提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
项目介绍
本项目旨在通过使用Python编程语言,爬取B站哔哩哔哩英雄联盟赛事直播间的部分弹幕,并对这些弹幕进行分析。通过关键词统计、生成词云以及情感分析等技术手段,将弹幕中的信息提取出来并进行可视化展示,以帮助用户深入了解B站直播弹幕的特征和情感倾向。 以下是项目的主要功能:
-
弹幕爬取: 使用Python的网络爬虫技术,从B站直播间中获取部分弹幕数据。通过与B站弹幕服务器进行交互,获取直播间中的实时弹幕信息,并存储为文本文件用于后续分析。
-
关键词统计: 对爬取到的弹幕数据进行关键词提取与统计。使用Python中的自然语言处理(NLP)库,分析每条弹幕中的词汇,并计算出现频率前十高的关键词。这有助于了解直播间中用户关注的话题和热点。
-
生成词云: 利用关键词统计结果,使用Python的词云生成库,生成弹幕词云图。词云图以关键词出现频率为权重,将词云以视觉化方式展示,使用户能够直观地了解弹幕中的热门话题和关注点。
-
情感分析: 使用自然语言处理技术,对弹幕中的情感进行分析。通过Python中的情感分析库,将每条弹幕的情感倾向进行分类,如积极、消极或中性。这有助于了解用户对直播内容的情感态度和反馈。
-
数据可视化: 将关键词统计和情感分析的结果进行可视化展示。使用Python的数据可视化库和数据可视化工具Tableau,将分析结果以直观、易懂的图表形式呈现。这可以帮助用户更好地理解直播弹幕的特征和趋势。
一、数据获取和数据预处理
本项目分析的是LPL(英雄联盟职业联赛)的官方直播间中2023年6月28日EDG对战UP中的第一场比赛的部分弹幕,直播间地址:2023LPL夏季赛。
先打开直播间网址,进入开发者选项,点击Network界面,选XHR类型,然后刷新界面,经过一系列的查看和筛选,找到所需要的接口:
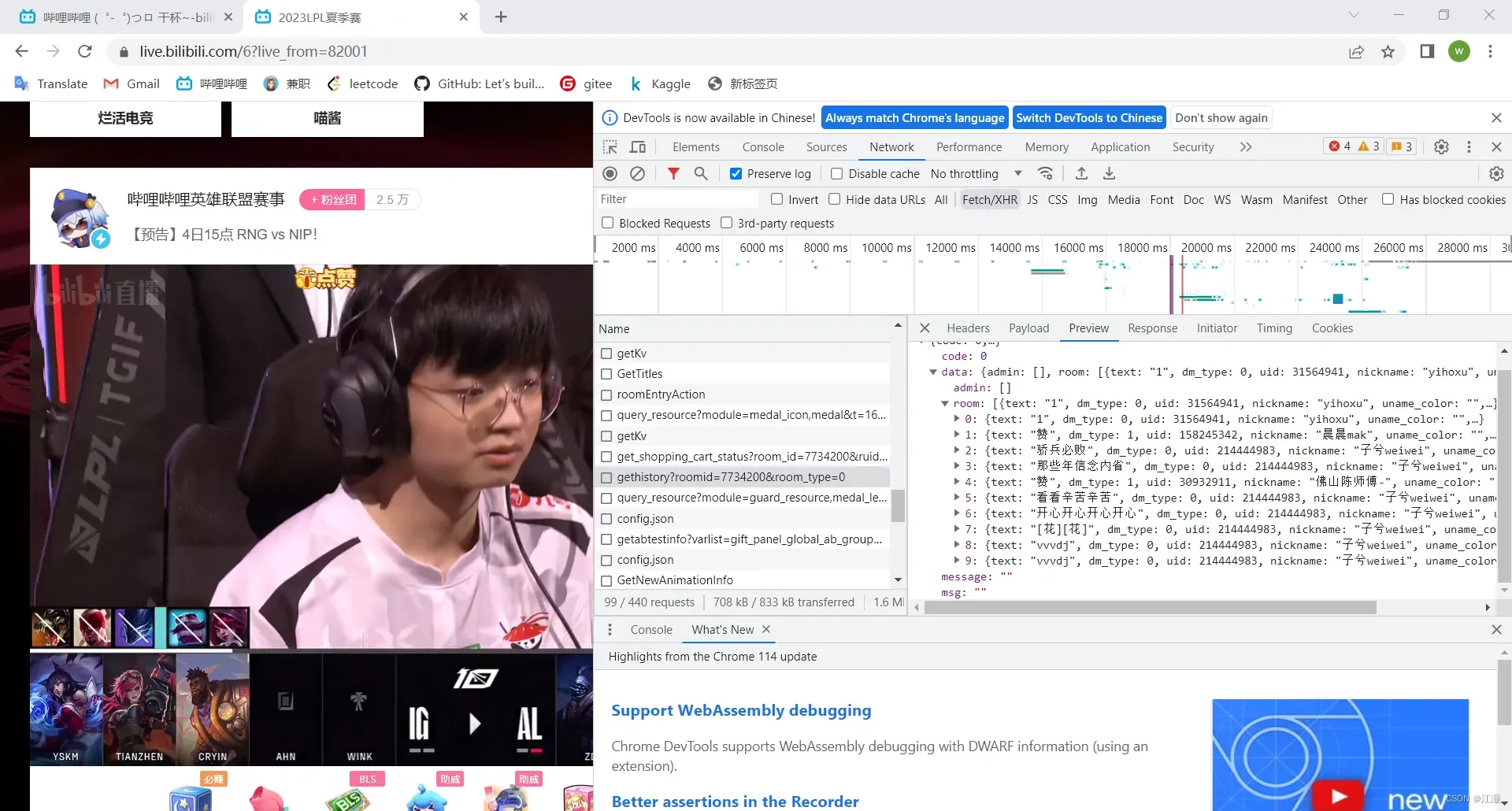
经过分析后,可以知道这条接口能够返回直播间历史最新的10条弹幕,那么就可以开始编辑代码了:
def get_json(filename, n, interval_time):
# n是请求接口次数,1次请求10条,interval_tima为请求间隔
post_url = 'https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory?roomid=7734200'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
reviews_list = []
with open(filename, 'w', encoding='utf-8') as f:
for i in range(1, n + 1):
response = requests.get(url=post_url, headers=headers)
reviews = json.loads(response.text)
reviews_list.append(reviews['data']['room'])
