目录
一、变量和字符串
1、python转义字符

2、交换x,y变量的值
>>> x = 5
>>> y = 3
>>> x,y = y,x
>>> print(x,y)
3 53、原始字符串,忽略转义字符
在引号前加r,或者使用“\”对转义字符进行转义。
>>> print("D:\three\two\one\now")
D: hree wo\one
ow
>>> print(r"D:\three\two\one\now")
D:\three\two\one\now
>>> print("D:\\three\\two\\one\\now")
D:\three\two\one\now4、长字符串两种方式
1.长代码换行方式:句尾加一个反斜杠
>>> print("下面有一句话\n\
下面还有一句话\n\
这是一个长字符串\n")
下面有一句话
下面还有一句话
这是一个长字符串2.使用三引号(三个双引号或者三个单引号配套使用)
print("""下面有一句话
下面还有一句话
这是一个长字符串""")
下面有一句话
下面还有一句话
这是一个长字符串5、字符串加法和乘法
>>> print("520"+"1314")
5201314
>>> print("520"*10)
520520520520520520520520520520二、是时候讲讲代码了
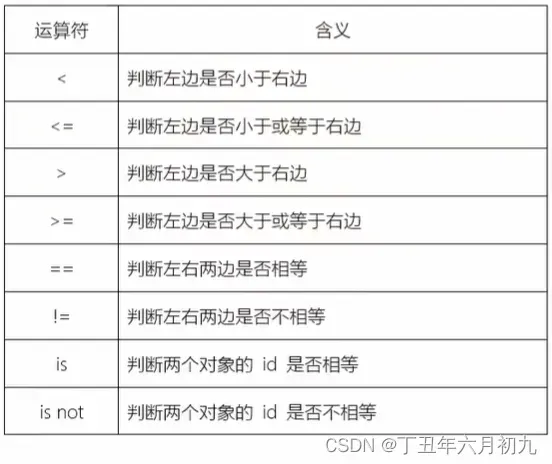
1、python比较运算符
三、改进小游戏
1、python随机模块random
randint(x,y)函数,参数x,y表示获取随机数的范围。
>>> import random
>>> num = random.randint(1,100)
>>> print(num)
2
>>> num = random.randint(1,100)
>>> print(num)
682、重现random随机数
random模块使用操作系统系统时间作为随机数种子,也就是随机数生成器内部状态
getstate()函数可以获得随机数生成器内部状态,并可以将其存入一个变量中
setstate()函数可以将当前的随机数生成器内部状态进行重新设置
>>> x = random.getstate()
>>> random.randint(1,100)
9
>>> random.randint(1,100)
99
>>> random.randint(1,100)
60
>>> random.randint(1,100)
26
>>> random.setstate(x)
>>> random.randint(1,100)
9
>>> random.randint(1,100)
99
>>> random.randint(1,100)
60
>>> random.randint(1,100)
26四、数字类型
1、python中的浮点数精度较低
>>> 0.1+0.2
0.30000000000000004
>>> 0.3 == 0.1+0.2
False2、如何精确的计算浮点数:decimal模块
使用前先实例化对象decimal.Decimal()
>>> import decimal
>>> a = decimal.Decimal('0.1')
>>> b = decimal.Decimal('0.2')
>>> print(a + b)
0.3
>>> c = decimal.Decimal('0.3')
>>> c == a + b
True3、python使用科学计数法,E记法。
5e-08表示5*10的-8次方
>>> 0.00000005
5e-084、复数
>>> 1+2j
(1+2j)
>>> x = 1+2j
>>> x.real
1.0
>>> x.imag
2.05、python支持的数字运算

x \\ y 地板除向下取整
>>> 3 // 2
1
>>> -3 //2
-2x % y所得为余数
x == (x // y) * y + (x % y)
pow()函数有隐藏第三个参数,pow(x , y , z),相当于 x ** y % z
>>> pow(2, 3, 5)
3
>>> 2 ** 3 % 5
3五、布尔类型
1、bool()函数
返回false的所有情况

