目录
一、简要介绍
(一)材料与准备工具
数据集下载
数据集是国外团队实验数据(建议用FTP或者迅雷下载,减少不必要的时间)
这个团队邀请了54位实验人员,做了两天实验,里面有多个范式,只用MI范式就可以了
这个数据的文件名是sess01_subj1_EEG_MI.mat的格式
里面的sess表示是第几天的数据(session1和session2),subj表示被试者(实验人员)
下载地址:GigaDB Dataset – DOI 10.5524/100542 – Supporting data for “EEG Dataset and OpenBMI Toolbox for Three BCI Paradigms: An Investigation into …
工具箱下载
下载地址:http://openbmi.org
github:GitHub – PatternRecognition/OpenBMI: An open software package dedicated for the development of Brain-Computer Interfaces with various advanced pattern recognition algorithms
参考
这里给出其它作者的一篇博客,这个作者前面的东西非常详细,但是在分类器设计那里使用的是Matlab,不太适合所有人,但还是非常值得参考
参考链接:基于OpenBMI的运动想象分类_半個俗人的博客-CSDN博客_知乎openbmi
(二)OpenBMI工具箱介绍
这个工具箱是国外团队写的工具,使用的是Matlab,它相当于是一个集成的函数、类,使用的时候直接调用就可以了

比如这样,Load_MAT其实是它工具箱的函数
(三)数据集详细介绍
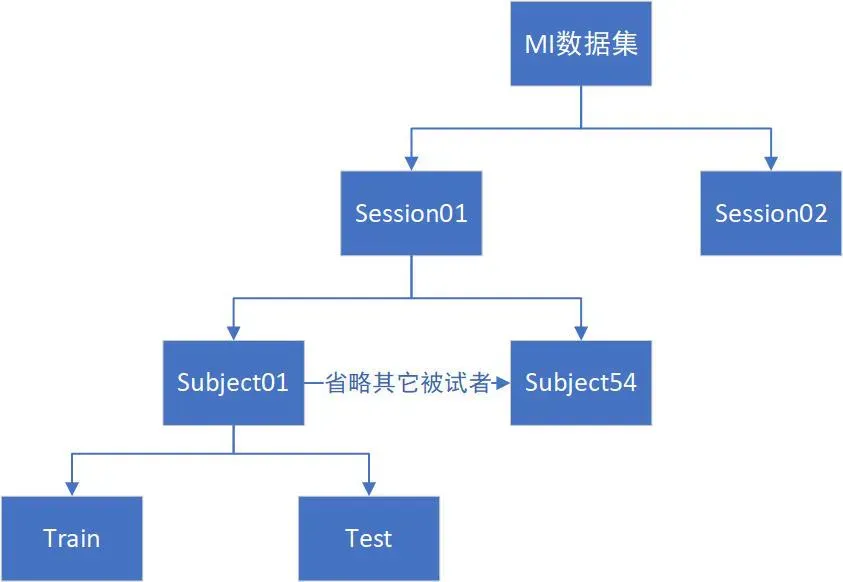
数据拆分
每一个文件,也就是单个session中的某一个subject,例如sess01_subj1_EEG_MI.mat,这个文件中其实包含了两个文件,通过Matlab读取的时候也能发现,一个是train,一个是test,但其实并不是真正意义上的训练集和测试集,train代表的是离线数据,test是在线数据(就是做实验的方式有些许区别),也就是这样理解
数据解读
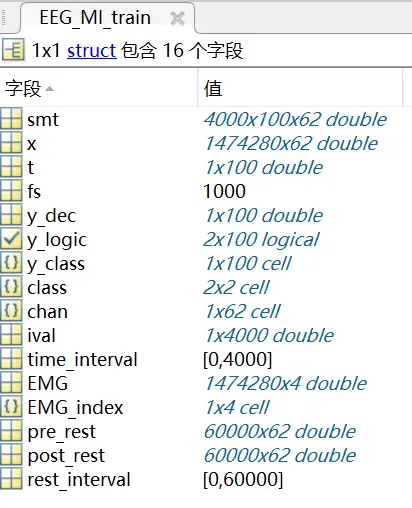
读取数据后,得到这么一个struct数据(不管是train还是test),因为脑电信号是随时间变化的图像,以下为部分理解
X:输入,可知维度
t:取样时间,这里1X100,表示有100个取样点
fs:取样频率
y_dec:y标签,1表示左,2是右。(这里也知道是一个二分类问题了)
y_logic:y标签的逻辑值
y_class:y标签的类
class:类别
chan:通道数,1X62表示是62个通道
time_interval:采样持续时间,这里是4000ms
这个时候,我们能知道特征和标签,之后会经常提到trial(这个概念对后续数据划分设计很重要),实际上对应就是y标签的数量,这里实际上是进行了100次间歇性实验,所以有100个结果,那么,一个train或者test对应就是100个trial
二、预处理
(一)目标
看到x的维度非常奇怪,脑电信号有很多通道,自然是非常奇怪。我们要使用一些算法,把某些频率的信号进行增强,然后提取出其中重要的特征,然后作为处理后的输入。
常见的算法有CSP,FCSP等等,这些东西都已经集成在工具箱内,你需要看懂那些函数的输入和输出是什么,然后就可以对x进行滤波操作
(二)特征提取
代码
这里给出我预处理使用的代码,实际上这个代码是从工具箱提供者的论文中搬过来的,所以,有时间一定要去看看原作者的论文,其实他们写的一些东西也非常详细的,你也可以看到分类的准确率,可以与自己的做对比
另外,原作者在后面其实加上了LDA分类器,这个是Matlab实现的,所以就一起写进去了,loss是损失,也就是可以说是错误率
%读取数据集
[CNT_tr,CNT_te] = Load_MAT('./sess02_subj04_EEG_MI.mat');
%训练集预处理
CNT_tr = prep_selectChannels(CNT_tr,{'Index',1:20});%划分电极1到20