time.sleep(interval_time)
# 转化成json类型存储
json.dump(reviews_list, f, indent=4, ensure_ascii=False) 我定义了一个名为 get_json 的函数,其作用是通过发送HTTP请求,从B站的API接口获取直播弹幕数据,并将数据以JSON格式存储到指定的文件中。在函数内部,首先定义了我要请求的API接口地址 post_url,该地址是用于获取B站直播间弹幕数据的。然后,我们设置了请求头部信息 headers,其中包含了用户代理信息,以确保请求的合法性和正确性。然后,通过一个循环进行了n次请求。在每次循环中,使用 requests 库发送GET请求,通过指定的URL和头部信息向API接口获取弹幕数据。使用 json.loads 函数将响应的文本数据解析为JSON格式,并将弹幕数据添加到 reviews_list 列表中。为了控制请求的频率,我使用了 time.sleep(interval_time) 函数,在每次请求之间暂停一段时间。最后,在循环结束后,我使用 json.dump 函数将 reviews_list 列表以JSON格式写入到打开的文件中。
接着,可以看到得到的json数据里每一条弹幕有很多条信息,这里还需要对数据进行进一步处理,提取出需要的有用信息:
def process_json(filename):
text = []
name = []
timeline = []
medal = []
level = []
df = pd.DataFrame(columns=['text', 'name', 'time'])
with open(filename, "r", encoding='utf-8') as file:
# 加载未处理的json
reviews = json.load(file)
new_reviews = []
# 设置flag检查json数据是否已存在于新json里
for review_list in reviews:
for review in review_list:
flag = 1
for new_review in new_reviews:
if review['text'] == new_review['text'] \
and review['uid'] == new_review['uid'] \
and review['timeline'] == new_review['timeline']:
flag = 0
# flag为1说明数据不重复
if flag:
text.append(review['text'])
name.append(review['nickname'])
timeline.append(review['timeline'][:16])
level.append(get_user_level(review['nickname']))
if len(review['medal']) > 0:
medal.append(review['medal'][2])
else:
medal.append('NULL')
new_reviews.append(review)