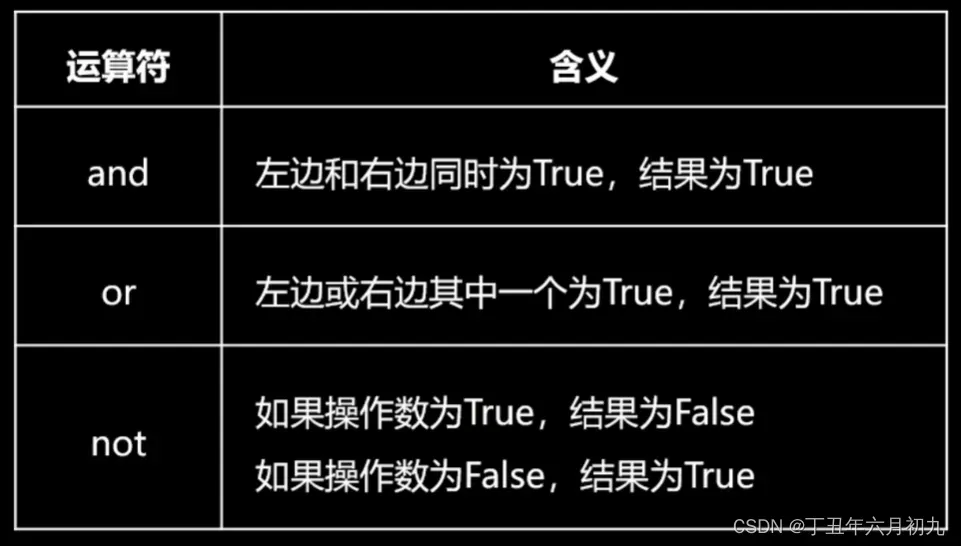
2、python逻辑运算符
and:同真为真,一假则假。or:同假为假,一真则真。
3、and和or遵从短路逻辑的思想
即只有当第一个操作数的值无法确定逻辑运算的结果时,才对第二个操作数进行求值。
>>> (not 1) or (0 and 1) or (3 and 4) or (5 and 6) or (7 and 8 and 9)
4
>>> not 1 or 0 and 1 or 3 and 4 or 5 and 6 or 7 and 8 and 9
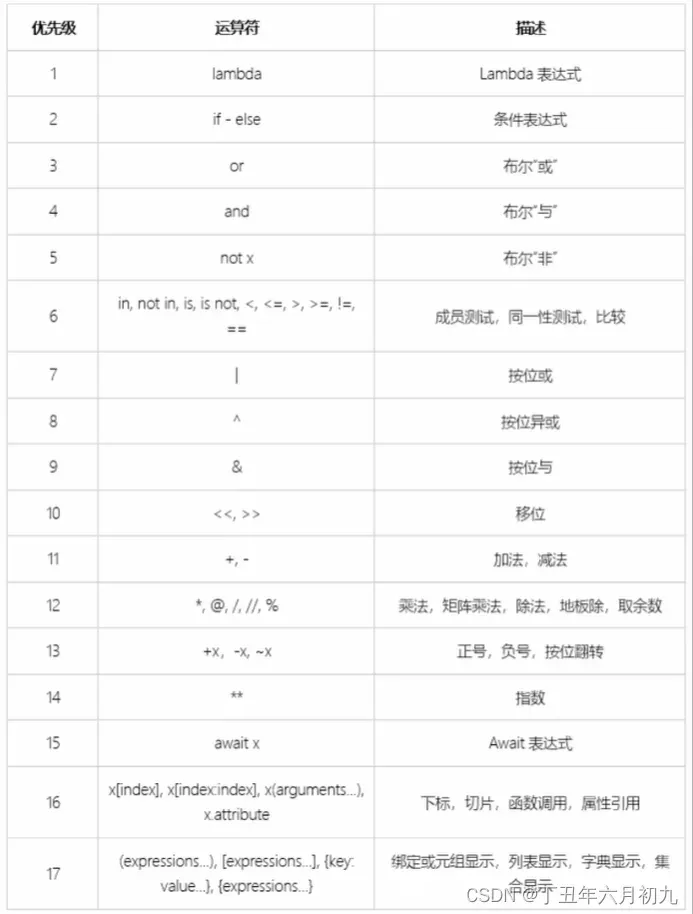
44、python运算符优先级
六、分支和循环
1、条件表达式
语法:满足条件的执行语句 if 判定条件 else 不满足条件的执行语句
>>> if 4 > 3:
print("确实")
else:
print("胡扯")
确实
>>> print("确实") if 4 > 3 else print("胡扯")
确实
\\用一句代码比较两个变量的大小并将小的数赋值给small变量
>>> import random
>>> x = random.randint(1,100)
>>> y = random.randint(1,100)
>>> small = x if x < y else y
>>> small
23
>>> x
23
>>> y
59
>>> small = x if x < y else small = y
SyntaxError: cannot assign to conditional expression在条件表达式中的执行语句只能是表达式,不能是语句
\\用条件表达式给分数划分等级
>>> score = 80
>>> if 0 <= score < 60:
level = 'E'
elif 60 <= score < 70:
level = 'D'
elif 70 <= score < 80:
level = 'C'
elif 80 <= score < 90:
level = 'B'
elif 90 <= score <= 100:
level = 'A'
else:
level = '请输入0-100的数字'
>>> level
'B'
>>> score = 100
>>> level = ('F' if 0 <= score < 60 else
'D' if 60 <= score < 70 else
'C' if 70 <= score < 80 else
'B' if 80 <= score < 90 else
'A' if 90 <= score <= 100 else
'请输入0-100的数字')
>>> level
'A'当语句过长需要跨数行时可以使用小括号将语句括起来,或者是在句尾加\
2、while循环
break和continue
循环里面的else:当循环的条件不为真的时候,执行else中的语句。
其与直接跟在循环体后的语句的区别在于循环体内是否有break。即循环体内部的break可以跳过else中的语句。
主要的作用是用来检测循环的退出情况。
i = 1
while i < 5:
print('里面的i:',i)
i += 1
print('外面的i:',i)
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
里面的i: 1
里面的i: 2
里面的i: 3
里面的i: 4
外面的i: 5
>>>
i = 1
while i < 5:
print('里面的i:',i)
i += 1
else:
print('外面的i:',i)
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
里面的i: 1
里面的i: 2
里面的i: 3
里面的i: 4
外面的i: 5
>>> i = 1
while i < 5:
print('里面的i:',i)
if i == 2:
break
i += 1
print('外面的i:',i)
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
里面的i: 1
里面的i: 2
外面的i: 2
>>>
i = 1
while i < 5:
print('里面的i:',i)
if i == 2:
break
i += 1
else:
print('外面的i:',i)
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
里面的i: 1
里面的i: 2
>>> print()函数中可以使用end参数设置输出以什么符号结束
>>> print('你是谁')
你是谁
>>> print('你是谁',end='?')
你是谁?
>>>print('你是谁?')
print('我是你霸霸!')
你是谁?
我是你霸霸!
>>>print('你是谁?',end=' ')
print('我是你霸霸!')
你是谁? 我是你霸霸!3、for循环
for 变量 in 可迭代对象: 执行语句
>>> for i in 'wdnmd':
print(i,end=' ')
w d n m d range()函数:生成一个数字序列,即为可迭代对象,参数只能是整形
range(stop) , range(start , stop) , range(start , stop , step)
>>> for i in range(5):
print(i, end=' ')
0 1 2 3 4
>>> sum = 0
>>> for i in range(5):#1+2+3+4
sum += i
>>> sum
10
>>> sum = 0
>>> for i in range(3 , 5):#3+4
sum += i
>>> sum
7
>>> sum = 0
>>> for i in range(1 , 10 , 2):#1+3+5+7+9
sum += i
>>> sum
25
>>> for i in range(5 , 1 , -1):
print(i, end=' ')
5 4 3 2 使用for循环嵌套实现找出10以内的素数
for i in range(2, 10):
for j in range(2, i):
if i % j == 0:
break
else:
print(i,'是一个素数')
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
2 是一个素数
3 是一个素数
5 是一个素数
7 是一个素数七、列表
1、列表元素
python中的列表可以存放多种类型的数据
>>> list = [1, 2, 3, 4, 5, '上山打老虎']
>>> print(list)
[1, 2, 3, 4, 5, '上山打老虎']for循环遍历列表元素,下标索引访问列表单个元素list[0]、list[1]
长列表访问列表最后一个元素list[-1]、list[len(list) – 1],索引带符号为反向索引
>>> list[0]
1
>>> list[1]
2
>>> list[-1]
'上山打老虎'
>>> list[len(list) - 1]
'上山打老虎'
>>> list[-3]
4
>>> list[-4]
32、列表切片
list[start: stop: step]
>>> list[0: 3]
[1, 2, 3]
>>> list[3: 5]
[4, 5]
>>> list[: 3]
[1, 2, 3]
>>> list[3:]
[4, 5, '上山打老虎']
>>> list[:]
[1, 2, 3, 4, 5, '上山打老虎']
>>> list[1: 6: 2]
[2, 4, '上山打老虎']
>>> list[1::2]
[2, 4, '上山打老虎']
>>> list[:-1:2]
[1, 3, 5]
>>> list[::-1]#使用切片倒序输出列表
['上山打老虎', 5, 4, 3, 2, 1]3、增,append(),extend(),insert()
append(),在列表末尾添加一个指定元素
>>> list=[1,2,3,4,5,'上山打老虎']
>>> list.append('老虎打不到')
>>> list
[1, 2, 3, 4, 5, '上山打老虎', '老虎打不到']extend(),向列表中最后一个元素后面添加一个可迭代对象
>>> list.extend(['打到小松鼠',5])
>>> list
[1, 2, 3, 4, 5, '上山打老虎', '老虎打不到', '打到小松鼠', 5]insert(x, y):向列表指定位置插入元素,x:指定的插入位置,y:插入的元素
>>> l.insert(len(l),9)
>>> l
[1, 2, 3, 4, 5, 6, 7, 8, 9]使用切片实现以上三个方法
>>> l = [1, 2, 3, 4]
>>> l[len(l):] = [5]#相当于append()
>>> l
[1, 2, 3, 4, 5]
>>> l[len(l):] = [6,7,8]#相当于extend()
>>> l
[1, 2, 3, 4, 5, 6, 7, 8]
>>> l[1:1] = [2]#相当于insert()
>>> l
[1, 2, 2, 3, 4, 5, 6, 7, 8]
>>> l[3:3] = [3,3]
>>> l
[1, 2, 2, 3, 3, 3, 4, 5, 6, 7, 8]4、删,remove()
remove():若列表中存在多个匹配的元素,只会删除第一个。若指定元素不存在,则程序报错。
>>> list = [1, 2, 2, 3, 4, 5]
>>> list.remove(2)
>>> list
[1, 2, 3, 4, 5]
>>> list.remove(6)
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
list.remove(6)
ValueError: list.remove(x): x not in listpop():参数为下标,打印并删除指定下标的元素
>>> list = [1, 0, 2, 4, 8]
>>> list.pop(4)
8
>>> list
[1, 0, 2, 4]clear():清空列表所有元素
>>> list.clear()
>>> list
[]5、改
赋值更改
>>> list = [1, 2, 3, 4, 7]
>>> list[4] = 5
>>> list
[1, 2, 3, 4, 5]切片更改
>>> list = [1, 2, 3, 4, 7]
>>> list[4:5] = [5]
>>> list
[1, 2, 3, 4, 5]
>>> list[2:] = [4, 8, 16]
>>> list
[1, 2, 4, 8, 16]
sort():对纯数字列表进行排序,reverse参数:False为从小到大(默认),True为从大到小。key参数:设定排序对比大小的算法
>>> list = [5,4,9,7,1,32,3,5]
>>> list.sort()
>>> list
[1, 3, 4, 5, 5, 7, 9, 32]
>>> list.sort(reverse = True)
>>> list
[32, 9, 7, 5, 5, 4, 3, 1]
>>> list.sort(reverse = False)
>>> list
[1, 3, 4, 5, 5, 7, 9, 32]
>>> list = ['Python','int','to','do','large']
>>> list.sort(key = len)
>>> list
['to', 'do', 'int', 'large', 'Python']reverse():翻转列表,与元素大小无关
>>> list = [1, 2, 3, 7, 5]
>>> list.reverse()
>>> list
[5, 7, 3, 2, 1]6、查,count(),index(),copy()
count():返回参数的元素所出现的次数
index(x, start, end):x:查找元素x的索引值,多个相同元素返回第一个下标。start、end:指定查找的开始结束位置。
copy():以及切片实现copy()都是浅拷贝。
>>> list = [1, 3, 4, 5, 5, 7, 9, 32]
>>> list.count(5)
2
>>> list.index(5)
3
>>> list.index(5, 4, 7)
4
>>> list1 = list.copy()
>>> list1
[1, 3, 4, 5, 5, 7, 9, 32]
>>> list2 = list[:]#使用切片实现copy()
>>> list2
[1, 3, 4, 5, 5, 7, 9, 32]7、列表的加法和乘法
加法是拼接两个列表,乘法是重复列表内所有元素若干次
8、嵌套列表
二维列表,矩阵
访问嵌套列表需要使用嵌套循环实现
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]#通过值创建二维列表
>>> matrix
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> matrix = [[9, 8, 7],
[6, 5, 4],
[3, 2, 1]]
>>> matrix
[[9, 8, 7], [6, 5, 4], [3, 2, 1]]
>>> A = [0]*3#使用循环创建列表
>>> for i in range(3):
A[i] = [0] * 3
>>> A
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> for i in matrix:#遍历二维列表
for j in i:
print(j)
9
8
7
6
5
4
3
2
1
>>> for i in matrix:
for j in i:
print(j,end=' ')
print('\n')
9 8 7
6 5 4
3 2 1
>>> matrix[0][0]#访问二维列表单个元素
9>>> A = [[0] * 3] * 3#不能使用该方法创建列表
>>> A
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> A[0][0] = 1
>>> A
[[1, 0, 0], [1, 0, 0], [1, 0, 0]]#会出现该错误
>>> A[0] is A[1]#原因在于使用该方法创建的列表每一行都指向了同一个对象
True
>>> A[1] is A[2]
True
#试图通过乘号对嵌套列表进行拷贝,但是是对同一个列表的引用进行了重复。9、is,同一性运算符
用以检验两个变量是否指向同一个对象的运算符
有同样字符串值的变量在内存中指向的是同一个字符串对象,但是有同样列表值的变量在内存中指向的不是同一个列表对象,
>>> x = 'nihao'
>>> y = 'nihao'
>>> x is y
True
>>> x = [1,2]
>>> y = [1,2]
>>> x is y
Falsepython赋值是将引用传递给变量,若直接使用赋值来复制列表,那么对原列表进行更改,复制的列表也会跟着改变,要想复制一个新的独立列表还是需要用到拷贝,copy(),见10
>>> x = [1, 2]
>>> y = x
>>> x is y
True
>>> x[1] = 1
>>> y[1]
110、浅拷贝和深拷贝
copy()和切片是浅拷贝
>>> x = [1, 2]
>>> y = x.copy()
>>> x is y
False
>>> x[1] = 1
>>> y[1]
2当对嵌套列表使用copy()时只会拷贝最外层,内层的列表依然是传递的引用
>>> x = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> y = x.copy()
>>> x[1][1] = 0
>>> y
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]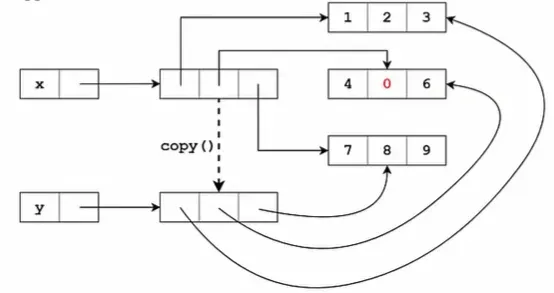
深拷贝需要用到copy模块,copy模块包含两个函数,其中的copy()函数依然是浅拷贝,其中的deepcopy()函数实现的是深拷贝,即为拷贝原对象以及其所有子对象
>>> import copy
>>> x = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> y = copy.copy(x)
>>> y
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> x[1][1] = 0
>>> y
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]
>>> y = copy.deepcopy(x)
>>> x[2][2] = 0
>>> x
[[1, 2, 3], [4, 0, 6], [7, 8, 0]]
>>> y
[[1, 2, 3], [4, 0, 6], [7, 8, 9]]
11、列表推导式
(1)基本语法
[expression for target in iterable ]
list = [执行语句 for i in 可迭代对象 ]
>>> list = [i for i in range(10)]
>>> list
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list = [i+1 for i in range(10)]
>>> list
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> list = [i*2 for i in 'love']
>>> list
['ll', 'oo', 'vv', 'ee']
>>> list = [ord(i) for i in 'love']
>>> list
[108, 111, 118, 101]ord()函数,将字符转换成对应的表达式
(3)使用列表推导式,现有一个纯数字列表,将其每个元素变为两倍
>>> list = [1, 2, 3, 4, 5]
>>> for i in range(len(list)):#传统循环方式实现
list[i] = list[i] * 2
>>> list
[2, 4, 6, 8, 10]
>>> list = [1, 2, 3, 4, 5]
>>> list = [i * 2 for i in list]#列表推导式实现
>>> list
[2, 4, 6, 8, 10](4)使用列表推导式,将一个三阶二维矩阵的第二列提取出来
>>> list = [i[1] for i in matrix]
>>> list
[2, 5, 8](5)使用列表推导式,将一个三阶二维矩阵的主对角线元素提取出来
>>> list = [matrix[i][i] for i in range(3)]
>>> list
[1, 5, 9](6)使用列表推导式,将一个三阶二维矩阵的次对角线元素提取出来
>>> list = [matrix[i][len(matrix)-i-1] for i in range(len(matrix))]
>>> list
[3, 5, 7]循环与列表推导式的区别:循环通过迭代来逐个修改原列表中的元素,列表推导式则是创建一个新的列表然后赋值给原列表变量
(7)使用列表推导式,创建一个二维列表
>>> list = [[0]*3 for i in range(3)]
>>> list
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> list[0][0] = 1
>>> list
[[1, 0, 0], [0, 0, 0], [0, 0, 0]](8)列表推导式的if分句
[expression for target in iterable if condition]
list = [执行语句 for i in 可迭代对象 if 满足的条件]
>>> list = [i for i in range(100) if i%10 == 0]
>>> list
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
(9)使用列表推导式筛选出F开头的单词
>>> word = ['Four','Love','Five','int','For']
>>> F = [i for i in word if i[0]=='F']
>>> F
['Four', 'Five', 'For'](10)嵌套列表推导式
[expression for target1 in iterable1 [执行语句 for i in 可迭代对象1
for target2 in iterable2 for j in 可迭代对象2
…… ……
for targetN in iterableN ] for N in可迭代对象N ]
使用嵌套列表推导式展开二维列表
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> list = [j for i in matrix for j in i]
>>> list
[1, 2, 3, 4, 5, 6, 7, 8, 9]
#等同于以下循环嵌套
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> list = []
>>> for i in matrix:
for j in i:
list.append(j)
>>> list
[1, 2, 3, 4, 5, 6, 7, 8, 9](11)列表推导式完整语法
[expression for target1 in iterable1 if condition1
for target2 in iterable2 if condition2
……
for targetN in iterableN if conditionN ]
[执行语句 for i in 可迭代对象1 if 满足的条件1
for j in 可迭代对象2 if 满足的条件2
……
for N in可迭代对象N if 满足的条件N ]
>>> list = [[x,y] for x in range(5) if x%4==0 for y in range(7) if y%3==0]
>>> list
[[0, 0], [0, 3], [0, 6], [4, 0], [4, 3], [4, 6]]
#转换成循环
>>> list = []
>>> for x in range(5):
if x%4==0:
for y in range(7):
if y%3==0:
list.append([x,y])
>>> list
[[0, 0], [0, 3], [0, 6], [4, 0], [4, 3], [4, 6]]编程kiss原则:keep it simple and stupid
八、元组
元组可以用小括号括起来,也可以不用括号,但建议一直加上小括号
可以使用下标进行索引
可以进行切片操作,用法同列表
元组内容不可变,不能修改元组内部元素,列表所能进行的‘增’、‘删’、‘改’均不能在元组中使用,唯有‘查’可以,因此元组只能使用count()和index()方法。但是元组内部还有列表等可以更改元素的序列,那么这个嵌入序列的元素是可更改的
元组可以使用加号和乘号两个运算符
元组可以进行嵌套
元组支持迭代
列表推导式可以对元组使用
创建一个单元素元组
>>> x = (123)
>>> x
123
>>> type(x)
<class 'int'>#使用该方法创建的只是一个整形变量
>>> x = (123,)#创建单元素元组必须加上一个逗号
>>> x
(123,)
>>> type(x)
<class 'tuple'>#tuple是元组的意思1、打包和解包
生成一个元组称为元组的打包
将元组内的元素分别赋值给不同的变量称为元组的解包
>>> x = (123, 'love', 520)#打包
>>> tuple = (123, 'love', 520)
>>> x, y, z = tuple#解包
>>> x
123
>>> y
'love'
>>> z
520解包同样可以使用在字符串和列表上面
>>> A = 'love'
>>> a, b, c, d = A
>>> print(a,b,c,d)
l o v e
>>> list = [1, 2, 3]
>>> x, y, z = list
>>> print(x, y, z)
1 2 3使用解包赋值号左边的变量数量必须同右边的元素数量一致
若数量不一致,可以在最后一个变量前加’*’号,将序列剩下的元素全装入最后一个变量
>>> A = 'love'
>>> x, y, *z = A
>>> print(x, y, z)
l o ['v', 'e']
>>> list = [1, 2, 3, 4, 5]
>>> a, b, *c = list
>>> print(a, b, c)
1 2 [3, 4, 5]python的多重赋值是通过打包解包实现的
>>> x, y = 10, 20#多重赋值
#等同于
>>> _ = (10, 20)
>>> a, b = _
>>> a
10
>>> b
20九、字符串
1、大小写字母换来换去
capitalize():字符串首字母大写,其他小写
swapcase():翻转字符串所有字母的大小写
title():单词首字母大写,其他小写
upper():全变大写
lower():全变小写(只用于英文)
casefold():全变小写(可用于英文以外的其他语言)
2、左中右对齐
center(width, fillchar=”):居中
rjust(width, fillchar=”):右对齐
Ijust(width, fillchar=”):左对齐
zfill(width):用0填充字符串左侧,多用于数据报表
width参数用于指定字符串的宽度,若指定的宽度小于或等于原字符串,那么则直接输出源字符串
fillchar参数用于指定填充的字符,默认为空格
3、实现字符串的查找功能
count(sub[, start[, end]]):用于查找sub参数指定的子字符串在字符串中出现的次数
find(sub[, start[, end]]):用于定位sub参数指定的子字符串在字符串中的索引下标值
rfind(sub[, start[, end]]):同上,但是从右往左检索
index(sub[, start[, end]]):同find(),但是find在找不到对应的字符串会返回-1,index则抛出异常
rindex(sub[, start[, end]]):同上,但是从右往左检索
4、替换
expandtabs([tabsize=8]):使用空格替换制表符,参数是指定一个tab等于多少个空格
replace(old, new, count=-1):返回一个将old参数指定的子字符串替换为new参数指定的字符串的新字符串,count为替换的次数,默认为-1,相当于替换全部
translate(table):返回一个根据table参数转换后的新字符串,table用以指定一个转换规则的表格(加密),table表格需要使用str.maketrans(x, y, z)来获取
>>> table = str.maketrans('abcdefg','1234567')
>>> str = 'The quick brown fox jumps over a lazy dog.'
>>> str.translate(table)
'Th5 qui3k 2rown 6ox jumps ov5r 1 l1zy 4o7.'
>>> table = str.maketrans('abcdefg','1234567','xyz')
>>> str.translate(table)
'Th5 qui3k 2rown 6o jumps ov5r 1 l1 4o7.'str.maketrans(x, y, z):x:指定需要替换的字符。y:指定替换的目标字符。z:删除对应的字符
5、字符串各种情况下的判断和检测
startswith(prefix[, start[, end]]):判断参数指定的子字符串是否出现在字符串起始位置
endswith(suffix[, start[, end]]):判断参数指定的子字符串是否出现在字符串结束位置
start和end参数指定查找的开始和结束位置
以上两个方法的参数支持以元组的形式传入,同时查找多个子字符串。
isupper():判断字符串中所有字母是否大写
islower():判断字符串中所有字母是否小写
istitle():判断字符串中所有单词是否以大写开头、其余字母小写
isalpha():判断字符串中是否只由字母构成
isspace():判断字符串中是否是空白字符串,空格、tab、转自字符、\n
isprintable():判断字符串中是否所有字符串都是可打印的,\n为非打印字符
isdecimal():判断是否为数字
isdigit():同上
isnumeric():同上
三个检测是否是数字的方法,能检测的范围不一样。例如isdecimal()只能检测123,isnumeric()可以检测罗马数字、中文数字等。根据不同的需求选择不同的方法。
isalnum():检测是否为数字或者字母,只要isalpha()、isdecimal()、isdigit()、isnumeric()几个方法任何一个会返回True,它都会返回True
isidentifier():判断字符串是否是一个合法的python标识符
isascii():判断是否空字符串或字符串中每个字符都是ASCII编码的字符
判断一个字符串是否为python的保留标识符:keyword模块的iskeyword函数
以上方法返回都是布尔类型的值
6、截取字符串
strip(chars=None):截掉字符串左侧和右侧的空白
Istrip(chars=None):截掉字符串左侧的空白
rstrip(chars=None):截掉字符串右侧的空白
char用来设置截掉的匹配字符,可以是多个字符,用一个字符串表示,默认是空白
removeprefix(prefix):从前面截掉一个具体的子字符串
removesuffix(suffix):从前面截掉一个具体的子字符串
>>> L = 'www.baidu.com'
>>> L.lstrip('wcom.')
'baidu.com'
>>> L.rstrip('wcom.')
'www.baidu'
>>> L.removeprefix('www.')
'baidu.com'
>>> L.removesuffix('.com')
'www.baidu'7、拆分和拼接
partition(sep):将字符串以参数指定的字符为分隔符对字符串进行拆分,从左边开始匹配,只匹配拆分一次,返回一个三元组
rpartition(sep):同上,只是从右边匹配
split(sep=None, maxsplit=-1):将字符串拆分成若干个字符串,sep:拆分的分隔符,默认空格,maxsplit:拆分次数,也就是匹配分隔符的次数
rsplit(sep=None, maxsplit=-1):同上,但从右往左
splitlines(keepends=False):将字符串按行进行分割,将结果以列表的形式返回,keepends参数用于设定返回的列表是否包含换行符本身,若为True,换行符将包含到上一个字符串中去。可以用于需要按行进行字符串分割,但不同平台换行符的转义字符不同的情况。
join(iterable):将字符串拼接起来。join的效率比加号高很多,在大数量情况下甚至会快上千倍。
>>> '.'.join(['www', 'baidu', 'com'])
'www.baidu.com'
>>> ''.join(('L', 'o', 'v', 'e'))
'Love'8、格式化字符串
format():在字符串中使用一对花括号来表示替换字符串,替换的字符串为format()的参数,花括号中可以填上数字,表示引用参数的位置,同一个参数可以被引用多次,也可以使用关键字进行索引,参数中的字符串当做元组来处理。选项可以通过关键字参数来设置选项的值。
完整语法:format_spec::= [[fill]align][sign][#][0][width][grouping_option][.precision][type]
>>> '祖国的生日是{}年。'.format(1949)
'祖国的生日是1949年。'
>>> '{mounain}上有座{1},{1}里有个{0}'.format('老和尚', '庙', mounain='山')
'山上有座庙,庙里有个老和尚'[fill]:指定填充的符号
[align]:指定对其方式
‘<’:强制字符串在可用空间内左对齐(默认)
‘>’:强制字符串在可用空间内右对齐
‘=’:强制将填充放置在符号(如果有)之后但在数字之前的位置(这适用于以”+000000120″的形式打印字符串)
‘^’:强制字符串在可用空间内居中
[sign]:仅对数字类型有效
‘+’:正数在前面添加正好(+),负数在前面添加负号(-)
‘-’:只有负数在前面添加负号(-),默认行为
空格:正数在前面添加一个空格,负数在前面添加负号(-)
[0]:感知正负号的用0填充空白位置,只对数字有效
[width]:指定填充字符串的宽度
[grouping_option]:设置数字千分位的分隔符,有下划线和逗号
[.precision]:精度,※对于[type]设置为’f或’F’的浮点数来说,是限定小数点后显示多少个数位;
※对于[type]设置为’g’或’G’的浮点数来说,是限定小数点前后一共显示多少个数位;
※对于非数字类型来说,限定的是最大字段的大小
※对于整数类型来说,则不允许使用[.precision]选项
[type]:决定了数据如何来呈现
‘b’:将参数以二进制形式输出
‘c’:将参数Unicode字符形式输出
‘d’:将参数以十进制形式输出
‘o’:将参数以八进制形式输出
‘x’:将参数以十六进制形式输出
‘X’:将参数以十六进制形式输出
‘n’:与‘d’类似,但会使用当前语言环境设置的分隔符插入到恰当的位置
None:同‘d’
[#]:参数以二进制、八进制或者十六进制在字符串中进行输出的时候会自动追加代表进制的前缀,配合[type]中的进制输出使用
以下适用于浮点数和复数
‘e’:将参数以科学计数法的形式输出(以字母’e’来标示指数,默认精度为6)
‘E’:将参数以科学计数法的形式输出(以字母’E’来标示指数,默认精度为6)
‘f’:将参数以定点表示法的形式输出(“不是数”用’nan’来标示,无穷用’inf’标示,默认精度为6)
‘F’:将参数以定点表示法的形式输出(“不是数”用’NAN’来标示,无穷用’INF’标示,默认精度为6)
‘g’:通用格式,小数以’f’形式输出,大数以’e’的形式输出
‘G’:通用格式,小数以’F’形式输出,大数以’E’的形式输出
‘n’:跟’g’类似,不同之处在于它会使用当前语言环境设置的分隔符插入到恰当的位置
‘%’:以百分比的形式输出(将数字乘以100并显示为定点表示法’f’的形式,后面附带一个百分号)
None:类似于’g’,不同之处在于当使用定点表示法时,小数点后将至少显示一位,默认精度与给定值所需的精度一致。
9、f-字符串(f-string)
直接在字符串前加(f-)即可,format方法的语法糖,f-字符串仅支持python3.6以上版本
十、序列
列表、元组和字符串都统称为序列
可分为可变序列和不可变序列,列表是可变序列,元组和字符串是不可变序列
1、能够作用于序列的运算符和函数
加号和乘号:+、*
is、is not:检测对象id值是否相等(不等),是否是(不是)同一个对象,叫同一性运算符
in、not in:用于判断某一个运算符是否包含(不包含)在序列中
del语句:用于删除一个或多个对象,或者删除可变序列中的指定元素del list[start: end]
clear():清除列表中的元素
2、跟序列相关的一些函数
list()、tuple()、str():列表、元组、字符串相互转换,参数为可迭代对象
min()、max():对比传入的参数,返回最小值或者最大值,当传入的可迭代对象为空,且default未设置时会报错,若设置了default,则输出default指定的内容。