CNT_tr = prep_filter(CNT_tr,{'frequency',[8,30]});%划分频率8到30赫兹
SMT_tr = prep_segmentation(CNT_tr,{'interval',[1000,3500]});%数据分段,10ms分一段,为250X20X100(trials)
%得到SMT下一步数据
%测试集预处理
CNT_te = prep_selectChannels(CNT_te,{'Index',1:20});
CNT_te = prep_filter(CNT_te,{'frequency',[8,30]});
SMT_te = prep_segmentation(CNT_te,{'interval',[1000,3500]});
%CSP训练
[CSP_tr,CSP_W] = func_csp(SMT_tr,{'nPatterns',[2]});%csp空间滤波,得到滤波后的训练集、滤波参数,滤波评分
FT_tr=func_featureExtraction(CSP_tr,{'feature','logvar'});%对滤波后的训练集进行特征提取
CF_PARAW=func_train(FT_tr,{'classifier','LDA'});%训练LDA模型,得到分类器参数
%CSP测试
CSP_te = func_projection(SMT_te,CSP_W);%csp空间再滤波,得到滤波后的测试集
FT_te = func_featureExtraction(CSP_te,{'feature','logvar'});%对滤波后的测试集特征提取
cf_out = func_predict(FT_te,CF_PARAW);%输入分类器参数和滤波后的测试集特征,得到结果
loss = eval_calLoss(FT_te.y_dec,cf_out);%将测试集结果和滤波特征结果进行比对解释
然后你会发现在Matlab左侧出现了一堆变量
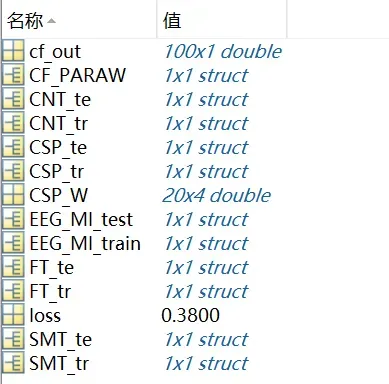
Matlab会存储你的每一行代码运行结果,这点我觉得比较可以的,然后,FT变量就是提取出来的特征变量(就是feature的缩写),比如FT_te
进入这个变量,你会发现某些变量变化了,比如x,现在变成了4X100大小,也就是说,CSP滤波提取出了4个特征。
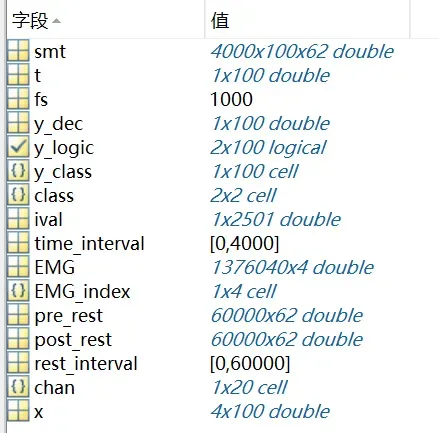
你需要做的就是把这里的x和y_dec作为数据的特征和标签导出来
这里给出我的导出代码,这个也是Matlab代码
FT_tr_x = FT_tr.x;
FT_tr_y = FT_tr.y_dec;
save('E:\learning\data\train\sess02_subj04_FT_tr_x.mat',"FT_tr_x")
save('E:\learning\data\train\sess02_subj04_FT_tr_y.mat',"FT_tr_y")新建变量存储特征结构体中的x和y,然后用save函数导出(这里只是sess01_subj1_EEG_MI.mat,根据你需要多少trial,以及你的设计方式提取足够的特征数据)
三、分类器设计
(一)划分方式
假如我们把所有的数据集都已经提取过,然后我们需要对数据进行拼接和划分,确定哪些是模型的训练集和测试集,这里数据量仅仅使用前10个subj
这里介绍一下概念,不跨被试的意思就是,仅仅对单个被试者的数据进行建模和预测,不把其它的被试者数据拼接。跨被试的意思就是,将你手上被试者的数据拼接在一起,进行建模和预测
第一种不跨被试
10个分类器,把每个subj的train和test拼接在一起(也就是200个trial),作为不跨被试的数据集,然后对数据集进行交叉验证,至于是几折,则依据情况确定(这个概念不懂的自己去查)
第二种不跨被试
10个分类器,把每个subj的train和test拼接在一起(200个trial),然后以session01作为训练集,session02作为测试集
跨被试
1个分类器,把每个subj的train和test拼接在一起(200个trial),然后9个subj拼接在一起作为训练集,剩余一个作为测试集(其实是留一验证法)
