Swin Transformer的详细原理我已经在上一篇文章写过了,这回我来细细的写一篇它的代码原理。有朋友跟我反应Vit代码直接全贴上去光靠注释也不容易看懂,这会我用分总的方法介绍。
注:此代码支持多尺度训练。
文章仅供学习
先从最难的下手。
SW-MSA之mask
def create_mask(self, x, H, W):
# 第一部分:初始化
Hp = int(np.ceil(H / self.window_size)) * self.window_size
Wp = int(np.ceil(W / self.window_size)) * self.window_size
img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device)
# 第二部分:编号,分窗口
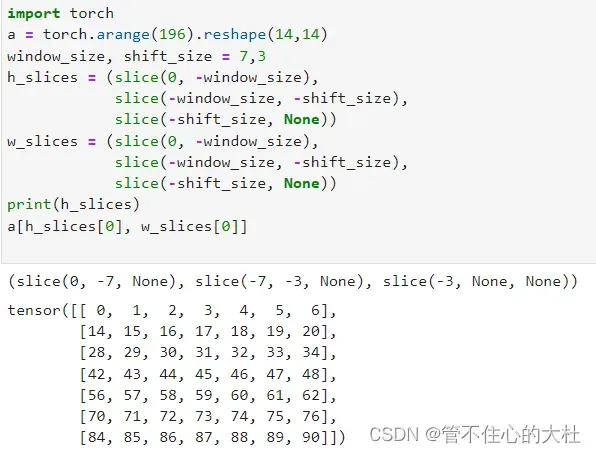
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
# 第三部分:生成蒙版
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
第一部分:初始化
因为蒙版要和attention中的矩阵相加,但attention中输入的特征图已经被padding到window_size的整数倍,所以蒙版的维度也要是window_size的整数倍。先将他初始化为(1,Hp,Wp,1)的0矩阵,之所以维度顺序如此是因为在window_partition中的维度顺序如此,我们稍后再讲。
第二部分:编号,分窗口
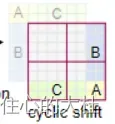
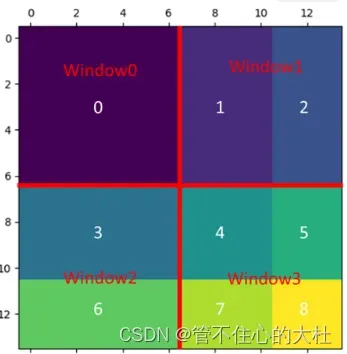
如图,这是上一篇原理文章中shifted后再平移后对应的窗口,建议先对蒙版的原理聊熟于心,可以看我的上一篇文章。这里的“编号”就是将刚刚生成的全0的蒙版分成这样的区域。
这里的前提条件是蒙版是window_size的整数倍。所以[0, -window_size; 0, -window_size]的所有窗口内都来自区域0。
因为我们是移动了shift_size个单位,再补到其他地方去。因此[0, -window_size; -window_size, -shift_size]内都来自区域1。[0, -window_size; -shift_size, None]都来自区域2。以此类推。
slice函数就是切片的作用,他的元素可以用于在张量中取值,如图
紧接着我们就可以通过一个不断增加的变量cnt将这九个区域全部编上号
经过window partition后的维度是[nW, Mh, Mw, 1],nW是窗口数,再将其展平,维度变为[nW, Mh*Mw]
第三部分:生成蒙版
这里主要用了广播机制。
我们知道,现在一个窗口的值代表对应patch的区域,一个窗口有Mh*Mw和值,每个值的维度为1.展平后就是取消最后一个维度,并且将二维窗口变为一维。如下图
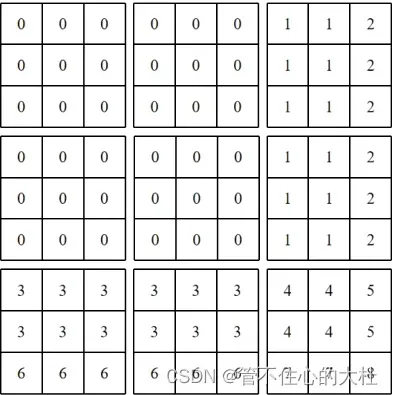
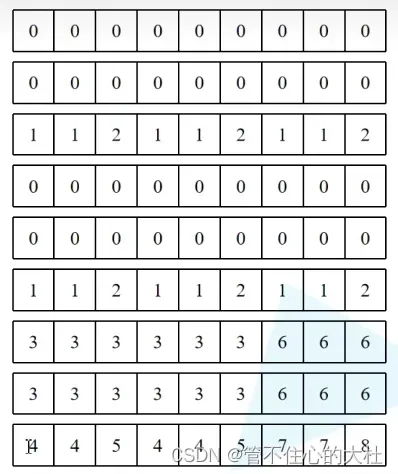
通过unsqueeze实现两个张量相减,维度如下[nW, 1, Mh*Mw] – [nW, Mh*Mw, 1]。抛开第一个维度不看,于是我们取最后一行举例,这相当于一个Mh*Mw的行向量减去一个Mh*Mw的列向量,广播以后如下
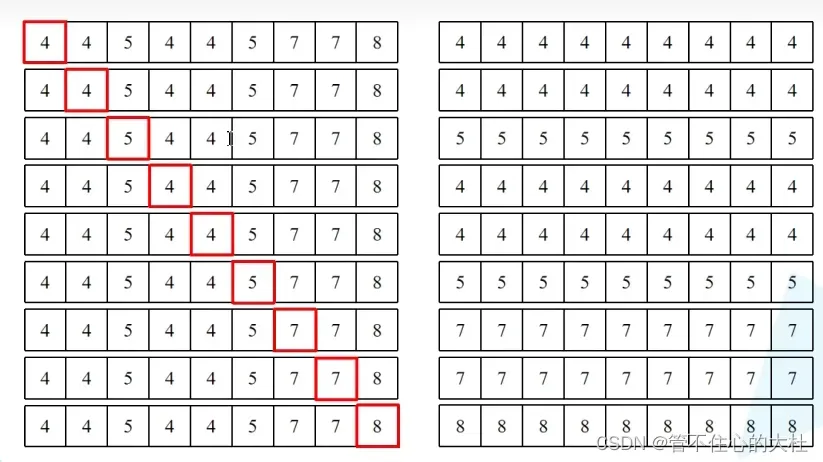
这么理解,A的每一行按红框的数字代表区域几进行attention,根据我们mask的原理只能和来自相同区域进行attention,来自不同的区域要被mask掉,所以减去B后,为0就代表不需要mask,不为0就代表需要mask。作者使用-100进行mask,通过softmax后就基本为0了。
最终,每一个window的维度为[1, Mh*Mw, Mh*Mw],所以最终mask矩阵为[nW, Mh*Mw, Mh*Mw]
相对位置编码
# 第一部分:相对位置表
self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
# 第二部分:相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing="ij"))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten.unsqueeze(2) - coords_flatten.unsqueeze(1)
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
# forward方法中:
......
