目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于协同过滤算法的电商平台推荐系统
课题背景和意义
电商平台消费客户千人千面,客户的需求、特征和其价 值体现相对比较复杂,并且受多方面的影响。分析历史订单信 息能准确地定位买家的心理,进一步调整运营方向以此提高客 户忠诚度,稳定客流,保持平台自身的竞争力。以电商平台为实例,借助协同过滤推荐算法,考虑用户对商品的 偏好以及对热门商品流行度进行惩罚的措施,优化推荐模型。在消费品零售行业数字化的推动下,网络零售对国内消 费市场的贡献作用持续提升。统计局最新数据显示,2021 年, 全国网上零售额达 13.1 万亿元,同比增长 14.1%,增速比上 年加快 3.2 个百分点。随着互联网各类基础设施的应用和完 善,供应商将数字技术应用于产品研发、生产和销售等环节, 实现流程再造,从而促进企业的智能化转型升级。因此,探 索如何利用大数据、人工智能等技术分析消费者的购物习惯, 有助于电商平台挖掘客户个性化需求,实现精准营销。在激烈的市场竞争中,如何精准定位买家的需求一直是电商平台需要考虑的重点问题。因此,研究用户的行 为数据,通过这些数据的信息分析出买家的购买需求度,对实现个性化推荐具有一定的现实意义。
实现技术思路
一、文献综述
学者们对相关问题进行了研究,取得一定的成果。WIJAYA 表示吸 引购买者关注的特征之一就是商品推荐特征,同时每个电子 商务平台提供的功能完备性是买家决定在哪里进行交易的标 准之一,因此电商企业需要构建实现产品的精准推荐系统。 HUSSIEN 使用统计方法改进了传统推荐系统算法,以提高向 客户推荐列表的准确性。HUSSIEN 对推荐系统的价值进行 了研究概述,并对协同推荐系统技术进行了深入分析,指出 协同推荐系统技术能更好根据客户的兴趣向客户提出建议, 使客户更容易搜索,从而选择适合他的商品。
二、基于用户协同过滤推荐系统算法
基于用户协同过滤推荐系统算法基本步骤
通过协同过滤算法选取和目标用户相关的 K 个最相似的 用户,在 K 个用户的订单记录中选取目标用户尚未购买的物 品进行推荐,计算这 K 个用户的推荐得分,从而选取得分最 高的 N 个商品,生成最后的推荐列表,主要步骤如下。
1、相似度计算
计算余弦相似度时,需计算用户共同购买商品的次数, 再统计每个用户购买商品的数目,这里采用余弦相似度进行计 算,两个用户之间的相似度公式为:
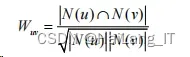
式中:Wuv 表示用户 u 和用户 v 的相似度;N(u) 表示用户 u 历史偏爱物品集合;N(v) 表示用户 v 历史偏爱物品集合。
2、用户最近邻搜寻
根据相似度将目标用户的近邻用户进行排序后,选取前 K 个用户进入最近邻集合。
3、预测评分并生成 top-N 推荐
完成最近邻搜寻后能够获得目标用户的近邻集,将项目按 照预测评分降序进行排序,把前 N 个项目推荐给目标用户,Pu, j 为目标用户 u 对未评分项目 j 的预测评分,其计算公式为:
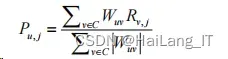
式中:用户 u 的最近邻集合为 C;用户 u 与邻近用户 v 之 间的相似度为 Wuv;邻近用户 v 对项目 j 的评分为 Rv, j 。
根据以上算法用户前一年的购买历史数据,预测他们该 月有可能购买的产品,并评估算法的准确性。
老用户推荐模型——考虑对热门商品进行惩罚