df['text'] = text
df['name'] = name
df['time'] = timeline
df['medal'] = medal
df['level'] = level
df.to_csv('reviews.csv')我又定义了名为 process_json 的函数,用于处理从文件中加载的原始JSON数据,并提取出需要的字段。通过遍历原始数据中的每个弹幕,使用一个flag标志检查该弹幕是否已经存在于 new_reviews 中,以避免重复数据的存储。如果弹幕数据不重复,则将其相关字段的值分别添加到对应的列表中,并将该弹幕数据添加到 new_reviews 中,最后将DataFrame保存为名为 reviews.csv 的CSV文件。
从上述函数可以看出,我提取的弹幕信息有弹幕内容,发送者的姓名,发送时间,佩戴的粉丝勋章(这可以反映出用户平时喜欢观看的直播对象),以及用户等级。值得一提的是,在我通过调用接口获得的用户数据中并没有用户等级的信息,但是我可以通过用户名在b站搜索功能中查询到对应的用户,再去查看用户等级,所以我又写了一个获取用户等级的函数:
def get_user_level(name): # 获取用户等级
post_url = f'https://search.bilibili.com/upuser'
data = {
'keyword': name
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
}
response = requests.get(url=post_url, headers=headers, params=data) # 返回输入用户名的查询页面
response.encoding = response.apparent_encoding
result = etree.HTML(response.text).xpath(
'//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div[2]/div[1]/div[1]/div/div/h2') # xpath查询第一个用户的html标签
try:
result = html.tostring(result[0])
level = re.findall(r'lv_(\d)', str(result))
return level[0]
except Exception as e:
return 0我使用了 etree.HTML 函数将响应的文本数据解析为HTML树,并使用XPath表达式进行查询。XPath查询语句用于提取第一个用户的HTML标签。在 try 块中,将查询到的HTML标签转换为字符串,并使用正则表达式 re.findall 提取出用户等级信息。等级信息的格式为 lv_数字,使用正则表达式 r'lv_(\d)' 进行匹配,并返回等级数字。如果在查询和解析过程中出现异常,如找不到用户或其他错误,则在 except 块中返回0,表示获取用户等级失败。
运行我们写好的函数:
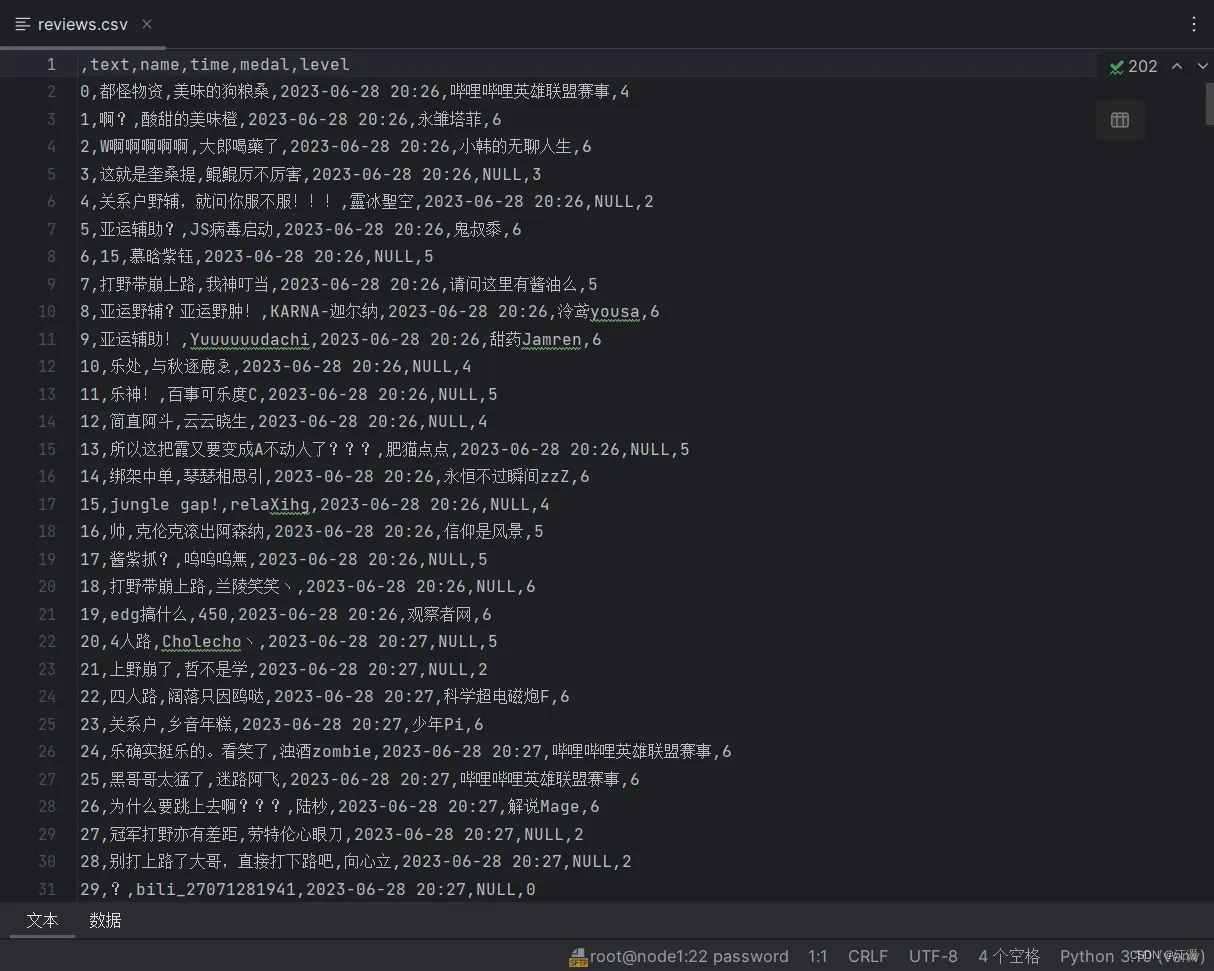