len():在底层是直接读取C语言结构体里面的对象的长度,有一个能读取的最大长度,对于32为平台来说,这个长度是2^31-1,对于64位平台来说是2^63-1。
sum():其中可选一个start参数,会将该参数加到求和的可迭代对象里面。
sorted():返回一个全新的排序后的列表,与列表的sort()方法区分开。同样支持key与reverse参数,使用方法与sort()一致。可接受任何形式的可迭代参数。
reversed():返回的是一个参数的反向迭代器,暂且当做一个可迭代对象来看。
>>> s = [1, 2, 3, 4, 5]
>>> reversed(s)
<list_reverseiterator object at 0x00000284AD4AF310>
>>> list(reversed(s))
[5, 4, 3, 2, 1]
>>> s.reverse()
>>> s
[5, 4, 3, 2, 1]
>>> list(reversed('上山打老虎'))
['虎', '老', '打', '山', '上']
>>> list(reversed((1, 2, 3, 7, 8, 9)))
[9, 8, 7, 3, 2, 1]
>>> list(reversed(range(10)))
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]all():判断可迭代对象中是否所有元素的值都为真。
any():判断可迭代对象中是否存在某一个元素的值为真。
enumerate():用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从0开始的序号共同构成一个二元组的列表。start参数:用于指定序号开始的值。
>>> s = ['虎', '老', '打', '山', '上']
>>> enumerate(s)
<enumerate object at 0x00000284AD183480>
>>> list(enumerate(s))
[(0, '虎'), (1, '老'), (2, '打'), (3, '山'), (4, '上')]
>>> list(enumerate(s, 5))
[(5, '虎'), (6, '老'), (7, '打'), (8, '山'), (9, '上')]zip():用于创建一个聚合多个可迭代对象的迭代器。他会将作为参数传入的每个可迭代对象的每个元素一次组合成元组,即第i个元组包含来自每个参数的第i个元素。
若传入的可迭代对象的长度不相等,则以最短的为准,将多余的元素抛弃。若不想丢弃多余的元素,则可以使用itertools模块中的zip_longest()函数来代替zip()。
>>> sing = [1, 2, 3, 4]
>>> song = [5, 6, 7, 8]
>>> zip(sing, song)
<zip object at 0x00000284AD4B6F40>
>>> list(zip(sing, song))
[(1, 5), (2, 6), (3, 7), (4, 8)]
>>> z = [11, 22, 33, 44, 55]
>>> list(zip(sing, song, z))
[(1, 5, 11), (2, 6, 22), (3, 7, 33), (4, 8, 44)]
>>> import itertools
>>> itertools.zip_longest(sing, song, z)
<itertools.zip_longest object at 0x00000284AD4CD720>
>>> list(itertools.zip_longest(sing, song, z))
[(1, 5, 11), (2, 6, 22), (3, 7, 33), (4, 8, 44), (None, None, 55)]map():根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器。
若提供的函数需要两个或者多个参数时,只需要同时去调整可迭代对象的数量即可。
若提供的可迭代对象的长度不一致时,以最短的可迭代对象为准,抛弃掉多余的。
>>> s = 'list'
>>> map(ord, s)#ord函数为返回字符的编码值
<map object at 0x0000023CCC91F2B0>
>>> list(map(ord, s))#每次从字符串s中取出一个字符,执行ord函数
[108, 105, 115, 116]#返回的则为‘l’‘i’‘s’‘t’四个字母的编码值
>>> list(map(pow, [2, 3, 10],[4, 3, 2]))
[16, 27, 100]
>>> list(map(max, [5, 7, 9], [3, 7, 564], [1, 4, 765, 2, 3]))
[5, 7, 765]filter():与map()函数类似,根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回。
>>> list(filter(str.islower, 'Love'))
['o', 'v', 'e']3、迭代器与可迭代对象
一个迭代器肯定是一个可迭代对象。可迭代对象是可以重复使用的,但是可迭代器是一次性的
iter():将一个可迭代对象变为一个迭代器。
>>> x = [1, 2, 3, 4, 5]
>>> y = iter(x)
>>> y
<list_iterator object at 0x0000023CCC895190>
>>> type(x)
<class 'list'>
>>> type(y)
<class 'list_iterator'>next():逐个将迭代器中的元素提取出来
>>> next(y)
1
>>> next(y)
2
>>> next(y)
3
>>> next(y)
4
>>> next(y)
5
>>> next(y)#当迭代器中没有元素的时候抛出异常
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
next(y)
StopIteration
>>> y = iter(x)
>>> next(y, '没有了')
1
>>> next(y, '没有了')
2
>>> next(y, '没有了')
3
>>> next(y, '没有了')
4
>>> next(y, '没有了')
5
>>> next(y, '没有了')#当next有第二个参数时,在提取完元素之后输出其指定的内容
'没有了'十一、字典
字典是Python中唯一实现映射关系的内置类型。
映射关系:举例摩斯密码
使用Python实现摩斯密码解码
在映射类型的数据的获取上,字典的效率是远远高于列表的。
在序列中元素可以重复,字典中的键值对只有一个
1、创建字典的六种方法
冒号左边为字典的键,右边为字典的值。
获取:与序列所不同的是,序列是通过位置的偏移来存取数据的,而字典则是通过键来进行的,使用字典的值则需要在方括号中传入键即可。
改/增:通过对字典的键赋值,即可更改该键的值,若字典中无该键,则新增一个。
>>> x = {'1':'1', '2':'4', '3':'9', '4':'16', '5':'25'}
>>> type(x)
<class 'dict'>
>>> x['4']
'16'
>>> x['5'] = '50'
>>> x
{'1': '1', '2': '4', '3': '9', '4': '16', '5': '50'}
>>> x['6'] ='36'
>>> x
{'1': '1', '2': '4', '3': '9', '4': '16', '5': '50', '6': '36'}
(1)直接使用大括号和冒号的组合
(2)使用dict()函数,参数为键值对
(3)使用列表作为参数,列表中的元素是使用元组包裹起来的键值对
(4)将(1)中的语句作为参数传递给dict()
(5)混合使用以上几种方法
(6)通过zip()函数作为参数
>>> a = {'一':'1', '二':'4', '三':'9'}#(1)
>>> b = dict(一='1', 二='4', 三='9')#(2)
>>> c = dict([('一', '1'), ('二', '4' ), ('三', '9')])#(3)
>>> d = dict({'一':'1', '二':'4', '三':'9'})#(4)
>>> e = dict({'一':'1', '二':'4'}, 三='9')#(5)
>>> f = dict(zip(['一', '二', '三'], ['1', '4', '9']))#(6)
>>> a == b == c == d == e == f
True2、增,fromkeys()
fromkeys(iterable[, values]):使用iterable指定的可迭代对象创建一个新的字典,并将所有值初始化为参数values指定的值
>>> x = dict.fromkeys(range(3), 520)
>>> x
{0: 520, 1: 520, 2: 520}3、删,pop()
pop(key[, default]):返回key键所指的值,而后删除该键值对。
>>> x.pop(2)
520
>>> x.pop(2)
Traceback (most recent call last):
File "<pyshell#16>", line 1, in <module>
x.pop(2)
KeyError: 2
>>> x.pop(2, '没有该键')
'没有该键'popitem():python3.7之前是随机删除一个键值对,在3.7之后则是删除最后一个加入字典的键值对。
>>> x.popitem()
(1, 520)del:删除指定的键值对,也可以删除字典
>>> del x[0]
>>> x
{}
>>> del x
>>> x
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
x
NameError: name 'x' is not definedclear():清空字典的内容
>>> x = {'1':'1', '2':'4', '3':'9', '4':'16', '5':'25'}
>>> x
>>> x.clear()
>>> x
{}4、改,update()
直接对字典的某一个键进行赋值以修改耽搁单个值。
update([other]):同时对多个键值对进行修改,传入多个键值对、字典、包含键值对的可迭代对象
>>> x = dict.fromkeys('Love')
>>> x
{'L': None, 'o': None, 'v': None, 'e': None}
>>> x['L'] = 100
>>> x
{'L': 100, 'o': None, 'v': None, 'e': None}
>>> x.update({'o':101, 'v':102})
>>> x
{'L': 100, 'o': 101, 'v': 102, 'e': None}
>>> x.update(v='103', e='104')
>>> x
{'L': 100, 'o': 101, 'v': '103', 'e': '104'}5、查,get(),setdefault()
get(key[, default]):key为查找的键,default为未查到键时返回的数据。
>>> x['L']
100
>>> x['l']
Traceback (most recent call last):
File "<pyshell#12>", line 1, in <module>
x['l']
KeyError: 'l'
>>> x.get('L','没找到')
100
>>> x.get('l','没找到')
'没找到'setdefault(key[, default]):查找字典中的数据,若找到则返回该值,找不到则新建一个键值对,新建的键值对的键为key,值为default。
>>> x.setdefault('L', '110')
100
>>> x.setdefault('l', '110')
'110'
>>> x
{'L': 100, 'o': 101, 'v': '103', 'e': '104', 'l': '110'}items()、keys()、values():分别用于获取字典的键值对、键、值三者的视图对象。视图对象即字典的动态视图,当字典的内容发生改变的时候,视图对象的内容也会相应的跟着改变。
>>> items = x.items()
>>> keys = x.keys()
>>> values = x.values()
>>> items
dict_items([('L', 100), ('o', 101), ('v', '103'), ('e', '104'), ('l', '110')])
>>> keys
dict_keys(['L', 'o', 'v', 'e', 'l'])
>>> values
dict_values([100, 101, '103', '104', '110'])
>>> x.pop('l')
'110'
>>> x
{'L': 100, 'o': 101, 'v': '103', 'e': '104'}
>>> items
dict_items([('L', 100), ('o', 101), ('v', '103'), ('e', '104')])
>>> keys
dict_keys(['L', 'o', 'v', 'e'])
>>> values
dict_values([100, 101, '103', '104'])6、字典的其他操作
(1)copy():对字典进行浅拷贝
(2)len():获取字典键值对的数量
(3)in()、notin():判断某个键是否在(不在)字典中
(4)list():将字典转换为列表,返回的是由字典的键构成的列表,等于list(x.keys()),想要得到字典的值组成的列表则需要使用list(x.values())
(5)iter():将字典的键构成一个迭代器
(6)reversed():对字典的键值对进行倒序,但是不能对python3.8之前的版本使用,因为之前的版本中的字典键值对是无序的。
7、嵌套
某个键的值可以是另外一个字典或者列表
>>> score = {'张三':{'语文':'70', '数学':'60', '英语':'45'}, \
'小红':{'语文':'99', '数学':'98', '英语':'97'}}
>>> score
{'张三': {'语文': '70', '数学': '60', '英语': '45'}, '小红': {'语文': '99', '数学': '98', '英语': '97'}}
>>> score['张三']['英语']
'45'
>>> score = {'张三':[70, 60, 45], '小红':[99, 98, 97]}
>>> score['小红'][2]
978、字典推导式
>>> score = {'语文':70, '数学':60, '英语':45}
>>> erocs = {i:j for j,i in score.items()}
>>> erocs
{70: '语文', 60: '数学', 45: '英语'}
>>> P = {i:j for i,j in score.items() if j>=60}
>>> P
{'语文': 70, '数学': 60}
>>> x = {i:ord(i) for i in 'Love'}
>>> x
{'L': 76, 'o': 111, 'v': 118, 'e': 101}十二、集合
>>> type({})
<class 'dict'>
>>> type({123})
<class 'set'>
>>> type({123:123})
<class 'dict'>集合中所有元素都是无序的,所以不能使用下标索引的方式来对其进行访问。可以使用in和notin来判断元素是否存在于集合中。可以通过迭代的方式来访问全体集合元素。
集合中的所有元素都是唯一的,不能存在重复的元素。因此可以使用集合来对列表进行去重或者检测列表是否存在重复元素
1、集合的三种创建方法
(1)使用花括号,并在其传入多个元素
>>> {123, 123}
{123}
>>> {123, 456}
{456, 123}(2)使用集合推导式
>>> s = {i for i in 'Love'}
>>> s
{'L', 'v', 'e', 'o'}
(3)使用类型构造器set()
>>> set('love')
{'e', 'v', 'o', 'l'}2、集合的各种内置方法
下面列举的方法不会对集合的元素进行改动,所以既适用于可变集合set(),也适用于不可变集合frozenset():
s.copy():返回s集合的一个浅拷贝
s.isdisjoint(other):如果s集合中没有与other 容器存在共同的元素,那么返回True,否则返回False
s.issubset(other):如果s集合是 other容器的子集(注1),那么返回True,否则返回False
注1:对于两个集合A、B,如果集合A中任意一个元素都是集合B中的元素,我们就说这两个集合有包含关系,称集合A为集合B的子集(Subset)( <= 真子集、 < 子集)
s.issuperset(other):如果s集合是 other容器的超集(注2),那么返回True,否则返回False
注2∶对于两个集合A、B,如果集合B中任意一个元素都是集合A中的元素,我们就说这两个集合有包含关系,称集合A为集合B的超集(Superset) ( >= 真超集、 > 超集)
s.union(*others):返回一个新集合,其内容是s集合与others容器的并集(注3)
注3:对于两个集合A、B,把他们所有的元素合并在一起组成的集合,叫做集合A与集合B的并集(Union).( | 管道符)
s.intersection(*others):返回一个新集合,其内容是s集合与others容器的交集(注4)
注4∶对于两个集合A、B,由所有属于集合A且属于集合B的元素所组成的集合,叫做集合A与集合B的交集(Intersection) .( & and符)
s.difference(*others):返回一个新集合,其内容是存在于s集合中,但不存在于others容器中的元素(注5)
注5:对于两个集合A、B,由所有属于集合A且不属于集合B的元素所组成的集合,叫做集合A与集合B的差集(Difference)。( – 减号)
s.symmetric_difference(other):返回一个新集合,其内容是排除掉s集合和other容器中共有的元素后,剩余的所有元素,即对称差集。( ^ 脱字符)
注6: others参数表示支持多个容器(参数类型可以是集合,也可以是序列) ; other参数则表示单个容器。若使用括号中的运算符,则需要符号两边都为集合类型的数据。
3、仅适用于set()的方法
update(*others):使用others参数指定的值来更新集合
intersection_update(*others):使用交集的方式来更新集合
difference_update( *others):使用差集的方式来更新集合
symmetric_difference_update(others):使用对称差集的方式来更新集合
以上三个方法与上一点中的交集差集对称差集的区别在于,上一点是直接返回一个新的集合,而update是对原集合进行更新,在原集合上进行改动。
add(elem):向集合中添加数据。当向集合中添加字符串时,使用update是迭代字符串中的每一个字符分别作为集合的元素,而add是将整个字符串作为一个元素插入。
>>> x = {1, 2, 3}
>>> x.update('love')
>>> x
{1, 2, 3, 'l', 'v', 'e', 'o'}
>>> x.add('123')
>>> x
{1, 2, 3, '123', 'l', 'v', 'e', 'o'}remove(elem)、discard(elem):删除集合中指定的元素,但不同的是remove方法在找不到指定的元素时会抛出异常,而discard则会静默处理。
pop():随机从集合中集合中弹出一个元素
clear():清空集合的所有元素
4、可哈希
想要正确的创建字典或者集合,那么则要求字典的键和集合元素是可哈希的
可哈希:如果一个对象是可哈希的,那么就要求他的哈希值必须在其整个生命周期中保持不变
不可变对象:可哈希。例如元组、集合等 可变对象:不可哈希。例如列表等
hash(object):获取对象的哈希值。
对整数求哈希值,其哈希值等于本身。
若两个对象的值是相等的,尽管是不同的对象,那么哈希值也是相等的。
只能对不可变的对象求哈希值,可变的对象不行。
十三、函数
1、创建和调用函数
>>> def myfunc():
print('喊我干嘛')
pass
>>> myfunc()
喊我干嘛2、函数的返回值,return语句
>>> def mul(x, y):
return x*y
>>> mul(2, 2)
4
>>> def mul():
pass
>>> print(mul())
None当执行到return语句时,函数将会返回,不会再执行之后的语句
若函数没有写return语句,那么在函数执行结束之后会默认返回一个None值
3、函数的参数
>>> def myfunc(name, times):
for i in range(times):
print(f'I love {name}')
>>> myfunc('you', 3)
I love you
I love you
I love you参数可以分为形式参数和实际参数,形参是定义函数时写的参数的名字,例如name,times,实参指调用函数时传进函数的参数值,例如‘you’和3
(1)位置参数
实参是按照形参定义的顺序进行传递的。
(2)关键字参数
知道参数的名字就可以使用关键字参数
若要同时使用位置参数以及关键字参数,则位置参数必须在关键字参数之前
>>> def func(x, z):
print(x, '爱', z)
>>> func('你', '我')
你 爱 我
>>> func(z = '你', x = '我')
我 爱 你
>>> def ppp(x, y, z, a):
print(x, y, z, a)
>>> ppp(1, 2, 3, z = 5)
Traceback (most recent call last):
File "<pyshell#49>", line 1, in <module>
ppp(1, 2, 3, z = 5)
TypeError: ppp() got multiple values for argument 'z'
>>> ppp(1, 2, a = 3, z = 5)
1 2 5 3(3)默认参数
函数在定义时为参数设定的值,若为传入实参,则使用默认参数,并且默认参数应该放置在所有参数的最后。
(4)’ / ‘
在’ / ‘左侧的参数必须传递位置参数,不能使用关键字参数。

