实验名称: 实验5 应用sklearn分析竞标数据 实验时间: 2023-04-26
(gcc的同学不要抄袭呀!)
一、实验目的
1、掌握skleam转换器的用法。
2、掌握训练集、测试集划分的方法。
3、掌握使用sklearm进行PCA降维的方法。
4、掌握 sklearn 估计器的用法。
5、掌握聚类模型的构建与评价方法。
6、掌握分类模型的构建与评价方法。
7、掌握回归模型的构建与评价方法。
二、实验内容
任务1:使用sklearn处理竞标行为数据集。
**要求任务的源代码文件名为:实验5-1,并在源代码的起始位置输出自己真实的学号、姓名和班级信息。**
1、需求说明
竞标行为数据集(shill bidding.csv)是网络交易平台eBay为了分析竞标者的竞标行为而收集整理的部分拍卖数据,包括记录ID、竞标者倾向、竞标比率等11个输入特征和I个类别标签,共6321条记录,其特征/标签说明如表6-18所示。通过读取竞标行为数据集,进行训练集和测试集的划分、为后续的模型构建提供训练数据和测试数据;并对数据集进行降维,以适当减少数据的特征维度。
2、实现思路与步骤
(1)使用pandas库读取竞标行为数据集。
(2)对竞标行为数据集的数据和标签进行划分。
(3)将竞标行为数据集划分为训练集和测试集,测试集数据量占总样本数据量的20%。
(4)对竞标行为数据集进行PCA降维,设定n-components=0.999、即降维后数据能保留的信息为原来的99.9%、并查看降维后的训练集、测试集的大小
截图: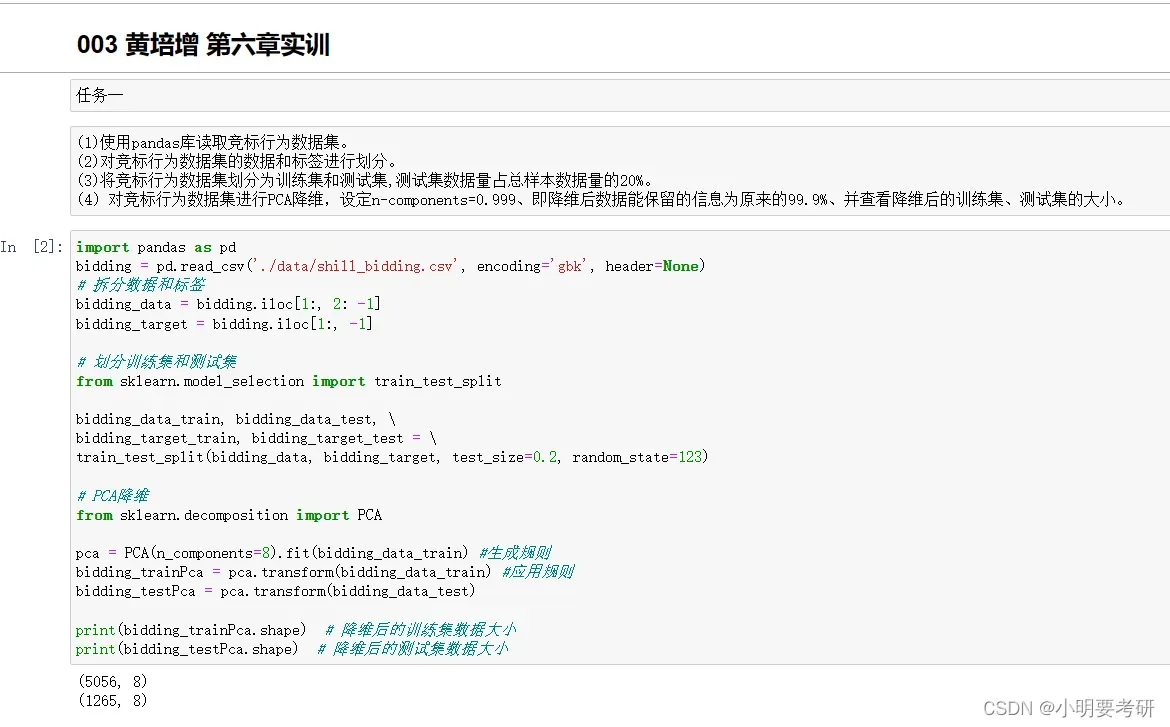
任务2:构建基于竞标行为数据集的K-Means聚类模型。
要求任务的源代码文件名为:实验5-2,并在源代码的起始位置输出自己真实的学号、姓名和班级信息。
1、需求说明
使用实训1中的竞标行为数据集,竞标行为标签总共分为2种(0表示正常竞标行为,1表示非正常竟标行为)为了通过竞标者的行为特征将竞标行为划分为簇,选择数据集中的竞标者倾向、竞标比率,连续竞标3个特征,构建K-Means模型,对这3个特征的数据进行聚类,聚集为2个族,实现竞标行为的类别划分,并对聚类模型进行评价,确定最优聚类数目。
2、实现思路与步骤
(1)选取竟标行为数据集中的竞标者倾向、竞标比率、连续竞标、类别特征。
(2)构建K-Means模型。
(3)使用ARl评价法评价建立的 K-Means模型。
(4)使用V-measure评分评价建立的K-Means模型。
(5)使用FMI评价法评价建立的 K-Means模型,并在聚类数目为1-3类时,确定最优聚类数目。
###代码截图如下:
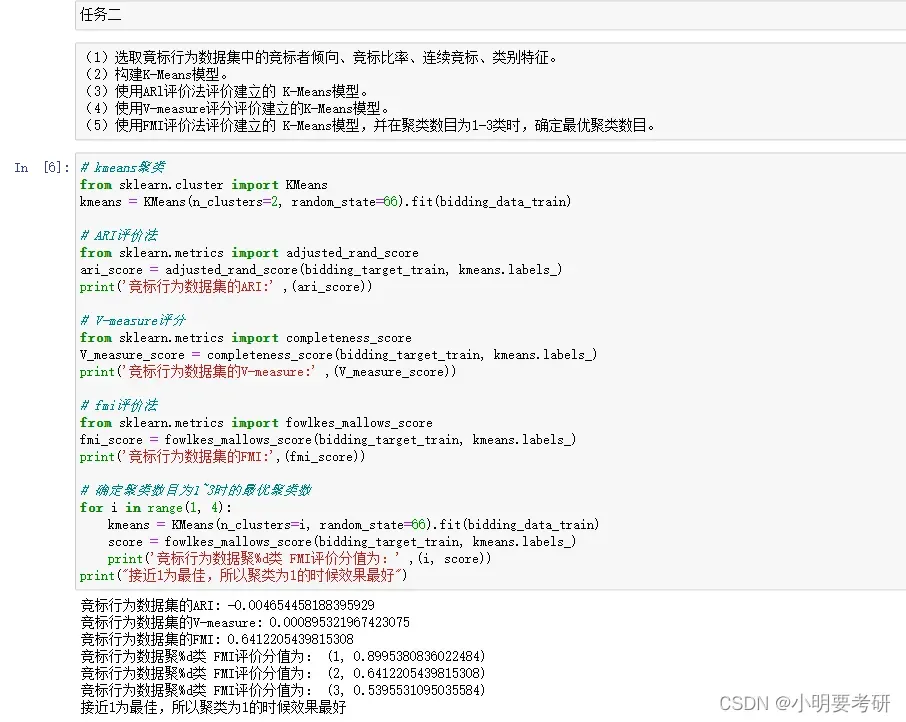
代码:
import pandas as pd
bidding = pd.read_csv('./data/shill_bidding.csv', encoding='gbk', header=None)
# 拆分数据和标签
bidding_data = bidding.iloc[1:, 2: -1]
bidding_target = bidding.iloc[1:, -1]
