
来源|Latent Space
OneFlow编译
翻译 | 杨婷、宛子琳
如果 AI 如此重要,那么为什么软件如此糟糕?
创办 Modular 之前,这是让 LLVM 之父 Chris Lattner 困扰已久的问题。随后,他与 TensorFlow 的前产品同事 Tim Davis 合作研究模块化解决方案,以解决人工智能开发中庞大、单一、分散的平台问题。2022 年,他们以 3000 万美元的种子资金启动 Modular ,继今年 5 月成功推出 AI 引擎 Modular 与编程语言 Mojo,不久前又获得 1 亿美元的 A 轮融资。
尽管 Mojo 以其多线程编译的 Python 超集和出色的性能受到瞩目,但这只是一个副业项目,而 Modular 的 Python 推理引擎的愿景同样宏大。
Chris在编译器方面的成就卓著。他在博士期间开发了 LLVM,并因此获得了 2012 年 ACM 软件系统奖。随后,他加入苹果,创建了 Clang 和 Swift(取代 Objective-C 的 iPhone 编程语言)。之后,他在 Google 带领 TensorFlow 基础设施团队,并开发了 XLA 编译器以及 MLIR 编译器框架,这时,他的任务不是建立一套最适用于 AI 的编译器,而是为 TPU 构建最佳的编译器,以便所有 TensorFlow 用户都能在 Google Cloud 上获得良好的体验。
在他看来,Meta 的 PyTorch 团队也并非在改善所有领域的 AI 性能,而是主要服务于他们的推荐和广告系统。Chris 和 Tim 意识到,大型科技公司并没有将 AI 引擎和开发者体验作为优先考虑的产品,因此,他们认为,Modular 是交付未来的 AI 开发平台的最佳方式。
尽管 Chris 是业内公认的顶级编译器工程师,但他并没有将编译器方法简单地应用到 Python 上,相反,他选择了与此完全不同的方法。
Modular 的最初目标是构建“统一的 AI 引擎”,以加速 AI 的开发和推理。与 GPU 即是一切的 AI 世界不同,在那里只有“富有 GPU 资源”的人才能受益,而 Modular 将 AI 视为一个大规模、异构化、并行计算的问题。他们希望以一种更加广泛和包容的方式来运行 AI,不仅仅依赖于 GPU ,而是探索利用多种计算资源,以满足不同应用、不同环境和不同需求下的 AI 计算需求。
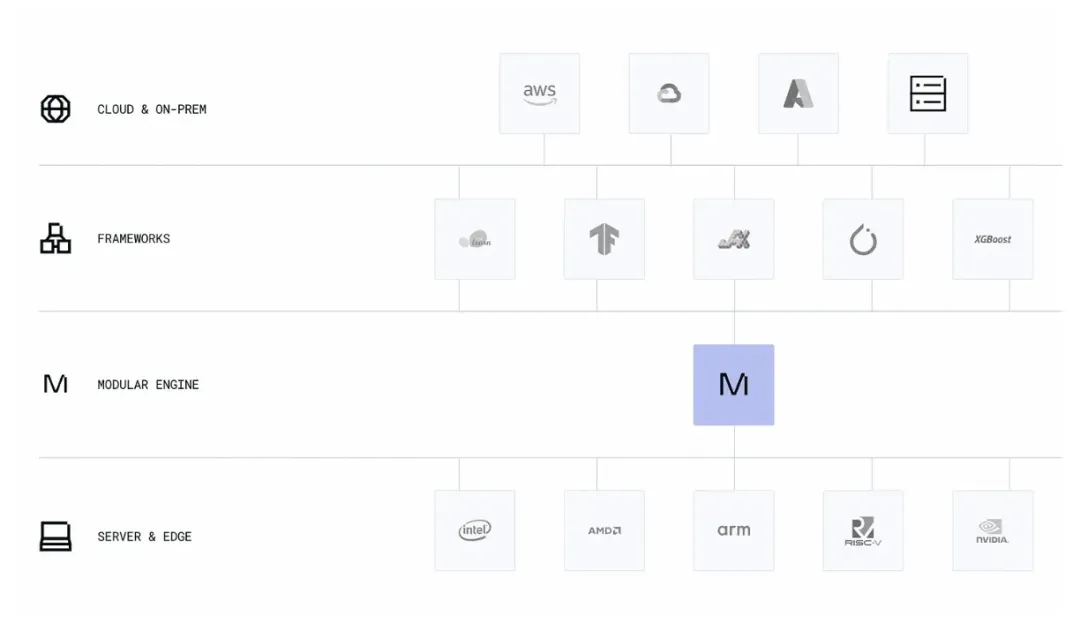
作为一个独立的 AI 引擎,Modular 可以在 CPU 上运行所有其他框架,相比原本的性能,它可以将这些框架的速度提升 10% 至 650%( 即将支持 GPU)。
Mojo 是 Modular 的一部分,它是一种全新的 AI 编程语言,是 Python 的超集,它最初作为一种内部 DSL 来提高团队的工作效率而创建。
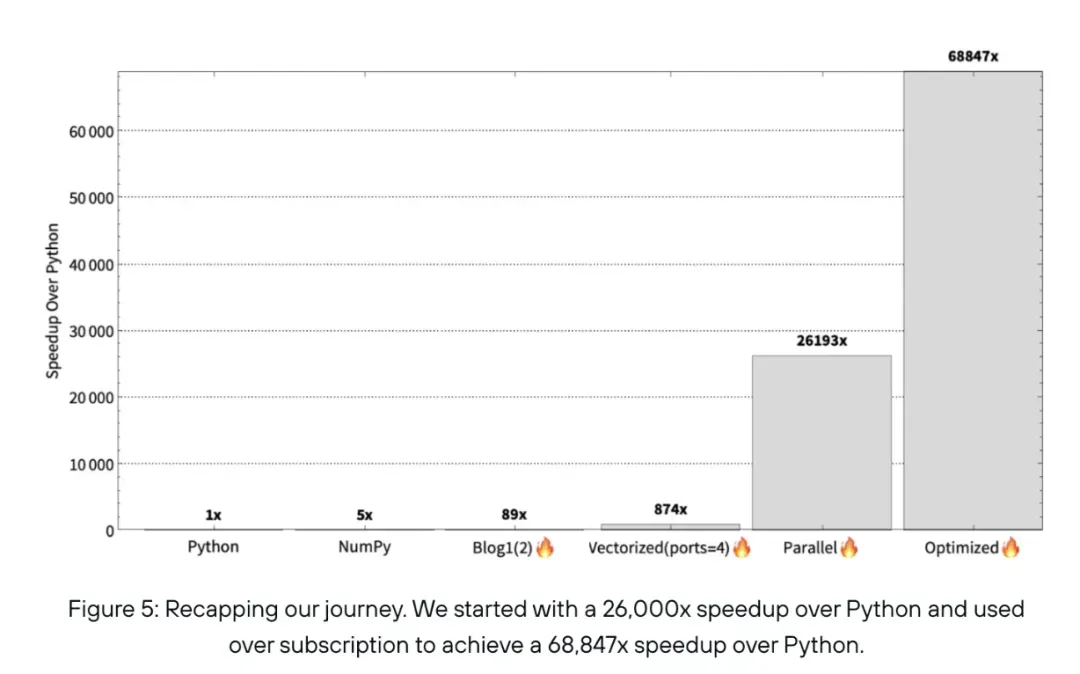
Mojo 采用了 Python 的语法,同时,它还支持所有现有的 PyPi 包,开发者从 Python 切换到 Mojo 不需要进行任何代码更改。在性能上,Mojo 相比 Python 的运行速度最高快约 68000 倍,而大多数 Python 代码库只需进行很小的调整,转换到 Mojo 后其运行速度就可以提高 10 到 100 倍。
Modular 团队正在进行一项艰巨的技术挑战。在 Latent Space 的最新一期播客中,Chris Lattner 解释了他为何开发 Modular 与 Mojo,并分享了他所看到的 AI 基础设施软件发展的挑战和未来。
