(74条消息) Cox与KM生存分析及结果解读 不同的生存分析方法 单因素和多因素生存分析的比较km cox回归分析差异_YoungLeelight的博客-CSDN博客
(64条消息) 分类,等级,或者有序变量如何进行多因素Cox回归 变量的类型决定了最终结果的reference_YoungLeelight的博客-CSDN博客
一文理清回归分析思路及方法选择 – 知乎 (zhihu.com)
Cox比例风险回归(Cox ProportionalHazards Model)
在医学研究中,观察对象生存时间往往受到多个因素的影响。例如,研究某肿瘤患者生存时间与治疗措施的关系,患者的生存时间不仅与治疗措施有关,还受病人的年龄、性别、病情、心理、环境、社会等因索的影响,如果要显示治疗措施的效果,除了治疗措施不同以外,其他影响因素应尽可能相同或相近.这时采用多变量分析方法能够分析包括治疗措施在内的可能因素对生存时间的影响。因为生存时间资料的分布往往不服从正态分布(大多为正偏态分布),有时甚至不知道它的分布类型,这样就不能采用多重线性回归方法分析。本节介绍的Cox比例风险回归模型(Cox proportional hazard model)可以分析多个因素对生存时间的影响,而且允许有截尾数据存在,是生存分析中最重要的多因素分析方法。
例16.3 为研究急性淋巴细胞性白血病患者的生存时间与其预后因素的关系,某研究者随访了50例急性淋巴细胞性白血病患者,获得其生存时间(月)及有关预后因素资料。其中, x1 为入院时白细胞数( ×109/L ) , x2 为淋巴结浸润度(分为0,1,2三级), x3 为缓解出院后的巩固治疗( x3=1 为有巩固治疗, x3=0 为无巩固治疗),随访的终点事件是死于白血病。
由于此资料为随访的生存资料,且影响因索有多个,故需采用Cox比例风险回归分析解决。本节将以此为例,介绍Cox比例风险回归分析的模型构建、分析步骤及实际应用等。
一、 Cox比例风险回归分析的基本原理
(一)基本概念
生存分析的主要目的是研究协变量(自变量) X 与观察结果即生存函数 S(t,X) 之间的关系,当 S(t,X) 受到协变量的影响时,传统的方法是考虑回归分析,即各协变量对 S(t,X) 的影响。由于生存数据中包含有截尾数据,用一般的回归分析难以解决上述问题。生存分析中一个很重要的内容是探索影响生存时间或生存率的危险因素,这些危险因素可通过影响各时刻的死亡风险(即风险率)而影响生存率,不同特征的人群在不同时刻的风险率函数不同,通常将风险率函数表达为基准风险率函数与相应协变量函数的乘积,即