>>> def aaa(a, /, b, c):
print(a, b, c)
>>> aaa(a = 1, 2, 3)
SyntaxError: positional argument follows keyword argument
>>> aaa(1, b = 2, c = 3)
1 2 3(5)’ * ‘
在’ * ‘右侧的参数必须传递关键字参数,不能使用位置参数。
>>> def bbb(a, *, b, c):
print(a, b, c)
>>> bbb(1, 2, 3)
Traceback (most recent call last):
File "<pyshell#63>", line 1, in <module>
bbb(1, 2, 3)
TypeError: bbb() takes 1 positional argument but 3 were given
>>> bbb(1, b = 2, c = 3)
1 2 3(6)收集参数
例如print()这种参数可多可少的函数。定义的时候在形参前面加上星号,传的参数在函数中是一个元组。
>>> def myfunc(*xs):
print('传入了{}个参数'.format(len(xs)))
print('第一个参数是{}'.format(xs[0]))
print(xs)
>>> myfunc(1, 2, 3, 4, 5)
传入了5个参数
第一个参数是1
(1, 2, 3, 4, 5)元组的打包解包功能也可以用在函数中。若要函数返回多个值,就会使用元组进行打包。也可以对返回的值进行解包
>>> def a():
return 1, 2, 3
>>> a()
(1, 2, 3)
>>> x, y, z = a()
>>> print(x, y, z)
1 2 3函数的收集参数就是使用该原理,通过使用‘ * ‘实现打包操作。
>>> def myfunc(*xs):
return type(xs)
>>> myfunc(1, 2, 3)
<class 'tuple'>若在收集参数后还需要指定其他参数,在调用函数的时候则应该使用关键字参数进行传值,在第(5)点中的’ * ‘号就是一个匿名的收集参数,因此它后面才不能使用位置参数。
>>> def myfunc(*xs, a, b):
print(xs, a, b)
>>> myfunc(1, 2, 3, 4, 5)
Traceback (most recent call last):
File "<pyshell#22>", line 1, in <module>
myfunc(1, 2, 3, 4, 5)
TypeError: myfunc() missing 2 required keyword-only arguments: 'a' and 'b'
>>> myfunc(1, 2, 3, a = 4, b = 5)
(1, 2, 3) 4 5收集参数还可以将参数打包为字典,使用‘ ** ‘,同时必须使用关键字参数进行传值
>>> def myfunc(**keywords):
print(keywords)
>>> myfunc(a = 1, b = 2, c = 3)
{'a': 1, 'b': 2, 'c': 3}将打包为元组的收集参数和打包为字典的收集参数混合起来进行使用,字符串的format()方法就是使用了这两种方法。
>>> def myfunc(a, *b, **c):
print(a, b, c)
>>> myfunc(1, 2, 3, 4, d = 5, e = 6, f = 7)
1 (2, 3, 4) {'d': 5, 'e': 6, 'f': 7}(7)解包参数
收集参数中的‘ * ‘、‘ ** ‘不仅可以在函数定义的时候使用,还可以在函数调用的时候进行使用,在形参上称之为参数的打包,在实参上使用则是解包。两个星号对应的是关键字参数
>>> args = (1, 2, 3, 4)
>>> def pp(a, b, c, d):
print(a, b, c, d)
>>> pp(args)
Traceback (most recent call last):
File "<pyshell#37>", line 1, in <module>
pp(args)
TypeError: pp() missing 3 required positional arguments: 'b', 'c', and 'd'
>>> pp(*args)
1 2 3 4
>>> keyargs = {'a':1, 'b':2, 'c':3, 'd':4}
>>> pp(**keyargs)
1 2 3 44、作用域
变量可以别访问的范围。
(1)局部作用域
变量的定义为在函数中,那么其作用域就在该函数中,称为局部变量
(2)全局作用域
在函数外部定义一个变量,那么其作用域就在全局,称为全局变量
在函数中,同样名称的局部变量会覆盖全局变量
(3)global语句
在函数内部定义一个全局变量
>>> x = 123
>>> def fun():
global x
x = 456
print(x)
>>> fun()
456
>>> print(x)
456(4)嵌套函数
内层函数无法在全局调用
>>> def funa():
x = 111
def funb():
x = 222
print('在内层的X是', x)
funb()
print('在外层的x是', x)
>>> funa()
在内层的X是 222
在外层的x是 111
>>> funb()
Traceback (most recent call last):
File "<pyshell#62>", line 1, in <module>
funb()
NameError: name 'funb' is not defined(5)nonlocal语句
在内部函数修改外部函数的变量
>>> def funa():
x = 111
def funb():
nonlocal x
x = 222
print('在内层的X是', x)
funb()
print('在外层的x是', x)
>>> funa()
在内层的X是 222
在外层的x是 222(6)LEGB规则
当各个作用域覆盖范围重复,出现冲突的时候,按此规格执行。L最高,B最低。
L:Local,局部作用域
E:Enclosed,嵌套函数的外层函数作用域
G:Global,全局作用域
B:Build-In,内置作用域(内置函数,内置方法)
若使用内置函数名创建全局变量,将不能再使用内置函数的功能。因此避免命名与内置函数同名的变量或者函数等。
>>> int = 123
>>> int('123')
Traceback (most recent call last):
File "<pyshell#75>", line 1, in <module>
int('123')
TypeError: 'int' object is not callable5、闭包
1、利用嵌套函数的外层作用域具有记忆能力这个特性让数据保存在外层函数的参数或者变量中
2、将内层函数作为返回值,就可以从外部间接的调用到内层的函数。
开篇例:在嵌套函数外部作用域中的一些变量是可以通过一些方法保存下来的。
>>> def funa():
x = 123
def funb():
print(x)
funb()
>>> funa()
123
>>> def funa():
x = 123
def funb():
print(x)
return funb
>>> funa()
<function funa.<locals>.funb at 0x000001E978DB5040>
>>> funa()()
123
>>> fun = funa()
>>> fun()
123闭包:工厂函数
>>> def power(exp):
def exp_of(base):
return exp ** base
return exp_of
>>> square = power(2)
>>> cube = power(3)
>>> square(2)
4
>>> square(3)
8
>>> cube(2)
9
>>> cube(3)
27>>> def outer():
x = y = 0
def inner(a, b):
nonlocal x, y
x += a
y += b
print(x, y)
return inner
>>> move = outer()
>>> move(1, 2)
1 2
>>> move(3, 4)
4 66、装饰器
将函数作为参数传递给另一个函数
>>> def myfunc():
print('这里是myfunc')
>>> def report(func):
print('这里是report')
func()
print('这里是report')
>>> report(myfunc)
这里是report
这里是myfunc
这里是report(1)将闭包和将函数作为参数综合起来就是装饰器。
import time
def time_master(func):
def call_func():
print('开始运行程序...')
start = time.time()
func()
end = time.time()
print(f'运行结束,用时{(end - start):5f}')
return call_func
def myfunc():
print('myfunc是为了打印这个字符串')
myfunc = time_master(myfunc)
myfunc()
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
开始运行程序...
myfunc是为了打印这个字符串
运行结束,用时0.004998
通过参数将函数传入time_master,func就执行myfunc的语句,而后将call_func作为函数的返回值返回,赋值给myfunc,调用myfunc就相当于把两个函数的内容都执行了一遍。
(2)装饰器语法糖:@time_master
import time
def time_master(func):
def call_func():
print('开始运行程序...')
start = time.time()
func()
end = time.time()
print(f'运行结束,用时{(end - start):5f}')
return call_func
@time_master
def myfunc():
print('myfunc是为了打印这个字符串')
myfunc()
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
开始运行程序...
myfunc是为了打印这个字符串
运行结束,用时0.005981(3)多个装饰器可以用在同一个函数上。若有多个装饰器,则从下往上执行,先执行@trp,再@mul,再@sum
def sum(fun):
def inner():
x = fun()
return x + 1
return inner
def mul(fun):
def inner():
x = fun()
return x*x
return inner
def trp(fun):
def inner():
x = fun()
return x*x*x
return inner
@sum
@mul
@trp
def myfunc():
return 2
print(myfunc())
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
65(4)给装饰器传递参数
import time
def log(msg):
def time_master(func):
def call_func():
start = time.time()
func()
end = time.time()
print(f'{msg}程序用了{(end - start):.5f}')
return call_func
return time_master
@log('A')
def funcA():
print('打印了funcA中的字符串')
@log('B')
def funcB():
print('打印了funcB中的字符串')
funcA()
funcB()
>>>
==== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\text.py ====
打印了funcA中的字符串
A程序用了0.04354
打印了funcB中的字符串
B程序用了0.00630@log(‘A’) 相当于 funcA = log(‘A’)(funcA)
@log(‘B’) 相当于 funcB = log(‘B’)(funcB),先调用log()并向其传参’B’,随后调用time_master,并将函数funcB传入
7、lambda表达式
匿名函数
lambda arg1, arg2, arg3, …argN : expression
相当于:def <lambda>(arg1, arg2, arg3, …argN):
return expression
因为lambda是一个表达式,所以它可以做一些常规函数不能做到的事
例如将lambda表达式作为元素放到列表中;将lambda用到map、filter函数中;
>>> func = lambda x:x*x
>>> func(2)
4
>>> y = [lambda x:x*x, 2, 3]
>>> y[0](y[2])
9
>>> mapped = map(lambda x:ord(x), 'Love')
>>> list(mapped)
[76, 111, 118, 101]
>>> filted = filter(lambda x:x % 2, range(10))
>>> list(filted)
[1, 3, 5, 7, 9]8、生成器
实现生成器的两种方法
(1)使用yield语句替换函数中的return
让函数在退出之后还能保留状态,除了使用闭包以及全局变量以外,还可以在函数中使用yield语句来代替return,也就是生成器。
生成器会在每调用一次的时候提供一个数据,并且记住当时的状态,支持next()函数,无法使用下标索引
>>> def counter():
i = 0
while i <= 3:
yield i
i += 1
>>> counter()
<generator object counter at 0x000001922FA6C740>
>>> for i in counter():
print(i, end = ' ')
0 1 2 3
>>> c = counter()
>>> next(c)
0
>>> next(c)
1
>>> next(c)
2
>>> next(c)
3
>>> next(c)
Traceback (most recent call last):
File "<pyshell#43>", line 1, in <module>
next(c)
StopIteration
>>> c = counter()
>>> c[2]
Traceback (most recent call last):
File "<pyshell#45>", line 1, in <module>
c[2]
TypeError: 'generator' object is not subscriptable使用生成器实现斐波拉契数列
>>> def F():
x, y = 0, 1
while y <= 100:
yield y
x, y = y, x + y
>>> for i in F():
print(i, end = ' ')
1 1 2 3 5 8 13 21 34 55 89 (2)生成器表达式
>>> (i ** 2 for i in range(3))
<generator object <genexpr> at 0x000001922FB4DB30>
>>> i = (i ** 2 for i in range(3))
>>> next(i)
0
>>> next(i)
1
>>> next(i)
4
>>> next(i)
Traceback (most recent call last):
File "<pyshell#85>", line 1, in <module>
next(i)
StopIteration9、递归
递归就是函数调用自身的过程
要让递归进行正常工作,必须设置一个结束条件,并且在运行过程中需要向这个条件推进。
>>> def funA(i):
if i > 0:
print('Love')
i -= 1
funA(i)
>>> funA(5)
Love
Love
Love
Love
Love使用递归方法是实现阶乘
>>> def fact(i):
if i == 1:
return 1
else:
return i * fact(i-1)
>>> fact(5)
120汉诺塔
>>> def hanoi(n, x, y, z):
if n == 1:
print(x, '-->', z)
else:
hanoi(n-1, x, z, y)
print(x, '-->', z)
hanoi(n-1, y, x, z)
>>> n = int(input('请输入汉诺塔的层数:'))
请输入汉诺塔的层数:3
>>> hanoi(n, 'A', 'B', 'C')
A --> C
A --> B
C --> B
A --> C
B --> A
B --> C
A --> C10、函数文档、类型注释、内省
(1)函数文档
在定义函数的时候,在语句前用字符串形式插入。使用help()调用。内置函数也有。
>>> def exchange(dollar, rate = 6.32):
"""
功能:美元汇率转换
参数:
- dollar:美元数量
- rate:美元汇率,默认值为6.32
返回值:
- 人民币数量
"""
return dollar * rate
>>> exchange(10)
63.2
>>> help(exchange)
Help on function exchange in module __main__:
exchange(dollar, rate=6.32)
功能:美元汇率转换
参数:
- dollar:美元数量
- rate:美元汇率,默认值为6.32
返回值:
- 人民币数量
>>> help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
(2)类型注释
s:str表示还函数的作者希望调用该函数的人员传入s参数的实参是str类型,可使用默认参数
n:int表示还函数的作者希望调用该函数的人员传入n参数的实参是int类型,可使用默认参数
-> str表示该函数的返回值是str类型
虽然有类型注释,但是如果在调用函数的时候往里面传入的参数并不符合注释的类型,python是不会报错的。若想让python对调用传入的参数进行检测,检测其是否符合类型注释,可以使用第三方模块Mypy
>>> def sstr(s:str, n:int) -> str:
return s * n
>>> sstr('Love', 2)
'LoveLove'
>>> def sstr(s:str = 'hot', n:int = 5) -> str:
return s * n
>>> sstr()
'hothothothothot'(3)内省
指在程序运行的时候可以进行自我检测的一种机制。python通过一些特殊的属性来实现内省的。
>>> sstr.__name__#输出函数的名字
'sstr'
>>> sstr.__annotations__#输出函数的类型注释
{'s': <class 'str'>, 'n': <class 'int'>, 'return': <class 'str'>}
>>> exchange.__doc__#输出函数的文档
'\n\t功能:美元汇率转换\n\t参数:\n\t- dollar:美元数量\n\t- rate:美元汇率,默认值为6.32\n\t返回值:\n\t- 人民币数量\n\t'
>>> print(exchange.__doc__)
功能:美元汇率转换
参数:
- dollar:美元数量
- rate:美元汇率,默认值为6.32
返回值:
- 人民币数量11、高阶函数
当一个函数接收另一个函数作为参数的时候,就称这个函数为高阶函数。
functools模块
python中包含实用高阶函数以及装饰器的模块
reduce()函数:
functools.reduce(function, iterable[ ,initializer])
将iterable 可迭代对象中的元素作为参数依次应用到function函数中,最终返回累计的结果。
>>> def add(x, y):
return x+y
>>> import functools
>>> functools.reduce(add, [1, 2, 3, 4, 5])#相当于↓
15
>>> add(add(add(add(1, 2), 3), 4), 5)
15
>>> functools.reduce(lambda x,y:x*y, range(1, 11))
3628800partial()函数,偏函数
functools.partial(func, /, *args,**keywords)
对指定的函数进行二次包装,通常是将现有的函数部分参数预先绑定,得到的新函数即为偏函数。
也就是将一个函数的多个参数进行拆分,分为多次传递。
>>> square = functools.partial(pow, exp = 3)
>>> square(2)
8
>>> ssum = functools.partial(sum, start = 3)
>>> ssum([1, 2, 3])
9@wraps装饰器
装饰器的副作用:在使用了装饰器之后,装饰器装饰过的函数已经不是其本身了,是装饰器内部的函数,则导致函数名与其实际引用的函数名不一致。
>>> def zhuangshi(func):
def inner():
print('调用了inner')
return inner
>>> @zhuangshi
def outer():
print('调用了outer')
>>> outer.__name__ #副作用在这里
'inner'@wraps装饰器主要用来装饰装饰器
>>> import functools #导入了functools模块
>>> def zhuangshi(func):
@functools.wraps(func) #使用装饰器装饰了装饰器
def inner():
print('调用了inner')
return inner
>>> @zhuangshi
def outer():
print('调用了outer')
>>> outer.__name__ #没有副作用啦
'outer'十四、永久储存
1、打开文件
(1)创建并打开文件,open()函数
open()函数用于打开一个文件并返回其对应的文件对象。
open(file, mode= ‘r ‘ , buffering=-1, encoding=None,errors=None,newline=None,closefd=True,opener=None)
| 参数 | 含义 | |
| file | 指定一个将要打开的文件的路径(绝对路径或相对路径) | |
| mode | 可选参数,指定文件的打开模式: | |
| 字符串 | 含义 | |
| ‘r’ | 读取(默认) | |
| ‘w’ | 写入(如果文件已存在则先截断清空文件) | |
| ‘x’ | 排他性创建文件(如果文件已存在则打开失败) | |
| ‘a’ | 追加(如果文件已存在则在末尾追加内容),注1 | |
| ‘b’ | 二进制模式,注2 | |
| ‘t’ | 文本模式(默认),注3 | |
| ‘+’ | 更新文件(读取和写入) | |
更多参数请查看函数文档。
>>> f = open('D:/mypy/text.txt', 'w')
>>> f
<_io.TextIOWrapper name='D:/mypy/text.txt' mode='w' encoding='cp936'>随后在D:/mypy文件夹创建一个新文件text.txt,若未指定文件夹路径,则直接在python安装目录中创建文件,随后在该文件夹中可以看见新创建的文件。成功创建之后会返回文件对象,将文件对象赋值给变量f。
(2)文件对象的各种方法
| 方法 | 含义 |
| f.close() | 关闭文件对象 |
| f.flush() | 将文件对象中的缓存数据写入到文件中(不一定有效) |
| f.read(size=-1,/) | 从文件对象中读取指定数量的字符(或者遇到EOF停止)﹔当未指定该参数,或该参数为负值的时候,读取剩余的所有字符 |
| f.readable() | 判断该文件对象是否支持读取(如果返回的值为False,则调用read()方法会导致OSError异常) |
| f.readline(size=-1,/) | 从文件对象中读取一行字符串(包括换行符),如果指定了size参数,则表示读取 size个字符 |
| f.seek(offset,whence=0,/) | 修改文件指针的位置,从whence参数指定的位置((0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移 offset个字节,返回值是新的索引位置 |
| f.seekable() | 判断该文件对象是否支持修改文件指针的位置(如果返回的值为False,则调用seek(),tell(),truncate()方法都会导致OSError异常) |
| f.tell() | 返回当前文件指针在文件对象中的位置 |
| f.truncate(pos=None, /) | 将文件对象截取到pos 的位置,默认是截取到文件指针当前指定的位置 |
| f.write(text, /) | 将字符串写入到文件对象中,并返回写入的字符数量(字符串的长度) |
| f.writable() | 判断该文件对象是否支持写入(如果返回的值为 False,则调用write()方法会导致OSError异常) |
| f.writelines(lines, /) | 将一系列字符串写入到文件对象中(不会自动添加换行符,所以通常是人为地加在每个字符串的末尾) |
将字符串写入到文件中,使用write()、writeline()方法。
执行写入代码之后马上打开文件,并不能立即看见写入的内容,因为写入的内容还在文件的对象的缓冲区,只有将文件对象关闭之后,数据才能写入文件中。
使用flush()方法可以在不关闭文件的情况下将缓存区的内容写入文件。
>>> f.write('歪卜八卜')
4
>>> f.writelines(['玛卡巴卡\n', '唔西迪西'])
>>> f.close()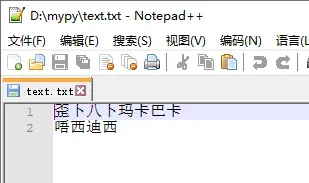
更新文件内容用’r+’,’r+’模式既可以读取也可以写入
文件对象是可迭代的,可以使用循环读取
可以通过read()、readline()方法读取文件,read读取到文件末尾,readline读取一行。
文件对象内部有文件指针,负责指向文件的当前位置,当在文件中读取一个字符的时候,文件指针就会指向下一个字符,直到文件末尾EOF(end of the file),因为之前使用了for语句对文件进行了读取,所以现在的文件指针指向了文件的末尾,所以使用f.read()没有返回字符。
使用tell()方法追踪文件指针的位置。
使用seek()方法修改文件指针。
>>> f = open('d:/mypy/text.txt', 'r+')
>>> f.writable()
True
>>> f.readable()
True
>>> for i in f:
print(i)
歪卜八卜玛卡巴卡
唔西迪西
>>> f.read()
''
>>> f.tell()
26
>>> f.seek(0)
0
>>> f.readline()
'歪卜八卜玛卡巴卡\n'
>>> f.read()
'唔西迪西'2、路径处理
pathlib –面向对象的文件系统路径
pathlib是Python3.4之后新添加的模块,它可以让文件和路径操作变得快捷方便,完美代替os.path模块。
(1)路径查询相关操作
cwd():获取当前目录路径
is_dir():判断一个路径是否为一个文件夹
is_file():判断一个路径是否为一个文件
exists():检测一个路径是否存在
name:获取路径的最后一个部分
stem:获取文件名
suffix:获取文件后缀
parent:获取父级目录
parents:获取逻辑祖先路径构成的不可变序列,支持索引
parts:将路径的各个组件拆分成元组
stat():查询文件或文件夹的信息
resolve():将相对路径转换为绝对路径
iterdir():获取当前路径下所有子文件和子文件夹
>>> from pathlib import Path
>>> Path.cwd()
WindowsPath('C:/Users/chaos/AppData/Local/Programs/Python/Python39')
>>> p = Path('C:/Users/chaos/AppData/Local/Programs/Python/Python39')
>>> p
WindowsPath('C:/Users/chaos/AppData/Local/Programs/Python/Python39')
>>> q = p / 'text.txt'
>>> q
WindowsPath('C:/Users/chaos/AppData/Local/Programs/Python/Python39/text.txt')
>>> p.is_dir()
True
>>> q.is_dir()
False
>>> p.is_file()
False
>>> q.is_file()
True
>>> q.exists()
True
>>> p.name
'Python39'
>>> q.stem
'text'
>>> q.suffix
'.txt'
>>> p.parent
WindowsPath('C:/Users/chaos/AppData/Local/Programs/Python')
>>> ps = p.parents
>>> for i in ps:
print(i)
C:\Users\chaos\AppData\Local\Programs\Python
C:\Users\chaos\AppData\Local\Programs
C:\Users\chaos\AppData\Local
C:\Users\chaos\AppData
C:\Users\chaos
C:\Users
C:\
>>> ps[3]
WindowsPath('C:/Users/chaos/AppData')
>>> p.parts
('C:\\', 'Users', 'chaos', 'AppData', 'Local', 'Programs', 'Python', 'Python39')
>>> q.stat()
os.stat_result(st_mode=33206, st_ino=15199648742442202, st_dev=1726722931, st_nlink=1, st_uid=0, st_gid=0, st_size=26, st_atime=1668584601, st_mtime=1668414575, st_ctime=1668413617)
>>> Path('./doc')
WindowsPath('doc')
>>> Path('./doc').resolve()
WindowsPath('C:/Users/chaos/AppData/Local/Programs/Python/Python39/Doc')
>>> for i in p.iterdir():
print(i)
C:\Users\chaos\AppData\Local\Programs\Python\Python39\DLLs
C:\Users\chaos\AppData\Local\Programs\Python\Python39\Doc
C:\Users\chaos\AppData\Local\Programs\Python\Python39\game.py
C:\Users\chaos\AppData\Local\Programs\Python\Python39\include
.
.
.
(2)修改路径相关操作
mkdir(parents, exists_ok):创建文件夹。路径中的父文件夹不存在会报错, 将parents参数设置为parents = true,在创建文件夹的同时创建不存在的父级文件夹。若创建的文件夹已经存在会报错,若设置exists_ok = true则忽略报错信息。
open():打开文件
rename():修改文件或者文件夹的名字
replace():替换指定的文件或文件夹
rmdir():删除文件夹。若文件夹下有文件,会报错
unlink():删除文件
glob(): 功能强大的查找功能
3、上下文管理器:with语句
#正常对文件进行操作
>>> f = open('text.txt', 'w')
>>> f.write('I Love Python.')
14
>>> f.close()
#使用with语句对文件进行同样的操作
>>> with open('text.txt', 'w') as f:
f.write('I Love Python.')
14正常的对文件进行操作有时候会忘记关闭文件,或者是程序在执行到close()之前就停止了运行,这样会导致之前写入的内容丢失,使用上下文管理器则可以确保文件资源的释放。
4、pickle模块
python对象序列化,也就是说将python对象转化为二进制字节流的过程
永久储存python对象,也就是说将字符串、列表、字典等python对象保存为文件的形式,.pkl文件
dump():将对象以二进制形式写入到.pkl文件中,
import pickle
x, y, z = 1, 2, 3
with open('test.pkl', 'wb') as f:
pickle.dump(x, f)#可以用元组进行打包
pickle.dump(y, f)#相当于pickle.dump((x, y, z), f)
pickle.dump(z, f)
load():从.pkl文件中读取存储的对象
import pickle
with open('test.pkl', 'rb') as f:
x = pickle.load(f)#使用元组打包的话,读取也应该解包
y = pickle.load(f)#相当于x, y, z = pickle.load(f)
z = pickle.load(f)
print(x, y, z, sep = ' ')
== RESTART: C:\Users\chaos\AppData\Local\Programs\Python\Python39\readtest.py ==
1 2 3十五、异常
1、程序报异常
查文档去
2、捕获并处理异常
(1)try-except