(本文经授权后由OneFlow编译发布,转载请联系授权。原文:https://www.latent.space/p/modular#details)
1
统一的 AI 引擎平台
Alessio:Modular 的目标是构建一个统一的 AI 引擎,这意味着AI 引擎面临的情况是碎片化的。从源头出发,在 AI 研究和开发领域,需要解决问题有哪些?
Chris:虽然 AI 发展的状况大家有目共睹,但回顾 2015年-2017 年,对于那些追随者来说,AI 领域的发展确实令人惊叹。那个时代的技术主要由 TensorFlow 和 PyTorch 驱动,虽然 PyTorch 稍晚一些出现,但它们在某些方面的设计有点相似。
其中的挑战在于,构建这些系统的人主要专注于人工智能、研究、微分方程、自动微分等各个方面,并没有考虑解决软硬件边界问题。因此,他们认为需要一种方法来让人们设置层,类似于 Keras 或 NNModule。
在底层,这些被称为算子(operator)的部件起到了作用,因此会得到不同类型的操作,如卷积、矩阵乘法、归约和逐元素操作,那么如何实现这些操作?可以使用 CUDA 和英特尔的数学库(如Intel MKL)进行构建。
起初看起来不错,即使只是推出一个新的 Intel CPU 型号,也只能得到很有限的算子。然而现在 TensorFlow 和 PyTorch 已经拥有数千个算子。结果就是每个算子都会有对应的 kernel,这通常由人工手动编写。因此,当引入一款新的硬件时,就需要复现成千上万个 kernel,这使得人们进入硬件领域变得十分困难。
另一方面,只有少数人知道这些 kernel 如何运行,而且要掌握这些技能与创新模型架构所需的技能截然不同,因此不便展开研究。
当我参与 Google TPU 的开发工作时,最初的目标主要是激励和推动大量的研究。在我加入之前,已经有人提出了一个新颖的思路,那就是使用编译器进行处理,而非手动编写成千上万个 kernel,并重新编写所有算子,试图做到英特尔或者 NVIDIA 那样。
相比之下,编译器具有更强的可扩展性和通用性,它能以不同的方式组合 kernel,这其中还有许多重要的优化技术,包括可以大幅减少内存流量的 kernel 融合。如果使用传统的手写 kernel,得到的是人们认为有趣的特定组合,而不是研究人员接下来想要研究的新事物,但很多研究都在尝试探索新的领域。
因此,我们押注在编译器上,开发了 XLA 系统,它是 Google 堆栈的一部分,它使得数十亿亿次规模的超级计算机成为可能,并且在此基础上展开了许多令人惊叹的工作。但最大的问题是,它最初是为了支持硬件如 Google TPU 而开发。
现在就需要雇佣编译器工程师,而熟悉机器学习和所有这些领域的编译器工程师更是凤毛麟角。从技术角度出发,如果你在 Google 工作并且可以访问相关硬件,就可以对其进行扩展,否则就会面临真正的挑战。
因此,我特别喜爱 NVIDIA 平台的一个原因是,虽然人们对 CUDA 抱有各种不满,但如果我们回顾 AI 起飞的那个时刻,如深度学习与 AlexNet 的结合,很多人将这个时刻归功于两个因素:数据(如 ImageNet)和计算能力(强大的 GPU)的结合,这才使得 AlexNet 的诞生成为可能。