get_json('reviews.json', 120, 5)
process_json('reviews.json')在这里我们的循环次数设定为120,每一次循环的间隔设定为5秒钟,因为一次循环调用一次接口,调用一次接口返回十条数据,所以我们最终得到了1200条弹幕数据。处理好的数据如下图所示:
二、数据统计和分析
1.查询弹幕
在数据处理完后,我首先想到的是如果我想查询包含指定词汇的弹幕的功能怎么实现,在这里我选择将数据存储到数据库之后,在用sql语句进行模糊查询。
import sqlite3
import pandas as pd
conn = sqlite3.connect('reviews.db')
cur = conn.cursor()
def creat_database():
cur.execute('''CREATE TABLE reviews
(弹幕内容 TEXT,
名字 CHAR(20) NOT NULL,
时间 DATETIME,
勋章 CHAR(20) ,
等级 INTEGER);''')
df = pd.read_csv('analyse.csv')
for index, row in df.iterrows():
cur.execute("INSERT INTO reviews VALUES (?, ?, ?, ?, ?)", (row[1], row[2], row[3], row[4], row[5]))
conn.commit()
def select_reviews(text):
result = []
c = cur.execute('SELECT 弹幕内容 FROM reviews WHERE 弹幕内容 LIKE ?', ('%' + text + '%',))
for row in c:
result.append(row[0])
return result
text = input('请输入你想查询的相关内容:')
print(select_reviews(text))
cur.close()
conn.close()
我定义了一个名为 creat_database 的函数,用于创建数据库表和向表中插入数据。在函数内部,通过 cur.execute 方法执行SQL语句,创建名为 reviews 的数据表,该表包含了弹幕内容、名字、时间、勋章和等级等字段。表的结构通过SQL语句的 CREATE TABLE 部分定义。
接着定义了一个名为 select_reviews 的函数,用于根据指定的关键词从数据库中查询匹配的弹幕内容。在函数内部,创建了一个空列表 result,用于存储查询结果。通过 cur.execute 方法执行SQL查询语句,使用 SELECT 语句从 reviews 表中选择弹幕内容 (弹幕内容) 字段,通过 LIKE 子句进行模糊匹配,查询包含指定关键词的弹幕内容。
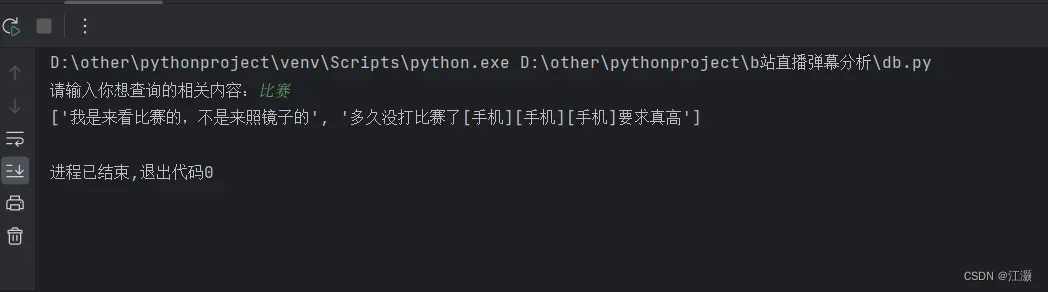
以下是该功能的实现展示,输入要查询的词汇,会以列表形式返回包含该词汇的有关弹幕:
2.词频统计
def word_analyse():
word_list = [] # 词列表,可重复