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
bidding_data_train, bidding_data_test, \
bidding_target_train, bidding_target_test = \
train_test_split(bidding_data, bidding_target, test_size=0.2, random_state=123)
# PCA降维
from sklearn.decomposition import PCA
pca = PCA(n_components=8).fit(bidding_data_train) #生成规则
bidding_trainPca = pca.transform(bidding_data_train) #应用规则
bidding_testPca = pca.transform(bidding_data_test)
print(bidding_trainPca.shape) # 降维后的训练集数据大小
print(bidding_testPca.shape) # 降维后的测试集数据大小
# kmeans聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=66).fit(bidding_data_train)
# ARI评价法
from sklearn.metrics import adjusted_rand_score
ari_score = adjusted_rand_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的ARI:' ,(ari_score))
# V-measure评分
from sklearn.metrics import completeness_score
V_measure_score = completeness_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的V-measure:' ,(V_measure_score))
# fmi评价法
from sklearn.metrics import fowlkes_mallows_score
fmi_score = fowlkes_mallows_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据集的FMI:',(fmi_score))
# 确定聚类数目为1~3时的最优聚类数
for i in range(1, 4):
kmeans = KMeans(n_clusters=i, random_state=66).fit(bidding_data_train)
score = fowlkes_mallows_score(bidding_target_train, kmeans.labels_)
print('竞标行为数据聚%d类 FMI评价分值为:' ,(i, score))
print("接近1为最佳,所以聚类为1的时候效果最好")
好了,剩下的实训三和实训四后面补上,也可以加我微信交流哦,bmt1014

文章出处登录后可见!