使用用户兴趣相似度的最简单的公式(余弦相似度公式), 推荐模型的预测结果中会出现大量的热门商品的情况。原因是 根据余弦相似度公式进行计算,热门商品会频繁的出现在用户 和商品的共现矩阵中,热门商品的频繁出现导致在生成最后的 推荐列表中包含了大量重复的热门商品,但这并不是个性化推 荐想得到的预期结果。在模型当中为了更好地挖掘客户的兴趣 爱好,有必要对热门商品的流行度进行惩罚。
本文选用商品的流行度对相似度计算的算法进行 改进。改进的用户兴趣相似度为:
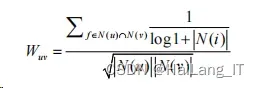
式中:选择通过添加系数 1/ log 1 + N|(i)| 来对热门商品进行 惩罚,这里的 N(i) 为商品的流行度,商品的流行度越高代表 着其惩罚系数越小,对相似度的影响会相应的下降。
新用户推荐模型——冷启动问题
在推荐系统中,都是基于用户的历史行为数据集,而新 用户并不存在历史数据。用户最邻近搜索在用户数量比较大的 时候,搜索的效率会得到极大的提升,本文中用户数量和物品 数量并不算太大,选择考虑将这一思想应用到解决冷启动问题 中。由于不存在客户的基本信息,数据当中唯一包含的客户 信息只有客户身份标识号码(Identity document,ID)这一项, 相近的客户 ID 意味着客户可能是因为同一个渠道了解到这一 购物平台,或者意味着客户有着相同的购物习惯,从而根据客 户 ID 进行近邻搜索,寻找 ID 接近的用户。
在对新用户进行推荐时,考虑是否需要对热门商品进行 惩罚。本文考虑选用的是未对热门商品进行权重惩罚的模型, 在对新用户进行推荐的时候,本文挑选的是在统计意义上的优 质商品,或者是电商平台主打的“明星产品”,这样的推荐虽 然降低了一定的“个性化”推荐程度,但是针对历史信息空 白的新用户,推荐统计意义上的优质商品是一个不错的选择。 在搜集到客户一定的购物历史信息,再考虑对用户的历史行为 进行分析,对其进行个性化推荐。
推荐算法准确性评估
通过 Python 3.9.0 实现上述推荐算法,并使用准确率 (Precision)和召回率(Recall)来评估算法的准确性。 它的计算方式为

式中:TP 为被模型预测为正的正样本数量;FP 为被模型 预测为正的负样本数量;FN 为被模型预测为负的正样本数量。
结合电商购物平台的商品推荐场景,对 Precision 和 Recall 进行了改进,使评价结果更贴合实际场景。改进后的计 算公式为

同时,本文考虑到企业更希望产品被更大范围的推荐, 而不是仅仅推荐热销品,因此本文引入了覆盖率 Cover 来评估 该推荐算法。它的计算公式为

三、实证分析
某礼品批发电商平台一年中产生的订单数 据。累计 378 823 条交易记录,其中销售出 3676 个产品,产 生了 19 636 个订单。本文选择在历史数据集中选取 30% 的数 据当作测试集,用于对本文建立的模型进行评估。
老用户推荐模型——考虑对热门商品进行惩罚
用原始的模型对预测数据中的老用户进行预测,该推荐 模型对预测数据中未加惩罚预测 645 个存在历史数据的老用户 一共推荐了 1234 个商品种类,用加入惩罚之后的模型进行预 测,共推荐了 1308 个商品种类。两个模型推荐次数前 5 的商 品如表所示。
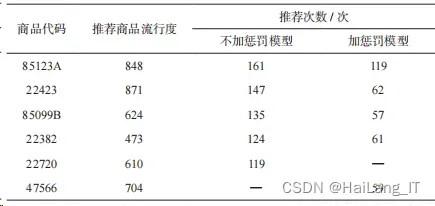
两个模型推荐前 5 的商品有 4 个相同,且流行度都很高, 但加惩罚模型推荐热门商品的次数明显下降,下降 52.19%。 说明非热门商品推荐次数有明显提升。