然而,他们经常忽略了第三个因素,即可编程性。正是因为 CUDA 使研究人员能够创造出之前不存在的卷积 kernel。当时还没有像 TensorFlow 这样的框架,也没有如今的丰富工具。实际上,正是数据、计算能力和可编程性三位一体,才开启了一种新的研究范式,形成了整个深度学习系统的浪潮。
因此,我们必须借鉴历史经验,采用模块化的思路,思考如何迈向下一个时代。如何获得人们在算法创新、思想、稀疏性等方面的惊人优势,以及那些研究边缘中可能相关的思想。我们应该如何充分发挥编译器的优势?编译器具有广泛的适用性和强大的可扩展性,能够处理新问题。最后,我们要如何充分发挥可编程性的优势,将所有这些因素融合在一起?
Alessio:记得你提过,那些对某些领域不熟悉,无法做出贡献的人会被甩在身后,而 CUDA 在这方面做得很棒。对于类似后模块化世界中的 AI 开发,你有什么看法?
Chris:我的信念是人类很了不起,但我们无法将所有知识都记在脑中,人们各有所长,如果能让他们协同合作,并理解这些架构的内部原理,就能创造出超越个体能力的成果,实现新的突破。
我认为,关键在于如何促进良性循环,如何推动创新?如何让更多了解问题的不同领域的人切实展开合作?这就是为何我们在 Mojo 和 AI 引擎方面的工作如此重要,我们真正致力于消除这个问题的复杂性。
许多已构建的系统只是简单地聚合在一起,这就好比一个有用的工具可以帮助我解决问题,然而,它们并没有从上到下经过精心设计。我认为,模块化提供了一个更简单、更正交、更一致、更有原则的堆栈,使得我们能够消除整个堆栈的复杂性。但如果你的工作建立在所有这些碎片化的历史基础设施之上,就只能自求多福。
此外,尤其很多 AI 研究系统都存在这种预设路径,只有按照准确的演示步骤,才能正常运行。一旦稍作改变,一切就会崩溃,性能会下降甚至停止工作。这就是底层碎片化的产物。
Swyx:所以,编译器和语言是人类可以进行合作或跨界的媒介。
Chris:我从事编译器方面的工作已有很长时间,但我们要从问题出发,如果编译器或编译器技术有助于解决问题,就可以使用,不能本末倒置。
你可能会问,编译器有何用处?它的根本目的是什么?这在于你不需要过多地了解硬件。你可以为每个问题编写十分底层的汇编代码,但是编译器、编程语言或者 AI 框架的真正作用是让你能够以更高的抽象级别表达事物,且这一目标具有多重功能。
其中一个目标是,让一切变得更容易,另一个目标则是,如果你能够剔除大量无关的复杂性,就会为新的复杂性腾出空间。因此,这实际上是减少非核心复杂性,使你能够专注于解决问题的本质复杂性。另一个目标是通过抽象化提供更多的可能性,尤其像我们正在构建的现代编译器,它们无限关注细节。
人类不具备这种能力。事实证明,如果你手工编写一堆汇编代码,然后遇到类似的问题,就只需要稍作调整,而无需进行全面的基本原则分析来解决问题,而编译器实际上能够比人类做得更好。
更高级别的抽象还会给你带来其他的能力。我认为,深度学习系统与像 Modular 正在构建的系统非常令人兴奋的一点在于,它已经将计算提升到了图形级别。一旦你将计算从混乱的 for 循环和充斥着分号的代码中分离出来,转换为更具声明性的形式,就可以对计算进行转换。
这是许多人尚未意识到的一点,某种程度上说,在现有系统中实现这一点非常困难。因为抽象化提供的很大一部分能力就是能进行像 Pmap 和 Vmap 这样的操作,即对计算进行转换。而我在 Google 工作期间获得的灵感之一是,可以从最底层开始,从单节点 GPU 机器到集群,再到异步编程,进行诸如此类的大量基础性工作。
