图去看代码能更好的理解结构
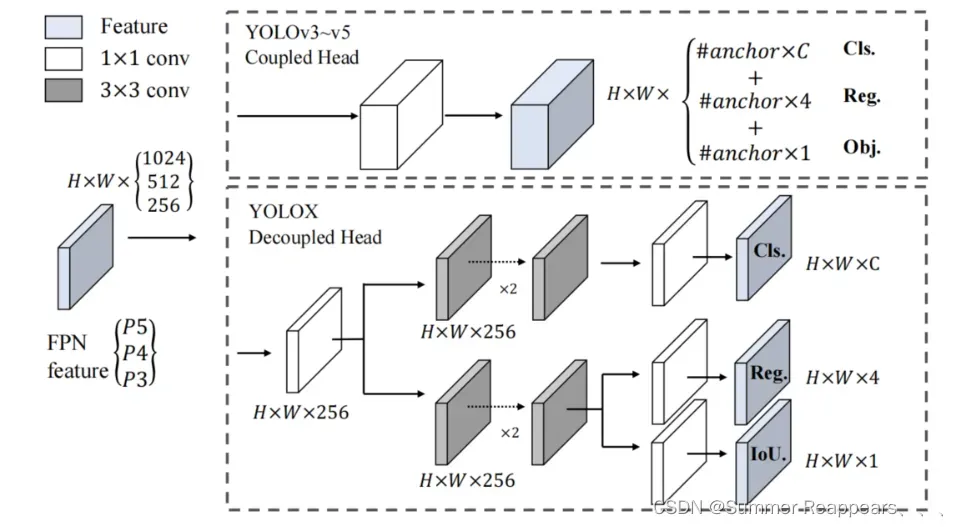
#======================= 解耦头=============================#
class DecoupledHead(nn.Module):
def __init__(self, ch=256, nc=80, anchors=()):
super().__init__()
self.nc = nc # number of classes
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.merge = Conv(ch, 256 , 1, 1)
self.cls_convs1 = Conv(256 , 256 , 3, 1, 1)
self.cls_convs2 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs1 = Conv(256 , 256 , 3, 1, 1)
self.reg_convs2 = Conv(256 , 256 , 3, 1, 1)
self.cls_preds = nn.Conv2d(256 , self.nc * self.na, 1) # 一个1x1的卷积,把通道数变成类别数,比如coco 80类(主要对目标框的类别,预测分数)
self.reg_preds = nn.Conv2d(256 , 4 * self.na, 1) # 一个1x1的卷积,把通道数变成4通道,因为位置是xywh
self.obj_preds = nn.Conv2d(256 , 1 * self.na, 1) # 一个1x1的卷积,把通道数变成1通道,通过一个值即可判断有无目标(置信度)
def forward(self, x):
x = self.merge(x)
x1 = self.cls_convs1(x)
x1 = self.cls_convs2(x1)
x1 = self.cls_preds(x1)
x2 = self.reg_convs1(x)
x2 = self.reg_convs2(x2)
x21 = self.reg_preds(x2)
x22 = self.obj_preds(x2)
out = torch.cat([x21, x22, x1], 1) # 把分类和回归结果按channel维度,即dim=1拼接
return out
class Decoupled_Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(DecoupledHead(x, nc, anchors) for x in ch)
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid(y, x, indexing='ij')
else:
yv, xv = torch.meshgrid(y, x)
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid这部分是ASFF代码
首先需要在common.py导入该段代码
import torch.nn.functional as F然后在common.py最下方加入ASFF的代码
#====================================== ASFF ===========================================#
class ASFFV5(nn.Module):
def __init__(self, level, multiplier=1, rfb=False, vis=False, act_cfg=True):
"""
ASFF version for YoloV5 .
different than YoloV3
multiplier should be 1, 0.5
which means, the channel of ASFF can be
512, 256, 128 -> multiplier=1
256, 128, 64 -> multiplier=0.5
For even smaller, you need change code manually.