当检测范围内出现异常,则执行异常处理代码
>>> try:
1/0
except:
print('出错了')
出错了若检测范围没有异常,则不会执行异常处理代码
>>> try:
1/1
except:
print('出错了')
1.0expression用于指定想要捕获的异常,当程序异常与指定的异常相同时才会执行异常处理代码。
>>> try:
1 / 0
except ZeroDivisionError:#指定了除数为0的异常
print('除数为0')
除数为0
>>> try:
520 + '123'
except ZeroDivisionError:#未出现除数为0的异常
print('除数为0')
Traceback (most recent call last):
File "<pyshell#15>", line 2, in <module>
520 + '123'
TypeError: unsupported operand type(s) for +: 'int' and 'str'
也可以在该处使用元组打包多个想要捕获的异常,只要程序出现任何一个就执行异常处理代码。
>>> try:
520 + '123'
except (ZeroDivisionError, TypeError):#元组打包多个异常
print('出错了')
出错了当想捕获多个异常,并对不用的异常分别进行处理,只需要多个except语句即可。
>>> try:
520 + '123'#执行到该出时直接跳到对应的异常处理代码,之后的语句不执行
1/0
except ZeroDivisionError:
print('除数为0')
except TypeError:
print('数据类型出错')
数据类型出错as identifier用于提取出现异常的原因
>>> try:
520 + '123'
except TypeError as e:
print(e)
unsupported operand type(s) for +: 'int' and 'str'(2)try-except-else
当try语句执行时未出现异常,则执行else的内容
>>> try:
520 + 123
except:
print('类型错误')
else:
print('没有异常')
643
没有异常(3)try-except-finally
无论异常是否发生,都执行finally的内容
finally通常使用在程序收尾的地方,例如关闭文件。
>>> try:
520 + '123'
except:
print('类型错误')
else:
print('没有异常')
finally:
print('程序执行完毕')
类型错误
程序执行完毕
>>> try:
520 + 123
except:
print('类型错误')
else:
print('没有异常')
finally:
print('程序执行完毕')
643
没有异常
程序执行完毕(4)完整try语句语法

