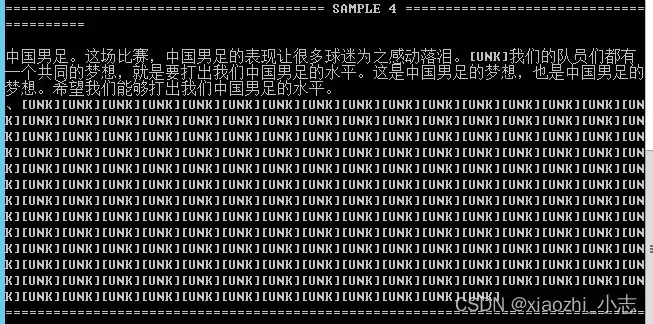
效果抢先看



准备工作
从GitHub上拉去项目到本地,准备已训练好的模型百度网盘:提取码【9dvu】。
- gpt2对联训练模型
- gpt2古诗词训练模型
- gpt2通用中文模型
- gpt2通用中文小模型
- gpt2文学散文训练模型
- gpt2中文歌词模型
环境搭建
- 配置好GPU的pytorch环境
a. 安装Anaconda环境
b. NIVIDA配置流程
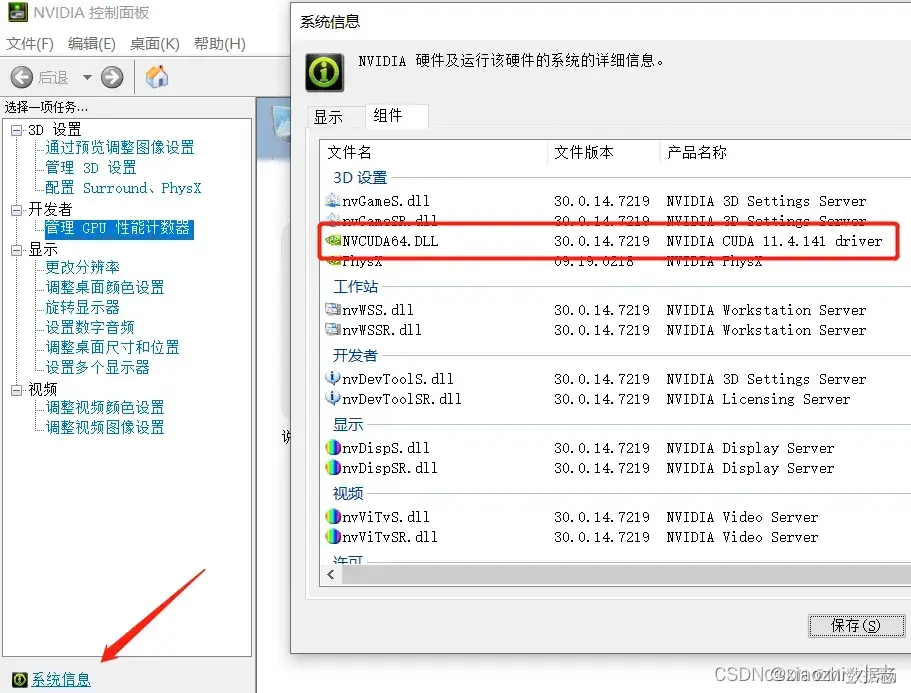
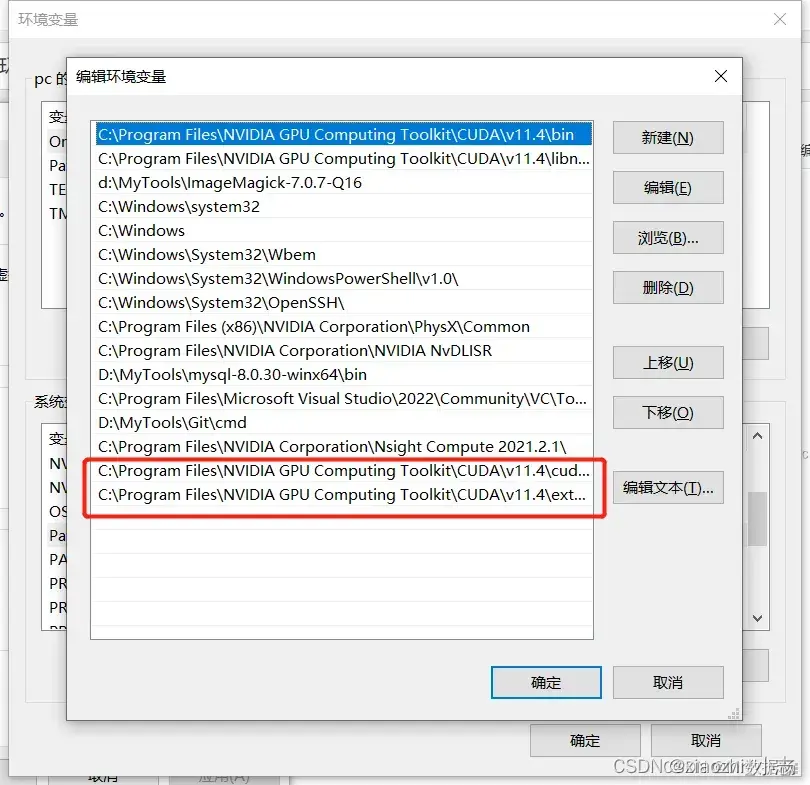
桌面右键鼠标,找到NVIDIA控制面板,在左边找到开发者下管理GPU性能计数器,导航栏点击桌面选择启用开发者设置,弹出的系统信息中找到组件,找到产品名前缀为NVIDIA CUDA的那一条,记住其后面的版本号。
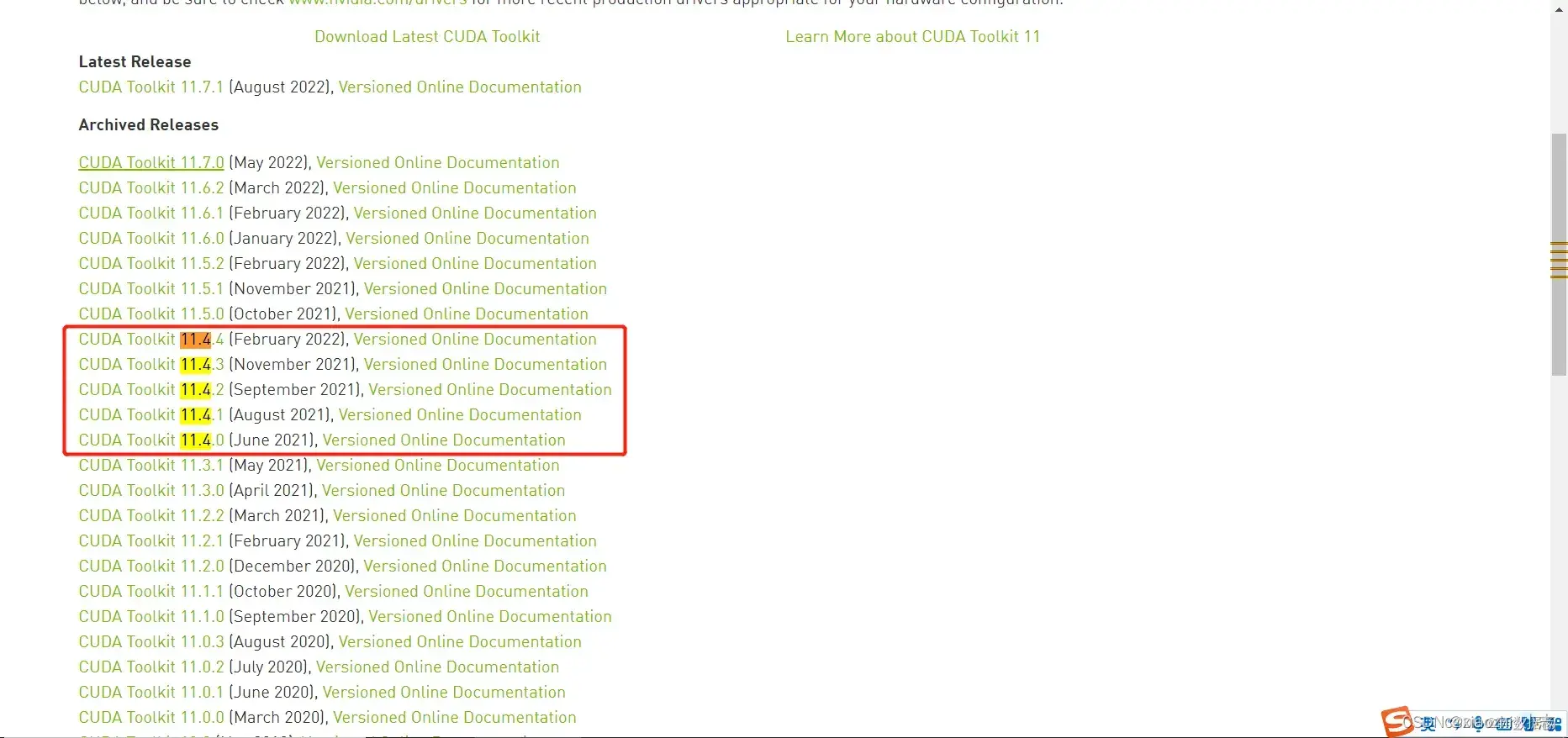
c. 进入NVIDIA官网下载CUDA,找到上一步记录的NVIDIA CUDA后的版本号相对应的链接。如版本信息为11.4就选择11.4
d. 下载完点击安装就行了
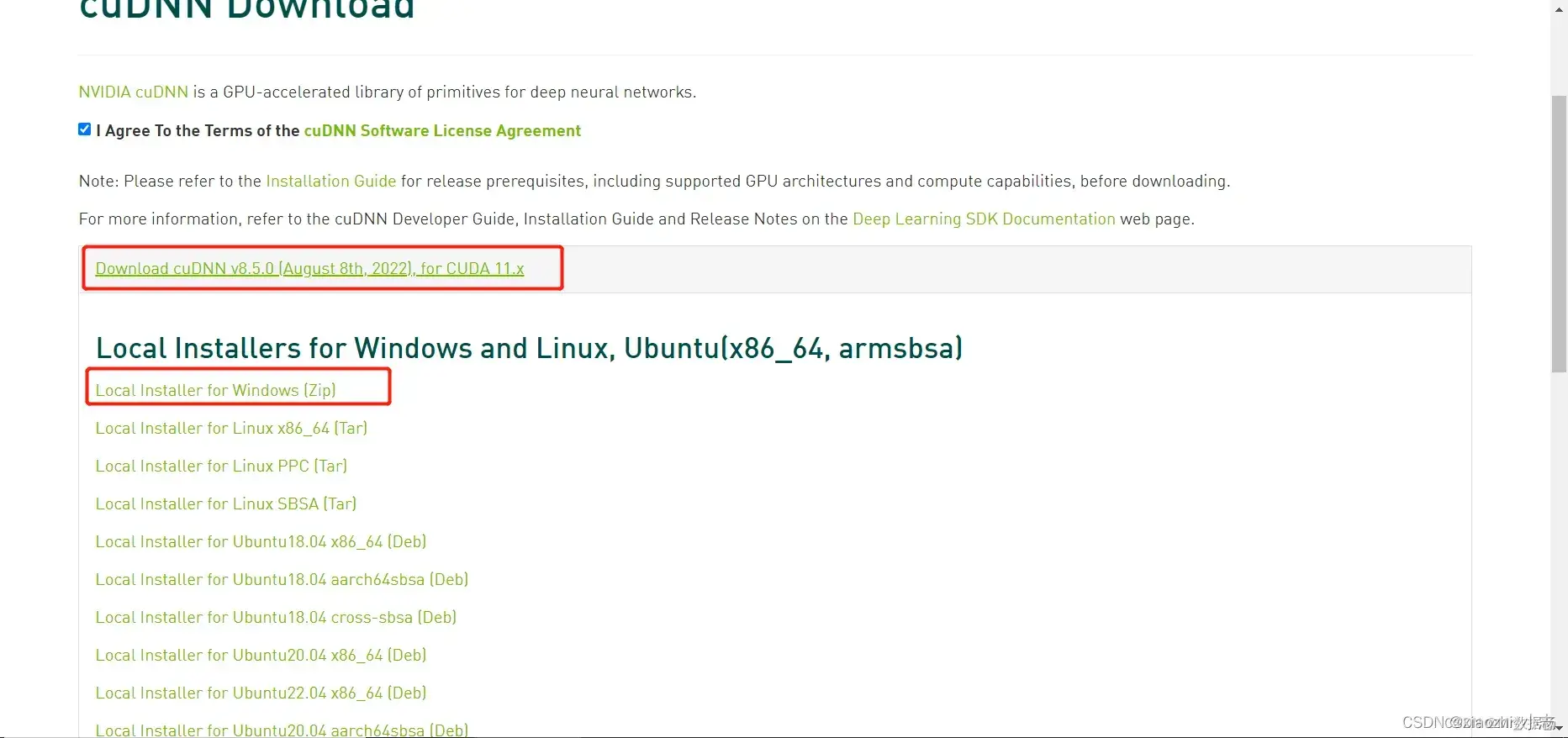