"""
super(ASFFV5, self).__init__()
self.level = level
self.dim = [int(1024*multiplier), int(512*multiplier),
int(256*multiplier)]
# print(self.dim)
self.inter_dim = self.dim[self.level]
if level == 0:
self.stride_level_1 = Conv(int(512*multiplier), self.inter_dim, 3, 2)
self.stride_level_2 = Conv(int(256*multiplier), self.inter_dim, 3, 2)
self.expand = Conv(self.inter_dim, int(
1024*multiplier), 3, 1)
elif level == 1:
self.compress_level_0 = Conv(
int(1024*multiplier), self.inter_dim, 1, 1)
self.stride_level_2 = Conv(
int(256*multiplier), self.inter_dim, 3, 2)
self.expand = Conv(self.inter_dim, int(512*multiplier), 3, 1)
elif level == 2:
self.compress_level_0 = Conv(
int(1024*multiplier), self.inter_dim, 1, 1)
self.compress_level_1 = Conv(
int(512*multiplier), self.inter_dim, 1, 1)
self.expand = Conv(self.inter_dim, int(
256*multiplier), 3, 1)
# when adding rfb, we use half number of channels to save memory
compress_c = 8 if rfb else 16
self.weight_level_0 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = Conv(
self.inter_dim, compress_c, 1, 1)
self.weight_levels = Conv(
compress_c*3, 3, 1, 1)
self.vis = vis
def forward(self, x): #l,m,s
"""
# 128, 256, 512
512, 256, 128
from small -> large
"""
x_level_0=x[2] #l
x_level_1=x[1] #m
x_level_2=x[0] #s
# print('x_level_0: ', x_level_0.shape)
# print('x_level_1: ', x_level_1.shape)
# print('x_level_2: ', x_level_2.shape)
if self.level == 0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter = F.max_pool2d(
x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level == 1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized = x_level_1
level_2_resized = self.stride_level_2(x_level_2)
elif self.level == 2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=4, mode='nearest')
x_level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized = F.interpolate(
x_level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized = x_level_2
# print('level: {}, l1_resized: {}, l2_resized: {}'.format(self.level,
# level_1_resized.shape, level_2_resized.shape))
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