h(t,X)=h0(t)∙f(X)
注:我们假设最开始的风险是一致的,不同协变量函数可以认为是在这个基准之上的作用。这样就可以区分不同协变量之间是有利于减小风险率还是增大风险率。即可以知道哪些是危险因素。
式中, h(t,X) 表示t时刻的风险率函数又称瞬时死亡率。 h0(t) 表示t时刻的基准风险率函数,即t时刻所有的协变量取值为0时的风险率函数; f(X) 为协变量函数。最常用协变量函数模型是对数线性模型,即 f(X)=e∑j=1mβjxj ,j=1,2,…,m为模型中协变量的个数,当基准风险率函数 h0(t) 已知时, h(t,X)=h0(t)∙f(X) 为参数模型。例如,当 h0(t)=λ 时,为指数回归模型; h0(t)=λtγ−1 时,为Weibull模型。 1972年,英国生物统计学家D.R Cox提出在基准风险率函数未知的情况下估计模型参数的方法。后人将该模型称为Cox比例风险回归模型,简称Cox回归。
注:因为基准风险率函数未知,所以不能称之为参数模型。只能说是半参数模型。
(二)Cox回归模型的基本形式
基本形式为:
h(t,X)=h0(t)∙e(β1×1+β2×2+…+βmxm)
式子中 β1,β2,…,βm 为自变量的偏回归系数。
h0(t) 分布无明确的假定,一般也是无法估计的,这是非参数部分;另一部分是参数部分,其参数是可以通过样本的实际观察值来估计的。正因为Cox回归模型由非参数和参数两部分组成,故又称为半参数模型。
对上式做对数变换可得:
ln[h(t,X)/h0(t)]=β1×1+β2×2+…+βmxm
因此,Cox回归模型与一般的回归分析不同,协变量对生存时间的影响是通过风险函数和基准风险函数的比值反映的。其中的风险函数和基准风险函数是未知的。在完成参数估计的情况下,可对基准风险函数和风险函数做出估计,并可计算每一个时刻的生存率。
(三) Cox回归模型的建模假设
1、比例风险假定 各危险因素的作用不随时间变化而变化,即 h(t,X)/h0(t) 不随时间变化而变化。因此应注意Cox回归模型要求风险函数与基准风险函数呈比例。如果这一假定不成立,则不能用Cox回归模型进行分析。
2、对数线性假定 模型中的协变量应与对数风险比呈线性关系。
(四)Cox回归模型中偏回归系数的意义