e. 安装cuDNN,选择相应的版本。这个地方要登录账号,没有账号可以注册,也可以选择QQ或微信登录,选择刚才的CUDA版本,下载压缩包
-
pytorch配置
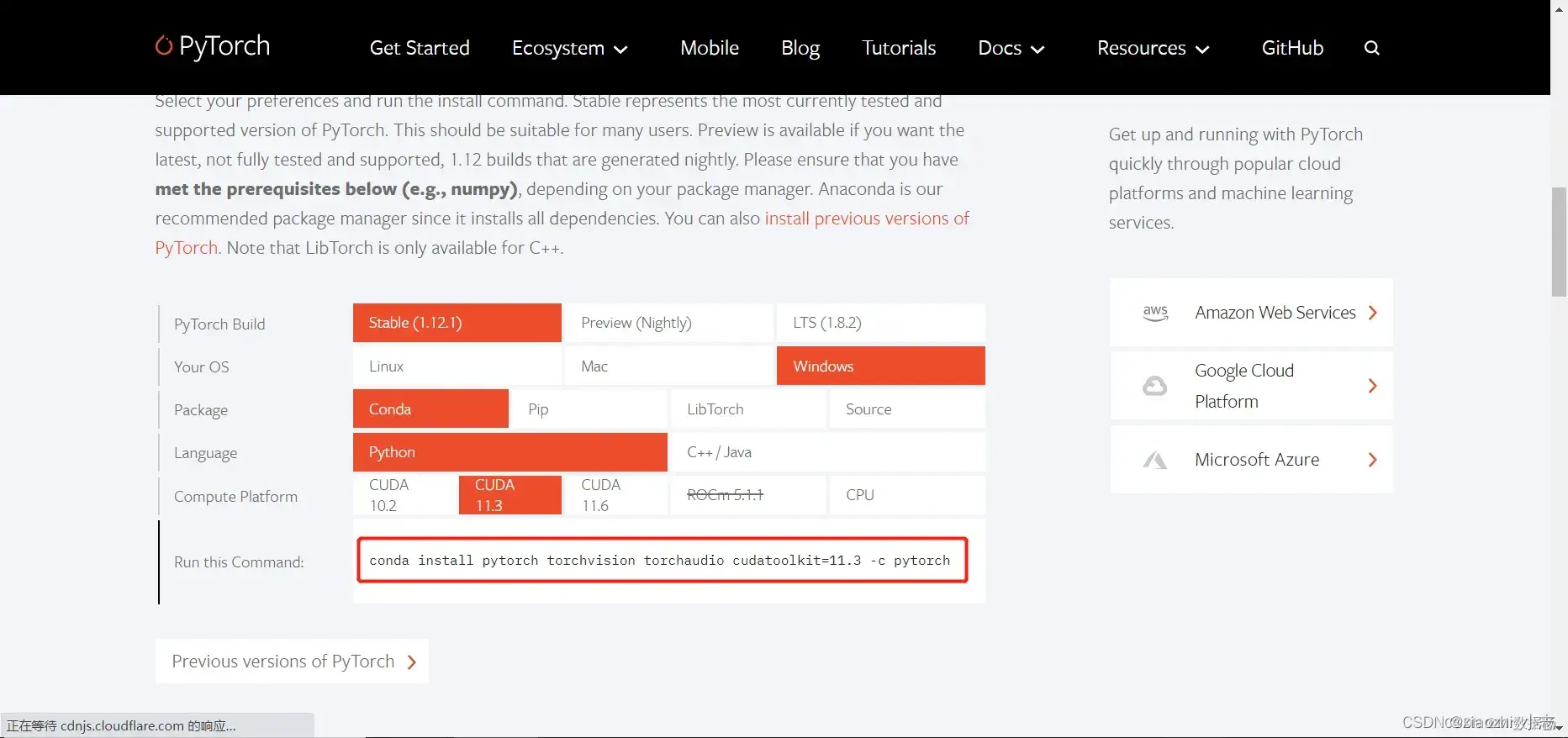
a. 去pytorch官网找到相应的gpu版本或cpu版本,找到后安装命令会出现在command栏
找不到自己的版本点击previous version链接
b. 使用管理员身份执行cmd,否则会安装失败conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch安装完成之后执行命令
conda list查看是否安装成功打开终端输入
python,使用以下代码查看torch显示GPU不可用状态>>>import torch >>>torch.cuda.is_available() Falsec. 标准查看torch版本
>>>import torch >>>torch.__version__ 1.10.2 -
pytorch轮子配置
a. whl轮子配置,根据CUDA版本选择相应的版本。其中cu表示GPU版本,cpu表示CPU版本
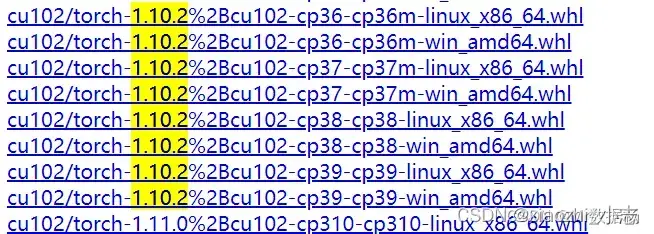

b. 下载完成之后本地使用pip install安装pip install .\torchvision-0.13.1+cpu-cp39-cp39-win_amd64.whl pip install .\torch-1.10.2+cu113-cp39-cp39-win_amd64.whlc. 安装完成之后验证
