在强化学习中,epsilon-greedy可以说是非常基础的一个探索利用算法。应用十分广泛。尝试进行平衡的探索-利用方法。
在Epsilon-Greedy策略中,一个agent会以概率epsilon随机选择行动,也就是进行探索。此外以1-epsilon的概率选择当前估计的最佳行动,也就是利用 。
具体来说,如果epsilon=0,则代理总是选择当前估计的最佳行动;如果epsilon=1,则代理总是随机选择行动;在介于0和1之间的情况下,代理在每个时间步以概率epsilon随机选择行动,以概率1-epsilon选择当前估计的最佳行动。
Epsilon-Greedy的目的是在探索(尝试新的行动)和利用(选择当前估计的最佳行动)之间达到平衡。当代理刚开始学习时,它需要探索环境以找到最佳策略,这时epsilon应该设置为较高的值,以使代理更多地尝试不同的行动。随着代理的学习,它需要利用已知的知识来最大化奖励,此时epsilon应该设置为较低的值,以使代理更多地选择当前估计的最佳行动。
总的来说,Epsilon-Greedy是一种简单而有效的行动选择策略,可以平衡探索和利用之间的权衡,并在强化学习任务中表现良好。
在此,我们以强化学习中最基础最开端的多臂老虎机来做一个例子,代码如下:
import numpy as np
import matplotlib.pyplot as plt
class MultiArmedBandit:
def __init__(self, num_arms, mu=0, sigma=1):
self.num_arms = num_arms
self.mu = mu
self.sigma = sigma
self.action_values = np.random.normal(self.mu, self.sigma, self.num_arms)
def get_reward(self, action):
reward = np.random.normal(self.action_values[action], self.sigma)
return reward
class EpsilonGreedy:
def __init__(self, num_actions, epsilon=0.1):
self.num_actions = num_actions
self.epsilon = epsilon
self.action_values = np.zeros(num_actions)
self.action_counts = np.zeros(num_actions)
def select_action(self):
if np.random.uniform() < self.epsilon:
# 随机选择行动
action = np.random.randint(self.num_actions)
else:
# 选择具有最高价值的行动
action = np.argmax(self.action_values)
self.action_counts[action] += 1
return action
def update_action_value(self, action, reward):
self.action_values[action] += (reward - self.action_values[action]) / self.action_counts[action]