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
......相对位置编码我们没有专门做成一个模块,而是直接放在WindowAttention当中。
第一部分:相对位置表
首先参数化一个[2*Mh-1 * 2*Mw-1, nH]的张量,nH的意思是每个head都有自己的可学习的相对位置表,至于为什么是2*Mh-1 * 2*Mw-1可以见原理篇。
第二部分:相对位置索引
首先先构建一个绝对位置表,最后的coords如下。这里coords[0]代表行,[1]代表列。
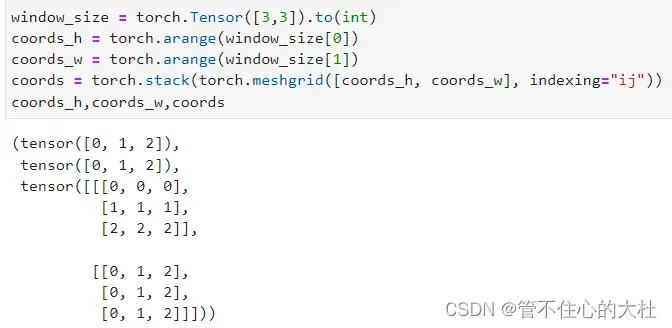
然后再对它进行展平
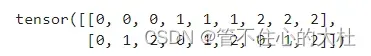
最关键的来了,又是一句代码解决,又是用了广播机制
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
维度是[2, Mh*Mw, 1] – [2, 1, Mh*Mw],再用一次广播机制。
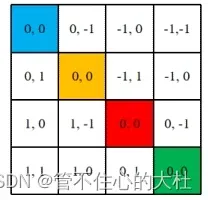
举个例子现在有四个位置,表格中是他们的绝对位置,现在要求他们的相对位置索引。在图A中,左右矩阵相减可以看做是各个绝对位置依次去减其他的绝对位置,最终得到相对位置索引矩阵
| 0,0 | 0,1 |
| 1,0 | 1,1 |
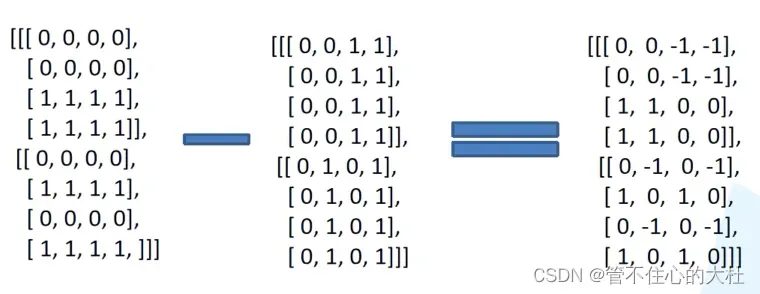
然后将二维索引转为一维索引,先给行列坐标都加上2M-1以消除负数,再给行标乘2M-1,再将行列相加,最终得到相对位置索引。
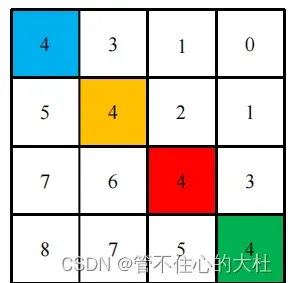
在整个训练过程中,窗口大小永远不变,而相对位置索引仅跟窗口有关,所以将我们得到的这个相对位置索引矩阵存在缓存之中。
第三部分:使用它
在forward方法中,首先把它的数据取出来。在张量a,b可以使用a[b],使用效果如下

也就是说会根据b的内容取值,
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)因此这一句我们先将relative_position_index变为一维,再根据他之内的索引在relative_position_bias_table中取值,然后变成[Mh*Mw,Mh*Mw,nH]的形状,通过permute变成[nH, Mh*Mw, Mh*Mw],最后再unsqueeze上batch的维度和attention相加,得到结果。
以上是最难理解的两部分,全部代码我会放在下一篇文章说明。
另:本篇文章参考自12.2 使用Pytorch搭建Swin-Transformer网络_哔哩哔哩_bilibili
仅供学习
文章出处登录后可见!