word_freq = {} # 词频字典
df = pd.read_csv('reviews.csv')
stop = open('cn_stopwords.txt', 'r', encoding='utf-8') # 读取停用词表
stopword = stop.read().split("\n")
for text in df['text']:
seg_text = list(jieba.cut(text, cut_all=False)) # jieba精确分词
# 统计词频
for word in seg_text:
if word in stopword or word == ' ': # 如果是停用词则不计数
break
if word not in word_freq.keys():
word_freq[word] = 1
word_freq[word] += 1
word_list.append(word)这段代码用于对弹幕文本进行词频分析。我使用了分词工具 jieba 对弹幕文本进行精确分词,并统计各个词语的出现频率,得到词频统计结果和词列表。对于分词结果中的每个词语,如果词语存在于停用词表中或为空格,则跳过不计数;否则,将词语作为字典 word_freq 的键,并将其初始词频设置为1。如果词语已经在 word_freq 的键集合中,即已经存在于字典中,则将其对应的词频加1。
3.弹幕内容情感分析
def get_access_token(): # 将key转化为token
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
def get_api(text): # 调用百度api进行情感分析
url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=&access_token=" + get_access_token()
payload = json.dumps({
"text": text
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response.text
def emotion_analyse():
df = pd.read_csv('reviews.csv', index_col=0)
emotion_dict = {0: '消极', 1: '中性', 2: '积极'} # 设置返回结果转化成情感字典
emotion_list = []
for text in df['text']:
response = json.loads(get_api(text))
try:
emotion = emotion_dict[response['items'][0]['sentiment']]
emotion_list.append(emotion)
time.sleep(1)
except Exception as e:
print(e)
print(text)
print(response)
emotion_list.append('NULL')
df['emotion'] = emotion_list
