1.Yolov8介绍
Ultralytics YOLOv8 是由 Ultralytics 开发的一个前沿的 SOTA 模型。它在以前成功的 YOLO 版本基础上,引入了新的功能和改进,进一步提升了其性能和灵活性。YOLOv8 基于快速、准确和易于使用的设计理念,使其成为广泛的目标检测、图像分割和图像分类任务的绝佳选择。
YOLOv8 算法优化点:
-
提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求;
-
将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构;
-
Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
-
Loss 采用 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
-
引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
-
github: GitHub – ultralytics/ultralytics: NEW – YOLOv8 🚀 in PyTorch > ONNX > CoreML > TFLite
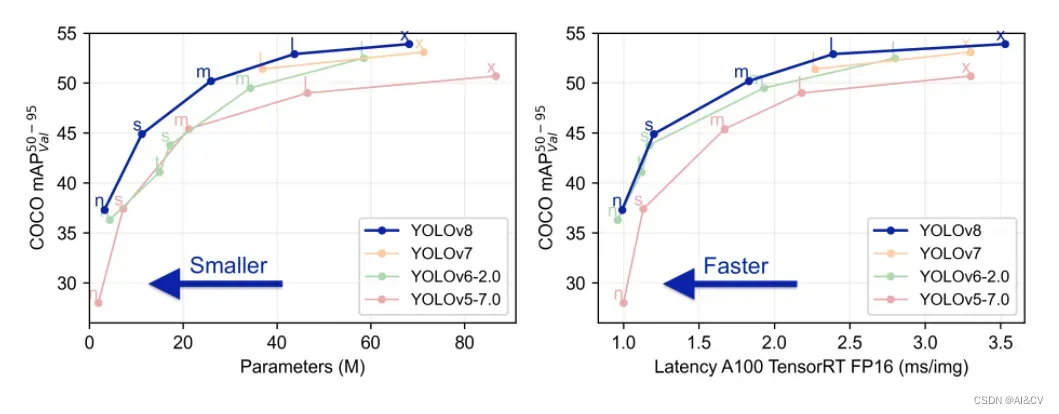
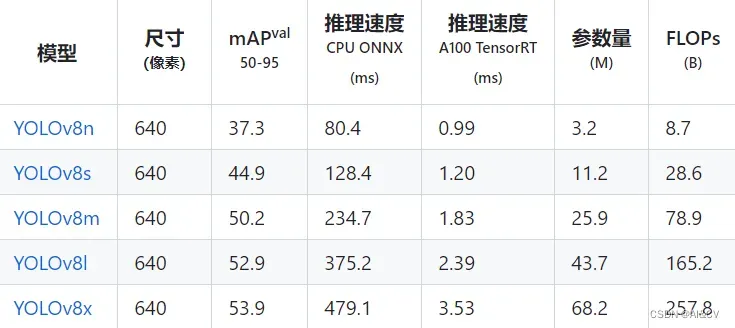
可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少
2.用自己的数据集训练yolov8
选择道路缺陷数据集作为本文数据集
缺陷类型:crack
数据集数量:195张
标记后的文件夹如下
2.1 通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close() 
2.2 通过voc_label.py得到适合yolov5训练需要的
将xml文件转换成YOLO系列标准读取的txt文件:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["crack"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()最终得到
2.3 配置 ultralytics/datasets/crack.yaml
path: D:/ultralytics-main/data/crack # dataset root dir
train: train.txt # train images (relative to 'path') 118287 images
val: val.txt # val images (relative to 'path') 5000 images
# number of classes
nc: 1
# class names
names:
0: crack2.4默认参数开启训练
yolo task=detect mode=train model=yolov8n.yaml data=ultralytics/datasets/crack.yaml3.测试效果
yolo5n map 0.748
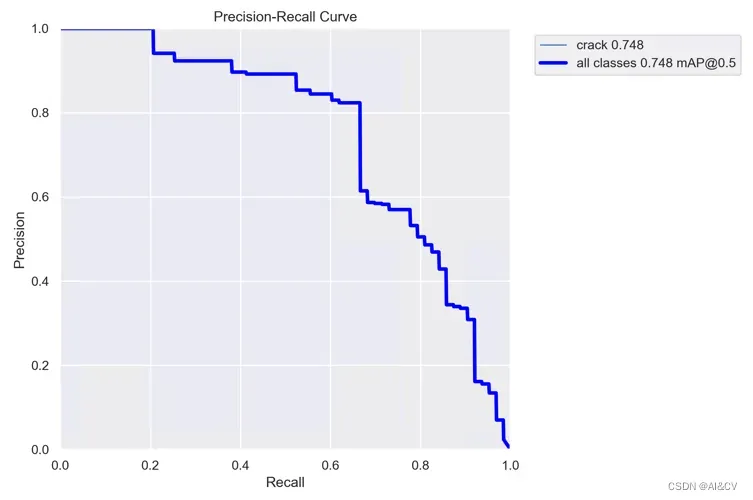

文章出处登录后可见!