当我离开 Google 时,我们已经在 Jupyter Notebook 中使用每秒超过一千亿次的超级计算机进行研究和训练。这在技术方面是一个巨大的飞跃,要归功于很多层次清晰且设计良好的系统,基于许多创新的 HPC 类型硬件以及一系列的突破。因此,我希望看到这项技术得到更广泛地采用、推广并普及,同时也希望它能够解决沿途累积的各种复杂性。
Alessio:你提到框架层和硬件层之间的关系。当你们的 AI 引擎首次发布时,它可以在 A100 上实现多少百万亿次浮点运算(petaflops)的性能,但我发现,你们的官网目前披露却都是关于 CPU 的强大性能信息。
Chris:这正是我们从第一性原理出发开展工作的原因。你必须从头完成所有的工作,如果做得对,就不应跳过任何重要的步骤。很多人认为,如今的 AI 系统就是针对 GPU,都在争论 GPU 的性能,但在我看来,AI 实际上是一个大规模异构的并行计算问题。
因此,AI 的起点通常是数据加载,但 GPU 并不负责加载数据,你必须进行数据加载、预处理、网络传输等一系列工作,然后进行很多矩阵乘等计算。接下来,你还需要进行后处理,并将结果通过网络发送或存储到硬盘上。而事实证明,CPU 是驱动 GPU 所必需的。
同时,当你为加速器准备软件时,会发现自己只是在解决问题的一部分,因为他们只将矩阵乘法或他们认为重要的部分当作问题的重点,所以你构建的系统只能做到芯片能做的一部分。
你从来没有时间去解决真正的主要问题,所以使用像 TensorFlow 或 PyTorch 这样的工具时,你会发现 CPU 的工作在很大程度上是通过 Python 运行的,比如 tf.data 等。这些工具不可编程,不可扩展,在许多情况下速度非常慢,很难进行分布式处理,非常混乱。
因此,现在的 CPU 已经拥有张量核心。它们只是被赋予了一些有趣的名字,类似于 AMX 指令,原因在于以前的 CPU 和 GPU 完全不同。随着时间的推移,GPU 变得更加可编程并更类似于 CPU,而 CPU 则变得更加并行化,我们正处于这种技术的多样化发展过程中。
当我们开始模块化时,如果从技术角度来看待这个问题,那么构建一个通用的架构用处很大,因为可以对其进行专用化。
正如我在对 XLA 和其他一些堆栈的研究中发现,从专用化的架构开始再进行泛化非常困难。此外,实际情况表明,不同的人在 AI 不同方面花费不同的成本,投入不同的领域,但训练扩大了研究团队的规模,推理扩大了产品和用户群的规模以及其他方面。因此,现如今仍有很多推理任务是在 CPU 上完成的。因此,我们应该从 CPU 开始改进其架构。
CPU 也更容易使用,它们不会缺货,并且出于多种其他原因更加容易处理。我们证明了可以构建一个通用架构,在不同加速器系列之间进行扩展。我们还展示了可以处理 Intel、AMD 以及ARM Graviton 等不同类型的处理器,甚至对于 Intel CPU 内部各种奇特组合的情况,也能提供大量支持。
针对不同的向量长度和其他复杂操作,我们可以通过更通用和灵活的编程方法提供优于供应商提供的软件。我们正在针对 GPU 进行针对性开发。你将获益于一个经过深思熟虑、层次清晰,并具备有正确 DNA 的堆栈。因此,随着时间的推移,我们将逐步扩展到不同类型的加速器。
2
构建 AI 引擎的挑战
Alessio:在我看来,CPU 是人们关注的重点,这就是为什么会看到LLAMA.cpp 等各种技术和方法,大多数人认为通过对模型进行量化,使其能够在 CPU 上运行,但你们的想法更加激进,你们是否重新设计了整个引擎?在方法上有何不同?实际构建引擎的挑战是什么?