# 模拟多臂老虎机
num_arms = 10
num_steps = 1000
num_trials = 1000
eps = 0.1
avg_rewards = np.zeros(num_steps)
for i in range(num_trials):
bandit = MultiArmedBandit(num_arms)
agent = EpsilonGreedy(num_arms, epsilon=eps)
rewards = np.zeros(num_steps)
for t in range(num_steps):
action = agent.select_action()
reward = bandit.get_reward(action)
agent.update_action_value(action, reward)
rewards[t] = reward
avg_rewards += (rewards - avg_rewards) / (i+1)
# 绘制结果
plt.plot(avg_rewards)
plt.xlabel('Steps')
plt.ylabel('Average Reward')
plt.title('Epsilon-Greedy Bandit')
plt.show()在这个模拟中,我们首先定义了一个MultiArmedBandit类来表示多臂老虎机。在初始化函数中,我们设置了臂数和每个臂的均值和标准差,通过随机生成的方式给每个臂赋予不同的奖励期望。
然后我们定义了一个EpsilonGreedy类,其中包含了选择行动和更新行动价值的方法。在初始化函数中,我们设置了行动数和epsilon值,并将所有行动的估计价值和选择次数初始化为0。
在模拟中,我们通过循环多次试验,每次试验随机生成一个新的多臂老虎机,并使用Epsilon-Greedy策略选择行动,计算每个步骤的平均奖励。最后,我们计算所有试验的平均奖励,并绘制出结果图。
在实际使用中,需要根据任务和代理的特定要求,对epsilon的值进行调整,以达到最佳的性能和
最佳策略。较小的epsilon值会导致代理更多地选择已知的最佳行动,但可能会错过发现更优行动的机会;较大的epsilon值会导致代理更多地尝试未知的行动,但可能会导致代理的行动选择不够理智。
在上面的代码示例中,我们使用了一个较小的epsilon值(0.1),这意味着代理有10%的概率随机选择行动,而有90%的概率选择当前估计价值最高的行动。在多次试验中,我们观察到代理逐渐学习到哪些行动是最有利的,并开始偏向于选择这些行动。结果显示出代理在学习期间的初始探索阶段和稳定的利用阶段。
运行后我们得到如下结果:
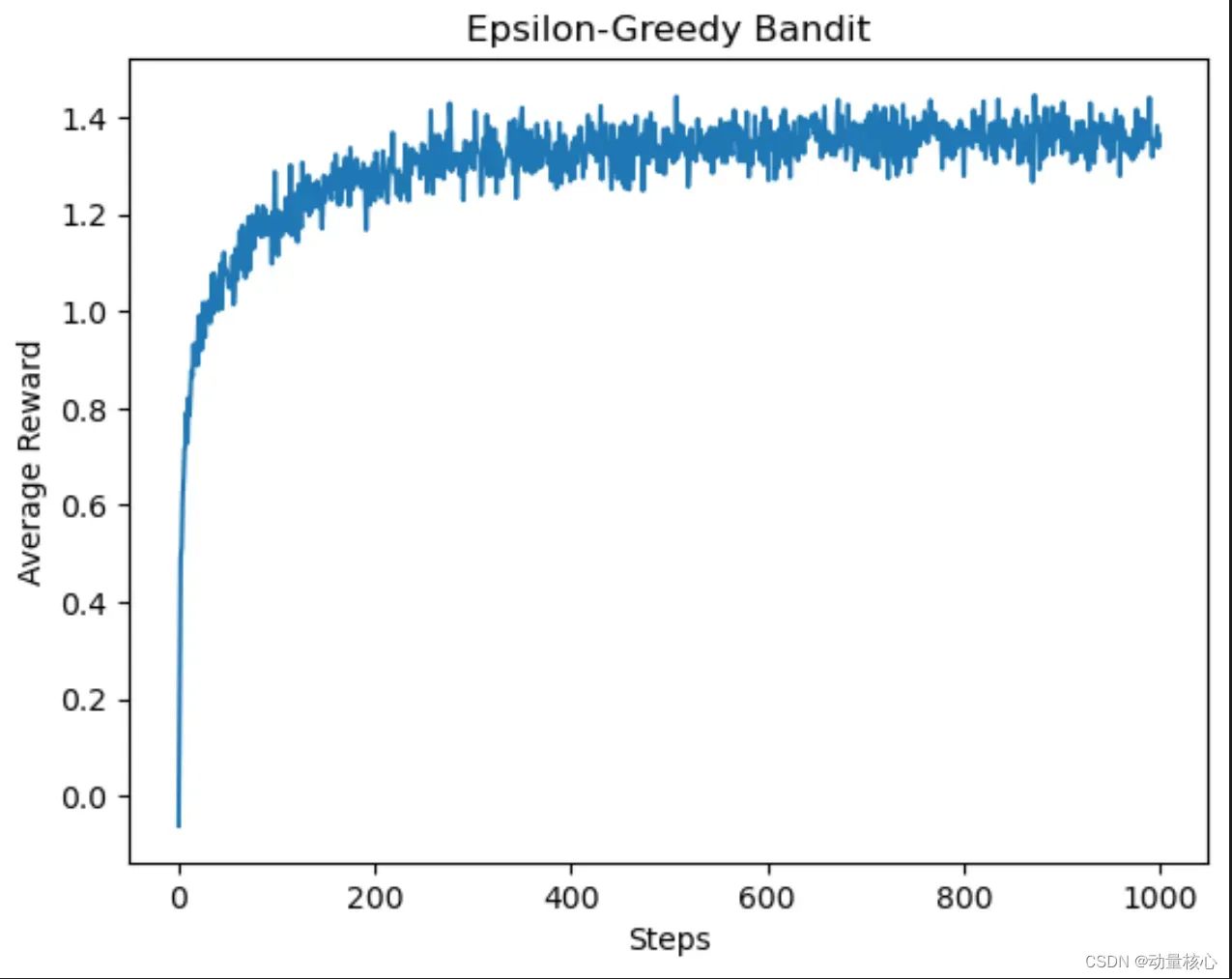
对此我们可以看到,伴随着试验次数的增多,我们获得的最大回报也会增多。其实意味着我们对多臂老虎机中的概率分布获得了一个比较好的期望,于是我们每次拉下那个期望比较高的老虎机手臂,于是我们就可以获得更高的一个回报。
在开始阶段,我们不知道每个老虎机的回报期望,因此,我们更多的去进行探索,通过探索的次数越来越多,我们对老虎机的回报预估的越来越准,于是我们更多的选择期望高的老虎机进行操作,由此获得的回报越来越高。
文章出处登录后可见!