(二)分类器
不跨被试
import pandas
from scipy.io import loadmat
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn import svm
import pandas as pd
def preprocess(data):
for i in data.keys():
if i == "FT_tr_x":
data = data["FT_tr_x"]
elif i == "FT_tr_y":
data = data["FT_tr_y"]
elif i == "FT_te_x":
data = data["FT_te_x"]
elif i == "FT_te_y":
data = data["FT_te_y"]
else:
continue
data = pd.DataFrame(data)
data = data.T
return data
x1_train = loadmat("E:\\learning\\data\\train\\sess01_subj01_FT_tr_x.mat")
x1_train = preprocess(x1_train)
x2_train = loadmat("E:\\learning\\data\\test\\sess01_subj01_FT_te_x.mat")
x2_train = preprocess(x2_train)
x_train = pd.concat([x1_train,x2_train])
y1_train = loadmat("E:\\learning\\data\\train\\sess01_subj01_FT_tr_y.mat")
y1_train = preprocess(y1_train)
y2_train = loadmat("E:\\learning\\data\\test\\sess01_subj01_FT_te_y.mat")
y2_train = preprocess(y2_train)
y_train = pd.concat([y1_train,y2_train])
KF = KFold(n_splits=10,random_state=3,shuffle=True)
model = svm.SVC(C=10,kernel='linear',probability=True)
score_accuracy1 = cross_val_score(model,x_train,pd.DataFrame(y_train).values.ravel(),cv=KF,scoring='accuracy',n_jobs=-1)
print(f"SVM准确率:{score_accuracy1.mean()}")
log = LogisticRegression(max_iter=1000)
score_accuracy2 = cross_val_score(log,x_train,pd.DataFrame(y_train).values.ravel(),cv=KF,scoring='accuracy',n_jobs=-1)
print(f"LOG准确率:{score_accuracy2.mean()}")这里仅仅给出不跨被试的python代码,跨被试的代码太多,平台撰写的时候崩了,不放这里
里面可以看到文件读取操作,这个是绝对路径,如果想让代码正常运行,建议新建一样路径下的文件夹,然后把特征数据这些也放到对应的位置,或者就自己改地址,改到自己电脑中放的位置
我对原特征矩阵进行了转置,因为正常来说列表示特征,行表示样本量,4X100的x就变成了100X4
里面的SVM和Logistic是sklearn中的模型,没有仔细调参,只设置了惩罚系数、最大收敛值、核函数这些,实际上一个模型变量很多(这里建议熟悉机器学习的自己建模,毕竟你已经的到特征和标签了)
这里给出一个sklearn机器学习库的参考博客:【Sklearn】【API详解】【SVM】sklearn.svm.SVC参数详解(一)_拾夕er的博客-CSDN博客_sklearn.svm.svc
最后给出我的源代码链接:
链接:百度网盘 请输入提取码
提取码:2023
文章出处登录后可见!