3、异常嵌套
>>> try:
try:
1/0
except:
print('内部异常')
520 + '123'
except:
print('外部异常')
finally:
print('程序结束')
内部异常
外部异常
程序结束4、raise语句,主动抛出异常
>>> raise ValueError("值不正确。")
Traceback (most recent call last):
File "<pyshell#50>", line 1, in <module>
raise ValueError("值不正确。")
ValueError: 值不正确。不能用该语句生成不存在的异常
>>> raise Error("值不正确。")
Traceback (most recent call last):
File "<pyshell#51>", line 1, in <module>
raise Error("值不正确。")
NameError: name 'Error' is not defined异常链
>>> raise ValueError("值不正确。") from TypeError
TypeError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "<pyshell#52>", line 1, in <module>
raise ValueError("值不正确。") from TypeError
ValueError: 值不正确。5、assert语句
跟raise类似,主动引发异常,但只能引发AssertionError异常。通常用于代码调试
>>> assert 'Love' == 'love'
Traceback (most recent call last):
File "<pyshell#53>", line 1, in <module>
assert 'Love' == 'love'
AssertionError6、利用异常来实现goto
>>> try:
while True:
while True:
while True:
for i in range(10):
print(i)
if i > 3:
raise
print('循环都被跳出了')
except:
print('跳出来了')
0
1
2
3
4
跳出来了十六、类和对象
对象 = 属性 + 方法
1、类、class关键字
类名用大写字母开头
属性是类中的变量,方法是类中的函数

2、封装
在创建对象之前,通过类将相关的属性和方法给打包到一起。然后再通过类来生成相应的对象。
python处处皆对象
self参数
>>> class C:
def hello():
print('hello')
>>> c = C()
>>> c.hello()
Traceback (most recent call last):
File "<pyshell#82>", line 1, in <module>
c.hello()
TypeError: hello() takes 0 positional arguments but 1 was given
>>> class C:
def getSelf(self):
print(self)
>>> c = C()
>>> c.getSelf()
<__main__.C object at 0x000002036622F5B0>
>>> c
<__main__.C object at 0x000002036622F5B0>传递到方法中self参数的实参就是实例对象本身
一个类可以生成无数个对象,当调用类中的方法时,python为了明确是哪一个实例对象在调用该方法,于是使用self参数将调用该方法的实例对象的信息进行了传递。
3、继承
>>> class A:
x = 1
def hello(self):
print('你好')
>>> class B(A):#继承自A
def bb(self):
print('我是B的对象')
>>> b = B()
>>> b.x
1
>>> b.hello()
你好
>>> b.bb()
我是B的对象当子类继承父类时,子类拥有和父类相同的方法和相同的属性,调用子类的方法时,会默认调用子类的方法,属性也是。
>>> class B(A):
x = 123
def hello(self):
print('我是B的对象')
>>> b = B()
>>> b.x
123
>>> b.hello()
我是B的对象isinstance():判断某个对象是否属于某个方法
>>> isinstance(b, B)
True
>>> isinstance(b, A)
Trueissubclass():检测一个类是否为某个类的子类
>>> issubclass(B, A)
True(1)多重继承
>>> class A:
x = 1
def hello(self):
print('你好')
>>> class B():
x = 123
def hello(self):
print('这里是B')
>>> class C(A, B):
pass
>>> c = C()
>>> c.x
1
>>> c.hello()
你好多重继承时,多个父类拥有同样的属性和方法,子类对象调用时优先级从左至右。
(2)组合
>>> class A:
def hello(self):
print('这里是A')
>>> class B:
def hello(self):
print('这里是B')
>>> class C:
def hello(self):
print('这里是C')
>>> class ABC:
a = A()
b = B()
c = C()
def hello(self):
self.a.hello()#a, b, c三个变量是属性,需要使用self进行绑定
self.b.hello()
self.c.hello()
>>> abc = ABC()
>>> abc.hello()
这里是A
这里是B
这里是C(3)绑定
实例对象跟类的方法进行绑定
实例能拥有自己的属性,如果要通过类的方法对属性进行操作,则需要使用self进行绑定。
>>> class A:
x = 120
def set_x(self, i):
self.x = i #对属性进行操作,需要self绑定
>>> a = A()
>>> a.set_x(520)
>>> a.x
520若没有这个self,那么直接对x进行操作,只是在set_x()函数内部创建了一个局部变量x
>>> class A:
x = 100
def set_x(self, i):
x = i
>>> a = A()
>>> a.set_x(250)
>>> a.x
100
>>> A.x
100直接对类中的属性进行更改(不建议这样操作),使用该类实例化的对象的该属性也会随之改变。因为此时实例化的对象并没有自己的属性
>>> class A:
x = 150
>>> a = A()
>>> A.x = 666
>>> a.x
666
>>> a.__dict__
{}(4)旁门左道,使用类来模拟字典
通常使用空类的实例来模拟字典
>>> class A:
pass
>>> a = A()
>>> a.x = 123
>>> a.y = 'Love'
>>> a.z = [1, 2, 3]
>>> print(a.x, a.y, a.z)
123 Love [1, 2, 3]
>>> d = {'x':123, 'y':'Love', 'z':[1, 2, 3]}#正常使用字典
>>> print(d['x'], d['y'], d['z'])
123 Love [1, 2, 3]4、构造函数__init__()
在类中定义__intit__()方法,就可以在实例化对象的时候实现一些变量的初始化
如果创建类的时候,没有添加构造函数,python解释器会自动创建一个不执行任何操作的默认构造函数;也就是说,只要创建类,一定会伴随着一个构造函数诞生。只不过可以自定义一个构造函数,也可以由python解释器自动创建一个默认的构造函数。
>>> class go:
def __init__(self, x, y):
self.x = x
self.y = y
def add(self):
return self.x + self.y
def mul(self):
return self.x * self.y
>>> a = go(3, 4)
>>> a.__dict__
{'x': 3, 'y': 4}
>>> a.add()
7
>>> a.mul()
125、重写
子类可以重新定义父类已有的属性和方法来对父类中同名的属性和方法进行覆盖。
可以在子类中直接调用父类的方法,即调用未绑定的父类方法。但会造成钻石继承的问题。
>>> class gozi(go):
def __init__(self, x, y, z):
go.__init__(self, x, y)#调用未绑定的父类方法
self.z = z
def add(self):
return go.add(self) + self.z#调用未绑定的父类方法
def mul(self):
return self.x * self.y * self.z
>>> b = gozi(2, 3, 4)
>>> b.__dict__
{'x': 2, 'y': 3, 'z': 4}
>>> b.add()
9
>>> b.mul()
24钻石继承
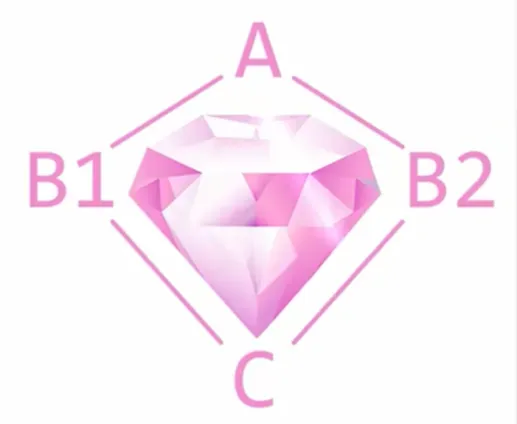
>>> class A:
def __init__(self):
print('这里是A')
>>> class B1(A):
def __init__(self):
A.__init__(self)
print('这里是B1')
>>> class B2(A):
def __init__(self):
A.__init__(self)
print('这里是B2')
>>> class C(B1, B2):
def __init__(self):
B1.__init__(self)
B2.__init__(self)
print('这里是C')
>>> c = C()
这里是A
这里是B1
这里是A
这里是B2
这里是CA被调用了两次,因为C调用B1、B2,B1、B2又分别调用了A。
为解决这个问题,可以使用super()函数
super()
在父类中搜索指定的方法,并自动绑定self参数
使用super函数去查找父类的方法,可以自动按照MRO顺序去搜索父类的相关方法,并且自动避免重复调用的问题。
>>> class A:
def __init__(self):
print('这里是A')
>>> class B1(A):
def __init__(self):
super().__init__()
print('这里是B1')
>>> class B2(A):
def __init__(self):
super().__init__()
print('这里是B2')
>>> class C(B1, B2):
def __init__(self):
super().__init__()
print('这里是C')
>>> c = C()
这里是A
这里是B2
这里是B1
这里是CMRO顺序
Method Resolution Order 方法解析顺序
出现同名的属性和方法python的查找覆盖顺序。
#mro方法
>>> C.mro()
[<class '__main__.C'>, <class '__main__.B1'>,
<class '__main__.B2'>, <class '__main__.A'>,
<class 'object'>]#object是所有类的基类
>>> B1.mro()
[<class '__main__.B1'>, <class '__main__.A'>, <class 'object'>]
#mro属性
>>> C.__mro__
(<class '__main__.C'>, <class '__main__.B1'>,
<class '__main__.B2'>, <class '__main__.A'>,
<class 'object'>)
>>> B1.__mro__
(<class '__main__.B1'>, <class '__main__.A'>, <class 'object'>)6、Mixin模式
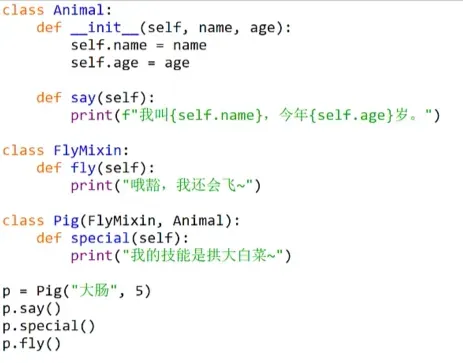
一种设计模式(利用编程语言已有的特性,针对面向对象开发过程中反复出现的问题而设计出来的解决方案),Mixin直译理解就是混入、补充的意思,它是多继承的一种。在多继承中,查找顺序是按MRO继承链中的顺序进行的。在不修改原有类代码结构的前提下,向类中添加新方法。
一个简单Mixin案例

