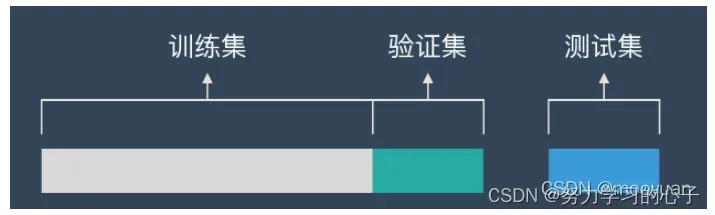
1、训练集
用来构建模型,通过训练拟合一些参数建立分类器。
2、验证集
用于确定网络结构以及调整模型的超参数。
使用验证集的目的就是为了快速调参(如网络层数、网络节点数、迭代次数等等),从而获得当前最优模型。
验证集是在训练集中划分出的一部分。
验证集不是必须要有的!
3、测试集
用来评估最终模型好坏。

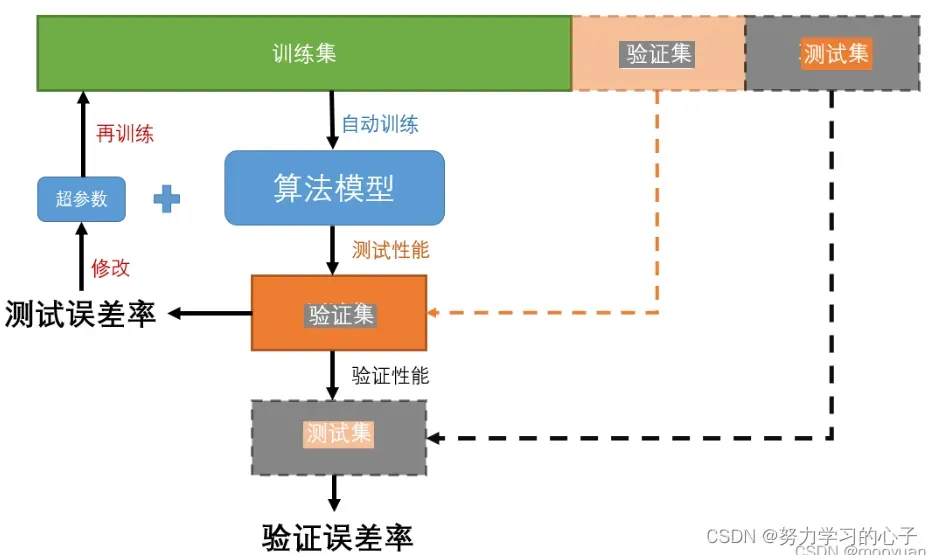
4、是否需要划分验证集判断
4.1划分验证集
如果样本数量为万级以上,可以考虑划分为训练集(60%)、验证集(20%)、测试集(20%);
如果样本数量达到百万级以上,验证集和测试集都留1W即可;
超参数越少或者容易调整,可以减少验证集比例,更多的分配给训练集。
4.2不需要划分验证集
如果样本数量少于1w,可以不用划分验证集,采用交叉验证训练优化选择模型。
5、交叉验证
5.1简单交叉验证
所谓简单是相对于其他交叉验证方法而言的。
随机将样本划分为训练集(70%)和测试集(30%),用训练集训练模型,用测试集验证模型及参数。接着再把样本打乱,重新选择训练集和测试集,继续训练模型和验证模型。最终选择损失函数评估最优模型和参数。
5.2 K折交叉验证
将样本随机划分为K个大小相同的互斥的子集,每次选K-1个作为训练集,剩的那个作为测试集。重复若干次(小于K)后,选择损失函数评估最优模型和参数。
这种方法评估结果的稳定性和保真性很大程度上取决于K的选择。
5.3留一交叉验证
是K折交叉验证的特例,适用于样本数量很少的情况。
该方法中,K等于样本数量N,每次选择N-1个样本进行训练,剩的1个样本进行测试。
5.4三种方法的选择
如果只是做个初步的模型建立,不是做深入分析的话,选择简单交叉验证,否则用K折交叉验证;在样本量少的情况下,使用留一交叉验证。
5.5交叉验证函数
cross_val_predict和cross_val_score都是交叉验证函数,区别主要是而这返回的评估结果不一样。
①、cross_val_predict:返回的是与样本数量个数一样的分类结果或者预测值。可以通过该预测输出与实际目标值做对比,准确定位到预测出错的地方,有利于参数优化和问题排查。输出的预测值可以用于计算PR曲线和ROC曲线。