以 ID 为 12409 的老用户为例,分别用两个模型进行商品 推荐,未加惩罚预测推荐商品流行度均分为 378.5,用加入惩 罚之后的模型对进行预测,推荐商品流行度均分为 332.5。推 荐商品得分如表所示。
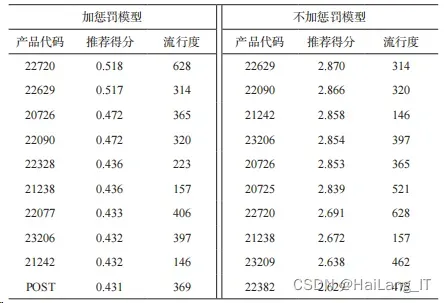
通过对比整体推荐次数和商品流行度本文不难发现,热 门商品的推荐次数减少的同时,在个体的商品流行度上下降比 较明显,而在整体的结果当中,流行度高的商品依然占了较大 的比重。推荐系统推荐的高流行度商品的推荐频次下降明显,也就是意味着更多的流行度不低的商品被推荐出来,推荐商品 的种类明显提升。
新用户推荐模型——冷启动问题
根据邻近 ID 用户搜索得到推荐商品得分,以 ID 为 12367 的新用户为例,搜寻临近的客户 ID,并且累加临近的客户 ID 的推荐列表得分,考虑对新用户的推荐是否需要对热门商品进 行惩罚。用加入惩罚前后的模型预测最终的数据,对新用户的 预测结果(部分展示)如表所示。
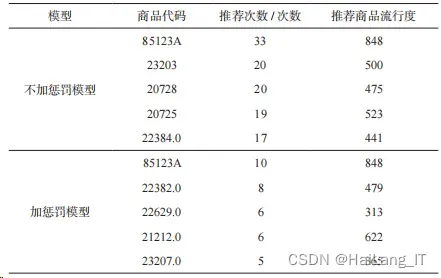
两个模型推荐前 5 的商品只有一个相同,且加惩罚模型 推荐热门商品的流行度较低,且推荐热门商品的次数明显下 降,说明非热门商品推荐次数有明显提升。 加惩罚模型和不加惩罚模型的商品推荐对比如图所示。
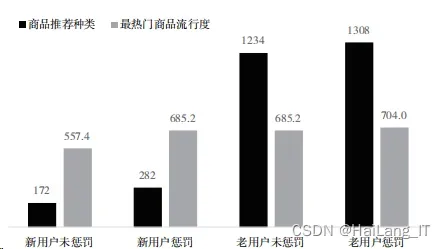
从图中可以很直观看出,模型加入惩罚之后推荐的商品种类 得到了明显的提升,加入惩罚的模型商品的推荐更加多样化, 商品的覆盖率更高。对比两模型下热门商品流行度可见,推荐 出来的商品依旧是流行度较高的商品。加入惩罚之后虽然在推 荐模型当中出现了更多的商品,热门商品依然会出现在推荐的 列表当中,虽然热门商品的推荐顺序会相对延后,但流行度不 高的商品也有机会出现在流行度高的商品之前,这样的推荐更 具有个性化,而不是千篇一律的热门商品,加入惩罚之后的模 型依然是保持着优质推荐的基础理念进行推荐。
加入惩罚的模型对用户购买商品的行为进行预 测,预测的部分结果如表所示。

推荐算法准确性评估
本文基于商品和客户之间的关系对客户进行了个性化的 销售预测,将平台历史数据划分为训练集和测试集。同时,利 用加入惩罚模型和用推荐得分代替相似度权重的模型进行销 售预测,对比两者的准确率、召回率 、覆盖度及推荐商品流 行度,结果如表所示。
用推荐得分代替相似度权重的模型的准确率在所有的测 试集上有 35% 左右,也就是说在推荐的 10 个商品中平均有 3.5 个商品会被客户购买,该模型的召回率有 40% 左右,意味着 在客户每购买 10 个商品中大约有 4 个商品会出现在本文的推 荐列表中。准确率和召回率相差不大,意味着在测试集的数据 当中,用户平均购买商品的种类在 10 左右,也就是一个用户 大概会购买 10 种商品。考虑到该数据集中用户和物品的信息 有限,无法像深度学习模型一样挖掘深层次的客户物品交叉特 征,这个准确率和召回率是在一个可以接受的范围之 内的。
四、总结
利用平台的订单数据,利用基于用户协同过滤算法 实现对客户的个性化推荐。考虑到流行商品在推荐中的权重较 大,在传统的基于用户的协同过滤推荐算法上添加了惩罚 以平衡推荐结果的均衡性,同时解决新用户的冷启动问题。
实现效果图样例
电商平台推荐系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
文章出处登录后可见!