查看缺失值
使用DataFrame对象的info()方法
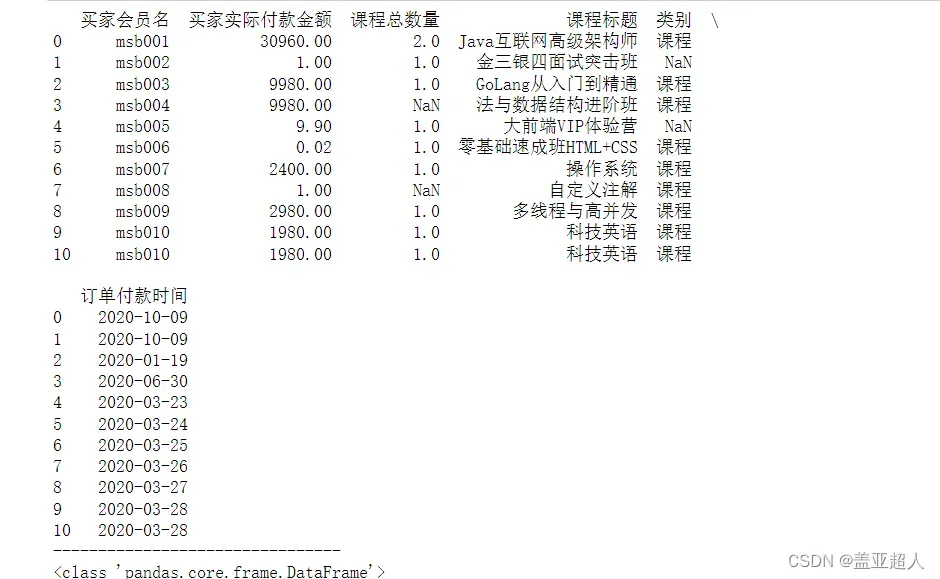
注:NaN为空缺值
查看是否有缺失值
print(df.info()) # 查看是否有缺失值 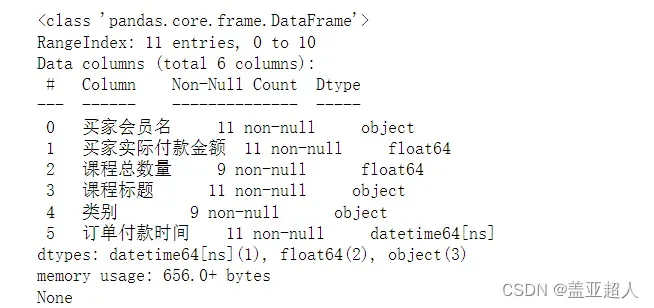
Non-Null Count列显示的是每个索引中不是空缺的个数
判断数据是否存在缺失值
使用DataFrame的isnull()方法和notnull()方法
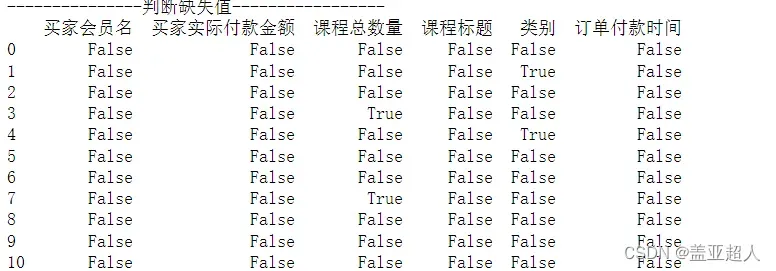
1. isnull()方法——判断是否为空,输出结果为True和False,不为NaN时返回False,为NaN时返回True。
print(df.isnull()) # 结果为True或False, 不为NaN时为False
2. notnull()方法——判断是否不为空,输出结果也是True和False,为NaNcy时返回False,不为NaN时返回True。
print(df.notnull()) # 不为NaN时为True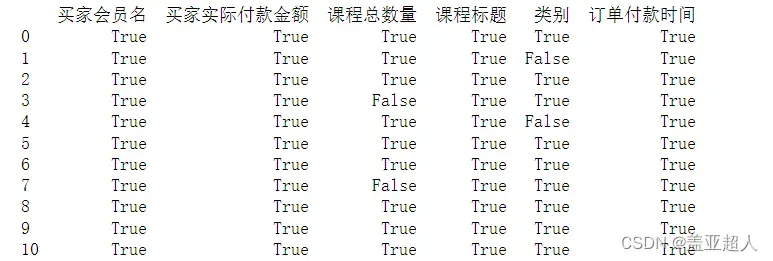
缺失值的处理方式
1.不处理
有的数据空着也不影响整体,所以就放那吧。。。。。
2.删除
可以使用dropna()函数,这个函数比较狂野,只要有一有个数据时空缺的,就会把整行删除
df = df.dropna() #将所有含空缺值的行都删除3.填充或替换
df['课程总数量'] = df['课程总数量'].fillna(0) # 把‘课程总数量’中为空的值填充为0,并赋值给‘课程总数量’
print(df)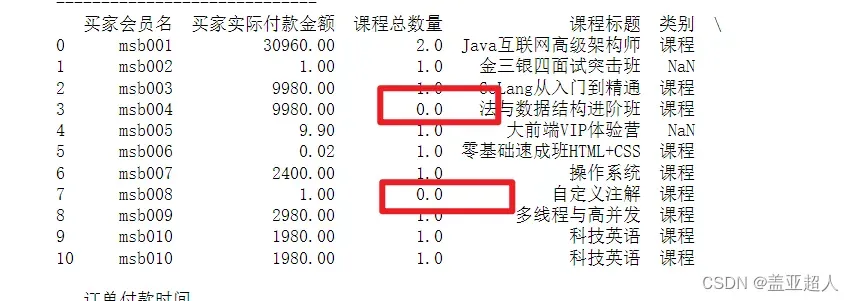
重复值处理
删除呗,见Pandas基本操作——增加、修改和删除
# 判断是否存在重复值, 值为True说明为重复值
print(df.duplicated())
print('---------------------------')
# 删除全部重复值
print(df.drop_duplicates())
# 删除指定列的重复数据,,,保留重复行的最后一行
print('---------删除指定列的重复数据---------')
print(df.drop_duplicates(['买家实际付款金额'],keep='last')) # 删除重复数据中的最后一条
# 直接删除,保留一个副本
df1 = df.drop_duplicates(['买家实际付款金额'],inplace=False)
print(df1)
———————————–算是对今天学的东西的总结了—————————–
文章出处登录后可见!
已经登录?立即刷新