# print('level_0_weight_v: ', level_0_weight_v.shape)
# print('level_1_weight_v: ', level_1_weight_v.shape)
# print('level_2_weight_v: ', level_2_weight_v.shape)
levels_weight_v = torch.cat(
(level_0_weight_v, level_1_weight_v, level_2_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:, 0:1, :, :] +\
level_1_resized * levels_weight[:, 1:2, :, :] +\
level_2_resized * levels_weight[:, 2:, :, :]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
class ASFF_Detect(nn.Module): #add ASFFV5 layer and Rfb
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), multiplier=0.5,rfb=False,inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.l0_fusion = ASFFV5(level=0, multiplier=multiplier,rfb=rfb)
self.l1_fusion = ASFFV5(level=1, multiplier=multiplier,rfb=rfb)
self.l2_fusion = ASFFV5(level=2, multiplier=multiplier,rfb=rfb)
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
result=[]
result.append(self.l2_fusion(x))
result.append(self.l1_fusion(x))
result.append(self.l0_fusion(x))
x=result
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid() # https://github.com/iscyy/yoloair
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid(y, x, indexing='ij')
else:
yv, xv = torch.meshgrid(y, x)
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
#print(anchor_grid)
return grid, anchor_grid二、修改yolo.py
1)修改这部分,用下边的代码直接替换红框这行代码就行,注意看我代码所在的行数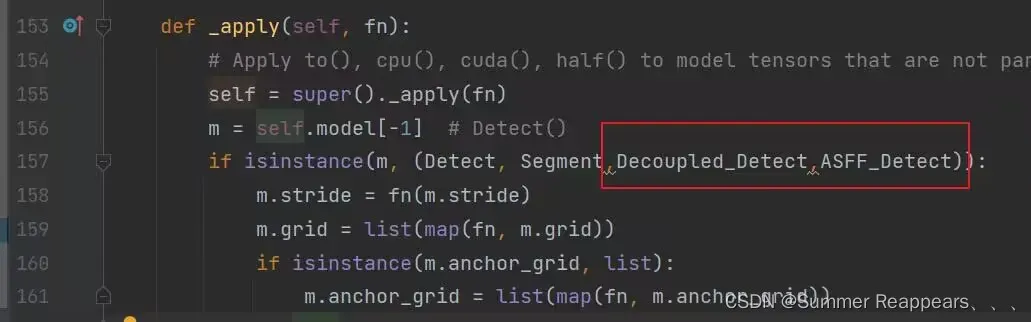
if isinstance(m, (Detect, Segment,Decoupled_Detect,ASFF_Detect)):2) 在这里添加红框中的代码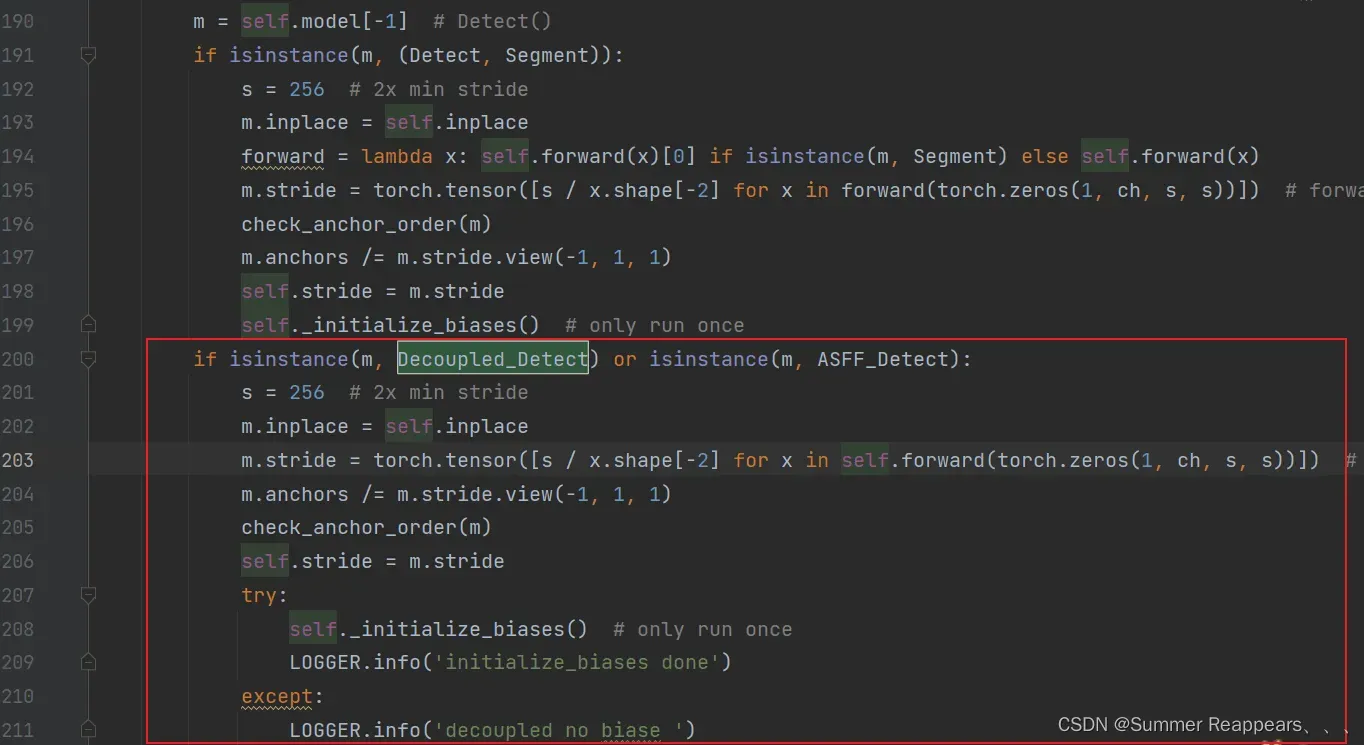
if isinstance(m, Decoupled_Detect) or isinstance(m, ASFF_Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
try:
self._initialize_biases() # only run once
LOGGER.info('initialize_biases done')
except:
LOGGER.info('decoupled no biase ')3)这里添加红框代码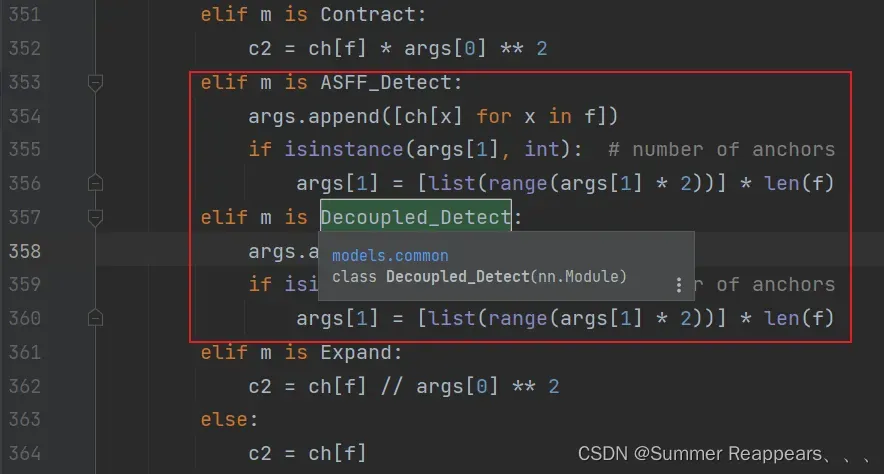
elif m is ASFF_Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Decoupled_Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)三、配置文件
只需要更改最后一层的Detect,使用解耦头的时候用 Decoupled_Detect,使用ASFF的时候用ASFF_Detect
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5),解耦
]
我在电脑上可以运行,有什么错误可以在评论区指出
文章出处登录后可见!
已经登录?立即刷新