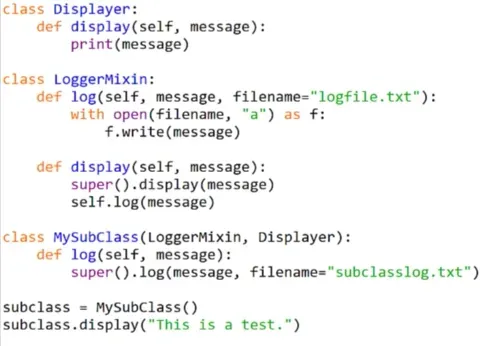
稍微难点的Mixin案例
MRO继承链

运行结果


7、多态
同一个运算符、函数或对象在不同的场景下具有不同的作用效果。
>>> 3 + 5#运算符的多态
8
>>> 'L' + 'ove'
'Love'
>>> len('Love')#函数的多态
4
>>> len(['lala', 'jiji', 'xixi'])
3(1)有关继承的多态
重写就是实现类继承的多态


正方形、圆形、三角形都继承自Shape类,都重写了构造函数和area()方法,即为多态的体现。
(2)自定义函数实现多态接口


向animal()函数中传入不同的对象,可以调用不同对象同样的方法,animal()则具有了多态性
(3)鸭子类型
鸭子类型(英语:duck typing)是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定。
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
并不关心对象是什么类型,到底是不是鸭子,只关心行为。


只要有animal()函数接收这个类的对象,然后并没有检查对象的类型,而是直接调用这个对象的intro和say方法。
python鸭子类型的灵活性在于它关注的是这个所调用的对象是如何被使用的,而没有关注对象类型的本身是什么。这里的自行车并不是动物,但是它有intro()方法和say()方法,他在这个地方就是一个动物了。
8、“私有变量”
一种保护机制,就是指通过某种手段,使得对象中的属性或方法无法被外部所访问。
在python中,仅限从一个对象内部才能够访问的“私有变量”并不存在,引入了一种name mangling的机制(名字改变、名称改写、名称修饰)
语法就是在名字前面加上两个下横线。

python中“私有变量”的实现方式就是将类中的变量偷偷改了个名字,也就是name mangling机制,方法名也可以进行同样的操作。

名字改编是发生在类实例化对象的时候,如果试图通过动态添加属性的方式来添加一个“私有变量”是不可行的,添加的变量并不会被name mangling机制改名。

单个下横线开头的变量
仅供内部使用的变量,约定俗成的命名规则,看到该类变量不要随意的去访问、修改它。
单个下横线结尾的变量
当想使用python自带关键词作为变量的时候,可以使用下横线结尾以示区分。
9、效率提升之道
在python中类的属性是通过字典来进行存放的,但是使用字典虽然效率很高的,但是需要占用大量的空间,利用空间换时间。
若当一个类的对象只需要固定的几个属性,以后也不会有动态添加属性的需求,那么再利用字典来存放属性是对空间的浪费。针对这种情况,python设计了一个__slots__的类属性
__slots__类属性

使用了__slots__类属性之后,无论是在实例化对象之后动态添加属性,还是在类的内部创建一个__slots__不包含的属性都是不被允许的。
使用了__slots__类属性之后,对象会划分一个固定大小的空间来存放指定的属性。__dict__属性也就没有了。
继承自父类的__slots__属性是不会在子类中生效,也会拥有__dict__属性。python只关注各个具体类中定义的__slots__属性
>>> class C:
__slots__ = ['x', 'y']
>>> class E(C):
pass
>>> e = E()
>>> e.x = 250
>>> e.y = 520
>>> e.z = 666
>>> e.__slots__
['x', 'y']
>>> e.__dict__
{'z': 666}10、python会魔法——魔法方法
__init__(self[, …])就是一个魔法方法,它可以在类实例化对象的时候自动进行调用
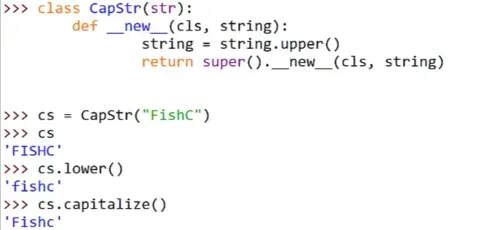
(1)__new__()方法
创建对象的方法
__new__(cls[, …]),该方法在__init__()之前被调用的,事实上对象是由__new__()创建的,第一个参数cls是类。所以对象的实例化流程是先调用__new__()方法创建一个实例,然后将其传递给__init__()方法。
之所以这里能对不可变对象进行修改,是因为在实例对象被创建之前进行了拦截,然后对其进行了修改,最后才调用super().__new__()去创建真正的实例。
因为CapStr是继承自str的,所以由CapStr实例化的对象也继承了str的方法
(2)__del__(self)方法
销毁对象时调用的方法
并不是使用了del就一定会触发__del__()方法,__del__()方法触发的条件是对象被销毁时它才会触发,python拥有垃圾回收机制garbage collection,意思是当检测到一个对象没有任何引用的时候才会将其销毁。
在该案例中,将c的引用赋值给了d,执行了del c之后,由于d还引用了原实例,所以并没有触发__del__()方法,在执行了del d之后,已经没有引用原实例的变量了,所以触发了垃圾回收机制,也就开始销毁原实例,也就触发了__del__()方法。

del方法可以通过创建一个该实例的新引用来推迟其销毁
方法一:创建一个全局变量将对象的引用传出去。

方法二:通过函数调用的形式(闭包),将对象的引用保存起来。
使用闭包将self保存在外部函数的x变量中,内部函数则是用来窃取这个self对象。
在创建对象时将闭包函数传入了实例中,而后在__del__()方法中调用闭包函数时是带参数self的,闭包就将这个self对象存储起来了。随后再次调用闭包,但是没有参数,于是闭包函数返回了之前保存下来的self对象。

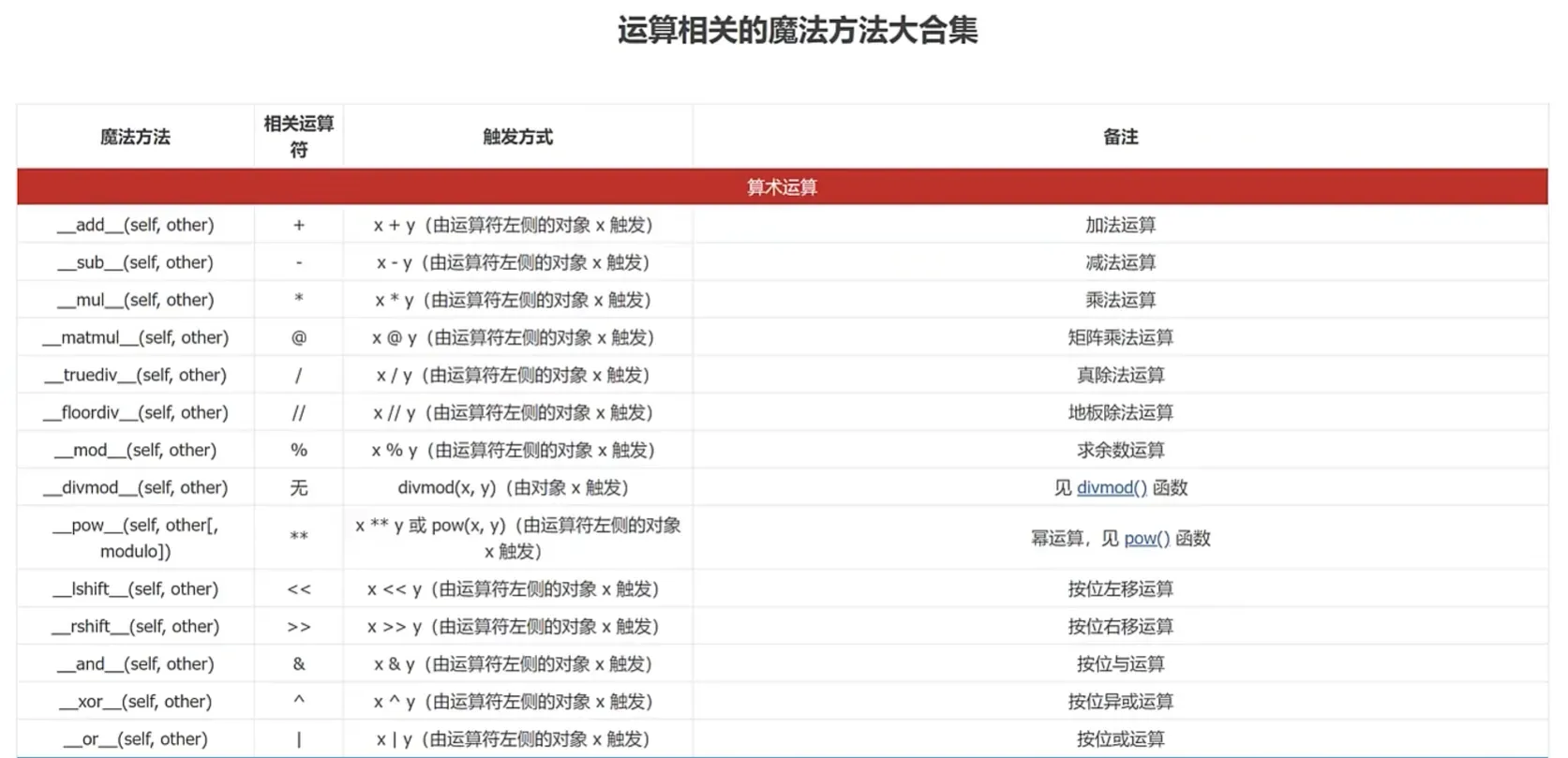
(3)运算相关的魔法方法
__add__()方法
重写__add__()方法实现对加法运算的拦截,实现两字符串相加不是拼接而是计算字符数之和
 __radd__()方法( r 反算数运算)
__radd__()方法( r 反算数运算)
__radd__()方法调用前提:当两个对象相加的时候,①如果左侧的对象和右侧的对象不同类型,并且②左侧的对象没有定义__add__()方法,或者其__add__()返回Notlmplemented(表示该方法是未实现的),那么Python就会去右侧的对象中找查找③是否有__radd__()方法的定义。
__iadd__()方法( i 增强赋值运算)
如果+=左侧的对象没有实现__iadd__()方法,那么python会使用相应的__add__()方法和__radd__()方法来替代

__int__()方法

位运算
与& 或| 非~ 异或^ 左移<< 右移>>






__index__(self)方法
当对象作为索引值时会触发该方法。

运算相关魔法方法合集



(4)属性访问相关的函数和魔法方法
python中为属性访问服务的BIF函数:hasaattr()、getattr()、setattr()、delattr()
hasaattr():检测对象是否有某个属性
getattr():获取对象中的某个属性值
setattr():设置对象中指定属性的值
delattr():删除对象中指定的属性

对应魔法方法
__getattr__(): 对应的是__getattribute__()魔法方法。
__getattr__()只有在用户试图去获取一个不存在的属性的时候才会触发。


__setattr__()
直接对self.name进行赋值会出现无限递归的错误,因此应避免使用__setattr__()对属性进行直接赋值,可以使用对属性字典进行操作来实现,__delattr__()也会出现同样的问题。


11、索引、切片、迭代协议
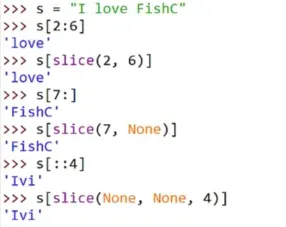
(1)针对索引、切片的魔法方法__getitem__()、__setitem__()
__getitem__(self, index)魔法方法
__index__()魔法方法并不是当对象发生索引的时候触发的方法,而是当对象被作为索引值使用的时候才会触发。
当对象被索引的时候会调用__getitem__(self, index)魔法方法。
它既能响应单个下标的索引操作,又能支持代表范围的切片索引方式

slice():BIF函数,切片操作是该函数的语法糖
__setitem__()魔法方法
为索引或切片赋值的操作则会被__setitem__()魔法方法所拦截

从可迭代对象中获取元素也会触发__getitem__(self, index)魔法方法

(2)针对可迭代对象的魔法方法__iter__(self)、__next__(self)
对应的BIF函数为iter()、next()
如果一个对象定义了__iter__()魔法方法,那么他就是一个可迭代对象
如果一个可迭代对象定义了__next__()魔法方法,那么他就是一个迭代器
可迭代对象中是没有__next__()的,因此for语句对可迭代对象进行遍历执行的操作首先是将对象传入内置函数iter()中,以拿到一个相应的迭代器,而后利用__next__()魔法方法进行真正的迭代操作

对for语句进行模仿:

自己创造一个迭代器对象

12、代偿
(1)__contains__(self, item)
实现成员关系的检测,对应的运算符是in,notin

(2)代偿
以迭代为例,若未定义__iter__()、__next__()魔法方法,那么将对象放到迭代工具中时,python在找不到__iter__()、__next__()魔法方法的情况下,就会尝试去查找__getitem__()魔法方法。
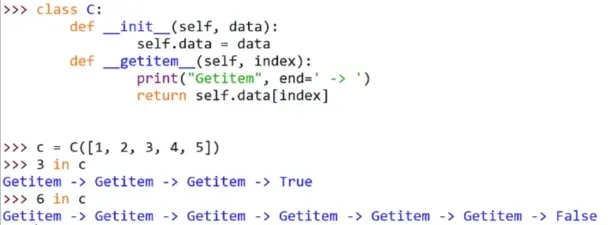
__contains__()魔法方法的代偿,若没有实现__contains__(),又使用in和notin进行成员关系判断,那么python会尝试查找__iter__()、__next__()魔法方法,使用迭代的方法去查找元素。

