简介
贝叶斯算法是由英国数学家托马斯·贝叶斯提出的,这个算法的提出是为了解决“逆向概率”的问题。首先我们先来解释下正向概率与逆向概率的含义:
正向概率:假设一个箱子里有5个黄色球和5个白色球,随机从箱子里拿出一个球,请问取出的是黄球的概率是多少?很容易计算P(黄球)= N(黄球)/N(黄球)+ N(白球) = 5/5+5 = 1/2。
逆向概率:起初我们并不知道箱子里有多少个球,我们依次从箱子里取出10个球,发现这个10个球中有7个白球,3个黄球,那么我们会根据我们观察到的结果去推测箱子里白球与黄球的分布比例大概是7:3,但是我们无法推测出箱子里的球的个数。
朴素贝叶斯分类(NBC)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入X求出使得后验概率最大的输出Y。
以下先介绍贝叶斯定理:
贝叶斯定理
在统计学中有两个较大的分支:一个是“频率”,另一个便是“贝叶斯”,它们都有各自庞大的知识体系,而“贝叶斯”主要利用了“相关性”一词。下面以通俗易懂的方式描述一下“贝叶斯定理”:通常,事件 A 在事件 B 发生的条件下与事件 B 在事件 A 发生的条件下,它们两者的概率并不相同,但是它们两者之间存在一定的相关性,并具有以下公式(称之为“贝叶斯公式”):

- P(A) 这是概率中最基本的符号,表示 A 出现的概率。比如在投掷骰子时,P(2) 指的是骰子出现数字“2”的概率,这个概率是 六分之一。
- P(B|A) 是条件概率的符号,表示事件 A 发生的条件下,事件 B 发生的概率,条件概率是“贝叶斯公式”的关键所在,它也被称为“似然度”。
- P(A|B) 是条件概率的符号,表示事件 B 发生的条件下,事件 A 发生的概率,这个计算结果也被称为“后验概率。
举一例子说明贝叶斯公式:
有两个桶,1号桶里有40个球,其中30个白球,10个黑球;2号桶里也有40个球,其中20个白球,20个黑球。
先假设几个事件:
A事件:抓取1个球,球来自1号桶。
B事件:抓取的是白球。
C事件:抓取1个球,球来自2号桶。
条件概率:从1号桶中抽取白球的概率P(B|A)=30/(30+10)=75%;从2号桶中抽取白球的概率P(B|C)=20/(20+20)=50%,这些都是条件概率。
全概率:抽取一个球,为白球的概率,这个概率叫全概率,是1号桶中抽取白球和2号桶中抽取白球两个事件的概率之和,即 P(B)=P(B|A)P(A)+P(B|C)P(C)=75% * 50% + 50% * 50%= 62.5%。
逆概率/贝叶斯定理:抓取了一个球是白球,那么这个白球来自1号桶的概率P(A|B)是多少,这就是典型的贝叶斯定理解决的问题。
1. 先求P(A),即抓取一个球,球来自A桶的概率,这叫做【先验概率】,也就是在没有约束条件(约束条件为抽取的是白球)下事件A发生的概率,这个很好计算为50%。
2. 再求P(B|A)/P(B),这叫做【可能性函数】或【调整函数】,也就是在已知条件下抓取的是白球的情况下,对P(A)进行调整的因子。根据上文计算的P(B|A)= 75%,P(B)= 62.5%,得出调整因子为75%/62.5%=1.2。
3. 最后求P(A|B),也被叫做【后验概率】= 【先验概率】 * 【调整函数】= P(A) * (P(B|A)/P(B)) = 50% * 1.2 = 60% 。
朴素贝叶斯算法
基于贝叶斯定理,朴素贝叶斯就是一种简单的贝叶斯算法,因为贝叶斯定理涉及到了概率学、统计学,其应用相对复杂,因此我们只能以简单的方式使用它,比如天真的认为,所有事物之间的特征都是相互独立的,彼此互不影响。
特征条件假设:假设每个特征之间没有联系,给定训练数据集,其中每个样本都包括维特征,即 ,类标记集合含有种类别,即
,类标记集合含有种类别,即 。
。
对于给定的新样本 ,判断其属于哪个标记的类别,根据贝叶斯定理,可以得到属于类别
,判断其属于哪个标记的类别,根据贝叶斯定理,可以得到属于类别
后验概率最大的类别记为预测类别,即 :。
:。
朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征 互相独立,在这个假设的前提上,条件概率可以转化为:
互相独立,在这个假设的前提上,条件概率可以转化为:
代入上面贝叶斯公式中,得到:

于是,朴素贝叶斯分类器可表示为:
因为对所有的,上式中的分母的值都是一样的,所以可以忽略分母部分,朴素贝叶斯分类器最终表示为:

举一例子说明朴素贝叶斯算法:
给定数据如下:
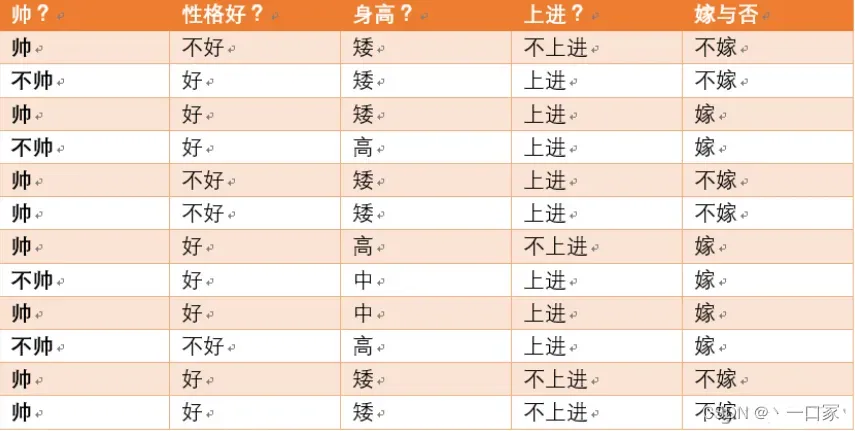
问题:如果一对男女朋友,男生想女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
这是一个典型的分类问题,转为数学问题就是比较p(嫁|(不帅、性格不好、身高矮、不上进))与p(不嫁|(不帅、性格不好、身高矮、不上进))的概率,谁的概率大,我们就能给出嫁或者不嫁的答案。
由朴素贝叶斯公式可知:
由上图易知 p(嫁) = 6/12= 1/2,p(不帅|嫁) = 3/6 = 1/2,p(性格不好|嫁)= 1/6,p(矮|嫁) = 1/6,p(不上进|嫁) = 1/6,p(不帅) = 4/12 = 1/3,p(性格不好) = 4/12 = 1/3,p(身高矮) = 7/12, p(不上进) = 4/12 = 1/3。
将以上结果带入
得p(嫁|(不帅、性格不好、身高矮、不上进)) 0.053。
0.053。
同理可求出p(不嫁|(不帅、性格不好、身高矮、不上进))0.964.
0.964>0.053,于是有p (不嫁|不帅、性格不好、身高矮、不上进)>p (嫁|不帅、性格不好、身高矮、不上进),所以我们根据朴素贝叶斯算法可以给这个女生答案,是不嫁。
垃圾邮件过滤
通过朴素贝叶斯算法过滤垃圾邮件的训练步骤大致如下:
一:将收集的数据集标注上ham或spam的标签,ham表示为正常邮件,spam表示为垃圾邮件。
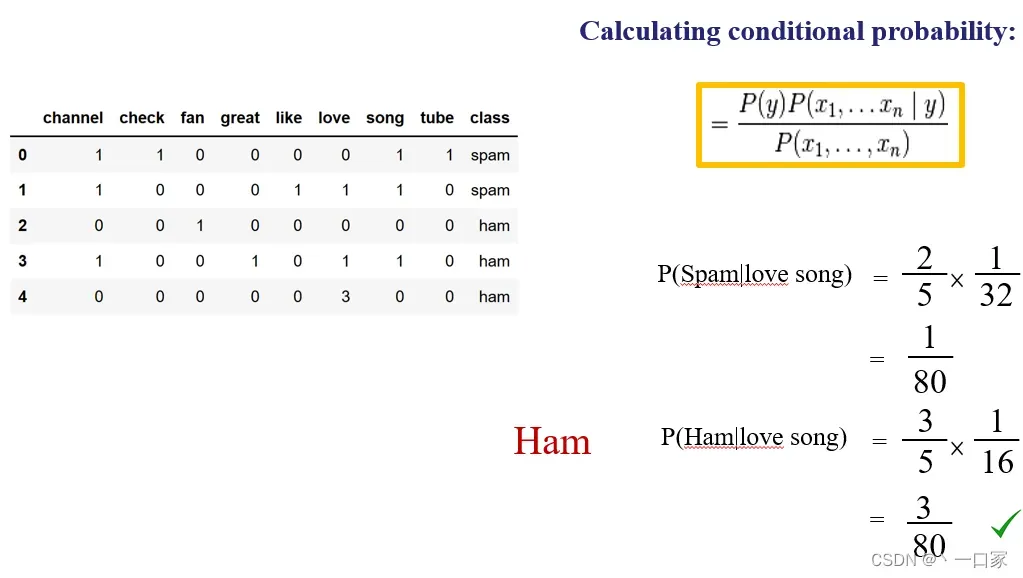
例如收集了以下五条邮件并进行标注:
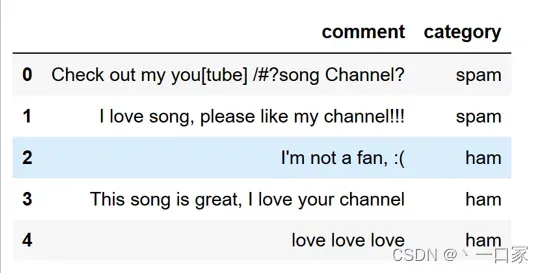
二:将每条邮件中的数据进行预处理,基本流程为:识别并切分邮件中的单词——>将切分出来的单词进行小写化处理——>将长度小于3的单词与停用词剔除——>统计剩余单词出现次数。