Chris:模块化的特点之一是,用更困难的方式来获得更好的结果。我们团队中的很多人都参与过各种系统的开发,甚至包括行业中创造出 ONNX Runtime 等一些奇特工具或技术的优秀人才。很多人一直从事不同的系统开发工作,而这些系统的挑战在于,其中许多系统是在五至八年前设计的,随着系统的演变,要进行根本性的改变就变得越来越困难。因此,我们决定从头开始,这样做确实更加困难,但我和团队喜欢构建新事物。
其实 TensorFlow、PyTorch 等所有这些系统仍然使用与 Caffe 相同的线程池(thread pool)。人们普遍认为,这是一个巨大的漏洞,会导致严重的性能问题,使得推理时的延迟变得极其不可预测。针对这一问题,需要做出一系列非常具体的设计选择,使线程池阻塞并保持同步。
就像整个底层的架构出现错误一样。一旦出现这种错误,就无法挽回。因此,我们的线程池假设没有测试可以阻塞。这就需要非常轻量级的线程,直接关系到构建在其上的所有内容。然后会进行到如何表达 kernel,我们仍然希望能够手写 kernel,从 C++ 开始进行原型设计,然后进一步进入 Mojo 阶段。
因此,我们构建了一个非常复杂的自动融合编译器,采用了所有最先进的技术,同时超越了现有技术,因为我们知道用户讨厌静态形状的限制和缺乏可编程性。他们不想仅仅局限于张量,例如,许多 LLM 使用不规则张量等等。
所以你希望做的是,通过第一性原理,可以将在其他系统中所经历和感受到的所有困扰汇总起来,而以往由于进度安排、各种限制等原因,还从未有机会对此做出任何改变。但现在,我们可以构建正确的东西,使其具备可扩展性。这就是我们所采取的方法。
因此,其中很多工作都十分常规,但这是非常深入的设计工程,需要切实了解每个决策的二阶和三阶影响。幸运的是,其中很多内容不再处于研究阶段。
Swyx:你非常注重第一性原理的思考方式,但我认为你的原则与大多数人不同。这些洞察力是你多年来研究大量AI工作的结果,具体是什么呢?
Chris:我不确定自己有一套具体的原则,我们的很多工作是要释放许多硬件的潜力,并以十分易用的方式实现。因此,我们的出发点往往不是启用一个新的功能,而是消除人们难以处理的复杂性,从而达到目标。
所以这不是研究,而是设计和工程。关于这一点,我们追求的也是让任何给定的硬件发挥最大的性能。因此,如果你和一家花费了 2 亿美元购买特定内存大小的 A100 GPU 的 LLM 公司交谈,他们想要的是从那块芯片中获得最大的价值,而不是采用最小公约数的解决方案。
另一方面,许多人希望拥有更高的可移植性、通用性和抽象性。因此,挑战在于如何实现并设计一个系统,在默认情况下获得抽象化,而不放弃全部的性能?那些针对机器学习等类型的编译器系统,实际上已经放弃了全部的性能,它们只是试图在空间中覆盖某一个特点。因此,拥有并为此设计一个系统,对我们当前的工作非常重要。
而在其他方面,则要对用户表示同情,很多对技术痴迷的人忽略了使用技术的人与构建技术的人之间的巨大差异。在开发者工具中,理解使用工具的开发者并不想过多了解技术,这一点非常重要。
在编译器工作中非常有趣的一点是,没有人想要关心编译器。你可能正在开发一个 Mojo 应用程序或 C 应用程序,或者其他类型的应用程序,但你只是希望编译器不会妨碍你,或者在出错时告诉你。只有当编译器变得太慢、出现故障或存在其他问题时,你才会在意它的重要性。
因此,AI 技术也是一样。用户在构建和部署模型时有多少时间被用于与工具的斗争,而不是因为它遇到了特殊情况让你偏离了正轨,然后你会从某个工具中获得一堆令人疯狂的 Python 堆栈跟踪信息。因此,对用户的同情心非常重要,尤其是 AI 基础设施还不够成熟,而同情心从来不是工具构建者的核心价值观之一。
3
Mojo 的诞生
Alessio:迄今为止最容易理解的应该是 Mojo,它是 Python的超集。我确信这并不是一时兴起,你看到了哪些局限性?
Chris:当我们展开 Modular 项目时,当时并没有打算要构建一种编程语言。我们只是必须创造一种语言来解决问题。接下来就是处理线程池和其他非常基本的流程。
我们如何与现有的 TensorFlow 和 PyTorch 系统集成?事实证明,这在技术上非常复杂。但是接下来进入了更深层次的范畴,即推动硬件加速。我们决定发明一整套非常专业、底层的编译器技术,具备自动融合等功能,其设计是面向云计算的,毕竟,世界上不止一台计算机。
由于硬件的复杂性,人类在算法上表现出色,但注意力广度不总是解决问题的关键,这就引出了一些需求。因此,我们构建了这种纯粹的编译器技术并进行验证,以展示我们可以生成性能非常高的 kernel。
下一阶段我们手动编写了这些非常底层的 MLIR 代码。当时我们对它很满意,但团队讨厌手动编写这些代码。因此需要一种语法规则。当时可以选择创建一个类似于 Halide 的专用领域嵌入式语言 (Domain-Specific Language,DSL),或者其他解决方案。