布尔测试,如果遇到bool()函数,python会寻找__bool__()魔法方法,如果未定义__bool__()魔法方法,那么python就会去寻找是否存在__len__()这个魔法方法的定义,如果有,那么__len__()魔法方法返回的值是非0,表示True,否则表示False

13、跟比较运算相关的魔法方法
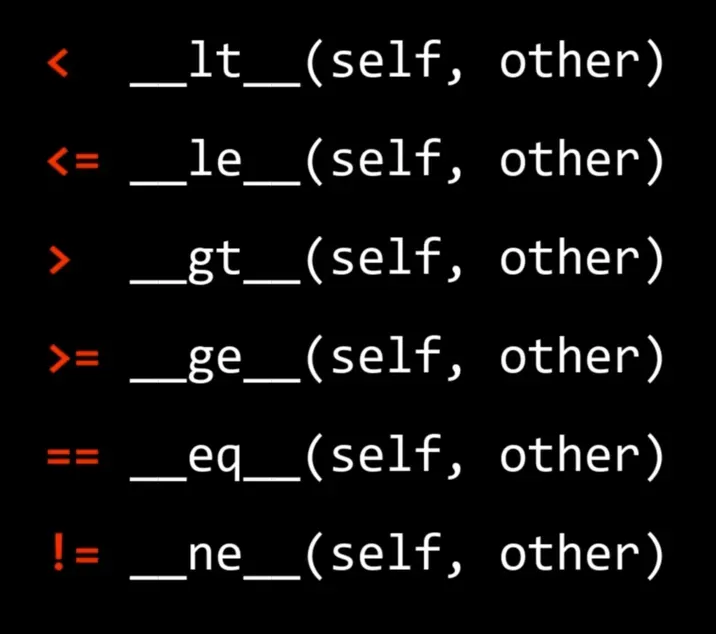
将比较字符串的功能更改为比较字符串的长度

若不想让某个魔法方法生效,可以直接将其赋值为None

14、给人看还是给程序看
(1)__call__(self, [, args…])
python可以像调用函数一样去调用一个对象,要求就是需要这个对象的类中有__call__()魔法方法。

__call__()支持位置参数和关键字参数

定义__call__()魔法方法可以实现使用闭包实现的工厂函数的效果。

(2)跟字符串相关的魔法方法:__str__(self)、__repr__(self)
__str__()响应的是str()内置函数的魔法方法
__repr__()对应的内置函数为repr()
str()函数是将参数转换为字符串对象,是给人看的;repr()函数则是将对象转换为程序可执行的字符串,是给程序看的
eval():将字符串转换为语句执行,去掉引号。为repr()的反函数

这两个魔法方法返回的都是字符串类型
__repr__()这个魔法方法是可以对__str__()魔法方法进行代偿的,反过来不行

__str__()魔法方法定义的只能应用于对象出现在打印操作的顶层的情况,也就是对该对象直接进行打印

如果定义__repr__()魔法方法则可以避免这个问题

通过同时定义两个方法的实现,可以让对象在不同场景下支持不同的显示效果

15、property()

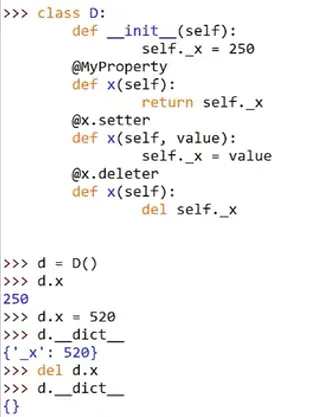
property()函数用于返回一个property属性对象
这个没有下横线的x就全权代理了_x,通过对x的访问和修改,都会影响到_x的值

使用__getattr__()、__setattr__()、__delattr__()三个魔法方法来实现以上案例的功能,很复杂。

装饰器是property()函数最经典的应用
将property()函数作为装饰器来使用,用于创建只读属性。原理是只赋值了property()的第一个参数,也就是实现获取的fget参数,另外两个参数为默认值None,表示不支持写入和删除。

用property()函数创建的属性对象拥有setter、getter、deleter三个方法

16、类方法和静态方法
(1)类方法@classmethod
专门用于绑定类的方法,使用@classmethod装饰器

funA:普通方法,绑定的是一个普通的对象object
funB:类方法,绑定的是一个类class
self参数与cls参数为约定俗成的命名,可以更改,但不建议。
类方法主要用于实现统计对象的数量或者通过创建一个列表来维护一个类对应的所有对象等需求
统计实例化对象的数量

如果创建跟类属性同名的实例属性,后者会覆盖类属性,但是此处使用了类方法get_count(),所以如果实例属性覆盖了类属性,依然不会对其有影响。
(2)静态方法@staticmethod
放在类里面的函数,跟普通函数的区别就是它可以放在类里面去,而且不需要绑定,即静态方法的参数不需要self,使用@staticmethod装饰器

使用静态方法模仿类方法实现统计实例化对象的数量的功能

使用了静态方法,如果实例属性覆盖了类属性,也不会对其有影响。
当操作不涉及类属性或者实例属性引用的时候,使用静态方法比较合适,类似于实现统计实例化对象的数量的功能则使用类方法更合适。
(3)对(1)中的统计实例化对象的数量功能进行优化
当涉及继承的时候,count的关系将会变得比较复杂,这时候引入add()类方法,可以避免混淆,不论子类或父类,哪个类去调用add()就会将其自身的类传进去,自增的count也是它们对应自身的count

17、描述符及property()实现原理
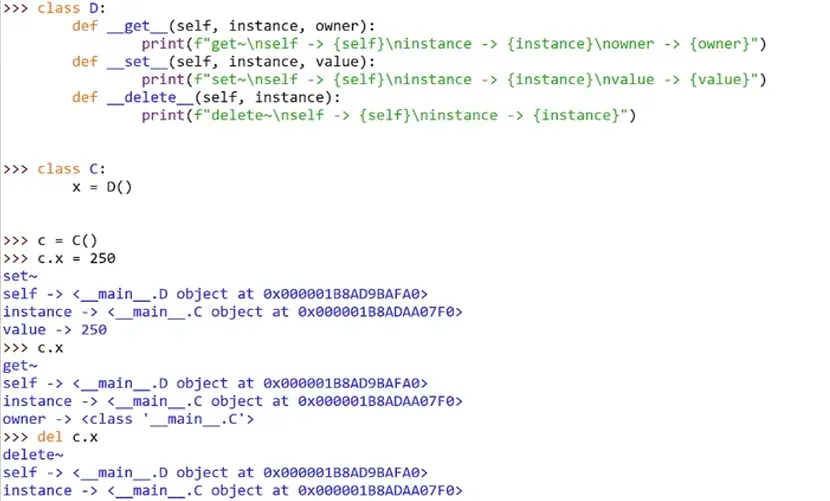
(1)描述符
定义:只要实现了__get__()、__set__()、__delete__()中任何一个或者多个方法的类,这个类就叫做描述符
拦截对象属性的读取、写入和删除的操作
__get__( self, instance, owner=None)
__set__(self, instance, value)
__delete__(self, instance) 要与__del__()魔法方法区分开
与魔法方法不同的是,它们管理的是其他类的属性,而不是自身类的属性
要使用描述符,只需要在另一个类中将描述符的实例化对象赋值给想要管理的属性
(2)使用描述符实现property案例的功能
property案例:

描述符实现:

(3)使用描述符创造一个property()函数

(4)实现getter()、setter()、deleter()三个方法

18、数据描述符、非数据描述符
对象方法绑定、静态方法、类方法以及类属性__slots__等都是基于描述符协议来实现的。
描述符只能用于类属性

描述符分类为数据描述符和非数据描述符,这是根据所实现的魔法方法的不同来进行划分的。
如果实现了__set__()、__delete__()任意一个方法,那么就是数据描述符
如果只实现了__get__()方法,则为非数据描述符
进行如此分类的原因在于优先级,当发生属性访问的时候,优先级从高到低依次是:数据描述符、实例对象属性、非数据描述符、类属性
>>> class D:
def __get__(self, instance, owner):
print('get')
>>> class C:
x = D()
>>> c = C()
>>> c.x
get
>>> c.x = 'nihao'
>>> c.x #因为优先级问题,未打印数据描述符中的get,而是实例对象属性
'nihao'
>>> C.x #类属性优先级较低,因此打印的是非数据描述符的get
get赋值操作属于类属性,被数据描述符拦截了

优先级是定义在__getattribute__()魔法方法的默认实现,__getattribute__()管理的是属性的获取

描述符的第四个魔法方法__set_name__(self, name, owner)
在实际的开发工作中,通过描述符拦截了一个属性,进行操作之后通常还需要进行访问、赋值、删除等操作,最后仍然是要写入到实例对象的属性中去,也就是在描述符中对实例对象的__dict__()字典进行操作,其中的关键就是instance参数代表的就是描述符所拦截的属性所在的实例对象。
实现在描述符中对实例对象的__dict__()字典进行操作的功能

以上的实现方法有一些瑕疵,于是就有了__set_name__()魔法方法

19、函数、方法、静态方法、类方法的底层实现原理
通过描述符实现的
但是,没听懂……
20、类装饰器
与函数装饰器的用法相似


类装饰器的作用就是在类被实例化对象之前对其进行拦截和干预
用类来做装饰器,用于装饰函数,统计函数被调用的次数
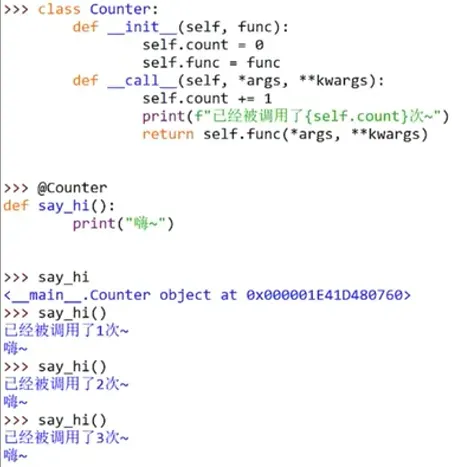
在调用say_hi()的过程中,由于@Counter相当于say_hi=Counter(say_hi),将say_hi()作为参数传递进了类Counter中,在Counter中将say_hi()函数改变为了类Counter的实例化对象,从而触发了__call__()魔法方法。
21、type()函数和__init_subclass__
虽然可以是用type()函数来检测对象类型,但是并不推荐,推荐使用的是isinstance(),因为isinstance()函数会考虑到子类的情况。
type()的一些小用法

type()第二种用法:根据传入的三个参数,返回一个新的type对象
class type(name, bases, dict, **kwds)
name:指定创造类的名字
bases:指定创造类的父类,为元组类型
dict:指定创造类的属性和方法,为字典类型
kwds:可选收集参数,当且仅当需要时,该收集参数将被传递给适当的元类机制(通常为__init_subclass_())




__init_subclass__(),python3.6新添加的类方法
用于加强父类对子类的管理,子类D定义完成之后,其父类的__init_subclass__()方法就会被触发
在子类中定义的x会被父类的__init_subclass__()方法所覆盖

当使用type()函数来构造class D这种继承了定义过__init_subclass__()的父类时,如果需要给__init_subclass__()传递参数,type()函数的第四个参数就排上了用场。

使用type()实现以上代码
type()第四个参数为搜集参数,可以多个参数同时传递

22、元类(metaclass)

元类是99%的用户都无需关注的终极魔法,如果你犹豫是否需要使用元类,那么你肯定是不需要的,因为真正需要用到元类的人,是不会纠结这个问题的。
类是创造对象的模板,元类就是创造类的模板,type本身就是一个元类,所以它能够用来创造类。
类之间存在继承关系,元类也一样,所有元类都继承自type
想要创建一个元类,就需要让它继承自type
最简单的元类
如果没有MetaC()这个元类,直接执行type(C),返回的是<class ‘type’>,而在以下代码中,相当于元类在类和type之间架上了MetaC()这个桥梁

__init__()并非实例化对象调用的第一个魔法方法,而是__new__(),现在来定义元类和类里面的__init__()和__new__()魔法方法
元类MetaC的__new__()方法是在类C定义完成的时候被触发的
类C的__new__()方法是在类实例化对象的时候被触发的
类C的super.__new__()调用的是object的new,而不是MetaC的new,因为当一个类没有指定父类的时候,就会直接找到object。不能将元类与父类搞混淆了,元类是比类更高一个级别。

在类里面的__call__()方法就是拦截对象被当做函数调用时候的操作,__call__()方法定义在元类中实现的是拦截类实例化对象的操作

23、元类的应用
(1)给所有的类添加一个属性
使用__new__()实现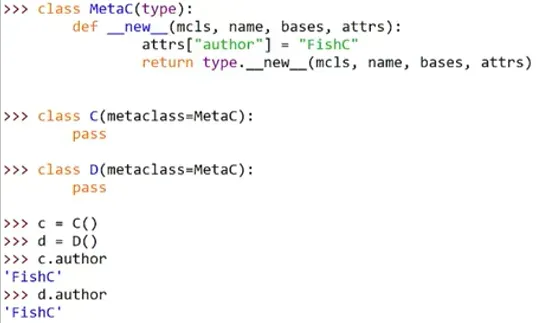
使用__init__()实现
(2)对类名的定义规范做限制

(3)修改对象的属性值
把对象的所有字符串属性值都变为大写,重新定义的是__call__(),是因为要操作的是类实例化的过程,把它在实例化的过程中传入的属性值变为大写。

(4)限制类实例化时的参数传递方式
实现类在实例化对象的时候,只能通过关键字参数进行参数传递

(5)禁止一个类被实例化

如果类不能实例化对象,还能通过静态方法、类方法的形式来进行使用

(6)只允许实例化一个对象
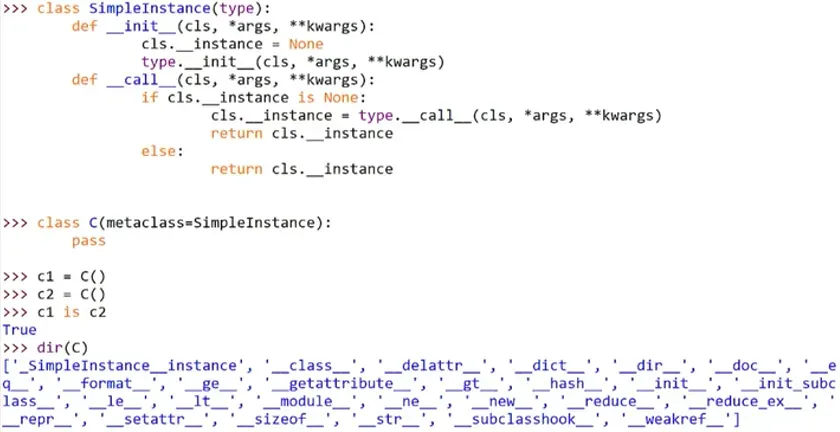
文章出处登录后可见!