df.to_csv('analyse.csv')关于情感分析,因为我并没有能够用于模型训练的数据,且我这次项目的重点并不在关于情感分析模型的建立,所以选择调用现成的百度开发者平台的API完成,下面是我写的几个函数:
get_access_token 函数,用于获取百度API的访问令牌(Access Token)。该函数发送一个 POST 请求到百度的 OAuth 2.0 授权接口,使用提供的 API Key(API_KEY)和 Secret Key(SECRET_KEY)进行身份验证。成功后,函数从响应中提取并返回访问令牌。
get_api 函数,用于调用百度API进行情感分析。该函数构建请求的 URL,包含了获取的访问令牌。然后,将要进行情感分析的文本作为数据发送给百度API。函数返回响应的文本结果。
emotion_analyse 函数,用于对弹幕文本进行情感分析并生成分析结果。调用 get_api 函数,将弹幕文本作为参数传入,获取情感分析结果。将返回的结果解析为JSON格式。从响应的JSON结果中提取情感值(sentiment),根据情感值在情感字典 emotion_dict 中查找对应的情感标签。
三、数据可视化
1.直播间出现频率最高的十个词汇
def wf_generate(word_dict): # 绘制出出现次数最多的前十个词语图
word_freq = sorted(word_dict.items(), key=lambda d: d[1], reverse=True) # 对词频降序排序
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签SimHei
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(8, 4))
plt.title("出现最多的前十个词语")
plt.xlabel('词语') # x轴标签
plt.ylabel('次数') # y轴标签
p = plt.bar([item[0] for item in word_freq[:10]], [item[1] for item in word_freq[:10]])
plt.bar_label(p, label_type='edge') # 绘制标签到柱顶上
plt.savefig('words_frequency.png')之前我针对每一条弹幕都进行了jieba分词,并存储到了一个字典里。所以我可以利用matplotlib库绘制图像。先对字典按照value值进行降序排序,然后绘制出出现次数最多的前十个词语的柱状图。下面是生成的图像:
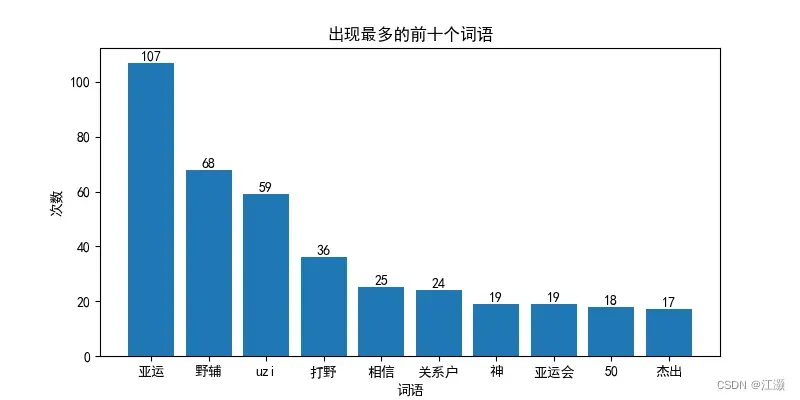
可以看到出现最多的词汇是亚运,我首先联系到在比赛的前一天刚好公布了杭州亚运会英雄联盟比赛的参赛名单,因此亚运是近期讨论度非常热门的一个话题。而当天比赛的双方战队之一EDG,他们的野辅(野辅指的是比赛的打野位和辅助位,是英雄联盟比赛的职位,就像足球中也有前锋后卫之类的职位)正是亚运会的首发人员名单,因此讨论度也比较高,出现的次数排在第二。而词汇出现次于野辅的是uzi,uzi是EDG战队的一名选手,且人气知名度非常大,可以认为算是明星球员,所以讨论度也非常大。而其他的出现频率前十的词汇都跟比赛,以及战队选手之间的话题有关。