构建一种编程语言是一种更为困难的方式,但可以得到更好的结果。当时也有 Halide 或者 OpenAI Triton 等类似工具,虽然其演示效果很好,问题在于它们的调试器很糟糕,相关工具也不便于使用,通常情况下,最擅长使用这些工具的人是工具创建者。
因此,我们决定构建一门完整的编程语言。我曾构建过 Swift ,因此知道该怎样做,但也明白这是一项艰巨的任务。
显然,机器学习社区都是聚焦于 Python 的,深入进行决策时,发现有很多类似 Python 的语言,但它们并没有被广泛采用,并且存在着巨大的问题,可能还会导致社区分裂等后果。因此我们尝试构建一种需要时间来完善的语言,最终它将成为 Python 的超集。
实际上,Python 的语法并不是最重要的,关键在于社区,即程序员的经验和技能积累。所以构建一个看起来像 Python,但实际上不是 Python 的语言从来都不是我们的目标。我们最终的目标是通过构建 Mojo 实现质量更高的结果,即便这需要花费更长的时间。
如今,Modular 公司拥有最重要的 Mojo 开发者。在构建一门语言时,亲身使用实际上非常重要。这是我们在 Swift 开发过程中犯的一个错误,我们构建 Swift 是为了解决人们不喜欢 Objective-C 语法的问题,但在我们推出之前,还没有内部用户。
相比 Swift,Mojo 是更轻量级的语言。实际上,我们正在使用 Mojo,它是驱动引擎中所有内核的动力源。我们认为它对其他人也有价值和吸引力,所以我们将其作为一个独立项目发布。
Mojo 总有一天会走向成熟,我们希望能够围绕 Mojo 构建大型社区,为达成这一目标,我们将对 Mojo 开源。这是一件意义非凡的事情,一旦决定要做,我们就希望能够做到最好。
Alessio:我们经历了 Python 2 到 Python 3 的一段混乱时期,这是一个所有人都不愿回忆的阶段。Mojo 的一些特性非常优秀,为什么不支持 Python 2?从长远来看,你们计划如何保持这两种语言的同步?如何相互关联?
Chris:Guido 在 Mojo 发布之前就对它有所了解,他与我们团队进行了很多沟通,并且偶尔会在 Discord 上向我们提问。
Guido van Rossum(Python 之父)喜欢拿我们开涮,当然,这是一件好事。Mojo 是 Python 大家庭的一员,此外还有 PyPy、Cython 等。我们想成为 Python 大家庭中的一员,希望 Python 能够持续发展并添加新的功能。
Mojo 也将如此。这就好比是回到三十年前 C 语言诞生时,之后在 1983 年左右, C++ 突然出现,它是带有类(class)的 C 语言。而 Python 不仅有类,还包括通常在 C 语言下进行的所有操作。最初,C 和 C++ 是两个不同的社区,但是这两个社区进行了很多交流,彼此之间相互影响,导致彼此拥有了对方的一些特征。
我希望同样的融合发生在 Python 和 Mojo 之间。Python 3 与 Mojo 就像是 C++ 与 C 语言。Python 3 由其运行时及一种特定的对象模型定义,而 Mojo 则通过一种更丰富的表达能力来定义,我们拥有精巧的 MLIR 编译器等,因此能够实现类似的表达能力。我希望 Mojo 能够成为 Python 的超集,即在所有功能方面都更加强大,但是这些功能会并行发展。我们的目标不仅仅是添加“Walrus 2”算子等通用功能,而是添加系统编程特性。
4
为什么创办 Modular
Swyx:Modular 的灵感来自于 SciFive(一家创造自由开源处理器架构的公司),你曾与一些大型云服务提供商进行过对话,但对方对 Modular 并不感兴趣,最终你是否认为将 Modular 放在大型云平台上并不是最佳选择?你是如何想到要创办这家公司的?
Chris:2016 年左右,我开始涉足 AI 等多个领域。在特斯拉,我参与了自动驾驶的研发工作;在 Google,我负责了一个硬件项目,并尝试改善 TensorFlow 的架构设计。当时,我对 Google以及它对 PyTorch 的不重视感到不满,所以离开 Google,加入了一家硬件初创公司。但 2020 年(恰好是疫情爆发之前)并不是一个合适的时机,因为当时一切充满了不确定性。PyTorch 仍在摸索中,他们有很多雄心勃勃的项目。
当时,我认为 Meta 会解决这些问题,因此我加入了一家硬件初创公司,以了解商业战略、商业化以及公司建设等方面的知识与经验。当时我们的一名软件人员,Tim Davis(现 Modular 联合创始人)也正在探索自己的道路。2017 年,Tim 和我一起加入 Google Brain 并密切合作,我从事数据中心 TPU 方面的工作,而他从事移动端(如 Android 等)的工作;我担任工程师,而 Tim 负责产品方面的工作。在工作上,我俩非常互补,后来,我们开始思考职业发展的下一步,2021 年年中,我们发现 AI 基础设施的问题仍然存在,仍未获得有效解决。
因此,我们开始分析 AI 领域的问题,简单来说,如果 AI 对世界如此重要(即便在 ChatGPT 之前),为什么所有的软件都非常糟糕?为什么模型部署如此困难?尽管我们做了大量的工作来简化模型的训练过程,但将其投入生产却仍然非常具有挑战性。