模型中偏回归系数 βj 的意义是当其他协变量固定不变时,协变量 xj (j=1,2,…,m)变化一个单位,其对数风险比的改变量。假定只有一个协变量 x ,其为二分类变量( x=1 为暴露于某因素, x=0 为未暴露于该因素),建立的Cox回归模型为 h(t,X)=h0(t)∙e(βx) 。则暴露与未暴露的相对危险度RR的计算为:
RR=h(t,X|x=1)h(t,X|x=0)=h0(t)∙e(β×1)h0(t)∙e(β×0)=eβ
可见,回归系数 βj 又可解释为固定其他自变量时,自变量 xj 每改变一个单位,得到的相对危险RR的对数值。这个解释在生存时间的危险因素分析中更常用。若 βj>0,则 RR>1 ,该因素为危险因素;若 βj<0 ,则 RR<1 该因素为保护因素;若 RR=1 ,该因素为无关因素。
二、 Cox回归分析的步骤
(一)变量赋值与数据准备
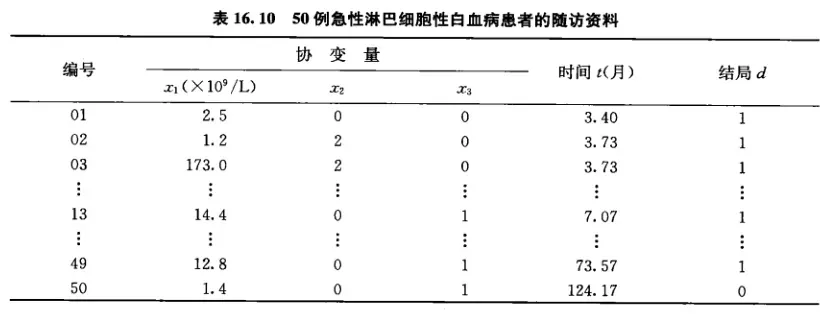
Cox回归模型中的协变量可以是分类变量或定量变量。对协变量的合理赋值十分重要,其赋值方法同logistic回归分析中的变量赋值方法。由于生存资料往往包括研究对象的生存时间和截尾变量,因此在进行Cox回归分析时最好先进行数据整理。例如,在例16.3中,用t表示生存时间变量,用d表示截尾变量(d=1表示出现结局,d=0表示截尾数据),其数据整理如下表。
(二)参数估计
偏回归系数的估计Cox模型中,由于其基准风险函数的分布不明确,因此不能用一般最大似然法来估计其参数,是用偏似然函数估计。
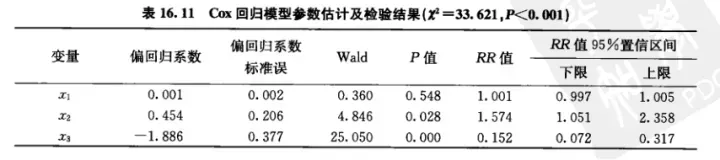
参数估计结果如下表:
(三)假设检验
模型参数的假设检验常用的方法有似然比检验、计分检验、 Wald检验等方法。Component-wise likelihood based boosting for variable selection
这里只介绍Wald检验:用于检验模型中的协变量是否应从模型中剔除,也可检验模型中第j个因素对模型的贡献是否有统计学意义。 Wald检验统计量为:
χ2=(βjSβj)2
其服从自由度为1的 χ2 分布。同线性回归分析和logistic回归分析类似,当自变量个数较多时,Cox回归可采用前进法、后退法和逐步法等方法筛选变量。
α=0.05 检验水准上所建立的Cox回归模型成立 ,(χ2=33.621,P<0.001) ,入院时白细胞数的偏回归系数 x1 无统计学意义,淋巴结浸润度 x2 和缓解出院后的巩固治疗 x3 的偏回归系数有统计学意义,去除无统计学意义的 x1 后,重新拟合cox回归模型的结果如下表