2.弹幕词云图
def wc_generate(wordlist): # 根据词语列表生成词云图
wc = WordCloud(
font_path="msyh.ttc", # 中文字体
background_color="white", # 背景颜色
max_words=200, # 显示最大词数
width=1000, # 图幅宽度
height=700 # 图幅高度
)
wc.generate(','.join(wordlist))
wc.to_file("wordcloud.png")为了更加直观的展示弹幕里的词汇信息,我又调用了python的wordcloud库来帮助我生成一张词云图,我之前在创建词频字典的同时还创建了一个词汇列表,这里用这个词汇列表来生成词云图。

可以看到词云图里不同词汇的大小跟词汇出现的频率有关,这里也进一步和我统计出直播间出现频率最高的十个词汇柱形图想对应起来,我们能根据词云图更加清晰的理解比赛的讨论热点,和观众们喜欢讨论的话题方向。
3.Tableau进行数据可视化
我在先前的步骤中将分析好的数据储存到了csv文件中,利用Tableau进一步制作更为细致的可视化图表。先来看看我们最终的数据源是长这样的:
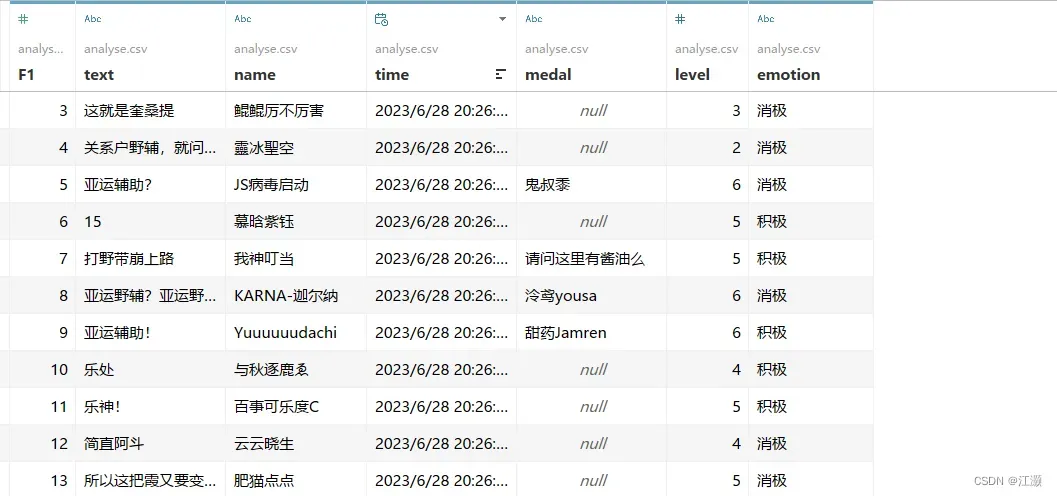
下面来展示我最终制作完成的可视化图像:
3.1.直播间弹幕情感倾向占比
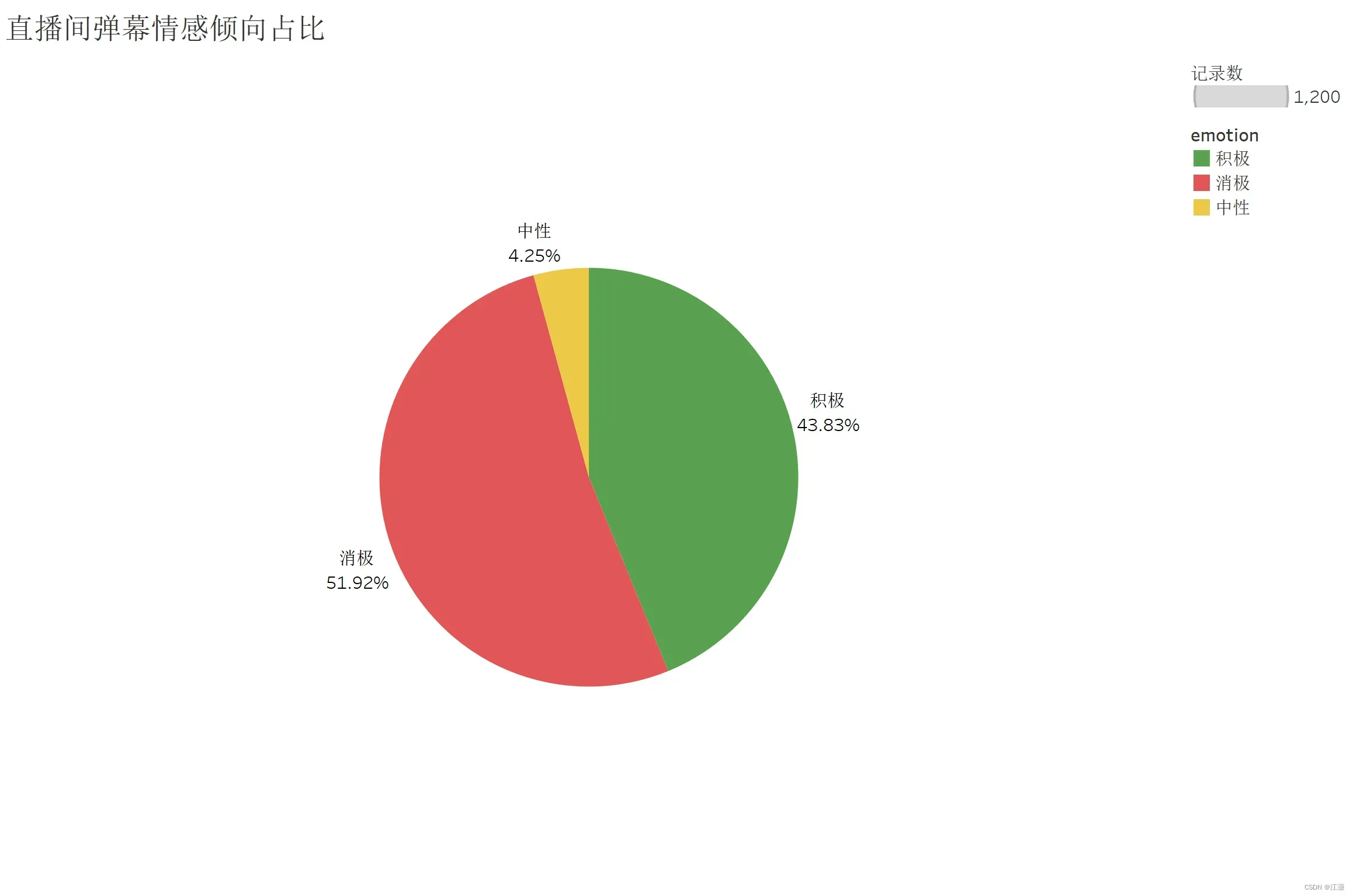
通过百度的api调用返回的情感种类一共三种:积极,中性,消极。从这张图可以看到在1200条记录的数据中,消极情感的弹幕占比超过了百分之五十以上。但是,在我的观察后,其实这个数据的真实值应该是偏小的,消极情感的弹幕占比其实是还要大的。事实上,观看电子竞技赛事的观众年龄段偏小,而网络上的发言又较为自由,就英雄联盟比赛这方面来说,无论在哪个平台,弹幕的环境都是很差的,直播的观看氛围也是较为恶劣。另一方面,因为流行网络词汇的更新频率很快,以及一些恶劣弹幕一般发表不好的言论都不会直接明目张胆的发送,而是利用谐音字替换,所以会影响情感分析的判断,如果要提高情感分析的准确率可能需要更新且更针对性更强的数据集进行训练。同时,这个结果也告诉我们如果想让观看比赛的氛围变得更良好,平台也需要采取进一步的行动,比如加强对直播间弹幕的管控程度,创造更和谐的发言环境。
3.2.直播间用户不同等级人数
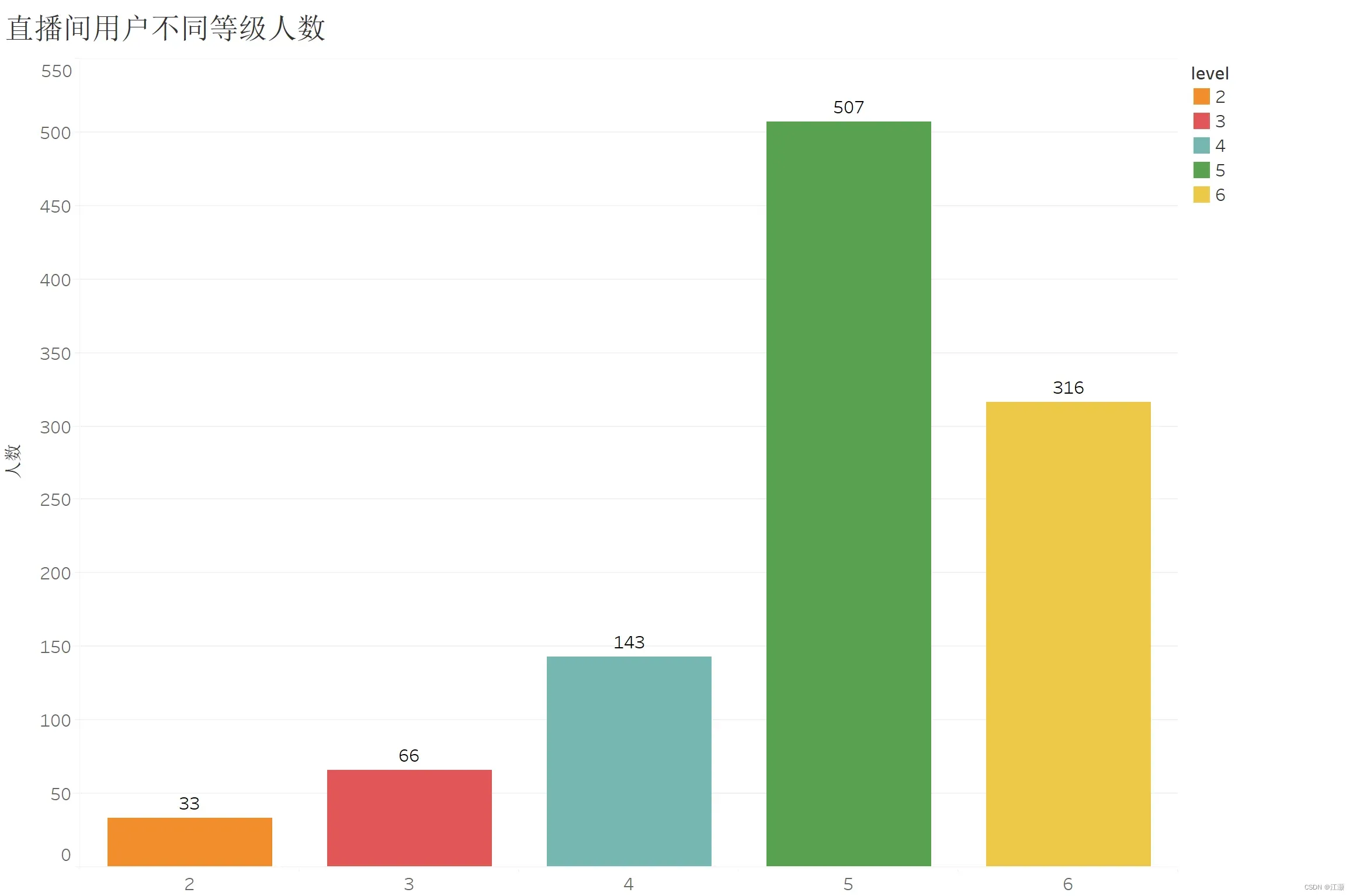
我对观看直播的用户等级制作了一个柱形图,首先我排除掉了等级为空的账户。会有等级为空的账户的原因是因为我之前写了一个根据用户名请求b站网页返回用户等级的函数,这个函数是在我获取到源数据后过了两天才执行的,在此期间有些用户注销了,且注销的用户数据很少,因此我便排除了。我们可以看到,1200条数据中没有1级的账户,我猜测是因为b站账号注册后1级升到2级的门槛非常低,因此1级账号的用户个体本来就很小,可能刚好1200条数据中没有抽取到1级账户。