torch>>>import torch >>>torch.cuda.is_available() True
创建虚拟环境
- 为了能够顺利使用环境,推荐使用
python3.7.1版本conda create -n venv_name python=3.7.1 - 激活 虚拟环境
conda activate venv_name - pip安装所需库
pip install transformers==2.1.1 pip install tensorflow==2.0.0 pip install numpy pip install tqdm pip install sklearn pip install keras pip install tb-nightly pip install future pip install thulac pip install setuptools==59.5.0 pip install torch==1.10.2+cu113 torchvision==0.3.0 --extra-index-url
训练&预测
项目结构
- config: 存放模型的配置文件
- data: 存放训练数据
- model: 存放模型
- cache: 用于模型训练之前的数据预处理
- sample: 用于存放生成样本的目录
- generate.py: 生成代码
- train.py: 训练多文本启动代码
- train_single.py: 训练但文本启动代码
- tokenizations: 用于文本数据转换tokenizations的脚本
模型预测续写
参数说明:
- length: 生成的最长长度
- prefix: 文章开头
- fast_pattern: 快速生成模式
- save_samples: 保存生成文本结果的位置
- temperature: 越小越遵循训练样本,续写的内容的思维越发散
# 通用模型预测文本 python ./generate.py --length=100 --nsamples=4 --prefix=天津是一座美丽的城市。 --fast_pattern --save_samples ----model_path=model/use_model --model_config=config/model_config_small.json --topk=8 --temperature=0.8 --batch_size=2 # 制定模型输出 python ./generate.py --length=300 --nsamples=4 --prefix=萧炎,斗之力。 --fast_pattern --save_samples --model_path=model/model_epoch18 --model_config=model/model_epoch18/config.json --topk=8 --temperature=1 --batch_size=1
其他参数参考:

训练模型
将训练语料以train.json的格式放入data目录中
如果文件格式为train.json格式,那么将train.py文件中的读取方式为:lines = json.load(f)
如果文件格式为train.txt格式,即数据格式为[”正文1“, ”正文2“, ”正文3“],那么将train.py文件中的读取方式为:lines = f.readlines()
运行train.py文件并设定--raw参数,会自动预处理数据,预处理完成之后,会自动执行训练。
python train.py --raw
遇到的问题及解决办法
显存不足
- 语料太大:在
config文件中选择小一点的json文件 - batch_size过大:默认训练是8,可以改成4或者6尝试
生成的内容一样
- 修改
generate.py中的batch_size=1
文末
此训练结果生成比较简单的文章还可以,但是需要达到理想的效果,还需要更大的数据体系和语料以及长期的模型训练,基于原有的算法二次开发,门槛也比较高,而且这种业务比较吃硬件资源。
文章出处登录后可见!
已经登录?立即刷新