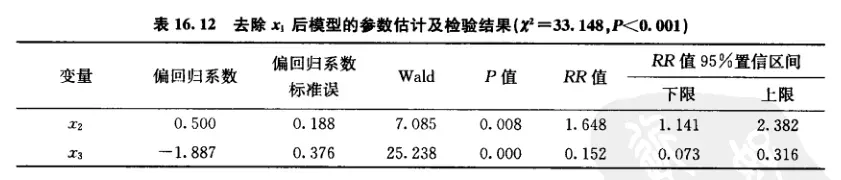
可见,α=0.05 检验水准上所建立的Cox回归模型成立 ,(χ2=33.148,P<0.001) .淋巴结浸润度 x2 和缓解出院后的巩固治疗 x3 的偏回归系数均有统计学意义。cox回归模型可表示为:
h(t,X)=h0(t)∙e(0.500×2−1.887×3)
(四)模型评价
考察cox回归模型拟合优度的方法最常用的方法为图示法这里不详细展开
(五)模型诊断
最重要的是要考虑比例风险假设是否满足以及协变量之间是否存在多重共线性。
(六)回归分析结果的解释:略
三、Cox回归模型的用途和条件
(一)用途
Cox回归模型的主要用途有:
- 建立以多个危险因素估计生存或者死亡的风险模型,并由模型估计各危险因素的相对危险度RR。
- 用已建立的模型,估计患者随时间变化的生存率
- 用已建立的模型,估计患病后的危险系数(或预后系数)
(二)应用条件
Cox回归模型的应用条件有:
- 自变量可以为定量资料也可为分类资料。
- 自变量取值不随时间变化
- 样本含量要足够大,且截尾数据不能过多,死亡数不能过少,因素各水平的例数也不能过少
从一篇新英格兰文章看懂K-M曲线与Cox的关系
2018-12-06 15:00
各位学友好,今天来看一个虽然没有什么可比性,但是大家很容易混淆的两个概念,Kaplan-Meier 曲线(简称K-M曲线) 和Cox回归。
用一张PPT来概括就是这样的:当我们需要描述生存分析数据时,我们常常使用生存曲线来展示,这个时候需要估计每个时间点位的生存率,用的就是K-M方法。因此准确来说,K-M方法是一种统计描述方法,就好比用饼状图来展示比例,用箱图来展示连续变量。
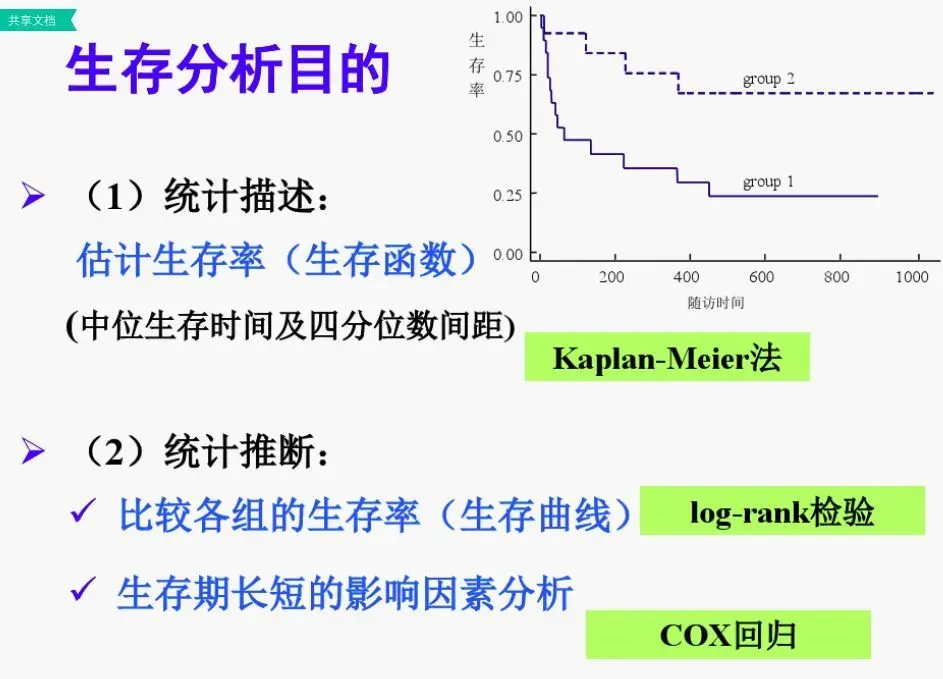
相比于之前使用的寿命表法(Life-table method),这种方法更加充分地利用了信息,给出更准确的统计量。同时,作为一种非参数估计方法,不要求总体的分布形式,因此非常适合生存分析时使用。K-M曲线还可以很直观地表现出两组或多组的生存率或死亡率,非常适合在文章中进行展示。因此,K-M曲线也成为了生存分析中最常用的方法之一。
只有描述是不够的,我们还需要进行统计推断,也就是比较。因为生存数据往往都是非正态分布,因此常使用非参数的检验方法,也就是log-rank检验,这就类似于对于非正态连续变量比较使用的方差分析。因此在实际写作中,K-M曲线都会搭配log-rank检验的P值,这样才算完整。