而另一方面,可以看到直播间6级号,也就是满级号的观众居然排名第二,说明直播间是有很多老用户的。而直播间观众用户等级数最多的是5级账号,快接近一半了,我认为原因是因为b站1级升到级时很快的,而5级升到6级却非常慢,拿我个人来说,我的账号从1级升到5级的时间约等于5级升到6级的时间,因此大部分用户的等级都卡到了5级,所以从另一方面说,并不仅仅是直播间观看的用户5级账号多,而是b站用户整体的5级账号比例很大,这个图也能反映一部分b站用户整体的等级分布。
3.3.直播间用户佩戴不同粉丝牌子人数
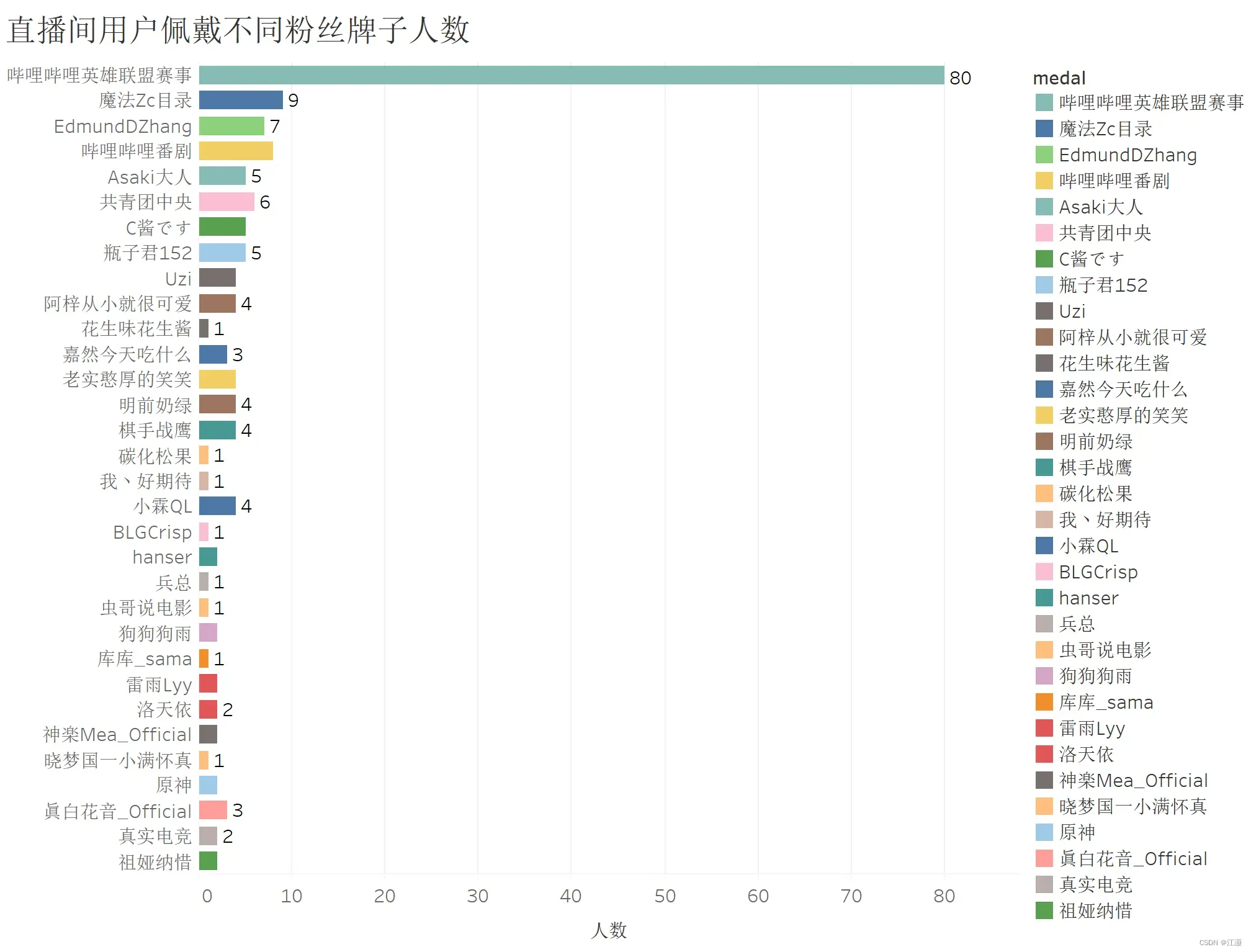
b站用户在观看某一个直播间一定时间后,或者为直播间充钱送礼物后,就会获得对应的粉丝牌子(前提时直播间开启粉丝牌子),因此粉丝牌子能够反映出观看用户的观看喜好。但是佩戴粉丝牌子是需要主动设置的,在我的统计里,没有佩戴粉丝牌子的用户有546条,我在这里筛选掉不再展示了。让我们来看向佩戴了粉丝牌子的用户里,其中最多的牌子正是哔哩哔哩英雄联盟赛事,毕竟是统计该直播间的粉丝,因此数量最多合情合理。而其他的粉丝牌子的数量也不是很多,且相差不大,一方面是b站的直播间有很多,另一方面是统计的数量不足够大并不能完全反映出观众的观看倾向,但在其中我看到很多游戏和番剧方面的直播间,所以还是或多或少的反映出观看英雄联盟赛事观众的喜好。如果我们再进行进一步的统计,可以能够做出根据直播间用户佩戴粉丝牌子进行直播间推荐的分析。
3.4.直播间信息分析
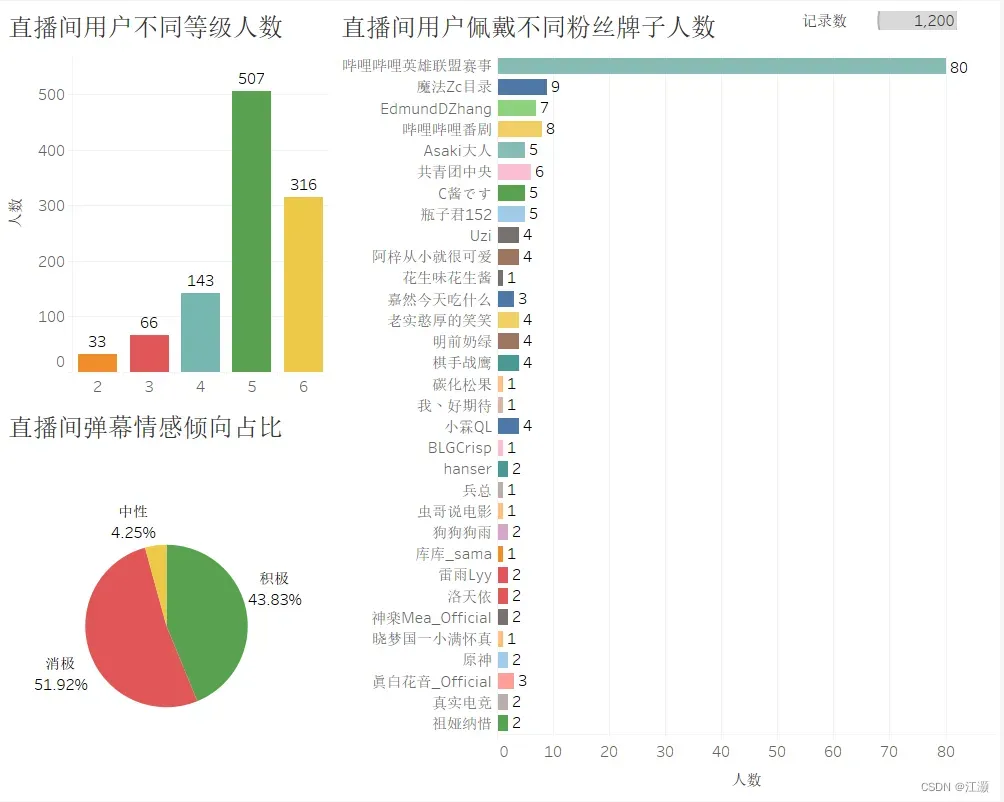
根据做的三个工作表,我将结果最终汇聚到了一个仪表盘之中。同时,我将直播间用户不同等级人数设置成了筛选器,这样我们可以统计出各个等级用户的弹幕情感占比和佩戴粉丝牌子分布,但是由于这里导出的是图像,并不能完全展示出来。我在比对了不同等级用户弹幕的情感分析后,发表积极弹幕占比从大到小的用户等级依次为:2,5,4,6,3。
总结
通过这次项目,我更加牢固的掌握了对python爬虫的运用以及pandas库对数据的处理,此外我还学习到了新的库,像是wordcloud库可以根据词汇列表生成词云,甚至能够根据模板图片生成对应形状的词云。同时我也巩固了对数据可视化工具Tableau的使用,比如在项目中我遇到过一个问题,就是在我做完对应的可视化图表后发现,我统计的直播间不同用户等级人数的数据里可能会有相同的用户,因为我之前对弹幕数据的去重是同时满足发表时间和用户以及发言内容相等才去除,所以我的数据里可能会有同一个用户在不同时间里发表不同的弹幕内容。为了解决这个问题,我的想法是重新制作一个新的数据集,是专门针对用户等级和用户名的数据,但是感觉有点麻烦且不必要,在经过查阅学习后,我学会在Tableau创建了新的数据字段:{fixed level:countd(name)},能够使在level的领域中对name进行去重,极大的提高了我的效率。最后,项目还有值得改进的地方,比如在弹幕情感分析的预测方面可能会有不准确,如果时间充足的话,我会自己手动统计一个数据集,再取训练分类模型,最终呈现的效果可能会更好。感谢你能看到这里,欢迎指正批判!
文章出处登录后可见!