我们对这些问题进行了细化,认为世界上的软件可分为三类。第一种是硬件专有的软件,比如 CUDA、XLA 堆栈或苹果的神经引擎(CoreML)等。这不是硬件人员的错,因为没有现成的解决方案,他们必须为硬件构建垂直的软件堆栈。但这样做的结果是,在无意间造成了软件领域的分裂以及软件生态的碎片化。
第二种是框架软件。在框架方面,我们有 TensorFlow、PyTorch、TVM 等,这些框架已经出现八年左右。框架本身是研究性质的,创建于机器学习的不同时代,随着时间的推移以及新的硬件和用例的出现而不断发展演进,但从未根据现有情况进行精心设计。此外,由于 AI 对其所属公司非常重要,因此,这些公司在其中投入了大量资源。框架开发人员相当之多,但却缺乏清晰的愿景。
事后来看,理解 AI 在五年后会是什么样子要比预测其形态更容易。我们会遇到很多已知的问题,以 PyTorch 为例,它的部署相当困难,不太适用于许多非 NVIDIA 硬件,而且对于语言大模型的扩展性也存在问题。这些都是众所周知的问题,但要从根本上解决这些问题却非常困难。PyTorch 的工程师们非常努力,他们正在努力解决这些问题,但由于所处的环境,修复这些问题确实很困难。
硬件导致了软件的碎片化,而框架则与最初的架构绑定。许多人希望能够简化 AI,使其变得简单,因此,MLOps 这个概念得以出现。我认为,很多人试图通过极简化的 API 来实现 AI 的简化。AutoML 就是其中一个例子。
第三种是试图在这个庞大而复杂的系统之上增加一层 Python 封装,以简化 AI 操作。然而,通过在上层添加一层 Python 封装无法解决可编程性、性能、硬件能力、新型算法或安全性等核心问题。所以,我们决定回归到第一性原理,思考导致这一混乱的根本原因。我们认为,这主要是因为缺少统一的接入平台,因此,我们决定从最基层开始构建软件,以解决这个棘手问题。
Alessio:你的职业生涯很长,是一位令人惊叹的工程师。突然之间你就创办了自己的公司,成为了 CEO,并承担着产品负责人和融资负责人的角色,同时还要负责建设团队、指导员工等,在这些方面,你有哪些经验和教训?
Chris:在 Modular,我和联合创始人 Tim 之间有着非常紧密的关系,我们能够彼此互补,有一个志同道合的合伙人非常重要,这是我在 Google或 Apple 工作时所没有的体验。另外,我曾在他人的框架下建立过很多团队、产品和技术。而现在,我们有了自己的框架,这让我们不再受制于其他框架存在的问题。
做任何事情之前,我们都要从第一性原理出发进行思考。我们理解 AI 领域所面临的问题、理解 AI 从业者所经历的痛苦,这也是我们成立 Modular 的出发点。Tim 在 Google 工作时,对这种痛苦也深有感受,在初创公司工作和在 Google是两种非常不同的感受。
在创办公司时,我们分工合作。作为工程领导者,我主要负责工程构建、建立工程团队等,而 Tim 则负责产品和业务方面的工作,他访谈了上百家不同的公司,了解这些公司的痛点和他们面临的挑战,以便更好地向这些公司提供帮助。通过这些深入访谈,我们真正明确了公司的发展愿景,并将同事真正地团结在一起。
Modular 面临的挑战是,我们正试图解决一项非常困难的技术问题,而且相当抽象。尽管现在项目已经开始运行且各部分正在合作,我们可以公布一些成果,但要解决这个问题需要花高价聘请大型科技公司的专家,这在很大程度上决定了我们公司的最初状态以及我们思考问题的出发点。
当我们以第一性原理思考,发现出于上述原因,必须筹集大量资金、激励员工、提供丰厚薪酬等,此外还要提供一个舒适的工作环境,上述需求塑造了我们的行事风格。这个过程非常有趣。
回头来看,TensorFlow 或 PyTorch 是否是产品呢?我的答案:不是。但我也要自我反思,我曾经参与过 Swift 或 Xcode 等项目,从某种意义上,它们算是产品,其中有产品经理和一个工程团队参与开发,并会将其交付给客户,但它们并非公司的核心产品。Xcode 并不赚钱,苹果没有从中获利,它与客户之间的联系是间接的,有一定的独立性。这容易导致团队或 TensorFlow、PyTorch 等支持团队的研究项目与客户的需求脱节。
Modular 团队直接面向客户,我们了解客户所历经的痛苦和需求。众所周知,在 AI 领域,构建和部署这些东西非常困难。当然,你可以在顶层加入一层 Python,这种做法看似简单,但这并非领先公司和构建这些东西的顶级人才所面临的痛点。
问题在于,他们周围存在很多无用之物,而我们的愿景之一就是将这些东西都统一起来,利用更少的东西,发挥更大的作用。我们的愿景源于与一些团队的交流,他们所面临的问题是,由于需求的不断演进,他们构建的产品在不断变化,这些公司使用了多个模型,这导致与我们合作的团队通常都相当复杂,为了各种不同的用例,这些公司演变出很多混乱的系统,造成很大麻烦,因此常常会有如下疑问:我是否需要大量工程师来部署这个模型?为什么需要这样做?
