一、BERT的基本理念
BERT是Birdirectional Encoder Representation from Transformers的缩写,意为多Transformer的双向编码器表示法,它是由谷歌发布的先进的嵌入模型,BERT是自然语言处理领域的一个重大突破,它在许多自然语言处理任务中取得了突出的成果,比如问答任务,文本生成,句子分类等等,BERT成功的一个主要原因是,它是基于上下文的嵌入模型,这是它与其他流行的嵌入模型的最大不同,首先让我么了解有上下文的嵌入模型和无上下文的嵌入模型之间的区别,如以下两个句子
A:he got bit by python(他被蟒蛇咬了)
B:python is my favorite programming lauguage(python是我最喜爱的编程语言)
如果使用上下文无关的的嵌入模型进行计算单词python的嵌入值,则两个句子中python嵌入值相同,因为它会忽略语境
BERT是一个基于上下文的模型,它先理解预警,然后根据上下文生成该词的嵌入值,对于上面两个句子它将生成python不同的嵌入值,BERT将该句中的每个单词与句子中的所有单词相关联,以了解每个单词的上下文含义
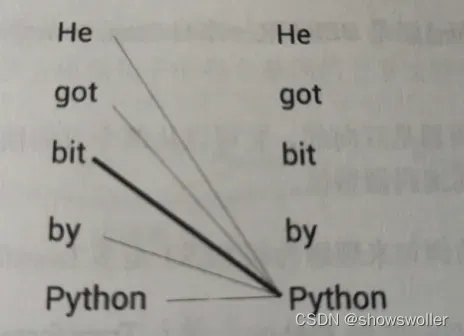

由此可见,与上下文无关的模型生成的静态嵌入不同,BERT能够根据语境生成动态嵌入
二、BERT的工作原理
顾名思义,BERT是基于Transformer的,我们可以把它看成只有编码器的Transformer
Transformer的编码器是双向的,它可以从两个方向读取一个句子,因此BERT由Transformer获得双向编码器特征,通过BERT模型,对于一个给定的句子,我们可以获得每个单词的上下文特征
三、BERT的配置
BERT的研究人员在发布该模型是提出了两种标准配置
BERT-base
BERT-large
1:BERT-base
它由十二层编码器叠加而成,每层编码器都使用十二个注意力头,其中前馈网络层由768个隐藏神经元组成,所以它得到的特征向量的大小为768
我们使用符号来表示上述内容
编码器的层数用L表示
注意力头的数量用A表示
隐藏神经元的数量用H表示
它的网络参数总数可达1.1亿个
2:BERT-large
该模型由二十四层编码器叠加而成,每层编码器都使用十六个注意力头,其中前馈网络层包含1024个隐藏神经元,所以得到的特征向量大小为1024
它的网络参数可达3.4亿个
3:BERT的其他配置
除了上述两种标准配置外,BERT还有多种不同的配置,下面列举一些小型配置
BERT-tiny L=2 H=128
BERT-mini L=4 H=256
BERT-small L=4 H=512
BERT-medium L=8 H=512
在计算资源有限的情况下,我们可以使用较小的BERT配置,但是标准的BERT配置可以得到更准确的结果并且应用更为广泛
创作不易 觉得有帮助请点赞关注收藏~~~
文章出处登录后可见!