其中,Ytrain为正确的标签,y_score为输出概率值,thresholds1为阈值,当 y_score>thresholds1时预测为正样本;当 y_score<thresholds1时预测为负样本。注意,输出的precision和recall最后一个值分别为1和0,并且没有对应的阈值。
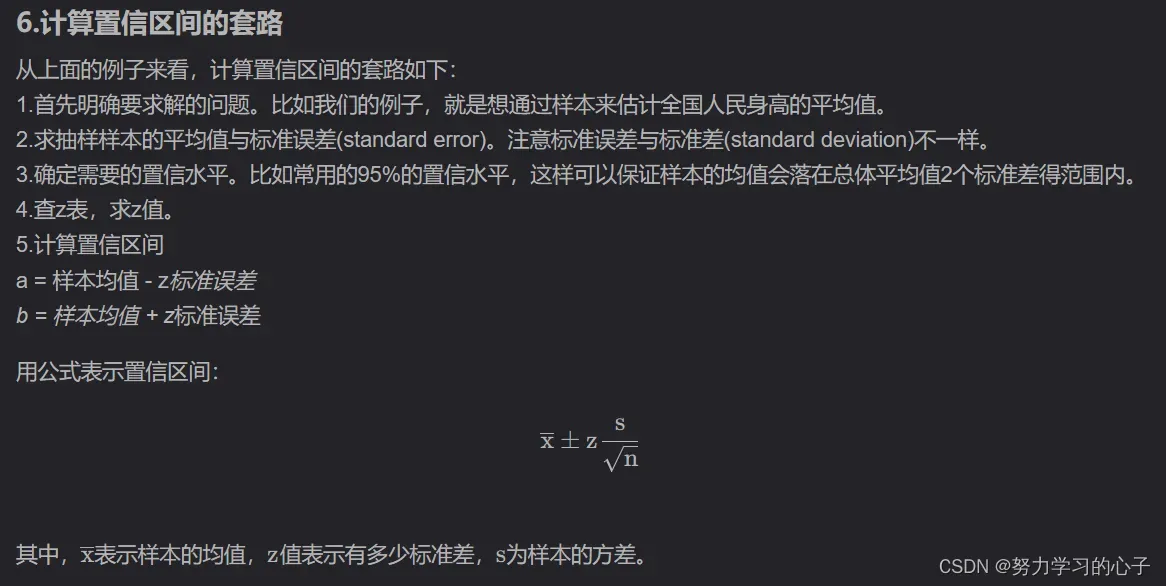
②、cross_val_score:输出的是每一折的得分(准确率),K个得分取平均值就是模型的平均性能。最终输出的Accuracy可以由平均得分和95%置信区间共同得出。
cross_val_predict的输出结果不可以作为模型泛化性能参考;cross_val_score可以作为模型泛化性能的参考。

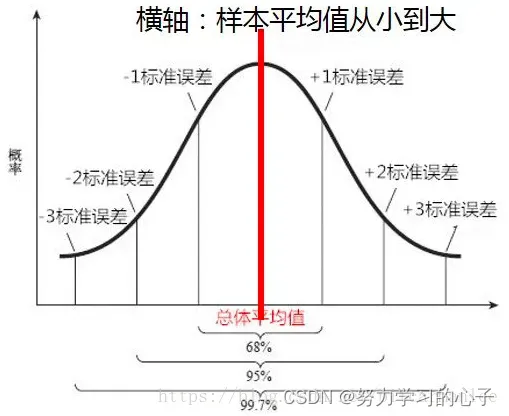
5.6置信区间
表示估计的准确度或精确度。






文章出处登录后可见!