Swyx:有一个地方我比较困惑,你提到 Modular 没有云服务,但人们是通过你们的云服务来使用 Modular 推理引擎,也就是说 Modular 有云工程师。
Chris:我们确实有云工程师。实际上,我们的产品是在用户的云平台上使用的。我们提供了一个 Docker 容器,使得 Modular 的推理引擎可以在云端、本地服务器或笔记本电脑上运行。
Modular 的设计理念非常重视模块化,用户可以根据自己的需求使用各种不同的平台。尽管一些用户不想自己管理,但 Modular 团队真正关注的是如何满足用户的需求,因此我们打算逐渐构建一个托管产品以为用户提供更多方便。在我们看来,如果要求用户将所有内容都迁移到 Modular 的云平台上,对于那些不愿意自己管理的用户来说是有价值的,但这会减缓技术的采用速度。
Swyx:你有大量搭建团队和招聘工程师的经验,在这方面你拥有独特的优势,人们都很乐意与你一起工作。在工程管理方面,你有什么经验、建议想要分享?
Chris:我的工作是帮助团队取得胜利,我会尽一切努力去达成这一目标。有些人认为,想要获胜是理所当然的事情,但你必须先搞清楚什么是获胜,也就是说,团队要有一个清晰的愿景、明确的目标,团队成员之间要彼此协调,特别是,当你有一群非常优秀的人,他们都希望在自己的工作中大放异彩。如果成员之间目标一致,那我们就能快速取得进展,而如果成员之间彼此对立,就会影响我们的工作进程。
我喜欢凡事亲力亲为,从头做起。这样做不仅能直接向团队成员展示如何做事,同时也塑造了我们的团队文化。
效率对团队来说非常重要,如果你只是随便坐在哪里,花24小时或者三周来等 CI 运行,这会拖慢一切。这意味着测试策略,意味着这些核心软件工程问题非常重要。一旦在团队中营造出独立、不依赖第三方等文化,你就能吸引很多优秀人才,你需要在招聘和后续工作中发掘这些人才的潜力。我深信,一个真正优秀的人能够解决任何问题,并从中取得进步。
如果你有非常优秀并充满热情的同事,并让他们从事真正想做的事情,那么他们就会拥有超能力。所以,我们需要确保团队成员处理正确的问题,培养他们做事和解决问题的能力,帮助他们成长。尤其是在一个高速发展的团队当中,你不仅要着眼于具体事务,还要查看自己是否作出了贡献等。
通常来说,人们会非常关注产品,关注客户和客户所面临的问题,但如果没有团队,就无法解决问题和构建产品。
上述问题最终会形成良性循环,对于领导者和团队构建来说,以上问题至关重要。这也是我喜欢 Tim,并且能和他愉快共事的原因之一,他能有效弥补我不擅长的地方,我们彼此都能从对方身上学到很多。
总之,要打造一个团队,我们需要做的事情还有很多。我喜欢构建事物,但不会为此放慢脚步。
5
关于 AI 领域的发展
Alessio:在 AI 领域,有什么是已经实现,但你曾认为需要花费更长时间的东西?
Chris:ChatGPT是对用户界面的一种创新,它的爆发式发展让人们意识到了 AI 的力量。但回顾过去,我本来认为 AI 进入公众视野还需要好几年时间。
Swyx:在 AI 领域解决的问题中,你最感兴趣的是什么?
Chris:不同的人对 AI 有着不同的定义,一些人认为,一切都应该用端到端的神经网络来实现,而不是软件。我认为,训练算法和智能设计算法之间的平衡是一个开放式问题,个人而言,这并非是一个非此即彼的选择,比如,如果你想要构建一个猫咪检测器,那么使用卷积神经网络是一个非常好的方法,但如果你想编写操作系统,那么应该选择循环语句。
但随时间推移,这些技术会发生何种变化,我们该如何让应用开发者更加一致地思考这些问题,而不局限于A类或B类的范畴等,这些都是开放式问题。
作为软件开发方法的 AI 最终将成为人们思考构建应用的工具之一。这里的应用不仅仅局限于 iPhone 应用等,而是云服务、数据管道等等,涉及到一系列复杂的环节,最终构建出用户可用的产品。我认为,AI 行业仍处于发展青春期,我们尚未完全掌握这一点。
Alessio:有趣的是,ChatGPT的出现还不到一年,而我们已经从谈论 AI 安全问题发展到了 AI 将会毁灭世界,而这一切仅仅是因为一个聊天机器人的出现,这不得不令人深思。
Chris:不得不承认,2017 年的时候已经有很多人关注 AI 安全问题了,但当时我对此非常不解,我不认为这个问题有什么可讨论的,但事实证明,这些人很有远见。
这也是我欣赏 Geoffrey Hinton 等人的原因之一,他们在 AI 走进大众视野之前就进入了这一行业,见证并融合了更长的时间跨度,能以一种更全面的角度来看待问题,并取得更大的成就。
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/![]() http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/
文章出处登录后可见!