上述所有邮件在进行预处理后画出的统计表如下:
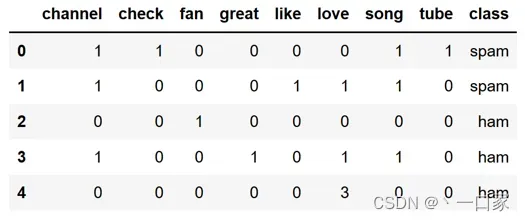
三:通过朴素贝叶斯算法计算并比较P(Spam|I love song)=P(Spam|love song)与P(Ham|I love song)=P(Ham|love song)的大小并以此构造分类器判断”I love song”到底是不是垃圾邮件。

首先由表可知P(Spam)=2/5,P(Ham)=3/5。

其次由表亦可知P(love|Spam)=1/8,P(song|Spam)=2/8,P(love|Ham)=4/8,P(song|Ham)=1/8。
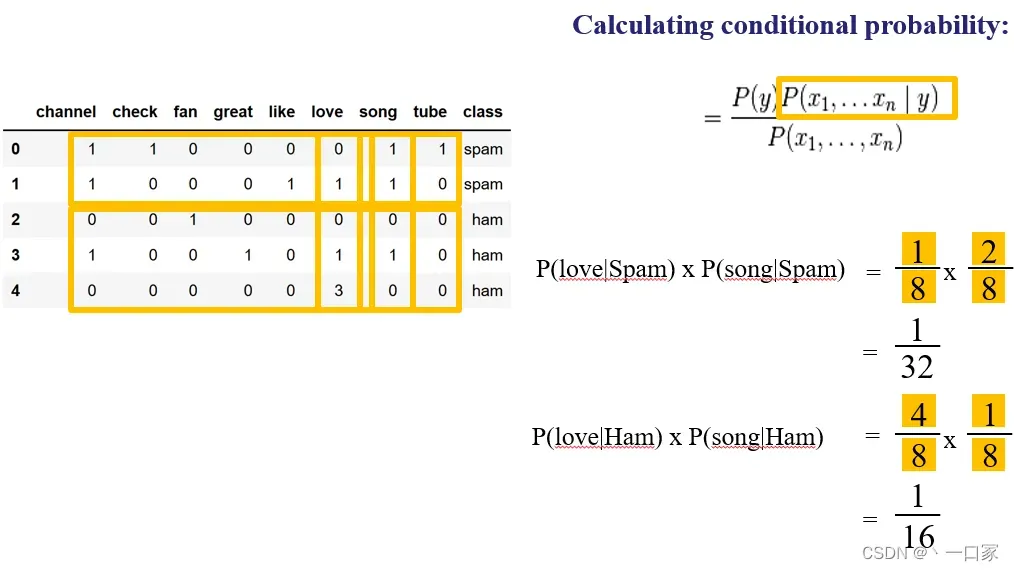
最后由朴素贝叶斯算法可知
P(Spam|love song)=P(Spam)*P(love|Spam)*P(song|Spam)=2/5*1/8*1/4=1/80。
P(Ham|love song)=P(Ham)*P(love|Ham)*P(song|Ham)=3/5*1/2*1/8=3/80。
显然3/80>1/80,故”I love song”邮件被分为Ham一类,并非垃圾邮件。
python代码实现
一 准备收集好的数据集,并下载到本地文件夹
ham文件夹下的文件为正常邮件,里面共有25封txt格式按数字命名顺序排列的正常邮件
正常邮件内容如下图所示:

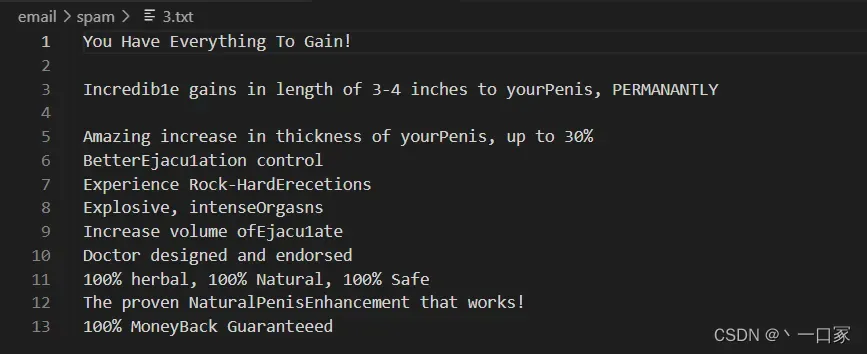
spam文件下的txt文件为垃圾邮件,里面有25封txt格式按数字命名顺序排列的垃圾邮件
垃圾邮件内容如下图所示:
数据集下载地址:垃圾邮件数据集
提取码: 1234
二 朴素贝叶斯分类器训练函数
参数:
trainMatrix – 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory – 训练类别标签向量,即loadDataSet返回的classVec
返回值:
p0Vect- 正常邮件类的条件概率数组
p1Vect – 垃圾邮件类的条件概率数组
pAbusive- 文档属于垃圾邮件类的概率
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) # 计算训练的文档数目
numWords = len(trainMatrix[0]) # 计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) # 文档属于侮辱类的概率
p0Num = np.ones(numWords); p1Num = np.ones(numWords) # 创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 # 分母初始化为2,拉普拉斯平滑
for i in range(numTrainDocs):
if trainCategory[i] == 1: # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Denom) # 取对数,防止下溢出
p0Vect = np.log(p0Num/p0Denom)
return p0Vect, p1Vect, pAbusive # 返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
三 朴素贝叶斯分类器训分类函数
参数:
vec2Classify – 待分类的词条数组
p0Vec – 正常邮件类的条件概率数组
p1Vec- 垃圾邮件类的条件概率数组
pClass1 – 文档属于垃圾邮件的概率
返回值:
0 – 属于正常邮件类
1 – 属于垃圾邮件类
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) # 对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1)
p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0四 定义切分预处理函数
def createVocabList(dataSet):
vocabSet = set([]) # 创建一个空的不重复列表
for document in dataSet:
vocabSet = vocabSet | set(document) # 取并集
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else: print("the word: %s is not in my Vocabulary!" % word)
return returnVec # 返回文档向量
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量
for word in inputSet: # 遍历每个词条
if word in vocabList: # 如果词条存在于词汇表中,则计数加一
returnVec[vocabList.index(word)] += 1
return returnVec # 返回词袋模型
def textParse(bigString): # 将字符串转换为字符列表
# 使用W 或者W+ 都可以将字符数字串分割开,产生的空字符将会在后面的列表推导式中过滤掉
listOfTokens = re.split(r'W+', bigString) # 将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] # 除了单个字母,例如大写的I,其它单词变成小写
五 测试朴素贝叶斯分类器,使用朴素贝叶斯进行交叉验证
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26): # 遍历25个txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) # 读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1) # 标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) # 读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0) # 标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) # 创建词汇表,不重复
trainingSet = list(range(50)); testSet = [] # 创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10): # 从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) # 随机选取索引值
testSet.append(trainingSet[randIndex]) # 添加测试集的索引值
del(trainingSet[randIndex]) # 在训练集列表中删除添加到测试集的索引值
trainMat = []; trainClasses = [] # 创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: # 遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) # 将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) # 将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) # 训练朴素贝叶斯模型
errorCount = 0 # 错误分类计数
for docIndex in testSet: # 遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误
errorCount += 1 # 错误计数加1
print('classification error',docList[docIndex])
print('the error rate is:%.2f%%' % (float(errorCount) / len(testSet) * 100))
六 测试结果截图
![]()


可以看出实验结果错误率大概在0%~20%之间。
文章出处登录后可见!