微调:
共同训练新添加的分类器和部分或者全部卷积层,这允许我们微调基础模型中的高阶特征表示,一是他们与特定任务相关。
只有分类器训练好了(就是Linear层),才能微调卷积基,不然刚开始训练误差很大,微调之前的卷积层学到的东西会被破坏。
步骤:
1. 在预训练卷积基添加自定义层
2. 冻结卷积基
3. 训练添加的分类层
4. 解冻卷积基的一部分也可以解冻全部(一般解冻靠近输出部分的卷积基)
5. 联合训练整个模型
迁移学习的一般步骤: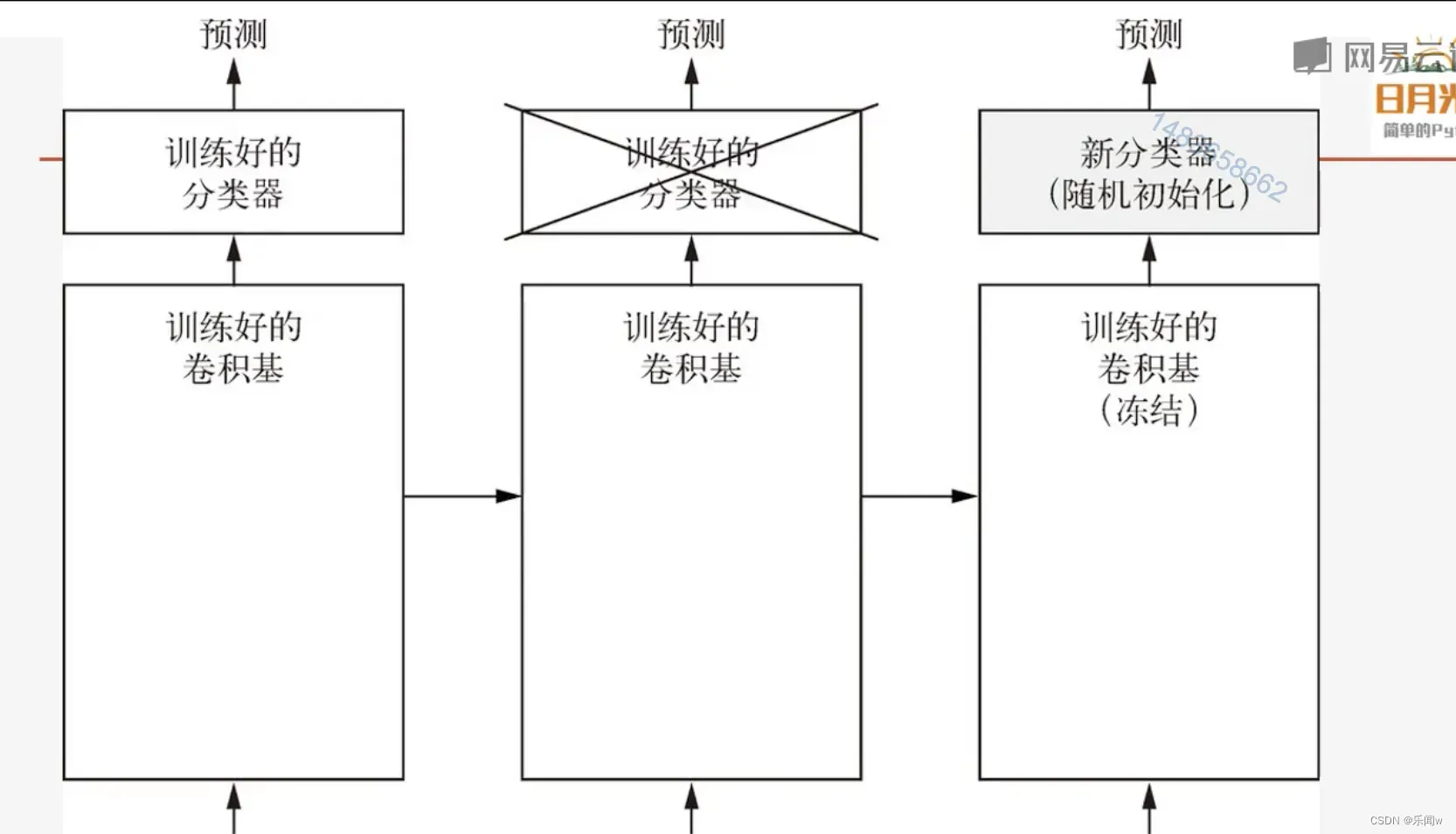
代码:
"""使用Resnet模型预训练模型+微调"""
import torch.cuda
import torchvision
from torch import nn
import os
from torchvision import transforms
# import matplotlib.pyplot as plt
#预处理数据
base_dir = r'./dataset/4weather'
train_dir = os.path.join(base_dir,'train')
test_dir = os.path.join(base_dir,'test')
train_transformer = torchvision.transforms.Compose(
[ transforms.Resize((224,224)),
transforms.RandomCrop((192,192)),
transforms.ColorJitter(brightness=0.4),
transforms.RandomHorizontalFlip(0.2),
transforms.ColorJitter(contrast=4),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
]
)
test_transformer = torchvision.transforms.Compose([
transforms.Resize((192,192)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])
#创建dataset
train_ds = torchvision.datasets.ImageFolder(
train_dir,
transform = train_transformer
)
test_ds = torchvision.datasets.ImageFolder(
test_dir,
transform =test_transformer
)
#创建dataloader
batch = 8
train_dl =torch .utils.data.DataLoader(
train_ds, batch_size = batch,
shuffle = True
)
test_dl = torch.utils.data.DataLoader(
test_ds,
batch_size = batch)
imgs,labels =next(iter(train_dl))
#加载模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = torchvision.models.resnet18().to(device)
for param in model.parameters():
param.requires_grad = False
#只需要将全链接层分类类别数进行更改
in_f= model.fc.in_features
#替换掉了全链接层 是可训练
model.fc = nn.Linear(in_f, 4)
#优化器只需要优化最后一层
optim =torch .optim.Adam(model.fc.parameters(),lr =0.001)
#损失函数
loss_fn = nn.CrossEntropyLoss()
#训练函数fit 必须要指定 model.train,model.eval Resnet中有BN层
def fit(epoch,model,trainloader,testloader):
correct = 0
total = 0
running_loss =0
model.train() #指明这是train模式需要bn和drop
for x,y in trainloader:
if torch.cuda.is_available():
x,y =x.to('cuda'),y.to('cuda')
y_pred =model(x)
loss = loss_fn(y_pred,y)
optim.zero_grad()
loss.backward()
optim.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred,dim=1)
correct +=(y_pred==y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss/len(trainloader.dataset)
epoch_acc =correct/total
test_correct = 0
test_total = 0
test_running_loss =0
model.eval()
with torch.no_grad():
for x,y in testloader:
if torch.cuda.is_available():
x,y = x.to('cuda'),y.to('cuda')
y_pred =model(x)
loss = loss_fn(y_pred,y)
y_pred = torch.argmax(y_pred,dim=1)
test_correct +=(y_pred==y).sum().item()
test_total +=y.size(0)
test_running_loss +=loss.item()
epoch_tst_loss =test_running_loss/len(testloader.dataset)
epoch_tst_acc = test_correct/test_total
print('epoch',epoch,'loss',round(epoch_loss,3),
'acc:',round(epoch_acc,3),
'test_loss:',round(epoch_tst_loss,3),
'test_acc:',round(epoch_tst_acc,3))
return epoch_loss ,epoch_acc,epoch_tst_loss,epoch_tst_acc
# epochs =5
# train_loss =[]
# train_acc =[]
# test_loss =[]
# test_acc=[]
#
# for epoch in range(epochs):
# epoch_loss,epoch_acc,epoch_tst_loss,epoch_tst_acc =fit(epoch,model,train_dl,test_dl)
# train_loss.append(epoch_loss)
# train_acc.append(epoch_acc)
# test_loss.append(epoch_tst_loss)
# test_acc.append(epoch_tst_acc)
#绘制图像:
# plt.plot(range(1,epochs+1),train_loss,label='train_loss')
# plt.plot(range(1,epochs+1),test_loss,label = 'test_loss' )
# plt.legend()
# plt.show()
# #微调
for param in model.parameters():
param.requires_grad=True
extend_epoch =8
#微调的时候学习速率要更小一些
optimizer = torch.optim.Adam(model.parameters(),lr=0.00001)
#
# #训练过程
train_loss =[]
train_acc =[]
test_loss =[]
test_acc=[]
for epoch in range(extend_epoch):
epoch_loss,epoch_acc,epoch_tst_loss,epoch_tst_acc =fit(epoch,model,train_dl,test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_tst_loss)
test_acc.append(epoch_tst_acc)文章出处登录后可见!
已经登录?立即刷新