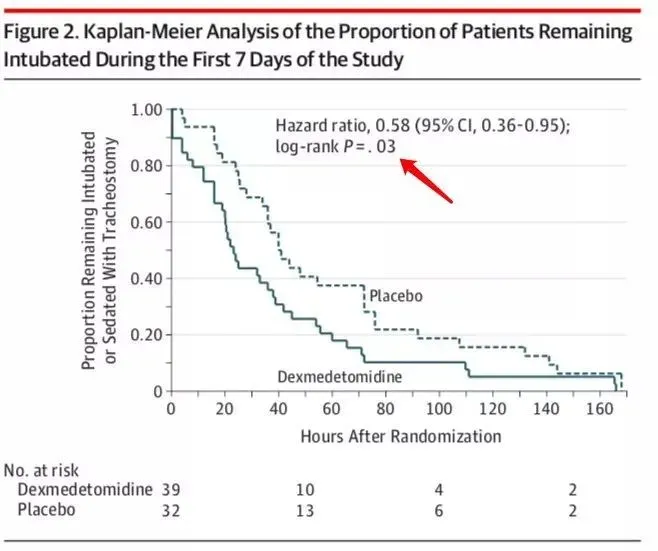
说完了K-M曲线,下面我们就说说Cox回归,从上面的PPT里面可以看到Cox回归和log-rank检验都属于统计推断的方法,那么Cox回归什么时候用呢?这时候就需要简单说一说Cox回归的定义了:
Cox回归本质上是一种回归模型,它没有直接使用生存时间,而是使用了危险度(hazard)作为因变量,该模型不用于估计生存率,而是用于因素分析,也就是找到某一个危险因素对结局事件发生的贡献度。
本质上和logistics回归更为相似,只是Cox回归考虑了时间,核心结果为HR/RR,而logistics回归没有考虑时间,核心结果为OR。
同时因为本身为回归模型,所以Cox可以进行多因素分析,K-M曲线log-rank检验只能进行单因素分析,这是两者的重要区别。

说完了定义上的区别,我们来看2004年发表在新英格兰NEJM的一篇文章。这篇文章写的是一个RCT研究,观察某个药物和对照药物对肺腺癌的治疗效果,纳入999个病人,随访了5年的时间,是一个典型的生存分析。

文章的统计描述部分是怎么写的:

里面几句话翻译过来就是:
使用K-M方法绘制生存曲线,使用log-rank检验评估生存差异。使用Cox比例风险模型进行多因素分析,评估预后因素作用。
这计划的表述非常清晰,我们可以看到生存数据的评估使用的是K-M方法,区别假设使用的是log-rank检验,预后因素的评估使用的是Cox多因素回归。这个时候我们再看对应的图表就会非常清晰了:
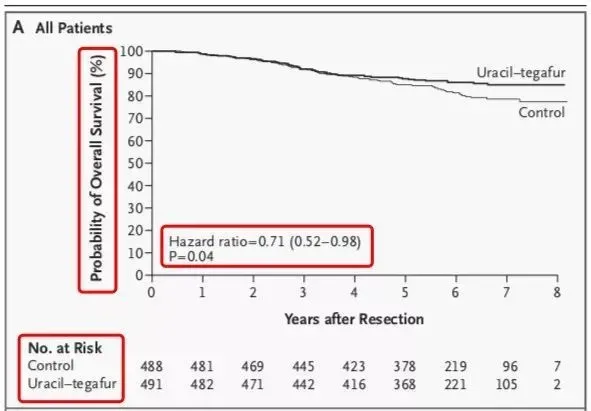

图1是文章的主要结论,两组的log-rank检验p值<0.05,HR=0.71,说明试验药物相对对照组可以减少时间的发生风险,提高生存时间,且差异具有显著性。
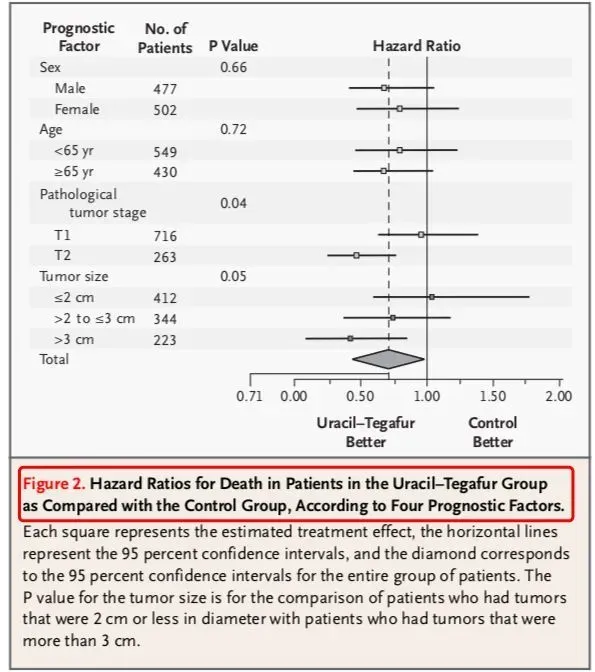
图2则是使用森林图的方式展示了四个分层之内两组之间的风险比HR,这里用到的就是Cox回归分析。
两种方法相互补充,充分完整的展示了在一个研究中,生存数据的“样貌”和不同因素对结局事件的影响,大家可以把这篇文章找出来看一看。同时,其中的统计描述部分写法很专业,如果你在写生存分析的文章,不妨直接拿来借鉴。
好了,以上就是关于K-M曲线、log-rank检验、Cox回归之间的“爱恨情仇”
文章出处登录后可见!